« 読了:Pan, et al. (2014) 標本ウェイティングの下で中央値や分位数について群間の差を検定する方法 | メイン | 読了:Hadfield(2010) MCMCglmmパッケージ »
2017年1月22日 (日)
ここんとこ山のようなデータ整形を抱え込んでいて、これはほんとに終わるのかという不安と、こんなことをしていてよいのかという不安に両側から押し潰されそうだが... とにかく仕事があるだけありがたいと考えるべきか。
ともあれ、ちょっと驚いたことがあったのでメモしておく。なんだか恥をさらしているような気も致しますが。
Rで、ユニークなキーを持つとても大きなテーブルを左外部結合(LEFT JOIN)したいとき、どうするのが速いか。
思いつくのは、
- 素直にmerge()する
- merge()より高速だといわれている, Hadley神つくりたもうた dplyr::left_join() を使う
- match()で行位置を探し、テーブルの行を並び替えてくっつける
- match()で行位置を探しておき、テーブルの各変数を ひとつづ並び替えてくっつける
4番目のは一種の冗談のつもりであった。そんなん遅いにきまってるじゃん? たぶん2,1,3,4の順だろう。いやひょっとして2,3,1,4かな。私はそう思いました。
衝撃の結果は下図。クリックで拡大。Rpubsにものっけてみました。
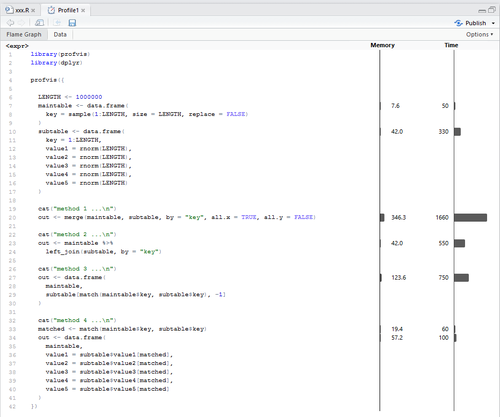
4がぶっちぎりで優勝。ぐぬぬぬ。これまでの苦労は何だったんだ。
雑記:データ解析 - RでどうやってLEFT JOINするか (ああなんて最先端な話題だろうか)