メイン > 雑記:データ解析
2020年3月11日 (水)
仕事の都合であれこれ考えていたらわけがわからなくなってしまったので、ちょっとシミュレーションをやってみたら、さらに新たな疑問が生じ... という話を記録しておく。
背景
ある量的変数の時系列 $Y_t$ があって、それに影響を及ぼしているであろうなんらかの変数の時系列$X_t$があるとする。なんでもいいんだけど、たとえば売上と広告出稿量とか。
で、$Y_t$に対する$X_t$の効果の大きさをデータから推定したい。こういうこと、よくありますよね。
話を簡単にするために、分析者は次のことを知っているとしよう。
- $X_t$の$Y_t$に対する効果は即時的、かつ線形である。つまり、
$Y_t = \alpha + \beta X_t + V_t$
とモデル化できる。 - $X_t$は定常である。なんでそんなことを知っているのかわからんが、なにか実質的な知識があるのでしょう。
- $Y_t$の撹乱項$V_t$は一次自己回帰過程 (AR(1)過程)に従う。つまり、
$V_t = \rho V_{t-1} + E_t, \ \ E_t \sim N(0, \sigma_E^2)$
とモデル化できる。これも、まあ、ありそうな仮定ですわね。時系列の自己相関関数を観察した結果、これAR(1)でいいんじゃね? と思うことはさほど珍しくないと思う。 - 自己回帰係数$\rho$は$0 \leq \rho \leq 1$である。つまり、$V_t$は非負の自己回帰係数を持つ定常AR(1)過程に従う($0 \leq \rho <1$)か、単位根AR(1)過程に従う($\rho = 1$)かのどちらかである。これもそれほど変な仮定ではないと思う。自己回帰はふつう正だし、もし負だったらデータの観察でそれと気がつくだろう。仮に$\rho >1$なら$V_t$はどっかに飛んでいってしまうはずなので、これも除外できる。でも、$\rho <1$か$\rho = 1$かは簡単には判断できない。
問題
さて、分析者が関心を持っているのは$\beta$である。ここで疑問なのは、$\beta$の推定誤差は$\rho$とどういう風に関連しているのか、という点である。特に次の点について知りたい。
- Q1. $\rho$が大きいとき、つまり結果変数の撹乱項が高い自己相関を持つとき、$\beta$の推定誤差は大きくなるか、それとも小さくなるか。
- Q2. $\rho = 1$であるのにそれと知らず、$\rho < 1$と仮定するモデルを推定したとき、$\beta$の推定誤差は大きくなるか。
いずれも、私にとってはちょっと切実な疑問だ。
Q1についていえば... 仕事のなかで時系列データの分析が生じる際、まずは目的変数の時系列を観察して、これからわざわざ説明変数のデータを集めモデリングする労力は報われるかしらん? と算段することが多いと思う。そういう場面での手掛かりがほしい。見通しが暗いなら早めに白旗を上げたい。
Q2についていえば... 理屈の上からいえば、$\rho=1$かそうでないかでAR(1)過程の挙動はがらっとかわる。でも、実データの背後にあるデータ生成プロセスが$\rho=1$かどうかなんて、どうせわかりっこない。だから、きっと$\rho<1$だよねと信じてAR(1)誤差を仮定したり、いや$\rho=1$にちがいないと信じて差分時系列を分析したりするわけである(そんなことないですか?)。でも心には常に不安の影が付きまとう。$\rho$についての仮定をしくじることが、$\beta$の推定にとってどのくらい致命的なのかを知りたい。
方法
気になって夜も眠れないので(大げさな表現)、簡単なシミュレーションをやってみました。
$t=-100,\ldots,100$について、データを次のように生成した。
$x'_t \sim unif(0, 1)$
$e_t \sim N(0, 1)$
$v_t = \rho v_{t-1} + e_t$
$y'_t = x't + v_t$
つまり$\beta = 1$である。で、$x'_t, y'_t$から$t=1$以降を切り出し、それぞれを中心化する。これを$x_t, y_t$とする。
$\rho$を$0, 0.1, 0.2, \ldots, 1.0$の11通りに動かし、それぞれについて1000個のデータセットを生成した。
それぞれについてデータセットをひとつ選び$x_t, y_t$を描画すると、こんな感じである。
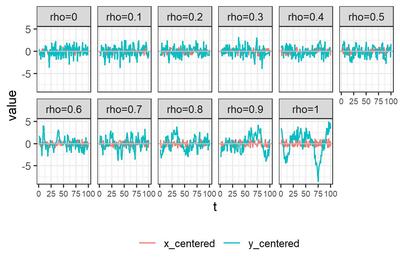
モデルの推定方法として、次の6つを試す。
- A. 単にOLS推定
- B. Rのforecast::Arima()でML推定
- C. Rのnlme::gls()でFGLS推定
- D. 状態空間モデルとして定式化し、RのKFASパッケージを使ってカルマンフィルタで推定
- E. Mplusでベイズ推定
- F. Stanでベイズ推定
推定にあたっては、次の5つのアプローチを試してみる。
- アプローチ1. $\rho = 0$と仮定して、
$y_t = \beta x_t + e_t$
$e_t \sim N(0, \sigma_e^2)$ - アプローチ2. $|\rho| < 1$と仮定して、
$y_t = \beta x_t + v_t$
$v_t = \rho v_{t-1} + e_t, \ \ |\rho| < 1$
$e_t \sim N(0, \sigma_e^2)$ - アプローチ3. $\rho = 1$と仮定し、$\Delta y_t = y_t - y_{t-1}, \Delta x_t = x_t - x_{t-1}$について、
$\Delta y_t = \beta \Delta x_t + e_t$
$e_t \sim N(0, \sigma_e^2)$ - アプローチ4. $y_t$について単位根検定を行い、単位根を持たないと判断されたらアプローチ2, 持つと判断されたらアプローチ3に進む。
- アプローチ5: アプローチ2と同じなんだけど、$\rho$の範囲について仮定しない。
私の乏しい理解では、A(OLS), B(ML), C(FGLS)では撹乱項の定常性が仮定されるので、アプローチ5は選べない。いっぽうD(カルマンフィルタ), E,F(ベイズ)では、$\rho$を明示的に制約しないかぎりアプローチ5になる... というように理解しているのだけれど、ここ、全然自信がない。悲しい。誰か私に教えてくださらないでしょうか。
まあいいや!とにかくシミュレーションしてみたのであります。
単位根検定
まず、アプローチ4で必要になる単位根検定の結果について紹介しておく。Dickey-Fuller検定を使った。Rコードはこんな感じ。$y_t$がdfIn$y_centeredにはいっている。
library(urca)
oDFTest <- ur.df(dfIn$y_centered, type = "none", lags = 1)
nD <- if_else(oDFTest@teststat[1,1] < oDFTest@cval[2], 0, 1)
トレンドもドリフトもないAR(1)であると知っているので、type ="none", lags=1と決め打ちしている。$H_0: \rho=1$が 5%水準で棄却されたら$\rho<1$と判断し、そうでなかったら$\rho=1$と判断することにして、後者の場合にnDを1としている。
素朴に考えると、本当は$\rho=1$であるデータセットのうち95%くらいが$\rho=1$と判断されてほしい($H_0$が真のときに誤って棄却される確率は5%であってほしい)。本当は$\rho<1$である場合は、なるべく多くのデータセットが$\rho<1$と判断されてほしい。
さて、11通りの$\rho$の、それぞれ1000個のデータセットのうち、$\rho = 1$と判断されたデータセットの数は?
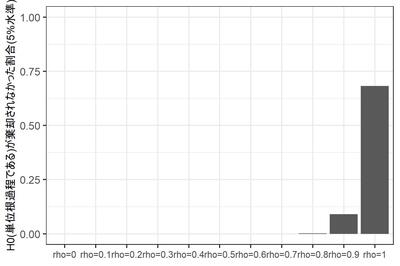
蓋をあけてみると... $\rho=1$であるデータセットのうち、$H_0$が棄却されなかった($|\rho|=1$と判断された)データセットは95%には到底及ばず、実に68%にとどまる。なぜだろう? よくわからない。
$\rho<1$であるにもかかわらず$H_0$が棄却されないデータセットは、当然ながら$\rho$が1に近づくにつれて増えるのだが、それでも$\rho = 0.9$のときに9%。$\rho = 0.8$までではほとんど生じない。
このように、DF検定の場合、保守側($H_0: \rho = 1$が棄却されない側)に大きくバイアスがかかるようだ。$H_0$を反対側に設定するPP検定であればまた違う結果になるだろうけど...
まあとにかく、ここで確認しておきたいのは、$\rho = 1$かそうでないかなんて、そんなに簡単にはわからないよね、ということである。
選手紹介
お待たせしました、選手入場です。拍手でお迎え下さい。
A. 単にOLS推定。アプローチ1($\rho=0$と仮定)のRコードは
oModel <- lm(y_centered ~ 0 + x_centered, data = dfIn)
自己相関を華麗にスルーしちゃうわけだが、これ、それほど捨てたもんじゃないと思う次第である。だって、$|\rho| < 1$であれば、$\hat{\beta}$は少なくとも一致推定量ではあるわけでしょう?
アプローチ1, 3($\rho=1$と仮定)を試してみる。
B. forecast::Arima()で最尤推定。Rによる時系列モデリングの定番 forecast パッケージはArima()という関数をご用意している(実はstat::arima()へのラッパーである)。アプローチ2($|\rho|<1$と仮定)のRコードはこんな感じ。
library(forecast)
oModel <- Arima(
y = dfIn$y_centered,
include.mean = FALSE,
order = c(1, 0, 0),
xreg = dfIn$x_centered ,
method = "ML"
)
アプローチ3($\rho=1$と仮定)ならorder = c(0,1,0)となる。アプローチ2, 3, 4(DF検定で切り替え)を試す。
C. nlme::gls()でFGLS推定 ついでにnlme::gls()でFGLS推定を試してみる。計量経済学の教科書に載っているのは、最尤推定じゃなくてこっちのほうですね。
アプローチ2($|\rho|<1$と仮定)のRコードはこんな感じ。
library(nlme)
oModel <- gls(
y_centered ~ 0 + x_centered,
corr = corARMA(p=1, q=0),
data = dfIn
)
アプローチ2のみ試す。
D. 状態空間モデルとして定式化し、RのKFASパッケージを使ってカルマンフィルタで推定。おさらいすると、アプローチ2,5のモデルは
$y_t = \beta x_t + v_t$
$v_t = \rho v_{t-1} + e_t, \ \ e_t \sim N(0, \sigma_e^2)$
である。これを状態空間表現に書き換えよう。状態変数は$\beta$と$v_t$だと考え、縦に積んで$\alpha_t = [\beta, \ v_t]'$としよう。
観察方程式は
$Y_t = Z \alpha_t$
ただし $Z = [x_t, 1]$である。撹乱項がないことに注意。状態方程式は
$\alpha_t = T \alpha_{t-1} + R \eta, \ \ \eta \sim MVN(0, Q)$
遷移行列$T$は2x2の対角行列で、対角要素は$1, \rho$である。$R$は2x2の単位行列で、状態撹乱項は$\eta = [0, e_t]'$とする。共分散行列$Q$は2x2で、右下に$\sigma_e^2$がはいり、残りが0。
こいつをカルマンフィルタで推定する。Rコードはこんな感じ。遷移行列$T$に未知パラメータが入っているので、ちょっと面倒くさい。
library(KFAS)
mgZ <- array(dim = c(1, 2, nrow(dfIn)))
mgZ[1,1,] <- as.vector(dfIn$x_centered)
mgZ[1,2,] <- 1
oModel <- SSModel(
dfIn$y_centered ~ -1 + SSMcustom(
Z = mgZ,
T = matrix(c(1, 0, 0, 1), nrow = 2), # 最後の要素がrho
R = matrix(c(1, 0, 0, 1), nrow = 2),
Q = matrix(c(0, 0, 0, 1), nrow = 2), # 最後の要素がsigma_e
P1 = matrix(c(0,0,0,0), nrow = 2),
P1inf = matrix(c(1,0,0,1), nrow = 2)
),
H = matrix(0)
)
sub_update <- function(par, model){
# par: (sigma_eの対数, rho)
# model: 現在のモデル
model$T[2,2,1] <- par[2]
model$Q[2,2,1] <- exp(par[1])
return(model)
}
oFitted <- fitSSM(
oModel,
inits = c(log(var(dfIn$x_centered)/2), 0.5) ,
updatefn = sub_update,
lower = c(-10, -2),
upper = c(+10, +2),
method = "L-BFGS-B"
)
oEstimated <- KFS(oFitted$model)
計算の都合上$|\rho| < 2$と制約しているものの、このモデルは$|\rho| = 1$という仮定を置かないモデル、つまりアプローチ5ということになると思うのですが... 正しいでしょうか?
E. Mplusでベイズ推定。ここまではRなどという古くさい言語を使っておりましたが、いけてる分析者なら、ここは当然 Mplus ですよね! (すいません冗談です)
構造方程式モデリングの世界ではもはや標準となっているソフトウェア Mplus だが、実はN=1の時系列分析についても便利な機能を持っているのである。
Mplusのコードはこんな感じ。
DATA:
FILE = est2.dat;
VARIABLE:
NAMES = y x;
MISSING=.;
ANALYSIS:
ESTIMATOR = BAYES;
BITERATIONS = (2000);
MODEL:
v by (&1);
v;
v on v&1;
y on v@1 x;
[y@0];
y@0;
MODELコマンドがわかりにくいが、1行目は「vは潜在変数ですが指標を持っていません。モデルのなかでラグ1を使わせて下さい」。2行目は「その残差分散(つまり$\sigma_e$)を自由推定したいです」。3行目で$v_t$の自己回帰を定義し(v&1とは$v_{t-1}$を表す)、4行目で$y_t$のモデルを定義している($v_t$の回帰係数は1に固定している)。ほっとくと$y_t$の切片と残差分散を推定してしまうので、最後の2行でそれを抑止している。
このとき$v_t$の自己回帰係数($\rho$)は範囲が制約されていない、つまりアプローチ5だ、というのが私の理解なのだが、正しいだろうか...?
F. Stanでベイズ推定。ほんとはここまでやるつもりはなかったんだけど、毒も食らわば皿まで、ということで... Stanファイルはこんな感じ。
data {
int T;
vector[T] y;
vector[T] x;
}
parameters {
real beta;
real<lower=-1, upper =1> rho;
real<lower=0> sigma;
}
model {
vector[T] v;
v = y - beta * x;
v[1] ~ normal(0, sigma/sqrt(1-rho^2));
v[2:T] ~ normal(rho * v[1:(T-1)], sigma);
} 下から3行目、v[1]でなにか変なことを書いているが、これは$v_{t-1}$が未知であるときの$v_t$の周辺分布の分散が、$v_{t-1}$の下での$v_t$の条件つき分布の分散 $\sigma_e$より大きくなるからである。
どのくらい大きくなるかというと、
$v_t = \rho v_{t-1} + e_t$
の両辺の分散をとって
$Var(v_t) = Var(\rho v_{t-1} + e_t)$
$e_t$と$v_{t-1}$との共分散は0なので、
$Var(v_t) = \rho^2 Var(v_t) + \sigma_e^2$
ここから
$Var(v_t) = \sigma_e^2 / (1-\rho^2)$
である。
というわけで、尤度計算に当たってデータ点ひとつも無駄にしまいという質実剛健な精神に則り、v[1]についても誠意を込めて分布を書いてみたんだけど、でもこれって、$1-\rho^2 \neq 0$、つまり$|\rho| \neq 1$という仮定を暗黙のうちに含んでいないだろうか? そんならいっそ、というわけで、parametersブロックではreal <lower=-1, upper =1> rho; と書いた次第である。
このモデルとともに、parametersブロックでrhoの範囲制約をなくし、かつ下から3行目を消したモデルも推定してみた。前者はアプローチ2, 後者はアプローチ5に相当すると思うんだけど... うーーん、こういう理解で正しいのだろうか? からきし自信がない。
まとめると、出場選手は以下の10名である。
- A1: OLS推定, $\rho = 0$と仮定
- A3: OLS推定, $\rho = 1$と仮定
- B2: 最尤推定, $|\rho| < 1$と仮定
- B3: 最尤推定, $\rho = 1$と仮定
- B4: 最尤推定, 単位根検定に基づきモデル選択
- C2: FGLS推定, $|\rho| < 1$と仮定
- D5: カルマンフィルタ
- E5: ベイズ推定(Mplus)
- F2: ベイズ推定(Stan), $|\rho| < 1$と仮定
- F5: ベイズ推定(Stan)
推定の様子
この10人の選手に、11水準の$\rho$の各1000個のデータセットについて、$\beta$を推定させた。ただしStanは時間がかかるので、1000個のうち100個だけについて推定するだけで勘弁してやった。
いったいなにをやっているのか、自分でもよくわかんなくなってきたので、選手B2(最尤推定, $|\rho| < 1$と仮定)による推定結果を図にしてみた。
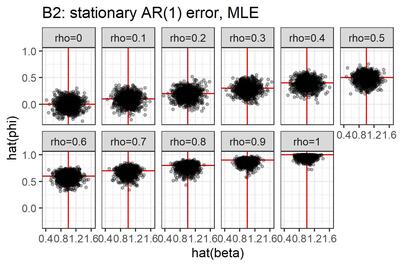
点はデータセット、横軸は$\beta$の推定値, 縦軸は$\rho$の推定値である。真値が赤で表現してある。こうしてみると、真の$\rho$が1に近づくにつれ、$\rho$の推定値は0に向かって歪むみたいですね。横軸と縦軸の間にはあまり相関がなさそうだ。
さて、関心があるのは、$\beta$の真値すなわち 1 と、$\beta$の推定値$\hat{\beta}$とのずれである。その大きさを次の2つの指標で評価しよう。
- バイアス。$\hat{\beta}$の平均から1を引いた値。0に近くないと困る。
- RMSE、すなわち$(\hat{\beta}-1)^2$の平均の平方根。0に近いほうがありがたい。
結果
大変ながらくお待たせいたしました!お待たせしすぎたかもしれません! (ちょっと懐かしい冗談だ)
結果発表です!
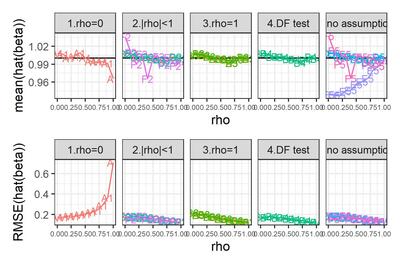
選手F2, F5のみ試行回数が100である点に注意。
シンプルなチャートだが、なかなか情報量が多いので、順にみていこう。
まずは、$\rho = 0$と勝手に想定し、OLS回帰をやってしまった場合。
真の$\rho$がそれほど大きくなければバイアスはそれほど大きくない。しかしRMSEは$\rho$とともに増大する。$\rho$が1に近づくと、バイアス・RMSEともに急増する。なるほど、撹乱項が非定常に近づいているわけだから、パラメータがうまく推定できないのも道理である。
やっぱりあれですね、時系列を分析する際には、きちんと自己相関を考慮することが大事ですね。
次に、$|\rho|<1$と決め打ちした場合(図のパネル2)と、$\rho=1$と決め打ちした場合(パネル3)について。バイアスはそれほど大きくないようだ。RMSEのみ拡大して示す。なお、選手F2はあとで観察することにして、ここでは省略する。
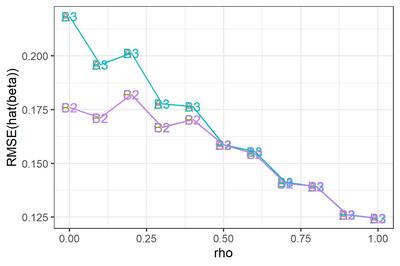
選手B2とC2, 選手B3とA3はぴったり重なってしまっている。つまり、$|\rho|<1$と決め打ちする場合、最尤推定するかFGLS推定するかにはたいしたちがいがないわけだ。$\rho=1$と決め打ちする場合に差分をとって最尤推定するかOLS推定するかも... そりゃそうか、きっと推定値は同じだ。
$\rho$が小さいとき、$\rho=1$と決め打ちするとRMSEが大きくなる。誤ったモデルを指定したわけだから、これは当然である。
これをみて大変に意外だった点がふたつある。
第1に、$\rho$が大きくなるにつれ、つまり撹乱項の自己相関が大きくなるにつれ、$\beta$のRMSEが小さくなっているという点である。$e_t$の分散が同じなら$\rho$が大きいほど撹乱項$v_t$の分散は大きくなるんだから、直感的には、$\beta$の推定はより難しくなるんじゃないかと思ったんだけど... なぜだろう???
もうひとつ、ふへええと言葉にならないため息をついたのは、$\rho$が1に近づくほど、$|\rho|<1$と仮定して定常AR(1)撹乱項を持つ回帰モデルを推定しても、$\rho=1$と仮定して差分時系列について回帰モデルを推定しても、違いがなくなってしまう点である。さきにみたように、単位根検定がしくじりやすいのは$\rho$が1に近いときである。そういうときほど、実は間違えたところでたいした実害はないわけだ。
このように、単位根検定でモデルを切り替えようが、頭から$|\rho|<1$と信じこんで定常AR(1)撹乱項を持つ回帰モデルを使い続けようが、ほとんどちがいがないようだ。たとえ$\rho=1$だったとしても、である。
ええええ? わざわざ単位根検定をやったのに、意味なかったわけ...?
最後に、$\rho$の範囲について制約しないモデル。
元の図にもどると、選手E5がとんでもないバイアスを持っていることがわかる。どうしたんだMplus! しっかりしろ! 医者だ、医者を呼べ!!
... 冗談はともかく、ひょっとすると私がコードを間違えているのかもしれない。残念ながらMplusくんは休場とし、他の選手についてRMSEを拡大してみよう。
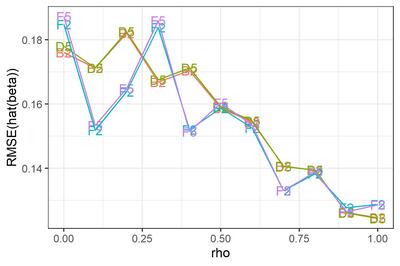
選手D5 (カルマンフィルタ) について。参考のために選手B2 (最尤推定) と並べてみた。ほとんど変わらない。
恥かしながらわたくし、撹乱項の定常性を仮定しているB2は$\rho=1$に近づくとだめになるが、定常性を仮定していないD5はうまくいく... という結果になるかな、と思っておりました。不明を恥じる次第であります。へええ、そうなのかー。
選手F5(Stanでベイズ推定)について。D5との優劣ははっきりしない。参考のためにF2 ($|\rho|<1$と仮定してStanでベイズ推定)と並べてみたところ、$\rho$が小さいところではF2が僅差で勝つが(そりゃそうだ、F2は正しい制約を追加しているわけだから)、$\rho$が1に近づくと僅差で負けるようだ。
まとめ
というわけで、シミュレーションの結果わかったことをまとめておくと、
- Q1. 時系列回帰モデル$Y_t = \alpha + \beta X_t + V_t$において、撹乱項$V_t$が高い自己相関を持つとき、$\beta$の推定誤差は大きくなるか、それとも小さくなるか。→小さくなる。
- Q2. $V_t$の自己回帰係数が1であるのにそれと知らず、1未満と仮定するモデルを推定したとき、$\beta$の推定誤差は大きくなるか。→ならない。
ううむ。どちらも意外な結果であった。勉強が足りないようだ。
それにしても、単位根検定の意味ってなんだろう? 時系列分析の教科書には必ず書いてあるけど、やっても意味なくない? ... と思ってしまったのだが、これは私が「時系列回帰で回帰係数を推定する」という場面だけに焦点を絞っているからで、たとえば予測に関心があるなら話はちがうのかもしれない。
それに、ここでは説明変数時系列が定常であると知っている場合について考えているが、もしそうでなかったら、そりゃあまあ単位根があるかどうか知りたいですわね、みせかけの回帰が怖いから。そういう意味でも、単位根の有無を調べることは、やはり大事なのでありましょう。
なお、この記事のために書いたコードはすべてGithubにアップしております。自己満足もいいところだがな!
2020/03/16追記: 先週書いたこの記事を見直して、はっと気が付いたので記録しておく。
お題は次の通りである。
$y_t = \beta x_t + v_t$
$v_t = \rho v_{t-1} + e_t, \ \ e_t \sim N(0, \sigma_e^2)$
というAR(1)誤差回帰モデルで、$\rho$が大きくなるほど$\hat{\beta}$のRMSEが小さくなるのはなぜか?
2本目の式をラグ演算子$L$を使って書き直すと
$v_t = \rho L v_t + e_t$
$(1-\rho)L v_t = e_t$
ラグ多項式$(1-\rho)L$を$R(L)$とし、
$R(L) v_t = e_t$
と書くことにする。$|\rho| < 1$なら$R^{-1}(L)$が定義できて
$v_t = R^{-1}(L) e_t$
1本目の式に代入して
$y_t = \beta x_t + R^{-1}(L) e_t$
両辺に$R(L)$をかけて
$R(L) y_t = \beta R(L) x_t + e_t$
これは($\rho$を既知とすれば)通常のOLS回帰と同じなので、$x_t^* = R(L) x_t$と略記して
$\displaystyle Var(\hat{\beta}) = \frac{\sigma^2_e}{\sum(x_t^* - \bar{x}^*)^2} $
である。つまり、AR(1)誤差回帰モデルの回帰係数の標準誤差は、ふつうの単回帰のように「撹乱項の分散と独立変数の偏差平方和の比」なのでなく、「AR(1)誤差の裏にあるホワイトノイズの分散と、$x_t - \rho x_{t-1}$の偏差平方和の比」なのである。だから、自己回帰係数が大きいほど分母は大きくなり、$\hat{\beta}$のSEは小さくなるわけだ。うっわー。
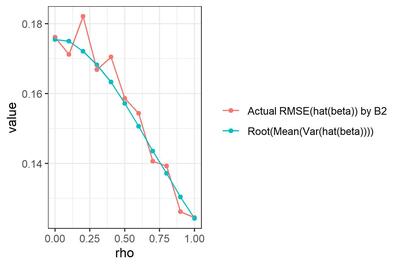
オレンジ色は、選手B2による$\hat{\beta}$の、真値($\beta=1$)に対するRMSE (再掲)。青色は、各試行について真の$\rho$を既知として$Var(\hat{\beta})$を求め、試行を通じて平均して平方根をとった値。
な・る・ほ・ど...
時系列回帰の撹乱項が自己回帰していると、いったいなにがどうなるのか(追記あり)
2020年2月29日 (土)
Rをつかっているとformulaを書かないといけないことがあるけど(回帰系の関数を呼ぶときとかに)、なんか便利な書き方がありそうなのに全然使っていない。このたび、ふとstats::formula()のドキュメントを眺めていたら、恥ずかしながら「へぇー」と思うことがいくつかあった。
この話題、Rを使っている人にとってはたぶん馴染み深い話で、webをちょっと検索するだけで、丁寧に解説しておられるブログ記事をいくつもみつけることができる(たとえばこちら:[R] 予測モデルを作るには formula を活用せよ)。そういうのをきちんと読んできちんと理解しておけばいいんですけどね。そのときは「へぇー」と思うんだけど、すぐに忘れちゃうのである。
というわけで、今日は忘れないようにメモしておこう。なぜか執事風の丁寧語で。お嬢様、羊肉のソテーでございます、って感じで。
- 「
y ~ model」: 反応yをmodelで指定した予測子でモデル化いたします。 - 「
a + b」:aとbの線形和でございます。 - 「
a : b」:aとbの交互作用でございます。 - 「
a * b」:aとbのクロス、すなわちa+b+a:bでございます。 - 「
(a + b + c)^2」:(a + b + c)の二次のクロス、すなわちa,b,cの主効果と二次交互作用でございます [これ知らなかった... 文字通り展開するとa*a, b*b, c*cが生まれるけど、それらは算術的な意味での$a^2, b^2, c^2$ではなくて、単にa, b, cの主効果ってことになるのね。へー] - 「
a + b %in% a」:bはaにネストしております。すなわちa + a:bでございます。[ここちょっと不思議なところで...%in%は常に:と等価なのかしらん?] 「(a + b + c)^2 - a:b」:(a + b + c)^2からa:bを取り除いたもの、すなわちa + b + c + b:c + a:cでございます。- 「
y ~ x - 1」: 切片項を取り除いております。y ~ x + 0,y ~ 0 + xでもよろしゅうございます [←Rを使い始めたときから、formulaの右辺で0と1が等価だってのが気持ち悪くてしかたない。責任者でてこい] 「log(y) ~ a + log(x)」: このように、算術表現もお使いになれます [←私、formulaのなかでこういう変数変換を掛けるのが生理的に許せなくて、必ず自力で前処理している。なぜ気持ち悪いのかいま気が付いた。formulaのなかの演算子は算術演算子ではないのに(たとえば+は和ではないのに)、関数は算術表現として扱われるというのが気持ち悪いんだ...]- 「
a + I(b+c)」: aとb+cの線形和でございます。I()のなかの演算子は算術演算子として扱われるのでございます。 - 「
.」: 「そのformulaのなかにないすべての列」を表します [←formulaをupdateするときはちがう意味になるのだが、まあupdateなんて使わないからいいや] - 「
a + b + offset(z)」: aとbの線形和とzとの和でございます。zの係数は1となります。なお、この表現は受け付けない関数もございます。
ところで、lm(y ~ a/b)なんていう書き方をみたことがあるけど(y ~ a + a:bと等価だと思う)、stats::formula()のドキュメントにも、stats::lm()のドキュメントにも載ってなかった。あれえ?
2020年2月14日 (金)
時系列データを扱っていると、たまーに単位根検定をやりたくなることがあるんだけど、Rのパッケージがいろいろあって困る。
仕方がないので、目についたやつについてメモを取った。なんというか、恥をさらしているような気がしますが...
tseriesパッケージ
時系列分析パッケージの古手だと思う。ADF検定, KPSS検定, PP検定の関数を持っている。
adf.test(x, alternative, k): H0「xは単位根を持つ」のADF検定。モデルは定数と線形トレンドを含む。引数は:
- x: 時系列
- alternative: 対立仮説の指定。値は"stationary", "explosive"。後者はnonstatonaryってこと?
- k: ラグ次数。デフォルトではtrunc((length(x)-1)^(1/3))となるそうだ。k=0とするとDickey-Fuller検定になる。
えーっと、いっつも混乱するんだけど、ここで「モデルは定数と線形トレンドを含む」っていうのはどういうことなの?
話を単純にするためにラグ次数を1として、ここで「定数と線形トレンドを含む」といっているのは、差分時系列について
$\Delta y_t = \beta_1 + \beta_2 t + (\phi-1) y_{t-1} + e_t$
というドリフト+トレンドつきモデルを考えて$H_0: \phi = 1$の検定をいたします、ってこと? それとも、元の時系列に切片と1次の項をいれて
$y_t = \mu + \beta_1 t + \phi y_{t-1} + e_t$
$\Delta y_t = \beta_1 + (\phi-1) y_{t-1} + e_t$
つまり差分時系列はドリフトつきモデルです、ってことなの? うぐぐぐぐ。
[02/16 追記: コードをざっと眺めたところ、どうやら前者、つまり$\Delta y_t$のモデルに定数項と1次の項がはいるという話らしい... しらんけど]
kpss.test(x, null, lshort): H0「xはレベル定常ないしトレンド定常である」のKPSS検定。引数は
- x: 単変量時系列
- null: H0はレベル定常かトレンド定常か。値は"Level", "Trend". しっかし、すごい引数名でびびるわ... nullになにかを代入する日が来るとは...
- lshort: 値は論理値。TRUEのとき、truncation lagパラメータが trunc(4+(n/100)^0.25), FALSEのとき trunc(12+(n/100)^0.25) となるのだそうだ。なんだかよくわからん、KPSS検定についてちゃんと勉強しなきゃ。
pp.test(x, alternative, lshort): H0「xは単位根を持つ」のPP検定。定数項と線形トレンドを含む。引数は
- x: 単変量時系列
- alternative: 対立仮説の指定。adf.test()と同じ。
- type: 検定のタイプ。値は"Z(alpha)", "Z(t_alpha)". ううむ、PP検定について不勉強で、なにいってんだかさっぱりわからん。
- lshort: kpss.test()と同じ。
urcaパッケージ.
単位根検定のためのパッケージとして最も有名なのはこれだと思う。
ur.df(y, type, lags, selectlags): ADF検定。引数は
- y: 時系列。
- type: "none"だと切片もトレンドもなし, "drift"だと切片をいれる、"trend"だと切片とトレンドをいれる。これは差分時系列のモデルのことをいってんですよね。
- lags: ラグ次数.
- selectlags. "Fixed"だとなにもしない。"AIC", "BIC"だとlagsに指定した以下の次数をAICなりBICなりで勝手に選んでくれる。
ur.ers(y, type, model, lag.max): Ellot, Rothenberg, & Stock の単位根検定だそうだ。なにそれってかんじだけど、どうやらADF-GLS検定のことらしい。ADF検定より検定力が高いって前に読んだことがあるぞ、理屈はさっぱり理解できなかったけど。引数は
- y: 時系列.
- type: 値は"DF-GLS", "P-test". 後者は誤差項の系列相関を考慮するのだそうだ。へー。
- mode: 値は"constant", "trend". これって元の時系列の話?それとも差分時系列の話?
- lag.max: よくわからんけど、ラグ次数の最大値だそうな。
ur.kpss(y, type, lags, use.lag): KPSS検定. 引数は
- y: 時系列.
- type: 値は"mu", "tau". 前者は切片のみ、後者は切片と線形トレンド。
- lags: 値は"short", "long", "nil"。"short"にするとラグ次数はほにゃらら(メモ省略)、"long"にするとラグ次数はほにゃらら、"nil"にする誤差項の指定なし。
- use.lag: lagsを使わずに、ここで最大ラグ次数を指定してもよい。
ur.pp(x, type, model, lags, use.lag): PP検定。引数は
- x: 時系列.
- type: 値は"Z-alpha", "Z-tau". なんだかわからん。
- model: 値は"constant", "trend".
- lags: 値は"short", "long". マニュアルに説明が書いてない...
- use.lag: lagsを使わずにここで次数を指定してもよい。
ur.sp(y, type, pol.deg, signif): Schmidt & Phillips単位根検定。黒住(2008)ではADF検定ではない「その他の検定」というところで名前だけ出てくる。いわく、ADF検定ってのはWaldタイプの検定なんだけど(なるほど、最尤推定量の差の検定なわけね)、これはラグランジュ乗数検定なんだってさ。そういわれても困るけどな!
引数は
- y: 時系列
- type: 値は"tau", "rho". そういう種類があるんだってさ。しらんがな。
- pol.deg: 多項式の次数だそうだ。値は1,2,3,4。
- signif: 有意水準。値は0.01, 0.05, 0.1.
- y: 時系列
- model: 値は"intercept", "trend", "both". potential breakが切片で起きるか、線形トレンドで起きるか、両方で起きるか。
- lag: ラグ次数の最大値。指定しなくてもいいらしい(えっ、どういうこと?)
forecastパッケージ
泣く子も黙る(?) 有名パッケージ。中の人Hyndman先生は、ただいまこのパッケージのtidyverse対応版であるfableパッケージを鋭意ご製作中らしいのだが、単位根検定関係はまだ移植していない模様。
ndiffs(x, alpha, test, type, max.d, ...): 超お手軽な単位根検定の関数。実はこれ、昨年社外で時系列解析のセミナーやった時にはじめて存在を知り、あまりの簡単さにがっくり膝をついた次第である。だってあれですよ、検定統計量とか一切無視で、単に「何階差分をとるべし」という整数値だけをぽろっと返してくるんですよ。それって、カツカレーくださいって言ったらカツカレーが出てきたようなものじゃないですか...(ちょっとちがうか)
引数は
- x: 時系列
- alpha: 有意水準. 0.01から0.1までの値。
- test: 値は"kpss", "adf", "pp"。
- type: 値は"level", "trend". 恥ずかしながら、これがよく理解できてないんですが... 差分時系列に切片だけはいるか(つまりドリフトつきモデルか)、$t$の1次項もはいるか(つまりトレンドつきモデルか)、ということでしょうか。ってつぶやいてないで、今度ちゃんと調べよう。
- max.d: ラグ次数の最大値。AICかなんかで自動選択してるんだろうなあ。これも今度調べてみよう。
- ...: 単位根検定に渡す引数。たぶんurcaパッケージに渡るんだと思う。
[02/16 追記: 上記の想像通りで、ndiffs()のコードをざっと眺めたところ、ur.df(), ur.kpss(), ur.pp()のいずれかをコールしている模様。次のような対応になっているようだ:
ndiffs(x, test="adf",type="level") → ur.df(x, type="drift")をコール
ndiffs(x, test="adf",type="trend") → ur.df(x, type="trend")をコール
ndiffs(x, test="kpss", type="level") → ur.kpss(x, type = "mu")をコール
ndiffs(x, test="kpss", type="trend") → ur.kpss(x, type="tau")をコール
ndiffs(x, test="pp", type="level") → ur.pp(x, type="Z-tau", model="constant")をコール
ndiffs(x, test="pp", type="trend")→ ur.pp(x, type="Z-tau", model="trend")をコール]
nsdiffs(x, alpha, test, max.D, ...): ndiffs()のSARIMA版、つまり、季節について何階差分をとるべきかを返す。testの値は"seas", "ch", "hegy", "oscb"。おっと、hegyってのがある... uroot::hegy()と同じことなのかなあ...
そのほかのパッケージ
uroot::hegy(x, ...): Hylleberg, Engle, Granger & Yoo の季節単位根検定、だそうだ。勉強不足であれですけど、要するにモデルに季節ダミーが入りますってこと? それとも、SARIMA(p,d,q,P,D,Q)モデルを当てはめるときにDをどうするかってこと? いやまてよ、それって実は同じことなの? うーん、よくわからん。引数はいっぱいあるので省略する。
CADFtest::CADFtest(model, x, type, data, max.lag, min.lag.y, min.lag.X, max.lag.X, dname, criterion, ...): Covariate ADF単位根検定、だそうだ。どうやら、共変量をいれたADF検定らしい。へええ!そんなのあるんだ! ってことはあれですか、時系列変数間で回帰するとき、yが単位根を持っていてもこの検定に通るなら差分取らなくていいよってことっすか? それ助かるわー... J.Stat.Softwareに論文が出てるらしい、今度読んでみよう。
MultipleBubbles::ADF_FL(y, adflag, mflag): ラグ次数を固定したADF検定。adflagがラグ次数、mflagは1のとき切片のみ、2のとき切片とトレンド、3のとき両方なし。これ、関数のヘルプを見る限りふつうのADF検定なんだけど、このパッケージは「バブルの存在をチェックするためのADF検定」のパッケージなので、きっとなんか特別なことをやっているんだろうなあ。
MultipleBubbles::ADF_IC(y, adflag, mflag, IC): 上と同じだが、mflagは最大ラグ次数となり、IC=1とするとAIC, 2とするとBICで次数選択するらしい。
fUnitRootsパッケージ: チューリッヒのThe Rmetrics Accoc.というところが本やRパッケージをたくさん出していて、これもそのひとつ。ADF検定の関数を自前で持っている(unitrootTest(), adfTest())。ほかにurcaパッケージへのラッパーもある。
FinTS::Unitroot(x, trend, medhod, lags): これはTsay(2005)という本のコンパニオン・パッケージ。この関数はfUnitRootsパッケージへのラッパーだそうだ。
aTSAパッケージ: SASとよく似た出力を返す時系列分析パッケージなのだそうだ(ははは)。adf.test(), pp.test(), kpss.test()を持っている。
Rの時系列分析パッケージとしては、ほかにTSAという強力なやつがあるんだけど、単位根検定の関数は持っていないようだ。
2019年11月15日 (金)
用事があって、日帰りで長野の軽井沢というところに行った。有名な避暑地だが、これまでご縁がなく、記憶の限りでは初めての訪問である。
思ったより早く帰れることになったのだが、夕方の軽井沢駅は池袋駅並みにごった返しており、切符の都合で1時間半ほど時間を潰さなければならなくなった。駅の北側に少し歩いて、運よく喫茶店に空席をみつけた。
本でも読もうと思ったんだけど、ウェイターのお兄さんがコーヒーと一緒になにかをテーブルに置き、「時間つぶしにでもどうぞ...」という。それは木製の小さなパズルであった。ボードの上にイラストが描かれた小さなコマがいくつかあり、使い込まれてかすかに茶色い光沢を帯びている。コマを上下左右にずらし、目指す模様をつくるパズルだ。子供の頃にやったことがある。
「ははは」と愛想笑いしたけれど、そんなに暇そうに見えたかなあ、とちょっと気になった。もっともこれは私の気の回しすぎで、他のテーブルのお客さんにも渡していたようである。隣のテーブルの母娘連れも、親戚の悪口などを云いながらひとしきりこのパズルで遊んでいた。
鞄から本を取り出したが、こんな子供だましのパズルも懐かしいものだ、などと思い、頬杖をつき、戯れに指でコマを適当に滑らせてみた。完成したら本でも読もうか、と。
... それから1時間半。読書どころか、ぶっつづけでこのパズルに取り組む羽目になった。
解けない!解けないよ!
このパズル、めちゃくちゃ難しいじゃん!!
時間切れでお店を出るときにはイライラが極限に達しており、レジの横に並べられたこのパズルをひっつかんで買ってしまった。1300円、思わぬ出費である。店主らしき方が笑っていた。
帰りの新幹線でもこのパズルがぐるぐると頭をめぐって離れなかったのだが(「あの4つのリンゴを隣り合わせにして...」云々)、いやまてよ、と我に返った。レジ前の陳列には「日本一難しいパズル」と謳われていた。このパズル、たぶんほんとに難しい奴なのだ。いっぽう、私はあんまし頭の良いほうじゃない。パズルなんて大の苦手だ。なにも私が頑張って解くことはないんじゃないか。
むしろ、パズルを解くプログラムを書いたほうが早いんじゃないか?
問題
買ってきたパズルはこちら。
 コマをボードの外に出さずに移動させ、左上のこびとを右下の角に3つの柵でとじこめる、というのがゴールである。
コマをボードの外に出さずに移動させ、左上のこびとを右下の角に3つの柵でとじこめる、というのがゴールである。パズルももちろん著作物であり、勝手にブログに載せてはいけないと思ったのだが、検索してみたところ、喫茶店の方が画像を公開しておられることに気が付いた。これって、喫茶店の店主の方のオリジナル作品なのかしらん? すごいなあ。
お店の名前は「喫茶館丹念亭」。とてもよい雰囲気のお店で、コーヒーもシナモンケーキも美味しかった。いつかまた軽井沢に行く機会があったら立ち寄りたいと思います。
うちに帰ってビールを飲みながら再び試してみて、このパズルにはまった理由がなんとなくわかってきたような気がした。
このパズル、なんとなくコマをすべらせていると、なんとなく盤面が変化する。思いもよらぬ形で大きなコマが動いたときなど、ちょっとした快感がある。しかしよくみると、全く展望が開けていない。同じような局面をぐるぐると回っているだけで、そこから全く脱出できないのである。まるで迷路にはまり込んでしまったような気分だ。
よくわからんが、こういうパズルを考案するのってきっとすごい才能と努力の結晶なのであろうと思う。ほんとに尊敬します。
プログラムで解くにあたっての方針は次の通り。
- Rで書く。この課題にRが向いているからではなくて、単に私がRに慣れているからである。
- このパズルに限らず、このタイプのパズルすべてに適用できるプログラムにする。Wikipediaによれば、こういうパズルのことをスライディング・ブロック・パズル、ないしスライド・パズルと呼ぶらしい。知らなかった。
- 初期状態(つまり、最初のコマの配置)から出発し、そこからコマを動かして到達し得る状態を、力づくですべて探索する。なぜなら、どういう評価関数を書いたらいいのか、私にはよくわからんからである。
- 得られたすべての状態からなるネットワーク・グラフを生成する。パズルの解を求めるコードは書かない。だって、グラフが手に入っていれば、ネットワーク分析のソフトを使えば最短経路を探索できるじゃん?
- 朝までに書き終える。
我ながら頭の悪さがにじみ出る方針である。特に最後の奴がそうだ。結局、翌朝までには書けませんでした。
上で状態のネットワーク・グラフと書いたが、これはこういう意図である。
このパズルについていえば、最初にできるのは右上の柵を上に動かすことだけである。2手目にできることは2つある。右端列の下から2番目のリンゴを上に動かす、ないし、右から2つめのリンゴ2個のピースを上に動かしていくことである。3手目にできることは...
... と考えていくと、どんどん枝分かれしていくが、単純に増えていくだけではない。元の状態に戻ったり、別の手順でたどり着いた状態に一致したりすることもありうる。
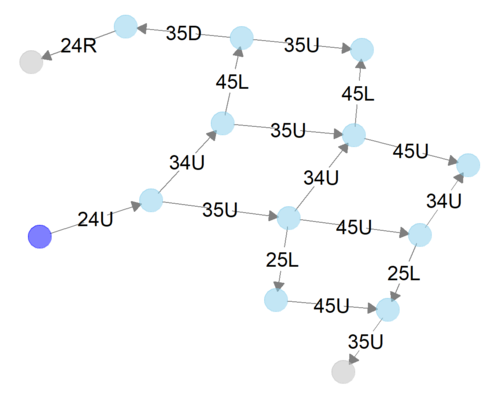
上図は5手までの状態を表現するネットワーク・グラフである。紫色のノード(円)は初期状態を表している。24Uとは「行2, 列4にあるコマを上に動かす」こと、つまり右上の柵を上に動かすことを意味している。
このように、5手までで14個の状態に到達できるわけだ。到達できる状態の数はどんどん増えていく。これをずーっと続けていけばさ!いつかはゴールに辿りつくよね!
後述するが、こういう過度に楽観的な態度、問題の難しさを最初に客観的に推し量ることを怠る姿勢が、人生の悲劇を招くのである。
これがパズルの解答だ
初期状態から到達し得る状態をすべて調べてみた。ただし、目標条件を満たす状態に辿り着いたら、そこからさらに探索するのはなし、ということにした。つまり、何も考えずにピースを動かしてはいるものの、ゴールに辿り着いたことに気がつかないほどアホではないプレイヤーが、いったいどのような盤面に辿り着きうるか、網羅的に調べたわけである。
軽井沢で買ったパズルの場合、手元のパソコンで約8時間で探索が終了した。8時間。映画を4本見られる時間、本を数冊読める時間、精力絶倫な王様なら子供をたくさん作れる時間だ。
すべての状態のネットワーク・グラフを描いてみた。それではご覧ください。軽井沢駅北口の喫茶店の店内でパズルのコマを動かしているみなさん! あなたはいま、この図の中のどこかにいますよ!
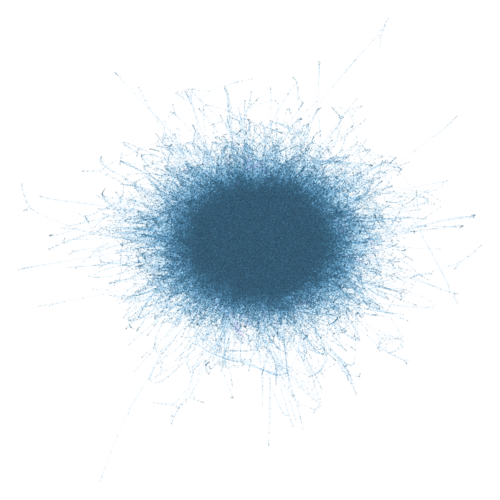
ネットワーク・グラフどころか、なにか模様のようなものしかみえないが、これはカメラをすごく引いているからで、目を凝らせば見えるであろう微小な点が個々の状態を表している。状態の数は977,412個。うち1個は初期状態、14個はゴールの条件を満たす状態である。
これではあまりに見にくいので、初期状態からゴールまでの経路(正確に言うと、14個のゴールそれぞれへの最短経路)の途中に位置する状態、計3,028個だけを抜き出して描いてみると...

青いノードが初期状態、ピンクのノードが経路上の状態、赤いノードがゴール状態である。
青いノードをお探しですか? 図右側のちょっと下寄りにあります。拡大してみましょう。
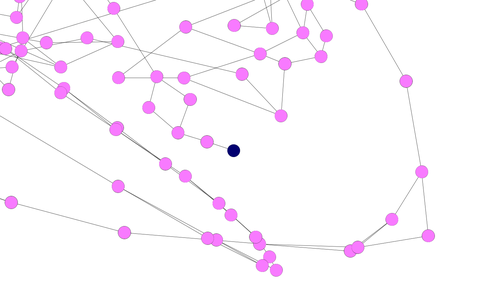
要は、この青いノードから辿って行けば、誰でもゴールにたどり着けるわけだ。
ああよかった、これで自分でパズルを解く必要がなくなった。夜もぐっすり眠れるというものだ。
ついでにいうと... 野暮なのでパズルの解答は書きませんけど、このパズルにおけるゴールへの最短経路は217手である。
買ってきたパズルには親切にも模範解答を図示した紙が添付されているのだが、その手数は254手(181手と記載されているが、ここではひとつのコマの1マスの移動を1手と数える)。おかげさまで、模範解答よりもすこし手数の少ない解答を見つけたことになる。ほんの少しだけ達成感があるが、いやいやそれよか、パズルを考案する人のほうがずっとすごいですよね。
だからどうした
だからどうしたんだこの暇人め、といわれると困ってしまうのだが、今回は自分なりにいろいろ学ぶところ大きかった。
帰りの新幹線のなかでぼんやり思ったのは、どうせ盤面の状態は限られているだろう、ということであった。盤面の大きさは4x5マス、コマの数は10個。喫茶店内でコマをあれこれ動かしているときも、なんだか同じ状態を行きつ戻りつしているような気がしてならなかった。だったら私にも全探索できちゃうんじゃない?と思ったのである。
振り返るとこれは無謀な賭けであった。組み合わせの数の大きさというものは人間の直感を遥かに超える。今回のパズルはたまたま初期状態から到達できる状態の全探索が可能であったし、あとで試算したところでは、そもそもこのパズルで可能な状態の数は1,281,550個しかない。しかし、問題が少し異なるだけで、状態の数は爆発的に増大し、まともな時間では到底全探索できないものとなっていただろう。
なんについてもいえることなんだろうけど、最初に問題の大きさを推し量ることって、すごく大事ですね。どうもそういう姿勢が私には欠けているようだ。反省。
なぜ難しいのか
それにしても不思議なのは、このパズルがなぜこんなに難しいのかという点である。実際に遊んだことがない方に、解のネタバレを避けつつ説明するのはすごく難しいんですが、とにかくほんとに難しいんですってば。イライラするんですってば。
難しい理由のひとつは、もちろん、ゴールまでの手順の多さであろう。しかしそれだけが要因ではないという気がしてならない。なんというか、いくらコマを動かしても、同じような局面をぐるぐると回っているように感じられるのである。
こうした難しさを、ネットワーク・グラフの形状によって定量的に示すことはできないだろうか。
同じような局面からなかなか脱出できないということは、ネットワーク・グラフのあちこちにノードの密な固まりがあって、その固まりから外に出て行くエッジが少ない、ということだろう。とすれば、ネットワーク・グラフ全体を通じてノードが局所的に固まっている程度を測ればよいのではないか。このパズルでは、その値がとても高くなっているのではないか?
思い悩んだ末、次のようなことを試してみた。
あるネットワーク・グラフについて、ノードをいくつかのグループにわけたとする。ネットワーク分析の慣例に従い、これをコミュニティと呼ぶことにする。
ノードの間のエッジは、同一コミュニティ内でつながるエッジと、コミュニティをまたがるエッジとにわかれる。前者のエッジの比率が大きいとき、コミュニティはネットワークのなかの密度の高い固まりをうまく捉えていることになる。
そこで、コミュニティ内のエッジの比率が、「そのグラフのエッジを一旦すべて消し、かわりに同じ数のエッジをランダムに張ったときに得られる、コミュニティ内のエッジの比率」と比べてどれだけ大きいかを調べる。これをモジュラリティという。うーん、下手な説明だが、要するに、モジュラリティが大きいことは、ノードがコミュニティの中で高密度に固まっていることを示しているわけである。
上のアイデアに従い、丹念亭パズルのネットワーク・グラフを徐々にたくさんのコミュニティに分割していき、そのたびにモジュラリティを測ってみよう。
どうやってコミュニティに分割するか。いろんな方法があるんだけど、ここでは手っ取り早く、Clausetたちの手法を使うことにする。これ、計算がすごく速いんです。
比較のために、すごくシンプルなスライドパズルについても同じことを試してみる。盤面は3x3, コマは8つ、サイズはすべて1x1であるパズルを考える。つまり、下図を3x3に縮めたようなパズルです。

このパズルについて、初期状態から辿り着くことができるすべての状態(181,440個)のネットワーク・グラフを作った。で、こちらについてもコミュニティ数を増やしながらモジュラリティを調べた。
結果は下図の通り。
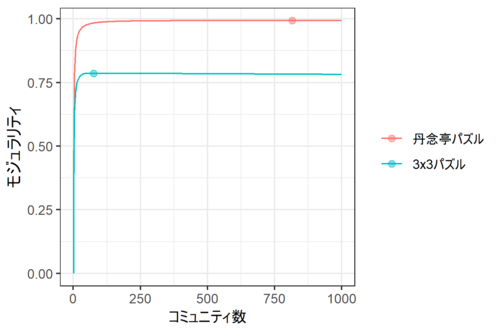
丹念亭のパズルではコミュニティ数816、3x3のパズルではコミュニティ数76のとき、モジュラリティが最大になった。
ここで注目したいのはモジュラリティの違いである。丹念亭パズルのモジュラリティは最大で0.993と、法外に高い。つまり、ネットワーク・グラフの描画からは読み取れないが、あたかも少量の水に溶かした小麦粉のダマのように、ノードが小さくて密度の高い固まりを形成しているのではないかと思う。そのため、やみくもにコマを動かしても、その固まりの外側になかなか出られない... ということではないかしらん?
疑問点
... などと書いてはみたものの、正直なところ、あまり自信がない。
- 3x3パズルは丹念亭のパズルよりも状態数が小さいし(9!=362880通り)、ネットワーク・グラフの作成にあたって目標状態を設定せずに全探索しているので、適切な比較になっているかどうかわからない。
- Clausetたちの手法は凝集的なコミュニティ検出手法なので、所与のコミュニティ数についてモジュラリティ最大のコミュニティを検出していないかもしれない。
- なにより、ここでモジュラリティに注目したのは良いやり方だったのだろうか。ネットワークがクラスタ化している程度を調べる際にはクラスタ係数と呼ばれる指標を使うことが多いと思うんだけど、スライド・パズルの状態のネットワーク・グラフはクリークを持たないので(3手で元に戻ることはできないから)、クラスタ係数は0となる。こういうネットワークについて、それがクラスタ化されている程度を調べるためにはどうしたらいいんだろう?
ううむ... このへんで時間切れということにしておくけど、いろいろ勉強が足りないことがわかった。
rSlidePzlパッケージ
軽井沢駅前の喫茶店でパズルを渡された副産物として、任意のスライド・パズルについて初期状態から到達しうる状態を全探索しネットワーク・グラフを生成するRパッケージ rSlidePzl を作りました。
ああ、私には聞こえる。任意のスライド・パズルについて初期状態から到達しうる状態を全探索しネットワーク・グラフを生成したいと思っている、世界三千万人の善人男女の歓喜の叫びが。(嘘です聞こえません)
パッケージはgithubからインストールできる。
このパッケージを使えば、お手元のスライド・パズル(9x9マス以内)について、初期状態から到達し得る状態をすべて探索し(幅優先探索)、みつかった状態からなるネットワーク・グラフをつくることができる。
せっかくなので、初期状態からゴールへの最短手順を出力する関数もつくっておいた。また、得られたネットワーク・グラフを(それが小さめであれば)簡単に描画できる関数もつくった。
探索すべきすべての状態を探索し尽くす場合、とんでもなく時間がかかることを覚悟する必要がある。これを避けるため、探索する手の深さ(何手目まで探索するか)や、探索する状態の総数について上限を指定し、探索を途中で打ち切ることもできる。
このパッケージを使って得られるネットワーク・グラフは igraph パッケージの igraph クラスのオブジェクトである。igraph パッケージが提供する多様な関数によって、その性質を心ゆくまで調べることができる。
コード例を示す。
### devtoolパッケージをインストール
### install.packages("devtools")### rSlikePzlパッケージをインストール
# devtools::install_github("shigono/rSlidePzl")### rSlikePzlパッケージをロード
library(rSlidePzl)library(tidyverse)
library(igraph)### セッティング
oSetting <- makeSetting(
## 盤面のサイズ (行サイズ, 列サイズ)
boardsize = c(4,5),
## コマのサイズ (行サイズ, 列サイズ)
piecesize = list(
A = c(2, 2), # コマタイプA.こども パズルに添付されている解答ではNo.1
B = c(2, 1), # コマタイプB.りんごとサク No.5
C = c(1, 2), # コマタイプC.横長のサク No.7
D = c(1, 1), # コマタイプD.りんご, No.2,3,9,10
E = c(2, 1), # コマタイプE.縦長のサク, No.6
F = c(2, 1), # コマタイプF.縦長のりんご No.8
G = c(1, 2) # コマタイプG.横長の林檎 No.4
)
)### こどものピースの位置(1,1), (1,2), (2,1), (2,2)について考える
anNumStates <- sapply(
list(c(1,1), c(1,2), c(2,1), c(2,2)),
function(anLoc){
### 可能な状態の数を算出する
getNumStates(
makeState(
list(
makePiece(type = "A", loc = anLoc),
makePiece(type = "B", loc = c(NA,NA)),
makePiece(type = "C", loc = c(NA,NA)),
makePiece(type = "E", loc = c(NA,NA)),
makePiece(type = "F", loc = c(NA,NA)),
makePiece(type = "G", loc = c(NA,NA))
)
),
oSetting
)
}
)
# - こどものピースが位置(1,1)(左上端)であるときの状態数は、
# 左下端(3,1), 右上端(1,4), 右下端(3,4)にあるときの状態数と同じはずなので、4倍する
# - こどものピースが位置(1,2) にあるときの状態数は、
# (1,3), (3,2), (3,3) にあるときの状態数と同じはずなので、4倍する
# - こどものピースが位置(2,1) にあるときの状態数は、
# (2,4) にあるときの状態数と同じはずなので、2倍する
# - こどものピースが位置(2,2) にあるときの状態数は、
# (2,3) にあるときの状態数と同じはずなので、2倍する
# 各状態においてりんごのピースを置く位置は6 x 5 / 2 通りあるから...
print(sum(anNumStates * c(4,4,2,2)) * 6 * 5 / 2) # 状態数は1281550### 開始時点の盤面の作成
oStart <- makeState(
list(
makePiece(type = "A", loc = c(1,1)), # パズルに添付されている解答ではNo.1
makePiece(type = "B", loc = c(1,3)), # No.5
makePiece(type = "C", loc = c(2,4)), # No.4
makePiece(type = "D", loc = c(3,1)), # No.2
makePiece(type = "D", loc = c(3,2)), # No.3
makePiece(type = "E", loc = c(3,3)), # No.6
makePiece(type = "F", loc = c(3,4)), # No.8
makePiece(type = "D", loc = c(3,5)), # No.9
makePiece(type = "G", loc = c(4,1)), # No.4
makePiece(type = "D", loc = c(4,5)) # No.10
)
)
stopifnot(isValidState(oStart, oSetting))### 目標条件の作成
oGoalCondition <- makeState(
list(
makePiece(type = "A", loc = c(3,4)), # No.1
makePiece(type = "B", loc = c(1,3)), # No.5
makePiece(type = "E", loc = c(3,3)), # No.6
makePiece(type = "C", loc = c(2,4)) # No.7
)
)
stopifnot(isValidState(oGoalCondition, oSetting))### 5手だけ検索
oGraph <- makeGraph(oSetting, oStart, oGoalCondition, verbose = 1, max_depth = 5)### 描画
set.seed(123)
plotGraph(oGraph, method = "GGally")### すべての手順を探索。手元のパソコンで8時間くらい
oGraph <- makeGraph(oSetting, oStart, oGoalCondition, verbose = 1)### 目標条件を満たした状態を表示
print(V(oGraph)[V(oGraph)$status == 4])### 目標条件を満たした状態への最短経路を表示
print(getShortestPath(oGraph)$transition)### コミュニティ検出。fast_greedy法でmodularityを最適化する
oGraph_undirected <- as.undirected(oGraph)
oCommunity <- cluster_fast_greedy(oGraph_undirected, modularity = TRUE)### 描画。Rでは大変なのでGephi (https://gephi.org/) で描く。
### グラフに描画のための属性を追加する
### state_color属性: {1(初期状態),2(目標状態),3(目標への途中),4(ほか)}
### Gephiでこの属性をcolorに指定すると、ノードを色分けできる
anColor <- rep(4, length(V(oGraph))) # 4: 下記以外の状態
anColor[getReachability(oGraph) == 1] <- 3 # 3: 目標状態に至るパス上にある状態
anColor[V(oGraph)[V(oGraph)$status == 4]] <- 2 # 2: 目標状態
anColor[1] <- 1 # 1: 初期状態
V(oGraph)$state_color <- anColor### state_size属性: {1(目標への経路上にない),2(ある)}
### Gephiでこの属性をsizeに指定すると、目標への経路上のノードを大きくできる
V(oGraph)$state_size <- c(2,2,2,1)[anColor]
V(oGraph)$state_comm <- membership(oCommunity)### state_x属性, state_y属性: x座標とy座標
### GephiのGeo layoutでこれらの属性を緯度経度に指定すると、レイアウトを再現できる。
### コミュニティ内のエッジに大きな重みを与え、Fruchterman-Reingoldアルゴリズムで
### 最適化している。Gephiでレイアウトを作成してもいいけど、こっちのほうが速い
oLayout <- layout_with_fr(
oGraph,
weights = ifelse(crossing(oCommunity, oGraph), 1, 10),
niter = 1000
)
### 座標が大きな値だとメルカトル図法では歪んでしまうので、-1から+1に基準化する
oLayout <- norm_coords(oLayout)
V(oGraph)$state_x <- oLayout[,1]
V(oGraph)$state_y <- oLayout[,2]### graphml形式で出力。このファイルをGephiで読み込む
write.graph(oGraph, file = paste0("./full_states.graphml"), format = "graphml")### 3x3パズルのセッティング
oSetting <- makeSetting(
boardsize = c(3,3),
piecesize = list(
A = c(1, 1), B = c(1, 1), C = c(1, 1), D = c(1, 1),
E = c(1, 1), F = c(1, 1), G = c(1, 1), H = c(1, 1)
)
)
oStart <- makeState(
list(
makePiece(type = "A", loc = c(1,1)),
makePiece(type = "B", loc = c(1,2)),
makePiece(type = "C", loc = c(1,3)),
makePiece(type = "D", loc = c(2,1)),
makePiece(type = "E", loc = c(2,2)),
makePiece(type = "F", loc = c(2,3)),
makePiece(type = "G", loc = c(3,1)),
makePiece(type = "H", loc = c(3,2))
)
)
stopifnot(isValidState(oStart, oSetting))### 3x3パズルのネットワーク・グラフ作成
oGraph_Nine <- makeGraph(oSetting, oStart)### 上と同じやり方でコミュニティ検出
oCommunity_Nine <- cluster_fast_greedy(as.undirected(oGraph_Nine), modularity = TRUE)### モジュラリティ比較
oGraph_undirected <- as.undirected(oGraph)
anModularity <- sapply(
1:1000,
function(nNum){
modularity(oGraph_undirected, cut_at(oCommunity, no = nNum))
}
)
oGraph_undirected <- as.undirected(oGraph_Nine)
anModularity_Nine <- sapply(
1:1000,
function(nNum){
modularity(oGraph_undirected, cut_at(oCommunity_Nine, no = nNum))
}
)
dfPlot <- data.frame(
nNumComm = 1:1000,
nMod_1 = anModularity,
nMod_2 = anModularity_Nine
) %>%
gather(sVar, gValue, c(nMod_1, nMod_2)) %>%
separate(sVar, c("sVar1", "nVar2")) %>%
group_by(nVar2) %>%
mutate(bMax = if_else(gValue == max(gValue), 1, 0)) %>%
ungroup() %>%
mutate(fGraph = factor(nVar2, levels = c("1", "2"), labels = c("丹念亭パズル", "3x3パズル")))
g <- ggplot(data = dfPlot, aes(x = nNumComm, y = gValue, color = fGraph))
g <- g + geom_line()
g <- g + geom_point(data = dfPlot %>% filter(bMax == 1), size = 2, alpha = 0.5)
g <- g + labs(x = "コミュニティ数", y = "モジュラリティ")
g <- g + scale_color_discrete(name = NULL)
g <- g + theme_bw()
print(g)### 以上
githubを使うのも、Rパッケージを公開するのもはじめてなので、いろいろ不備があるかもしれませんが、そのへんはひとつ、ご愛敬ということで...
軽井沢駅前の喫茶店の店員さんに渡されたパズルを解く (ためのRパッケージを作った)
2019年11月13日 (水)
ここんところこういう覚え書きばかりで、自分でも嫌になっちゃうんだけど...
無向グラフにおいて、ノードiとj, jとkの間にエッジがあるときに、iとkの間にもエッジがあることを推移的であるという。有向グラフでは、iからj, jからkへのエッジがあるときに、iからkへのエッジもあることを推移的であるという。
あるグラフにおいて、推移的であるかもしれない2つのノード(上でいうiとk)が実際に推移的である割合を推移性 transitivity という。えーと、Newman, Watts & Strogatz(2002)が提案したのだそうだ。
Rのigraphパッケージでいうと、transivity(g, type ="global") で無向グラフの推移性を求めることができる。なお、transitivity()は有向グラフも無向グラフとして扱うようだ。エッジの向きを考慮したいんなら自分で求めろ、ってことでしょうか。
あるノードからみて、それと隣接するノードからなるサブグラフを考え、その密度(つまり、ありうるエッジの数に占める実際のエッジの数の割合)を求める。これをそのノードのクラスタ係数 clustering coefficient と呼ぶ。igraphパッケージではtransivity(g, type = "local")で求めることができる。
あるグラフについてノードのクラスタ係数を平均した値を、グラフのクラスタ係数という。igraphパッケージではtransivity(g, type = "average")で求めることができる。
このクラスタ係数というのはWatts & Strogatz (1998)が提案したのだそうだ。どっちもワッツさんたちである。なんだかなあ。
推移性とグラフのクラスタ係数はよく似ているんだけど、ちょっと異なる。
いったいどう異なるのか。なにがなんだかわかんなくなってイライラしてきたので、仕事を中断してメモを取った。
準備。
無向単純グラフ$G = (V,E)$について考える。つまり、エッジに向きはないし、自己ループもないし、2ノード間には辺があるかないかのどっちかで、エッジに重みなどというややこしいものはない。
ノード$v$に隣接するノード数を次数$d(v)$とする。
$G$の3つのノードからなる完全サブグラフを三角形と呼ぶ。ノード$v$を含む三角形の数を$\delta(v)$とする。グラフ全体について考える場合、ひとつ三角形が増えるだけで$\delta(v)$の合計は3増えるから、グラフ全体の指標としては
$\delta(G) = \frac{1}{3} \sum_{v \in V} \delta(v)$
がふさわしい。
ノード$v$を中間に持つ長さ2のパスを$v$のトリプルと呼ぶ。その数を$\tau(v)$とすると、$n$個から$k$個を取り出す組み合わせを$combn(n, k)$と書くならば$\tau(v) = combn(d(v), 2)$だ。合計すると
$\tau(G) = \sum_{v \in V} \tau(v)$
本題に戻ろう。
推移性とはなにか。それはトリプルの総数に占める三角形の総数だから、
$\displaystyle T(G) = \frac{3\delta(G)}{\tau(G)}$
である。
グラフのクラスタ係数とはなにか。
次数$d(v) \geq 2$のノードについて、ノードのクラスタ係数$c(v)$とは、トリプルの数に占める三角形の数、つまり$c(v) = \delta(v)/\tau(v)$である。グラフのクラスタ係数というのはこれを平均した値だから、次数2以上のノードの集合を$V'$として
$\displaystyle C(G) = \frac{1}{|V'|} \sum_{v \in V'} c(v)$
である。
なお、次数が1までのノードについてもなんらかクラスタ係数を決め(0だか1だか)、単純平均してしまうという方法もある。
ここで加重クラスタ係数というのを考えてみる。各ノードにウェイトとして正の実数$w(v)$が振られているとしよう。グラフの加重クラスタ係数を
$\displaystyle C_w(G) = \frac{1}{\sum_{v \in V'} w(v)} \sum_{v \in V'} w(v) c(v)$
とする。
仮に、トリプルの数をウェイトにしたら、つまり$w(v) = \tau(v)$としたらどうなるか。$c(v) = \delta(v)/\tau(v)$より、総和記号の右の$\tau(v)$は消えて、
$\displaystyle C_\tau(G) = \frac{\sum_{v \in V'} \delta(v)}{\sum_{v \in V'} \tau(v)} = T(G)$
となる。
つまり推移性とは、各ノードが持つトリプルの数を重みにした加重クラスタ係数のことだ。全ノードの次数が同じとき、ないし全ノードのクラスタ係数が一致しているとき、グラフのクラスタ係数と推移性は等しくなる。
以上、次の論文のイントロ部分よりメモ。
Shank, T., Wagner, D. (2005) Approximating clustering coefficent and transitivity. Journal of Graph Algorithms and Applications. 9(2), 265-275.
なるほどね...
グラフの特性を記述する際、推移性を使うべきなのだろうか、グラフのクラスタ係数を使うべきなのだろうか。たとえばある社会が「友達の友達もまた友達だ」的性質を持っているかどうかを調べるならば、ノードをベースに考えて後者を使い、たくさんの離散的状態を遷移していくなにかについて、そこでの遷移が「3期後には元に戻っちゃう」的性質を持っているかどうかを調べるならば、エッジをベースに考えて前者を使う、ということかなあ...
ちょっとした覚え書き:グラフの推移性とクラスタ係数はどうちがうか
2019年11月 8日 (金)
最近なんだかこんなことばっかりなんだけど...
Rで環境 (environment) と呼ばれるオブジェクトを操作したいとき、関数名がよく分からなくて困ることが多い。rlangパッケージというのを使うと、もっと使いやすい関数がわかりやすい名前で提供されていてありがたいんだけど、従来の関数との対応がわからなくて、それはそれで混乱する。
このたびついに業を煮やして、神Hadleyが与えたもうたAdvanced R 2nd edition, Chapter 7. Environments を参照しつつメモを取った。
すいません、私の私による私のためのメモです。
環境そのものの操作
- 環境をつくる: rlang::env(); new.env()
- 環境 e を表示する: rlang::env_print(e), print(e). ただしprint()では中身はわからない
- 環境 e の親環境: rlang::env_parent(e), parent.env(e)
- 環境 e のすべての先祖の環境: rlang::env_parents(e)
- 空の環境(すべての環境の始祖): rlang::enpty_env()
- グローバル環境(いわゆるワークスペース): rlang::globalenv(), .GlobalEnv
- サーチパス(グローバル環境の先祖の環境たち)の名前を返す: search()
- サーチパスの環境たちを返す: rlang::search_envs()
- baseパッケージのパッケージ環境 (そのパッケージが外部に提供する環境): rlang::base_env()
- 現在の実行環境(関数の実行中はその関数の実行環境、そうでない場合はグローバル環境): rlang::current_env(), environment()
- 現在の関数を呼び出している関数の実行環境: rlang::caller_env(), parent.frame()
- ある関数が実行されるときに生まれる実行環境の親は、その関数の「関数環境」である(呼び出し元の関数の実行環境ではない。ここ、ときどき勘違いしちゃいますね)。関数環境とは、その関数がつくられたときにそいつがbindしたというかキャプチャした環境のこと。対話的につくった関数の関数環境はグローバル環境、関数1のなかでつくった関数2の関数環境は関数1の実行環境となる。
- 関数 fの関数環境: rlang::fn_env(f), environment(f)
- パッケージのなかの関数の関数環境はそのパッケージの名前空間環境。その親はそのパッケージのimports環境。その親はbaseパッケージの名前空間環境。その親はグローバル環境。
環境の中身の操作
- 環境 e のなかの名前をみる: rlang::env_names(e), names(e), ls(e, all.names = T)
- 環境 e が要素 x を持っているかを調べる: rlang::env_has(e, "x"), exists("x", e)
- 環境 e の要素 x にアクセスする: e$x, e[["x"]]
- 環境 e の要素 x の値を得る(存在しないときにはエラーを発生させる): rlang::env_get(e, "x"), get("x", e, inherits = FALSE)
- 環境 e の要素 x に値 1 をbindする: rlang::env_poke(e, "x", 1), rlang::env_bind(e, x = 1); assign("x", 1, e).
- 環境 e の要素 x に表現myfun()をbindするが、そのときは評価せず、最初にアクセスしたときだけ評価する: rlang::env_bind_lazy(e, x = myfun()), delayedAssign("x", myfun(), assign.env = e)
- 環境 e の要素 x に関数myfunをbindする。アクセスするたびに評価する: rlang::env_bind_active(e, x = myfun), makeActiveBinding("x", myfun, e)
- 環境 e の要素 x を消す: rlang::env_unbind(e, "x"), rm("x", envir = e)。なお、e$x <- NULL では消せない。
- 永続付値 <<- は、先祖の環境たちのどこかにある変数を変更する。どこにもみつからなかったらグローバル環境に変数をつくる。現在の環境にある変数を変更したり、変数をつくったりすることはない
2019年10月29日 (火)
話はちがうが(なにからだ)、Stanを使っていると、ときどきデータ型について混乱してしまうことがある。数日前も同僚が書いたコードをみていて、しばしわけがわからなくなってしまった。私が悪いんです、すいません。
松浦「StanとRでベイズ統計モデリング」の9章を熟読すればよい問題なのだが(自宅にも職場にも置いてあるんだし)、毎度毎度めくっているのもどうかという気がしてきたので、Users Guide (2.19)の15-16章を眺めてメモを取った。
15. Matrices, Vectors, and Arrays
- Stanのデータ型は、int, real, vector, row_vector, matrixの5つ。
- どの型も配列にできる。たとえばreal b[M,N]は2次元の配列。
- サイズを動的に変えることはできない。
- 2次元配列と行列を比べると、行列のほうがメモリがちょっと小さい。行列はメモリ上で固まってストアされているが配列はそうでない。
- 行列は列優先順でストアされているので、matrix[M,N] aならさきに1:Nでループしたほうが速い。配列は行優先順ではいっているので、real b[M,N] ならさきに1:Mでループしたほうが速い。そして行列のほうが速い。
- matrix[M,N] aに対して a[m] を呼ぶと行ベクトルが返るけど、これは遅い。row_vector[N] b[M]に対して b[m]を呼んだほうが速い。
- 行列の行列演算は速い。
- コンテナとしてみたとき、vector, row_vector, スカラーの一次元配列は同じ(ただし整数が入れられるのは配列だけだけど)。
16. Multiple Indexing and Range Indexing
- たとえば int c[3] に(5,9,7)をいれといて、ind indx[4]に(3,3,1,2)をいれとくと、c[idxs]は(7,7,5,9)を返す。こういうのがmultiple indexing。
- その特殊ケースとしてrange indexing (slicing)がある。c[1:2]とかね。c[2:size(c)]ってのもあり。c[:2]はc[1:2]の略記になる。c[]とc[:]は同じ。
16章にはほかにもいろいろ書いてあるんだけど、なんだかめんどくさくなってきたので、まあいいや、別の機会にしよう。
2019年8月14日 (水)
昔取ったメモのなかからR言語の自作チートシートが出てきた。2011年4月、転職をきっかけにしてRを使わなければらない羽目になり、何冊かの参考書をめくりながらとったノートである。当時はRについて全くの初心者で、右も左もわからない状態であった。
その後数か月間は折に触れて眺めては、新たに気が付いたことを追記・更新したと思うけれど、いずれ参照しなくなり、すっかり忘れ去っていた。チートシートというのはそういうものであろう。
それから8年の月日が流れ (自分で書いててショック)、いま見返してみると、いまではごく当然に思えることに新鮮な驚きを感じている形跡があったり、いまでは全く使わなくなった関数について真剣に調べていたり、それまで日々使っていたSAS言語といちいち比べていたり... なんというか、感慨深い。ああ、あのころ私は若かった... (嘘です。当時からおっさんでした)
せっかくなので、ちょっと整形してブログに載せ、供養としたい。
式
- 数値演算子は ^(ないし**), *, /, +, -, %/%(整数除算), %%(剰余)
- 演算子の優先順位がわからなくなったら
?Syntaxをみる - 代入記号として
<-が推奨されている - 代入式を評価すると、左辺の代入後の値が戻る
- オブジェクト名はcase sensitive
- ピリオドから始まるオブジェクトはhiddenとなる
データ型
- atomicなデータ型は5つ: {NULL, logical, numeric, complex, character}
- numericはメモリ上ではintegerだったりdoubleだったりする
is.character()etc. で型を確認as.character()etc. で型キャスト
データ構造
- 主なデータ構造は{vector, matrix, array, list, data frame}
- scalarという構造はない。要素1のvectorとして表現する
str()で構造とか中身の要約とかを表示- vector: ベクトル
- 要素は任意のデータ型
- ただし、あるベクトルの中の要素はすべて同じデータ型でなければならない。無理に突っ込むと一番上位の型に強制変換される
- 生成方法:
-
c()で要素を結合して生成 numeric(length=3)etc. でいきなり生成1:3ないしseq(3)でベクトル(1,2,3)を生成rep(2:4, 1:3)でベクトル((2),(3,3),(4,4,4))を生成
-
- 生成時の注意点
c()やnumeric()でいきなり数値をいれた場合、メモリ上では double になる (Matroff本p.54)。ゆえにc(1,2,3) != 1:3- コロン演算子 「:」 の挙動に注意 (Matroff本p.33)。
x==0のとき、1:xはc(1,0)になってしまう。正方向にのみ動かしたかったらseq()を使うべし。ただし、is.null(x)のとき1:xは NULL になるので都合がよいという面もある
length()が長さを返す- ベクトルの加減乗除が可能。要素ごとに計算される。長さが違うときは短いほうが繰り返される。例:
t(2:4) %*% 1:3ないしcrossprod(2:4,1:3)が内積20を返す x[3]がベクトルxの3番目の要素(からなるベクトル)を表す。添え字はベクトルでもよいx[-3]はベクトルxの「3番目の要素を除く全要素」のベクトルを表すx == c(1,3,5)のとき、x>4はベクトル(FALSE, FALSE, TRUE)を返すので、x[x>4]はベクトル(5)を表す- このとき、
which(x>4)はベクトル(3)を返す。3番目の要素がヒットしたという意味 x[] <- 2は xの全要素を2に置き換える (x <- 2との違いに注意)- 要素に名前をつけることができる。例)
x <- c(itemA = 1, itemB=2)。x["itemA"]が1を返す (perlのハッシュのような感じで使えるようだ)
- 次元つきのvector (←ベクトルの特殊な場合と考える。面白いなあ)
matrix(1:6, ncol=3)というようにして生成。→ 1列目が(1,2)になるX <- c(1:6); dim(X) <- c(2,3)でも同じall(X == Y)という風に比較dim(), ncol(), nrow()が次元数、列数、行数を返すrow(), col()は同じサイズの行列を返す。その要素は行番号ないし列番号で埋まっているX[i,j]が要素を表すX[i,]が行ベクトル、X[,j]が列ベクトルを表す (気持ち悪い...)- 上の記法でアクセスすると、返ってくるのはmatrixかもしれないしvectorかもしれない。
X[1,1,drop=FALSE]とするとXと同じ次元数のmatrixを返す - 添え字は行列でもよい。これを利用して、(行番号、列番号、値) を行としてもつ行列から表をつくることができる(cf. スペクター本のp.97)
diag(X)は対角要素のベクトルを表す
- 任意の数の次元を持つ
array(1:12, dim=c(2,3,2))というようにして生成
- 要素として異なる型のデータ構造を含みうる
list()で要素を結合して生成L[3]はリストLの3番目の要素からなるリストを返す。添え字はベクトルでもよいL[[3]]がリストLの3番目の要素そのものを表す。それがどんな型のデータ構造かはわからない- 二重括弧添字をベクトルにすると再帰的な指定になる。例)
L <- list(1:3, c("Hello", "World"))のとき、L[[c(2,1)]]とL[[2]][1]は等しい ("Hello") - 要素の名前を付けることができる。例)
L <- list(Start = 1, End = 2)。L[["Start"]]が 1 を返す。これをL$Startと略記できる
- データセットを表す特殊なリスト
- 要素は同じ長さのベクトル。つまり、Rではデータセットを行構造体のベクトルとしてではなく、列ベクトルの集合として扱うわけだ
data.frame()で要素(データセットの列ベクトル)を結合して生成- 文字は勝手にfactorにされてしまう。嫌なら
stringsAsFactors=TRUEをつける - 要素の名前をつけることができる。例)
purchase <- data.frame( product = c("a", "b")) $略記も使える。例)purchase$product[2] == "b"- [行番号、列番号] と添え字をつけてアクセスできる。
purchase[2,1] == "b" attach()すると変数名を直接呼べるようになる。detach()で解放される。attach()はデータフレームの中身を新しい環境にコピーしている。元のオブジェクトを書き換える際には、attach()していようがいいがデータフレーム名から呼ぶこと。attach()はまちがいのもと、つかわないほうがよい- カテゴリカル変数はfactor型として表現される。factorはatomicな型ではなく、
factor()で生成されるオブジェクト
リストの操作
stack(): リスト要素がすべてベクトルであるとき、それをすべて縦に結合した列と、タグ名を縦に結合した列の2列からなるデータフレームをつくる。例)stack(list(x=1:3, y=4:6, z=7:9))
データフレームの操作
- データフレームの例:
purchase <- data.frame(
product = c("apple", "cheese", "yogurt", "ham", "water"),
shop = c("drink", "daily", "daily", "meat", "drink"),
amount = c(2,3,1,5,6)
) - ソート:
order()は順位ベクトルを返すので、purchase[order(purchase$amount) , ]でソートしたことになる (なるほどー) - 行抽出(SASでいうサブセットif)
purchase[["shop"]] == "daily"はベクトル(FALSE, TRUE, TRUE, FALSE, FALSE)を返すから、purchase[purchase[["shop"]] == "daily" , ]とすればよいsubset(purchase, shop == "daily")でもよい。subset()は条件がNAになったときにfalse扱いしてくれる%in%演算子をつかってベクトルと比較してもよい。subset(purchase, shop %in% c("daily","meat"))
- 分割 (SASでいう when ... output ...):
LD <- split(purchase, purchase$shop)。LDは3つのデータフレームからなるリストになる。要素はLD$drink, LD$daily, LD$meatとなる - 縦に結合 (SASでいうset A B):
rbind(LD$drink, LD$daily) - 横に結合 (SASでいう byなしのmerge):
cbind(1:3,11:13)。ただし長さが同じでないといけない - マッチマージ (SASでいうby文つきのmerge):
merge(X, Y [, オプション])- マッチキーの指定
- 指定しないと名前が共通する列すべてがマッチキーになる (SQLでいう natural join)
by=(ベクトル)... マッチキーを指定するby.X=(ベクトル), by.Y=(ベクトル)... データフレーム別にマッチキーを指定する- 長さ0のベクトルを指定するとデカルト積になる(SQLの cross join)
- マッチキーによる事前のソートは不要 (そりゃ助かるね)
- マージの種類の指定
all = FALSE... マッチした行だけ (SQLの inner join)all.X = TRUE... Xは全行、Yはマッチした行だけ (SQLの left join)all.Y = TRUE... Xはマッチした行だけ、Yは全行 (SQLの right join)all = TRUE... マッチしようがしまいが全行 (SQLの full join)
データの集約(スペクター本の8章)
table(X)- Xはベクトル、リスト、データフレーム
Xにはいっているユニークな行ごとに、その行数を数えるXに入っているベクトルの数の次元数の配列を返す。例, 3本なら3次元配列- 各次元には名前がつく。それはデータベクトルに出現する水準
exclude=NULL引数で欠損値を含むことができるas.data.frame()に渡すと便利addmargins()に渡すと、各次元につきSum行を追加してくれるprop.table()に渡すと、割合の表に変換してくれる
xtabs(formula, data=X): formulaの左辺はなし、ないし頻度ウェイトftable(X)※本項は間瀬本p.181Xはふつうtable()なりxtabs()なりの出力Xを二次元の表にして返すrow.vars = 1:3で、1,2,3次元が表側、残りが表頭になるwrite.ftable()に渡すときれいなascii形式にしてくれる。いいんだかわるいんだか
- 集約のためのヒント
- グループがすでにリストの要素に分けられている → sapply, lapply
- グループが行列の行or列である → apply
- グループが一つ以上のグループ化変数で示されている
- 操作対象が単一のベクトル
- 結果はグループごとのスカラー → aggregate
- 結果はベクトル → tapply
- 操作対象が複数のベクトル → tapply, by
- 操作対象が単一のベクトル
lapply(X, FUN)ないしsapply(X, FUN)- ふつうXはリスト。各要素に
FUNを適用する。例)x <- strsplit(c("Hello world", "How do you do")," ")。length(x)は 2 を返す。sapply(x, length)は c(2,4)を返す - lapplyは常にリストを、sapplyは(もし可能なら)ベクトルないし行列を返す
- Xがデータフレームの場合、各列にFUNを適用する
- ふつうXはリスト。各要素に
apply(X, MARGIN, FUN)- 配列
Xの次元MARGINにFUNを適用する - 結果はベクトルないし行列
- よく使う
FUNについてはすでに関数が用意してあるので探すこと。rowSums(), colSums(), rowMeans(), colMeans(), etc. - sweep(X, MARGIN, STAT, FUN)のSTATに渡す。例) 列ごとに最大値を出し, 値をその列の最大値で割る:
Y <- sweep(X, 2, apply(X, 2, max) , "/")
- 配列
aggregate(X, BY, FUN)- ふつう
Xはデータフレーム。Xの全列 についてBYごとにFUNを適用 BYはグループ分け変数のリストでなければならない。X$byvar1なんていうのはだめ。X[c("byvar1","byvar2")]ないしlist(v1 = X$byvar1, v2=X$byvar2)とする。BYの値の組み合わせ数ぶんの行を持つデータフレームを返す。BYにNAを持っている行は無視される!
- ふつう
tapply(X, INDEX, FUN)- ベクトル
Xについて、INDEXの値ごとにFUNを適用 FUNがスカラーを返したら、名前付きベクトルないし行列を返す。as.data.frame(as.table(), responseName="xxx")に渡すとよい。responseNameを指定しないと、結果がFreqという列になってしまうFUNがベクトルを返したら、名前付きリストを返す- 例1) INDEXがひとつ
ranges <- tapply(PlantGrowth$weight, PlantGrowth$group, range)
# 下の行でcbindとするとresultは行列になり全要素が文字列に強制変換される
result <- data.frame(
group = dimnames(ranges)[[1]],
matrix (unlist(ranges), ncol=2, byrow=TRUE) #ベクトルの長さが2だとわかってる
) - 例2) INDEXが複数
ranges = tapply(CO2$uptake, CO2[c("Type","Treatment")], range)
# rangesは2x2のmatrixで、その要素が名前なしのリストで、
# リストの要素が長さ2のベクトル。悪夢だ
result <- data.frame(
expand.grid(dimnames(ranges)),
matrix(unlist(ranges),byrow=TRUE,ncol=2)
) - FUNを指定しないと、指定したときに生成されるであろうベクトル(行列, リスト)の添え字を返す
# 中央値を格納する2x2行列。
meds <- tapply(CO2$uptake, CO2[c("Type","Treatment")], median)
# 行数ぶんのベクトル。tapplyが生成する行列の添え字を格納している。
# ここでは(1,1,1,...,3,3,3,....,2,2,2,...,1,1,1...) となる。
inds <- tapply(CO2$uptake, CO2[c("Type","Treatment")])
# それぞれの値から、そのセルの中央値を引くのは
adj.uptake <- CO2$uptake - meds[inds]
# この例は、ave()にFUNを指定しても同じことができる
adj.uptake <- CO2$uptake - ave(CO2$uptake, CO2$Type, CO2$Treatment, FUN=median
- 例1) INDEXがひとつ
- ベクトル
split(X, F)- データフレーム
Xを、因子(のリスト)Fで分割し リストにして返す - 例) iris データセットの"Species" ごとに、残りの変数の相関行列の第一固有値を求める
# もし全体についてだったら
# eigen(cor(iris[setdiff(colnames(iris),"Species")]))$values[1]
frames <- split(iris[setdiff(colnames(iris),"Species")], iris$Species)
maxeig <- function(df) eigen(cor(df))$value1[1]
sapply(frames, maxeig) split()のかわりに行番号をtapply()に与える手もある。 例) iris データセットの"Species" ごとに、残りの変数の相関行列の第一固有値を求める# 話を簡単にするために、"Species"は5列目だとわかっているとしよう
# もし全体についてだったら eigen(cor(iris[-5]))$values[1]
# いま仮に行番号のベクトルがindであるとすると eigen(cor(iris[ind,-5]))$values[1]
maxeig <- function(ind, data) eigen(cor(data[ind,-5]))$values[1]
tapply(1:nrow(iris), iris[5], maxeig, data=iris)
- データフレーム
by(X, INDEX, FUN)- データフレーム
Xについて、INDEXの値ごとにFUNを適用 - 名前付きリストを返す
FUNがデータフレームを返すようにすると便利- 例)
CO2$uptakeの観測数、平均値、標準偏差からなるデータフレームをつくるsumfun <- function(x) {
data.frame(n=length(x$uptake), mean=mean(x$uptake), sd=sd(x$uptake))
}
bb <- by(CO2, CO2[c("Type", "Treatment")], sumfun)
cbind(
expand.grid(dimnames(bb)), # リストbbのグループ因子をデータフレームに展開
do.call (rbind, bb) # rbindにリストbbを与え、要素ごとに処理させている。つまり縦結合
)
- データフレーム
2019年7月12日 (金)
先月終わったセミナーの準備の際に悩んだあれこれを、いまだ気分的に引きずっているのだが...これもそのときにとったメモ。
うーん、やっぱり基礎教養が足りないのだと思う。辛いなあ。でも、もともと文系だし... 別に意図して選んだ仕事じゃないし... (泣き言)
$L$をラグ演算子とする。一階差分方程式
$(1-\phi L) y_t = w_t$
があるとき、$(1-\phi L)^{-1}$をどう定義すればよいか。
ラグ演算子を含む方程式の操作では、$|\phi| < 1$のとき
$(1-\phi L)^{-1} = 1+\phi L + \phi^2 L^2 \cdots$
だと定義するのが普通である。この話はあっちこっちの参考書に書いてある。
しかしここでは$|\phi| \geq 1$である場合について考えたい。この話、なかなか本に書いてないような気がするのです。
そういう例として...
時点$t$におけるある株の価格を$P_t$, 配当を$D_t$とする。ある投資家がこの株を$t$において買い$t+1$において売ったら、この投資家は配当から利率$D_t/P_t$を、売買差益から利率$(P_{t+1}-P_t)/P_t$を得る。リターンは
$r_{t+1} = (P_{t+1}-P_t)/P_t + D_t/P_t$
となる。
話をすごく単純にして、リターン$r_{t+1}$がどの時点でも一定の正の値$r$であるとしよう。
$r = (P_{t+1}-P_t)/P_t + D_t/P_t, \ \ r > 0$ ... [リターン公式]
両辺に$P_t$を掛けて移項すると一階の差分方程式になる。
$P_{t+1} = (1+r)P_t - D_t$ ... [株価の差分方程式]
ところで、一階の差分方程式
$y_t = \phi y_{t-1} + w_t$
は、元の式の右辺に$y_{t-1}, y_{t-2}, \ldots$を逐次代入して
$y_t = \phi^{t+1} y_{-1} + \phi^t w_0 + \phi^{t-1} w_1 + \cdots + \phi w_{t-1} + w_t$
と書き換えられる。従って、株価の差分方程式は
$P_{t+1} = (1+r)^{t+1} P_0 - (1+r)^t D_0 - (1-r)^{t-1} D_1 - \cdots - D_t$
と書き換えられる。
配当$\{D_0, D_1, \ldots, D_t\}$と、初期株価$P_0$の両方が決まれば、株価$\{P_1, P_2, \ldots, P_{t+1}\}$も決まる。初期株価$P_0$が未知の場合には、株価は決まらない。
ちょっと話がそれるんだけど、話をさらにものすごく単純にして、リターン$r_t$は常に$r$、配当$D_t$は常に$D$であるとしよう。
$P_{t+1} = (1+r)^{t+1} P_0 - [(1+r)^t + (1-r)^{t-1} + \cdots + 1] D_t$
カメカッコの中身をよくみると等比数列の和になっている。等比数列の総和ってのは、えーと、$c \neq 1$のときに$\sum_{k=1}^n c^{k-1} = (1-c^n)/(1-c)$でしたね(Wikipediaをみながら書きました)。よって
$P_{t+1} = (1+r)^{t+1} P_0 - \frac{1-(1+r)^{t+1}}{1-(1+r)} D$
分母が$r$になるので、結局こうなる。
$P_{t+1} = (1+r)^{t+1} [P_0 - (D/r)] + (D/r)$
ここでも、初期株価$P_0$が決まらないと株価は決まらない。
- 初期株価が$P_0 = D/r$だったらどうなるか。第1項が消えるので、株価は常に$P_t = D/r$となる。売買差益はゼロになり、全収益は株価に対する配当の比$r = D/P$となる。
- 初期株価が$P_0 > D/r$だったらどうなるか。投資家たちがその株に、配当を超えた価値を見出している場合である。このとき、株価$P_{t+1}$は上がり続ける。バブルみたいな感じですね。
本題に戻して...
話をもうちょっと現実的にする。配当$D_t$は変化する、しかし有界である、としよう。
話をリターン公式
$r = (P_{t+1}-P_t)/P_t + D_t/P_t, \ \ r > 0$
に巻き戻す。両辺に$P_t$を掛けて移項すると
$P_t = \frac{1}{1+r} [P_{t+1} + D_t]$
以下、$R = \frac{1}{1+r}$と略記する。
これに
$P_{t+1} = R [P_{t+2} + D_{t+1}]$
を代入して、さらに$P_{t+2}$を代入して...という風に、時点$T$まで前向きに逐次代入していくと、
$P_t = R^T P_{t+T} + R^T D_{t+T-1} + R^{T-1} D_{t+T-2} + \cdots + R D_t$ ... [★]
となる。
株価$P_t$が有界であれば、第一項の極限は
$\lim_{T \rightarrow \infty} R^T P_{t+T} = 0$
だし、配当$D_t$が有界であれば、第二項以降の和には極限
$\lim_{T \rightarrow \infty} \sum_{j=0}^{T} R^{j+1} D_{t+j}$
が存在する。というわけで、株価と配当が有界であれば、株価は第二項以降の和
$P_t = \sum_{j=0}^{\infty} R^{j+1} D_{t+j}$ ...[ファンダメンタル解]
となる。
ここでは、初期株価$P_0$も上の式で決まるという点にご注目。$D_t=D$としても決まらなかった$P_0$だが、$D_t$が有界だと仮定すれば決まるようになるわけだ。
ずいぶん前置きが長かったが... ここからはラグ演算子$L$をつかってやりなおす。
リターン公式
$r = (P_{t+1}-P_t)/P_t + D_t/P_t \ \ r > 0$
の両辺に$P_t$を掛けて移項して、一階の差分方程式をつくり
$P_{t+1} = (1+r)P_t - D_t$
これをラグ演算子を使って書き換える。
$[1-(1+r) L] P_{t+1} = - D_t$
以下、$\phi = 1+r$と略記する。
さあ、$P_{t+1}$はどうなるか。ここで$\phi > 1$だという点がこの話のミソである。
まず、ラグ演算子そのものの逆数を定義しておく。
$L^{-1} w_t = w_{t+1}$
まず、両辺に$-\phi^{-1} L^{-1}$をかける。左辺は
$[-\phi^{-1} L^{-1}] [1-\phi L] P_{t+1} = [1 - \phi^{-1} L^{-1}] P_{t+1}$
右辺は
$\phi^{-1} D_{t+1}$
となりますね。
さらに、両辺に$1+\phi^{-1} L^{-1} + \phi^{-2} L^{-2} + \cdots +\phi^{-(T-1)} L^{-(T-1)}$を掛ける。左辺はうまいこと整理されて
$P_{t+1} - \phi^{-T} P_{t+T+1}$
となる。右辺は
$\phi^{-1} D_{t+1} + \phi^{-2} D_{t+2} + \cdots +\phi^{-T} D_{t+T}$
となる。つないで移項すると
$P_{t+1} = \phi^{-T} P_{t+T+1} + \phi^{-1} D_{t+1} + \phi^{-2} D_{t+2} + \cdots +\phi^{-T} D_{t+T}$
よくよくみると、★式を1期ずらした式になっていますね。
$r >0$で、株価$P_t$が有界であれば、$T$が十分に大きい時、左辺から移行した第1項$\phi^{-T} P_{t+T+1}$は無視できる。従って、$r >0$で$P_t$と$D_t$が有界であれば、両辺に$-\phi^{-1} L^{-1} [1+\phi^{-1} L^{-1} + \phi^{-2} L^{-2} + \cdots +\phi^{-(T-1)} L^{-(T-1)}]$を掛けるという演算子は、その極限において、演算子$(1-\phi L)$の逆数だとみることができる。
というわけで、$(1-\phi L)$の逆数は、$|\phi| < 1$のとき
$(1-\phi L)^{-1} = 1 + \phi L + \phi^2 L^2 + \phi^3 L^3 + \cdots$
$|\phi| > 1$のとき
$(1-\phi L) ^{-1} = -\phi^{-1} L^{-1} \left[ 1 + \phi^{-1} L^{-1} + \phi^{-2} L^{-2} + \cdots \right]$
と定義できる。
ただし、いずれの場合も、$y_t$, $w_t$が有界であるという暗黙の仮定があることに注意すべし。
... 以上、Hamilton(1994) の2.5節からメモ。
ううう、わからん...
この本の2.2節には、$|\phi| < 1$のときの$(1- \phi L)$の性質についての説明があり、末尾に「$|\phi| \geq 1$のときの$[1-\phi L] ^{-1}$の性質については2.5節をみよ」と書いてある。ハミルトン先生、$|\phi| > 1$についてはわかりました。では、$|\phi| = 1$のときの$[1-\phi L] ^{-1}$はどう定義すればよろしいのでしょうか。
愚かな私の考えるところによれば、差分方程式
$y_{t} = y_{t-1} + w_t$
$(1-L) y_t = w_t$
において、$w_t$が有界でも$y_t$は有界じゃないし、仮に$y_t$が有界だと仮定したところで、$w_t$が与えられても$y_t$はなお未知だから、$(1-L)^{-1}$は定義できないように思うのですが、正しいでしょうか?
それとも、$(1-L)^{-1}$とは
$(1-L)^{-1} w_t = y_t = y_0 + \sum_{t=1}^{t} w_t$
となる演算子、つまり「演算子の左に書いてある奴をt=1から累積して初期値を足せ」という奇妙な演算子だと考えるべきなのでありましょうか???まさかねえ...
2019年1月20日 (日)
構造方程式モデリング界の帝王、泣く子も黙るMplus様には分厚いマニュアルがついていて、膨大な数のモデル例が紹介されている。そのなかには私には到底理解できないものもあれば、いっけん易しそうだがよく考えてみるとわけがわからないものもある。
後者のひとつがExample 9.26「Cross-classifiedデータのランダム二値項目IRTモデル」で、よんどころない都合により、本日はずっとこの事例についてあれこれ思い悩んでいた。そりゃあ出世しないわ...!
というわけで、この事例について考えたことをメモしておく。文字通り、私の・私による・私のためのメモであって、いちいちブログに書くんじゃないよ、情けないな、という気もする。
Example 9.26とはこういうモデルである。Mplus 7.2から追加された TYPE=CROSSCLASSIFIEDを使っている。
VARIABLE: NAMES = u subject item;
CATEGORICAL = u;
CLUSTER = item subject;
ANALYSIS: TYPE = CROSSCLASSIFIED RANDOM;
ESTIMATOR = BAYES;
PROCESSORS = 2;
MODEL: %WITHIN%
%BETWEEN subject%
s | f BY u;
f@1;
u@0;
%BETWEEN item%
u; [u$1];
s; [s];Mplusのサイトで公開されているデータを確認したところ、クラスタ変数 item は50水準, subjectは100水準。で、subject * item ごとに1行を持つ5000行のデータである。
このモデルを数式で表現してみよう。
コードに登場する変数は、u, item, subjectの3つ。そのうちitem と subject はCLUSTER=に指定されている。以下、subject を$i$, item を$j$とする。データの構造をコードから知るのは難しいが、上で確認したように、u は subject * item ごとにひとつ得られている二値の測定値である。これを$u_{ij}$と書く。
VARIABLEセクションの注目点は2つ。
- CLUSTER= item subject; となっている。あれこれ試していて気が付いたのだが、後述するように、CLUSTER=で指定する順番は無意味ではない。Mplusのマニュアルでは、cross-classifiedモデルにおける2つのbetweenレベルは2A, 2Bと表現されていて、CLUSTER=で最初に指定したのが2B, 次が2Aになる。ここではsubjectが2A, itemが2Bである。
- WITHIN=もBETWEEN=もない。ここで、u の指定は次の4通りがあり得た。(1)WITHIN=に指定する、(2)BETWEEN=で subject レベルの変数として指定する、(3)BETWEEN=で item レベルの変数として指定する、(4)WITHIN=でもBETWEEN=でも指定しない。ここでは(4)が選択されているわけで、$u_{ij}$が、subjectのレベルでもitemのレベルでもモデル化される、ということがわかる。
なお、$u_{ij}$がWITHINレベルでモデル化されるかどうかは、これだけではわからない(このことに気が付くまでに時間がかかった)。通常の階層モデル(TYPE = TWOLEVEL)では、ある変数がWITHIN=にもBETWEEN=にも指定されていないとき、その変数はどちらのレベルでもモデル化されるということがわかる。しかし、TYPE=CROSSCLASSIFIEDの場合は一概にそうともいえないのだ。このExample 9.26がよい例で、実は$u_{ij}$はWITHINレベルではモデル化されていない($u_{ij}$のモデルを式で表現したとき、その右辺に、$ij$を添え字に持つ項がない)。
MODELセクションに移ろう。
Mplusでは、カテゴリカル従属変数の背後には連続潜在変数が想定される。これを$u^*_{ij}$と書く。デフォルトではプロビット・リンクになる。つまり、標準正規分布関数を$\Phi$として
$Prob(u_{ij}=1 | u^*_{ij}) = \Phi(u^*_{ij} - \tau)$
である。%BETWEEN item%に [u$1] と指定されているから、ついつい$\tau$が item ごとに動くのかと考えてしまったのだが、そうではない。(ここも私が混乱した点のひとつであった。考えてみれば、通常のTWOLEVELモデルで%BETWEEN%に [u$1]と指定したら、それは動かないよね。落ち着け俺)
なお、Mplusのアウトプット上では、[u$1]は item レベルのパラメータとして扱われる。%BETWEEN item%に[u$1]と書こうが書くまいが結果は変わらない。%BETWEEN subject%に[u$1]と書くとエラーになり、ふたつあるBETWEENのどっちかで固定しろといわれる。そこで
MODEL: %WITHIN%
%BETWEEN subject%
s | f BY u;
f@1;
u@0; [u$1];
%BETWEEN item%
u; [u$1@0];
s; [s];u$1は0に固定され、結果として自由パラメータがひとつ減る。想像するに、MODEL=CROSSCLASSIFIEDにおいてカテゴリカル従属変数の閾値を推定する際は、レベル2B(つまり、CLUSTER=で1つめに指定したクラスタ変数のレベル)でしか指定できない、というルールがあるのかもしれない。
ここからは$u^*_{ij}$のモデル。
まずは、説明変数は無視して残差項にだけ注目しよう。uは%WITHIN%には登場せず、%BETWEEN subject%では u@0, %BETWEEN item%では u となっている。つまり、残差はsubject間では動かず、item間で動く。itemを「テスト項目」と捉えるなら、残差という言い方はなんだか変だな。むしろ切片というべきであろう。これを$a_j$と書き、その分散を$\sigma_a^2$と書こう。
いよいよ説明変数について考える。はい深呼吸!
%BETWEEN subject%に s | f BY u と指定されている。つまり、われらが $u^*_{ij}$は謎の潜在変数 f の指標なのだ。この潜在変数を $F$と書こう。[f]という記載がどこにもないので平均は0, f@1とあるので分散は1である。
sは因子負荷である。おさらいしよう。Mplusでは、縦棒を使って傾きや因子負荷に名前を付けると、それはただの傾き・因子負荷ではなく、BETWEENレベルで変動するランダム傾き・ランダム因子負荷になる。通常の階層モデル(TYPE=TWOLEVEL RANDOM)では、%WITHIN%において s | y ON x; とかs | f BY y; と指定するのが常道である。このとき、WITHINレベルでは(つまりクラスタの中では) s は変動しない。ただし、ランダム傾きに限り、アスタリスクをつけて s* | y ON x; と書けば、sはクラスタ内でも変動する。
しかし TYPE = CROSSCLASSIFIED RANDOMでは勝手が違う。まず、ランダム傾きだろうがランダム因子負荷だろうがアスタリスクは使えない。つまり、そのレベルでは変動しない。さらに、%WITHIN%だけでなく%BETWEEN%でも指定できてしまう。%BETWEEN%で指定した場合、そのレベルでは変動しないけど、隣のレベルでは変動しうるのだ。びっくり!
ここでは、sは%BETWEEN subject%で定義され、%BETWEEN item%で s; [s]; とある。ってことは、このモデルでは、因子負荷 s は subject によっては動かないが、itemによって動くのだ。sを $s_j$と書き、その平均を$\mu_s$, 分散を$\sigma_s^2$と書こう。
というわけで、この事例を数式で書き下ろすと、こういうモデルだと思う。
$Prob(u_{ij}=1 | u^*_{ij}) = \Phi(u^*_{ij} - \tau)$
$u^*_{ij} = a_j + s_j F_i $
$E(F) = 0, \ \ Var(F) = 1$
$a_j \sim N(0, \sigma_a^2), s_j \sim N(\mu_s, \sigma_s^2)$
推定するパラメータは、$\tau, \mu_s, \sigma_s^2, \sigma_a^2$の4つである。
つまりこのモデルは、50指標1因子のカテゴリカル因子分析モデル、ないしIRTモデルといってよいと思う。ちがいは、因子負荷$s_1, \ldots, s_{50}$, 項目切片$a_1, \ldots, a_{50}$をモデルのパラメータとみるのではなく、確率変数の実現値として捉えているという点である。
覚え書き: Cross-classifiedデータのランダム二値項目IRTモデルをMplusで表現する
2019年1月18日 (金)
cross-classifiedマルチレベルモデルについて大急ぎで勉強する必要が生じ、よく引用されている参考書である
Raudenbush, S.W., Bryk, A. (2002) Hierarchical Linear Models: Applications and Data Analysis Methods. Second Edition.
を急遽注文し、12章だけ読んだ。さぞや難しかろうと覚悟していたのだが、意外にもわかりやすい内容であった。
若くてやる気のある学生のみなさんに私がひとつだけ勝てるとしたら、このように、高めの本をためらいなくバカスカ買っちゃうということだけなのである... 悲しい...
以下はそのメモ。
本章ではデータが階層的ではあるんだけどきれいな階層になっていなくて、複数のユニットにcross-classifyされているようなデータについて扱う。子供が地域と学校に属しているとか、子供が中学と高校に属しているとか、従業員を職業と産業で分類するとか。
なお、子供がある学校に属していて、学校の中で実験群か統制群のどちらかに割り当てられている、というような場合と、構造は似ているけど全然違う。「子どもが地域と学校に属している」場合、分析者は結果をいろんな地域・学校に一般化したいと思っているので、地域と学校はランダム効果である。「子どもが学校と実験条件に属している」場合、いろんな地域に一般化したいとは思うが「実験条件の母集団」というのはないので、学校はランダム効果で実験条件は固定効果となり、実験条件をlevel-1変数にとったtwo-levelとなる。
以下、子ども$i$, 地域$j$, 学校$k$に属する子ども$i$の到達度を$Y_{ijk}$とする。
まずunconditonalなモデル(予測子のないモデル)について。
withinモデルは
$Y_{ijk} = \pi_{0jk} + e_{ijk}$
$e_{ijk} \sim N(0, \sigma^2)$
betweenモデルは
$\pi_{0jk} = \theta_0 + b_{00j} + c_{00k} + d_{0jk}$
$b_{00j} \sim N(0, \tau_{b00})$
$c_{00k} \sim N(0, \tau_{c00})$
$d_{00j} \sim N(0, \tau_{d00})$
$b_{00j}$は地域$j$の効果, $c_{00k}$は学校$k$の効果, $d_{0jk}$は学校と地域の交互作用効果。セル(学校x地域)のサイズが小さい時は交互作用効果の推定は無理。
このモデルはこう書き換えられる。
$Y_{ijk} = \theta_0 + b_{00j} + c_{00k} + d_{0jk} + e_{ijk}$
要するに二元配置分散分析である。
分散が$\sigma^2, \tau_{b00}, \tau_{c00}, \tau_{d00}$に分解されたので、ユニット内相関係数も3種類定義できることになる[...メモ省略]
ではconditionalなモデルについて。
地域特性を$W_j$, 学校特性を$X_k$とする。話を単純にするため、どちらも1変数、固定効果、2水準(実験群と 統制群)とする。個人特性を$a_{ijk}$とする。話を単純にするため、1変数2水準(男と女)とする。
withinモデルは
$Y_{ijk} = \pi_{0jk} + \pi_{1jk} a_{ijk} + e_{ijk}$
$e_{ijk} \sim N(0, \sigma^2)$
さて、betweenモデルは...
まずは簡単に、地域の予測子の効果も学校の予測子の効果も固定と考えよう。以下、$\pi_{0jk}$と$\pi_{1jk}$を一発で書くために、$p=0,1$とする。
$\pi_{pij} = \theta_p + b_{p0j} + \gamma_p W_j + c_{p0k} + \beta_p X_k + d_{pjk}$
このモデルだと、地域の効果は全学校で共通、学校の効果は全地域で共通である。
これを緩和すると
$\pi_{pij} = \theta_p + b_{p0j} + (\gamma_p + c_{p1k}) W_j + c_{p0k} + (\beta_p + b_{p1j}) X_k + d_{pjk}$
地域特性と学校特性の交互作用をいれると
$\pi_{pij} = \theta_p + b_{p0j} + (\gamma_p + c_{p1k}) W_j + c_{p0k} + (\beta_p + b_{p1j}) X_k + \delta_p X_k W_j + d_{pjk}$
実際には、理論と照らし合わせて、もうちょっと簡略にしないといけないわけで...
ここからは実例の紹介。
実例1, 子どもの達成に地域と学校がどう効くか研究。
withinモデルは
$Y_{ijk} = \pi_{0jk} + \pi_{1jk} a_{ijk} + e_{ijk}$
$e_{ijk} \sim N(0, \sigma^2)$
betweenでは主効果だけ考えた。
$\pi_{0jk} = \theta_0 + b_{00j} + c_{00k}$
$b_{00j} \sim N(0, \tau_{b00})$
$c_{00k} \sim N(0, \tau_{c00})$
このモデルを推定して級内相関を求めると...[略]
予測子をいれてみます。withinレベルで、入学前の言語能力VRQと読み到達度Reading, 父親の職業DADOCCと教育DADED, 母親の教育MOMEDと働いているかDADUNEMP, 性別SEX。地域特性は、社会的剥奪レベルDEPRIVATION。ただし、学校によって違ってくるかもしれないので
$\pi_{0jk} = \theta_0 + (\gamma_{01} + c_{01k})DEPRIVATION_j + b_{00j} + c_{00k} $
とし、$(c_{00k}, c_{01k})'$の分散共分散を3つすべて推定した。で、カイ二乗検定で「$c_{01k}$の分散も$c_{00k}$との共分散も0」という帰無仮説が棄却されなかったので、$c_{01k}$を取っ払った。[←なるほど...]
実例2はめんどくさいので読み飛ばした。
勉強になりましたです...
実例1で、地域特性の効果が学校によって違うってのをモデル化しているけど($(\gamma_{01} + c_{01k})W_j$という項をいれる。なるほどねえ)、こういうのMplusだとどうやって指定するんだろう?
そうか、私がいまやりたいのは
$Y_{ijk} = \theta_0 + b_{00j} + b_{01j} c_{00k} + e_{ijk}$
というモデルだということに気が付いた。うーむ、こういうのはMplusだとどうなるんだ???
覚え書き:cross-classifiedなマルチレベルモデル
2019年1月 6日 (日)
昨年暮れ、学会発表のための分析をやっててわけがわからなくなり、頭を整理するために、Mplusユーザーズ・マニュアル9章(complex survey dataの階層モデリング)の事例40個を全部読んだ。そのときにとったメモ。
事例9.30-9.40はAR(1)構造がはいって難しさもさらにグレードアップするのだが、当面使う予定がないので(←言い訳)、メモも省略している。
- TYPE=TWOLEVELで、WITHINレベルでもBETWEENレベルでも x が y に刺さっているとき、データとしてxのクラスタ別平均 xm をつくっておいて、 MODELで
とする手と、単に%WITHIN%
y ON X;
%BETWEEN%
y ON xm;
とする手がある。前者の場合はDATAでWITHIN=x; BETWEEN=xm;と宣言すること。いっぽう後者の場合、xはWITHINレベルの潜在変数とBETWEENレベルの潜在変数に分解されていることになる。階層回帰モデルの一般的アプローチではないけれど、xmの信頼性が低いときに後者がお勧め。[←これを読んで、むしろ前者がアリだということに驚いた。個票があるのに標本平均をデータにするなんて邪道という気がするが、クラスタのサイズが十分に大きければ構わんってことか...] なお、後者のモデルにおけるBETWEENレベルの係数とWITHINレベルの係数の差を、Raudenbush & Bryk (2002)は「文脈効果」と呼んでいる[←どういう意味だろう?](事例9.1)%WITHIN%
y ON x;
%BETWEEN%
y on x; - TYPE=RANDOMのときの縦棒("|")の左はランダム回帰係数の名前を表すが、TYPE=TWOLEVEL RANDOMで%WITHIN%での指定だったらそのランダム回帰係数はBETWEENレベルの変数になりますわね。ところがアスタリスクをつけると(「s* | y on x」という風に)、これはWITHINでも分散を持つようになる。[←これはほんとに、いままでぜんっぜん知らなかった。こういうことがあるからMplusは怖い...] (事例9.14)
- TWOLEVEL RANDOMでは、
というようなモデルを組める。logvはyの残差分散の対数を表す。[そうそう、これも謎の機能で... ESTIMATOR=BAYESが登場してから追加された機能だと思う。理屈はわかるけど、どういうときに使えばいいのかがいまいちわからない。係数がクラスタによって違うモデルをつくりたいというのはわかるけど、残差分散がクラスタによって違うモデルをつくりたいってことはあるのか...あるか... そうか...] (事例9.28)%WITHIN%
logv | y;
%BETWEEN%
logv on w;
ところで、Mplusは結構長く使っているはずなのだが、それでも「えええ、そんなことができるの」と呆れたモデルがあったので、呆れついでにメモしておく。事例9.26。変数はu(カテゴリカル)、subject, itemの3つ、subjectとitemがクラスタのCROSSCLASSIFIED RANDOMモデル(THREELEVEL RANDOMではないという点に注意)。
%WITHIN%
%BETWEEN subject%
s | f BY u; f@1; u@0;
%BETWEEN item%
u; [u$1]; s; [s]; つまり、subjectレベルではuは分散1の潜在変数fに残差無しで規定されていて、その負荷というかプロビット回帰係数がsである(uをテスト項目の正誤とすると、fは対象者の能力、sは項目の識別性のようなものであろう)。uはitemレベルで切片が動き、残差分散も動く。さらにsも、subjectのなかでは動かないけどitemレベルで動く。ええええ... そういうのを組みたくなる動機はわかるけど、まさかほんとに組めるとは。 sはsubjectレベルで定義されているからitemレベルではモデル化できないかと思った。CROSSCLASSIFIEDモデルおそるべし。
いやあ、やっぱり使っているソフトのマニュアルは読むべきだ... 読むべきものが多すぎて辛い...
Mplusについては、Muthen一家の手によるものを含め、多種多様なレベルの解説が手に入るのだが、CROSSCLASSIFIEDモデルについてのまとまった解説は見当たらない。どこかにないかしらん。
2019/01/20追記: 事例9.26のコードについて誤解していたことにあとで気が付いた。CROSSCLASSIFIEDおそるべし。
覚え書き: Mplusがご提供する階層モデリングのための謎機能たち
2018年10月30日 (火)
仕事の都合で、統計学の一般的な知識についてのご相談を頂くことがある。そうしたご相談の、そうだなあ...4割か5割くらいは、南風原「心理統計学の基礎」を熟読すれば答えられる内容である。いうなれば、私の日々の仕事の一部は、南風原本を適宜わかりやすく言い換えることに過ぎない。嗚呼、哀れな人生。
しかし、ここにふたつの問題がある。(1)ご相談を受けてから熟読している時間はない。(2)前もって熟読していたとしても、覚えていられるとは限らない。
幸か不幸か、私は人生においてヒマな時期が結構長かったので、(1)の問題は一応クリアしているんだけど(つまり、2002年の刊行時にかなり真剣に読んだんだけど)、(2)の問題が壁となって立ちはだかる。特に最近は、この壁がすごく、すごーく、ものすごーく高い。
このたび都合であれこれ説明を書いていて、ああこの話って、あの本の8章、部分相関係数とか偏相関係数とかからはじめてTypeIII平方和に至るくだりの、下手な書き換えに過ぎないなあ... と気が付いた。
というわけで、せめてもの忘備録として、8章の内容をメモしておきます。
事例を剥ぎ取って要点のみメモする。なので、メモだけをみると、いっけんすごく難しい話のようにみえるだろうと思う。
南風原先生の略記法とはちがい、変数$X$の標準偏差を$s[X]$, $X,Y$の相関係数を$r[X,Y]$と略記する。
8.1 部分相関係数と偏相関係数
ここに変数$y, x_1, x_2$がある。$x_2$と$y$の間には、その両変数と$x_1$との相関関係だけでは説明できないような独自の関係があるか。
$x_2$を、$x_1$によって完全に予測可能な成分と、$x_1$と完全に無相関な成分$x_2|x_1$とにわけ、$x_2|x_1$と$y$との相関
$\displaystyle r[y, (x_2|x_1)] = \frac{r[y, x_2] - r[y, x_1] r[x_1,x_2] }{ \sqrt{1-r^2[x_1, x_2]} }$ [8.1]
を調べよう。これを部分相関係数part correlation coefficient, ないし片偏相関係数(半偏相関係数) semipartial correlation coefficentという。
部分相関係数においては、$x_2$からは$x_1$の影響を除いてあるが、$y$に関してはもとのままである。そこで、$y$から$x_1$の影響を除いた$y|x_1$と、$x_2|x_1$との相関
$\displaystyle r [(y|x_1), (x_2|x_1)] = \frac{r[y, x_2] - r[y, x_1] r[x_1,x_2]}{\sqrt{1-r^2[y, x_1]} \sqrt{1-r^2[x_1, x_2]}}$ [8.2]
も調べよう。これを偏相関係数partial correlation coefficientという。
$x_1$から$x_2$と$y$にパスが刺さるパス図で考えると、部分相関係数$r[y, (x_2|x_1)]$は「$y$と、$x_2$の残差との相関」であり、偏相関係数$r [(y|x_1), (x_2|x_1)]$とは「$y$の残差と、$x_2$の残差との相関」である。
部分相関係数と偏相関係数の間には次の関係がある。
$\displaystyle r [(y|x_1), (x_2|x_1)] = \frac{ r [(y|x_1), (x_2|x_1)] }{ \sqrt{1-r^2[y, x_1]} }$ [8.3]
8.2 偏回帰係数とその解釈
ここで唐突におさらいしますが、一般に、散布図の横軸が$X$、縦軸が$Y$のとき、回帰係数は
$b[X,Y] = r[X,Y] \times (s[Y] / s[X])$ [3.13]
$X$で$Y$を予測したときの予測の標準誤差は
$s[e] = s[Y] \sqrt{1-r^2[X,Y]}$ [3.25]
である。
本題に戻って...
横軸に$x_2|x_1$、縦軸に$y$をとった散布図に、回帰直線をあてはめてみよう。
- 相関にあたるのは、部分相関係数$r[y, (x_2|x_1)]$
- 横軸の標準偏差は、$x1$で$x2$を予測したときの予測の標準誤差だから、[3.25]より $s[x_2|x_1] = s[x_2] \sqrt{1-r^2[x_1, x_2]}$ [8.4]
- 縦軸の標準偏差は、$y$の標準偏差$s[y]$
以上により、この散布図にあてはめた回帰直線の傾き
$b[ y, (x_2|x_1) ]$
は、[3.13]より
$\displaystyle = r[ y, (x_2|x_1)] \frac{s[y]}{s[x_2|x_1]}$
[8.1],[8.4] を代入して
$\displaystyle = \frac{r[y, x_2] - r[y, x_1] r[x_1,x_2]}{\sqrt{1-r^2[x_1, x_2]}} \times \frac{ s[y] }{ s[x_2] \sqrt{1-r^2[x_1, x_2]} }$
$\displaystyle = \frac{r[y, x_2] - r[y, x_1] r[x_1,x_2]}{ 1-r^2[x_1, x_2] } \times \frac{ s[y] }{ s[x_2] }$ [8.5]
これを偏回帰係数 partial regression coefficientと呼ぶ。なお、横軸に$x_2|x_1$、縦軸に$y|x_1$をとっても、同じ偏回帰係数が得られる。
[8.5]の第2項は標準偏差の比である。仮に$x_2$と$y$をまず標準偏差1に標準化してから求めたなら、この項は消えて、
$\displaystyle b^{*}[ y, (x_2|x_1) ] = \frac{r[y, x_2] - r[y, x_1] r[x_1,x_2]}{ 1-r^2[x_1, x_2] }$ [8.7]
これを標準偏回帰係数standardized partial regression coeffientという。
部分相関係数[8.1], 偏相関係数[8.2], 標準偏回帰係数[8.7]は分母のみ異なるという点に注目すべし。
8.3 重回帰モデル
ここからは、
$y = \alpha + \beta_1 x_1 + \beta_2 x_2 + \epsilon$ [8.10]
という線形モデルを考える。なお、推測に際しては
$\epsilon | x_1, x_2 \sim N(0, \sigma^2_\epsilon)$
という確率モデルを想定する。
ここから、
$E[y | x_1, x_2] = \alpha + \beta_1 x_1 + \beta_2 x_2$
である。これを回帰平面ないし予測平面と呼ぶ。
母数$\alpha, \beta_1, \beta_2$の推定量を$a, b_1, b_2$とすると
$\hat{y} = a + b_1 x_1 + b_2 x_2$
残差 $e = y - \hat{y}$の二乗和 $Q = \sum_i^N e_i^2$を最小化する推定量は
$\displaystyle b_1 = \frac{r[y,x_1] - r[y, x_2] r[x_1,x_2]}{1-r^2[x_1,x_2]} \times \frac{s[y]}{s[x_1]}$ [8.15]
$\displaystyle b_2 = \frac{r[y,x_2] - r[y, x_1] r[x_1,x_2]}{1-r^2[x_1,x_2]} \times \frac{s[y]}{s[x_2]}$ [8.16]
$\displaystyle a = \hat{y} - b_1 \bar{x}_1 - b_2 \bar{x}_2$ [8.17]
なお、[8.16]は[8.5]と同じである。
$y$と$\hat{y}$の相関係数は
$\displaystyle R = \sqrt{ \frac{r^2[y,x_1] + r^2[y,x_2] - 2 r[y,x_1] r[y,x_2] r[x_1,x_2]}{1-r^2[x_1,x_2]} }$ [8.20]
これを重相関係数multiple correlation coefficientという。重相関係数は、独立変数の1次式で与えられる変数と従属変数との相関のうち最大のものである。
8.4 重回帰分析の仕組み
平均0に中心化したデータを$\mathbf{y}, \mathbf{x_1}, \mathbf{x_2}$とする。
予測値ベクトルは
$\hat{\mathbf{y}} = b_1 \mathbf{x_1} + b_2 \mathbf{x_2}$
である。これは$\mathbf{x_1}, \mathbf{x_2}$によって張られた平面上のベクトルである。
その先端から$\mathbf{y}$に向かうベクトルが残差ベクトル$\mathbf{e}$である。最小二乗法では、$\mathbf{e}$の長さを最小にするように$\hat{\mathbf{y}}$を決める。つまり、$\mathbf{y}$から平面に垂線をおろし、その足を$\hat{\mathbf{y}}$の先端に決めているわけである。
重相関係数$R$とは、$\mathbf{y}$と$\hat{\mathbf{y}}$のなす角度のコサインである。これを最大にするように$\hat{\mathbf{y}}$を決めている、といってもよい。
重相関係数$R$はどういうときに大きくなるか。
まず、単独で高い相関を持つ独立変数があれば大きくなる。これは、$\mathbf{y}$が$\mathbf{x_1}$に近づくにつれて平面も近づいていく、と理解できる。
独立変数間の相関が-1に近いときにも大きくなる(「0に近いとき」でない点に注意)。これは、$\mathbf{x_1}, \mathbf{x_2}$と$\mathbf{y}$との角度を保ったまま$\mathbf{x_1}$と$\mathbf{x_2}$の角度を拡げると、平面が$\mathbf{y}$に近づいていく、と理解できる(90度に拡げた瞬間なにか特別なことが起きるわけでない点に注意)。
$\mathbf{x_1}$と$\mathbf{x_2}$の相関が高いとき、$\hat{\mathbf{y}}$が少し変動するだけで$b_1, b_2$が大きく変動する。
このことは、独立変数間に高い相関があると、サンプリングによる偏回帰係数の変動が大きくなることを意味している。これを多重共線性という
偏回帰係数の標準誤差は
$\sigma[b_1] = \sigma[e] / (\sqrt{N} s[x_1] \sqrt{1-r^2[x_1,x_2]})$ [8.23]
$\sigma[b_2] = \sigma[e] / (\sqrt{N} s[x_2] \sqrt{1-r^2[x_1,x_2]})$ [8.24]
一般化すると
$\sigma[b_j] = \sigma[e] / \left( \sqrt{N} s[x_j] \sqrt{1-R^2[x_j, x_1,\cdots (x_j) \cdots x_p]}) \right)$ [8.25]
である($R^2[x_j, x_1,\cdots (x_j) \cdots x_p]$は$x_j$とそれ以外のすべてとの重相関係数)。他の変数との相関が高いほど大きくなるのがわかる。
最後に、偏回帰係数を幾何学的に説明しよう。[←ここがこの本の難関のひとつだと思うんですよね...」
8.2節にいわく、偏回帰係数とは、横軸に$x_2|x_1$、縦軸に$y$をとった散布図の回帰係数である。また8.3節にいわく、偏回帰係数とは、$x_1, x_2$で$y$を予測するときの係数である。
$\mathbf{x_1}, \mathbf{x_2}$で張られた平面を考えよう。$\mathbf{x_2|x_1}$とは、$\mathbf{x_2}$の先端から$\mathbf{x_1}$に下した垂線を逆向きにしたベクトルである。当然、平面に乗っている。話を簡単にするため、こいつをずずずっと平行移動して、始点を原点に揃えよう。$\mathbf{x_2|x_1}$は$\mathbf{x_1}$と原点で直交しているわけね。
こいつで$\mathbf{y}$を予測しよう。上空に斜めに伸びている$\mathbf{y}$の先端から、平面に垂線を降ろすんじゃなくて、$\mathbf{x_2|x_1}$に向けて垂線を降ろす(上空から斜めに落ちてくる線になる)。その足が、ベクトル$b_2(\mathbf{x_2|x_1})$の先端。これが8.2節の説明である。
今度は、$\mathbf{y}$の先端から平面に垂線を降ろそう。その足の位置から、$\mathbf{x_1}$と平行に(つまり$\mathbf{x_2|x_1}$と垂直に)$\mathbf{x_2}$に移動し、ぶつかったところが、偏回帰係数$\times \mathbf{x_2}$の先端である。これが8.3節の説明。図に書いてみると、なるほど、それは$b_2\mathbf{x_2}$となる。
なお、部分相関係数$r[y, (x_2|x_1)]$とは、$\mathbf{y}$(上空に斜めに伸びている)と$\mathbf{x_2|x_1}$(さっき地表に引いた新しい線)がなす角度のコサインである。
$\mathbf{y|x_1}$とは、$\mathbf{y}$の先端から$\mathbf{x_1}$に斜めに降ろした垂線を逆向きにしたベクトルである。これを原点へと平行移動すると、それは、$\mathbf{x_2|x_1}$(さっき地表に引いた新しい線)の原点を押さえて先端を持ち、$\mathbf{x_1}$との角度を変えないようにまっすぐに引き上げ、$\mathbf{y}$の先端の高さまで伸ばした新しい棒となる。偏相関係数$r[(y|x_1), (x_2|x_1)]$とは、この引き上げ角度がなすコサインである。
5. 平方和の分割と重相関係数の検定
$\mathbf{y}, \hat{\mathbf{y}}, \mathbf{e}$は直角三角形をなしているんだから、
$||\mathbf{y}||^2 = ||\hat{\mathbf{y}}||^2 + ||\mathbf{e}||^2 $ [8.26]
ベクトルの長さは平方和だから
$SS[y] = SS[\hat{y}] + SS[e]$ [8.27]
分散説明率は
$SS[\hat{y}] / SS[y] = ||\hat{\mathbf{y}}||^2 / ||\mathbf{y}||^2 = cos^2 \theta[y,\hat{y}] = R^2$ [8.28]
[8.27] より
$R^2 = 1 - SS[e] / SS[y]$ [8.29]
である。
$SS[y]$の自由度は$N-1$。残差平方和$SS[e]$の自由度は平方の数から母数の数を引いたもので、ここで母数は$p+1$だから(切片がはいる)、自由度は$N-p-1$。よって$SS[\hat{y}]$の自由度は$p$である。
予測の誤差分散と標準誤差はそれぞれ
$s^2[e] = SS[e] / N = SS[y] (1-R^2)/N = s^2[y] (1-R^2)$ [8.32]
$s[e] = s[y] \sqrt{(1-R^2)}$ [8.33]
だが、$\sigma[e]$の推定量としては(そして予測の標準誤差としても)、自由度$N-p-1$で割った不偏推定量
$s^{'}[e] = s[y] \sqrt{N/(N-p-1)}$ [8.34]
を使うことが多い。同様に、$\sigma^2[y]$の推定量としても$s^{'2}[y] = SS[y] / (N-1)$を使うことが多い。[8.29]を書き換えると
$R^2_{adj} = 1 - \sqrt{\frac{N-1}{N-p-1}}(1-R^2)$
これが自由度調整済み決定係数である。$R^2$が$p$の増大につれて過大になるのを修正しているわけだ。
重相関係数がゼロであるという帰無仮説の下で、
$F = \frac{SS[\hat{y}]/p}{SS[e]/(N-p-1)}$ [8.36]
は自由度$p, N-p-1$のF分布に従う。[8.28]で書き換えると
$F = \frac{R^2/p}{(1-R^2)/(N-p-1)}$ [8.36]
である。
6. 個々の独立変数の寄与の評価
[8.20]から$r^2[y,x_1]$を引くと
$\displaystyle R^2 - r^2[y, x_1] = \frac{(r[y,x_2]-r[y,x_1]r[x_1,x_2])^2}{1-r^2[x_1,x_2]}$
となる。よくみると、これは[8.1]の部分相関係数$r[y, (x_2|x_1)]$の二乗である。
これは独立変数の数に限らず成り立つ。つまり、$q$個[原文では$p_1$個]の独立変数からなるモデルに変数を1個以上加えて$p$個にした時の決定変数の増分は、部分相関係数の二乗になる。これを
$R^2[y,x_1\cdots x_p] - R^2[y,x_1\cdots x_q] = r^2[y, (x_p|x_1\cdots x_q)]$
と書こう。
追加した$p-q$個の偏回帰係数について、帰無仮説
$H_0: \beta[x_{q+1}] = \cdots = \beta[x_p] = 0$
を検定することができる。検定統計量
$\displaystyle F = \frac{(R^2[y, x_1\cdots x_p]-R^2[y,x_1\cdots x_q])/(p-q)}{(1-R^2[y, x_1\cdots x_p])/(N-p-1)}$ [8.43]
が帰無仮説の下で自由度$p-q, N-p-1$のF分布に従う。
上で述べた独立変数の寄与の評価は、独立変数の投入順で変わってくる。
投入順を決め、各ステップにおける$R^2$の増分に全平方和$SS[y]$を掛けて得られる平方和をタイプIの平方和という。
投入順は決められないことが多い。そこで、それぞれの独立変数を最後に投入したと想定し、部分相関係数の二乗に全平方和$SS[y]$を掛ける。これをタイプIIIの平方和という。
[8.25]で示した偏回帰係数の標準誤差$\sigma[b_j]$の、分子の$\sigma[e]$を$s^{'}[e]$で置き換えて$s[b_j]$とし、これと偏回帰係数$b_j$を比較した $t = b_j / s[b_j]$ は、$H_0: \beta_j = 0$の下で自由度$N-p-1$のt分布に従う。
[8.43]で追加した変数が1個だった場合の$F$は、この$t$の二乗になる。つまり、偏回帰係数の標準誤差を使った検定は、タイプIII平方和を使った検定と同じである。
(以上!)
2018年9月19日 (水)
久々にスキャン・パネル・データについて考える機会があって(生計のためになんでもやるけど、我ながら節操がない)、そういえば前にこんなの読んだな...と頭をよぎるんだけどよく思い出せないということが続き、どんよりした気分になった。頭の整理のため、このブログに記録した範囲で、スキャン・パネル・データを分析している論文のリストをつくってみた。
そういえば、2011年から2012年にかけては意識してスキャン・パネル・データ関連の奴を読むように心がけていたんだよな... 勤務先が変わったこともあって... あの頃の私は多少は誠実であった... 最近はなんだかもう疲れちゃって...
分類は適当である。すいません、これほんとに個人的な覚え書きなんです。
ブランド選択:
- Abramson, et al. (2000) 消費者選択の多項ロジットモデルにおけるパラメータのバイアス (2011/05)
- Andrews, Ainslie, & Currim (2002) 有限混合モデル vs. 階層ベイズモデル ~選択データ分析での対決~ (2012/04)
- Lemon & Nowlis (2002) 販促とブランドのシナジー構築 (2011/06)
- van Heerde, Gupta, & Wittink (2003) 販促の効果に占めるスイッチングは君が思うよりずっと小さい (2012/04)
- Varki, S. & Chintagunta, P.K. (2004) 一部の世帯が複数セグメントに所属することを許す購買行動セグメンテーション (2012/05)
- Chib, Seetharaman, & Strijnev (2004) スキャナー・パネル・データのための「買わない」選択肢つきブランド選択モデル (2012/04)
- Erdem, Zaho, & Valenzuela, A. (2004) アメリカでPBが売れない理由を購買データだけで突き止める (2012/04)
複数カテゴリの購買:
- Manchanda et al. (1999) 複数カテゴリ購買生起モデル (2011/12)
- Russell&Petersen(2000) 複数カテゴリ購買の確率モデル・最終章 (2012/03)
- Chib, Seetharaman, & Strijney (2002) 複数カテゴリ購買の多変量プロビットモデル (2011/12)
- Seetharaman, et al. (2005) 複数カテゴリの選択モデルレビュー (2011/12)
- Boztug & Hildebrandt (2005) 多変量ロジットモデルでバスケット分析 (2011/12)
ブランド購買:
購入数量:
- Chandon & Wansink (2002) 買い置きを使ってしまうのはいつ?(2011/06)
- Bell, Iyer, & Padmanabhan (2002) 値引きが買い置きやカテゴリ消費増大をもたらすような商品カテゴリにおける価格競争 (2011/06) ※ゲーム理論的モデル
購入価格:
購買間隔:
- Jain & Vilcassim (1991) 購買タイミングの比例ハザードモデル (クラシカル・バージョン) (2013/06)
- Seetharaman & Chintagunta (2003) 購買タイミングの比例ハザードモデル (2013/04)
- Fader, Hardie & Huang (2004) 新製品販売予測の動的変化点モデル (2011/06)
- Seetharaman(2004) 購買データを分析するみなさん、比例ハザードモデルばっかり使ってないで加法リスクモデルをお使いなさい (2013/05)
店舗レベルで分析しているもの:
- Pauwels, Hanssens, & Siddarth (2002) 値引きの長期的功罪 (2012/04)
- van Heerde, et al. (2000) POSデータによる販促前後売上減の推定 (2011/05)
書籍:
- 守口(2002)「プロモーション効果分析」(2012/02)
- 阿部・近藤(2005)「マーケティングの科学―POSデータの解析」(2011/05)
2018年9月10日 (月)
地球統計学モデルによる空間的推測をやってるとき、コバリオグラムとバリオグラムのちがいについてたびたび混乱したので、メモをとった。というか、ふだん頼りにしているDiggle&Ribeiro(2010)って、このくだりについては結構わかりにくいような気がするのである。(←理解力の低さをさりげなく他人のせいにする)
瀬谷・堤「空間統計学」5.2節のメモ。話がややこしくなるので異方性の話は省略する。
観測地点$\mathbf{s}_i$($i=1,\ldots,n$)における観測値を$y(\mathbf{s}_i)$とし、
$y(\mathbf{s}_i) = Y(\mathbf{s}_i) + \epsilon(\mathbf{s}_i)$
$\epsilon(\mathbf{s}_i)$は平均0, 分散$\sigma_\epsilon^2$, iidとする。
ついでに共分散関数を定義しておこう。任意の$\mathbf{s}, \mathbf{h}$について、
$C(\mathbf{s}, \mathbf{h})$
$= Cov[Y(\mathbf{s}), Y(\mathbf{s}+\mathbf{h})]$
$= E[\{Y(\mathbf{s}) - m(\mathbf{s})\}\{ Y(\mathbf{s}+\mathbf{h}) - m(\mathbf{s}+\mathbf{h}) \}$
ここで$m(\mathbf{s})$は空間過程の期待値である。
さて、空間過程が強定常であるとは、確率変数$\{Y(\mathbf{s}_1), \cdots, Y(\mathbf{s}_n)\}$によって構成される多変量分布の分布関数が、任意の移動に関して不変であるということである。
強定常性は強すぎる仮定なので緩和し、1次モーメントと2次モーメントの定常性だけを仮定することにしたい。そこでふたつのアプローチが生じる。
その1、弱定常性(二次定常性)。
任意の$\mathbf{s}, \mathbf{h}$について以下が成り立つと仮定する。
$E[Y(\mathbf{s})] = m(\mathbf{s}) = \bar{m}$
$Cov[Y(\mathbf{s}), Y(\mathbf{s}+\mathbf{h})] = C(\mathbf{h})$
$Cov[Y(\mathbf{s}), Y(\mathbf{s}+\mathbf{0})] = Var[Y(\mathbf{s})] = C(\mathbf{0})$
つまり、2地点間の共分散が$\mathbf{h}$の関数だと捉えているわけである。いいかえると、変数の一次モーメントと二次モーメントが定常だと考えている。
その2、固有定常性。
任意の$\mathbf{s}, \mathbf{h}$について以下が成り立つと仮定する。
$E[Y(\mathbf{s}+\mathbf{h}) - Y(\mathbf{s})] = \mathbf{0}$ [あれ?右辺はなぜ太字なの?]
$Var[Y(\mathbf{s}+\mathbf{h})-Y(\mathbf{s})] = 2\gamma(\mathbf{h})$
つまり、2地点の差の分散が$\mathbf{h}$の関数だと捉えているわけである。いいかえると、変数の差の一次モーメントと二次モーメントが定常だと考えている。
[ここでいつも混乱するのだが... 二次定常であれば固有定常だが、逆は成り立たない。つまり、二次定常性のほうが強い仮定である。ってことで合ってますかね?]
さて。
$C(\mathbf{h})$を二次定常共分散関数、またはコバリオグラムという。次の性質を持つ。
有界である: $|C(\mathbf{h})| \leq C(\mathbf{0})$
対称である: $C(-\mathbf{h}) = C(\mathbf{h})$
分散は非負である: $C(\mathbf{0}) \geq 0$
$2\gamma(\mathbf{h})$をバリオグラム、$\gamma(\mathbf{h})$をセミバリオグラムという。えーと、バリオグラムってのは差の分散だが、差の期待値は0だと思ってんだから、差の二乗の期待値だと言い換えてもいいわね。
次の性質を持つ。
$\gamma(\mathbf{0}) = 0$
$\gamma(\mathbf{h}) \geq 0$ [原文に誤植があると思うので勝手に直した]
$\gamma(-\mathbf{h}) = \gamma(\mathbf{h})$
固有定常性の下では、バリオグラムは有界ではないかもしれないという点に注意。
二次定常性が満たされていれば、共分散関数とバリオグラムとの間には
$\gamma(\mathbf{h}) = C(\mathbf{0}) - C(\mathbf{h})$
という関係が成り立つ。
空間予測を可能にするためには、共分散関数は非負定値性、バリオグラムは条件付き非正定値性を満たさなければならないんだけど、ややこしいので省略して...
バリオグラムの形状は、ナゲット、シル、レンジの3つで規定される。ナゲットは切片(正確に言うと、$\mathbf{h}$を$0$に近づけた時の極限値)、シルは空間過程の分散、レンジは$Y(\mathbf{s})$と$Y(\mathbf{s}+\mathbf{h})$が相関を持たなくなる最小の$\mathbf{h}$である。
具体例を挙げよう。
例1、線形バリオグラム。
$||h||=0$のとき $\gamma(\mathbf{h}) = 0$
$||h||>0$のとき $\gamma(\mathbf{h}) = \tau^2 + \sigma^2 ||\mathbf{h}||$
$\tau^2$がナゲットで、シルとレンジは無限大。
共分散関数は存在しない。このように、バリオグラム・モデルというのは文字通りバリオグラムのモデルなのであって、共分散のモデルではない。ああそうか、ここで私は混乱していた...
例2、指数型バリオグラム。
$||h||=0$のとき $\gamma(\mathbf{h}) = 0$
$||h||>0$のとき $\gamma(\mathbf{h}) = \tau^2 + \sigma^2[1-\exp(-\phi ||\mathbf{h}||)]$
$\tau^2$がナゲット。シル$\tau^2 + \sigma^2$は漸近的にしか到達できず、レンジは無限大なので、セミバリオグラムがシルの95%を達成する距離$3/\phi$のことを有効レンジと呼ぶ。
共分散関数は、
$||h||=0$のとき $C(\mathbf{h}) = \tau^2+\sigma^2$
$||h||>0$のとき $C(\mathbf{h}) = \sigma^2 \exp(-\phi^2||\mathbf{h}||^2)$
となる。
...ってな感じですね。端的にいっちゃうと、セミバリオグラム$\gamma(\mathbf{h})$は$\mathbf{h}$とともに上がっていく関数、コバリオグラム$C(\mathbf{h})$は下がっていく関数である。いまのどっちの話をしてんだか、注意せんといかん。
2018年8月12日 (日)
GLMM(一般化線形混合モデル)のRパッケージMCMCglmmというのがあるんだけど、その使い方があまりにヤヤコシイ(少なくとも私にとっては)。必要になるたびに資料をめくり、用事が終わるたびにすぐに忘れてしまう、という繰り返しで、流石にうんざりしてきたので、まとめてメモをとることにする。
参照した資料は以下の通り。
- パッケージのマニュアル。
- パッケージのビニエット。たぶん、前に読んだJSS論文と同じだと思う。
- 著者によるCourse Notes。これも昨年ひととおり目を通したのだけれど、そのときからずいぶん加筆されているような気がする。
- 著者による、2010年のチュートリアル。この資料の位置づけはよくわからない。Course Notesの旧版かと思ったのだが、ここにしか載っていない情報もあるようだ。
概念
最初に基本的な概念の説明から。
MCMCglmmでは、まず反応変数$y_i$の確率密度を
$f_i (y_i | l_i)$
とする。そういわれるとわかりにくいが、たとえばポアソン分布、ログリンクであれば、ポアソン密度関数を$f_P$として
$f_P(y_i | \exp(l_i))$
である。リンク関数で変換する前の変数$l$を潜在変数と呼ぶ。
潜在変数のベクトルを$\mathbf{l}$とする。これは個体レベルの話じゃなくて、たとえ単純なガウシアン回帰でも、100人いたら長さ100である。さらに反応変数が複数あったり、(反応変数が単一でも)潜在変数が複数あったりする場合、それを全部縦に積む。だから$\mathbf{l}$はすごく長い。
固定効果を持つ説明変数の計画行列を$\mathbf{X}$, ランダム効果を持つ説明変数の計画行列を$Z$として、線型モデル
$\mathbf{l} = \mathbf{X \beta} + \mathbf{Z u} + \mathbf{e}$
を考える。潜在変数に残差項$\mathbf{e}$が入っている点にご注目。これは測定誤差ではない。ポアソン・モデルであれば、この項でover-dispersionを説明することになる。
MCMCglmmは、係数はすべてMVNに従うと考え
$\mathbf{u} \sim N(\mathbf{0},\mathbf{G})$
$\mathbf{e} \sim N(\mathbf{0}, \mathbf{R})$
とする(これはデータ生成メカニズム)。$\mathbf{G}, \mathbf{R}$は巨大な正方行列である。なお、事前分布は逆ウィシャート分布である模様。
さらに、MCMCglmmはベイジアン・アプローチに立つので、固定効果の係数$\mathbf{\beta}$でさえ確率変数であり、
$\mathbf{\beta} \sim N(\beta_0, \mathbf{B})$
だと考える(これは事前分布)。
実行例
MCMCglmmパッケージ所収のサンプルデータBTdataには、Blue tit(アオガラ)という鳥についてのデータがはいっている。828行, 行はひなの個体を表す。変数は:
- tursus: 量的変数。ひなの体長。平均0, 分散1に標準化済み。
- back: 量的変数。ひなの色。平均0, 分散1に標準化済み。
- animal: 因子。ひなの個体ID。828水準。
- dam: 因子。母鳥の個体ID。106水準。
- fosternest: 因子。巣のID。104水準。なんでも、アオガラのひなが孵化したのち、およそ半分くらいを他の巣に移したのだそうだ。つまり巣と巣のあいだでひなを交換し、巣のなかに血縁のない子とある子が混じるようにしたらしい。かわいそうになあ。
- hatchdate: 量的変数。その巣で最初の卵が孵化した日。平均0, 分散1に標準化済み。
- sex: 因子。ひなの性別。3水準(オス、メス、不明)。
さらに、BTpedには鳥の親子関係がはいっている。1040行、行は個体を表す。変数は:
- animal: 個体ID。1040水準。
- dam: 母鳥の個体ID。106水準、欠損あり。
- sire: 父鳥の個体ID。106水準、欠損あり。
サンプルコード。わかりやすいようにすべての引数を書いてみる。
m <- MCMCglmm(
fixed = cbind(tarsus, back) ~ trait:sex + trait:hatchdate -1,
random = ~ us(trait):animal + us(trait):fosternest,
rcov = ~ us(trait):units,
family = c("gaussian", "gaussian"),
mev = NULL,
data = BTdata,
start = NULL,
prior = list(
R = list(V = diag(2)/3, n=2),
G = list(
G1 = list(V = diag(2)/3, n=2),
G2 = list(V = diag(2)/3, n=2)
),
),
tune = NULL,
pedigree = BTped,
nodes = "ALL",
scale = TRUE,
nitt = 60000,
thin = 25,
burnin = 10000,
pr = FALSE,
pl = FALSE,
verbose = TRUE,
DIC = TRUE,
singular.ok = FALSE,
saveX = TRUE,
saveZ = TRUE,
saveXL = TRUE,
slice = FALSE,
ginverse = NULL,
trunc = FALSE
)この実行例に沿って、主な引数の指定の仕方をメモしていく。
fixed引数
fixed引数で固定効果を指定する。
fixed = cbind(tarsus, back) ~ trait:sex + trait:hatchdate -1fixed引数はformulaをとる。formulaの左辺には目的変数を書く。この例のように目的変数が複数ある場合にはcbind()でつなぐ。
ややこしいのはformulaの右辺である。
上の例では目的変数が2個ある。MCMCglmmは目的変数の2 x n行列を、(値, 目的変数名, 行番号)の3列からなる2n x 3行列に展開する(reshape2パッケージでいうmelt(), dplyrパッケージでいうgather()ね)。で、目的変数名の列に trait, 行番号の列に unitsという名前を付けるのである。そうです、traitというのは予約語なのです! 勘弁してくださいな、もっと予約語っぽい名前にしてくださいよ... _TRAIT_ とかさ...。
上の例では、目的変数tarsusとbackそれぞれについて、固定効果を持つ説明変数としてsexとhatchdateを指定したい。つまり、素直に書けば
tarsus ~ sex + hatchdate
back ~ sex + hatchdate
である。もちろん係数はtarsusとbackで異なると考えたい。
tarsusとbackを縦に積んだ、長さ2 x nの反応変数ベクトル y についてモデルを組むことを考えよう。
y ~ sex + hatchdate
とすると、係数がtarsusとbackで共通になってしまう。だから、反応変数名とsexの交互作用項 trait:sexと、反応変数名とhatchdateの交互作用項 trait:hatchdate を投入して
y ~ trait:sex + trait:hatchdate
と書かないといけない... という理屈である。
最後に -1 として切片項を除外しているのは、そうしないとbackに対するパラメータ推定値がtarsusとの対比になってしまうからである。
この理屈もしばらく腑におちなかったのだが、上で得たオブジェクトm1について
View(as.matrix(m1$X))
を観察してようやく意味がわかった(Xは固定効果の計画行列だが、疎行列のdgCMatrixクラスになっているのでas.matrix()しないとわかりにくい)。計画行列は828x2行、8列になる。列の内訳は、まずsexのダミー行列、2(traitの水準数)x3(sexの水準数)=6列。そして、hatchdateの値を格納した2列である(うち828行は左列のみ、残り828行は右列のみ値を持ち、残りは0で埋めてある)。
仮に
fixed = cbind(tarsus, back) ~ trait:sex + trait:hatchdate
とすると、計画行列にはすべての行で1を持つ切片列が加わり、かわりにダミー行列の右端の一列(trait=back:sex=UNK)が削除される。そ、それはわかりにくいわ...
いまこのメモを書いていてふと気になったんだけど、仮に説明変数がhatchdateだけだったらどうするんだろう。hatchdateはダミー行列ではないので、
fixed = cbind(tarsus, back) ~ trait:hatchdate - 1,
だと切片が消えてしまう。
fixed = cbind(tarsus, back) ~ trait:hatchdate + trait - 1,
とかかな? こんど試してみよう。
random引数
いよいよ本丸である。random引数でランダム効果を指定する。はっきりいってすごくわかりにくいので、深呼吸するように。
random = ~ us(trait):animal + us(trait):fosternest random引数はformulaをとる。その書式は
random = ~ 分散関数(formula):リンク関数(ランダム項) + ...
である。おそらくは左辺はいらないのだと思う。分散関数、formula, リンク関数は省略できる。
まずは、いくつかの例からみていこう。
その1, ランダム項だけ指定する場合。
random = ~ fosternest
もし目的変数がtarsusしかなかったらこれでよい。tarsusに対するfosternestのランダム効果の分散$\sigma^2_f$を推定することになる。$\mathbf{u}$は長さ104のベクトルとなり、$\mathbf{R}$は$104 \times 104$の対角行列で、対角要素はすべて$\sigma^2_f$となる。
しかし、目的変数がふたつあるときは、これではいけない。なぜか。この指定だと、tarsusに対するfosternestのランダム効果の分散は$\sigma^2_f$だ、backに対するランダム効果の分散も$\sigma^2_f$だ、そして「tarsusに対するfosternestのランダム効果とbackに対するfosternestのランダム効果の共分散」も$\sigma^2_f$だ、と推定することになるのである。
なにそれ!わけがわからないよ!いやー、そうなる理由がぜんぜん腑に落ちない...
その2, formulaを付け加える。
random = ~ trait:fosternest
目的変数が複数あるときは、この式が基本である。
いま、$\mathbf{u}$は長さ828x2の長ーいベクトルである。ランダム項としてfosternestを指定したので、計画行列$\mathbf{Z}$は828x2行、104x2列の行列となる。$\mathbf{G}$は828x2行、828x2列の壮大な正方行列である。さて、この$\mathbf{G}$から、ある特定の巣に関わる行と列だけを取り出すと、2x2の正方行列になる。行と列はtraitである。
random = ~ trait:fosternestとは、この2x2の分散共分散行列を、非対角要素は0、対角要素は同一とします、という指定である。これ、おそらくidv(trait):fosternest の略記だと思う。
その3, 分散関数を付け加える。
random = ~ idh(trait):fosternest
とすると、分散共分散行列の対角要素だけが別々に推定される。つまり、tarsusに対するfosternestのランダム効果の分散$\sigma^2_{f:tarsus}$とbackに対するfosternestのランダム効果の分散$\sigma^2_{f:back}$の2つのパラメータが推定される。非対角要素は0。
random = ~ us(trait):fosternest
とすると、非対角要素を含めた4つが別々に推定される。
この事例では、巣が体長に与える効果と体色に与える効果のあいだに共分散があると考えているので、~ us(trait): fosternest となっているわけだ。
さて、書式の詳細について。
分散関数には以下がある。
- idv: formulaのすべての要素を通じて分散を一定とする。
- idh: formulaの要素ごとに分散を推定する。
- us: formulaの要素ごとに分散を推定し、さらに共分散も推定する。
- corg: 共分散行列の対角要素を1にする。
- cogh: 共分散行列の対角要素を事前分布で指定した値に固定する。
- cors: 相関下位行列を許容する。(意味がわからない)
- ante1, ante2, ...: 1次, 2次...のante-dependence 構造。次数の前にcをつけると(例, antec2)、次数の間で回帰係数が同じになり、次数の後にvをつけると(antec2v)、イノベーション分散がすべて等しくなる。 (ここも意味がわからない)
formulaは、上の例ではtraitになっているが、量的変数を指定しても良い。たとえば
random = ~ us(1+age):individual
とすると、切片とageのスロープがindividualごとにランダムに決まることになる。
random = ~ us(1+poly(age,2)):individual
もアリである。うーむ、ややこしい。説明の流れのせいでわかりにくくなっているが、formulaでは「ある個体における計画行列」を指定し、ランダム項には個体を表す変数を指定する、という理屈であろう。
リンク関数には次の2種類がある。いずれも、複数のランダム項を+でつないで記述する。
- mm: マルチメンバーシップモデルとなる。
- str: ランダム効果のあいだの共分散が推定される。
なお、上の例でus(trait):animalというのをいれているのは、pedigree引数を指定しているからなのだそうである。ここはよくわからない。
rcov引数
rcov引数で$\mathbf{R}$を指定する。
rcov = ~ us(trait):units 書式はrandom引数と同じだが、項はひとつしかとれない。
おそらく、多変量なら ~ us(traits):units とするのが基本であろう。単変量なら ~ units かな?
family引数
family引数で分布を指定する。
family = c("gaussian", "gaussian")family引数は、反応変数の数だけの文字列ベクトルをとる。指定できる分布はは以下の通り。
- gaussian
- poisson. ログリンクとなる。
- categorical. カテゴリ1が参照水準になり、(水準数-1)列の潜在変数ができる。
- multinomialJ. Jはカテゴリ数。つまり、たとえばmultinomial3だったら反応変数は3列必要。カテゴリJが参照水準になり、2列の潜在変数ができる。
- ordinal.
- threshold. これはなんだかよくわからない。マニュアルには記載があるがビニエットにはない。
- exponential.
- geometric.
- 先頭にcenをつけるとcensored変数のモデルになる。cengaussian, cenpoisson, cenexponentialがある。
- 先頭にziをつけるとゼロ過剰変数のモデルになる。zipoisson, zibinomialがある。
- ztpoisson(zero-trancated poisson), hupoisson(hurdle poisson), zapoisson(zero altered poisson).
mev引数
各データ点における測定誤差分散を表すベクトルを指定できるらしい。
この引数はメタ分析の際に使うことを想定しているらしいのだが... まてよ、これを使えば小地域推定のFay-Harriotモデルを推定できるのではなかろうか。
prior引数 もうひとつの山場、事前分布の指定である。
prior = list(
R = list(V = diag(2)/3, n=2),
G = list(
G1 = list(V = diag(2)/3, n=2),
G2 = list(V = diag(2)/3, n=2)
),
)prior引数はリストをとる。リストには3つの要素をいれることができる。
- B. リストをとる。そのリストには、要素muとVをいれる。それぞれ$\mathbf{\beta_0}$, $\mathbf{B}$を意味する。デフォルトでは、mu=0, V=I*1e+10である(Iは単位行列)。
- R. $\mathbf{R}$の指定である。リストをとる。その書式は後述する。
- G: $\mathbf{G}$の指定である。リストをとる。その各要素はランダム項に対応する。上の例ではG1, G2と名前を付けているが、そうしないといけないのかどうかはよくわからない。各要素はリストをとる。その書式は後述する。
さて、上述のR、ならびにGの各要素は、以下の要素を持つリストである。
- V: 期待される共分散行列。
- nu: 逆ウィシャート分布の自由度。
- alpha.mu, alpha.V: 正直、これは意味が良く理解できない。通常は指定しないのだそうである。
- fix: 指定しないと分散パラメータを推定する。1にすると固定。ほかに、1でない整数を指定して、分散共分散行列の一部を推定するように指示できるらしいのだが、この機能も良く理解できていない。
わかりにくいので例に基づいて考えよう。
上の例では、R, G1, G2のいずれについても、Vは2x2の対角行列(対角要素は1/3)、nは2としている。Rに注目しよう。rcov引数により、体長の潜在変数における残差項の分散$\sigma^2_{e:tarsus}$、体色の潜在変数の残差項の分散$\sigma^2_{e:back}$, 体長の潜在変数における残差項と体色の潜在変数における残差項との共分散$\sigma_{e:tarsus,back}$の3つを推定することになっている。しかしここでは、Rの持つVは対角行列で、対角要素は1/3である。つまり、$\sigma_{e:tarsus,back}$の事前分布の期待値は0だと指定していることになる。
対角要素を1/3としているのは、この事例では反応変数がすでに標準化されていて分散1であり、それを3つの要素に均等に分けている、という意味合いである。
ところで、prior引数の要素R、ならびに要素Gの各要素は、デフォルトではlist(V=1, nu=0)なのだそうである。うーん、よくわからん。
- 仮に潜在変数がk個あったら、Vはk x k の正方行列でないといけないと思うんだけど、そのときMCMCglmmはV=1をV=diag(k)と解してくれるのか? それとも「正しい事前分布を指定しろ」とエラーを吐くのか? これは試してみればわかることだけど。
- k x kの共分散行列の事前分布を逆ウィシャート行列$IW(\Lambda, \nu)$で表現する場合、ふつうは$\Lambda = \mathbf{I}, \ \ \nu = k+1$とするんじゃないかと思うわけです。こうすると、得られる相関の周辺分布が一様になるのだと聞いたことがある。しかるに、MCMCglmmのデフォルトでは、$\nu$ をやたらに小さくするわけだ。なぜこうしているんだろう?
starts引数
初期値の指定。リストをとる。次の4つの要素をいれることができる。
- R: $\mathbf{R}$の初期値。行列をとるのかな?
- G: $\mathbf{G}$の初期値。リストをとる。その要素数はランダム効果の要素数と一致させる。要素はどうするんだろう... 行列のとるのかな?
- liab: 潜在変数の初期値。liabというのはliabilitiesの略らしい。意味がわからないが、きっとこのパッケージ開発者の研究分野では筋の通った命名なのだろう。なにをとるのかよくわからない(ベクトル?)。
- QUASI: 論理値をとる。TRUEだと潜在変数の初期値がheuristicallyに決められ、FALSEだとZ分布からサンプリングされるのだそうである。
... と、この辺で力尽きたので、メモはここまでにしておく。さらに難解なpedigree引数、ginverse引数には、残念ながら踏み込めなかった。またの機会に。
いやー、自分の能力を棚に上げていうけど、なんてわかりにくいんだろう。SASのproc mixedのほうがはるかにわかりやすい。参ったなあ。
覚え書き:RのMCMCglmmパッケージの使用方法の難解さを目の前にして途方に暮れるの巻
2018年7月29日 (日)
仕事の関連でお問い合わせ頂いて、いちおうお返事はしたんだけど、その途中で、よくよく考えてみたらこれって不思議だなあ、ということがでてきた。
層別抽出標本から母分散を推定するという問題について考える。標本推定量の分散の推定じゃなくて母分散そのものの推定である。こういう話、本にはなかなか載ってない。そりゃそうかもな、そんな用事はあんまりないような気もする。
層$h (=1,\ldots, H)$の$i(=1,\ldots,n_h)$個目の値を$x_{hi}$とし、層が母集団に占める割合を$P_h$とする。すべての層を通じた標本サイズを$n = \sum_h^H n_h$とする。
層ごとの平均は $\bar{x}_h = (1/n_h) \sum_{i}^{n_h} x_{hi}$
全体平均は $\bar{x}_{Total} = \sum_h^H P_h \bar{x}_h$
層ごとの分散は $S^2_h = (1/n_h) \sum{i}^{n_h} (x_{hi}-\bar{x}_h)^2$
層内分散は $S^2_{Within} = \sum_h^H P_h S^2_h$
層間分散は $S^2_{Between} = \sum_h^H P_h (\bar{x}_h - \bar{x}_{Total})^2$
全分散は層内分散と層間分散の和だから、$S^2_{Total} = S^2_{Within} + S^2_{Between}$が答えだ。と思いません??
例を挙げて計算してみよう。層1の値が$(1,2,3)$, 層2の値が$(1,2,3,4,5,6,7)$、どちらの層も母集団に占める割合は$1/2$とする。
層ごとの平均は$\bar{x}_1 = 2, \bar{x}_2 = 4$
全体平均は$\bar{x}_{Total} = 3$
層ごとの分散は $S^2_1 = 0.667, S^2_2 = 4$
層内分散は $S^2_{Within} = 2.333$
層間分散は $S^2_{Between} = 1$
全分散は $S^2_{Total} = S^2_{Within} + S^2_{Between} = 3.333$
となる。なりますよね?
とここまで考えて、あれれ?おかしいな?と気が付いた次第である。
だって、母分散を推定したいわけでしょ? 不偏推定したいでしょ? だったら、層ごとの分散の分母は$n_h$じゃなくて$n_h-1$じゃない?つまり、層ごとの分散は
$U^2_h = (1/(n_h-1)) \sum_i^{n_h} (x_{hi}-\bar{x}_h)^2$
じゃない?
こうして求める全分散を$U^2_{Total,1}$と呼ぼう。実例で計算し直すと
層ごとの分散は $U^2_1 = 1, U^2_2 = 4.667$
層内分散は $U^2_{Within} = 2.833$
全分散は $U^{2}_{Total,1} = U^2_{Within} + S^2_{Between} = 3.833$
となる。
とここまで考えて、さらに、あれれ?さらにおかしいな?と気がついたわけである。
層ごとの分散$S^2_h$を標本分散から不偏分散に代えたのに、層間の分散$S^2_{Between}$はそのままでよろしいわけ?
散々探してついに見つけたのだが、よろしくないらしい。Wakimoto(1971)によれば、母分散の不偏推定量は
$U^2_{Total} = U^2_{Within} + S^2_{Between} - \sum_h^H P_h(1-P_h) U^2_h/n_h$
なのだそうである(p.235, 記号は原文から書き換えました)。$S^2_{Between}$はちょっと大きめになってしまうので第3項を引く、っていうことなんじゃないかと思う。
これを$U^2_{Total,2}$と呼ぼう。実例で計算し直すと、
層間分散は $U^2_{Between} = 1 - 0.25 = 0.75$
全分散は $U^2_{Total,2} = U^2_{Within} + U^2_{Between} = 3.583$
となる。
ところで... 四の五の言わずに、上記の$S^2_{Total}$を$n/(n-1)$倍すればいい、という考え方もあるかもしれない。
この考え方は次のように言い換えることもできる。母分散ってのは値と母平均との差の二乗の母平均のことであり、不偏分散ってのは値と標本平均の差の二乗の合計を(標本サイズ-1)で割った値のことだ。だから、まず全体平均$\bar{x}_{Total}$を求め(もちろん単純な平均ではなく、層ごとの平均を$P_h$で重みづけて合計する)、次に標本のそれぞれの値から$z_{hi} = (x_{hi} - \bar{x}_{Total})^2$を求め、その合計を求め(各層の合計を$P_h$で重みづけて合計する)、最後に$n-1$で割ればよい。
あるいは、こういう風に考えることもできる。複雑な抽出デザインのデータを分析する際によく行われているように、それぞれの値に確率ウェイトを付与しよう。層別抽出の場合、確率ウェイトとは、各層における標本抽出確率(母集団のある層に属しているある個体が、標本として選ばれる確率)の逆数に比例した値である。このデータの場合、層1では5/3=1.667, 層2では5/7=0.714を与えればよい。さて、このデータが層別抽出であることを無視し、データ$x_1, \ldots, x_n$にウェイト$w_1, \ldots, w_n$が付与されているのだと考える。このウェイトを頻度ウェイト、すなわち「標本におけるその行の出現頻度」として捉えてしまい、不偏分散
$\sum_i^n w_i (x_i - \bar{x}_{Total})^2 / (\sum_i^n w_i - 1)$
をしれっと求める。
これを$U^2_{Total, 3}$と呼ぼう。実例で計算すると、
全分散は $U^2_{Total, 3} = S^2_{Total} * n / (n-1) = 3.333 * 10 / 9 = 3.704$
では統計ソフトでやってみよう。Mplus, SAS, Rで試す。
Mplusの場合、次のようなコードで試してみたところ
DATA:
FILE IS data.dat;
VARIABLE:
NAMES ARE X nStrata gWeight;
WEIGHT = gWeight;
STRATIFICATION = nStrata;
ANALYSIS:
TYPE = COMPLEX; 分散は3.333と推定された。すなわち$S^2_{Total}$である。
これはまあ、わかる。標本分散は母分散の不偏推定量ではないが、正規分布に従う変数については、母分散の最尤推定量である。MplusはXの正規性を仮定し、最尤推定値を返しているわけだ。これはMplusのポリシーなので、そうですか、としかいいようがない。
SASの場合、層別抽出で得た平均の分散を求めることは簡単なんだけど(PROC SURVEYMEANS)、母分散はすぐには推定できそうにない。散々探した末、ようやくSAS社による解説を発見した。
サンプルコードを書き換えたコードがこちら。SAS University Editionで試しました。
dm log 'log; clear' ; dm output 'output; clear';
data ttt;
input strata value;
datalines;
1 1
1 2
1 3
2 1
2 2
2 3
2 4
2 5
2 6
2 7
;
run;
data ttt;
set ttt;
if strata = 1 then weight = 5/3;
if strata = 2 then weight = 5/7;
run;
proc surveymeans data = ttt mean stacking ;
stratum strata ;
var value;
weight weight;
ods output Statistics = Statistics Summary = Summary;
run;
data _null_;
set Statistics;
call symput("Mean", Value_Mean);
run;
data Summary;
set Summary;
if Label1="重みの合計" then call symput("N",cValue1);
run;
%put _user_;
data Working;
set ttt;
z=(1/(&N-1))*(value-&Mean)**2;
run;
proc surveymeans data = Working sum stacking;
weight weight;
var z;
run;
結果は3.704、つまり$U^2_{Total, 3}$である。あっれえええ?
コードを読むとわかるのだが、ここでやっているのは、「$z_{hi} = (x_{hi} - \bar{x}_{Total})^2$の合計を$n-1$で割る」という、まさに$U^2_{Total, 3}$の考え方に従った処理なのである。
Rの場合、複雑な抽出デザインの分析はsurveyパッケージが定番である。母分散を推定する関数はsvrvar()である。次のコードで試してみたところ
dfData <- data.frame(
X = c(1,2,3,1,2,3,4,5,6,7),
nStrata = c(rep(1, 3), rep(2, 7)),
gWeight = c(rep(5/3, 3), rep(5/7, 7))
)
oDesign <- svydesign(
ids = ~ 0,
strata = ~nStrata,
weight = ~gWeight,
data = dfData
)
print(svyvar(~ X , data=dfData, design=oDesign, estimate.only =TRUE)) 分散は3.704と推定された。あっれえええ?
svyvar()のコードをちょっと眺めてみたんだけど、やはり$U^2_{Total, 3}$のような処理をやっている模様である。
というわけで、SAS社のお勧めの方法でも、Rのsurvey::svyvar()でも、母分散の推定量は$U^2_{Total, 3}$となっていることがわかった。
私、正直、納得いかないです... 正しい推定量は$U^2_{Total, 2} $なのではなかろうか?
毒を喰らわば皿まで、ということで、シミュレーションしてみた。
層は2つとする。変数$X$は、層1においては$N(0,1)$に、層2においては$N(2,1)$に従うとする。層内分散は$1$、層間分散は$1$、よって母分散は$2$である。
ここからサイズ100の標本を層別抽出し、母分散を推定する。標本における層1のサイズは(10,20,30,40,50)の5水準とし、各水準につき50000回繰り返した。
50000個の母分散推定値の平均から2を引いた値をBiasと呼ぶことにする。これが0に近い推定量が、(不偏性という意味で)良い推定量である。
推定量は、上記の$S^2_{Total}, U^2_{Total,1}, U^2_{Total,2}, U^2_{Total,3}$の4種類。順にEst0, Est1, Est2, Est3と呼ぶことにする。SAS社の解説やRのsurveyパッケージの出力はEst3である。私が申し上げたいのは、Est2を出力してくれたらいいのになあ、Est3にはバイアスがあるのになあ、ということであります。
コードと結果はこちら。
library(MASS)
library(dplyr)
library(tidyr)
library(ggplot2)
# - - - - - -
nTOTALSIZE <- 100
anSIZE1 <- seq(10,50,10)
nNUMITER <- 50000
agMU <- c(0, 2)
agSIGMASQ <- c(1, 1)
agPROP <- c(1/2, 1/2)
# - - - - - -
set.seed(123)
sub_EstimateVar <- function(dfIn){
anSize <- tapply(dfIn$X, dfIn$nStrata, length)
agMean <- tapply(dfIn$X, dfIn$nStrata, mean)
agUnbiasedVar <- tapply(dfIn$X, dfIn$nStrata, var)
agSampleVar <- agUnbiasedVar * (anSize - 1) / anSize
agProp <- tapply(dfIn$gWeight, dfIn$nStrata, sum) / sum(dfIn$gWeight)
gTotalMean <- sum(agProp * agMean)
agBetweenVar <- sum(agProp * (agMean - gTotalMean)^2)
gEst0 <- sum(agProp * agSampleVar) +agBetweenVar
gEst1 <- sum(agProp * agUnbiasedVar) +agBetweenVar
gEst2 <- sum(agProp * agUnbiasedVar) + agBetweenVar - sum(agProp * (1-agProp) * agUnbiasedVar / anSize)
gEst3 <- gEst0 * sum(anSize) / (sum(anSize) -1)
out <- data.frame(
gEst0 = gEst0,
gEst1 = gEst1,
gEst2 = gEst2,
gEst3 = gEst3
)
}
# dfData <- data.frame(
# X = c(1,2,3,1,2,3,4,5,6,7),
# nStrata = c(rep(1, 3), rep(2, 7)),
# gWeight = c(rep(5/3, 3), rep(5/7, 7))
# )
# print(sub_EstimateVar(dfData))
lOut <- lapply(
anSIZE1,
function(nSize1){
lOut <- lapply(
1:nNUMITER,
function(nIter){
nSize2 = nTOTALSIZE - nSize1
data.frame(
nSize1 = nSize1,
nIter = nIter,
X = c(
rnorm(nSize1, agMU[1], agSIGMASQ[1]),
rnorm(nSize2, agMU[2], agSIGMASQ[2])
),
nStrata = c(rep(1, nSize1), rep(2, nSize2)),
gWeight = c(
rep(agPROP[1]/(nSize1/nTOTALSIZE), nSize1),
rep(agPROP[2]/(nSize2/nTOTALSIZE), nSize2)
)
)
}
)
bind_rows(lOut)
}
)
dfIn <- bind_rows(lOut)
out <- dfIn %>%
group_by(nSize1, nIter) %>%
dplyr::do(sub_EstimateVar(.)) %>%
ungroup() %>%
group_by(nSize1) %>%
summarize(
Bias_Est0 = mean(gEst0) - 2,
Bias_Est1 = mean(gEst1) - 2,
Bias_Est2 = mean(gEst2) - 2,
Bias_Est3 = mean(gEst3) - 2,
RMSE_Est0 = sqrt(mean((gEst0 - 2)^2)),
RMSE_Est1 = sqrt(mean((gEst1 - 2)^2)),
RMSE_Est2 = sqrt(mean((gEst2 - 2)^2)),
RMSE_Est3 = sqrt(mean((gEst3 - 2)^2))
) %>%
ungroup()
dfPlot <- out %>%
gather(sVar, gValue, -nSize1) %>%
separate(sVar, c("sVar1", "sVar2")) %>%
filter(sVar1 == "Bias")
g <- ggplot(data=dfPlot, aes(x = nSize1, y = gValue, group=sVar2, color=sVar2))
g <- g + geom_path(size=1)
# g <- g + facet_grid(. ~ sVar1)
g <- g + geom_abline(slope=0, intercept=0)
g <- g + labs(x = "size of strata1", y = "Bias")
g <- g + scale_color_discrete(name = "")
g <- g + theme_bw()
print(g)
...ほらね?
2018/07/31: SASのコード、Rによるシミュレーションをつけ加えました。
覚え書き:層別抽出標本から母分散を推定する方法(シミュレーションつき)
変数$X, Y$の共分散は、ご存じのように「ある人のXから平均を引き、Yから平均を引き、このふたつを掛けた値の平均」、つまり
$cov(X, Y) = (1/N) \sum_i^N (x_i - \bar{x})(y_i - \bar{y})$
である。これは「ある人のXとYを掛けて平均し、Xの平均とYの平均の積を引いた値」すなわち
$cov(X, Y) = (1/N) \sum_i^N x_i y_i - \bar{x} \bar{y}$
とも書き換えられますわね。さすがにここまでは学生時代に習った気がする。
さて、この中身をさらに$N$倍しますやんか?
$cov(X, Y) = \ (1/N^2) \left( N\sum_i^N (x_i y_i) - \sum_i^N x_i \sum_i^N y_i \right)$
大かっこの中身に注目。
第1項の$N\sum_i^N (x_i y_i)$とはなにか。たとえば$N=3$ならば、これは
$3 (x_1 y_1 + x_2 y_2 + x_3 y_3)$
$= (x_1 y_1 + x_2 y_2 + x_3 y_3) + (x_1 y_1 + x_2 y_2) + (x_1 y_1 + x_3 y_3) + (x_2 y_2 + x_3 x_3)$
と書き直せる。つまり、まずすべての$x_i y_i$を並べ、次に$i$と$j (\geq i)$について$(x_i y_i + x_j y_j)$を並べる形に書き直せる。なぜこんなことをしているのか? 我慢して先に進みましょう。
第2項の$\sum_i^N x_i \sum_i^N y_i$とはなにか。$N=3$ならば
$(x_1 + x_2 + x_3)(y_1 + y_2 + y_3)$
$= (x_1 y_1 + x_2 y_2 + x_3 y_3) + (x_1 y_2 + x_2 y_1) + (x_1 y_3 + x_3 y_1) + (x_2 y_3 + x_3 y_2)$
と書き直せる。つまり、まずすべての$x_i y_i$を並べ、次に$i$と$j (\geq i)$について$(x_i y_j + x_j y_i)$を並べる形に書き直せる。
第1項から第2項を引くと何が起きるか。最初の$(x_1 y_1 + x_2 y_2 + x_3 y_3)$は消える。そこから先は
$(x_1 y_1 + x_2 y_2) - (x_1 y_2 + x_2 y_1) $
$+ (x_1 y_1 + x_3 y_3) - (x_1 y_3 + x_3 y_1) $
$+ (x_2 y_2 + x_3 y_3) - (x_2 y_3 + x_3 y_2) $
おおお、なんということでしょう。上の3行のいずれも、$(x_i -x_j)(y_i - y_j)$ではありませんか。
というわけで、
$cov(X, Y) = \ (1/N^2) \sum_{i=1}^N \sum_{j=i+1}^N (x_i - x_j)(y_i - y_j)$
つまり、共分散とは「異なる2人を連れてきて、$X$の差と$Y$の差の積を求め、これを全ペアを通じて合計し、人数の二乗で割ったもの」でもあるのだ。
...こういう話を前にどこかで読んだことがあったんだけど、フーン面白いね、と聞き流していた。このたび仕事の都合で調べものをしていて、最初から分散を(偏差じゃなくて)ペアの差で定義している文献があって、困ってしまった次第である。深夜から早朝に掛けての数時間を費やした検索と苦悩の末、なんとか理解が追い付いたので、自分のためにメモしておく。
参考文献は
Zhang, Wu, Cheng (2012) Some New Deformation Formulas about Variance and Covariance. Proc. 4th Int. Conf. Modelling, Identification and Control, 1042-1047
なのだが、これはたまたまみつけただけで(Wikipediaに載っていた...)、おそらくどこかの統計学の教科書に書いてあるような話なのだろう。
なにしろきちんとした教育を受けていないもので、これがどのくらいのレベルの話なのか、よくわからない。実は、理系の学生さんならみんな知ってる話だったりしてね! はっはっは! そういうの困っちゃうよね!
2018年7月10日 (火)
これは徹頭徹尾自分向けのメモでございます。
仕事の都合で空間計量経済学の資料をあたっていると、XXXモデルという英字三文字の略語が乱舞し、しかもその意味が人によってかなりちがっていたりする。
許すまじ学者ども、とっつかまえて海の藻屑にしてやろうか、と腹を立てていたのだが、怒っていてもらちがあかないので、メモをとってみた。とりあえず、いま手元にある3冊のデータ解析者向け解説書の記述を比較しておく。
瀬谷・堤(2014)「空間統計学」
6.1, 6.2.1, 6.2.2よりメモ。
いわく。格子データのモデリングは大きく次の2つに分類できる。
- マルコフ確率場・条件分布に基づく方法。Besag(1974)が代表的。conditional autoregressive model(CAR)を使うことが多い。階層ベイズモデルの枠組みで便利。しかし、空間重み行列が対称であることが求められるので、空間計量経済学ではあまり用いられない。
- 非マルコフ確率場・同時分布に基づく方法。Anselin(1988)が代表的。smimultaneous autoregressive model (SAR)を用いることが多い。
というわけで、以下では後者について解説する。
空間計量経済学においては、空間自己相関をモデル化する際、次の2つのモデルがよく用いられる。
1. 空間ラグモデル(spatial lag model, SLM)。mixed regressive spatial autoregressive model, spatial autoregressive model(SAR)と呼ばれることもある。
SLMでは従属変数間に自己相関を導入する。空間的・社会的な相互作用の結果として生じた「均衡」のモデル化だといえる。一般的な形式としては
$y_i = g(y_{j \in S_i}) + \beta_0 + \sum_h x_{hi} \beta_h + e_i$
ふつうは空間重み行列を使って単純化する。
$y_i = \rho \sum_j^n w_{ij} y_j + \beta_0 + \sum x_{hi} \beta_h+ e_i$
右辺に$y$の空間ラグがあるという意味では時系列でいう自己回帰と似ている。
行列で書くと
$\mathbf{y} = \rho \mathbf{W} \mathbf{y} + \mathbf{X} \mathbf{\beta} + \mathbf{e}$
2. 空間誤差モデル(spatial error model, SEM)。これがsimultaneous autoregressive model(SAR)と呼ばれていることもある。
SEMでは誤差項間に自己相関を導入する。経済理論的な理由というより、空間的に系統性のある観測誤差といったデータの問題を処理するために用いられることが多い。
誤差項のモデル化の方法にはたくさんある。4つ紹介するが、いちばん良く用いられているのは2-1.SAR誤差である。
2-1. SAR誤差(spatial autoregressive)。これを狭義のSEMと呼ぶこともある。
$\mathbf{y} = \mathbf{X} \mathbf{\beta} + \mathbf{u}, \ \ \mathbf{u} = \lambda \mathbf{W} \mathbf{u} + \mathbf{e}$
$\mathbf{u}$の共分散行列は
$E[\mathbf{uu}'] = \sigma_e^2(\mathbf{I}-\lambda \mathbf{W})^{-1} (\mathbf{I}-\lambda \mathbf{W'})^{-1}$
となる。ここで$(\mathbf{I}-\lambda \mathbf{W})^{-1}$を空間乗数という。$\mathbf{I}-\lambda \mathbf{W}$が正則であることが求められる。
SAR誤差モデルの場合、ある地点のショックが他のすべての地点に波及する。また、地点の近傍集合の個数が地点によって違うとき、たとえ$e$がiidであっても$\mathbf{u}$の分散は不均一になる。
2-2. SMA誤差(spatial moving average)。
$\mathbf{u} = \gamma \mathbf{W} \mathbf{e} + \mathbf{e}$
$\mathbf{u}$の共分散行列は
$E[\mathbf{uu}'] = \sigma_e^2(\mathbf{I}+\gamma \mathbf{W})(\mathbf{I}+\gamma \mathbf{W})'$
ある地点におけるショックは、$\mathbf{W}$を通した1次の影響と, $\mathbf{WW}'$を通した2次の影響しかもたない。なお、SAR誤差と同じく、地点の近傍集合の個数が地点によってちがうと共分散は定常でなくなる。
2-3. SEC誤差(spatial error component)。
$\mathbf{u} = \mathbf{W} \mathbf{\phi} + \mathbf{e}$
誤差をスピルオーバーする部分$\mathbf{\phi}$としない部分$\mathbf{e}$に分けている。$\mathbf{\phi}$と$\mathbf{e}$の各要素はiidで、2本のベクトル間に相関はないと考える。
$\mathbf{u}$の共分散行列は
$E[\mathbf{uu}'] = \sigma_\phi^2 \mathbf{WW}' + \sigma_e^2 \mathbf{I}$
SEC誤差はもともとSAR誤差の代替案として提案されたものであった。$(\mathbf{I}-\lambda \mathbf{W})$は正則でなくてもよい。しかし共分散行列をみると、局所的相関しか考慮していないわけで、むしろSMA誤差に近い。
2-4. CAR誤差(conditonal autoregressive)。
これはSAR誤差との対比で紹介されることが多い。SAR誤差では$\mathbf{u}$の同時分布をモデル化したが、ここでは近隣集合の下での条件付き分布をモデル化する。
$E(u_i | u_j, j \neq i) = \eta \sum_j w_{ij} u_j$
$\mathbf{W}$にいくつか制約をつけると、
$E[\mathbf{uu}'] = \sigma^2 (\mathbf{I} - \eta \mathbf{W})^{-1}$
となる。
[話がすごくややこしいが、2.の空間誤差モデルの一部ではあるものの、2-1,2-2,2-3のような同時自己回帰モデルではないわけだ]
3. SLM(空間ラグモデル)とSEM(空間誤差モデル)の複合型もある。
3-1. 一般化空間モデル(SACモデル)。
[別の資料によれば、SACとはgeneral spatial autoregressive model with a correlated error termの略である由。] SARARモデルともいう(spatial autoregressive model with spatial autoregressive disturbances)。
$\mathbf{y} = \rho \mathbf{W} \mathbf{y} + \mathbf{X} \mathbf{\beta} + \mathbf{u}, \ \ \mathbf{u} = \lambda \mathbf{W} \mathbf{u} + \mathbf{e}$
空間ラグモデルと空間誤差モデル(SAR誤差)をあわせたものになっている。
3-2. 空間ダービンモデル(spatial Durbin model, SDM)。
$x$は定数項抜きとして、
$\mathbf{y} = \rho \mathbf{W} \mathbf{y} + \mathbf{X} \mathbf{\beta} + \mathbf{W x \delta} + \mathbf{e}$
SACモデルから$\mathbf{W u}$を落として、かわりに従属変数と説明変数の空間ラグをいれているわけだ。実はこのモデル、SAR誤差モデルから導くことができる。
古谷(2011)「Rによる空間データの統計分析」
上記のメモとの対応は以下の通り。
- 10.4.1 同時自己回帰(SAR)モデル... 誤差の自己相関パラメータが空間重みづけ行列で決まるのであれば、同書10.5.2と同一。すなわち 2-1. SAR誤差モデル。
- 10.4.2 条件付き自己回帰(CAR)モデル... 2-4. CAR誤差モデル。
- 10.5.1 空間的自己回帰モデル(空間同時自己回帰モデル, spatial auto-regression model) ... 1. 空間ラグモデル。
- 10.5.2 誤差項の空間的自己回帰モデル(空間誤差モデル, SEM, spatial error model) ... 2-1. SAR誤差モデル。
- 10.5.3 空間ダービンモデル ... 3-2.空間ダービンモデル。
谷村(2010)「地理空間データ分析」
上記のメモとの対応は以下の通り。
- 5.1.2 空間ARモデル ... 1.空間ラグモデルの、共変量がないやつ。
- 5.1.3 空間同時自己回帰モデル ... 1.空間ラグモデル。
- 5.1.4 空間誤差モデル(spatial error model, SEM) ... 2-1.SAR誤差モデル。
- 5.1.5 空間Durbinモデル(spatial Durbin model, SDM) ... 3-2.空間ダービンモデル。
- 5.1.6 条件付き自己回帰モデル(conditional autoregressive model, CAR model) ... 2-4.CAR誤差モデル。
覚え書き: 空間計量経済学における忌まわしき英字三文字略語たち
2018年6月20日 (水)
仕事の都合で小地域推定 (SAE) の勉強をしているんだけど、Rのパッケージが多すぎて困っている。別に使い分けたいわけじゃないんだけど、「もっといいパッケージがあるのでは...」という疑念が頭からは離れないのである。精神衛生に悪い。
現時点でのパッケージを調べてみたので、メモしておく。
CRAN Task ViewsにOfficial Statisticsというのがあり、そこのSAEの項目には、SAEに特化したパッケージとして次の3つが挙げられている。
- rsaeパッケージ。Task Viewsによれば、「基本的なユニット・レベルSAEモデル(nested error回帰モデル)のパラメータをMLないしロバストMLにより推定。MSE推定値、パラメトリック・ブートストラップなどによる、地域ごとの平均のロバストな予測を提供する。カテゴリカル独立変数は扱えない」とのこと。最終更新は2014/02。
- hbsaeパッケージ。「基本地域ないしユニット・レベルモデルに基づくSAEを計算。制約付きML法、階層ベイズ法を用いる。補足情報として、カテゴリカル変数から得られるカウント、ならびに連続的人口情報から得られる平均を使うことができる」。最終更新は2012/09。
- JoSAEパッケージ。「GREGによる点推定・分散推定、ユニットレベルのEBLUP推定量をドメインレベルで提供」とかなんとか(云ってる意味がよくわからん)。これは基本的には後述するnlmeパッケージのラッパーである由。最終更新は2018/05。
Task Viewsに載っていないパッケージとして、見つけたのは以下。といっても、googleで検索しただけだけど。
- saeパッケージ。SAEについての教科書 Rao & Molina (2015) で紹介されているのがこれである。開発者による解説もある(いま気が付いたけど、開発者のひとりがMolinaさんなのだ)。最終更新2018/06(おお、先週だ...)。
- saeRobustパッケージ。説明によれば、「通常使われているSAEモデルのロバストな代替手法を提供。BLUP予測と線形混合モデルに基づく。ランダム効果に時空間的相関があるエリアレベルモデルが利用可能」とのこと。最終更新2018/03。
- maSAEパッケージ。「MandallazのモデルによるSAE」という謎のパッケージである。Mandallazという人の論文を読まんといかんらしい。最終更新2016/08。
- BayesSAEパッケージ。ベイズなんでしょうね。最終更新2018/04。
- saeryパッケージ。時間効果のはいった地域レベルのEBLUP。最終更新2014/09。
- sae2パッケージ。時系列地域レベルモデル。最終更新2015/01。
- emdiパッケージというのもある。「地域非累積指標の推定・評価・マッピング」とのことで、よくわかんないんだけどこれもSAEのパッケージなのではなかろうか。最終更新2018/04。
- saeSimパッケージ。saeRobustと同じ人が開発している。これは推定のパッケージというよりシミュレーションの面倒をみるパッケージらしい。Task ViewsにもMicrosimulationのパッケージとして載っている。
- ほかにmmeパッケージというのがあったんだけど、先月CRANから消えた模様。
なお、SAEに特化したパッケージではなく、一般的な混合モデル・階層モデルのパッケージを使うという手もあろう。Task ViewsにはSAEの項目の下に、nlmeパッケージとlme4パッケージがあがっているが、別に他のパッケージでもいいのではなかろうか。久保先生のページでは、正規分布の混合モデルのパッケージとしてnlme, lme4が挙げられているほか、一般化混合モデルのパッケージとしてglmmML, MCMCglmmがお勧めされている。
2018年5月14日 (月)
仕事の都合で不意に対応分析を使ったりすると、いつも途中で混乱しちゃうので、思い余ってメモをとった。
でもあれなんだよな、メモを取れば覚えるかというと、これがそうでもないんだよな... 思えば、こういうのはじめて勉強したのは20代前半であった。それから時代は流れ、幕府は倒れ、江戸は東京となり、日本は急速な近代化を遂げたが(←ちょっと記憶が混乱してます)、私は全然進歩してないような気がする。
以下、Greenacre(1984) "Theory and Applications of Correspondence Analysis", Chap.4 の前半のメモ。この本だと、固有値分解ではなくて一般化SVDでスーッと説明しちゃうのである。
準備
$I \times J$行列を$\mathbf{N}=\{n_{ij}\}$とする。値は非負、行和と列和は非ゼロとする。そうでなくてもかまわないけれど、$\mathbf{N}$は二元クロス表だと考えるとわかりやすい。
$\mathbf{N}$で総和で割って$\mathbf{P}=\{p_{ij}\}$とし、これを「対応行列」と呼ぶ。$\mathbf{P}$の行和ベクトルと列和ベクトルをそれぞれ$\mathbf{r}=\{r_{i}\}, \mathbf{c}=\{c_{j}\}$とし、これを持たせた対角行列を$\mathbf{D}_r, \mathbf{D}_c$とする。
行プロファイルと列プロファイル
$\mathbf{P}$のある行$\mathbf{r}_i$をその行の和で割ったもの$\tilde{\mathbf{r}}_i$を「行プロファイル」、ある列$\mathbf{c}_j$をその列の和で割ったもの$\tilde{\mathbf{c}}_j$を「列プロファイル」と呼ぶ。プロファイル行列は
$\mathbf{R} \equiv \mathbf{D}^{-1}_r \mathbf{P}$
$\mathbf{C} \equiv \mathbf{D}^{-1}_c \mathbf{P}^T$
行プロファイル空間と列プロファイル空間
行プロファイル$\tilde{\mathbf{r}}_i$を、$J$次元空間におけるその行の座標とみる。その行の行和、つまり行和ベクトル$\mathbf{r}$の$i$番目の要素$r_i$を「質量」と呼ぶことにする。
二点間の距離を、重み$\mathbf{D}^{-1}_c$による加重ユークリッド距離(=カイ二乗距離)とする。つまり、次元$j$の重みは$1/c_j$となるわけである。
そもそも行$i$の行プロファイルの$j$番目の要素は$p_{ij}/r_i$であった。すべての行プロファイルについてその重心を求めると、$\sum_i r_i (p_{ij}/r_i) / \sum_i r_i = \sum_i p_{ij}= c_j$であるから、つまり行プロファイルの重心は列和ベクトル$\mathbf{c}$となる。
以上は行と列をひっくり返しても成立する。つまり$\tilde{\mathbf{c}}_j$を$I$次元空間における座標とみて、二点間の距離を重み$\mathbf{D}^{-1}_r$による加重ユークリッド距離としたとき、その重心は行和ベクトル$\mathbf{r}$である。
全慣性
ちょっと話が逸れるけど... 上の行プロファイル空間なり列プロファイル空間について、各点の重心からの二乗距離の、質量を重みにした加重和を「全慣性」と呼ぶ。
行$i$の重心からの二乗距離は、もし次元に重みがなかりせば
$(\tilde{\mathbf{r}}_i - \mathbf{c})^T (\tilde{\mathbf{r}}_i - \mathbf{c})$
だが、軸に重み$\mathbf{D}^{-1}_c$がつくので
$(\tilde{\mathbf{r}}_i - \mathbf{c})^T \mathbf{D}^{-1}_c (\tilde{\mathbf{r}}_i - c)$
で、この子の質量が$r_i$である。質量で重みづけて合計すると
$in(I) = \sum_i r_i (\tilde{\mathbf{r}}_i - \mathbf{c})^T \mathbf{D}^{-1}_c (\tilde{\mathbf{r}}_i - \mathbf{c})$
同様に
$in(J) = \sum_j c_j (\tilde{\mathbf{c}}_j - \mathbf{r})^T \mathbf{D}^{-1}_r (\tilde{\mathbf{c}}_j - \mathbf{r})$
これが、行プロファイルの空間の全慣性$in(I)$, 列プロファイルの空間の全慣性$in(J)$である。
導出は省略するけど、結局
$in(I)= in(J) = \sum_i \sum_j \{(p_{ij} - r_i c_j)^2/r_i c_j\}$
であることが示せる。この式をよーく見ると、$\mathbf{N}$を二元クロス表とみて、その独立性検定をしたときのカイ二乗値を、総和で割った値になっている。
一般化SVDの登場
さあ、ここからが本番だ!
上の行プロファイル空間・列プロファイル空間から、少数次元の下位空間を取り出したい。その際、オリジナルの空間からの各点の二乗距離の、質量を重みにした加重和を最小化したい。
こういうのは、ご存じ一般化SVD
$\mathbf{A} = \mathbf{N} \mathbf{D}_\mu \mathbf{M}^T$ ただし $\mathbf{N}^T \mathbf{\Omega} \mathbf{N} = \mathbf{M}^T \mathbf{\Phi} \mathbf{M} = \mathbf{I}$
の得意技である。
主はいわれた。あなたがたはこれまで、$\mathbf{A}$の行を点、列を次元とみなしていた。はっきり言っておくが、$\mathbf{N}$の左$K^*$列, $\mathbf{D}_\mu$の左上$K^* \times K^*$, $\mathbf{M}$の左$K^*$列を取ってきて
$\mathbf{A}_{[K^*]} \equiv \mathbf{N}_{[K^*]} \mathbf{D}_{\mu [K^*]} \mathbf{M}^T_{[K^*]}$
とし、$\mathbf{N}_{[K^*]} \mathbf{D}_{\mu [K^*]}$の行を点、列を次元とみなしなさい。なぜなら、ランク$K^*$以下のあらゆる行列$\mathbf{X}$のなかで、二乗距離
$trace\{\mathbf{\Omega}(\mathbf{A}-\mathbf{X}) \mathbf{\Phi}(\mathbf{A}-\mathbf{X})^T\}$
を最も小さくする$\mathbf{X}$こそ、$\mathbf{A}_{[K^*]}$だからである。
行プロファイル行列と列プロファイル行列の一般化SVD
行プロファイル行列$\mathbf{R} \equiv \mathbf{D}^{-1}_r \mathbf{P}$について考えよう。あらかじめ$\mathbf{R}$の各列$j$からその列の重心$c_j$を引き($\mathbf{R} - \mathbf{1} \mathbf{c}^T $)、各列の重心を0にしておく。
おさらいしておくと、点$i$の質量は$r_i$で、次元$j$の重みは$1/c_j$であった。ってことは、主よ、行$i$に重み$r_i$, 列$j$に重み$1/c_j$をつけた一般化SVDで
$\mathbf{D}^{-1}_r \mathbf{P} - 1\mathbf{c}^T = \mathbf{L} \mathbf{D}_\phi \mathbf{M}^T $ ただし $\mathbf{L}^T \mathbf{D}_r \mathbf{L} = \mathbf{M}^T \mathbf{D}_c^{-1} \mathbf{M} = \mathbf{I}$ [式1]
と分解し、$\mathbf{F} \equiv \mathbf{L} \mathbf{D}_\phi$を座標にすればよろしいのですね。
同様に、列プロファイル行列$\mathbf{C} \equiv \mathbf{D}^{-1}_c \mathbf{P}$については、
$\mathbf{D}^{-1}_c \mathbf{P}^T - 1\mathbf{r}^T = \mathbf{Y} \mathbf{D}_\psi \mathbf{Z}^T $ ただし $\mathbf{Y}^T \mathbf{D}_c \mathbf{Y} = \mathbf{Z}^T \mathbf{D}_r^{-1} \mathbf{Z} = \mathbf{I}$ [式2]
と分解し、$\mathbf{G} \equiv \mathbf{Y} \mathbf{D}_\psi$を座標にすればいいわけだ。
式1と式2は結局同じ行列の一般化SVDである (その1)
さて、式1に左から$\mathbf{D}_r$を掛ける。
$\mathbf{P} - \mathbf{rc}^T = (\mathbf{D}_r \mathbf{L}) \mathbf{D}_\phi \mathbf{M}^T$
左辺の分解は、もはや重み$\mathbf{D}_r, \mathbf{D}^{-1}_c$の一般化SVDではない。ええ、はい、わかってます、確かにそうなんです。しかしですね、$\mathbf{L}^T \mathbf{D}_r \mathbf{L} = \mathbf{I}$の$\mathbf{L}$に左から$\mathbf{D}_r$を掛けまくるという極悪非道な真似をしますとですね、
$(\mathbf{D}_r \mathbf{L})^T \mathbf{D}_r^{-1} (\mathbf{D}_r \mathbf{L}) = \mathbf{I}$
である。$\mathbf{D}_r$を二回も掛けた分、真ん中を逆数にして取り返していることに注意。また、
$\mathbf{M}^T \mathbf{D}^{-1}_c \mathbf{M} = \mathbf{I}$
であることには変わりない。結局、重み$\mathbf{D}^{-1}_r, \mathbf{D}^{-1}_c$の一般化SVDになっているわけだ。[←この理屈に気が付かなかったせいで、かなり時間を食いました...]
同様に、式2に左から$\mathbf{D}_c$を掛ける。
$\mathbf{P}^T - \mathbf{cr}^T = (\mathbf{D}_c \mathbf{Y}) \mathbf{D}_\psi \mathbf{Z}^T$
$\mathbf{P} - \mathbf{rc}^T = \mathbf{Z} \mathbf{D}_\psi (\mathbf{D}_c \mathbf{Y})^T$
ここで
$\mathbf{Z}^T \mathbf{D}_r^{-1} \mathbf{Z} = \mathbf{I}$
$(\mathbf{D}_c \mathbf{Y})^T \mathbf{D}^{-1}_c (\mathbf{D}_c \mathbf{Y}) = \mathbf{I}$
こちらも重み$\mathbf{D}^{-1}_r, \mathbf{D}^{-1}_c$の一般化SVDになっている。
あらやだわ、二人とも同じ行列$\mathbf{P} - \mathbf{rc}^T$を、同じ重み$\mathbf{D}_r^{-1}, \mathbf{D}_c^{-1}$で一般化SVDしてたのね。おほほほほ。
というわけで、一般化SVDの解が一意に決まるとして、
$\mathbf{D}_\phi = \mathbf{D}_\psi=\mathbf{D}_\mu$
$\mathbf{D}_r \mathbf{L} = \mathbf{Z} = \mathbf{A}$
$\mathbf{M} = \mathbf{D}_c \mathbf{Y} = \mathbf{B}$
と置き、
$\mathbf{P} - \mathbf{rc}^T = \mathbf{A} \mathbf{D}_\mu \mathbf{B}^T$ ただし $\mathbf{A}^T \mathbf{D}_r^{-1} \mathbf{A} = \mathbf{B}^T \mathbf{D}_c^{-1} \mathbf{B} = \mathbf{I}$
厳密にいうと、一般化SVDの解が一意に決まらない場合(特異値のなかに同じ値がある場合)もありうるけど、要するに上のように書ける。
座標は次のようになる。
行プロファイルの座標: $\mathbf{F} = \mathbf{L} \mathbf{D}_\phi = \mathbf{D}_r^{-1} \mathbf{A} \mathbf{D}_\mu$
列プロファイルの座標: $\mathbf{G} = \mathbf{Y} \mathbf{D}_\psi = \mathbf{D}_c^{-1} \mathbf{B} \mathbf{D}_\mu$
式1と式2は結局同じ行列の一般化SVDである (その2)
ここでChap.4 からちょっと離れるけど...
式1に右から$\mathbf{D}^{-1}_c$を掛けたら何が起きるか。
$\mathbf{D}^{-1}_r \mathbf{P} \mathbf{D}^{-1}_c - 11^T = \mathbf{L} \mathbf{D}_\phi (\mathbf{M}^T \mathbf{D}^{-1}_c) = \mathbf{L} \mathbf{D}_\phi (\mathbf{D}^{-1}_c \mathbf{M})^T $
ここで
$\mathbf{L}^T \mathbf{D}_r \mathbf{L} = \mathbf{I}$
$(\mathbf{D}^{-1}_c \mathbf{M})^T \mathbf{D}_c (\mathbf{D}^{-1}_c \mathbf{M}) = \mathbf{I}$
というわけで、こんどは重み$\mathbf{D}_r, \mathbf{D}_c$の一般化SVDになる。
同様に、式2に右から$\mathbf{D}^{-1}_r$を掛ける。
$\mathbf{D}^{-1}_c \mathbf{P}^T \mathbf{D}^{-1}_r - 11^T = \mathbf{Y} \mathbf{D}_\psi (\mathbf{Z}^T \mathbf{D}^{-1}_r) = \mathbf{Y} \mathbf{D}_\psi (\mathbf{D}^{-1}_r \mathbf{Z})^T$
$\mathbf{D}^{-1}_r \mathbf{P} \mathbf{D}^{-1}_c - 11^T = (\mathbf{D}^{-1}_r \mathbf{Z}) \mathbf{D}_\psi \mathbf{Y}^T$
ここで
$(\mathbf{D}^{-1}_r \mathbf{Z})^T \mathbf{D}_r (\mathbf{D}^{-1}_r \mathbf{Z}) = \mathbf{I}$
$\mathbf{Y}^T \mathbf{D}_c \mathbf{Y} = \mathbf{I}$
というわけで、こんどは重み$\mathbf{D}_r, \mathbf{D}_c$の一般化SVDになる。くどいですね。
あらやだわ二人とも同じ行列$\mathbf{D}^{-1}_r \mathbf{P} \mathbf{D}^{-1}_c - 11^T$を同じ重み$\mathbf{D}_r, \mathbf{D}_c$で一般化SVDしてたのねおほほほほ、というわけで、
$\mathbf{D}_\phi = \mathbf{D}_\psi=\mathbf{D}_\mu$
$\mathbf{L} = \mathbf{D}^{-1}_r \mathbf{Z} = \mathbf{A'}$
$\mathbf{D}^{-1}_c \mathbf{M} = \mathbf{Y} = \mathbf{B'}$
と置き、
$\mathbf{D}^{-1}_c \mathbf{P} \mathbf{D}^{-1}_r - 11^T = \mathbf{A'} \mathbf{D}_\mu \mathbf{B'}^T$ ただし $\mathbf{A'}^T \mathbf{D}_r \mathbf{A'} = \mathbf{B'}^T \mathbf{D}_c \mathbf{B'} = \mathbf{I}$
という一般化SVDで表現できる。
座標は次のようになる。
行プロファイルの座標: $\mathbf{F} = \mathbf{L} \mathbf{D}_\phi = \mathbf{A'} \mathbf{D}_\mu$
列プロファイルの座標: $\mathbf{G} = \mathbf{Y} \mathbf{D}_\psi = \mathbf{B'} \mathbf{D}_\mu$
つまり、一般化SVDで得られた左特異行列と右特異行列に特異値を掛けるだけで、座標が得られるわけである。その点ではこの表現のほうがスマートである。実際、この本のAppendix Aではこういう表現になっている。
Chap.4 に戻り、最後に2つだけメモしておこう。
遷移方程式
導出は省略するけど、
$\mathbf{G} = \mathbf{C} \mathbf{F} \mathbf{D}^{-1}_\mu$
$\mathbf{F} = \mathbf{R} \mathbf{G} \mathbf{D}^{-1}_\mu$
という関係が成り立つ。つまり、列$j$の列プロファイル(=$\mathbf{G}$の$j$行目)は、行プロファイル行列$\mathbf{F}$の各行の重心$\tilde{\mathbf{c}}_j F$を、次元$k$について$1/\mu_k$したものなのだ。うわーすごいわねー[←出来レース]。これを遷移方程式という。
中心化せずに一般化SVDしたら?
さきほどは$\mathbf{P}-\mathbf{rc}^T$を一般化SVDしたが、うっかり$\mathbf{P}$を一般化SVDしちゃったらどうなるか。
$\mathbf{P} = \tilde{\mathbf{A}} \mathbf{D}_\tilde{\mu} \tilde{\mathbf{B}}^T$ ただし$\tilde{\mathbf{A}}^T \mathbf{D}_r^{-1} \tilde{\mathbf{A}} = \tilde{\mathbf{B}}^T \mathbf{D}_c^{-1} \tilde{\mathbf{B}} = I$
めんどくさいので証明は省略するけど、$\tilde{\mathbf{A}}$は「$\mathbf{A}$の左にベクトル$\mathbf{r}$をくっつけた行列」、$\tilde{\mathbf{B}}$は「$\mathbf{B}$の左にベクトル$\mathbf{r}$をくっつけた行列」となり、第一特異値は1となり、元の特異値は一個づつ後ろにずれるのである。ああ、なんかわかるような気がしてきた。中心化してないので「質量因子」みたいのが出てきちゃうわけだ。
2018年5月 5日 (土)
これは私による私のためのメモでございます。まあ、そう云ってしまえば全部そうなんですけど。
Rのdplyrパッケージにはscoped variantsと呼ばれる関数(dplyr風にいうと、verb)がある。使い方がいまいちわかっておらず、毎回イライラするので、きちんと調べてみることにした。
scoped variantsを持つverbは、mutate(), transmute(), summarize(), filter(), group_by(), rename(), select(), arrange()の8つ。
verbのscoped variantsには all, at, ifの三種類がある。mutate()の場合には、mutate_all(), mutate_at(), mutate_if()があるわけだ。
mutate(), transmute(), summarize()
以下、変数変換のverbであるmutate()を例に、3つのvariantsについて使い方をメモしておく。transmute(), summarize()も同様である。
_all() variant
mutate_all(.tbl, .funs, ...)
オブジェクト.tblに含まれているすべての変数について、.funsに指定した変換を行う。
- 引数.tblは受け取るtblオブジェクトで、パイプを使っている場合にはふつう省略される。
- 引数.funsは関数のリスト。ふつうはfuns()で生成するが、関数名の文字列ベクトルでもよいし、単に関数でもよい。
さて、このfuns()の書式がちょっと不思議である(そうそう、ここでいつもとまどうのだ)。
funs(..., .args=list())
...に関数を指定する。たとえば変数の平均を求めるとして、...のとこには単にmeanと書いてもいいし、関数名の文字列"mean"と書いてもいいし、mean(., na.rm=T)という風に書いてもいい。しかし無名関数はだめ。function(x) mean(., na.rm=T)というのは許してもらえない。
funsの中に複数の関数をならべてもよい。ただし、文字列ベクトルは受け取れない。つまり、funs("min", "max")はありだがfuns(c("min", "max"))はなし。後者の場合にはfuns_(c("min", "max"))と書く。
複数の関数を並べるとなにが起きるかというと...
data.frame(v1=1:10, v2=1:10) %>% mutate_all(funs(min, max))
返ってくるデータフレームには、v1, v2, v1_min, v1_max, v2_min, v2_maxが含まれる。接尾辞("min", "max")は勝手につけてくれるけど、明示的にfuns(a =min, b=max)とすれば"a", "b"になる。
_at() variant
mutate_at(.tbl, .vars, .funs, ...)
mutate_all()との違いは、.varsに指定した変数だけについて変換が行われるという点である。
- 引数.varsは変数名のリスト。ふつうvars()で生成するが、変数名の文字列ベクトルでもいいし(なんと!!知らなかった)、列位置の整数ベクトルでもよい。starts_with()のような変数選択ヘルパはそのままでは使えず、一旦vars()と書く必要がある(ここでいっつも間違える)。
vars()の書式は
vars(...)
...で変数名を指定する。select()と同じように書ける。よってvars(starts_with("hoge"))という風に書ける。
_if() variant
mutate_if(.tbl, .predicate, .funs, ...)
mutate_all()との違いは、.predicateに該当する変数だけについて変換が行われるという点である。(そうか... 引数.varsはないのか...)
- 引数.predicateはふつう「各列に適用される関数」だが、論理ベクトルでも良い。関数を指定する場合は関数名を裸で書く。is.factorとか。
試してみたところ、どうやら引数.predicateを無名関数にするのはありらしい。mutate_if(df, function(x) is.numeric(x), as.factor)とか。
さて、他のverbだとどうなるか。特にわかりにくいのは、引数.funsの意味である。mutate(), transmute(), summarize()は変数変換のverbなので、引数.funsの役割ははっきりしている。他のverbではなにを意味するのか。
filter()
filter()のscoped variantsは引数.funsを持たない。かわりに引数.vars_predicateを持つ。この引数はall_vars(expr)かany_vars(expr)で生成する。exprは条件式。
わけわかんなくなって参りましたが、たとえば
filter_all(df, all_vars(. > 100))
とすると、すべての変数の値が100より大である行が選択される、ということである。
group_by()
引数.funsを持つ。グループ化変数が変数変換の引数を持つというのも変な感じだが、これはgroup_by()のあとにmutate()するのと同じことになる。たとえば
group_by_all(df, as.factor)
とすると、すべての変数でのグループ化が行われ、かつそのグループがfactorになる。
select(), rename()
引数.funsを持つが、これは変数に適用する関数ではなく、変数名に適用する関数となる。ここが直観に反するんだけど、rename()のscoped variantsだけでなく、select()のscoped variantsも引数.funsを持つのである。たとえば
select_all(df, toupper)
とすると、全ての変数が大文字になるんじゃなくて、全ての変数名が大文字になる。(あれ? じゃあ結局、select_all()とrename_all()って全く同じなの?)
試してみたところ、無名関数が使える。たとえば
select_all(df, function(x) paste0("hoge", x))
とすると、全変数の変数名の頭に"hoge"がつく。
ということはだ。たとえば質問紙調査のデータで、Q1S1, Q2S2, ... に5件法の回答(1,2,3,4,5)がはいっている。これを反転した変数 nImage1, nImage2, ...と、T2Bのとき1になるダミー変数bImage1, bImage2, ..をつくりたい。この場合、
df %>%
mutate_at(vars(starts_with("Q1S"), funs(n = 6 - ., b = if_else(. %in% 1:2, 1, 0))) %>%
rename_at(vars(starts_with("Q1S"), sub("Q1S(.+)_(.+)", "\\2Image_\\1", .))
とすればいいわけ? それとも
rename_at(vars(starts_with("Q1S"), function(x) sub("Q1S(.+)_(.+)", "\\2Image_\\1", x))
と無名関数にするわけ? 試してみたところ、後者のみOKであった。
arrange()
引数.funsを持つ。たとえば
arrange_all(df, desc)
とすると、左の変数から順に降順になる。
覚え書き: Rのdplyrパッケージのhogehoge_{all, if, at} 動詞の使い方
2018年5月 3日 (木)
仕事の関係でデータ解析について御相談をいただくことがあるのだけれど(嗚呼、流されていく人生...)、これこれこういうことをSPSSでやるためにはどうしたらいいでしょうか? なあんて問われることがあって、そのたびにオタオタしてしまう。SPSSなんて長らく使っていないもので。
いやいや、SPSSの悪口を言うつもりはないです、全然。神は地上にさまざまな命をもたらし、人類にさまざまなソフトウェアをお与えになりました。いずれも等しく素晴らしい(両手を広げるポーズ)。素敵ですよね、SPSS!
そんなこんなで、自分では普段使っていないソフトウェアについて考えるというのも、畳の上の水練みたいで、それはそれで興味深い。先日はSPSSでクラスタリングする際の事例間の近接性指標の選択について御相談いただき、かなり焦ったので、今後のためにメモを作っておく。
手順は次の通り。
- SPSS Statistics Base 25の英語版マニュアルを検索し、事例間の近接性を求めていそうなプロシジャについて片っ端からメモする。BaseというのはSPSS Statisticsの基本パッケージで、基本的なプロシジャしか入っていない。オプションパッケージにも近接性指標を使うのがあるかもしれないけど、ええい、省略だ。
- SPSSのなにが一番困るかというと... 訂正、SPSSのどこが一番面白いかというと、統計用語の独創的な日本語訳である。というわけで、日本語版マニュアルから該当ページを探し、日本語訳を[]内に付記する。
- さらにさらに、アルゴリズム解説書から、各指標の定義と思われるものをメモする。なにしろ、IBMの膨大なドキュメント群からこのPDFファイルを見つけるまでが大変なのである。このPDFには日本語版がないというのがポイント。さらにいうと、このPDFには目次もノンブルもなくて... いや、そういうところも楽しいですよね!ええ楽しいです!
さあ行きましょう! (と自分で自分を励まして)
距離
PROXIMITIESコマンドでは以下の指標が利用できる(英語版p.43-; 日本語版p.45-; アルゴリズム解説書p.864-)。
- 間隔データ:
- Euclidean distance[ユークリッド距離]: $EUCLID(x, y) = \sqrt{\sum_i (x_i - y_i)^2}$. 非類似性.
- squared Euclidean distance[平方ユークリッド距離]: $SEUCLID(x, y) = \sum_i (x_i - y_i)^2$. 非類似性.
- Chebychev[Chebychev]: $CHEBYCHEV(x, y) = max_i |x_i - y_i|$. 非類似性.
- block[都市ブロック]: $BLOCK(x, y) = \sum_i |x_i - y_i|$. 非類似性.
- Minkowski[Minkowski]: $MINKOWSKI(x, y) = (\sum_i | x_i - y_i |^p)^{1/p}$. 非類似性.
- Pearson correlation[Pearsonの相関係数]: $CORRELATION(x, y) = \sum_i(Z_{xi} Z_{yi}) / N$. $Z$は標準化得点。類似性。
- cosine[コサイン]: $COSINE(x,y) = \sum_i(x_i y_i) / \sqrt{(\sum_i x^2_i)(\sum_i y^2_i)}$. 類似性。
- customized[カスタマイズ].
- 頻度データ
- Chi-square measure[カイ二乗測度]: $CHISQ(x, y) = \sqrt{\sum_i \frac{(x_i-E(x_i))^2}{E(x_i)}+\sum_i \frac{(y_i-E(y_i))^2}{E(y_i)}}$. 非類似性.
- phi-square measure[ファイ二乗測度]: $PH2(x, y) = CHISQ(x, y) / \sqrt{N}$. 非類似性.
- 二値データ: 下記の27種類。
二値データの指標は山ほどある。アルゴリズム解説書ではいくつかのタイプにわけて説明しているので、このタイプ分けに従ってメモしておく。
以下、2x2のクロス表について、両方presentの頻度を$a$, 両方absentの頻度を$d$, 片方だけpresentの頻度を$c,d$とする。またメモを楽にするために、$n=a+b+c+d$とする。
タイプ1. 二値データの指標 [←いや、そういってしまえばみんなそうなんですけどね]。いずれも類似性の指標。
- Russell and Rao[RusselとRao]: $RR(x,y) = a / n$
- simple matching[単純整合]: $SM(x,y) = (a+d) / n$
- Jaccard[Jaccard]: similarity ratioともいう。$JACCARD(x,y) = a / (a+b+c)$
- Dice[Dice]: Czekanowski, Sorensonともいう。$DICE(x,y) = 2a / (2a+b+d)$
- Sokal and Sneath 1[SokalとSneath 1]: $SS1(x,y) = 2(a+d) / (2(a+d)+b+c)$
- Rogers and Tanimoto[RogersとTanimoto]: $RT(x,y) = (a+d) / (a+d+2(b+c))$
- Sokal and Sneath 2[SokalとSneath 2]: $SS2(x,y) = a / (a+2(b+c)))$
- Kulczynski 1[Kulczynski 1]: $K1(x,y) = a/(b+c)$。分母が0なら9999.999とする。
- Sokal and Sneath 3[SokalとSneath 3]: $SS3(x,y) = (a+d)/(b+c)$。分母が0なら9999.999とする。
いま気が付いたんだけど、普段頼りにしている齋藤・宿久(2006)「関連性データの解析法」(共立出版)では、JaccardとRussell & Raoの定義が入れ替わっている(p,18-19)。あらら。おそらく単純な誤植だろう。
タイプ2. 条件付き確率。いずれも類似性の指標である。
- Kulczynski 2[Kulczynski 2]: $K2(x,y) = (a/(a+b) + a/(a+c))/2$. 一方がpresentであるという条件の下での、他方がpresentである条件付き確率の平均。
- Sokal and Sneath 4[SokalとSneath 4]: $SS4(x,y) = (a/(a+b)+a/(a+c)+d/(b+d)+d/(c+d))/4$。一方がなにかであるという条件の下での、他方がそれと同じである条件付き確率の平均。
- Hamann[Hamann]: $HAMANN(x,y) = ((a+d)-(b+c))/n$. 値が同じである確率から、値が異なる確率を引いたもの。
うーん、Hamannの指標を条件付き確率と呼ぶことができるのだろうか? ま、条件付き確率に基づく指標ではある。
タイプ3. 予測可能性の指標。いずれも類似性の指標である。あらかじめ次のように定義しておく。
$t_1 = max(a,b)+max(c,d)+max(a,c)+max(b,d)$
$t_2 = max(a+c, b+d) + max(a+b, c+d)$
- Lambda[ラムダ]: $LAMBDA(x,y) = (t_1 - t_2)/(2n-t_2)$。Goodman-KruskalのLambda。一方の値が分かったことで、他方の値についての予測誤差が何割下がるかという指標。
- Anderberg's D[AnderbergのD]: $D(x,y) = (t_1 - t_2)/2n$。Lambdaと似ているが、実際の予測誤差の減少を測っている。
- Yule's Y[YuleのY]: $Y(x,y) = (\sqrt{ad}-\sqrt{bc})/(\sqrt{ad}+\sqrt{bc})$
- Yule's Q[YuleのQ]: $Y(x,y) = (ad-bc)/(ad+bc)$. Goodman-Kruskalのgammaの2x2バージョン。
タイプ4. その他(類似性)
- Ochiai[落合]: $OCHIAI(x,y) = \sqrt{(a/(a+b)) (a/(a+c))}$
- Sokal and Sneath 5[SokalとSneath 5]: $SS5(x,y) = ad/\sqrt{(a+b)(a+c)(b+d)(c+d)}$
- phi 4-point correlation[ファイ4分点相関]: $PHI(x,y) = (ad-bc)/\sqrt{(a+b)(a+c)(b+d)(c+d)}$
- dispersion[散らばり]: $DISPER(x,y) = (ad-bc)/n^2$
タイプ5. その他(非類似性)
- Euclidean distance[ユークリッド距離]: $BEUCLID(x,y) = \sqrt{b+c}$
- squared Euclidean distance[平方ユークリッド距離]: $BSEUCLID(x,y) = b+c$
- size difference[サイズの差]: $SIZE(x,y) = (b-c)^2/n^2$
- pattern difference[パターンの違い]: $PATTERN(x,y) = bc/n^2$
- shape[形]: $BSHAPE(x,y) = (n(b+c)-(b-c)^2)/n^2$
- variance[分散]: $VARIANCE(x,y) = (b+c)/4n$
- Lance and Williams[LanceとWilliams]: Bray-Curtisともいう。$BLWMN(x,y) = (b+c)/(2a+b+c)$
階層クラスタリング
Hierarchical Cluster[階層クラスター]プロシジャの場合 (CLUSTERコマンドのこと。英語版p.87-;日本語版p.93)... とメモしようと思ったら、順序は違えど上記のPROXIMITIESコマンドと同じであった。
ということは結局、SPSS Statisticsで二値データを階層クラスタリングしようとするとと、豊富な距離指標を選べてしまうわけだ。そのいっぽう、IBMのサポートページには「二値データで階層クラスタリングするのはやめろ」というアドバイスが載っているわけで... 落とし穴掘ったから落ちないようにね、と親切に教えてもらったような気分である。
最近隣法
Nearnest Neighbor Analysis[最近傍分析]プロシジャでは、以下の指標が利用できる(KNNコマンド。英語版p.66; 日本語版p.70; アルゴリズム解説書p.578)。
- Euclidean metric[ユークリッド計量]: $Euclidean_{ih} = \sqrt{\sum_p w_p (x_{pi}-x_{ph})^2}$
- City block metric[都市ブロック計量]: $CityBlock_{ih} = \sum_p w_p |x_{pi} - x_{ph}|$
なお、$w_p$は通常は$1$、特徴の重要度を使って重みづけする場合には、特徴の重要度を合計1に規準化した値になる。
TwoStepクラスタリング
TwoStep Cluster[TwoStepクラスタ]プロシジャでは、クラスタ間距離として以下が選べる(TWOSTEP CLUSTERコマンド。英語版p.79; 日本語版p.84。定義がアルゴリズム解説書p.1078-にあるけど、そこだけメモしてもしょうがないので割愛する)。
- Log-likelifood[対数尤度]
- Euclidean[ユークリッド]
K-Means法
K-Means Cluster[大規模ファイルのクラスター分析]プロシジャでは、距離はユークリッド距離に固定されている。(QUICK CLUSTERコマンド)
MDS
Multidimensional Scaling[多次元スケーリング法]プロシジャの場合、以下の指標が選択できる。(ALSCALコマンド。英語版p.124; 日本語版p.133。さすがに訳語はPROXIMITIESコマンドでの訳語と揃えているようなので、略記する。アルゴリズム解説書p.14-を見ると、重みつきユークリッド距離の定義しかないんだけど、なぜだろう? なにか見落としているのかもしれない。)
- 間隔データ: Euclidean distance, Squared Euclidean distance, Chebychev, Block, Minkowski, customized.
- 頻度データ: Chi-square measure, Phi-square measure
- 二値データ: Euclidean distance, Squared Euclidean distance, Size difference, Pattern difference, Variance, Lance and Williams.
覚え書き:SPSS Statisticsにおける近接性の指標
2018年5月 2日 (水)
大きなことから小さなことまで、悩みの種は尽きないが、そのなかには勉強不足に起因するとしかいいようがない問題もある。もっとも、勉強すりゃいいんだから、ある面では気楽である。
予測モデルの性能評価というのもそうした問題のひとつである。というわけで、数か月前に仕事を中断してメモをつくった。
以下はHastie, Tibshirani, Friedman「統計的学習の基礎」第7章「モデルの選択と評価」からのメモ。英語版なら無料なのに高価な訳書を買っちゃったので、せいぜい頑張ってモトをとらねばならぬ。
まずは損失関数loss functionの定義から。
目標変数を$Y$, 入力ベクトルを$X$、予測モデルを$\hat{f}(X)$、訓練データを$T$とする。訓練データにおける損失関数としては、$Y$が量的ないし間隔の場合は、
二乗誤差 $L(Y, \hat{f}(X)) = (Y - \hat{f}(X))^2$
絶対値誤差 $L(Y, \hat{f}(X)) = |Y-\hat{f}(X)|$
が用いられることが多い。$Y$が質的な場合は、水準数を$K$とし、モデルを$p_k(X) = Pr(Y=k|X)$、予測を$\hat{Y}(X) = argmax_k \hat{p}_k(X)$として、
0/1損失 $L(Y, \hat{Y}(X)) = I(Y = \hat{Y}(X))$
逸脱度 $L(G, \hat{p}(X)) = -2 \sum_k^K I(Y=k) \log \hat{p}_k(X)$
が使われることが多い。確率密度に関する損失関数としては
対数尤度 $L(Y, \theta(X)) = -2 \log Pr_{\theta(X)}(Y)$
が用いられる。
標本における損失の平均
$\bar{err} = (1/N) \sum_i^N L(y_i, \hat{F}(x_i))$
を訓練誤差training errorという。
いっぽうテスト誤差test error(=汎化誤差 generalization error)は
$Err_T = E[L(Y, \hat{f}(X)) | T]$
として定義される。その期待値、すなわち訓練データのランダム性を含むすべてのランダム性についての平均
$Err = E[L(Y, \hat{f}(X))]$
を期待テスト誤差 (期待予測誤差) という。ほんとにやりたいことは、手元の$T$についての$Err_T$の推定なんだけど、実際には$Err$を推定するわけである。
モデルに対する期待テスト誤差は、モデルが含んでいるパラメータ$\alpha$まで含めて $Err = E[L(Y, \hat{f}_\alpha(X))]$
と書くべきところだが、以下では略記する。
さて、(期待)テスト誤差を最小にするモデルを選ぶにはどうしたらよいか(モデル選択)。また、最終的なモデルの(期待)テスト誤差を推定するにはどうしたらよいか(モデル評価)。というのがここからのテーマである。
もしもデータが十分にあるならば、データを訓練集合、確認集合、テスト集合に分割するのがよい。確認集合はモデル選択に使い、テスト集合は最終的な(期待)テスト誤差の推定だけに使う。理想のサイズは一概にいえないが、たとえば50:25:25という感じ。
もっとも、データはふつう十分ではないので、なにかと大変なのである。
ここでちょっと脇道にそれて、バイアス-分散分解について。
$Y=f(X)+e, E(e)=0, Var(e)=\sigma_e^2$と仮定しよう。$f(X)$は回帰だとして、2乗誤差損失を採用しよう。入力点$X=x_0$における$f(X)$の期待テスト誤差は
$Err(x_0)$
$= E[(Y-\hat{f}(x_0))^2|X=x_0]$
$= [E\hat{f}(x_0)-f(x_o)]^2 + E[\hat{f}(x_0)-E\hat{f}(x_0)]^2 + \sigma_e^2$
と分解できる。第1項がバイアスの二乗、第2項が分散を表す。
もっともこれは二乗誤差損失の場合の話。バイアス-分散トレードオフの挙動は、損失をどう定義するかで変わってくる。
テスト誤差をもう一度きちんと定義しよう。
データの同時分布から生成された新しいテストデータ点$(X^0 ,Y^0)$におけるモデル$\hat{f}$のテスト誤差を
$Err_T = E_{X^0, Y^0}[L(Y^0, \hat{f}(X^0)) | T]$
とする。期待テスト誤差は、これを訓練集合$T$について平均した値
$Err = E_T E_{X^0, Y^0}[L(Y^0, \hat{f}(X^0)) | T]$
である。
ご存知のように、訓練誤差
$\bar{err} = (1/N) \sum_i^N L(y_i, \hat{F}(x_i))$
はテスト誤差の推定値としては楽観的である。
いま、訓練入力点$x_1, \ldots, x_N$に対して新しい応答変数$Y^0$が与えられたとしよう。
$Err_{in} = (1/N) E_{Y^0}[L(Y^0, \hat{f}(X^0)) | T]$
を訓練標本内誤差in-sample errorと呼ぶことにする。これ自体に関心はないんだけど(だってテスト入力点は訓練入力点とは異なるから)、話の都合上これを考えるわけである。
$\bar{err}$は$Err_{in}$に対してもなお楽観的である。そこで最善度optimismを
$op \equiv Err_{in} - \bar{err}$
と定義する。で、訓練集合上での予測変数のほうは固定して、出力変数にたいして期待値をとり[←ここの発想がややこしい...]
$\omega \equiv E_y(op)$
と定義する。
すると、幅広い損失関数について一般に
$\omega = (2/N) \sum_i^N Cov(\hat{y}_i, y_i)$
が成り立つ。つまり、$y_i$が予測値に強く効いているとき、$\bar{err}$はより楽観的なわけだ。
さて、話を戻して... (期待)テスト誤差をどうやって推定するか。路線がふたつある。
ひとつの路線は、どうにかして最善度$\omega$を推定するというもの。それを訓練誤差$\bar{err}$に乗せてやれば、すくなくとも訓練標本内誤差$Err_{in}$は推定できるわけで、モデル間の相対的な比較はできるわけである。
では、$\omega$を具体的にどうやって推定するか。
単純なケースとして、$\hat{y}_i$が$d$次元の線形フィッティングで得られている場合を考えよう。$Y=f(X)+e$において$\sum_i^N Cov(\hat{y}_i, y_i) = d \sigma_e^2$だから、
$\omega = 2 \cdot (d/N)\sigma_e^2$
ここから得られるのが$C_p$統計量
$C_p = \bar{err} + 2 \cdot (d/N) \sigma_e^2$
である。
これをもっと一般的にしたのがAICで...[ここから、AIC, 有効パラメータ数、BIC, MDL, VC次元の話が続くんだけど、ちょっと時間がないのでパス]
もうひとつの路線は、$Err$そのものを直接に推定しようというものである。
この路線としては、まずは交差確認(CV)が挙げられる。
推定対象について誤解しないように。leave-one-out(LOO)とかだとついつい$Err_{T}$を推定しているような気がしちゃうけど、あくまで$Err$を推定してるんだからね。
K-fold CVの$K$をどう決めるか。$K=N$の場合(つまりLOOの場合)、$N$個の訓練集合は互いに似ているから、気が付かないけど分散が大きくなる。いっぽう$K$が小さいと、訓練曲線によっては$Err$を過大評価するかもしれない。折衷案として5とか10とかを推奨する。
CVでは「1SE」ルールが用いられることが多い。これは、最良モデルの誤差とSEを求め、最良モデルより1SE以内のモデルのなかでもっとも簡素なモデルを選ぶというルール。
[ここで一般化CVの話。パス]
予測変数がたくさんある分類問題で、(1)予測変数を相関とかで絞り込み、(2)それらで分類器を組み、(3)CVでパラメータを推定して最終モデルにする、というやりかたをとる場合がある。これはよくある間違い。最初の選別が教師無しである場合を例外として、とにかく最初から標本を抜くのがポイント。(1)標本をKグループにわけ、(2)各群について、それを抜いた全群で予測変数簿を絞り込み分類器を組み立て、その群でテストする、というのが正しいやりかた。
分類誤差を最小にするような1変数を選ぶという場面を考える(こういうのをstumpという)。「すべての訓練集合に対してあてはめを行うと、データをとてもよく分ける予測変数をひとつみつけることになる。よってCVでは誤差を正確に推定できない」...これも間違い。CVの繰り返しのたびにモデルを完全に再学習しないといけないということを忘れている。
もうひとつはブートストラップ法。訓練集合から同じサイズの標本集合を復元抽出で取り出す。これをB回繰り返す。B個の標本のそれぞれから任意の量を求める。B個の値の分布を調べる。
予測誤差の推定という文脈ですぐに思いつくのが、各ブートストラップ標本にモデルをあてはめて、予測値$\hat{f}^{*b}(x_i)$を得て、
$\hat{Err}_{boot} = (1/B)(1/N)\sum_b^B \sum_i^N L(y_i, \hat{f}^{*b}(x_i))$
を得るというのがひとつのアプローチ。しかしこれは$Err$の良い推定値ではない。訓練集合とテスト集合が分かれていないから。
そうではなくて、個々の観察値について、それを含まないブートストラップ標本だけを使って予測値を得る、というのが正しい。観測値$i$を含まないブートストラップ標本の集合を$C^{-i}$, そのサイズを$|C^{-i}|$として
$\hat{Err}^{(1)} = (1/N) \sum_i (1/|C^{-i}|)\sum_{b \in C^{-1}} L(y_i, \hat{f}^{*b}(x_i))$
とするわけである。これがLOOブートストラップ誤差である。
ところが、CVの場合と同じく、訓練集合が小さくなったことに寄るバイアスが生じる。
バイアスの大きさはどのくらいか。ある観測値$i$があるブートストラップ標本$b$に含まれる確率は$1-(1-(1/N))^N$。およそ0.632である。つまり、それぞれのブートストラップ標本における「異なり観測値」の数は、平均しておよそ$0.632N$。これはCVでいえば$K=2$の場合に相当する。だから、訓練曲線の傾きが$N/2$のあたりでまだ大きいようであれば、LOOブートストラップ標本による推定は過大になる。
バイアスを修正するにはどうすればよいか。ふたつのアイデアがある。
その1,0.632推定量。
$\hat{Err}^{(0.632)} = 0.368 \bar{err} + 0.632 \hat{Err}^{(1)}$
となる[この導出は面倒らしい]。この推定量は過学習のことを全然考えていない。
その2,0.632+推定量。まず、$y_i$と$x_{i'}$の全ての組み合わせを通じて
$\hat{\gamma} = (1/N^2) \sum_i \sum_{i'} L(y_i, \hat{f}(x_{i'}))$
を求め、
$\hat{R} = (\hat{Err}^{(1)} - \bar{err}) / (\hat{\gamma} - \bar{err})$
を求める。これを相対過学習率と呼ぶ。で、
$\hat{\omega} = 0.632 / (1-0.368 \hat{R})$
$\hat{Err}^{(0.632+)} = (1-\hat{\omega}) \bar{err} + \hat{\omega} \hat{Err}^{(1)}$
を求める。なぜなら...[ちゃんと丁寧に説明されているのだが、ここで力尽き、頭が停止した。いずれまた気力のあるときに...]
最後に、CVで得た期待テスト誤差$Err$の推定は、我々が本当に知りたい対象であるテスト誤差$Err_T$の推定になっているか、という問題。
実験してみるとわかるんだけど[...中略...]、意外にうまくいかない。訓練集合$T$に対するテスト誤差の推定は、同じ訓練集合からのデータだけではわからない。
嗚呼... いろいろ勉強不足を痛感する次第である。LOOブートストラップってそういう意味だったのか。
いや、勉強不足なのはまだよい。本当の問題は、このトシになって勉強してても無駄なんじゃないかという絶望感がひたひたと押し寄せてくる、という点である。辛いなあ。
2018年5月 1日 (火)
たまにSNSとかを見るたびに、なんだか知らんがすごそうな若い人たちが、なんだか知らんがすごそうなことを語っていて(データサイエンティストっていうんですか?すごいですねえ)、彼我の違いにクラクラしてしまう。
私の仕事のかなりの部分をデータ解析が占めるんだけど、データ解析というものは、私の知る限り実に地味なものでして、9割がたは前処理でございます。あんまし憧れるようなものではないと思うんだけど、きっと世の中にはそうでない世界もあるのだろう。
Rには前処理用の便利機能を提供するパッケージが結構あるが、私はそういうのをあんまり使っていない。自力で書いちゃったほうが早いし、なんとなく安心できるからだ。
その一方で、そういう機能を活用した方が効率的なのかな、と後ろめたい気分になることもある。でもああいうの、ほんとに忙しいときには、いちいち調べるのも面倒なんですよね。
という事情により、ちょっと調べておくことにした。
caretパッケージは機械学習系の予測モデル構築で定番のパッケージだが、前処理用の機能もいろいろ用意している。パッケージ解説の3章 Pre-Processing で紹介されている前処理用の関数についてメモする。
(あとで気づいたのだが、逐語訳に近いものを作っておられる方がいた。ありがたいことであります)
- preProcess(): いろんな変数変換や変数削除に使う。後述。
- dummyVars(): カテゴリカル変数をダミー変数にする。文字通り各レベルをダミー変数にしてくれるだけで、lm()用に切片項をつけてくれたりはしないことに注意。
- findLinearCombos(): 行列をQR分解して、線形従属性がある変数群を特定する。
- classDist(): テストデータの各ケースについて、「学習データの各クラスの重心からの距離」という新しい変数をつくることができる。真の決定境界が実は線形である時に便利だ、と書いてある(「お、おう...」という感じだ)。これもpreProcess()と同様にオブジェクトを返し、predict()メソッドではじめて変数がつくられる。
ほかにnearZeroVar(), findCorrelation(), spatialSign()が紹介されているが、preProcess()でも実行できるようなので省略する。
。。。というわけなのだが、preProcess()の機能がとても多くて面食らう。
ここからはpreProcess()について、マニュアルを参照してメモしておく。
preProcess()は変数変換や削除そのものを行う関数ではなく。変換のためのパラメータを推定したり、どの変数を削除べきかを探してくれたりするだけ。実際の処理はこの関数が戻すオブジェクトとデータを引数にとったpredict()で行う。
基本的な使用方法は:
preProcess(x, method, ...)
xは予測子がはいっている行列かデータフレーム。numericでない変数は単に無視される。
methodは以下の文字列のうちひとつ、ないし複数個のベクトルをとる。
...でとれる引数(以下では便宜的に「追加引数」と呼ぶ)には3種類ある。
- methodを問わない引数。na.remove, verboseがある。
- methodによって異なる引数。以下で全部メモする。
- どちらでもない引数。methodとして"ica"を指定した場合、fastICA::fastICA()にパスされる。試してみたところ、methodに"ica"が入っていない場合は無言で無視されるようだ。怖い。
さて、methodがとる文字列は以下の通り。複数個指定した場合の処理順序も決まっているので、その順にメモする。
- "zv": 分散がゼロの変数を削る。
- "nzv": 分散がゼロに近い変数を削る。caret::nearZeroVar()をコールするのであろう。追加引数としてfreqCut, uniqueCutをとる。
- "corr": caret::findCorrelation()をコールし、相関の高い変数を削る。追加引数としてcutoffをとる。
- 以下の変換。うーん、目的変数じゃなくて予測子をBox-Cox変換するというのもなんだか変な気分だが、そういうこともあるんでしょうね。
- "BoxCox": ご存じBox-Cox変換 $(x^\lambda-1)/\lambda$。xに含まれている各変数について$\lambda$を決めてくれる。追加引数としてfudge(tolerance値), outcome(numericないしfactorのベクトル。どう使われるんだろう、よくわからない), numUnique(xのユニークな値の数がこの値より小さかったら変換しない)がある。内部でcaret::BoxCoxTrans()を呼ぶようだが、結局それはMASS::boxcox()のラッパーらしい。
- "YeoJohnson": Yeo-Johnson変換という、Box-Cox変換みたいなものがあって、負の値もゼロもとれるらしい。試してみたら$\lambda$なるものを決めてくれた。webで拾ったPDFによれば、$x$が0以上のときは$((x+1)^\lambda-1)/\lambda$つまり$x+1$のBox-Cox変換で、$x$が負の時は$-[(-x+1)^{2-\lambda}-1]/(2-\lambda)$となる由。いったいなにがなんだか。上記PDFにも「解釈は困難」と書いてあって、笑ってしまった。
- "expoTrans": exponential transformation. caretのマニュアルでreferされているManly(1976)の最初のページによれば$(\exp(\gamma x)-1)/\gamma$だそうである。これもBox-Cox変換みたいなもので、負の値がとれる。濱崎ら(2000)は「指数型べき変換」と呼んでいる。$\gamma$を決めてくれるのかなあ? 試してみたけどよく分からなかった。内部でcaret::expoTrans()を呼ぶらしいのだが、マニュアルに説明がない。
- "center": 平均を引く。
- "scale": SDで割る。
- "range": 指定した範囲に収める。範囲は追加引数rangeBounds(長さ2のnumericベクトル)で指定する。
- 以下の欠損値補完。
- "knnImpute": K最近隣法による欠損値補完。追加引数としてk, knnSummary(近隣の値を平均するための関数。デフォルトではmean)がある。
- "bag-Impute": 他の変数を全部使ったbagged treeモデルによる欠損値補完。
- "medianImpute": 単に中央値で欠損を埋める模様。
- "pca": PCAで新しい変数をつくる。追加引数としてthresh(分散の累積割合のカットオフ),pcaComp(主成分の数。threshをoverrideする)がある。
- "ica": ICAで新しい変数をつくる。fastICA::fastICA()をコールする。追加変数はfastICA()にパスされる。
- "spatialSign": caret::spatialSign()をコールする。spatial sign変換というのをやるらしいのだが、意味がよくわからん、今度調べよう。
このほかに、マニュアルでは実行順序がはっきりしないが、次のmethodがある(きっと最初に実行されるんだろうな)。
- "conditionalX": 追加引数としてoutcomeをとる。ここでoutcomeはfactorベクトルでないといけない(そうでないときは無視される)。「outcomeのどこかのクラスにおいて、値が1種類しかない予測子」を削る。caret::checkConditionalX()をコールする模様。
。。。ううむ。
自分の仕事にあてはめて考えると、dummyVars()には代替がいっぱいある。その場になってみないとわからないけど、私はdummiesパッケージを使うか、model.matrix()で計画行列を作ることを考えると思う。classDist()はちょっと使い道が思いつかない。preProcess()の機能のうち、center, scale, rangeは自前で書くだろうし、変数の単変量分布の観察にかなり時間をかけることが多いので、zv, nzvは手作業でやる。Box-Cox系の変換は、目的変数ならともかく、予測子のほうに掛けたくなったという記憶が無い。欠損値補完や変数直交化をやるとしたらかなり気合いを入れるので、caretではやらないと思う。
こうしてみると、使うことがありそうなのは、ひとつはfindLinearCombos()。こういうの、以前SASで苦労して自作したことがある。もうひとつは、意外にもpreProcess()のconditionalXだ。確かにね、こういうことが問題になるケース、ありそうですね。naive bayesのCPTにゼロを出したくない、とか。
... いやいや、そういう問題じゃないか。あれもこれも全部統一的な枠組みでできます、ってところがポイントなんでしょうね。業務改革への道は遠いぞ。
2017年11月13日 (月)
仕事でデータの分析していて、この場面ではこれこれこういうわけでこのような方法で推定しております、これは当該分野の常識でございます、なあんていかにも専門家づらでにこやかに語っているんだけど、心のなかでは、(ああ、こういうのってちゃんとした名前があるんだろうな... 俺がきちんと勉強してないだけで...) と不安を抱えていることが結構ある。
これは辛い。かなり辛い。人生間違えたな、生まれ変わってやり直したいな、と思う瞬間が毎日の生活の中に沢山あるけれど、これもそのひとつである。
たとえば、なにかについて推定していて、ああ、これって要するにスタイン推定量って奴じゃないのかしらん、って思うことがたまにある。でもそういうの、誰にもきちんと教わったことがない。辛い。
あんまり辛いので、月曜朝に早起きしてノートをとった。本来、仕事が溜まっていてそれどころじゃないのであって、こういう現実逃避をしているから人生ぱっとしないのだともいえる。まあとにかく、以下は自分用の覚え書きであります。
なんでもいいんだけど、いま$N$個の母集団特性$\mu_1, \ldots, \mu_N$があって、それぞれの$\mu_i$について$z_i \sim N(\mu_i, \sigma^2_0)$が独立に観測されるとする。$z_i$は1個の観測値でもいいし標本平均でもいい。また分散は$N$個の特性を通じて等しければなんでもよい。
個別の$\mu_i$について推定する場面を考える。その推定量$\hat{\mu}_i$として何を使うのがいいか。
もちろん$z_i$そのものであろう。$z_i$は最小分散不偏推定量であり、最尤推定量であり、MSEを損失としたときの許容的推定量である(=「$\mu_i$の値がなんであれ$z_i$よりも誤差の二乗の期待値が小さい推定量」は存在しない)。
ところが。
今度は$\mathbf{\mu}=(\mu_1, \ldots, \mu_N)^t$について同時推定する場面を考える。いま、$N$個の母集団特性を通じたMSEの和
$\sum^N E[(\hat{\mu}_i-\mu_i)^2]$
が小さいと嬉しい、としよう。これを最小化する推定量はなにか。
$N$が3以上の時、驚いたことに、それは$\mathbf{z} = (z_1, \ldots, z_N)^t$ではない。実は、$\mathbf{\mu}$がなんであれ、MSEの和が$\mathbf{z}$より小さくなるような推定量が存在する。それが有名なJames-Stein推定量
$\displaystyle \mathbf{\delta} = \left( 1 - \frac{N-2}{||z||^2}\right) \mathbf{z}$
である。
母集団特性$\mu_1, \ldots, \mu_N$の間にはなんの関係もない。従って、たとえば$\mu_1$を推定する際に役立つのは$z_1$だけであるはずであって、$z_2, \ldots, z_N$を使うのはおかしい。なぜこんなことが起きるのか?
1950年代の統計学を揺るがせた、スタイン・パラドクスの登場である。
この奇妙な現象を説明する方法はいくつかある。そのひとつが、James-Stein推定量を経験ベイズ推定量として捉える説明である。
母集団特性を確率変数と見なし、$\mu_i \sim N(0, A)$としよう。
話を簡単にするために、$z_i$の分散は当面 $1$ としておく。すなわち $z_i|\mu_i \sim N(\mu_i, 1)$。
ベイズの定理より、$z_i$の下での$\mu_i$の事後分布は
$\mu_i | z_i \sim N(Bz_i, B), \ \ B = A/(A+1)$
であることが示せる。
複数の母集団特性について一気に書こう。$I$を単位行列として
$\mathbf{\mu} \sim N_N(0, AI)$
$\mathbf{z} | \mu \sim N_N(\mathbf{\mu}, I)$
$\mathbf{\mu} | \mathbf{z} \sim N(B\mathbf{z}, BI), \ \ B = A/(A+1)$
$\mathbf{\mu}$の推定誤差を最小二乗誤差で表すことにしよう。
$L(\mathbf{\mu}, \hat{\mathbf{\mu}}) = || \hat{\mathbf{\mu}} - \mathbf{\mu}||^2 = \sum^N(\hat{\mu}_i - \mu_i)^2$
リスク関数を、所与の$\mathbf{\mu}$の下での推定誤差の期待値としよう。
$R(\mathbf{\mu}) = E_\mu[L(\mathbf{\mu}, \hat{\mathbf{\mu}}) ]$
$\mathbf{\mu}$は固定で$\mathbf{z}$が動くということをはっきりさせるために$E_\mu$と書いている。
さて、$\mathbf{\mu}$の最尤推定量は$\mathbf{z}$そのものである。
$\hat{\mathbf{\mu}}^{(MLE)} = \mathbf{z}$
そのリスクは、さきほど分散を$1$にしておいたので
$R^{(MLE)}(\mathbf{\mu}) = N$
いっぽう、$\mu_i \sim N(0, A)$というベイズ的信念の下では、最小二乗誤差の期待値を最小化する推定量は事後分布の平均である。
$\hat{\mathbf{\mu}}^{(Bayes)} = B\mathbf{z} = (1-\frac{1}{A+1}) \mathbf{z}$
そのリスクは、$\mathbf{\mu}$を固定した状態では
$R^{(Bayes)}(\mathbf{\mu}) = (1-B)^2||\mathbf{\mu}||^2+NB^2$
$A$を固定して$\mathbf{\mu}$を動かした全域的なリスクは
$R_A^{(Bayes)} = E_A[R^{(Bayes)}(\mathbf{\mu})] = N \frac{A}{A+1}$
$R^{(MLE)}(\mathbf{\mu}) = N$と比べると、$\frac{A}{A+1}$倍に減っているわけである。
ところが問題は、$A$が未知だという点である。そこで、$A$を$\mathbf{z}$から推測することを考える。いやぁ、大人はずるいなあ。
$\mathbf{z} | \mu \sim N_N(\mathbf{\mu}, I)$の周辺分布をとると
$\mathbf{z} \sim N_n(0, (A+I)/I)$
となる。ということは、$\mathbf{z}$の二乗和$S=||\mathbf{z}||^2$は、自由度$N$のカイ二乗分布を$A+1$倍した分布に従い
$S \sim (A+1) \chi^2_N$
ここから下式が示せる:
$E[\frac{N-2}{S}] = \frac{1}{A+1}$
やれやれ、というわけで、これを$\hat{\mathbf{\mu}}^{(Bayes)}$に代入して得られるのが、James-Stein推定量
$\hat{\mathbf{\mu}}^{(JS)} = \left(1-\frac{N-2}{S}\right) \mathbf{z}$
である。
その全域的なリスクは下式となる。
$R_A^{(JS)} = N \frac{A}{A+1} + \frac{2}{A+1}$
$R_A^{(Bayes)}$よりもちょっと大きくなるけど、たとえば$N=10, A=1$のときにはたった2割増しである。
$N \geq 4$の場合について、もっと一般的に書き直しておこう。
$\mu_i \sim N(M, A)$ (iid)
$z_i|\mu_i \sim N(\mu_i, \sigma^2_0)$ (iid)
として、
$z_i \sim N(M, A+\sigma^2_0$ (iid)
$\mu_i | z_i \sim N(M+B(z_i - M), B\sigma^2_0), \ \ B = \frac{A}{A+\sigma^2_0}$
となり、
$\hat{\mu}_i^{(Bayes)} = M + B(z_i - M)$
だが$M, B$がわからない。そこでJames-Stein推定量の登場である。$\bar{z} = \sum z_i/N, S=\sum(z_i - \bar{z})^2$として
$\hat{\mu}_i^{(JS)} = \bar{z} + \left(1-\frac{(N-3)\sigma^2_0}{S}\right) (z_i - \bar{z})$
このタイプの推定量が役に立つのはどんな場面か。
まずいえるのは、たくさんの同種類の量を同時に推定する場面であること。さらに、$X_i$の分散が大きくて困っている場面であること(でなければ、不偏性をなくしてまで$\hat{\mu}_i$を改善しようとは思わない)。
さらに付け加えると、なんらかの先験情報が存在すること。上記の説明だと、事前に$\mu_i \sim N(M, A)$という信念があるわけだけど、こういう風に、$\mu_i$がなにかに近い、という風に考えることができる場合に役に立つ。だから、形式的にいえば$X_1, X_2, \ldots, X_N$がお互いに全く無関係な事柄についての値であってもJames-Stein推定量は使えるんだけど、役に立つといえるのは、やはり、なんらかの意味で同じ種類の量についての同時推定の場面である。
以上、主に次の2つの資料の、それぞれ最初の数ページだけを読んで取ったメモである。続きはまたいずれ。
篠崎信雄(1991) Steinタイプの縮小推定量とその応用. 応用統計学, 20(2), 59-76.
Efron, B. (2012) Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction. Cambridge University Press.
2017年10月26日 (木)
空間データのモデリングではバリオグラムというのを描くけれど、たいてい従属変数は量で、誤差に正規性が仮定されている。もし従属変数が二値とかカウントとかだったら、モデルはGLMとして組めるにしても、バリオグラムはいったいどうなるのか。
これ、ここんところの疑問の一つだったのだが、このたびやっと説明を見つけたのでメモしておく。すいません、純粋に自分のための覚え書きです。
$S(x)$を平均0, 分散$\sigma^2$の定常ガウス過程とする。観察$Y_i$は互いに独立で平均$\mu_i=g(\alpha+S(x_i))$, 分散$v_i = v(\mu_i)$とする。$g(\cdot)$はリンク関数$h(\cdot)$の逆関数である。
$Y$の素直なバリオグラムについて考えよう。横軸は$u=||x_i - x_j||$、縦軸は
$\tau_Y(u)=E[(1/2)(Y_i-Y_j)^2]$
これを展開するとこうなる。
$\tau_Y(u)$
$= (1/2)E_S[{g(\alpha+S(x_i)) - g(\alpha+S(x_j))}]$
$+ E_s[v(g(\alpha+S(x_i)))]$
第2項に$i$だけ出てきているのは、$S(x_i)$の周辺分布が場所を問わず一定だから。よくよくみればこの項は定数なので、以後$\bar{\tau}^2$と書く。これ、$S(\cdot)$の条件付き分布の分散を平均したもので、ガウシアンモデルで言うところのナゲットである。
さて。第一項に出てくる$g(\alpha+S(x_i))$が、$g(\alpha) + S(x_i) g'(\alpha)$とテイラー近似できるのはわかるね。[←わかんないよ!こっちは文系なんだから!]
すると結局こうなる。
$\tau_Y(u) \approx g'(\alpha)^2 \gamma_S(u) + \bar{\tau}^2$
つまり、バリオグラムの縦軸は、潜在ガウス過程$S(\cdot)$だけを取り出したバリオグラム$\gamma_S(u)$に比例し、そこにさきほどの平均ナゲット効果を乗せたものになる。
というわけで、上記のような通常のバリオグラムをナゲットのサイズ把握のために使うのはOK。しかし、GLMは$S(x)$と$Y$のあいだに非線形的関係を仮定しているわけだから、診断のために使うのはおかしい。[←「診断のため」ってどういうことだろう。バリオグラム・モデルの診断には使えないということだろうか]
バリオグラム・モデルをどうやって推定するか。
まずは一般的に、GLMの尤度関数について考えよう。ランダム効果$S$の下での$Y$の条件付き分布を$f_i(y_i; S, \theta)$とすると、パラメータ$\theta$の条件付き尤度は
$L(\theta | S) | \prod_i f_i(u_i|S, \theta)$
混合モデルの尤度は、$S$の同時分布を$g(S; \phi)$として
$L(\theta, \phi) = \int_S \prod_i f_i(u_i|S, \theta) g(s|\phi) ds$
さて、こんな風に多重積分が掛かっている尤度が計算できちゃうのは、ひとえに$S_i$が互いに独立だからである。しかし空間データでは$S_i = S(x_i)$は互いに独立でないので、こんなもん計算できっこない。実をいうとこの積分を近似する方法も提案されているんだけど、$S$の分散が大きいときには役に立たない。
というわけで... モンテカルロ最尤法、階層尤度、GEEなどの方法が提案されておる、という話になるのだが、力尽きたのでこの辺にしておこう。
以上, Diggle & Ribeiro (2010) "Model-based Geostatistics", Chapter 4-5より。勤務先の経費とはいえ2万円以上した本だったので、元を取らねば、と読んだ次第。
実をいうと、ポワソン対数線形モデルを使ったクリギングの際に、いい感じのバリオグラム・パラメータを視認で決める方法について知りたかったんだけど、それはよくわかんなかった。先の章に書いてあるのかも。
2017年9月13日 (水)
Rの辛いところはパッケージがいっぱいありすぎるところだ。このたび空間統計のパッケージについて調べていてほとほと困惑したので、空間データ分析のCran Task View (2017/05/09)の、Geostatisticsの項についてメモしておく。100%自分用の覚え書きです。
[2018/06/18追記: 2018/06/02版のTask Viewに従って更新した]
- gstat: 単変量・多変量の空間統計の関数。大データにも対応。
- geoR, geoRglm: モデル・ベース空間統計の関数。
- vardiag: バリオグラムの診断。
- automap: gstatを使って自動的に補完。
- intamap: 自動補完手続き。
- pspg: projected sparse Gaussian process kriging. [2018/06/02版からは消えている]
- fields: 上記と同様に、幅広い関数を提要。
- spatial: base Rと同梱。
- spBayes: 単変量・多変量のガウシアンモデルをMCMCで。
- ramps: ベイジアンの空間統計モデリング。
- geospt: 空間統計の関数やradial basisの関数。予測とCV, 最適空間サンプリングネットワークの設計の関数を含む。
- spsann: 空間的シミュレーテッド・アニーリングで標本の配置を最適化する。[2018/06/02版に新登場しているのを発見]
- geostatsp: RastオブジェクトやSpatialPointsオブジェクトを使った空間統計モデリング。非ガウシアンのモデルはINLAで、ガウシアンのモデルはMLで推定。
- FRK: 大データセットのための空間・時空間モデリングと予測。共分散関数をn個の基底関数に分解する。
- RandomFields: 確率場の分析とシミュレーション。バリオグラム・モデルをgeoR, gstatとやり取りできる。
- SpatialExtremes: RandomFieldsを使った空間的極値モデリング。
- CompRandFld, constrainedKriging, geospt: 空間統計モデリングへのその他のアプローチ。[投げやりな説明をありがとう]
- spTimer: ベイジアン・ガウシアン過程モデルとか、ベイジアン自己回帰モデルとか、ベイジアン・ガウシアン予測過程モデルとかをつかって、巨大な時空間データについてフィットしたり予測したりできる。
- rtop: runoff related dataとかadministrative unitsからのデータといったirregularな空間サポートを伴うデータについての空間統計的補完。
- georob: 誤差に空間的相関がある線形モデルをロバストかつガウシアン制約付きMLでフィッティングしたり、customaryポイントやブロックのクリギング予測を与えたり、対数変換したデータのクリギング予測をもとに戻す不変な変換をしたり、CVしたりする関数を提供。
- SpatialTools: クリギングに重点を置いたパッケージ。予測・シミュレーションの関数を提供。
- ExceedanceTools: SpatialToolsを拡張。exceedance regionsのconfidence regions(?)や等高線をつくる。
- gear: SpatialToolのリブート版に近い。クリーンでストレートで効率的な手法を提供。[そういわれると心惹かれますね]
- sperrorest: 空間誤差推定、いろんな空間CVや空間ブロック・ブートストラップを使ったパーミュテーションベースの空間変数重要性。
- spm: 空間統計と機械学習のハイブリッドで空間的予測モデリング。
- sgeostat: [紹介文がないぞ...]
- deldir, tripack: sgeostatと同じ一般的な問題領域についてのパッケージ。
- akima: スプライン補完。
- MBA: マルチレベルBスプラインで散布データを補完。
- spatialCovariance: 矩形データについての空間共分散行列の計算。
- regress: spatialCovarianceパッケージ, tgpパッケージの一部 [2018/06/02版に登場しているのを発見。regress自体は共分散行列が線形に指定されているときのガウシアン線形モデルで、空間とは別に関係なさそう]
- Stem: 時空間モデルをEMアルゴリズムで推定, パラメータの標準誤差を時空間パラメトリック・ブートストラップで推定。
- FieldSim: 確率場シミュレーション。
- SSN: stream ネットワークのデータの空間統計モデリング。移動平均でモデルを作る。共変量つきの空間線形モデルをMLやREMLで推定できる。視覚化機能もある。
- ipdw: georeferenced point dataをInverse Path Distance Weightingで補完。沿岸海洋環境みたいにランドスケープ上のバリアのせいでユークリッド距離による補完ができないときに有用。
- RSurvey: 空間的に分散したデータを処理したり、エラーを直したり視覚化したりするのに便利かも。
あーもう。これがSAS/STATなら, VARIOGRAM, KRIGE2D, SIM2D, SPPの4択なのに。勘弁してよ、もう!
2017年9月12日 (火)
6月末頃に作ったメモ。トピックモデルの表記が資料によって違っているせいで、混乱しちゃったのである。
岩田(2015)「トピックモデル」の表記
文書集合$\{\mathbf{w}_1, \ldots, \mathbf{w}_D\}$について考える。文書$\mathbf{w}_d$に含まれる単語を$w_{d1}, \ldots, w_{dN_d}$とする(順序は問わない)。文書集合を通して現れる語彙の数を$V$とする。
トピックモデルによれば、文書は次のように生成される。文書集合の背後には$K$個のトピックがある。
- トピック$k=1,\ldots,K$のそれぞれについて、単語分布$\mathbf{\phi}_k = (\phi_{k1}, \ldots, \phi_{kV})$が生成される。
$\mathbf{\phi}_k \sim Dirichlet(\beta)$ - 文書$d=1,\ldots,D$のそれぞれについて...
- トピック分布 $\mathbf{\theta}_d = (\theta_{d1}, \ldots, \theta_{dK})$が生成される。
$\mathbf{\theta}_d \sim Dirichlet(\alpha)$
トピックが生成されているわけではない点に注意。文書はあるトピックを持っているのではない(トピックの確率分布を持っている)。逆向きにいうと、トピックモデルは文書にトピックを割り当てない。 - 単語 $n=1, \ldots, N_d$ について...
- まずはトピック $z_{dn}$が生成される。単語が生成される前に、単語の数だけトピックが生成されている。逆向きにいうと、単語にトピックを割り当てていることになる。
$z_{dn} \sim Categorical(\mathbf{\theta}_d)$ - いよいよ単語が生成される。あらかじめ作っておいた単語分布$\mathbf{\phi}_{z_{dn}}$を参照して、
$w_{dn} \sim Categorical(\mathbf{\phi}_{z_{dn}})$
- まずはトピック $z_{dn}$が生成される。単語が生成される前に、単語の数だけトピックが生成されている。逆向きにいうと、単語にトピックを割り当てていることになる。
- トピック分布 $\mathbf{\theta}_d = (\theta_{d1}, \ldots, \theta_{dK})$が生成される。
佐藤(2015)「トピックモデルによる統計的潜在意味解析」の表記
トピック$k$における単語の出現分布を$\mathbf{\phi}_k = (\phi_{k,1}, \ldots, \phi_{k,V})$とし、
$\mathbf{\phi}_k \sim Dir(\beta)$
文書$d$のトピック分布(トピックの構成比率)を$\mathbf{\theta}_d = (\theta_{d,1}, \ldots, \theta_{d,K})$とし、
$\mathbf{\theta}_d \sim Dir(\alpha)$
文書$d$における$i$番目の潜在トピック$z_{d,i}$について、
$z_{d,i} \sim Multi(\mathbf{\theta}_d)$
$i$番目の単語$w_{d,i}$について
$w_{d,i} \sim Multi(\phi_{z_{d, i}})$
Griffiths & Steyvers (2004, PNAS)の表記
細かいところを端折ると、
$w_i | z_i, \phi^{(z_i)} \sim Discrete(\phi^{(z_i)}) $
$\phi \sim Dirichlet(\beta)$
$z_i | \theta^{(d_i)} \sim Discrete(\theta^{(d_i)})$
$\theta \sim Dirichlet(\alpha)$
こういう順番で書かれるとめっさわかりにくいが、まあとにかく、ハイパーパラメータは$\alpha, \beta$である。
ふつうそうですよね。良識ある大人なら、たいていの人がハイパーパラメータを$\alpha, \beta$と書いていたら、その世間の風潮にあわせますよね。俺様だけは$\beta$を$\delta$と書くぜ、読者どもよついてこい、なんて子供じみた真似はしませんよね?
Grun & Hornik (2011, J.Stat.Software) の表記
...というか、Rのtopicmodelsパッケージの表記。
さあ、ここで我々は、世間の風潮など気にもしない漢たちを目の当たりにし、驚愕することになるのである。はい深呼吸!
文書$w$について考える。文書$w$に含まれる単語を$w_{1}, \ldots, w_{N}$とする(順序は問わない)。
文書は次のように生成される。文書集合の背後には$k$個のトピックがある。
- それぞれのトピックについて、単語分布$\beta$が生成される。
$\beta \sim Dirichlet(\delta)$ - 文書$w$について...
- トピック分布 $\theta$が生成される。
$\theta \sim Dirichlet(\alpha)$ - 単語 $w_i$ について...
- まずはトピック $z_i$が生成される。
$z_{i} \sim Multinomial(\theta)$ - 多項確率分布 $p(w_i | z_i, \beta)$から単語が生成される。
- まずはトピック $z_i$が生成される。
- トピック分布 $\theta$が生成される。
実のところ、こうやってメモしててやっと謎が解けたんだけど、topicmodelsパッケージで LDA(x, k, control = list(estimate_beta = FALSE), model=...) と指定した場合、固定される「beta」とは、トピック別単語分布のハイパーパラメータ$\beta$ではなく、トピック別単語分布そのものなのだ。ハイパーパラメータはdeltaと呼ぶのである。なんだかなあ、もう...
なお、ハイパーパラメータのほうは、Gibbsサンプリングの場合のみ control=list(delta=...)として指定できる由。
トピックモデルの表記比較 (いつも思うんですが、専門家のみなさん記号を統一していただけませんかね)
仕事の都合で仕方なく、トピックモデルについてあれこれ考えているんだけど、トピック数の決定ってのはいったいどうしたらいいのかしらん、と不思議である。
解説本などをみると、それは階層ディリクレ過程で推定できる、それにはまず中華料理店のフランチャイズ・チェーンの仕組みについて検討する必要がある、ただし店舗内のテーブル数は無限とする... なんて途方に暮れるようなことが書いてあるんだけど(本当)、そんなおそろしい話じゃなくてですね、探索的因子分析のスクリー基準みたいなしょっぼーい話でいいから、なんか目安がほしいだけなんですけど...
やっぱり、データをちょっとホールドアウトしておいて、perplexityが低くなるトピック数を選べって話だろうか。面倒くさいなあ、と思いながらぼんやり検索していたら、なんと!Rにはldatuningというパッケージがあり、topicmodelsパッケージでLDA(潜在ディリクレ配分モデル)を組む際の最適トピック数を教えてくれるのだそうである。すごい!偉い!
さっそくldatuningを試してみたところ、さまざまなトピック数について、CaoJuan2009, Arun2010, Daveaud2014, Griffiths2004という4つの指標が出力される。それだけのパッケージであった。チャートを描いて考えな、という話である。
なんだ、この謎の指標は? マニュアルには一切説明がなく、ただ出典が書いてあるだけ。
さすがに気持ち悪いので、出典をあつめてめくってみた。
CaoJuan2009
出典はJuan, Tian, Jintao, Yongdon, Sheng (2009, Conf.)。
パラパラめくってみただけであきらめたんだけど(第一著者は博士の院生さんで80年生まれとのこと。うわー)、どうやら、2トピック間の語彙を通じたコサイン類似性を求め、その総当たり平均が最小になるようなトピック数を求める... というような話らしい。LDAではトピックは独立なはずだから、ということみたいだ。へぇー。
ldatuningのソースを眺めるとこうなっている。トピック$k(=1,\ldots,K)$の単語事後分布を格納したベクトルを$x_k$として、
$dist_{k,j} = \sum x_k x_j / \sqrt{\sum x_k^2 * \sum x_j^2}$
と定義し、すべての2トピックの組み合わせについてこの距離を合計し, $K(K-1)/2$で割っている。
Deveaud2014
出典はDeveaud, SanJuan, Bellot (2014), 論文だか紀要だかよくわからない。
もちろんきちんと読もうなどという大それた野心は持ち合わせていないわけで、トピック数決定についてのページをディスプレイ上で眺めただけなのだが、どうやら、2トピック間での単語出現分布のKLダイバージェンスを求め、その総当たり平均が最大になるようなトピック数を求める... という話らしい。へぇー。
ldatuningのソースを眺めると、
$dist_{k,j} = 0.5 \sum x_k \log(x_k/x_j) + 0.5 \sum x_j \log(x_j/x_k)$
と定義し、すべての2トピックの組み合わせについてこの距離を合計し, $K(K-1)$で割っている。
Arun2010
出典はArun, Suresh, Madhaven, Murthy(2010, Conf.)。入手できなかった。上のDeveaud et al.(2014)によれば、これもトピック間の距離みたいなものを最大にすることを目指すのだそうだ。
ソースコードを眺めたのだが、トピック別の単語事後分布とそのハイパーパラメータを使って、なにかごにょごにょしている模様。
Griffiths2004
出典として、Griffiths & Steyvers (2004, PNAS) と、誰かの修論かなにかが挙げられている。前者は科学研究のトピックを推定するという話で、有名な論文であろう。
ちゃんと読んでないけど、パラパラめくったところによればこういうことらしい。
要するに、トピック数を$T$、コーパス全体の単語を$\mathbf{w}$として、対数尤度$\log P(\mathbf{w}|T)$が最大になる$T$にすればいいじゃん、というアイデアである。しかしその直接の算出は、単語をトピック$\mathbf{z}$に割り当てるすべてのパターンを通じた合計が必要になるので無理。ところが、次のやりかたでうまく近似できる。
まず事後分布$P(\mathbf{z} | \mathbf{w}, T)$から$\mathbf{z}$をドローし、$P(\mathbf{w}|\mathbf{z}, T)$をたくさん求める。で、その調和平均を求める。へぇー。
なおGrun& Hornik(2011, J.Stat.Software)によれば、このやり方には推定量の分散が無限大になるかもしれないという欠点があるのだそうだ。
ソースコードのほうは、little tricky というコメントがついており、よくわからないことをやっている。
こうしてみると、Griffith & Steyvers (2004) はモデルの周辺尤度に注目する路線、他の3つはトピック間の単語事後分布の類似性に注目する路線といえそうだ。前者はperplexityみたいなもの、後者はcoherenceみたいなもの、ということなのかしらん?
探索的因子分析のアナロジーで言うと、前者はどうにかしてモデル適合度を求めようという路線、後者は回転後負荷行列の性質を調べる路線(たとえば単純構造が得られたかどうかとか)、という感じかしらん?
えーと、自分で書いててよくわかんなくなってきたので、このへんで。
潜在ディリクレ配分のトピック数を手軽に決める方法 (Rのldatuningパッケージが提供する謎の4つの指標について)
2017年8月19日 (土)
Rのdplyrパッケージを使っていて困ることのひとつに、非標準評価(NSE)をめぐるトラブルがある。dplyrの関数のなかでは変数名を裸で指定できることが多い。これはとても便利なんだけど、ときにはかえって困ることもある。以前はいろんな関数に非標準評価版と標準評価版が用意されていたんだけど、最近は方針が変わったようだ。
これはきっと深い話なんだろうけど、きちんと調べている時間がない。かといって、いざ困ったときにあわてて調べているようでは追いつかない。しょうがないので、dplyrのvignettesのひとつ"Programming with dplyr"を通読してメモを取っておくことにする。Rの達人からみればつまらない情報だと思うが、すいません、純粋に自分用の覚え書きです。
●.data代名詞。たとえば...
mutate_y <- function(df){
mutate(df, y= .data$a + .data$b)
}
mutate_y(df1)
上の例ではa, bがdfの変数であることを明示している。仮に.dataをつけないと、dfの変数の中にa,bがないとき、グローバル環境にあるa,bが読まれちゃうかもしれない。
[←そうそう、そういうトラブルが時々ある。しょうがないから私は、危なそうなときはdplyrを呼ばず df$y <- df[,"a"] + df[,"b"] という風にクラシカルに書くか、関数の冒頭で stopifnot(c("a", "b") %in% colnames(df)) とトラップしていた。そうか.dataって書けばいいのか]
●quo()。たとえば、次のコードは通らない。
df <- tibble(
g1 = c(1,1,2,2,2),
a = sample(5)
)
my_summarize <- function(df, group_var){
df %>%
group_by(group_var) %>%
summarize(a = mean(a))
}
# my_summarize(df, g1) はだめ
# my_summarize(df, "g1") もだめ
そこで、関数にquosureを渡す。quo()は入力を評価せずクオートし、quosureと呼ばれるオブジェクトを返す。!!は入力をアンクオートする。UQ()と書いてもよい。
my_summarize <- function(df, group_var){
df %>%
group_by(!!group_var) %>%
summarize(a = mean(a))
}
my_summarize(df, quo(g1))
●enquo()。上の例で、関数に裸の変数名を渡したいとしよう。enquo()は謎の黒魔術を用い(ほんとにそう書いてある)、ユーザが関数に与えた引数そのもの(ここではg1という変数名)をクオートしてくれる。
my_summarize <- function(df, group_by){
group_by <- enquo(group_by)
df %>%
group_by(!!group_var) %>%
summarize(a = mean(a))
}
my_summarize(df, g1)
●quo_name()。たとえば
mutate(df, mean_a = mean(a), sum_a = sum(a))
mutate(df, mean_b = mean(b), sum_b = sum(b))
というようなのを関数にしたい。つまり、mean_a, sum_aといった新しい変数名を生成したいわけだ。こういうときはquo_name()でquosureを文字列に変換する。mutate()のなかの式の左辺で!!を使った時は、=ではなく:=を使う。
mu_mutate <- function(df, expr){
expr <- enquo(expr)
mean_name <- paste0("mean_", quo_name(expr))
mutate(df, !!mean_name := mean(!!expr)
}
my_mutate(df, a)
●enquos()。下の例では複数の裸の変数名を渡している。enquos()は...をquosureのリストにして返す。!!!はquosureのリストをアンクオートしてつないでくれる(これをunquote-splicingという)。UQS()と書いても良い。
my_summarize <- function(df, ...){
group_var <- enquos(...)
df %>%
group_by(!!!group_var ) %>%
summarize(a = mean(a))
}
my_summarize(df, g1, g2)
こうして書いてみると一見ややこしいけど、SASマクロ言語のクオテーションと比べれば全然わかりやすい。ああ、懐かしい...あれはほんとに、ほんとにわけがわからなかった...
ところで、vignetteにいわく、疑似クオテーション(quasiquotation)という概念は哲学者W.V.O.クワインの40年代の著述に由来するのだそうだ。へえええ?
2020/01/22 ちょっぴり追記。
2017年8月17日 (木)
Prelec, et al.(2017, Nature) の自分向け徹底解説、最終回。前回は、世界の数と知識の状態の数が等しいとき、回答から正解を導く方法が示された。今回はこれを、世界の数と知識の状態の数が異なる場合へと一般化する部分である... はずだ。
前回までのあらすじ
いまここに$m$個の可能世界がある。私たちはどの世界が現実なのかを知らない。そこで、$m$個の選択肢を提示し、いずれが正しいと思うかを人々に投票させる。その結果に基づき、どの可能世界が現実かを同定したい。
- 世界を確率変数$A$で表す。$A$は$m$個の可能世界$\{a_1, \ldots, a_m\}$を値としてとる。そのうち現実世界を$a_{i*}$とする。
- 個々の対象者の知識を、プライベートな「シグナル」$S$とみなす(特に明示したい場合は、対象者$r$が持っているシグナルを$S^r$と表記する)。対象者間の知識の差異はすべてシグナルで表現されていると考える。$S$はカテゴリカル確率変数で、値として$\{s_1, \ldots, s_n\}$をとる。任意の$k=\{1,\ldots,n\}$について$Pr(S = s_k) > 0$とする。
- 世界$a_i$の下で、異なる対象者のシグナルは独立に確率分布$Pr(S = s_k | A = a_i)$に従うと考える。
- 世界についての事前分布を$Pr(A=a_i)$とする。この事前分布は、すべての回答者の共通知識である証拠と整合的な確率を与えていると考える。任意の$i=\{1,\ldots,m\}$について$Pr(A=a_i) > 0$とする。
- 対象者は同時確率$Pr(S = s_k, A=a_i)$を知っていると想定する。この同時確率が可能世界モデルを定義している。しかし人々は、どの$a_i$が正解$a_{i*}$なのかを知らないし、シグナルの実際の分布も知らない。
- 対象者$r$の、「いずれが正しいと思うか」投票を$V^r$とする。$V^r$は$S^r$の関数であり、値として$\{v_1, \ldots, v_m \}$をとる。
- [定理1] 実際のシグナルの分布についての知識$Pr(S = s_k | A=a_i*)$と、それらのシグナルによって示唆される事後確率 $Pr(A=a_i | S = s_k)$に依存するアルゴリズムからは、正解は演繹できない。
- [定理2] $m=2, n \geq 2$のとき、任意の$s_j$について$Pr(V=v_{i*} | S=s_j) \leq Pr(V=v_{i*}| A=a_{i*})$であり、$Pr(A=a_{i*}| S=s_j)$のときに限り等号が成り立つ。つまり、個々の選択肢への投票の推定値の平均は、正解について過小評価となる。
- [定理3] $m=n, V(S=s_i) = v_i, Pr(A=a_i | S=s_i) > Pr(A=a_i | S=s_j)$とする。答え$a_k$への予測規準化投票$\bar{V}(k)$を以下のように定義する。
$\displaystyle \bar{V}(k) = Pr(V = v_k | A = a_{i*}) \sum_i \frac{Pr(V^q = v_i|S^r=s_k)}{Pr(V^q=v_k|S^r=s_i)}$
ただし$0 / 0 \equiv 0$。このとき、正解はもっとも高い予測規準化投票を持つ答えである。
世界が3つ以上、シグナルが2つの場合
以下では、世界が3つ以上、シグナルは2つの場合について考える。ここでは、シグナルは偏りのあるコインのトスのようなものである。
ある$a_i$について、ベイズの定理より、
$Pr(S = s_1 | A = a_i) = Pr(A = a_i | S = s_1) Pr(S=s_1) / Pr(A=a_i)$
$Pr(S = s_2 | A = a_i) = Pr(A = a_i | S = s_2) Pr(S=s_2) / Pr(A=a_i)$
比をとって
$\displaystyle \frac{Pr(S = s_1 | A = a_i)}{Pr(S = s_2 | A = a_i)}$
$\displaystyle = \frac{Pr(A = a_i | S = s_1) Pr(S=s_1)}{Pr(A = a_i | S = s_2) Pr(S=s_2)}$
分子と分母を$P(S=s_1)P(S=s_2)$で割って
$\displaystyle = \frac{Pr(A = a_i | S = s_1) /Pr(S=s_2)}{Pr(A = a_i | S = s_2) /Pr(S=s_1)}$
分子と分母に$Pr(S^q = s_1, S^r=s_2)=Pr(S^q = s_2, S^r=s_1)$を掛けて
$\displaystyle = \frac{Pr(A = a_i | S = s_1) Pr(S^q = s_1, S^r=s_2)/Pr(S=s_2)}{Pr(A = a_i | S = s_2)Pr(S^q = s_2, S^r=s_1) /Pr(S=s_1)}$
$\displaystyle = \frac{Pr(A = a_i | S = s_1) Pr(S^q = s_1 | S^r=s_2)}{Pr(A = a_i | S = s_2)Pr(S^q = s_2 | S^r=s_1)}$
つまり、私たちはコインの偏りそのものは知らないけれど、世界についての事後確率とペアワイズの予測を通じて、コインの偏りを推測することはできるわけである。
対象者に自分のコイントスの結果を報告してもらうとしよう。その結果は、$Pr(S=s_1|a_{i*})$と$Pr(S=s_2|a_{i*})$に収束するだろう。従って
$\displaystyle i = i* \Leftrightarrow \frac{Pr(A = a_i | S = s_1) Pr(S^q = s_1 | S^r=s_2)}{Pr(A = a_i | S = s_2)Pr(S^q = s_2 | S^r=s_1)} = \frac{Pr(S=s_1|a_{i*})}{Pr(S=s_2|a_{i*})}$
[ちょっ、ちょっと待って! これは定理2や定理3とどういう関係にあるの? 同じことを言っているの、それとも違う話なの?! わからなーい...]
[ここから逐語訳...]
具体例を挙げよう。3枚のコインを想定する。アプリオリには等しくもっともらしい。(A) 2:1でオモテが出やすいコイン。(B) 2:1でウラが出やすいコイン。(C) 偏りのないコイン。
実際のコインは(C)だとしよう。対象者は、自分のトス、(A)(B)(C)の事後確率、トスの予測分布を報告する。トスの報告は表と裏が五分五分となる結果に収束する。そこから、分析者は実際のコインが偏りのないコインであることを学ぶ。しかし、(A)(B)(C)のどれが偏りのないコインなのかを分析者はまだ知らない。[←ここの意味がわからない...]
対象者は、自分のトスにベイズの規則を適用し、事後確率を引き出して報告する。トスが表であった対象者にとっての(A)(B)(C)の事後確率は(4/9, 2/9, 1/3)であり、トスが裏であった対象者にとっての(A)(B)(C)の事後確率は(2/9, 4/9, 1/3)である。この情報によって、いまや分析者は(A)(B)(C)の正確な事後分布を知る。しかし、定理1が示しているように、こうした事後確率分布としてどんな分布が手に入ったとしても、それは3種類のコインのどれとでも整合可能である。
ここで、予測を付け加えることで現実世界を同定できる。上の例の場合、想定が対称的であるから、対象者の予測もまた対称的である。すなわち$p(s_j|s_k)=p(s_j|s_k)$である[←これ、なにかの誤植じゃないかなあ...]。予測と事後確率に基づき、分析者はそれぞれの可能なコインのバイアスを計算できる。ここで、コイン(C)は偏りのないコインであり、計算されたバイアスと実際のバイアスが一致する唯一のコインである。従って分析者は、実際のコインは(C)に違いないと演繹する。
[すいません、逐語訳しましたが、やっぱりわかりません... 話の主旨はわかるが、定理2, 定理3との関係がつかめない]
世界が3つ以上、シグナルが3つ以上
同じ方法が、シグナルが2つよりも多い一般的な場合にもあてはまる。しかし、elicitationがシグナルと世界の可能な状態と分離するという点が重要である。対象者はシグナルを報告し、シグナルを予測し、世界の状態に事後確率を付与する。
...というわけで、Prelec, et al. (2017) のSupplementary Informationを四回にわたってゆっくり読み進めてきたのだが、大変残念なことに、第四回の後半から途方に暮れた。一行一行は理解できるのだが、話の流れがつかめないのである。能力が足りないと云わざるを得ない。哀しい。
ま、ほとぼりが冷めたら、また読み直してみよう。ないし、誰かが私レベルに向けてわかりやすく解説して下さるのを待とう。
Prelec, et al.(2017, Nature) の自分向け徹底解説、第三回。前回は、世界が2つ、知識の状態が2つ以上の場合に「みんなが思うよりも意外に多い回答は正しい」ことが示された。今回は、これを世界が3つ以上の場合へと一般化する部分である。
前回までのあらすじ
いまここに$m$個の可能世界がある。私たちはどの世界が現実なのかを知らない。そこで、$m$個の選択肢を提示し、いずれが正しいと思うかを人々に投票させる。その結果に基づき、どの可能世界が現実かを同定したい。
- 世界を確率変数$A$で表す。$A$は$m$個の可能世界$\{a_1, \ldots, a_m\}$を値としてとる。そのうち現実世界を$a_{i*}$とする。
- 個々の対象者の知識を、プライベートな「シグナル」$S$とみなす(特に明示したい場合は、対象者$r$が持っているシグナルを$S^r$と表記する)。対象者間の知識の差異はすべてシグナルで表現されていると考える。$S$はカテゴリカル確率変数で、値として$\{s_1, \ldots, s_n\}$をとる。任意の$k=\{1,\ldots,n\}$について$Pr(S = s_k) > 0$とする。
- 世界$a_i$の下で、異なる対象者のシグナルは独立に確率分布$Pr(S = s_k | A = a_i)$に従うと考える。
- 世界についての事前分布を$Pr(A=a_i)$とする。この事前分布は、すべての回答者の共通知識である証拠と整合的な確率を与えていると考える。任意の$i=\{1,\ldots,m\}$について$Pr(A=a_i) > 0$とする。
- 対象者は同時確率$Pr(S = s_k, A=a_i)$を知っていると想定する。この同時確率が可能世界モデルを定義している。しかし人々は、どの$a_i$が正解$a_{i*}$なのかを知らないし、シグナルの実際の分布も知らない。
- 対象者$r$の、「いずれが正しいと思うか」投票を$V^r$とする。$V^r$は$S^r$の関数であり、値として$\{v_1, \ldots, v_m \}$をとる。
- [定理1] 実際のシグナルの分布についての知識$Pr(S = s_k | A=a_i*)$と、それらのシグナルによって示唆される事後確率 $Pr(A=a_i | S = s_k)$に依存するアルゴリズムからは、正解は演繹できない。
- [定理2] $m=2, n \geq 2$のとき、任意の$s_j$について$Pr(V=v_{i*} | S=s_j) \leq Pr(V=v_{i*}| A=a_{i*})$であり、$Pr(A=a_{i*}| S=s_j)$のときに限り等号が成り立つ。つまり、個々の選択肢への投票の推定値の平均は、正解について過小評価となる。
補題
補題. $m$個の答え、$n$個のシグナル、同時分布$p(S=s_j, A=a_i)$からなる、ある可能世界モデルについて考える。正解を$a_{i*}$とすると、
$\displaystyle Pr(A=a_{i*}|S=s_k) \propto Pr(S=s_k|A=a_{i*}) \sum_i \frac{Pr(S^q=S_i|S^r=s_k)}{Pr(S^q=S_k|S^r=s_i)}$
ただし$0 / 0 \equiv 0$。
証明。任意の2名$r, q$のシグナルの同時分布について考える。
$Pr(S^q=s_k, S^r=s_i) = Pr(S^q=s_k|S^r=s_i)P(S^r=s_i)$
$Pr(S^q=s_i, S^r=s_k) = Pr(S^q=s_i|S^r=s_k)P(S^r=s_k)$
$r$と$q$のシグナルを入れ替えても確率は同じ、すなわち$Pr(S^q=s_k, S^r=s_i)=Pr(S^q=s_i, S^r=s_k)$だから、上の2本の式の右辺は等しく
$Pr(S^q=s_k|S^r=s_i)P(S^r=s_i) = Pr(S^q=s_i|S^r=s_k)P(S^r=s_k)$
移項する。$P(S^r=s_i)$は$r$を$q$に書き換えても同じことだから$P(S=s_i)$ と略記して、
$\displaystyle P(S=s_i) = P(S=s_k)\frac{Pr(S^q=s_i|S^r=s_k)}{Pr(S^q=s_k|S^r=s_i)}$
両辺を$i$を通じて合計すると、左辺の合計は1になるから、
$P(S=s_k) = \left( \sum_i \frac{Pr(S^q=s_i|S^r=s_k)}{Pr(S^q=s_k|S^r=s_i)} \right)^{-1}$
これを(1)とする。
さて、ベイズの定理から
$Pr(A=a_{i*}|S=s_k)$
$\displaystyle = \frac{p(S=s_k | A=a_{i*}) Pr(A=a_{i*})}{Pr(S=s_k)}$
(1)を分母に代入して
$\displaystyle = Pr(S=s_k|A=a_{i*}) \sum_i \frac{Pr(S^q=S_i|S^r=s_k)}{Pr(S^q=S_k|S^r=s_i)} Pr(A=a_{i})$
ここで$Pr(A=a_{i})$は$k$を通じて定数だから、補題が成り立つ。証明終。
この補題が示しているのはこういうことだ。シグナルの分布$Pr(S=s_k|A=a_{i*})$と、シグナルのペアワイズ予測$Pr(S^q=S_i|S^r=s_k), Pr(S^q=S_k|S^r=s_i)$から、もっともinformedな回答者たちが支持する答えを特定できる。ここでinformedというのは、正解に最大の確率を付与しているという意味である。それらの対象者は、仮に正解が明らかになったとしてもっとも驚かない人々である。
[いやー、ここ、難しい。証明自体は納得できるけど、式がなにを意味しているのかがつかみにくい。我慢して先に進もう]
定理3
$m=n, V(S=s_i) = v_i, Pr(A=a_i | S=s_i) > Pr(A=a_i | S=s_j)$とする。正解を$a_{i*}$とする。答え$a_k$への予測規準化投票$\bar{V}(k)$を以下のように定義する。
$\displaystyle \bar{V}(k) = Pr(V = v_k | A = a_{i*}) \sum_i \frac{Pr(V^q = v_i|S^r=s_k)}{Pr(V^q=v_k|S^r=s_i)}$
ただし。$0 / 0 \equiv 0$。このとき、正解は、もっとも高い予測規準化投票を持つ答えである。
証明。$V(S=s_i)=v_i$だから、補題
$\displaystyle Pr(A=a_{i*}|S=s_k) \propto Pr(S=s_k|A=a_{i*}) \sum_i \frac{Pr(S^q=S_i|S^r=s_k)}{Pr(S^q=S_k|S^r=s_i)}$
は以下のように書き換えることができる。
$\displaystyle Pr(A=a_{i*}|S=s_k) \propto Pr(V^r=v_k|A=a_{i*}) \sum_i \frac{Pr(V^q=v_i|S^r=s_k)}{Pr(V^q=v_k|S^r=s_i)} = \bar{V}(k)$
さて左辺について、
$Pr(A=a_i | S=s_i) > Pr(A=a_i | S=s_j)$
より
$Pr(A=a_{i*} | S=s_{i*}) > Pr(A=a_{i*} | S=s_k)$
である。よって$\bar{V}(i*) > \bar{V}(k)$である。証明終。
対象者数が無限大の時、$Pr(V=v_k | A=a_{i*})$は$a_k$への投票の割合である。また、$Pr(V^q=v_k | S^r=s_i)$は、$a_i$に投票した人々による「何割の人が$a_k$に投票するか」予測の平均である。
[こうしてゆっくり読んでみると、定理3の証明に、定理2は使われてないんですね。
定理3が定理2の一般化なのだとしたら、$m=n=2$の場合には、定理2と定理3は同じことを意味しているのだろうか。つまり、
$Pr(V = v_1 | A = a_{i*}) \left(1+ \frac{Pr(V^q = v_2|S^r=s_1)}{Pr(V^q=v_1|S^r=s_2)} \right) > Pr(V = v_2 | A = a_{i*}) \left(1+ \frac{Pr(V^q = v_1|S^r=s_2)}{Pr(V^q=v_2|S^r=s_1)} \right) $
は
$Pr(V^q= v_1 | S^r = s_j) \leq Pr(V=v_1 | A=a_{i*})$ for any $j$
と同値なのか。式をあれこれ変形してみたのだが、どうも同値ではないような気がしてならない... 数学ができないとは悲しいもので、残念ながらどこかでなにかを間違えているような気もする。なんだか疲れちゃったので、また日を改めてチャレンジしたい]
Prelec, et al.(2017, Nature) の自分向け徹底解説、第二回。「意外に一般的」原理、すなわち「みんなが思うよりも意外に多い」回答は正しいということを最初に示す、この論文のキモになる部分である。
前回までのあらすじ
いまここに$m$個の可能世界がある。私たちはどの世界が現実なのかを知らない。そこで、$m$個の選択肢を提示し、いずれが正しいと思うかを人々に聴取し、その回答から、どの可能世界が現実かを同定したい。
- 世界を確率変数$A$で表す。$A$は$m$個の可能世界$\{a_1, \ldots, a_m\}$を値としてとる。そのうち現実世界を$a_{i*}$とする。
- 個々の対象者の知識を、プライベートな「シグナル」$S$とみなす(特に明示したい場合は、対象者$r$が持っているシグナルを$S^r$と表記する)。対象者間の知識の差異はすべてシグナルで表現されていると考える。$S$はカテゴリカル確率変数で、値として$\{s_1, \ldots, s_n\}$をとる。任意の$k=\{1,\ldots,n\}$について$Pr(S = s_k) > 0$とする。
- 世界$a_i$の下で、異なる対象者のシグナルは独立に確率分布$Pr(S = s_k | A = a_i)$に従うと考える。
- 世界についての事前分布を$Pr(A=a_i)$とする。この事前分布は、すべての回答者の共通知識である証拠と整合的な確率を与えていると考える。任意の$i=\{1,\ldots,m\}$について$Pr(A=a_i) > 0$とする。
- 対象者は同時確率$Pr(S = s_k, A=a_i)$を知っていると想定する。この同時確率が可能世界モデルを定義している。しかし人々は、どの$a_i$が正解$a_{i*}$なのかを知らないし、シグナルの実際の分布も知らない。
- [定理1] 実際のシグナルの分布についての知識$Pr(S = s_k | A=a_i*)$と、それらのシグナルによって示唆される事後確率 $Pr(A=a_i | S = s_k)$に依存するアルゴリズムからは、正解は演繹できない。
さあ、今回はどんなややこしい話が待ち受けているでしょうか。元気を出して行ってみよう!!!
新たなるセッティング
対象者$r$の、「いずれが正しいと思うか」投票を$V^r = V(S=S^r)$とする。$V^r$は値として$\{v_1, \ldots, v_m \}$をとる。
対象者の投票はシグナルの関数だから、シグナル$s_k$を受け取った理想的対象者$r$は、他の対象者$q$が$a_i$に投票する条件つき確率$Pr(V^q=v_i | S^r=s_k)$を算出できる。
その算出方法の例を挙げよう。いま、シグナル$s_j$を受け取った人は、可能世界のなかから条件つき確率$p(a_i | s_j)$が最大である可能世界を選びその可能世界に投票するのだとしよう。すなわち
$V(S=s_j) = argmax_i Pr(A=a_i | S=s_j)$
この場合、他の対象者$q$が$a_i$に投票する条件つき確率$Pr(V^q=v_i | S^r=s_k)$は、$a_i$への投票につながるような証拠を$q$が受け取る確率の合計である。すなわち
$Pr (V^q = v_i | S^r = s_k)$
$\displaystyle = \sum_{j: V(s_j) = v_i} Pr(S^q=s_j | S^r=s_k)$
$\displaystyle = \sum_{i = argmax_k Pr(A=a_k | S=s_j)} Pr(S^q=s_j | S^r=s_k) $
[落ち着け、ここはそんなにヤヤコシイことは言っていない。要するに、もし「人々はどういうシグナルを受け取るとどういう投票をするのか」がわかっているなら、自分が受け取ったシグナルから世界についての事後分布を求め、他人が受け取ったシグナルについての事後分布を求め、他人の投票についての事後分布を求めることが出来るはずだよね、という話だ。2行目のサメーションのインデクスに出てくる$k$は、項のなかに出てくる$k$とは別の記号だと思う]
同様に、ある人の投票と可能世界との同時確率も定義できる。
$Pr(V=v_i, A=a_k) = \sum_{j: V(s_j) = v_i} Pr(S=s_j, A=a_k)$
[原文では右辺は$\sum p(s_j, a_j)$だが、$a_j$は$a_k$の誤植だと考え書き換えた]
「意外に一般的」原理:世界が2つ、シグナルが2つ以上の場合
以下では、世界は2つ、シグナルは2つ以上の場合について、「みんなが思うよりも意外に多い回答は正しい」ことを証明する。
上では簡単な投票ルール
$\displaystyle V(s_j) = argmax_i p(A=a_i | S=s_j)$
を考えたが、もうちょっと一般化しよう。
世界を2つとし、各世界に対するカットオフ $c_1, c_2$(合計1)を考えて
$\displaystyle V(s_j) = argmax_i c^{-1}_i Pr(A=a_i | S=s_j)$
とする。$c_1=c_2=0.5$だったらさっきの投票ルールと同じである。
定理2. 全員が正解に投票するわけではないとしよう。このとき、正解に対する投票の平均推定値は過小評価される。
[つまり、島根が西にある世界においては、「島根が西」への他人の投票の推測は過小評価される]
証明:(まずは原文を逐語的にメモする)
We first show that actual votes for the correct answer exceed conterfactual votes for the correct answer, $p(v_{i*}|a_{i*}) > p(v_{i*}|a_k) , k \neq i*$, as:$\displaystyle \frac{p(v_{i*}|a_{i*})}{ p(v_{i*}|a_k)}= \frac{p(a_{i*}|v_{i*}) p(a_k)} {p(a_k|v_{i*}) p(a_{i*})}= \frac{p(a_{i*}|v_{i*})} {1- p(a_{i*}|v_{i*}) } \frac{1-p(a_{i*})}{ p(a_{i*}) }$
The fraction on the right is well defined as $0 < p(a_{i*}|v_{i*}) < 1$; it is greater than one if and only if $p(a_{i*}|v_k) > p(a_{i*}|v_{i*}) p( v_{i*} ) + p(a_{i*}|v_k) p( v_k ) = p(a_{i*})$, as $p(a_{i*}|v_{i*}) > c_{i*}, p(a_{i*}|v_k) < c_{i*}$ by definition of the criterion based voting function.
[深呼吸してゆっくり考えましょう。
表記を簡単にするために、仮に$a_1$が現実(原文の$a_{i*}$), $a_2$が反事実(原文の$a_k$)だということにする。
著者らが上記部分でいわんとしているのは、「現実のもとで現実に投票する確率は、反事実のもとで現実に投票する確率よりも大きい」、すなわち
$Pr(V=v_1 | A=a_1) > Pr(V=v_1|A=a_2)$
ということだ。なぜか。
条件付き確率の定義から、
$\displaystyle Pr(V=v_1 | A=a_1) = \frac{Pr(V=v_1 , A=a_1)}{Pr(A=a_1)} = \frac{Pr(A=a_1 | V=v_1) Pr(V=v_1)}{Pr(A=a_1)}$
$\displaystyle Pr(V=v_1 | A=a_2) = \frac{Pr(V=v_1 , A=a_2)}{Pr(A=a_2)} = \frac{Pr(A=a_2 | V=v_1) Pr(V=v_1)}{Pr(A=a_2)} $
であるから、
$\displaystyle \frac{Pr(V=v_1 | A=a_1)}{ Pr(V=v_1 | A=a_2) } = \frac{Pr(A=a_1 | V=v_1) Pr(A=a_2)}{Pr(A=a_2 | V=v_1) Pr(A=a_1)} $
である。$P= Pr(A=a_1 | V=v_1), Q= Pr(A=a_1) $と置けば
$\displaystyle = \frac{P(1-Q)}{(1-P)Q}$
である。
いま
$\displaystyle \frac{P(1-Q)}{(1-P)Q} > 1$
を解くと$P > Q$である。従って、
$Pr(V=v_1 | A=a_1) > Pr(V=v_1|A=a_2) \Leftrightarrow Pr(A=a_1 | V=v_1) > Pr(A=a_1)$
である。これを(1)としよう。
$Pr(A=a_1)$を投票で場合分けすると
$Pr(A=a_1) = Pr(A=a_1 | V=v_1) Pr(V=v_1) + Pr(A=a_1 | V=v_2) Pr(V=v_2)$
であるから、
$ Pr(A=a_1 | V=v_1) - Pr(A=a_1) $
$ = Pr(A=a_1 | V=v_1) (1- Pr(V=v_1)) - Pr(A=a_1 | V=v_2) Pr(V=v_2)$
$ = (1- Pr(V=v_1)) \{ Pr(A=a_1 | V=v_1) - Pr(A=a_1 | V=v_2) \}$
と書ける。$Pr(V=v_1) < 1$なので(全員が正解に投票するわけではないから)、結局
$Pr(A=a_1 | V=v_1) - Pr(A=a_1) > 0 \Leftrightarrow Pr(A=a_1 | V=v_1) - Pr(A=a_1 | V=v_2) > 0$
(1)とあわせると
$Pr(V=v_1 | A=a_1) > Pr(V=v_1|A=a_2) \Leftrightarrow Pr(A=a_1 | V=v_1) > Pr(A=a_1 | V=v_2)$
ということになる。ぜぇぜぇ。これを(2)としよう。
投票ルールの定義により、所与のシグナル$S=s_k$の下で$V=v_1$である必要十分条件は
$Pr(A=a_1|S=s_k)/c_1 > Pr(A=a_2|S=s_k))/c_2$
$d=Pr(A=a_1|S=s_k)$と置くと
$d/c_1 > (1-d)/(1-c_1)$
$(1-c_1)d > c_1(1-d)$
$d-c_1d > c_1 - c_1d$
$d > c_1$
従って、所与のシグナル$S=s_k$の下で
$V=v_1 \Leftrightarrow Pr(A=a_1|S=s_k) > c_1$
である。同様に、
$V=v_2 \Leftrightarrow Pr(A=a_1|S=s_k) < c_1$
ということは、任意の$s_k$の下で
$Pr(A=a_1 | V=v_1) = Pr(A=a_1 | Pr(A=a_1|S=s_k) > c_1) > c_1$
$Pr(A=a_1 | V=v_2) = Pr(A=a_1 | Pr(A=a_1|S=s_k) < c_1) < c_1$
従って$Pr(A=a_1 | V=v_1) > Pr(A=a_1 | V=v_2)$である。
これは(2)の右側の条件である。従って、左側の条件
$Pr(V=v_1 | A=a_1) > Pr(V=v_1|A=a_2)$
も成り立つ... ということだと思う。
A respondent with signal $s_j$ computes excected votes by marginalizing across the two possible worlds, $p(v_{i*}|s_j) = p(v_{i*}|a_{i*}) p(a_{i*}|s_j) + p(v_{i*}|a_k) p(a_k|s_j)$. The actual vote for the correct answer is no less than the counterfactual vote, $p(v_{i*}|a_{i*}) \geq p(v_{i*}|a_k)$.
Therefore, $p(v_{i*}|s_j) \leq p(v_{i*}|a_{i*})$, with strict inequality unless $p(a_{i*}|s_j) = 1$. Because weak inequality holds for all signals, and is strict for some, the average predicted vote will be strictly underestimated. (QED)
[シグナル$S=s_j$を持つ対象者$r$が計算する他人$q$の投票についての確率$Pr(V^q=v_1|S^r=s_j)$は、世界で場合分けして
$Pr(V^q=v_1|S^r=s_j) $
$= Pr(V^q=v_1|A=a_1)Pr(A=a_1|S^r=s_j) + Pr(V^q=v_1|A=a_2)Pr(A=a_2|S^r=s_j)$
式を簡単にするために$c=Pr(A=a_1|S^r=s_j)$と置くと
$= c Pr(V^q=v_1|A=a_1) + (1-c)Pr(V^q=v_1|A=a_2)$
つまり、他人が$a_1$に投票する確率$Pr(V^q=v_1|S^r=s_j)$は、正解が$a_1$であるときに他人が正解に投票する確率$Pr(V^q=v_1|A=a_1)$と、正解が$a_2$であるときに他人が正解に投票する確率$Pr(V^q=v_1|A=a_2)$のあいだのどこかの値となる。正解が$a_1$である確率$c=Pr(A=a_1|S^r=s_j)$がその位置を決めているわけである。
さて、この2つの確率について上で苦労して検討した結果、$Pr(V^q=v_1|A=a_1) > Pr(V^q=v_1|A=a_2)$であることがわかっている(原文では$\geq$となっているが、誤植と考え書き換えた)。
ということは、
$c=1$のときに$Pr(V^q=v_1|S^r=s_j) = Pr(V^q=v_1|A=a_1)$
$c < 1$のときに$Pr(V^q=v_1|S^r=s_j) < Pr(V^q=v_1|A=a_1)$
である。$c=Pr(A=a_1|S^r=s_j)$は$s_j$によっては1でありうるが、その場合でも残りの$s_j$については0である。従って、対象者が所与のシグナルの下で計算するところの「他人が正解に投票する確率」$Pr(V^q=v_1|S^r=s_j)$は、対象者を通じて平均すると、実際の「他人が正解に投票する確率」$Pr(V^q=v_1|A=a_1)$より小さくなる。
すなわち、「みんなが思うよりも意外に多い」回答は正解である。]
以上、p.5までの内容でありました。先は長い... くじけそう...
島根と鳥取、西側にあるのはどっちだろうか。あいにく地図が手元になく正解がわからない。そこで、たくさんの人に対してアンケートを行い、その回答の集計から正解を導きたい。
このとき、多数決はよろしくない。たとえば、西側にあるのはどっちだと思うかと人々に尋ねたところ、島根の得票率が4割、鳥取の得票率が6割となったとしよう。だからといって、鳥取が西側にある、と考えるのはよろしくない。
人々の知恵をうまく集約するには、むしろ次のように集計するのが良い。人々に2問尋ねる。(1)西側にあるのはどっちか。(2)自分と同じ回答をする人は何割いるか。で、「みんなが思うよりも意外に多い」回答が正解だと考える。
たとえば、(1)の回答で島根の得票率が4割であったとしよう。かつ、(2)の回答(得票率の予測)を平均すると島根が3割であったとしよう。つまり、「島根が西だ」という回答は全体の3割くらいだろうと人々は思ったが、実際には4割だったわけだ。このとき、「島根が西」説は少数派ではあるけれど、ほんとうは島根が西だと判断すべきだ。
... というのが、Prelec, Seung, & McCoy (2017, Nature)の主張である。
わたくし、ここ何年も、足りない頭でこの問題を考え続けているのだが、正直なところ、いまだにキツネにつままれたような思いが消えない。
なぜ「みんなが思うよりも意外に多い」回答が正解なのか? 以下ではその徹底的な解説を試みる。
なお、元ネタは上記論文のSupplementary Information pp.1-8 である。4回にわけてゆっくり読み進めることにする。改めていうまでもないことだが、主たる想定読者は私自身である。
セッティング
いまここに$m$個の可能世界がある。うちひとつが現実である。私たちはどの世界が現実なのかを知らない。そこで、$m$個の選択肢を提示し、いずれが正しいと思うかを人々に聴取し、その回答から、どの可能世界が現実かを同定したい。
世界を確率変数$A$で表す[原文にはない記号だが、わかりやすくするために付け加えた]。$A$は$m$個の可能世界$\{a_1, \ldots, a_m\}$を値としてとる。[ここでは、$a_1$を「島根が西にある世界」, $a_2$を「鳥取が西にある世界」としよう]
対象者$r$が持っている証拠を、プライベートな「シグナル」$S^r$とみなす。対象者間の知識の差異はすべてシグナルで表現されていると考える。$S^r$はカテゴリカル確率変数で、値として$\{s_1, \ldots, s_n\}$をとる。[ここでは、$s_1$を「島根が西だと学校で教わった」, $s_2$を「鳥取が西だと友達に教わった」, $s_3$を「鳥取って西っぽいと思う」としよう。ある人の知識状態はこの3つのうちどれかひとつだ]
世界$a_i$の下で、異なる対象者のシグナルは独立に確率分布$Pr(S = s_k | A = a_i)$に従うと考える。[原文では$p(s_k | a_i)$と略記されているのだが、理解を確かめるために、以下いちいち確率変数名を補完して書き直す。縦棒左側の$s_k$は、ここでは$r$さんに限らずすべての人に与えられるシグナルを指しているのだと思うので、原文にそんな表記は出てこないけど$S$と書くことにする]
世界についての事前分布を$Pr(A=a_i)$とする。この事前分布は、すべての回答者の共通知識である証拠と整合的な確率を与えていると考える。[ここでの例でいうと、仮に知識ゼロの状態だったら、島根が西だと思うか鳥取が西だと思うかの信念の程度には個人差がない]
対象者は同時確率$Pr(S = s_k, A=a_i)$を知っていると想定する($Pr(A=a_i), Pr(S = s_k)$はともに0より大とする)。この同時確率が可能世界モデルを定義している。しかし人々は、どの$a_i$が正解($a_{i*}$)かを知らないし、シグナルの実際の分布も知らない。[すべての対象者は、こころのなかに表1aを持っている。この表自体には個人差はない。でも、人は自分が上の行の地球に生きているのか下の行の地球に生きているのかを知らない。また、この表のほかに、自分が何を知っているかは知っている。でも他の人がどんな知識を持っているかは知らない]
対象者は2つのタイプの信念を持つ。どちらの信念も、与えられたシグナル$s_k$と、既知の同時確率$Pr(S=s_k, A=a_i)$から算出される。
- 正解についての信念$Pr(A = a_i | S = s_k)$。[表1b]
- 他の回答者が受け取っているシグナルについての信念 [表1c]。すなわち、ランダムに選ばれた他の回答者$q$について、
$Pr(S^q = s_j | S^r = s_k) = \sum_i Pr(S^q=s_j | A=a_i) Pr(A= a_i | S^r=s_k) $
[原文では右辺は$\sum_i p(s_j|a_i)p(a_i|s_k)p(a_i)$となっているのだが、最後に$p(a_i)$を掛ける理由がわからない... 大変僭越ながら誤植と捉えて取り除いている]
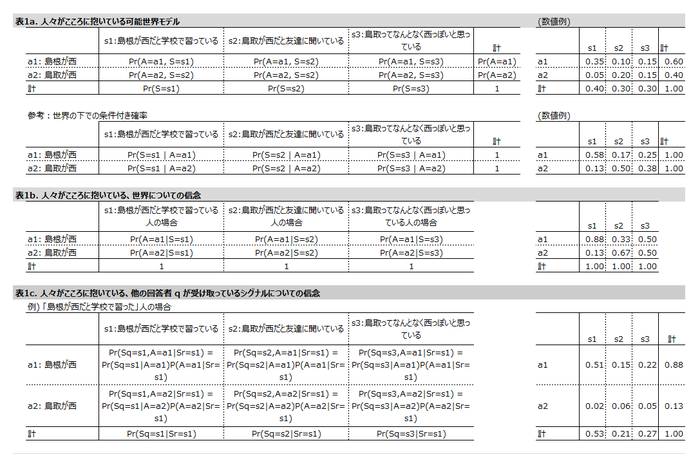
定理1
[私の理解では、ここは論文の本筋ではなく、前置きに当たる議論である]
定理1. 実際のシグナルの分布についての知識$Pr(S = s_k | A=a_i*)$と、それらのシグナルによって示唆される事後確率 $Pr(A=a_i | S = s_k)$に依存するアルゴリズムからは、正解は演繹できない。
証明:
以下では、これらのシグナル分布と、恣意的に選んだ答えについての事後確率を生成するような、ある可能世界モデルを構築することを試みる。
正解$a_{i*}$は未知、でもシグナルの分布 $Pr(S=s_k | A=a_{i*})$は既知だとしよう。また事後確率$Pr(A=a_j | S=s_k)$も既知だとしよう。[シグナルの分布を表2に示す。なお、本文で$a$の添え字が$i$じゃなくて$j$になっているのは、次の段落から$a_i$を「選択した任意の答え」という意味で用いるからではないかと思う]
任意の$a_i$を選び、それに対応する可能世界モデル$q(S=s_k, A=a_j)$を構築する。このモデルは、 $i*=i$であるときの既知のシグナル分布と事後確率を生成するものである。 [つまり、これから試したいことは、表1と表2から、表3を決めることだ。もし<島根が西バージョン>と<鳥取が西バージョン>の両方が作れたら、それは困ったことになる] 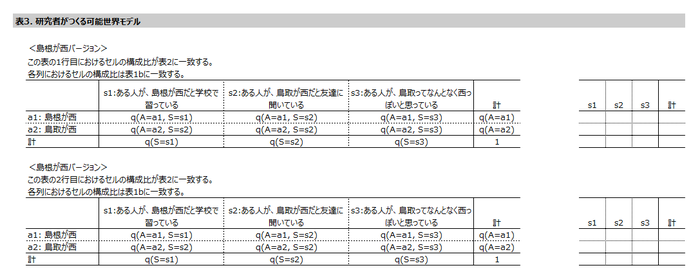 既知のパラメータはシグナルを通じた事前分布を制約していない。そこで次のように設定しよう。
既知のパラメータはシグナルを通じた事前分布を制約していない。そこで次のように設定しよう。
$\displaystyle q(S=s_k) = \frac{Pr(S=s_k | A=a_{i*})}{Pr(A=a_i | S=s_k)} \left( \sum_j \frac{Pr(S=s_j | A=a_{i*})}{Pr(A=a_i | S=s_j)} \right)^{-1}$
[第2項は$q(S=s_k)$の$k$を通じた和を1にするための規準化項。第1項の分子は表2。分母は、表1bにおけるいま選んでいる世界$a_i$の確率。なぜこう設定するのか理解できていないのだが、ここは「もし表3の列和をこう設定したら」という話がしたいだけで、意味を考えずに先に進んで良いところなのかも??? ともあれ、いま表3は下表のとおり]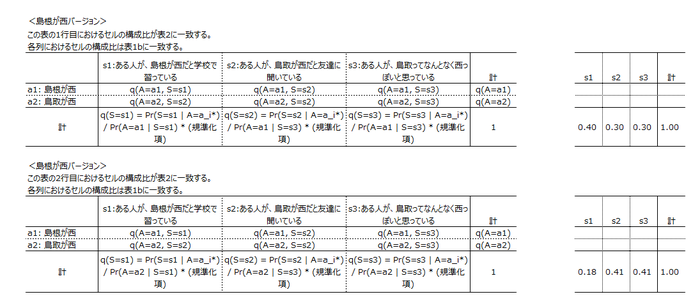 可能世界モデルから生成される事後確率は既知の事後確率と一致していないといけない。すなわち、全ての$k, j$について、
可能世界モデルから生成される事後確率は既知の事後確率と一致していないといけない。すなわち、全ての$k, j$について、
$q(A=a_j | S=s_k) = p(A=a_j | S=s_k)$
が成り立たなければならない。[表3の各列内のセル構成比が、表1bに一致していないといけない]
以上を踏まえると、可能世界モデルが次のように固定される。
$q(A=a_j, S=s_k) = q(A=a_j | S=s_k) q(S=s_k)$
この同時分布から、回答を通じた事前分布を求めることができる。まず
$q(A=a_i, S=s_k)$
$= q(A=a_i | S=s_k) q(S=s_k)$
さきほど設定した$q(S=s_k)$を代入すると、$q(A=a_i|S=s_k)=p(A=a_i|S=s_k)$が消えて
$\displaystyle = p(S=s_k | A=a_{i*}) \left( \sum_j \frac{p(S=s_j | A=a_{i*})}{p(A=a_i | S=s_j)} \right)^{-1}$
シグナルを通して合計すると
$\displaystyle q(A=a_i) = \left( \sum_j \frac{p(S=s_j | A=a_{i*}}{p(A=a_i | S=s_j)} \right)^{-1}$
こうして、可能世界モデルの周辺分布$q(S=s_k), q(A=a_i)$が手に入った。
さて、周辺分布$q(S=s_k), q(A=a_i)$、事後分布$q(a_j|s_k)=p(a_j|s_k), k=1, \ldots, n$からつぎのことがわかる。正解が$a_i$であるとき、観察されるシグナルの分布
$\displaystyle q(S=s_k | A=a_i) = \frac{q(A=a_i | S=s_k) q(S=s_k)}{q(A=a_i)}$
に、周辺分布$q(S=s_k), q(A=a_i)$を代入すると
$=p(S=s_k | A=a_{i*})$
となる。つまり、どんな$a_i$を選んでも、既知の事後分布を生成できる。証明終。
[このくだりの理路にはいまいちついていけないんだけど、こういうことじゃないかと思う。もし「島根が西」だといいたければ下表の上のような可能世界モデルを考えることができるし、「鳥取が西」だといいたければ下のような可能世界モデルを考えればよい。どちらも、表1と表2に対してつじつまが合う。いいかえると、表1と表2が決まっても、表3は決められない。] [いまこの地球上において、 「島根が西だと学校で教わった」 「鳥取が西だと友達に教わった」 「鳥取って西っぽいと思う」 のそれぞれの知識を持つ人が占める割合$Pr(S = s_k | A=a_i*)$、すなわち表2が、どうやって調べるのかわかんないけど、とにかくなんらかのすごい方法でわかったとしよう。また、島根が西である時になにが起きるか、鳥取が西である時に何が起きるかについて人々は知っており(表1)、それもなんらかのすごい方法でわかったとしよう。研究者はこの2つの表を組み合わせて、島根が西なのか鳥取が西なのかを知ることができるだろうか?
[いまこの地球上において、 「島根が西だと学校で教わった」 「鳥取が西だと友達に教わった」 「鳥取って西っぽいと思う」 のそれぞれの知識を持つ人が占める割合$Pr(S = s_k | A=a_i*)$、すなわち表2が、どうやって調べるのかわかんないけど、とにかくなんらかのすごい方法でわかったとしよう。また、島根が西である時になにが起きるか、鳥取が西である時に何が起きるかについて人々は知っており(表1)、それもなんらかのすごい方法でわかったとしよう。研究者はこの2つの表を組み合わせて、島根が西なのか鳥取が西なのかを知ることができるだろうか?
一見できそうなものだが、実は無理なのだ、だから、たとえば回答とともにその確信度を聴取してみたりして、人々の知識をいくら正確に調べようとしたところで、世界がどうなっているのかは結局わからないんだよ。というのが、この定理がいわんとしていることなのだと思う]
これでようやくp.4の半ば。先は長いぞ。
2017年1月22日 (日)
ここんとこ山のようなデータ整形を抱え込んでいて、これはほんとに終わるのかという不安と、こんなことをしていてよいのかという不安に両側から押し潰されそうだが... とにかく仕事があるだけありがたいと考えるべきか。
ともあれ、ちょっと驚いたことがあったのでメモしておく。なんだか恥をさらしているような気も致しますが。
Rで、ユニークなキーを持つとても大きなテーブルを左外部結合(LEFT JOIN)したいとき、どうするのが速いか。
思いつくのは、
- 素直にmerge()する
- merge()より高速だといわれている, Hadley神つくりたもうた dplyr::left_join() を使う
- match()で行位置を探し、テーブルの行を並び替えてくっつける
- match()で行位置を探しておき、テーブルの各変数を ひとつづ並び替えてくっつける
4番目のは一種の冗談のつもりであった。そんなん遅いにきまってるじゃん? たぶん2,1,3,4の順だろう。いやひょっとして2,3,1,4かな。私はそう思いました。
衝撃の結果は下図。クリックで拡大。Rpubsにものっけてみました。
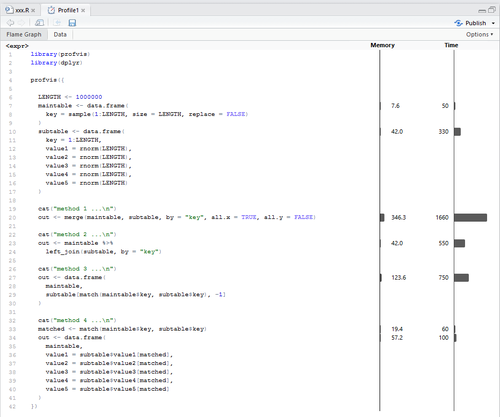
4がぶっちぎりで優勝。ぐぬぬぬ。これまでの苦労は何だったんだ。
RでどうやってLEFT JOINするか (ああなんて最先端な話題だろうか)
2016年6月10日 (金)
仕事の都合で必要になって書いたメモなんだけど、ブログに載せておこう。
二値変数を従属変数とする回帰モデルについて考える。よく使われているのはロジスティック回帰モデル
$\log(\frac{\pi(x)}{1-\pi(x)}) = \beta_0 + \beta_1 x$
だけど($\pi(x)$は生起確率ね)、リンク関数はほかにもある。諸君、視野を広く持ちたまえ。
- プロビットモデル。こいつの歴史は結構古い。係数が閉形式で表現できないのが欠点。標準正規分布関数を$\Phi$と書いて、
$\Phi^{-1}[\pi(x)] = \beta_0 + \beta_1 x$ - cloglogモデル。左裾が長めになる。
$\log[-\log(1-\pi(x))] = \beta_0 + \beta_1 x$ - loglogモデル。右裾が長めになる。
$-\log[-\log(\pi(x))] = \beta_0 + \beta_1 x$ - ログリンク関数を使っちゃう。疫学者に好まれる(係数がそのまま相対リスクになるから)。欠点としては、確率が1を超える、ML推定が収束しないことがある。お勧めはしないけど、もし使うんならポワソン回帰のプログラムを使うこと(Zou, 2004 Am.J.Epi. をみよ)。
$\log(\pi(x)) = \beta_0 + \beta_1 x$ - 線形モデルを使っちゃう。係数はリスク差になる。確率が0-1の範囲を超えるので、あんまし使われていない。お勧めはしないけど、もし使うんなら推定の際にちょっと工夫すること[重みを付けて反復推定せよとのこと。へぇー]。
$\pi(x) = \beta_0 + \beta_1 x$
どういうときにどのモデルを使うといいのか?
まず、分析の主な目的が確率の推定で、共変量の効果の推定はその次だ、という場合。こういうときは、ロジスティック回帰のかわりにプロビットやcloglogやloglogを使うのも悪くない。
分析の目的は共変量の効果の推定なんだけど、ロジスティック回帰だとオッズ比で表現されちゃうのがいやだ、という場合には、logリンクか線形モデル。
以上にあげた6つのモデルを比べる際には、とりあえずロジスティック回帰の確率推定値でケースを10群にわけ、適合を比べるのがよろしかろう。
左右対称なロジットやプロビットを使うのがよいか、非対称なcloglogやloglogを使うのがよいかを調べる方法がある。Stukel検定という、共変量を追加すべきかどうかの検定手法の応用である。残念ながらこの手法が載っているソフトはないので、手でやること。
まずロジスティック回帰をやって、ロジット推定値$\hat{g}(x)$と確率推定値$\hat{\pi}(x)$を得る。次に、次のふたつの人工的な共変量をつくる。
$z_1 = 0.5 \times [\hat{g}(x)^2] \times I[\hat{\pi}(x) \geq 0.5]$
$z_2 = -0.5 \times [\hat{g}(x)^2] \times I[\hat{\pi}(x) < 0.5]$
すべての確率推定値が0.5よりも右なり左なりだったら片方だけつくればよろしい。
で、これを追加してもう一度ロジスティック回帰モデルを推定し、係数の信頼区間を求める。もし両方の信頼区間に0.165がはいったらプロビットがよろしい。もし$z_1$の信頼区間に-0.037, $z_2$の信頼区間に0.620がはいったらloglog、逆になったらcloglogがよろしい。[←へええええええ!]
以上、Hosmer, Lemeshow, Sturdivant (2013) "Applied Logistic Regression", Third Edition, Section 10.3 より。
このメモは、amazonから届いた箱をあけて本をパラパラ捲っているときにこの章に引き込まれ、なるほどー!cloglogやloglogという選択肢も頭に置いておこう!と感心して書いたんだけど、読み返してみて思うに、自分にとっては、cloglogやloglogを使う場面ってやはりそんなにはなさそうだ。もし係数の解釈に関心がなく単に予測したいだけで、かつロジスティック回帰の予測精度が悪かったら、きっと機械学習系の手法を試すと思う。
いっぽう、ロジスティック回帰はもうイヤ!説明変数の効果はリスク差で示したいの!ああもう加法モデルにしちゃいたい!誰かボクをここから連れ出して!海辺の町に連れてって!と切実に思うことなら、それは頻繁にある。そういう哀れな分析者のためのガイドラインが欲しいんだけどなあ。加法モデルを使う際の注意点でもいいし、誤魔化しながらロジスティック回帰を使い続けるコツでもいいから。
2016年4月20日 (水)
新製品・サービスの普及プロセスを説明する古典的モデルである、Bassモデルの推定方法について、ちょっと混乱しちゃったので、覚え書きをつくっておく。個人的メモでごさいます。
そもそもBassさんが考えた理屈はこうだ。原典であるBass(1969)に沿ってメモする。
ある製品の初回購入だけに注目する。総購入個数を$m$としよう。
連続時間上の時点 $t$ における「購入の尤度」を $f(t)$ とする[わかりにくい表現だけど、ある潜在的購入者に注目したときにこの瞬間に購入が発生する確率密度、という意味合いであろう]。
$F(t)$ を以下のように定義する。
$F(t) = \int f(t) dt, \ \ F(0) = 0$
時点 $t$ における売上を $S(t)$、累積売上を $Y(t)$ とする。
時点$t$において、まだ購入が発生していないという条件の下での「購入の尤度」を$P(t)$とすると、
$P(t)=f(t)/(1-F(t))$
である。また、
$S(t) = m f(t) = P(t)(m-Y(t))$
$Y(t) = \int S(t) dt = m \int f(t) dt = m F(t)$
である。
さて、Bassモデルとは次のモデルである。
$P(t) = p + (q/m) Y(t)$
ここから以下が導かれる。
$f(t) = p + (q-p) F(t) - q F(t)^2$
$S(t) = pm + (q-p) Y(t) - (q/m) Y(t)^2$
さらに、$f(t), F(t)$を$t$について解くと、
$f(t) = \frac{(p+q)^2}{p} \frac{\exp(-(p+q)t)}{(q/p \exp(-(p+q)t)+1)^2}$
$F(t) = \frac{1-\exp(-(p+q)t)}{q/p \exp(-(p+q)t)+1}$
ここまではいいっすね。ここからはBass's Basement Research Instituteによる説明のメモ。
実際には$t$は離散変数だ。すると、次のような困った事態が発生する。
区間$[t-1, t]$について考えよう。$F(t)$は、この区間の右端までの$f(t)$の合計? では$f(t)$は? 時点$t$における瞬間の速度? それとも、$F(t-1)$から$F(t)$までの増分?
アルゴリズムとして実装するには、どうにかつじつまを合わせないといけない。ここで3つのアプローチが登場する。
第一のアプローチ。Sinivasan & Mason (1986)のアプローチである。$F(t)$のほうはさきほどの解をそのまま用いる。すなわち
$F(t) = \frac{1-\exp(-(p+q)t)}{q/p \exp(-(p+q)t)+1}$
いっぽう$f(t)$のほうを変えてつじつまを合わせる。
$f(t) = F(t) - F(t-1)$
ただし、$t=1$においては$f(t) = F(t)$。
このやり方の良い点:$F(t)$の定義はそのまま。$f(t)$は小さな値なので、これを直接求めずに引き算で求めるのは、数値的に正確。
第二のアプローチ。$f(t)$のほうの解をそのまま用いる。すなわち
$f(t) = \frac{(p+q)^2}{p} \frac{\exp(-(p+q)t)}{(q/p \exp(-(p+q)t)+1)^2}$
いっぽう$F(t)$のほうを変えてつじつまを合わせる。
$F(t) = \sum_{i=0}^{t} f(i)$
これはおかしい。$f(t)$はその瞬間の速度であって、ある期間の平均ではないからだ。
第三のアプローチ。Bass先生が1969年の段階で推していた方法。$f(t), F(t)$の差分方程式に戻る。
$f(t) = p + (q-p) F(t-1) - q F(t-1)^2$
$F(t) = F(t-1) + f(t)$
これはおかしい、すごくおかしい。Bass先生はなぜこんな方法を推したのか? コンピュータじゃなくて手回し計算機を使っていたからに他ならない。なんとかしてOLS回帰の形に持ち込む必要があったのだ。この$f(t)$の式なら、$f(t)$を当期購入数、$F(t-1)$を前期までの累積購入数として、重回帰で解けるからね。
教訓。Bass(1969)の推定方法を用いるなかれ。コンピュータを使いなさい。第一のアプローチを使って、非線形回帰で推定しなさい。
... なるほどね。
最後に、手元にあるいくつかの教科書を比較しておこう。
日頃より頼りにしております、朝野・山中(2000), p.152。
$m$をN, $F(t)$をn_T, $p$をp, $q$をr, $Y(t-1)$をZ_t (添え字に注意!), $S(t)$をX_tと呼んでいる。
本文中でZ_tを「t期における購入者」、X_tを「t期の購入者」と呼んでいるので、前後の文脈を読み取ってその意味をよく考えないといけない。
推定方法はOLS。推定する式はこうなる(8.5式):
$X_t= pN + (r-p) Z_t - \frac{r}{N} Z_t^2$
照井・ダハナ・伴(2009), pp.155-157。この本も頼りになります。
$m$をN, $F(t)$をF(t), $p$をp, $q$をq, $Y(t)$をN(t), $S(t)$をS(t), と呼んでいる。
推定方法はOLS。本文中の記号とRのコード例での変数名が違うので要注意。コード例ではなぜか$N(t-1)$にFt.1, $n(t)$にNtという名前をつけ、lm(Nt ~ Ft.1 + Ft.1^2)を推定している。(どうもよくわからないんだけど、formulaの指定はこれでいいのだろうか? Nt ~ Ft.1 + I(Ft.1^2) ならわかるんだけど...)
里村(2010)、pp.64-67。
$m$をm, $F(t)$をF(t)、$f(t)$をf(t)、$Y(t)$をN(t)、$S(t)$をX(t)と呼んでいる。$m-Y(t)$をY(t)と呼んでいるので注意。
この本は、$F(t)$を$t$の関数として解いた式を非線形回帰で推定している。推定にはRのnls()を使っている。シリーズの主旨に沿って、Rのコード例がとても充実している。よく見ると日本語の誤字が結構多いのだが(「統計的に有為」とか)、そういうことをいちいち気にしていてはいかんのである。
Lilien & Rangaswamy (2004), pp.255-258。ちょっと古い版の教科書だが、もったいないので使い続けている。前職のときに私費で買ったのだ、高かったのだ。
$m$を$\bar{N}$、$F(t)$をF(t), $f(t)$をf(t)、$p$をp, $q$をq, $Y(t)$をN(t), $S(t)$をs(t), と呼んでいる。推定方法として、OLSと非線形回帰の両方を紹介している。
分量も違うし、そもそも日本語の教科書と英語の教科書を比較してはいけないのだが(なにしろ市場規模が違う)、とにかくこの本の説明は最高にわかりやすい。もちろんBass(1969)なんかよりはるかにわかりやすい。
メモ:Bassモデルをどうやって推定するか (いろんな教科書を比べてみた)
2016年1月14日 (木)
たとえば、プロのサッカー選手が来ているシャツにはスポンサーのロゴなんかが入っている。小さなロゴの裏では莫大な金が動いている。
スポンサー契約を通じて、スポンサーは知名度を向上させたりなんだり、なんらかの価値を得るだろう。ひょっとするとクラブの側も、契約金とは別になんらかの価値を得るかもしれない(ないし、変な企業とスポンサー契約したせいで損をするかもしれない)。
スポンサー契約はどれだけの価値を生むのか。
あるスポンサー契約がクラブとスポンサーにもたらす、(契約金以外の)価値の合計について考える。その価値を手に入れたのがクラブ側かスポンサー側かはいったん脇に置いておく。この価値の合計のことを、経済学者っぽく「生産価値」と呼ぶことにする。
スポンサー契約の生産価値はなにによって決まるか。クラブにもいろいろあって、スポンサー契約が価値をもたらすようなクラブもあれば、そうでもないクラブがあるだろう。スポンサー企業にもいろいろあって、スポンサー契約が価値をもたらすような企業もあれば、そうでもない企業もあるだろう。さらに、クラブとスポンサーの相性というものもあるだろう。
次のように考えよう。市場$t$におけるクラブ$a$の特徴をベクトル$X_{at}$、スポンサー$i$の特徴をベクトル$Y_{it}$で表す。生産価値は
$f(a, i, t) = \alpha X_{at} + \beta [X_{at} Y_{it}] + \gamma Y_{it} + \epsilon_{ait}$
第1項は、いうなればクラブの力。第2項は相性の力で、ブラケットの中身をどうするかはあとで考える。第3項はスポンサーの力。最後は誤差だ。
ここで知りたいのは、係数$\alpha, \beta, \gamma$だ。これらが推定できれば、スポンサー契約の価値を推定する仕組みが手に入る。クラブとスポンサーの特徴をインプットすれば、スポンサー契約がもたらす価値の推定値がアウトプットされる仕組みだ。素晴らしい。
そこで、スポンサー契約の事例を片っ端から集めてくる。さらに、クラブとスポンサーの特徴についてのデータを片っ端から集めてくる。クラブとスポンサーの相性に影響しそうなデータも集める。
たとえば、大チームと大企業を組み合わせると相乗効果が生まれたりするかもしれない。 クラブとスポンサーが地理的に近いところにある方が相性は良いかもしれない。強くて人気がある大チーム、大企業、国際的企業、サッカー向きの業種の企業は力を持ち、スポンサー契約の価値を高めるかもしれない。でもその力も距離次第では損なわれてしまうかもしれない。なんであれ、スポンサー契約を続けていると価値が増すかもしれない。。。という具合に、思いつく仮説を、上の数式にどんどん入れていく。
さあ、準備はできた。データを上の式に放り込み、係数$\alpha, \beta, \gamma$を推定しよう... と思うところですよね。私もそう思いました。しかし、話はそのようには進まない。これがこのメモを書き始めた理由である。
なぜか。スポンサー契約がもたらした価値についてのデータがないからだ。クラブの観客数や企業の売上からスポンサー契約の価値を割り出すのは難しい。契約金からどうにか推定できるとしても、そもそもスポンサー契約の金額は企業秘密だ。式の右辺についてはデータがある、しかし左辺についてのデータがないのである。
さあ、ここからが本題。スポンサー契約がもたらした価値についてのデータなしで、スポンサー契約の価値を推定するモデルをどうやってつくるか。
サッカークラブは金をくれるスポンサーを求め、スポンサーはロゴをつけてくれるサッカークラブを求めている。クラブたちとスポンサーたちはひとつの市場を形成している。たとえばあるシーズンにおけるある国のクラブたちとスポンサーたち、これがひとつの市場だ。
いま、市場 $t$ においてクラブ $a$ がスポンサー $i$ と契約したとしよう。スポンサーがクラブに渡す金額を $r_{ait}$、スポンサーが得る価値を$\Delta V (a,i,t)$, クラブが得る価値を$\Delta U(a,i,t)$としよう。スポンサーの利得は
$\pi^S (a,i,t) = \Delta V(a,i,t) - r_{ait}$
クラブの利得は
$\pi^C (a,i,t) = \Delta U(a,i,t) + r_{ait}$
この契約によって生まれる価値、すなわち生産価値は
$f(a,i,t) = \Delta V(a,i,t) + \Delta U(a,i,t)$
である。両者の間でどれだけのカネが動いたか($r_{ait}$)は、もはやどうでもよくなっていることに注意。
同じ市場$t$において、別のクラブ $b$ が別のスポンサー $j$ と契約したとしよう。このとき、世の中がうまく回っているならば、
$f(a,i,t) + f(b,j,t) \geq f(a,j,t) + f(b,i,t)$
であるはずである。つまり、2つの契約から生まれる生産価値の合計は、仮にクラブとスポンサーのマッチングを入れ替えたときに生まれる生産価値の合計と同じ、ないしそれよりもマシであるはずだ。マッチング理論ではこれを「局所生産最大化条件」と呼ぶのだそうである。
市場$t$においてなされたスポンサー契約の集合から、2ペア$\{a,b,i,j\}$を取り出すすべての取り出し方について考える。契約が3つあったら3x2=6通り、k個あったらk(k-1)通りあるんでしょうね。で、すべての取り出し方について、局所生産最大化条件が満たされていたら1点、そうでなかったら0点とカウントする。このカウントを合計しよう。
さらに、市場の数が$H$個あるとして、それらの市場を通じて、カウント合計の平均を求めよう。
$Q_H(f) = \frac{1}{H} \sum_{t \in H} \sum_{\{a,b,i,j\} \in A_t} 1[f(a,i,t) + f(b,j,t) \geq f(a,j,t) + f(b,i,t)]$
$1[\cdot]$は、カッコ内の不等式が成立しているときに1, そうでないときに0を返す関数である。上記数式、原文にはどうもミスプリがありそうなので、勝手に表記を変えている。誤解していないといいんだけど。
この関数を$f$について最大化した解を、スポンサー契約市場における均衡状態と捉えることができるのだそうだ。
つまり、もし世の中がうまく回って回って回り続けていれば、いずれはスポンサー契約市場 がそうなるであろう姿。一旦世の中がそうなってしまった暁には、どの(合理的な)クラブもスポンサーもそこから抜け出すことができない、そんな姿。それがわかるというわけだ。まじですか。
ということは、もし世の中がこれまでうまく回って回って回り続けているならば、スポンサー契約市場は均衡状態に陥っているはずだ。ということは、スポンサー契約から生まれる価値の関数 $f$ は、上の$Q_H(f)$を最大化するような関数であるはずだ。ということは、実際のスポンサー契約、ならびにクラブとスポンサーの特徴についてのデータの下で、$Q_H(f)$を最大化する$f$を求めれば、それがこの世の中における、スポンサー契約の価値を求める関数となるはずだ。
... というロジックなのではないかと思う。えーと、こういう理解であっているんでしょうか。こういう考え方そのものに、私、 いささか戸惑ってしまうんですが...
このスコア関数$Q_H(f)$にさきほどの$f(a, i, t)$の式を放り込もう。ここで面白いのは、$Q_H(f)$の中身の不等式をよく見ると、$\alpha X_{at}, \alpha X_{bt}, \gamma Y_{it}, \gamma Y_{jt}$がひとつづつ出てくる、という点だ。つまりこれらは無視してしまってよい。問題はクラブとスポンサーの相性の力 $\beta [X_{at} Y_{it}]$ だけなのだ。おおお、なるほど。
ともあれこのようにして、スポンサー契約、クラブ、スポンサーについての十分なデータがあれば、スポンサー契約がもたらす価値を推定するモデルを手に入れることができる。
イギリスのサッカークラブのスポンサー契約のデータをつかって推定したところ、クラブとスポンサー企業は規模が釣り合っているときに相性がいいとか、クラブ本拠地と企業の本社所在地が地図上で近いほうが相性がいいとか、そういったことがわかった由。
以上、Yang & Goldfarb (2015, J. Marketing Research) からメモ。
実は上記は、私には途方もなく難しいこの論文のごく最初のほうに出てくる話で、ここから論文は「酒やギャンブルに関連する企業がサッカーのスポンサーになるのを禁止したら何が起きるか」という分析へと進んでいくのだが、分析の仕組みというか建付けの部分で途方に暮れてしまった。頭を冷やすために、論文のロジックを組み立て直し、私にも理解できるくらいに平易な筋立てに落として、メモにしてみた次第である。
均衡という概念に基づいたこういう分析が、ビジネス・ リサーチやデータ解析でもこれから重要になってくるのか、そうでもないのか、そういう大きな話は私にはよくわからない。だから、手探りで勉強することにどれだけの投資対効果があるのかはよくわからないんだけど、 とにかくその、読むたびに途方に暮れてしまうのである。なんというかその... 現象を理解するための分析に、いつのまにか規範的言明が入ってくる感じ、というか...
もっとも、ふつうの統計的分析だって、インプットは常に仮定とデータだ。上の場合でいうと、仮にスポンサー契約の価値のデータが手に入っていたら回帰分析でモデルを推定できただろうけど、でもそのときだって、きっと誤差項の分布についてなんらかの仮定を置くだろう。上の分析ではその確率的な仮定の代わりに「スポンサー契約市場が均衡状態にある」というゲーム理論的な仮定を置いただけだ、ということなのかもしれない。ううううむ。。。
メモ:スポーツ・スポンサー契約がもたらす価値をどうやって推定するか:マッチング理論の巻
2015年12月17日 (木)
なんというかその、判別モデルや回帰モデルを組んだ時、「で、どの説明変数が重要でしたか?」って聞かれること、あるじゃないですか。いやいや、ひとことで「重要」っていってもいろいろありましてですね... と交互作用や非線形性の話をしても、ある意味、煙に巻くようなもんじゃないですか。素朴な気持ちとしては、こっちも内心では 「いやあこの変数は効くなあ」なんて思っているわけだし。なんだかんだいいながら、どうにかして変数を選ばないといけないわけだし。
魚心あれば水心で、世の中には実にいろんな変数重要度指標があり、誠に困ったことである。さらに困ったことに、こういう話は仕事の中で不意に顔を出すので、いつかきちんと調べます、では間に合わない。
とりあえず、いろんなタイプの予測モデルを統合したパッケージである、R の caret パッケージが実装している重要性指標についてメモしておこう。出典はこちら。純粋に自分用の覚え書です。
まずは、モデルに依存しないタイプの指標。
- (2クラス分類の場合) ROC曲線下面積 (AUC)。
- (多クラス分類の場合) 他の個々のクラスとのペアワイズのAUCの最大値。[んんん...? 自分vs他クラスの分類のAUCじゃだめなの?]
- (2クラス分類の場合) 敏感度と特異度。
- (回帰の場合) 結果変数を説明変数に単回帰したときの傾きの t 値の絶対値。
- (回帰の場合) 結果変数を説明変数にloess回帰したときのR二乗。
モデルに依存するタイプの指標。
- 線形モデル: パラメータの t 値の絶対値。[ううむ、なんだかなあ... 重回帰の変数重要度評価の文脈では結構評判悪いと思うんだけど]
- ランダム・フォレスト: [たぶんここの説明は、おそらく randomForest パッケージのちょっと古いマニュアルの、impotrance関数の説明を引用しているのではないかと思う。かわりに最新のマニュアルから引用してみる。なお、importance関数では引数で2種類の重要度を選べる]
第一の指標は、OOBデータのpermutingから算出するものである。それぞれの木について、データのOOB部分における予測誤差を記録する(分類の場合はエラー率、回帰の場合はMSE)。で、それぞれの説明変数をpermuteしたあとでもう一度同じものを求める。この差をすべての木を通して平均し、差のSDで基準化する。ある変数について差のSDが0のときは割り算しない(しかしこの場合平均はたいてい0である)。第二の指標は、その変数についてsplitしたときのノードの不純度(分類の場合はジニ指標、回帰の場合は誤差平方和)の全体的減少をすべての木を通じて平均したものである。
- PLS: 回帰係数の絶対値の重みづけ和。重みはPLS成分を通した平方和の減少の関数。従って係数の寄与は平方和の減少と比例する形で重みづけられる。[いまいち腑に落ちない... plsパッケージのマニュアルをみたほうがよさそうだ]
- recursive partioning: それぞれの分岐における損失関数(たとえばMSE)の減少を当該の変数に帰属させ、変数ごとに合計する。なお、それぞれの分岐で競合していたが実際には使わなかった変数について合計する手もある[rpart.controlで制御できるって書いてある... つまりrpartパッケージの機能なんだろうな]
- バギング木: 上と同じ手法をすべてのブートストラップ木について行い合計する。[具体的にはどのパッケージを想定しているのだろう... caretの対応パッケージが多すぎてよくわからない]
- ブースティング木: gbmパッケージのラッパー。[現時点ではxgboostにも対応していたと思うんだけどな...]
- 多変量アダプティブ回帰スプライン(MARS): earthパッケージのevimp関数のラッパー。その説明変数がモデルに追加されたときのモデルの統計量の減少。統計量としては、一般化交差妥当化統計量(GCV)、誤差平方和(RSS)を選べる。ほかに、その変数が最終モデルに含まれた回数を調べるという手もある(nsubsets)。[駄目だ、MARSの仕組みについてよく知らないので全然腑に落ちない]
- nearest shrunken centroids [そもそも名前しか知らん...pamrというパッケージらしい]: その変数のクラス重心と全体重心の差。
- Cubist: その変数が条件に含まれるか線形モデルに含まれた回数の割合。[手法についてよく知らないので、意味もよくわからん...]
ふうん...
ランダムフォレストのような協調学習の分野では、変数重要性をpermutationベースで求めるとき、ふつうにその変数だけかきまぜちゃっていいのか (いわばmarginalな重要度になる)、それとも共変量で層別して層の中だけでかきまぜるべきか (conditionalな重要度になる)、という議論があるらしい。これは他の手法でもいえることであって、その辺のところが知りたいんだけど、caretパッケージではさすがにそこまで面倒はみてくれないようだ。
説明変数の重要度指標のいろいろ (by caretの中の人)
2015年6月16日 (火)
先日から仕事の都合で生存時間(イベント発生時間)データの分析について考えていたのだけど、資料をみていると、サンプリング・デザインの用語がいろいろあって混乱してしまう。同じことを違う名前で呼んでいることもあって、ちょっと困る。
というわけで、クライン&メシュベルガー「生存時間解析」より関連用語をメモ。この本、原題を"Survival Analysis: Techniques for Censored and Truncated Data"というだけあって、サンプリング・デザインの問題についてやたらに詳しい。
1. 打ち切り(censoring)。
- 1.1 右側打ち切り。
- 1.1.1 タイプ I 打ち切り。関心あるイベントが、前もって指定したある時点よりも前に生じたときにのみ観察できる。打ち切り時間は人によって同じでも、違っていてもよい。特殊ケースとして以下がある。
- 1) 進行性タイプ I 打ち切り。打ち切り時間が人によって異なる(これの打ち切り時間を「犠牲時間」ということもある)。
- 2) 一般化されたタイプ I 打ち切り。カレンダー時間でみて、観察開始時点が人によって異なり打ち切り時間が全員で固定されている。Lexis diagramはこういうときに便利 [←あ、なるほど...]
- 1.1.2 タイプ II 打ち切り。n 人の観察対象者のうち r 人でイベントが生じるまで観察する。尤度の決定や推定がちょっと楽になる。r はあらかじめ定められた定数だが、打ち切り時間は確率変数であることに注意。特殊ケースとして以下がある。
- 1) 進行性タイプ II 打ち切り。まず r1 人でイベントが生じるまで観察し、そこで残りの対象者のうちある人数について観察を打ち切る。
- 1.1.3 競合リスク打ち切り。競合リスクを体験した人の観察を打ち切る。特殊ケースとして以下がある。
- 1) ランダム打ち切り。
- 1.1.1 タイプ I 打ち切り。関心あるイベントが、前もって指定したある時点よりも前に生じたときにのみ観察できる。打ち切り時間は人によって同じでも、違っていてもよい。特殊ケースとして以下がある。
- 1.2 左側打ち切り。関心あるイベントが観察開始よりも前に生じていることがあり、生じていたことはわかるがいつ生じていたかはわからない。
- 1.3 両側打ち切り。左側打ち切りと右側打ち切りの両方がある。
- 1.4 区間打ち切り。イベント発生がある区間に生じたかどうかだけがわかる。
2. 切断(truncation)。ある期間中にイベントが発生した人だけが観察される。
- 2.1 左側切断。イベント発生時間が切断時間を超えた人だけが観察される。(この切断時間を「遅延登録時間」ということもある)。
- 2.2 右側切断。イベントがある時間までに生じた人だけが観察される。
やれやれ...
2015年6月11日 (木)
調査におけるウェイティング(いわゆるウェイトバック集計)について、このブログがきっかけでお問い合わせを受け、えええ? いったいこのブログにどんなことを書いてんだっけ... と読み返してみたところ、全然忘れているエントリもあってびっくりした。三歩歩けば全て忘れる、ニワトリなみの記憶力である。
せっかくなので、これまでに書いたウェイティングに関するエントリを時間順に並べてみた。すいません、完全に自分用のメモです。
- 読了:Hu, et al. (2001) 固定電話対象のRDD調査と携帯電話対象のRDD調査を両方やってひとつにまとめました (2015/06)
- 読了:Kalton & Flores-Cervantes (2003) 「ウェイトバック集計」のためのウェイト値のつくりかた(2015/04)
- 読了:Scott(2007) 調査ウェイティングの下でのカイ二乗検定のRao-Scott修正について振り返る(2014/11)
- 読了:Potthoff, Woodbury, & Manton (1992) 調査ウェイトつきデータの分析における「等価標本サイズ」「等価自由度」(2014/03)
- 「ウェイトバック集計」すべき場合とすべきでない場合がある(ということを説明するためのwebアプリを作ってしまった)(2014/03)
- 読了:Patterson, Dayton & Graubard (2002) 複雑な標本抽出デザインのデータに対する潜在クラス分析 (仁義なき質疑応答つき)(2014/03)
- 読了:Asparouhov (2005) 因子分析・潜在クラス分析における確率ウェイティング(または: Mplus 3はこんなにすごいんだぜ)(2014/03)
- 読了:Spencer (2000) 抽出確率が測定値と相関している標本におけるデザイン効果の推測(2014/03)
- 読了:Muthen & Satorra (1995) 複雑な標本抽出デザインのデータに対するSEM(2014/03)
- 読了: Park & Lee (2001) デザイン効果、その知られざる真実(2014/03)
- 読了: Gelman (2007) ウェイティングと回帰モデリングを巡る悪戦苦闘(2014/02)
- 統計ソフトの「ウェイト」は調査の「ウェイト」ではない(2013/05)
- 読了: Eltinge (2001) ウェイト値の算出方法が複数ある時にどっちがいいか決める方法(2008/04)
- 読了: Little & Vartivarian (2005) 無回答の補正のためにウェイティングすると推定量の分散は必ず大きくなるとはいえない(2008/03)
- 読了: Potter (1990) ウェイト値をトリミングする方法(2008/01)
- 読了: Kish (1990) ウェイティング:なぜ、いつ、どうやって(2007/12)
2014年10月17日 (金)
以下は純粋に個人的なメモであります。
ここにn変量時系列 $y_t$ がございます。
これを以下のように分解する。まずは
$y_t = B + Lf_t + u_t, \ \ \ u_t \sim N(0, \Sigma_u)$
$B$は切片(サイズ n x 1), $L$は係数行列(n x p), $f_t$はp変量の潜在動的因子(p x 1), $u_t$はn変量の不規則要素(n x 1)である。
潜在動的因子をトレンドと季節に分解する。季節要素を観測値のモデルにではなく因子の時系列モデルのほうに入れている点に注意。
$f_t = \alpha_t + \gamma_t$
トレンドのほうは
$\alpha_t = \alpha_{t-1} + \beta_{t-1} + \epsilon_t, \ \ \ \epsilon_t \sim N(0, \Sigma_\epsilon)$
トレンドの傾きも時間変動させて
$\beta_t = \beta_{t-1} + \delta_{t-1} + \eta_t, \ \ \ \eta_t \sim N(0, \Sigma_\eta)$
傾きの変化率をランダムウォークさせる。
$\delta_t = \delta_{t-1} + \zeta_t, \ \ \ \zeta_t \sim N(0, \Sigma_\zeta)$
季節のほうも確率的に変動させる。以下、添え字が煩雑になって混乱するので、季節周期を4に決め打ちする。
$\gamma_t = -\sum_{j=1}^{3} \gamma_{t-j} + \xi_t, \ \ \ \xi_t \sim N(0, \Sigma_\xi)$
以上、すごく複雑に見えるけど、因子の時系列構造を工夫しているだけで、要するに因子分析である。びびってはいけない。
さて、状態空間表現ではどうなるんだよ、という話である。さあ深呼吸!
観察方程式は
$y_t = A z_t + B + u_t, \ \ \ u_t \sim N(0, \Sigma_u)$
ここで状態変数ベクトルは
$z_t \equiv [\alpha_t \ \beta_t \ \delta_t \ \gamma_t \ \gamma_{t-1} \ \gamma_{t-2}]'$
実際には$\alpha_t, \beta_t, \ldots$は縦ベクトル(p x 1)なので、こういう書き方でいいのかどうかよくわかんないんだけど(自慢じゃないけど高校で数学の時間はずっと寝ていた)、原文でもこうなってるし、まあいいことにしよう。なお、原文で最後の項は$\gamma_{t-s-2}$となっているが、$\gamma_{t-(s-2)}$の誤りであろう。
係数行列は
$A \equiv [L_{n \times p} \ 0_{n \times p} \ 0_{n \times p} \ L_{n \times p} \ 0_{n \times p} \ 0_{n \times p}]$
順に、$\alpha_t$の係数, $\beta_t$の係数、$\delta_t$の係数, 季節ダミー1の係数($\alpha_t$の係数と同じ。なぜなら季節要素が状態方程式に突っ込んであるから), 季節ダミー2の係数、季節ダミー3の係数、である。結局、$z_t$の長さは$m = 6p$。季節周期を$s$として、$m=(2+s)p$である。
さあ状態方程式だ!
$z_t = C z_{t-1} + v_t, \ \ \ v_t \sim N(0, \Sigma_v)$
状態撹乱要素は
$v_t \equiv [\epsilon_t \ \eta_t \ \zeta_t \ \xi_t \ 0 \ 0]'$
問題は遷移行列$C$。原文では次のようになっている。
$C \equiv \left( \begin{array}{llllll} I_p & I_p & 0 & 0 & 0 & 0 \\ 0 & I_p & I_p & 0 & 0 & 0 \\ 0 & 0 & I_p & 0 & 0 & 0 \\ 0 & 0 & 0 & -I_p & \cdots & -I_p \\ 0 & 0 & 0 & I_p & 0 & 0 \\ 0 & 0 & 0 & 0 & I_{(s-3)p} & 0 \end{array} \right)$
本当かなあ? ここにどうも納得がいかなかったのである。
いちから考えてみたい。$C$の右側にあるのは、たとえば$[\alpha_4 \ \beta_4 \ \delta_4 \ \gamma_4 \ \gamma_3 \ \gamma_2]'$である。これに$C$を掛け、つくりたいのは$[\alpha_5 \ \beta_5 \ \delta_5 \ \gamma_5 \ \gamma_4 \ \gamma_3]'$である。以下、大きな行列を書くのが面倒なので、$C$をp行p列づつ区切り、上の段から順に考える。
最初のp行は$\alpha_5$をつくる奴だから、
$(I \ I_ \ 0 \ 0 \ 0 \ 0)$
次のp行は$\beta_5$をつくる奴だから
$(0 \ I \ I \ 0 \ 0 \ 0)$
次のp行は$\delta_5$をつくる奴だから
$(0 \ 0 \ I \ 0 \ 0 \ 0)$
次のp行は$\gamma_5$をつくる奴だから
$(0 \ 0 \ 0 \ -I \ -I \ -I)$
次のp行は$\gamma_4$をつくる奴だから、
$(0 \ 0 \ 0 \ I \ 0 \ 0)$
最後のp行は$\gamma_3$をつくる奴だから、
$(0 \ 0 \ 0 \ 0 \ I \ 0)$
ほんとだ...! 合っている!
やれやれ。分散行列 $\Sigma_v$はブロック単位行列で、左上から順に$\Sigma_\epsilon, \Sigma_\eta, \Sigma_\zeta, \Sigma_\xi, 0_p, 0_p$である。
なお、実際にはすべての分散行列を対角行列に制約した由。$\Sigma_v$のみならず、観察方程式の分散行列$\Sigma_u$も対角行列にしちゃうのである。不規則要素に共分散はないと考えたわけだ。ま、いいか。
パラメータ推定はEMアルゴリズムで行った由。詳細は略するが、ステップのなかでバリマクス回転している。いやーん。そんなんようせんわ。
なお、データはあらかじめ対数変換した由(歪度が大きかったから)。さらに平均0, 分散1に標準化した由(分析の主旨は動的因子にあるので、別にかまわない)。
以上、Du & Kamakura (2012, JMR)のWeb Appendix Bより。とても歯が立たないだろうと敬遠していたが、実際に読んでみたら、もちろん難しいんだけど、思ったほどではなかった。
本文を読んだときも思ったことだが、季節要素をこうして動的因子系列に入れるべきかどうかはデータの実質的な性質によるなあ、と思った。著者らは自動車ブランド名の検索量の時系列を分析していて、因子として「欧州車」というようなものを想定しているので、それなりに筋が通っている(欧州車に共通の季節要素があると考えているわけだ)。でもこれをマルチカテゴリに拡張して、著者らが主張するようにtrendspottingという観点から捉えたときには、観察方程式に入れたほうが自然ではないかと思う。
推定のところにオリジナルな工夫があるところがちょっと嫌だ。このモデルって、あらかじめ予備的分析で因子数と負荷行列にあたりをつけ(変量ごとに季節を除去しEFAにかけるとか)、$L$を何箇所か適当に固定すれば、最尤推定できたりしないのかなあ。
2014年10月 2日 (木)
仕事の都合で状態空間モデルのソフトを使っているのだけれど、参考書によってもソフトによっても、記法がバラバラで大変に混乱する。メモをつくったので載せておく。純粋に自分のための覚え書きであります。
話を簡単にするために、単変量のガウシアン状態空間モデルについてのみ考える。状態変数の数をmとする。
Commandeur & Koopman(2007): とりあえず参考書の例として。Section 8.1に基づく。
- 測定方程式: $y_t = z'_t \alpha_t + \epsilon_t,\ \ \epsilon_t \sim NID(0, \sigma^2_\epsilon)$
- 状態方程式: $\alpha_{t+1} = T_t \alpha_t + R_t \eta_t,\ \ \eta_t \sim NID(0, Q_t)$
Koopman, Shepard & Doornik (1998): SsfPackの基になっている論文なのだが、記法がすごくややこしい...
- まず$y_t = \theta_t + G_t \epsilon_t,\ \ \epsilon_t \sim NID(0, I)$ と考え ($\epsilon_t$ の分散が1であることに注意!)
- 信号をさらに$\theta_t = c_t + Z_t \alpha_t$ と分解して、
- $\alpha_{t+1} = d_t + T_t \alpha_t + H_t \epsilon_t$ (ここでも$\epsilon_t$が出てくる!)
- 簡略化して: $(\alpha'_{t+1}, y'_t)' = \delta_t \Phi_t \alpha_t + u_t,\ \ u_t \sim NID(0, \Omega_t)$. ここで$\delta'_t = (d'_t, c'_t)'$, $\Phi_t = (T'_t, Z'_t)'$, $u_t = (H'_t, G_t)'$, $\Omega_t$はブロック対角でないややこしい行列。
- 初期条件: $\alpha_1 ~ \sim N(0, P)$
SsfPack: Commandeur&Koopman(2007)のSection 11.2 より。
- 測定方程式: $y_t = Z'_t \alpha_t + \epsilon_t,\ \ \epsilon_t \sim NID(0, H_t)$
- 状態方程式: $\alpha_{t+1} = T_t \alpha_t + R_t \eta_t,\ \ \eta_t \sim NID(0, Q_t)$
- 簡略化して: $(\alpha'_{t+1}, y'_t)' = \Phi_t \alpha_t + u_t,\ \ u_t \sim NID(0, \Omega_t)$. ここで$\Phi_t = (T'_t, Z'_t)'$, $u_t = (\eta'_t, \epsilon_t)'$, $\Omega_t=\left(\begin{array}{cc}R_t Q_t R't & 0\\ 0 & H_t\end{array}\right)$となる。
- 信号: $\theta_t = Z'_t \alpha_t$
- 初期条件: $\alpha_1 ~ \sim NID(0, P_1)$。さらに $\Sigma = (P'_1, \alpha_1)'$ とする。
- というわけで、結局システム行列は $\Phi_t$ (サイズm+1, m), $\Omega_t$(m+1, m+1), 初期状態$\Sigma$(m+1, m)の3つである。
Rのdlmパッケージ: vignetteによれば、
- 測定方程式:$y_t = F_t \theta_t + \nu_t,\ \ \nu_t \sim NID(0, V_t)$
- 状態方程式:$\theta_t = G_t \theta_{t-1} + w_t, \ \ w_t \sim NID(0, W_t)$
- 初期条件:$\theta_0 \sim N(m_0, C_0)$
- というわけで、システム行列は$F_t$(1, m), $V_t$(1, 1), $G_t$(m, m), $W$(m, m), 初期状態$m_0$(m,1), $C_0$(m,1)となる。
RのKFAS パッケージ: reference manual によれば、
- 測定方程式:$y_t = Z_t \alpha_t + \epsilon_t,\ \ \epsilon_t \sim NID(0, H_t)$
- 状態方程式:$\alpha_{t+1} = T_t \alpha_t + R_t \eta_t,\ \ \eta_t \sim NID (0, Q_t)$
- 初期条件:$\alpha_1 ~ \sim NID(a_1, P_1)$
- というわけで、システム行列は$Z_t$(1, m), $H_t$(1, 1), $T_t$(m, m), $R_t$(m, k), $Q_t$(k, k), 初期状態$\alpha_1$(m,1), $P_1$(m, m)となる (kは$\eta_t$の長さ)。
よく使うdlmとKFASを比較すると、
- 測定方程式の係数行列は、dlmでは$F$, KFASでは$Z$
- 測定方程式の誤差分散行列は、dlmでは$V$, KFASでは$H$
- 状態方程式の遷移係数行列は、dlmでは$G$, KFASでは$T$
- 状態方程式の潜在変数(というか誤差項というか)の負荷行列は、dlmでは単位行列、KFASでは$R$
- 状態方程式の潜在変数(というか誤差項というか)の分散行列は、dlmでは$W$, KFASでは$Q$
- 状態変数の初期状態の平均は、dlmでは$m_0$, KFASでは$a_1$
- 状態変数の初期状態の分散は、dlmでは$C_0$, KFASでは$P_1$
と呼ばれているわけである。やれやれ。
追記: はじめてMathJaxを使ってみた。うわあ、これは便利だ...
統計学者のみなさん、記法は統一してもらえないかしら (状態空間モデルの巻)
2014年7月 3日 (木)
多変量時系列データの分析手法を指す、「動的因子分析」とか「ダイナミック・ファクター・モデル」とかいう言葉があるけど、この言葉で指しているモデルの形式が人によってバラバラであることに気が付いた。ちょっと混乱しちゃったので、メモしておく。どうも恥をさらしているような気がしないでもないんだけど...
なぜ混乱しちゃったかというと、次の2つのタイプのモデルが、両方とも動的因子分析と呼ばれているからである。
- タイプA: 時点 $t$ における測定変数群のベクトル $v_t$ について、
$v_t = \sum_{s=0}^S \Lambda_s f_{t-s} + e_t$
とするタイプ。$f_t$ は時点 $t$ における因子のベクトルである。つまり、時点 $t$ における測定変数の値を、時点$t$における因子得点、時点$t-1$における因子得点, ... で説明しようとする。 - タイプB: ごくふつうの因子分析モデル
$v_t = \Lambda_0 f_t + e_t $
を考え、さらに $f_t$ についての時系列モデルを考えるタイプ。つまり、時点 $t$ における測定変数の値は、時点 $t$ における因子得点だけで説明する。で、その因子得点を、時点 $t-1, t-2, ...$ における因子得点で説明する。
Bを「動的因子分析」と呼ぶのは何となく違和感があるんだけど、そう呼んでいる例も少なくないのである。以下、順不同でメモしておくと...
- 豊田「共分散構造分析 応用編」の4章は、Aを動的因子分析、Bを時系列因子分析と呼んで区別している。で、AとしてMolenaar(1985, Psychometrika), Hershberger, Corneal &Molenaar(1994, SEM), BとしてToyoda(1997, Soc.Theory&Methods)を挙げている。
- 川崎(2001, 統計数理)は私には難解なレビュー論文なのだが(私の知識不足のせいです)、3.1「共分散構造拡張型の動的因子分析」がAで、3.2「構造時系列モデルによる動的因子分析」と3.3「多変量ARMAモデルによる動的因子分析」がBなんじゃないかと思う。
- ずっと前に読んだHershberger(1998, in Marcoulides(eds.))では、紹介されているモデルはすべてAであった。
- 先日読んだDu & Kamakura (2012, J.Mktg.Res.)は、Aの例として、Sargent & Sims(1977), Forni et al(2000, Rev. Econ. Stat.), Stock & Watson(2002, J.Business & Econ. Stat.)を挙げている。いっぽう、この研究自体はB。そのほかのBの例として、Engle & Watson (1981, JASA), Zuur, et al.(2003, Environmetrics)を挙げている。
- いま読んでいるMolenaar & Ram (2009, in Valsiner et al.(eds.))は、前半の説明はA。後半で説明されているのはBだが、ただし因子負荷が時間変動する。
- 未読だけど、Ram, Brose & Molenaar (2013, in Little (eds.))が説明しているのはBっぽい。
- RのMARSSパッケージに入っている動的因子分析は、ユーザーズガイドを見る限り B。
- Rのtsfaパッケージというのは、Gilbert & Meijer (2005) というのに基づいていて、この論文はすごく難しそうで手が出ないのだが、たぶんBなんだろうと思う。
- これもいま読みかけなんだけど、Zhang, Hamaker, Nesselroad(2008, SEM)はwhite noise factor score (WNFS) modelとdirect autoregressive factor score (DAFS) modelという分け方をしていて、説明を読む限り、前者がAで後者がBだ。なお、Browne & Nesselroade (2005, McDonald記念論文集)ではショック・モデルとプロセス・モデルという言い方をしている由。ところが、この2種類のモデルはお互いに変換可能なのだそうだ。そそそ、そうなの? なんだか、このメモの意味自体がはっきりしなくなってきた...
- 2012年のMplus Users MeetingでのAsparouhovさんのトークの資料を見ると、MplusでDAFSモデルを推定するコードを示して、このモデルはMolenaar(1985)と発想は違えども同じ尤度になる、というようなことが書いてある。そうなんですか...
ほか、気になるけど、どっちだかわかんないやつ: Du Toit & Browne (2001, in Cudeck et al.(eds.)), Wood & Brown (1994, Psych.Bull.), Browne & Zhang (2007, in Cudeck & MacCallum(eds.)), Molennar, De goooijer & Schmitz(1992, Psychometrika)。
2014年6月22日 (日)
先日リリースされたMplus 7.2の改訂点を、こちらで公開されているPDFからメモしておく。すいません、純粋に自分のためのメモです。
一番大きな追加機能は、混合モデルで非正規分布を指定できるようになったこと。ANALYSISコマンドでTYPE=MIXTUREのときDISTRIBUTIONオプションで指定する。NORMAL(正規分布), SKEWNORMAL(歪正規分布), TDISTRIBUTION(t分布), SKEWT(歪 t 分布)から選べる。数値積分時は不可。うーむ、まだ使い方が良くわからない... Web Note #19を読めばいいのだろうか。
なお、ESTIMATOR=BAYES;POINT=MODEのときにモード推定のための反復回数の上限をDISTRIBUTIONオプションで与えることができるけど、それと同名だがちがうオプションである。あれれ、じゃ「TYPE=MIXTURE; ESTIMATOR=BAYES;POINT=MODE;」としたらDISTRIBUTIONオプションはどちらの意味になるのだろうか。今度試してみよう。
実はこの非正規分布の指定、TYPE=GENERALのモデルでも指定できるのだが、そちらは実験版である由。
この新機能と関係していると思うのだが、OUTPUTコマンドにH1MODELオプション、ANALYSISコマンドにH1STARTSオプションが追加された。まだよく理解できていない。
MODEL INDIRECTコマンドの変更。因果推論の観点から定義された直接効果・間接効果が出力されるようになった。こないだ読んだ奴に書いてあった話だ。
INDコマンドで、一番右の変数が連続変数であるとき、その後ろにかっこをつけて比較する2つの水準を指定できるようになった。
媒介変数(メディエータ)があるときの特別な間接効果を出力するMODオプションが追加された。メディエータ、メディエータの水準指定、外生モデレータ、外生モデレータのとる値の範囲、原因変数とメディエータの交互作用変数、外生モデレータとメディエータの交互作用変数、原因変数がとる値の2つの水準の指定、をカバーしている。なにもそこまでしなくても...
潜在クラスモデル・潜在遷移モデルで、二値ないしカテゴリカルな指標の残差共分散を指定できるようになった。ANALYSISコマンドのPARAMETERIZATIONオプションでRESCOVARIANCESを指定する。たとえばMODELコマンドで「%OVERALL% u1 WITH u3;」とだけ指定すると、u1とu3の残差共分散がクラス間等値制約のもとで推定される。さらにクラス別に追記して、あるクラスでだけ残差共分散を自由推定したりできる。そうそう、これ、これまでできなかったんだよな...
連続時間生存モデルの見直し。
まず、VARIABLEコマンドのSURVIVALオプションが変わった。生存時間変数を t として、「SURVIVAL = t;」とすると、従来は定数ハザードが推定されたのだが、改訂後はCox回帰みたいなノンパラメトリック・ベースライン・ハザード関数が推定される。ただし、もし t から連続潜在変数にパスが延びていたり、マルチレベルモデルだったり、モンテカルロ数値積分をするモデルだったりすると、セミパラメトリック・ベースライン・ハザード関数となる。このとき、10個の時間間隔が勝手に決定されるが、「SURVIVAL = t(10);」とか「SURVIVAL = t(4*5 1*10);」という風に時間間隔を明示的に指定することもできるし、「SURVIVAL = t (ALL);」とするとデータ中の時間間隔がすべて用いられる。「SURVIVAL = t (CONSTANT);」とすると定数ハザードになる。
これに伴い、ANALYSISコマンドのBASEHAZARDオプションも変わった。従来は、ONでパラメトリックなベースライン・ハザード、OFFでノンパラメトリックなベースライン・ハザードで、OFFのときのみ、その後ろの(EQUAL)ないし(UNEQUAL)でクラス間等値制約の有無を指定できた。改訂後は、パラかノンパラかではなくて、モデル・パラメータかどうかを指定するためのオプションとなった。デフォルトはOFFで、このときベースライン・ハザード関数のパラメータはモデルのパラメータではなく補助的なパラメータになる。ONにするとモデル・パラメータになり、MODELコマンドで t#1, t#2, ..., [t]が指定できる。またONでもOFFでも、後ろに(EQUAL)ないし(UNEQUAL)を指定できる。
とこのように、同名のオプションの使用方法が変わっちゃったのでややこしい。たとえば単純なCox回帰は、これまでVARIABLEコマンドで「SURVIVAL = t (ALL);TIMECENSORED = tc (0 = NOT 1 = RIGHT);」、ANALYSISコマンドで「BASEHAZARD = OFF;」であったが、改訂後はSURVIVALオプションの(ALL)は不要となり(事情がない限りノンパラになるから)、BASEHAZARDオプションは不要となる。
DEFINEコマンドが微妙に変わったらしい。 ちゃんと読んでないんだけど、たとえば、CENTERオプションのあとで交互作用変数をつくると、これまでは中心化される前の変数が使われたけど、改訂後は中心化された後の変数が使われるようになった、とかなんとか。
DEFINEコマンドなどで使うDOオプションがネストできるようになった。ふーん。
以上!
追記: いやいや、まだ細かい続きがあったのを見落としていた。
- 二値指標でALIGNMENTオプションを使うとき、従来はBAYES推定のみ可だったのが、ML推定も可能になったらしい。
- ML推定でALGORITHM=INTEGRATIONのとき、ブートストラップ標準誤差と信頼区間が表示されるようになったらしい。
- WLS推定でDeltaパラメタライゼーションのとき、TECH4で標準誤差が表示されるようになったらしい。それからTECH4でz検定やp値が表示されるようになったらしい。お、おう... (意味がよく理解できていない。WLSでDeltaって、カテゴリカル指標で多群ってことでしょう? TECH4って潜在変数の要約統計量だと思うのだが... 個々のカテゴリカル指標の裏に仮定されている潜在変数についてSEやpが出るということだろうか。それっていったいどういう意味があるのだろう)
- WLS推定のとき、共変量を伴うモデルで標準化係数と標準誤差が表示されるようになったらしい。(これまで表示されていなかったっけ?)
- プロットの新機能。推定分布とか、中央値・モード・パーセンタイルの推定値とか、個々の残差の散布図とか。
- モンテカルロシミュレーション、TYPE=TWOLEVEL、ESTIMATOR=BAYESのとき、真の因子得点と推定された因子得点の相関やMSEが表示されるようになった、とか... ALIGNMENTオプションを使ったモンテカルロシミュレーションで、真の因子得点と推定された因子得点の相関やMSEが表示されるようになった、とか...(正直、理解できていない。実物を見ないとわからないなあ)
- SAVEDATAコマンドにRANKINGオプションが追加された。ALIGNMENTオプションで実データのとき、RANKINGオプションでファイル名を指定すると、群の因子平均に基づく群のランキングと、因子平均の差の有意性が、CSVファイルに保存されるようになった由。(PISAデータの解析のような状況を想定しているのだろう。ずいぶんマニアックな機能だなあ)
- 識別できないパラメータ名が表示されるようになった (これ、従来はパラメータ番号が表示されていたところで名前が表示され、TECH1と照らし合わせなくて良くなったということかしらん。そりゃ助かる)
- 複数行コメントアウトが可能になった。!*と*!で囲む。(これ、ネストできるのだろうか。SASの/* */みたいにネストできないコメントアウトって、すごく不便だと思うんですよね)
- Mac版のエディタの新機能。
2014年3月30日 (日)
このブログの趣旨に反して、これから書くのは私の覚え書きではなく、他の方に読んでもらうための文章である。どうか私が事柄を正しく説明していますように。そしてこのエントリが、検索結果の上の方に出てきますように。
市場調査に関連する仕事で糊口を凌いでいるのだけれど、折々に受ける業務上のご質問のなかでかなりの領域を占めているのが、いわゆる「ウェイトバック集計」、すなわち確率ウェイティングに関するあれこれである。
もっとも基本的な質問はこういうのだ。「ウェイトバックしたほうがいい?しないほうがいい?」 これはですね、ほんとに答えに困ります。
いま手元に標本抽出確率が不均一な標本があり、集計・分析の際にウェイティングすべきかどうかが問われたとき、考慮すべきポイントは、主に4つあると思う。
- (1)適切なウェイトが構成できるのか。
- (2)それだけの能力とやる気があるか。
- (3)ウェイティングによって推定量の誤差は小さくなると期待できるか。
- (4)ウェイティングによるバイアスの除去という発想は、分析に際しての諸前提と整合するか。
(1) については誤解がないと思う。(2)についてはいろいろ誤解があり、以前義憤に駆られて思うところを書いた。(4)は話がすごく長くなる。
問題は(3)である。実のところこの論点こそが、調査実務に関わる人にとっての道しるべ、ウェイティングの是非という難しい問題に光を差してくれる灯火となると思うのだけれど、不思議なことに、この点についてきちんと説明した日本語の資料をほとんどみたことがない。同業種の方々と話していても、誠に失礼ながら、この点についてきちんと理解しておられる方は非常に少ないように思う。あまりに少ないので、ひょっとして私が全てを勘違いしているのではないかと不安になるほどだ。
(3)について誰かに説明しなければならない羽目に陥ることもある。これが結構大変なのである。できれば避けて通りたい。いまはなんでも検索する時代だから、いちど文章にしてブログかなにかに書いておけば、そのぶん説明の回数も減らせるかもしれない。もし私が全てを勘違いしているのならば、それを指摘してくださる奇特な方が現れないとも限らない。
以上が、この文章を書く主たる理由である。実はもうひとつ、ついうっかりwebアプリをつくってしまったというささやかな理由もあるのだけれど、それはあとで。
問題
以下では、いわゆる「ウェイト・バック集計」、すなわちデータの集計・解析における確率ウェイティングについて考える。上記の4つのポイントのうち(1)(2)(4)はすでにクリアされていることにする。
調査データの解析で確率ウェイティングが登場する局面は意外なほど多岐にわたるのだけれど(Kish(1990)は7種類挙げている)、説明に際しては、もっともわかりやすくて一般的な、非比例の層別抽出を想定する。集計対象は二値変数で、母集団全体における割合に関心があることにする。母集団は十分に大きいことにする。
あまりにシンプルすぎて非現実的ではあるが、次の場面について考えよう。ある新製品コンセプトに対する消費者の購入意向を調べたい。そこで潜在的顧客から抽出した調査対象者に、その製品を買ってみたいどうかを「はい/いいえ」で聴取した。以下、「はい」と答える人の割合のことを購入意向率と呼ぶことにする。
性別で層別した標本抽出を行った。つまり、男と女のそれぞれについて、決まった数の調査対象者を得た。潜在的顧客における男女比は5:5であることがわかっている。しかしなにかの事情があって、調査対象者は男60人、女40人とした(男女比は6:4)。これらの対象者は、その性別のなかでは無作為に抽出されたものとみなすことにする。
いま知りたいのは、潜在的顧客(母集団)の全体における購入意向率である。その推測の手段として、調査対象者(標本)から得た回答を集計し、購入意向率を算出する。
ここでunweightedの集計値とは、「はい」と答えた人の人数を100で割った値である。
いっぽうweightedの集計値は次のように説明できる。男60人における購入意向率、女40人における購入意向率をそれぞれ求め、得られた2つの値を、母集団における割合(ここではそれぞれ0.5)で重みづけて合計する。これがweightedの集計値である。
あるいは次のようにいいかえてもよい。まず各対象者に適切な「ウェイト」を与える。たとえば、男性の対象者には5/6=0.833, 女性の対象者には5/4=1.250というウェイトを与える。次に、「はい」を1点、「いいえ」を0点とし、各対象者の持ち点にウェイトを掛けて合計し、最後にウェイトの合計で割る。これがweightedの集計値である。
さて、unweightedの集計値とweightedの集計値、どちらを使うべきか。ウェイティングすべきか、すべきでないか。
たいていの人はこう答える。ウェイティングすべきです。なぜなら、母集団における男女比が標本における男女比と異なっているので、標本から得たunweightedの集計値は、男性の回答の方向に偏ってしまうからです。
もう少し経験のある方はこう答える。確かにウェイティングすべきでない場合もあります。この例では男女だけが問題になっていますが、男女、年代、地域、などなどと複数の層が登場すると、ウェイトを算出するためのサンプルサイズが小さくなり、極端なウェイトが得られてしまい、集計値はかえって不適切になってしまうことがあります。気をつけましょう。
僭越ながら、この説明は間違っていると思う。少なくとも、ストーリーの半分しか語っていない。
私はこう答えたい。ウェイティングすべきだとも、すべきでないともいえません。
シナリオA. ウェイティングすべき場合
いくつかの架空のシナリオを考えよう。
まず最初のシナリオ。私たちは知らないのだが、実は母集団における購入意向率は、男性で0.4, 女性で0.6であるとしよう(女性の評判のほうがよいわけだ)。関心があるのは全体の購入意向率だから、つまり0.5が「正解」である。
このとき、標本における購入意向率は、男性で0.4のまわりの値、女性で0.6のまわりの値となる。標本は男性を多く含んでいるので、unweightedの集計値は男性の方向に向かって偏る。つまり、「正解」よりも少し低めになりやすい。
下の図はその様子を示したものである。
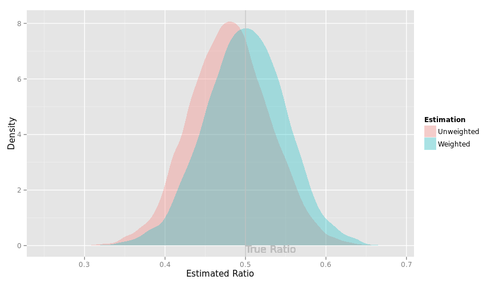
赤の山は、この架空の調査をコンピュータ上で10000回繰り返し、unweightedの集計値がどのような値をとるかを調べた実験結果を示している(微妙にデコボコしているけど、あまり気にしないでください)。赤の山の位置は、「正解」よりも少し左側にずれている。
いっぽう青の山はweightedの集計値の分布を示している。この山の真ん中(平均)は「正解」に一致する。つまり、ウェイティングによって、標本の男女比が母集団の男女比と異なることによる偏りを取り除くことができるわけである。
よかった、よかった。これがウェイティングにとってハッピーなシナリオである。私たちはウェイティングすべきだ。
シナリオB. ウェイティングすべきでないシナリオ
別のシナリオ。私たちは知らないのだが、実は母集団における購入意向率は、男性で0.5, 女性も0.5であるとしよう(購入意向は性別とは無関係なわけだ)。ここでも「正解」は0.5である。
標本における購入意向率は、男性で0.5のまわりの値、女性で0.5のまわりの値となるだろう。標本は男性を多く含んでいるけれど、男女のあいだに差がないので、unweightedの集計値は偏らない。でもweightedの集計値も偏りはしない。だから「ウェイティングしてもしなくてもよい」。と考える人が多い。
ここに落とし穴がある。このシナリオでの集計値の分布を示す。
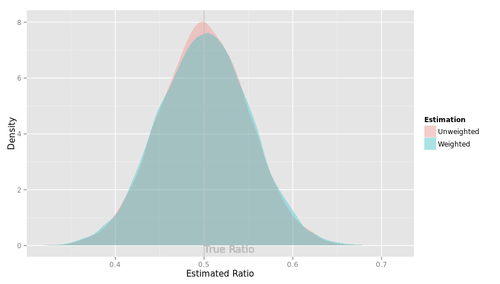
確かに、赤の山も青の山も、「正解」である0.5のまわりに分布している。でもよく見ると、青の山のほうがほんの少し、下方向につぶれて、裾の広い形になっている。つまり、unweightedの集計値に比べてweightedの集計値は、「正解」からより離れた値をとりやすい。このシナリオでは、「ウェイティングしてもしなくてもよい」のではない。ウェイティングすべきでないのである。
このように、weightedの集計値の分布は、unweightedの集計値の分布よりもばらつきが大きくなる。ウェイティングとは、集計値の分布のばらつきを犠牲にして、集計値の分布の偏りを取り除く手続きであるといえる。
シナリオC. 手に汗握るシナリオ
シナリオAは、集計値の偏りをウェイティングによって取り除くのが望ましいシナリオであった。シナリオBは、集計値に偏りが存在せず、ウェイティングによって集計値がばらついてしまう害が顕在化するシナリオであった。
では、その中間のシナリオ。母集団における購入意向率は性別によってわずかに異なり、男性で0.48, 女性は0.52であるとしよう。「正解」は0.5である。
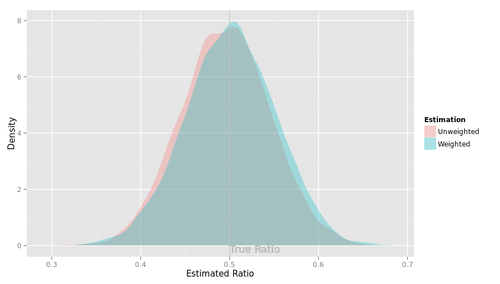
unweightedの集計値の分布は少し左にずれている。いっぽうweightedの集計値の分布は、その平均が「正解」に一致している。その代償として、分布のばらつきは少し大きい。
さて、どちらの集計値がよいだろうか?
そもそも、私たちが求める集計値とはどんな集計値だろうか。
weightedの集計値は、「正解」からみて偏りがない、すなわち、長い目で見て「正解」より大きくなりやすくも小さくなりやすくもない、という美点を持っている。いっぽうunweightedの集計値は、その分布の平均からみてばらつきが小さい、すなわち、長い目で見てその値が安定しているという美点を持っている。
でも私たちは、長い目で見て性質の良い集計値を得るために調査を行っているのではない。たった1回の調査を通じて、母集団(潜在的顧客)の性質について少しでも正しい知識を得たいと思っているのである。だから本当に重要なのは、調査によって得られた集計値が「正解」により近いことである。
上のシナリオで、集計値と「正解」0.5との差がどうなるかを計算してみよう。図でいえば、赤の山と青の山のそれぞれについて、山を形作る無数の点のそれぞれが、(その山の平均でなくて)「正解」0.5からどのくらい離れているかを調べてみる。統計学の伝統に従い、差を二乗した値を平均して表すことにする。これを平均二乗誤差という。
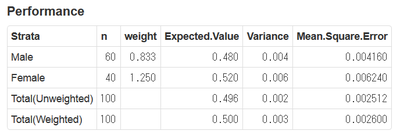
unweightedの集計値の分布は、平均0.496(男性寄りに偏っている)。分散0.002。平均二乗誤差0.0025。
weightedの集計値の分布は、平均0.5(偏りが取り除かれている)。分散0.003(すこし大きくなっている)。平均二乗誤差は0.0026。
僅差ではあるが、unweightedのほうが誤差が小さい。つまり、このシナリオでは、私たちはウェイティングすべきでない。
シナリオのマップ
これらの3つのシナリオでは、母集団の購入意向率が男女それぞれについてわかっていた。実際の調査は、母集団の性質がわからないからこそ行うわけだから、上のような図は手に入らない。
しかし、こういう図を描くことはできる。
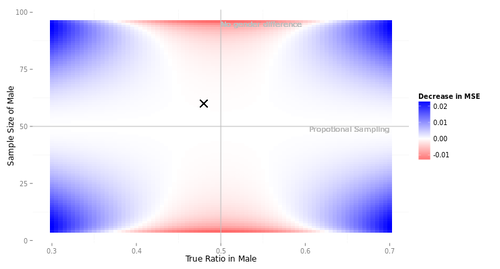
この図は、母集団の男女比は5:5, 母集団全体での購入意向率は0.5, 標本サイズは100, という3点だけを決めて描いている。
横軸は母集団における男性の購入意向率を示す。3つのシナリオでは、それぞれ横軸0.40, 0.50, 0.48であった。縦軸は男性の標本サイズを示す。3つのシナリオではすべて60であった。図中の×印はシナリオCを示している。
図中の色は、unweightedの集計値の平均二乗誤差と、weightedの集計値の平均二乗誤差との差を表している。青のエリアは、ウェイティングした方が誤差が小さい(ウェイティングすべきである)。赤のエリアは、ウェイティングしないほうが誤差が小さい(ウェイティングすべきでない)。
この図からいろいろなことがわかる。
- もし男性の標本サイズが50人に近かったら、ウェイティングしようがしまいが、集計値の性質はたいしてかわらない。考えてみれば当然である。母集団の男女比と標本の男女比がほぼ等しく、男にも女にもほぼ同じウェイトが与えられるためである。
- 男性の標本サイズが50人から離れると、ウェイティングすべきシナリオ(青)とすべきでないシナリオ(赤)が生まれる。母集団において購入意向に男女差があるときは青、ないときは赤である。
「極端なウェイト」
ウェイティングについての説明をみていると、ウェイティングの弊害として「ウェイトが極端なときは集計値の誤差が大きくなる」という点が挙げられていることが多い。この説明は当たっている面もある。上の図でいえば、ウェイト値は極端な値になるのは天井付近や床付近である。たしかに赤くなっている。
しかし、赤のエリアは天井や床だけでなく、もっと内側にも広がっている。たとえば、さきほどの3つのシナリオはすべて、ウェイトは男0.833, 女1.250であった。これを「極端なウェイト」と呼ぶのは難しいだろう。それでも、ウェイティングによって誤差が大きくなる事態は生じた。
このように、ウェイトが極端な値になるかどうかは、ウェイティングの是非にとって本質的問題ではない。
標本サイズとの関係
この図は状況によって変わる。全体の標本サイズを500に増やしてみよう。赤のエリアは小さくなってしまう。
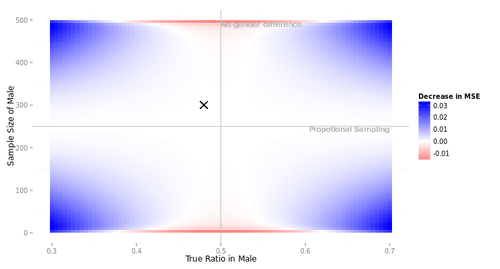
このように、標本サイズが大きいとき、weightedの集計値はunweightedの集計値に比べて有利になる。
これは次のように考えるとわかりやすいだろう。ウェイティングとは、集計値の偏りを取り除く代わりにばらつきを拡大する手続きである。集計値のばらつきは標本サイズと関係している。標本サイズが小さいときは、集計値のばらつきがもともと大きいので、ウェイティングによる拡大の影響が深刻でなる。それに対し、標本サイズが大きいときは、集計値のばらつきがもともと小さいので、ウェイティングによる拡大の影響はさほど問題にならない。
このように、ウェイティングの是非を判断する際のひとつの重要なポイントは、全体の標本サイズである。
母集団特性との関係
もっと評判の悪い製品だったらどうなるか。標本サイズを100に戻し、今度は母集団全体の購入意向率を0.2に下げてみよう。
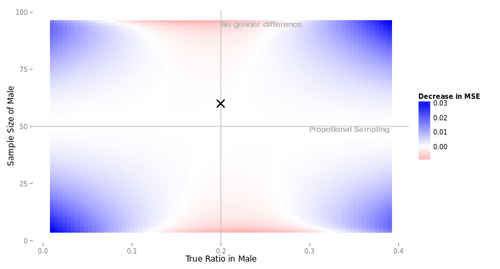
興味深いことに、赤のエリアは左右非対称になる。よくみると、男性の標本サイズのほうが大きい場合(図の上半分)、男性のほうが購入意向が高い場合にはウェイティングすべきエリアが広く(図の右上)、男性のほうが購入意向が低い場合にはウェイティングすべきでないエリアが広い(図の左上)。
これは割合という集計値の持っている性質に由来している。購入意向率とはすなわち購入意向者の割合である。割合という集計値は、真の値が0.5に近いときにばらつきが大きくなる性質を持っている。層別抽出においては、ばらつきが大きい層の標本サイズを増やしておけば、全体の集計値のばらつきを小さく押さえることができる。図の右上と左下がそれである。集計値のばらつきがもともと小さいぶん、ウェイティングにとって有利になる。
この実験からわかること
この簡単な実験から、次の点がわかる。ウェイティングすべきかどうかという問いに簡単な答えはない。
標本抽出デザインだけからは、ウェイティングすべきだともすべきでないともいえない。たとえばこんな批判を耳にすることがある。「この調査、性別と年代で均等割り付けしている調査なのに、なんでウェイトバック集計していないんだ?」 こういう非難はいささか早計に過ぎると思う。非比例の層別抽出でも、あえてウェイティングしないという判断があってしかるべきである。ウェイティングは集計値の誤差を減らすこともあれば増やすこともあるのだ。
ではどうすればいいのか
ウェイティングすべきかどうかという問いに簡単な答えはない。でも、あれこれ考えた上で、それなりの答えを出すことはできる。
上の実験から、集計値の誤差という問題について考えるための簡単なガイドラインを手に入れることができる。その調査で測定した変数のうち重要な変数(たとえば購入意向)について、次の3点に注目すれば良い。
- それらの重要な変数と、ウェイトを構成する際の層別変数(たとえば性別)との間に強い関係があるときは、ウェイティングしたほうがよい。上の例でいえば、購入意向が男女によって大きく違うときは、ウェイティングしたほうがよい。
- 集計値のばらつきがもともと大きいと考えられるときは、ウェイティングしないほうがよい。たとえば標本サイズが小さいときはウェイティングしないほうがよい。
- 調査の目的からみて、集計値の偏りよりもばらつきが問題になる場合は、ウェイティングしないほうがよい。たとえば、同じ標本抽出デザインで縦断調査(トラッキング調査)を行い、集計値の変化に注目する場合は、ウェイティングしないほうがよい。
この3つの注意点に、冒頭に挙げた3つのポイント(適切なウェイトを構成できるか、能力とやる気があるか、分析の諸前提と整合するか)を加えれば、ウェイティングの是非を判断するための材料が揃うのではないかと思う。
シミュレータつくっちゃいました
ところで、この文章を書いたもうひとつの理由、ささやかなほうの理由は...この文章で説明したシミュレーションを行うためのwebアプリを作ってしまったためである。図表はこのアプリでつくりました。
 URLは今後変わると思いますのでご注意ください。
URLは今後変わると思いますのでご注意ください。
Shinyというシステムの使い方を勉強するつもりで作り始めて、たった半日でできてしまった。おそろしい時代になったものだ。
ご関心あらばどなたでもお試しくださいまし。なかなか楽しいのではないかと思います。
2015/03/11 追記: アプリは停止しました。お粗末様でございました。
「ウェイトバック集計」すべき場合とすべきでない場合がある(ということを説明するためのwebアプリを作ってしまった)
2014年2月16日 (日)
Mplus 7.1に搭載された多群因子分析のための新機能が、魅力的なんだけどちょっとわかりにくいので、自分のための備忘録としてメモをとった。誰かの役に立たないとも限らないからブログに載せておく。きっとどこか間違えていると思うので、ほんとにお使いになる方はマニュアルをごらんください。
この新機能 「MODEL=」は、「GROUPING=」か「KNOWNCLASS=」をつかった多群モデルで、測定不変性についてのカイ二乗検定を自動的にやってくれるというもの。従来は「DIFFTEST=」を使ったりなんだり、非常に面倒だった。
「MODEL=」が使えるのはCFAかESEMのモデル。BY文は一回しか使えない(一次因子しか定義できない)。部分測定不変性は扱えない。変数のタイプは以下に限られる。
- 連続変数で、ML推定かベイズ推定
- センサード変数で、WLS推定かML推定
- 二値ないし順序カテゴリカル変数で、WLS推定かML推定かベイズ推定
- カウント変数で、ML推定
つまり、inflatedな変数(日本語ではなんて訳すのかしらん... 「ゼロ過剰モデル」っていうときの「過剰」ですね)、名義変数、連続時間生存変数、負の二項分布の変数、は扱えない。
「MODEL=」は値として、CONFIGURAL, METRIC, SCALARの並びをとる。たとえば「MODEL = CONFIGURAL METRIC SCALAR;」という風に指定する。
さて、「MODEL=」を指定すると正確にはどんなモデルが構築されるのか、という点だが、これが結構ややこしい...
以下、因子分散の指定を、どこかの項目の因子負荷を固定するやり方で行う場合を[A]、どこかの群の因子分散を固定するやり方で行う場合を[B]と略記する。なお、Mplusが勝手に [B]を適用するとき、「GROUPING=」を使っている場合は最初の群、「KNOWNCLASS=」を使っている場合は最後の群が選ばれる。
- 連続変数、センサード変数、カウント変数の場合。これはまあ想像通りで、
- CONFIGURAL: 因子負荷、切片、残差分散は群間で自由。因子平均は全群で0に固定。
- METRIC: 因子負荷は群間で等値。切片と残差分散は群間で自由。因子平均は全群で0に固定。
- SCALAR: 因子負荷と切片は群間で等値。残差分散は群間で自由。因子平均はある群で0に固定, 他の群は自由。
- さあ、徐々にややこしくなって参ります。二値変数、WLS推定の場合。なお、以下にスケール・ファクタとあるのはdelta法の場合、残差分散とあるのはtheta法の場合。
- CONFIGURAL: 因子負荷、閾値は群間で自由。スケール・ファクタor残差分散は全群で1に固定。因子平均は全群で0に固定。
- METRIC: 指定できない。
- SCALAR: 因子負荷と閾値は群間で等値。スケール・ファクタor残差分散はある群で1, 他の群で自由。因子平均はある群で0, 他の群で自由。
- 二値変数、ML推定の場合。METRICが指定できる。なぜなら、残差分散がどの群でも1であると暗黙のうちに指定されているから(そ、そうなんですか)。
- CONFIGURAL: 因子負荷、閾値は群間で自由。因子平均は全群で0に固定。
- METRIC: 因子負荷は群間で等値、閾値は群間で自由、因子平均は全群で0に固定。
- SCALAR: 因子負荷と閾値は群間で等値。因子平均はある群で0, 他の群で自由。
- 順序カテゴリカル変数、WLS推定の場合。なお、以下のいずれかの場合、METRIC は指定できない: (1)クロス・ローディングがある場合。(2)[B]路線。(3)ESEM。なお、以下にスケール・ファクタとあるのはdelta法の場合、残差分散とあるのはtheta法の場合。
- CONFIGURAL: 因子負荷、閾値は群間で自由。スケール・ファクタor残差分散は全群で1に固定。因子平均は全群で0に固定。因子分散は、[A]ならば群間で自由、[B]ならばある群を除き自由。
- METRIC: 因子負荷は群間で等値。スケール・ファクタor残差分散はある群で1, 他の群で自由。因子平均はある群で0, 他の群で自由(←ここ、つい勘違いしそうですね)。各項目の最初の閾値が群間で等値。2番目以降の閾値は、[A]のために選ばれた項目のみ群間で等値。因子分散は群間で自由。なんでこんな指定になるのかは、Millsapの測定不変性の本を読めとのこと。いやーん。
- SCALAR: 因子負荷と閾値は群間で等値。スケール・ファクタor残差分散はある群で1, 他の群で自由。因子平均はある群で0, 他の群で自由。因子分散は、[A]ならば群間で自由、[B]ならばある群を除き自由。
- 順序カテゴリカル変数、ML推定の場合。
- CONFIGURAL: 因子負荷、閾値は群間で自由。因子平均は全群で0に固定。
- METRIC: 因子負荷は群間で等値。閾値は群間で自由。因子平均は全群で0に固定。因子平均はある群で0, 他の群で自由。
- SCALAR: 因子負荷と閾値は群間で等値。因子平均はある群で0, 他の群で自由。
あれ? 二値や順序カテゴリカル変数でベイズ推定したらどうなるんだろうか。今度試しにやってみよう。
Mplus 7.1 で多群因子分析をやるときの魅惑の新機能 MODELオプションについて
2013年5月19日 (日)
このブログを書き始めてからずいぶん経つが、所詮は自分のための備忘録に過ぎない。いちばん熱心な読者はたぶん私だ。書店の棚に平積みになっている連載マンガのこの巻を、俺はもう読んだだろうか? と疑問に思った際、このブログはとても重宝する。店頭でスマフォと格闘している姿は、あまり格好のよいものではないけれど。
そもそも私には世の中に訴えたいことが特にない。とりたてて語るべき知恵もない。アクセスログを調べると、過去のいくつかの記事が予想外に多くの方に読まれていることに驚くが(片側検定について書いた記事とか)、もっときちんとした専門家がお書きになったものをご覧いただいたほうが良いわけで、少し申し訳なく思っている。
これから書くのは、このブログを書き始めて以来ほとんどはじめて、純粋に自分以外の誰かのために載せる記事だ。特に、検索エンジン経由でたどり着く方に向けて載せる記事だ。
振り返ってみると、私は何年か前から、だいたい年に数回のペースで、以下の内容をどなたかに説明している。聞き手にとっては面倒で退屈な内容だ。説明に成功することもあれば失敗することもある。偉大なるインターネットの力によって、説明の回数を減らし成功率を上げたい。
というわけで、ずっと前にお問い合わせに応じて書きためていた文章を載せておくことにする。どうかこの記事が、正しい内容を正しいやりかたで説明していますように。そしてgoogleの検索結果の上の方に出てきますように。
以下の内容はとても単純である。たった一言で要約できる。
統計ソフトがいう「ウェイト」は、調査でいう「ウェイト」ではない。
もう一度書きます。SPSSとかSASとか!そういう統計ソフトの! ウェイトとか重み付けとかっていうのは! 調査でいうところの! いわゆるウェイトのことではないです!
。。。このくらい大声で書いておけば、検索されやすくなるだろうか。
調査における「ウェイティング」
市場調査の会社にお世話になって驚いたことのひとつは、結果の集計に際してウェイティング(確率ウェイティング)を実に良く使う、ということである。親の仇かというくらいによく使う。
確率ウェイティングとはこういう話だ。
ある集団の性質について調べるため、その集団に属する人を対象に調査を行った。調査対象者がこの集団を互いに独立に偏りなく反映していると仮定し、得られたデータから統計的推測を行いたい。
さて、私たちはこの集団(対象母集団)における男女比が5:5であると知っている。しかしなにかの事情によって、調査対象者の男女比は7:3にならざるを得なかった。この事情にはいろんな種類がありうるが、たとえば調査設計時の事情が考えられる(比例割当でない層別抽出)。
この調査対象者の回答をそのまま集計し、平均や割合を求めてしまうと、その値は男の回答をより強く反映してしまい、母集団の推測としては歪んだ値になってしまう。
これを避けるために、男の回答には小さな重み(ウェイト)、女の回答には大きな重みを与えて集計する。これが調査でいうところのウェイティング、すなわち確率ウェイティングである。
なお英語では、probability weighting, survey weighting, sampling weightingなど、いろいろな呼び方が用いられている。検索するときに困る。
市場調査の業界団体である日本マーケティング・リサーチ協会がまとめた「マーケティング・リサーチ用語辞典」を見ると、「ウェイトつき集計」という項で確率ウェイティングが説明されている。市場調査に限らず、広義の社会調査全般において、ウェイト、ウェイティング、ウェイト・バックという言葉は確率ウェイティングを指して使われることが多いと思う。
確率ウェイティングと拡大推計
確率ウェイティングは拡大推計とごっちゃにして語られることもある。
たとえば、前掲の業界団体による市場調査会社向けガイドラインには、ウェイティングについての注意点を挙げている箇所がある。
一般的にウエイトバックが必要となる理由は
1. 層化サンプリングの段階でウエイト付けする場合
2. 回収率の違いにより標本構成に偏りが出てそれをウエイト付けにより補正する場合
上記2点が多いと考えられるが、[中略] ウエイト付けをした場合、主な表すべてにおいて、ウエイト付けした基数(ベース)としない基数(両者を明確に区別)を明示すること。
前半はどうみても確率ウェイティングに関する説明である。ところが後半では、「ウェイト付けした基数」という文言が登場する。ウェイティングしようがしまいが標本サイズは標本サイズなのであって、これは意味不明である。
実は、「1000人の対象者のうち3000人がこの製品を買いたいと答えた、市場には潜在顧客が1000万人いるから、発売すればきっと300万人が買ってくれるだろう」というような単純な拡大推計を指して「ウェイティング」ということもある。
ガイドラインの文言は、確率ウェイティングと拡大推計の両方について同時に述べているようである。
確率ウェイティングは標本の性質に応じて必要となるもので、あらゆる統計的分析に影響する。いっぽう、拡大推計は標本の性質とは無関係に要請され、要約統計量のなかでも合計にしか影響しない。クロス集計の手順のみについて考えれば似たようなものかもしれないが、このふたつは分けて考えたほうが良いと思う。
ウェイティングした分析はできますか?
調査データの分析において確率ウェイティングはどんなときに必要か。仮に必要だとして、ウェイトはどうやって求めるか。
これはなかなか難しい問題で、容易な答えはない。悩みの種である。あまりに悩んだ末、高名な専門家による解説を全訳してしまったことさえある。若気の至り、窓の雪。しかしその話は脇に置いておく。
本題は、確率ウェイティングのためのウェイトが各ケース(ローデータの行)に対してすでに付与されているとき、そのウェイトを用いながらさまざまな統計的推測を行うことができるか、という点である。つまり、統計ソフトを使い、データに確率ウェイティングを行いつつ、差の検定を行ったり、相関を求めたり、回帰分析や因子分析を行ったりすることができるか(行うべきかどうかは別にして)、という点である。
私は繰り返し説明してきた。できません。十中八九できません。なぜなら、お使いの統計ソフトがいうところの「ウェイト」は、私たちが思っているような意味でのウェイトではないからです。
手計算による確率ウェイティング
ごく簡単な例について考えよう。
母集団における男女比は5:5。事情があって、標本における男女比が7:3となるように設計した。母集団は十分に大きいものとする。非現実的ではあるが、標本サイズは男7, 女3, 計10であるとしよう。
この10人が、ある変数について次のような値を持っている。
| 男性 | 1, 2, 2, 3, 3, 4, 4 |
|---|---|
| 女性 | 1, 2, 3 |
このデータに基づき、母集団におけるこの変数の平均(母平均)について推測したい。
まずは、統計ソフトを使わずに考えてみよう。ひとまず男性に注目する。標本平均は、(1+2+2+3+3+4+4)/7=2.714。つまり、母集団における男性の平均は2.714と推定される。
この推定はどのくらいあてになるだろうか。標本平均の分散を求めよう。統計学の初級の教科書に書いてあるように、標本平均の分散は (不偏分散)/(標本サイズ) である。ええと、不偏分散は1.238, 標本サイズは7 だから、標本平均の分散は1.238/7=0.177だ。
同様に女性についても電卓を叩いてみると、標本平均は2.000, 標本平均の分散は0.333である。
では、全体の平均について考えよう。いま、男性の平均が2.714、女性の平均が2.000と推定されていて、かつ母集団のうち男性は5割、女性は5割であることがわかっているのだから、男女をあわせた平均は 2.714*0.5 + 2.000*0.5 = 2.357 と推定できる。
この推定はどのくらいあてになるか。推定量の分散は、{(男の標本平均の分散) * (男の割合)^2 + (女の標本平均の分散) * (女の割合)^2} となる (ご不審の向きは、L. Kish "Survey Sampling"(Wiley) の80-82頁、豊田秀樹「調査法講義」(朝倉書店) の131-132頁をご覧ください)。ええと、0.177*0.25 + 0.333*0.25 = 0.128である。
以上が「正解」である。表にまとめておく。なお、標本平均の分散の平方根は標準誤差と呼ばれ、広く用いられているので、それも添えておく。
| 母平均の推定値(標本平均) | その分散 | 標準誤差 | |
|---|---|---|---|
| 男性 | 2.714 | 0.177 | 0.421 |
| 女性 | 2.000 | 0.333 | 0.577 |
| 全体 | 2.357 | 0.128 | 0.357 |
手計算による確率ウェイティング(ケース・ウェイトを用いて)
この計算を、個々のケースにウェイトを与える形で表現しなおしてみよう。
まず、各ケースにウェイトを与える。このウェイトは、ケースが母集団から抽出される確率の逆数に比例した値であればなんでもよいのだが、一番わかりやすいのはこういう求め方だ。母集団における男の割合は5割、標本では7割だから、男のウェイトは5/7=0.714。同様に、女のウェイトは5/3=1.667。ウェイトの合計は10となる。
母平均の推定値、すなわち「ウェイティングされた標本平均」を求める際には、個々の値にウェイトを掛けながら合計し、ウェイトの合計で割る。{1*0.714 + 2*0.714 + ... + 2*1.667 + 3*1.667) / 10 = 2.357。
上記の結果とぴったり一致する。計算式を変形しただけだから、当たり前である。
SPSSで試してみると
では、統計ソフトを使って試してみよう。みんな大好きな IBM SPSS Statistic での例を紹介する (ver.19で試しました)。下図のデータを用意する。クリックすると大きくなるはずです。
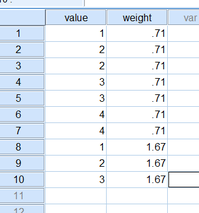
SPSSのメニューには[データ]-[ケースの重み付け]という機能がある。こいつはきっと確率ウェイティングの機能にちがいない、というわけで、「ケースの重み付け」を選び、変数weight を指定してみよう。次に、[分析]-[グループの平均]で変数valueの平均を求める。[オブション]で「平均値の標準誤差」を選んでおく。アウトプットは...
平均値は2.357。「正解」と一致する。ところが、平均の標準誤差は0.332。「正解」よりも少し小さい。
平均の標準誤差なんてどうでもいいです、などというなかれ。たいていの推測統計手法は標準誤差と関係している。みんなが死ぬほど大好きな検定だって、もちろんそのひとつだ。標準誤差が誤りなら、検定の結果だって誤りだ。これはとても大事な話なのである。
頻度ウェイティング
なぜこのような結果になるのか。理由は拍子抜けするほどに簡単だ。
SPSSでいう「ケースの重み付け」は確率ウェイティングのことではない。それは単に「ウェイトの数だけこのケースをコピーしてくれ」ということである。
たとえば上の3行のデータを与え、変数weightで「ケースの重み付け」を行うと、SPSSはこう考える。変数Xが10である行が100行、20である行が120行、30である行が130行、全部で350行のデータなんですね、わかりました、と。
こうした機能は「頻度ウェイティング」と呼ばれることがある。頻度ウェイティングはデータ行列のサイズを小さくするための工夫に過ぎない。
頻度ウェイトによってコンパクトに表現されたデータ行列を一発で扱う方法について考えてみよう。ある変数の標本平均を求める際には、個々の値に頻度ウェイトを掛けながら合計し、頻度ウェイトの合計で割ればよい(なぜなら、頻度ウェイトは本来のローデータにおけるケース数だから)。
この式は、幸か不幸か、確率ウェイティングのもとで母平均の推定値を求めるための式と、た・ま・た・ま、同じ形になっている。そのせいで、SPSSがウェイトを頻度ウェイトとみなして求めた標本平均は、同じウェイトが確率ウェイトだった場合の母平均の推定値 2.357 と、た・ま・た・ま、一致する。だからといって、SPSSが確率ウェイトを正しく扱えるわけではない。
なお、SPSSにとってはウェイトは頻度なのだから、それは整数でないとおかしい。さきほどはウェイトとして整数でない値を与えたが、よくもエラーにならないものである。実際、上記で試した[分析]-[グループの平均]は、整数でないウェイトをむりやり頻度として捉えるが、他の機能は、ウェイトを整数に丸めてしまったり、そもそも無視してしまったりすることがあるらしい。
分析ウェイティング
もうひとつの有名な統計ソフトであるSASでは、また少し話が違う。
SASでは各プロシジャのweight 文でケース・ウェイトを指定できる。その扱いはプロシジャによっても設定によってもちがうのだけれど、通常は、「このデータの行はサブグループの平均を表していて、それぞれのグループのサイズがウェイトで表されているのね」という意味に解される。
たとえば、さきほどの3行のデータをSASに与え、weight列をケース・ウェイトに指定すると、通常は次の意味になる。「サブグループ1はサイズ100, Xの平均は10だった。サブグループ2はサイズ120, Xの平均は20だった。サブグループ3はサイズ130、Xの平均は30だった。」
こうしたウェイティングは「分析ウェイティング」と呼ばれることがある。これもまた、確率ウェイティングではない。
統計ソフトにおける「ウェイティング」とは
統計ソフトの中には確率ウェイティングを扱うことができるものもある。
- SASのsurveymeanプロシジャは、複雑な標本抽出によるデータのために特に用意されているプロシジャで、確率ウェイトを正しく処理することができる。先ほどのサイズ10のデータをsurveymeanプロシジャに与えると、全体の平均は2.357, 標準誤差は0.357、手計算による「正解」とぴったり一致する。
- SPSS StatisticsにはComplex Samplesというパッケージが用意されているらしい。別料金で。
- 経済統計の分野で有名なStataは、与えたウェイトが確率ウェイトなのか頻度ウェイトなのか分析ウェイトなのかを指定できるそうである。
- Rにはsurveyというパッケージがある。
- 公的調査の分野ではSUDAANというソフトが有名である。検索すると茨城県大洗町の割烹「寿多庵」が引っかかるので困ってしまう。あんこう鍋がおいしいらしい。
- 構造方程式モデリングのソフト Mplus は確率ウェイティングに対応している。
- 最後に、世の中には調査データのクロス集計だけに特化した業務用ソフトというものがあって、それらのソフトは、(これも長い話になるのだが)基本的には、確率ウェイティングを伴う検定を正しく行うことができる模様である。
そういうソフトでないかぎり、お使いの統計ソフトでは ... もっと具体的にいえば、SPSS Statistic BaseならびにAdvanced Statistics、SAS/BASEならびにSAS/STATのsurvey系プロシジャを除く全プロシジャ、その他もろもろの統計ソフトでは ... 確率ウェイティングを伴う分析を行うことはできない。メニューに「重み付け」という機能があっても、プロシジャにweight文というのがあっても、それは確率ウェイティングではない。
考えてみれば、統計ソフトのユーザは多方面にわたるが、確率ウェイティングをしたいと思う人はせいぜい市場調査・社会調査の関係者くらいであろう。一般的な統計ソフトのメニューにある「重み付け」が、調査実務家の考える意味でのウェイティングでないとしても、文句をいえる筋合いではない。
ややこしいのは、確率ウェイティングに対応していないソフトに誤って確率ウェイトを与えて要約統計量を求めたとき、平均と割合だけは期待通りの値が出力されることがある、という点である。繰り返しになるが、それはた・ま・た・まである。他の結果は誤っている。
統計ソフトがいう「ウェイト」は、調査でいう「ウェイト」ではない。
あえて教訓を求めるならば
最初に書いたように、私には世の中に訴えたいことは特にない。とりたてて語るべき知恵もない。ただ単に、日頃繰り返している説明を文章にしておき、仕事を楽にしたいだけである。
しかし、あえて教訓らしきものを引き出すとすれば、こういうことはいえる。
私の説明にオリジナリティはない。webを探せば、もっとわかりやすい説明がみつかる。たとえばこちらやこちら。統計ソフトのアウトプットをこまかーく調べた面白い研究もある(PDF)。
さらに、SPSS Statisticsを起動し[ケースの重み付け]ダイアログの[ヘルプ] ボタンを押すと、次の説明が現れる。
[ケースの重み付け] では、統計分析を行うため (複製をシミュレートすることにより) ケースに異なる重みを付けることができます。重み付け変数の値は、データ ファイル内の 1 つのケースが表す観測数を示していなければなりません。いささか不親切ではあるけれど、簡にして要を得た説明である。この記事で長々と書いてきたことはすべて、ソフトのマニュアルに、はっきりと書いてあることなのだ。
にもかかわらず、推定や検定やもっと複雑な統計的分析の際に、SPSS Statisticsの[ケースの重み付け]で確率ウェイティングを行おうとしている方に、私はこれまでたくさん出会ってきた。それはもう、びっくりするくらいにたくさん。そのなかには、すごく優秀な分析者もいらっしゃったし、調査実務に携わって何十年というベテランの方もいらっしゃった。
というわけで、教訓はこうだ。実務家の豊富な経験なるものは、必ずしもあてにならない。統計ソフトの使い方を先輩に教わったり、誰かの書いたブログを読んでいる暇があったら、そのソフトのマニュアルを読んだほうがよいのではないかと思います。
2013年4月17日 (水)
連続変数のベクトル y を指標として持つ潜在クラスモデルについて考える(いわゆる潜在プロファイル・モデル)。話を単純にするため、共変量はなし、指標はすべて局所独立、条件つき分布に多変量正規性を仮定する。
対象者 i がデータ y_i を持っているとしよう。この人の所属クラス C が k である事後確率は
P(C=k | y_i) = P(C=k) [y_i | C=k] / [y_i]
ただし [y_i | C=k] は、クラス k の平均ベクトルと共分散行列を持つMVNである。みよ、大自然の単純な美しさを。
いったいなにを云わんとしているのかというと... 指標がV1とV2の2つしかない、2クラスの潜在クラスモデルを推定したとしよう。mplusが吐いたパラメータ推定値が
Latent Class 1: Means V1 3.248 V2 5.626; Variances V1 1.985 V2 8.243
Latent Class 2: Means V1 8.845 V2 5.298; Variances V1 1.985 V2 8.243
Categorical Latent Variables: Means C#1 0.220
であったとする。さて、V1=6, V2=4のオブザベーションがあったら、そのクラス所属確率は?
まず事前確率について。mplusはカテゴリカル潜在変数の平均を最後のクラスで 0 とするので、P(C=1) ∝ exp(0.22) = 1.24, P(C=2) ∝ exp(0) = 1。足しあげて割合にすると、0.55, 0.45である。
次に尤度。分子のほうだけ考える。Excel風に書くと、C=1ならばnormdist(6, 3.248, sqrt(1.985)) * normdist(4, 5.256, sqrt(8.243)) * 0.55 = 0.00351。C=2ならば0.00206。これを足しあげて割合にして、0.63と0.37。
これが事後確率である。mplusのSAVEDATAで出したものとぴったり、ぴったり一致する。みよ、大宇宙の壮大な神秘を。
なにが云いたいのかというと... マーケット・セグメンテーションの手法として、消費者調査データに基づく対象者分類を行った場合、あとで別の対象者に同じ調査項目を聴取し、その回答に基づいてその人がどのセグメントに属するかを判別したい、ということがある。ものすごくよくある。細かい商売ですみません。
で、分類の際にk-means法を使っていた場合は判別関数をつくるのは容易だが、潜在クラスモデルのような確率モデルをつくってしまうと、あとの判別が大変だ。などと思い込んでいる人がいる。愚かなり。実に愚かなり。
というか、私自身がついついそう思いこんでいたのである。このたび用事があってこの件について考える羽目になり、なんとか自分で考えずに済ませられないものかと考えたが逃げ道はなく、どんよりした気分で机の上に資料を揃え、気分転換用のお菓子も用意し、深呼吸してから考え始めた。15分後、菓子に手をつける間もなく、あまりの簡単さにあっけにとられている私がいた(お菓子は後で食べましたが)。私が愚かでした、反省してます。反省のあまりブログに記録する次第である。いっけんややこしそうだからといって、思考停止してはいけないのだ。
2012年11月14日 (水)
流れ流れて市場調査の会社に拾って頂いた当初,いろいろ面食らうことが多かったのだが,実験計画法? そんなのどうでもいいですよ,科学者じゃないんだから,と真顔でいわれたことがあって,このときも言葉を失った。たぶん実験ということばは,実験室やら白衣やら,おぞましくもアカデミックななにかを連想させ,人を思考停止に導いてしまうのであろう。
たとえば,調査対象者をランダムに2群に分け,一方の群にはある製品に現行のパッケージラベルを貼って提示し,他方の群には同じ製品に新しいパッケージラベルを貼って提示する。で,好意度なり購入意向を比較する。これだって立派な実験である。
ここで「パッケージラベル」を要因 factor という。登場するパッケージラベルは「現行ラベル」と「新ラベル」の二種類あるが,このそれぞれを水準 level という。つまり,このごくありふれたパッケージ・テストは,1要因2水準の実験である。
完全実施要因計画と一部実施要因計画
パッケージラベルの違いは製品への好意度に影響を与えるか。この点について推測する際には,要するに,それぞれのパッケージラベルに対して好意度を聴取し回答を集め,2グループの回答の集まりを比較すればよい。話の都合上,一方の水準について測定したこと(つまり,一方のパッケージラベルについて好意度を聴取したこと) を +1 と表現し,他方の水準について測定したことを -1 と表現することにする。
要因の数がもっと増えた場合について考えよう。たとえば,パッケージラベルの影響だけでなく,蓋の色による影響も,パッケージの形状による影響も同時に調べたい,というような場合である。3要因(A, B, Cと呼ぶ)がそれぞれ2水準を持つとすれば,水準の組み合わせは2*2*2=8個。この8個の製品をつくり,それぞれについて好意度を聴取すれば良いわけだ。以下,以下の8行の表のイメージで考えることにする。
| 製品番号 | A | B | C |
|---|---|---|---|
| 1 | -1 | -1 | -1 |
| 2 | -1 | -1 | +1 |
| 3 | -1 | +1 | -1 |
| 4 | -1 | +1 | +1 |
| 5 | +1 | -1 | -1 |
| 6 | +1 | -1 | +1 |
| 7 | +1 | +1 | -1 |
| 8 | +1 | +1 | +1 |
この表の行,つまり水準の組み合わせのことを,とりあえず製品と呼ぶことにする。英語ではラン run と呼ぶことがあるが,なんと訳せばいいのかわからない。
上の表のように,全ての属性の全ての水準の全ての組み合わせからなる全ての製品を使って実験するのが,ひとつの理想である。こういう実験計画を完全実施要因計画 full factorial design という。しかし,すべての製品を用意するのは大変だ。それに,要因の数が4つ, 5つ, ... と増えたり,2水準の要因だけではなく3水準の要因や4水準の要因が登場すると,可能な製品の数は膨大になり,そのすべてを使った実験は現実的でなくなってしまう。いくつかの少数の製品だけをうまく選び出して実験したい。これを一部実施要因計画 fractional factorial design という。
推定精度のシミュレーション
一部実施要因計画の場合,用いる製品をどうやって選べばよいだろうか。
四の五の言わずに,かんたんなシミュレーションをしてみよう。まず,「正解」を決めてしまう。好意度を7件法評定(1~7点)で聴取する場合について考えよう。各製品はある決まった好意度の高さ(「正解」)を持っている,と想定する。値はなんでもよいのだが,仮に,8製品を通じた好意度の平均は4.0ポイント,Aが-1のときよりも+1のときのほうが好意度が2.4ポイント高い,同様に B, Cではそれぞれ0.6, 0.3の差がある... ということにしよう。こうしてできた「正解」は以下の通り。
| 製品番号 | A | B | C | 正解 |
|---|---|---|---|---|
| 1 | -1 | -1 | -1 | 1.9 |
| 2 | -1 | -1 | +1 | 2.5 |
| 3 | -1 | +1 | -1 | 3.1 |
| 4 | -1 | +1 | +1 | 3.7 |
| 5 | +1 | -1 | -1 | 4.3 |
| 6 | +1 | -1 | +1 | 4.9 |
| 7 | +1 | +1 | -1 | 5.5 |
| 8 | +1 | +1 | +1 | 6.1 |
では,完全実施要因計画に基づいた架空の実験を行おう。対象者120人を8つの製品にランダムかつ均等に割り当てる。対象者には,自分が割り当てられた製品について好意度を評定してもらい,それでお役御免とさせていただく (市場調査ではこういう実験計画をモナディック・デザインと呼ぶことが多い)。各製品に対する人々の好意度はその製品が持っている「正解」の周りをばらつく,と仮定しよう。データ解析の世界でのちょっとした伝統に従い,ばらつきは左右対称なある決まった形状をとる(N(0,2)に従う)ということにしておく。
以上の仮定に従い,コンピュータ上で疑似的な回答データをつくる。現実世界と違って一瞬にしてデータが集まるので気分が良い。よくよく見ると,7件法で聴取したはずなのに回答は整数になっていないし,負の値や7以上の値も含まれているけれど,この際それは気にしないことにしよう。
得られた回答の集計結果をご報告しよう。このたびはどうも運が悪かったようで,各組み合わせに対する回答の平均は「正解」からかなりズレている。
| 製品番号 | A | B | C | 正解 | 回答平均 |
|---|---|---|---|---|---|
| 1 | -1 | -1 | -1 | 1.9 | 2.1 |
| 2 | -1 | -1 | +1 | 2.5 | 3.4 |
| 3 | -1 | +1 | -1 | 3.1 | 3.3 |
| 4 | -1 | +1 | +1 | 3.7 | 3.3 |
| 5 | +1 | -1 | -1 | 4.3 | 3.9 |
| 6 | +1 | -1 | +1 | 4.9 | 4.8 |
| 7 | +1 | +1 | -1 | 5.5 | 4.9 |
| 8 | +1 | +1 | +1 | 6.1 | 6.7 |
こうした実験を行った場合,データの分析には分散分析と呼ばれる手法を用いることが多いので,ここでもそれに従おう。主効果モデルと呼ばれる分散分析モデルを適用する(そのことの是非については,のちほど)。このモデルでは,全製品の平均, Aが+1であるときの平均に対する増加分, Bが+1であるときの増加分, Cが+1であるときの増加分,の4つをデータから推定する。以下ではこれらを「切片」「Aの係数」「Bの係数」「Cの係数」と呼ぶ。その「正解」は,4.0, 1.2, 0.6, 0.3である。
推定の結果は,それぞれ3.92, 1.16, 0.63, 0.38となった。Aの影響が過小評価され,B, Cの影響が過大評価されている。
この実験はたまたま運が悪かったのかもしれない。そこで,同じ設定の実験を10000回繰り返す。Excelなり統計ソフトウェアなりに慣れている人なら,さほど難しくはない作業だ。
各実験において,得られた4つの推定値と「正解」とのズレを調べ,10000回の実験についてズレを集計する。データ解析のちょっとした伝統に従って,ここでは推定値と「正解」の差の二乗の平均を集計値とする。推定の精度が低いほど大きな値になる。結果は... 切片0.033, Aの係数0.034, Bの係数0.033, Cの係数0.034となった。
完全実施要因計画ならば,ズレの大きさはこれくらいだ,という見当がついた。今度は,一部実施要因計画を用いて実験してみよう。あれこれ考えるのが面倒なので,片っ端から実験してみることにする。
ええと,8製品のうち7つを用いる実験計画は8パターン,8製品のうち6つ用いるなら28パターン,8製品のうち5つ用いるなら56パターン, 8製品のうち4つ用いるなら70パターン,ここまで計162パターン。さらに,8製品のうち3つなら... いや,それはさすがに虫が良すぎるだろう。実際,ちょっと考えてみればわかるのだが,各製品が持つ好意度の「正解」について予備知識がない状況で,3つの要因がもたらす影響を評価するためには,少なくとも4つの製品について調べる必要がある。
というわけで,対象者数を120人に固定したまま,8つの製品から4つ以上を用いる計162パターンのそれぞれについて,完全実施要因計画と同様に10000回の架空実験を繰り返してみる。さすがにExcelではちょっと面倒だが,なんらかの統計ソフトウェアの使用方法に慣れていれば,それほど難しい作業ではない。これをSASで試した時は,20分くらいで計算開始にこぎつけた。このたびRで書き下ろしたら,計算までに小一時間かかってしまったが,これは私が下手だからで,上手い人ならあっという間だと思う。
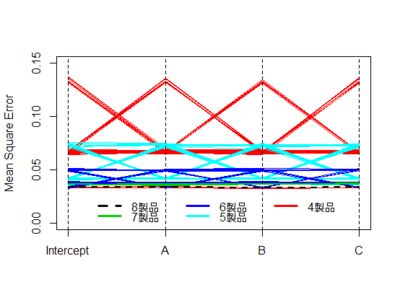
結果を上図に示す(クリックで拡大表示)。162パターンのなかには,とてもじゃないが無理,というようなパターンも登場してしまうので(例, 製品{1, 2, 3, 4}。どれもAが-1である),そのようなパターンは除外してある。
チャートの底部を水平に走る黒点線が,完全実施要因計画の場合のズレの大きさである。製品数 7 の場合のズレの大きさは,その少し上の緑色。つまり,製品を1つ減らしたせいで,「正解」からのズレが少し大きくなっている。以下,6製品, 5製品, 4製品と,製品数を減らすにつれてズレがますます大きくなることがわかる。
。。。いや,ちょっと待て! チャートの底部をよく見てほしい。目をこらすと,ああ,なんということだろうか! 黒点線の周りに,かすかな赤い輝きがみえるではないか!!
直交計画の威力
わざとらしい驚き方で恐縮だが,実は製品数4の一部実施実験計画のなかに,たったふたつだけ,完全実施要因計画に匹敵する推定精度を誇る,特別なパターンが存在するのである。それは,製品{1,4,6,7}(下表のアミカケ部分)を用いる計画,そしてその残りの製品{2,3,5,8}を用いる計画である。
| 製品番号 | A | B | C |
|---|---|---|---|
| 1 | -1 | -1 | -1 |
| 2 | -1 | -1 | +1 |
| 3 | -1 | +1 | -1 |
| 4 | -1 | +1 | +1 |
| 5 | +1 | -1 | -1 |
| 6 | +1 | -1 | +1 |
| 7 | +1 | +1 | -1 |
| 8 | +1 | +1 | +1 |
このふたつの実験計画はなぜ特別なのか。上の表のアミカケ部分をよくみると,このふたつの実験計画は次の2つの特徴を備えていることがわかる。
- A,B,Cのどれをみても,+1と-1が2行ずつはいっている。つまり,ある要因のなかで,各水準を持っている製品数が水準間で同じである。この性質を,釣り合いが取れている balanced という。
- たとえば要因AとBを取り出してみよう。Aが-1のとき,Bは-1がひとつ,+1がひとつである。Aが+1のときも,Bは-1がひとつ,+1がひとつである。つまり,どの2要因を取り出しても,「一方が+1だったら,そうでない場合に比べて,他方は+1になることが多い(少ない)」という関連性がない。この性質を直交している orthogonal という。
少々ヤヤコシイのだが,この2つの性質を同時に兼ね備えた実験計画のことを特に直交計画 orthogonal design という。ここでいう「直交」とは,さきほどの「直交」とはちょっと別の意味で用いられている(計画行列における直交性を指している)。
考えてみれば,これは不思議な話だ。私たちはいま,いくつかの製品についての消費者の好意度の回答を集め,それを分析することで,好意度の背後にあるメカニズムを探ろうとしている。だったら,調べる製品の数は多ければ多いほうがよい,と考えるのが自然であろう。しかし実際には,製品の選び方にはコツがあり,多ければ良いとは限らないのである。
ね? 実験計画法って必要でしょう?
主効果と交互作用
うまい話には大抵裏がある。直交計画の推定精度にも,それ相応の代償が伴うのだけれど,その話の前に,まず直交計画の性質について紹介しておこう。
話をいったん完全実施要因計画に戻す。たいていの場合,私たちは個々の要因が好意度にどの程度影響しているかを知りたい。たとえば,要因Aの2つの水準のあいだで,好意度にどのくらいの差が生じるかどうかを知りたい。これを要因Aの主効果 main effect という。その推測に際しては,Aが+1である4製品に対する好意度の集まりと,-1である4製品に対する好意度の集まりを比較すればよい。
しかし,世の中は時としてわれわれが期待するよりも複雑に出来ている。私たちがそれを知りたいかどうかは別にして,現実には,「要因AとBが両方+1だったときにのみ好意度が高くなる」... というような影響が生じているかもしれない。これを要因Aと要因Bの交互作用効果 interaction effect という。その推測に際しては,A列とB列の符号が合致している4行と,符号が異なっている4行を比較すればよい。
直交計画の分解能
交互作用効果の早見表をつくるつもりで,A列とB列を掛けた列(AB列)を表に追加しておこう。AとBの交互作用をチェックしたいときは,AB列が+1である4行と-1である4行とを比較すればよい。ついでに,「要因1と3の交互作用」(AC列),「要因2と3の交互作用」(BC列),「要因1,2,3の交互作用」(ABC列) も作っておくことにしよう。こうしてできた表は,実験計画法の世界でL8直交表と呼ばれる有名な道具となる。
| A | B | C | AB | AC | BC | ABC |
|---|---|---|---|---|---|---|
| -1 | -1 | -1 | +1 | +1 | +1 | -1 |
| -1 | -1 | +1 | +1 | -1 | -1 | +1 |
| -1 | +1 | -1 | -1 | +1 | -1 | +1 |
| -1 | +1 | +1 | -1 | -1 | +1 | -1 |
| +1 | -1 | -1 | -1 | -1 | +1 | +1 |
| +1 | -1 | +1 | -1 | +1 | -1 | -1 |
| +1 | +1 | -1 | +1 | -1 | -1 | -1 |
| +1 | +1 | +1 | +1 | +1 | +1 | +1 |
さて,話を一部実施要因計画に戻そう。さきほどみつけた直交計画とL8直交表を見比べると,L8直交表でABC列が+1である4行,ないし-1である4行を抜き出したのが,さきほどの直交計画であることがわかる。いいかえれば,さきほどの直交計画をつくるためには,L8直交表でABC列が+1ないし-1である行を抜き出せばよい。つまりこの例で,ABC列は「ありうる製品のうち,一部実施計画に取り入れるべき製品はどれか」を表していることになる。
この「ABC」をこの一部実施要因計画のジェネレータ generator という。また,ジェネレータの桁数を分解能 resolution と呼ぶ。なぜかわからないがローマ数字で書く習慣がある。さきほどの直交計画は分解能IIIと呼ばれる。英語でいうとかっこいいですね。自分がなにかすごくつまらない仕事をしているのではないかと気がめいるときは、小声で「よし、レゾリューション・スリーで実験だ」などと呟けば、すこしは虚栄心が満たせるかもしれない。
分解能IIIの直交計画,その欠点と役割
分解能IIIの直交計画にはある深刻な欠点がある。もう一度,よくみてみよう。
| 製品番号 | A | B | C |
|---|---|---|---|
| 1 | -1 | -1 | -1 |
| 2 | -1 | -1 | +1 |
| 3 | -1 | +1 | -1 |
| 4 | -1 | +1 | +1 |
| 5 | +1 | -1 | -1 |
| 6 | +1 | -1 | +1 |
| 7 | +1 | +1 | -1 |
| 8 | +1 | +1 | +1 |
アミカケされた4行では,Aが-1である2行ではBとCの符号が異なり,Aが+1である2行ではBとCの符号が一致している。
つまりこういうことだ。仮に,実験の結果Aが+1である2製品に対する好意度の集まりが,Aが-1である2製品に対する好意度の集まりよりも高かったとしよう。それは「Aによって好意度が変わる」ことを意味しているのかもしれないし,「BとCの組み合わせによって好意度が変わる」ことを意味しているのかもしれない。つまり,Aの主効果を意味しているのかもしれないし,BとCの交互作用効果を意味しているのかもしれない。
このように,分解能IIIの直交計画では,Aの主効果とBCの交互作用効果を区別して捉えることができない。同じことが,Bの主効果とACの交互作用効果の間にも,Cの主効果とABの交互作用効果の間にもいえる。
さきほどのシミュレーションでは,データに主効果モデルと呼ばれる分散分析モデルを適用した。つまり,主効果のみ推定するモデルである。本来,交互作用効果があるかどうかわからない状況下では,交互作用効果に関心があろうがなかろうが,交互作用効果の推定も行うべきである。交互作用効果が存在するのに,それを無視したモデルを使ってしまうと,誤った知見が得られてしまうかもしれないからだ。
しかし,分解能IIIの直交計画で得たデータでは,そもそも主効果と交互作用効果を切り分けられない。分散分析では主効果モデルしか使えない。得られた主効果の推定値がほんとに主効果を表しているのかどうかは,分析者の解釈に任されている。3要因の主効果をたった4製品で精度よく推定できることの,これが代償である。
いや,そういう言い方は後向きですね。もっとポジティブに言い直せば,こうだ。いま,測定値に影響しそうな要因がたくさんあるんだけど,どれが影響しているのかわからない,としよう。そんなときは,思いつく要因を片っ端から組み込んだ実験をやって,影響がありそうなものを選び出すことができたら便利である。そんな場合は,とりあえず交互作用効果は無視して,主効果だけに注目するという作戦が有用であろう。分解能 III の計画は,そんな場面で役に立つ。
最適計画への道
さて,上のアイデアは,完全実施要因計画で必要とされる膨大な数の製品のなかから,釣り合いと直交性を保ったまま現実的な数の製品をうまいこと選び出すというアイデアであった。
ところが実際には,要因の数や水準の数が多くなると,完全実施要因計画の製品数は膨大になる。そこから少数の製品を抜き出すと,釣り合いと直交性がどうしても崩れてしまうことが多い。どうしたらよいか?
さきほど試したような簡単なシミュレーション実験を行い,推定精度が相対的にましな計画を選べばよい,というのがひとつの答えである。しかし,ありがたいことに,分散分析のような線形モデルがさまざまな実験計画のもとで持つ推定精度は,数理的に単純な一定の性質を持つことが分かっている(パラメータの推定量の共分散行列は情報行列の逆行列に比例する)。それによれば,推定精度がもっともよいのは完全実施要因計画ないし直交計画であり,釣り合いが崩れたり直交でなくなったりするにつれて推定精度が下がっていく。その低下の程度も簡単に計算できる。
そこで,直交計画が作れない場合にも,実現可能な範囲内でもっとも推定精度のよい実験計画を探そう,という考え方が登場する。こういうアプローチを最適計画 optimum design という。完全実施要因計画のときに100%となるような推定精度の指標を使い,なるべく100%に近い一部実施実験計画を探そうというわけである。大変な作業だが,コンピュータが一瞬にして良い答えを出してくれる。推定精度を測る指標にはいくつかあるが,D-最適性という指標が用いられることが多い(この指標は,情報行列の逆行列の固有値の幾何平均の小ささを表す)。
面白いことに,釣り合いの崩れ方のちがいのせいで,要因が直交している計画よりも直交していない計画のほうがD-最適性が高くなったりすることがある。そのせいで,実験計画法の教科書の説明どおりに丁寧に計画するより,専用のソフトを使って力づくで作ったほうが,良い計画ができることがある。
市場調査の教科書をみると,実験計画の初歩的概念は紹介してあるし,直交計画について説明している親切な教科書もある。でも,ソフトウェアでの実験計画作成や,D-最適性について説明している本は見かけない。他の分野では常識となっている話なのに,なんでですかね? もっと普及してよい考え方だと思う。
最適計画の使い道
もちろん,実験計画の良し悪しは,あるひとつの基準だけで決められるものでもない。たとえば,交互作用効果を無視した実験ではあるものの,あとでこっそり交互作用の有無もチェックしたい,といったこみいった裏の事情がある場合も珍しくないだろう。D-最適性が多少低くなってもいいから,釣り合いが崩れているのだけは困る,とか。どうしても実現が難しい製品があるとか。どうしてもこの製品を入れたいとか。現実は常に多様である。
それに,ここまでの話はすべて,データのサイズが一定で,用いる製品数だけが変えられる,という場合の話である。実際には,製品数が増えればデータサイズも増える場合が多いだろう(各対象者に全製品を提示する場合とか)。その場合は,もちろんデータサイズが大きくなった方が推定精度は向上する。しかし,用いる製品数の増加は,実験にかかる時間やコストの増大を意味したり,対象者の疲労や回答の質の低下につながるかもしれない。いろいろな事情が複雑に絡み合い,もはやD-最適性どころの騒ぎではない。実験の設計はどうしたって,複数の条件を睨みながら考える複雑な意思決定プロセスなのだ。
というわけで,一部実施要因計画をつくる際のお勧めはこうだ。リサーチャーが残業して,手作業で必殺の実験計画をひとつだけ作り込むのは,もうやめよう。さっさと実験計画用のソフトを買い,さまざまな設定の下の実験について、実験計画のいくつかの候補をつくってしまえばよい。何個でも一瞬にして作れるし、追加料金はかからない。で,それぞれの候補について,D-最適性や,その場で求められているさまざまな特性についてチェックし,一番ましな奴を選ぶ。という手順が,よろしいのではないかと思います。
Postscript
ずいぶん前に,当時の同僚からもらった質問に応じて書きかけていた返事が,途中で放ってあったのをみつけた。捨ててしまうのもなんなので,具体的な業務と関わる部分を削って,ブログに書き留めて供養とする次第である。これを読んだ誰かが,私の愚かな誤りを見つけて馬鹿にするかもしれないが,それはまあ,そのときである。
要因計画を用いた製品テストなんて市場調査の世界では稀だ,とおっしゃる方がいらっしゃるかもしれない。そのような,良く言えば現実力旺盛な方(悪く言えば想像力を欠いた方)のためには,たとえばBIBDによる製品テスト,応答曲面モデルによる最適化,そして離散選択型コンジョイント分析といった,市場調査においてもっとおなじみの場面においても,最適計画というアイデアがきわめてパワフルであることを示せばよいのだが,ちょっと気力が尽きました。
本稿の種本はKuhfeld, Tobias & Garrett (1994, J. Mktg. Res.),岩崎(2006)「実験計画法」,などだが,どれもきちんと読んで理解しているとは言い難いので,すべての誤りの責任はもちろん私にあります。
2012年3月29日 (木)
被験者に $t$ 個の刺激のうち 2個を呈示し、どちらが好きかを比較させる場合について考える。提示順序を考慮すると刺激対の数は$t(t-1)$個ある。対象者をいずれかの刺激対にランダムに割り当て、たとえば、先に見せたほうの刺激が非常に良いときに3, 同じときに0, 後にみせたほうが非常に良いときには-3... というふうに答えてもらうことにする。各刺激に対する選好の程度に,刺激間でどのような差があるか。
刺激対$(i, j)$について対象者$k(=1,...,n)$が評価した際の反応を $x_{ijk}$ とし、
$x_{ijk} = (\alpha_i - \alpha_j) + \gamma_{ij} + \delta_{ij} + \epsilon_{ijk}$
と考える。$\gamma$は組み合わせの効果($\gamma_{ij} = -\gamma_{ji}$)、$\delta$は順序効果($\delta_{ij} = \delta_{ji}$)、$\epsilon$は誤差項。$\alpha$の総和、$\gamma$の$i$ないし$j$を通した総和は0とする。
この構造モデルに基づく分散分析は難しくない。全平方和は
$S_T = \sum_i \sum_j \sum_k x_{ijk}^2$
自由度は$nt(t-1)$, 値の個数そのものである。要因は4つあるが、横着して主効果と誤差のことだけ考える。
先に $\alpha_i$ の推定量について考えておく。これを $a_i$ と書くことにする。また、構造モデルの右辺から誤差項を取ったやつを$\mu_{ij}$、さらに$\delta$も取ったやつを$\pi_{ij}$、それぞれの推定量を $u_{ij}$, $p_{ij}$と書くことにする。順にゆっくり考えていくと、
$u_{ij}= 1/n \sum_k x_{ijk}$
$p_{ij} = 1/2( u_{ij} - u_{ji})$
$a_i = 1/t \sum_j p_{ij}$
以上を整理すると、$a_i = 1/(2tn) (\sum_j \sum_k x_{ijk} - \sum_j \sum_k x_{jik}) $となる。
$\alpha_i$ の推定量が手に入ったところで、主効果の平方和について考えると、
$S_\alpha = n \sum_i \sum_k (a_i - a_j)^2 = 2nt \sum_i a_i + 2n \sum_i \sum_j (a_i a_j)$
よくよくみると第二項は0である。スバラシイ。自由度は$t-1$。
誤差の平方和は
$S_\mu = n \sum_i \sum_j u_{ij}^2$
で、$S_E = S_T - S_\mu$ と考えれば楽勝である。自由度は $t(t-1)(n-1)$。このように、実に綺麗に算出できる。刺激間比較のためにはスチューデント化された範囲を使えば良い。
では、まったく同じデザインで、提示順序を無視して分析したらどうなるか? 構造モデルは
$x_{ijk} = (\alpha_i - \alpha_j) + \gamma_{ij} + \epsilon_{ijk}$
セル(i,j)とセル(j,i)をコミにして分析することになる。
$u_{ij}= 1/(2n) (\sum_k x_{ijk} - \sum_k x_{jik})$
全平方和と主効果はさっきと同じで、誤差が変わる。自由度は $t(t-1)(2n-1)/2$となる。なぜそうなのか真正面から考えていたらなんだかわけがわかんなくなってきたんだけど、搦め手から考えると$\gamma$の自由度は$(t-1)(t-2)/2$だから、これでつじつまが合うのは確かだ。
実のところ、前者のモデルはいわゆる「Scheffeの一対比較法」、後者のモデルは62年に芳賀敏郎が発表した「芳賀の変法」なのである。以上、佐藤信「統計的官能検査法」(日科技連)より。
学部生の頃だったか、修士1年の頃だったか、当時心理統計を担当していた先生が、本来教えるべき内容をそっちのけにして、サーストンのケースIIIだのVだの、シェッフェ法だの誰々の変法だの、官能検査関連の超・超・超古典的な手法について蛇のように執念深く語り倒し、心底辟易したことがあった。それは呆れるほどにかびくさく,死ぬほど面倒で、何の役に立つのかさっぱりわからない議論であった。そんなのどうでもいいじゃん、もっと普通の講義をしてくださいよ、と思ったものである。あれは冬だったのだろうか、窓の外には枯れた芝生がみえた。
このたび勤務先で、たまたま一対比較データの分析の話になり、いやその種のデータの分析方法は古くに確立してて、サーストン法とかシェッフェ法とか... と電話口で説明し始めたところで、突然あの時の記憶が、教室の空気の匂いさえも鮮やかに甦り、クラクラとめまいがするような感覚に襲われた。それはほんの数秒のことで、すぐにささやかで平凡な中年男ライフに戻ることができたけれども。
電話を切ってから、頬杖をついて、手元にあった本をぼんやりめくっていたら、シェッフェ法とその変法についてわかりやすく説明していて、なあんだ、あのややこしい話って、こんなシンプルな線形モデルだったのか... と、気の抜けるような思いであった。先生、あの話、もう少しわかりやすく説明できたかもしれませんよ。そして私も、もっとまじめに勉強するか、あるいはもう少し別のことをしておいたほうがよかったかもしれません。
とはいえ、いまとなってはなにもかも詮無い話である。あの先生が亡くなってからずいぶん経つ。
2009年9月25日 (金)
片側検定が許されるのはどんな状況だろうか?
こういうことを延々と考えても,なんら益がないことははっきりしているのだが,それでもいったん考え始めると,途中で投げ出すのは難しい。いや,むしろどうでもいいことだからこそ,ここまで真剣にあれこれ考えるのかもしれない。展望なき人生において,真に考えるべき事柄はおしなべて深刻な事柄であり,そして深刻な事柄を考えるだけで頭のなかにブザー音が響く。ストップ! 考えるな!
こういうのをなんていうんだっけ? 現実に対して真剣に向き合うだけの力がないことを。「駄目な人」? もっとひどい言い回しもたくさんありそうだ。その辺について熟考するのは,次回の人生にとっておいて,当座の問題は。。。片側検定が許されるのはどんな状況か。
仮説検定は統計学やデータ解析法の初級コースに登場する基礎的概念だ。片側検定は,仮説検定の説明のなかで登場する考え方で,これまた初歩的内容にはちがいない。
ところが,こういう話題の困ったところは,基本的な疑問であるにもかかわらず,統計学の教科書に答えが書いてあるとは限らない,という点である。たとえば,手元にある本のなかから中村隆英ほか「統計入門」(1984)をめくってみると,この本でひとり勉強したころの手垢や落書きが目に付いて,もう涙が出そうである。20年近い年月が経ってしまった。いや,そういう感傷は置いておいて。。。
「棄却域が x ≦ a または x ≧ b ( a < b ) の範囲となる検定方式を両側検定といい,[...] 棄却域が x ≧ c といった範囲になる検定方式を片側検定という。」(p.211)
これだけである。この直後から,説明は所与の対立仮説の下での棄却域設定についての議論へと移っていく(帰無仮説μ=c, 対立仮説μ≠c に対する一様最強力検定は存在しない,とか)。しかし,棄却域が片側になるような対立仮説(たとえば μ>0)を設定してよいのはいったいどんなときなのか,という疑問には,この本は答えてくれない。それこそが,俺にとっての疑問であり,多くの人にとっての疑問であるはずなのだ。
この「統計入門」は初学者向けの統計学の教科書で,決して数理統計学の専門書ではない。大変わかりやすい,良い本だと思う。それでも,ユーザの肝心の疑問にはなかなか答えてくれない。教科書とは往々にしてそういうものである。一冊の教科書に頼ってはいけない。
「片側検定が許されるのはどんなとき?」という疑問に対し,可能な答えが3つあるように思う。例として,母平均μと定数cとを比較する検定について考えよう。H1:μ>cという対立仮説を設定し,片側検定を行ってよいのはどんなときか?
- (A) μ<cではないと事前に知っているとき
- (B) μ>cと予測しているとき
- (C) μ=c か μ<c かというちがいに関心がないとき
もっと具体的な事例に当てはめて書き直したいのだが,これが案外難しい。平均と定数を比較する検定など,実際にはなかなか用いられないからだ。そこで,俺がかつて考えた素晴らしい事例を紹介したい。以前統計学の講義を担当していたときに考案した名作である。これが人々に知られないまま消えていくのは,あまりにもったいない。
町工場経営の山田さんはパチンコ玉を作っています。愛用のパチンコ玉製造機は,もう何十年も休みなく動き続け,新品のパチンコ玉を吐き出し続けています。パチンコ玉一個の重さの平均はぴったり2g, 寸分の狂いもありません。年月とともにスイッチやツマミの文字は薄れてしまいましたが,あまりに安定的な機械なので,オーバーホールの必要もツマミをまわす必要もなく,山田さんはすっかり安心していました。
ところがある日,山田さんの愛猫が,パチンコ玉の重さを変えるツマミの上に飛び乗ってしまいました。そのツマミを右に回すと,パチンコ玉は少しだけ重くなり,左に回すと少しだけ軽くなってしまうのです。大変だ!山田さんはあわててツマミを調べましたが,目盛がすっかり消えてしまっているので,ネコがツマミをまわしたのかどうか,まったく見当がつきません。
そこで山田さんは,ネコが飛び乗ったあとで生産されたパチンコ玉からN個を抜き出し,その重さを測定器で調べることにしました。
山田さんは次のように考えました。これから生産されるパチンコ玉の重さの集合を母集団と考えよう。私はこれから,無作為抽出したサイズNの標本を手に入れるわけだ。母平均が2gと異なっているといえるか,検定によって調べてみよう。
。。。おかしいな,名作だと思ったのに。こうして書いてみると,俺の資質と能力,人としての常識,といったあたりに深刻な疑念を感じざるを得ない。
まあいいや,この例で話を進めると,山田さんが片側検定を行って良い場合について,以下の3つの答えかたがある。
- (A) 机に向かった山田さんに対し,ネコが次のようにささやきました。「山田くん,このたびは迷惑をかけてすまない。きまぐれなネコとしての職分に鑑み,私がつまみを回したかどうかを君に話すわけにはいかない。許してほしい。しかしこれだけは,ネコの神に誓って打ち明けよう。私がそれを仮にまわしたとしても,断じて左には回してはいません。右に回したか,回していないかのどちらかです」 この場合,ネコを信じるならば,片側検定を用いるのが適切です。
- (B) 山田さんはこう考えました。「現在入手できるさまざまな情報源に照らせば,ネコは右にツマミを回したものと想定される。この仮説について検証したい」 この場合,片側検定を用いるのが適切です。
- (C) 山田さんはこう考えました。「これから生産されるパチンコ玉が2gより軽くなったとしてもいっこうにかまわない。しかし重くなってていては困る。ツマミが右に回ったのか,そうでないのかを調べたい」 この場合,片側検定を用いるのが適切です。
。。。書いていてだんだん頭が痛くなってきた。ネコの神ってなんだよ。
この3つの説明の違いは,いっけん言い回しの差のようにみえるかもしれないが,よく考えてみるとかなり異なる示唆を持っている。そのことは,山田さんが得た標本平均が,たとえば1.95gだった場合を考えればよくわかる。
- 説明(A)における山田さんは,ネコはツマミを回していなかったのだ,と推測する。標本平均が2gより小さいのはツマミのせいではなく偶然だと判断するのである。
- (B)の山田さんは,得られた結果が予想した方向と異なるので驚き,おそらくは,自分の予測をもたらした情報源を見直しはじめる。
- (C)の山田さんは,ああネコは右にツマミを回したのではないようだね,よかったよかった,と思い,それ以上はなにも考えない。左に回したのか回さなかったのか,という点には関心がないからである。
この問題について述べている解説書を探してみると,意外なほどに意見が割れている。手元にある日本語の解説書に限定して書き抜いてみよう。
まず,(A) μ<cではないと事前に知っているときしか片側検定を認めない解説書。
吉田「本当にわかりやすいすごく大切なことが書いてあるごく初歩の統計の本」(1998), p.164
研究者がある方向の差を研究仮説として設定したというだけでは片側検定を行なうべきではなく,研究仮説とは逆の方向の差がその領域や文脈においてまったく意味をもたないと考えられるような特殊な場合でない限り,基本的には両側検定を行うべきだと思います
市原「バイオサイエンスの統計学」(1990), p.194
あらかじめデータがどちらの方向に偏るかを特定できる場合[...]は,片側の効果だけを調べればよいという理屈になる。しかしそのような場合ですら,例外的に逆の効果をもつこともありえるので,やはり,両方の可能性を考えて両側検定しておくのが妥当と考えられる
実のところ,(A)における片側検定に反対する人はいないのではないかと思う。もしμ<cではないことをあらかじめ知っているのであれば,仮に標本平均がcをはるかに下回ったとしても,帰無仮説μ=cを棄却する理由がない。事前知識を生かして棄却域を設定すること自体には,文句のつけようがない。意見が割れるのは,(A)以外の状況での片側検定を認めるか,という点である。上の2冊は,片側検定が許される状況を(A)に限定している解説書であるといえよう。
(A)の状況は現実にはほぼあり得ないから(ふつうネコは喋らない),この立場に立てば,片側検定はめったに適用できないことになる。
次に,(B) μ>cと予測しているときに片側検定を許容する解説書。
山内「心理・教育のための統計法」(1987) p.104
[片側検定の]このような方向性を決定するのは,いままでに知られている情報や,理論的な仮定である。ただし,実験が行われる前に,方向性に関してH1や棄却域は決定しておかなければならない。[...] 例題:心理学者は,ある社会性のテストにおいて,テストの誤答数が通常の小学4年生において平均値25個,標準偏差4.3個であることがわかっているとしよう。いま,リーダーシップの高い子どもは,そのテストでより少ない誤答数を示すであろうと想定した(したがって,H1は方向性のある片側検定を要請する)
いま手元にないのだけれど,名高い古典である岩原信九郎「教育と心理のための推計学」も,たしかこのような説明をしていたと思う。
うーむ。ど素人の俺がこんなことを書くのは身の程知らずもよいところだが,こういう説明は,そのー,ちょっとまずいんじゃないでしょうか,と思う次第である。
たいていの分析者は,なんらかの予測なり想定なりを事前に胸に抱いているものだ。リーダーシップの高い子どもは誤答が少ないんじゃないかとか,ネコはツマミを右に回したんじゃないかとか。上記の解説書に従えば,とにかく想定がはっきりしていれば片側検定が使用できる,ということになろう(両側検定の出番などほとんど無くなってしまうのではなかろうか)。さて,健全な実証研究においては,蓋を開けてみると,事前の想定は往々にして裏切られるものである。実のところ,リーダーシップの高い子どものほうが誤答が多い,ということがあきらかになるかもしれない。山田さんの予測とは逆に,パチンコ玉の重さの標本平均は1.8gかもしれない。データに裏切られた分析者は,そのデータを投げ出すべきだろうか? それはデータに失礼というものだ。むしろ,自らの理論を修正するために,そのデータを再分析するのがあるべき姿であろう。というわけで,今度は新たな対立仮説についての検定が有用になるだろう。その新たな対立仮説が,たとえばμ<cならば,片側検定を2回繰り返すことになるわけだ。2回の検定をあわせたType I Errorは有意水準の2倍になってしまう。だったら最初から両側検定でType I Errorを制御しておいたほうが良いのではないでしょうか?
と,どきどきしながら偉そうなことを書いているわけだが,だんだん気弱になってきたので援軍を呼ぼう。世の中には物好きな人がいるもので,Lombardi&Hurlbert(2009)は統計学の教科書を52冊集め,片側検定が許される状況についての説明を抜き出し,Reasonable(白), Vague(灰色), Bad(黒)の3つに分類している。俺の分類と照らし合わせると,どうやら(A)と(C)は白,(B)は黒とされているようだ。ただし,この著者らはなかなか厳しくて,俺の目から見て(C)タイプの説明であっても,分析者が対立仮説を片側に設定する理由がassumptionとかpredictionなどと表現されているだけで,その教科書はもう黒呼ばわりである。ひええ。
さて,いよいよ本命の登場である。(C) μ=c か μ<c かというちがいに関心がないときに片側検定を許容する解説書。
南風原「心理統計学の基礎―統合的理解のために」(2002)
いま,帰無仮説をH0:ρ≦0とし,対立仮説をH1:ρ>0と設定したとします。つまり,『母集団相関はゼロまたは負である』という帰無仮説を『母集団相関は正である』という対立仮説に対して検定するということです。このような検定は,たとえばある市において,学級の児童数と,学級のなかで授業がわからないという不満を持つ児童の割合との相関係数について,帰無仮説が棄却されて『母集団相関は正である』という対立仮説が採択されたら,学級定員を減らすための検討を開始する,というような場合などに考えられる可能性のあるものです。このとき,r=-.5のように,負で絶対値が比較的大きな r が得られたとしても,これは明らかに対立仮説を支持するものではありませんから,こうした負の領域には棄却域を設けず,正で値の大きい r の範囲のみを棄却域とする片側検定を用いるのが合理的です。このように,片側検定が有効であるケースは考えられますが,通常の研究において検定が用いられる文脈では,このようなケースはあまりありません
永田「統計的方法のしくみ―正しく理解するための30の急所」(1996), p.107
たとえば,何らかの新しい機械の購入を考えているとしよう。その機械のある特性値の母平均μが"基準値"よりも上回るときのみ購入の価値があると考えるのならば[...](右)片側検定をおこなうことが妥当である
吉田「直感的統計学」(2006), p.245
消費者グループが,A自動車会社の『高速道路では一リットルあたり30キロ走る』という新車に関する主張をテストしている。[...] 消費者は一リットル30キロ走るのかそれ以下なのかに興味がある。もしもA自動車会社の主張に対して,サンプル平均が著しく低ければ,μ=30は到底受け入れることはできない。H0を棄却するということは会社を訴えるといったアクションを取ることになるかもしれない。それに対して,もしもサンプル平均が 30キロ以上だったら,つまり燃費が自動車会社が主張しているより良いときに消費者はアクションを取るだろうか?多分彼らはただH0を受け入れ,黙っているだろう。そういう意味でμ=30キロでもμ=35キロでも同じ受容域に入るのである
俺の手元にある本の中では,このタイプの解説が一番多い。英語なので抜き書きは省略するが,古典的名著として知られるWiner "Statistical Principles In Experimental Design" (2nd ed.)も,一番頼りにしている Kirk "Experimental Design" (3rd ed.) も,このタイプの説明であった。
告白すると,(C)の状況下での片側検定は間違っている,と俺はこれまで固く固く信じてきた。片側検定について他人に説明する際にも,それは山田さんの関心の持ちようで決まる問題じゃない,ネコがツマミを左に回していないと山田さんが事前に知っているかどうかという,事前知識の問題なんですよ,と強調してきた。時々見かける(B)(C)タイプの説明は,筆が滑ったか,ないし誤りだと考えていたのである。
このたび,仕事でこの関連の話を考える用事があって,南風原(2002)を読み直し,この名著がなんと(C)の状況での片側検定を認めていることに気づいて,うわあ,また俺は嘘をついていたか,と青ざめた。それがこの文章を書くきっかけである。
(C)の状況下での片側検定は誤りだ,と俺が考えていたのはなぜか。たぶん,吉田(1998)や市原(1990)のようなタイプの説明をどこかの本で読んだせいだろう。それがなんという本だったのか,思い出せないのがつらいところだ。
でも,思い返してみれば,自分なりに納得した理由が,大きく二つあったように思う。テクニカルな理由とプラクティカルな理由である。
まずテクニカルな理由。(C)の状況での片側検定を許容すると,物事はもう泣きたいくらいにややこしくなってしまう。
両側検定の場合について考えよう。帰無仮説をμ=c, 対立仮説をμ≠cとする。帰無仮説の下での平均の標本分布を考え,その両側5%ぶんを塗りつぶす。この5%を有意水準と呼ぶ。有意水準はType I Errorの確率,すなわち「帰無仮説が真のときそれを棄却してしまう確率」に等しい。
では,片側検定の場合はどうなるか。対立仮説をμ>cとしよう。素直に考えると,(C)の場合,対立仮説が真でないときはμ=cかもしれないしμ<cかもしれないのだから,帰無仮説はμ≦cだ。南風原(2002)もそう述べている。しかし,南風原先生は説明を端折っておられるが,帰無仮説がμ≦cであっても,棄却域を決める際にはμ=cの下での平均の標本分布を用いざるをえない。μ≦cの下での標本分布は一意に決まらないからだ。すると,この分布の右側5%ぶんを塗りつぶしたとして,この5%の意味,すなわち有意水準の意味が変わってくる。それはもはやType I Errorの確率ではない。「Type I Errorの最大確率」とでも呼ぶべきものになってしまうのである。
これに対し,永田(1996)がそうしているように,片側検定においても帰無仮説はμ=cだ,と言い張る手もある。(A)における片側検定と同じく,μ<cを考慮の外に置いてしまうわけである。クリアな解決策だが,μ<cはどこにいったんだ,という疑問が浮かぶ。
南風原流の説明と永田流の説明ではどちらが一般的だろうか。また物好きな人がいるもので,Liu&Stone(1999)は44冊の教科書を調べ,うち24冊はH0:μ≦c(南風原路線),20冊はH0:μ=c(永田路線)であると報告している。彼らに言わせると,どっちの説明でもかまわないけど,前者の路線を取る場合には有意水準の意味が変わることを説明しなければならない。しかし,永田路線の20冊のうち11冊がその点をちゃんと説明しているのに対し,南風原路線を取る24冊のうち実に20冊はその説明を端折っている由。これは統計教育における由々しき問題点だ,と彼らは憂えているのだが,うーん,教科書がややこしい話を端折ったからと言って,一概に責めることはできないと思うんだけど。
それはともかく,このややこしさこそが,(C)の状況下での片側検定が許されない理由なのだ,と俺は考えていた。H0:μ≦0ならば(南風原路線),仮説検定においてもっとも基礎的な概念である有意水準の意味が,両側か片側かというちょっとした選択によって変わってしまうことになる。H0:μ=0とすると(永田路線),直感に反する帰無仮説を設定することになる。
いまこうして書いてみると,俺が感じていたのは,(C)の状況下での片側検定はいろいろとややこしい問題を抱えている,ということに過ぎないようだ。片側検定が誤りだという根拠とは言い難い。反省。
というわけで,(C)における片側検定は間違いだ,という俺の確信は哀れにも揺らぎ始めているのだが,完全な納得にまでは至っていない。そのように未練がましく考える背後にあるのは,かつて(C)が誤りだと思った第二の理由,プラクティカルなほうの理由である。
素朴な言い方で恥ずかしいが,「μ=c か μ<c かというちがいに関心がない」だなんて,そんなの嘘じゃないか,と思うのである。
これは具体的な例で考えた方がいい話だと思う。二つ例を挙げてみたい。まず非劣性試験の話。聞きじったところによると,ジェネリック医薬品の承認申請のためには,新薬の場合とは異なり,先行薬よりも(ある限界を超えて)劣っていない,ということを示すための臨床試験を行うのだそうだ。で,テクニカルにはいろいろな工夫があるにせよ,基本的発想としては片側検定を用いるのだそうである。なるほど,既存の薬との間に差がなかろうが,ジェネリック薬のほうが優れていようが,それはどうでもいいわけだから,まさに(C)の状況であるといえよう。
今度は市場調査の話。日本の市場調査業界の基礎を築いた有名な実務家が書いたハンドブックから引用する。製品テストを例に,(C)的な状況を端的に説明している。
後藤「市場調査マニュアル」(1997)
テストの目的が製品A, Bのどちらを選ぶか,または選択を保留するかという場合には両側検定となる。[...] 製品Aの評価が高ければAを選び,そうでなければBを選ぶという場合には[...]片側検定となる。[...たとえば] 改良品Aがよければ現行品Bを改良品に切り替えるが,そうでなければ現行品Bを変えない,あるいは競合銘柄Bよりよければ当社製品Aを発売するが,そうでなければ発売しない場合。
新製品が対照製品と同等であろうが,新製品のほうが劣っていようが,それはどうでもいい,だから片側検定だ,というわけである。理屈としてはさきほどの臨床試験の話と同じなのだが,こんどは違和感を感じる。これは本当に(C)の状況なのか,と疑問に思われてならない。
なぜなら,もし新製品Aの評価が対照製品Bよりも低かったら,単に「発売しない」と決定するだけでは済まないだろう,と思うからだ。Aは,Bよりも劣った製品になってしまったのだろうか,それとも差がないだけなのだろうか。観察された差が統計的にみて意味を持つものなのかどうか,調べてみたくなりませんか? 再び検定してみたくなりませんか? 新製品が対照製品と同等であろうが劣っていようがどうでもいいなんて,嘘じゃありませんか?
このふたつの話はどこがちがうのか。まず,統計的推測と意思決定の間の距離がちがうと思う。臨床試験のほうは,その結果がそのまま製造販売の承認という社会的決定に直結する。いっぽう,消費者調査の結果をそのまま新製品上市の決定に直結させる発想は,あまり現実的とは思えない。むしろ,ビジネス上の意思決定は(科学的推論がそうであるように)幅広い情報に基づいてなされるべきものであり,消費者調査はそのデータソースの一つに過ぎない,と考えたほうがよいだろう。
別の観点からいうと,このふたつの話は,分析主体の「関心」の多様性が異なる。前掲のLombardi&Hurlbert(2009)は面白いことをいっている。現代の仮説検定論を築いたNeyman(1937)は,片側検定が許される状況について"[where] we are interested only [...] in one limit"と表現しているそうなのだが(Cタイプですね),このinterestはただのinterestではなく,個々の分析者から独立な"collective interest"として解するべきものである由。なるほど,上手いことをいうものだ。統計的仮説の設定において問われるのは,個々の分析者の関心ではなく,データにアクセス可能な当事者たちの間のコンセンサスなのだ。臨床試験の場合は,「ジェネリック薬が先行薬と同等であろうが,ジェネリック薬のほうが優れていようが,そのちがいはどうでもいい」という点に関係者すべてが合意するだろう。いっぽう製品テストのほうでは,この合意が得られるかどうか怪しい。調査のステイク・ホルダーは多種多様な関心を持っているはずだ。経営陣は「新製品が対照製品と同等であろうが,新製品のほうが劣っていようが,そのちがいはどうでもいい」と思っているのに対して,R&Dは大いに関心がある,という風に。
こうして整理してみると,俺が(C)タイプの説明に抵抗を感じるのは,μ<cとμ=cのちがいに「全く関心がない」場合の片側検定が論理的に誤っていると思うからではない。単に,そんな状況は極めて限定的だ,と感じているに過ぎない。いいかえると,片側検定が許される状況を,その場その場の「関心」をキーワードにして定義するのは甘すぎる,と危惧しているだけである。これもまた,(C)タイプの説明を誤りとみなすだけの根拠とはいえない。反省。
片側検定が許される状況をどのように定義するかという問題について,勝手に悩み,勝手に論破されて勝手に反省しているわけだが,そんな定義にかまけていないで,(D)そもそも片側検定をやめちゃえばいいじゃん,という意見もあるだろう。日本語でみかけた例としては,佐伯・松原編「実践としての統計学」(2000)のなかで,佐藤俊樹がそういう意見を書いている。この先生は「不平等社会日本」で知られる気鋭の社会学者だが,こういうテクニカルな話題にも造詣が深いんですね。
佐藤によれば,(C)の状況における片側検定には論理的飛躍がある。
帰無仮説θ=0の否定はθ≠0であって,θ>0 (やθ<0)ではない。にもかかわらず,何の説明もなしに『片側検定では帰無仮説θ=0を棄却することでθ>0(あるいはθ<0)という対立仮説がとられる』といえば,それはまさに論理的飛躍である
しかし佐藤は(A)の立場も拒否する。
論理を一貫させようとすれば,いくつかの本でやっているように,片側検定は何らかの根拠でθ<0(あるいはθ>0)でないと確定できる(無視できる)場合に使われる,とするしかない。[...]こういう形にすれば明確だが,[...] 限られたケースでしか片側検定は使えなくなる
佐藤の議論の眼目はこうだ。この論理的飛躍は片側検定に限ったことではない。両側検定だって同じことである。なぜなら,分析者は両側検定によって帰無仮説μ=cを棄却するが,それを根拠として彼が主張するのは,たいていμ≠cではなく,μ>cなりμ<cなりであるからである。検定ユーザはどのみち論理的に飛躍しているのである。
この飛躍は統計学的論理の一貫性と有用性という二つのメタ手順を同時に考えることでしか対処できない。θ<0 (あるいはθ>0)でないと確定している場合や,『差がある』とだけいえればいい場合には単純である。そうでない場合が問題になる。これについてはいくつかの解があろう。一つの解は,どちらにしても飛躍が発生するのだから,両側検定と片側検定は無差別である,とする。要するに,どちらを使ってもよい。例えば『片側で有意水準5% (両側なら10%)』と明記して,有意水準の実質的値について誤解が起きないようにすればよい。もう一つの解は,両側検定を使った上で,統計学的には根拠のない推論を一部していると認めるほうがよい,とする。結論だけいえば統計学的論理の一貫性を追求するのと同じだが,理由がちがう。飛躍を統計学に押し付けて消去するより,研究の内部にリスクとして明示的におくべきだ,という判断による。私としては第2の解がよいと思う
二つの解が実質的にどう異なるのか,俺はちょっと理解できていないんだけど,魅力的な見解だと思う。こうしてみると,片側検定が許される状況の定義なんて,どうでもいいような気がしてくる。
しかし,個々の分析者が佐藤に従い,熟慮した上で片側検定を使うのを止めたとしても,他人が片側検定を乱用するのを止めることはできない。誰もが仮説検定論について熟慮するわけではないのだ(仮にそんなことが起きたら,それこそ労力の無駄遣いだと思う)。さらに,片側検定が乱用される動機は十分にある。分析者はなんとか有意差を得たいと思っていることが多い。想定する方向での棄却域を広げてくれる片側検定は,分析者にとっての甘い誘惑なのである。実は私はμ>cだけに「関心」があるのです!と勝手に宣言し,片側検定を乱用する人々の姿が目に浮かぶ。
片側検定を使うのを止めよう,という呼びかけだけでは不十分だ。片側検定が許容されるのはどんな状況か,ユーザのための操作的ガイドラインが必要だと思う。
というわけで,あれこれ読みかじってみた結果,論理的には(C)タイプの説明が正しいと,半ば納得するに至った。その反面,(C)が示唆するcollective interestという基準はなかなか理解されにくいだろうなあ,という危惧も捨てきれない。南風原先生がそうしているように,片側検定の乱用を戒める文言を付け加えるのも大事だが,我々統計ユーザに対するガイドラインとしては,いっそ(A)タイプの説明にまで後退しちゃったほうがいいんじゃないか,と未練がましく考える次第である。
2008年5月 3日 (土)
2要因以上のunbalancedなANOVAでは,ある水準についてのunweightedな平均(SASのproc glmでいうmeans)と重みつき平均(lsmeans)の値が異なる。事後の多重比較で用いるべきはどちらだろう?
森・吉田の本は前者を比較する方法を紹介しているが,それは前者のほうが手計算しやすいからだと思う。この本の基になっているKirkの本は,不揃いになった理由が処理水準と無関係な欠損である場合は前者でよいとか,その不揃いさが母集団の比率を反映しているのなら後者がよいとか述べていたと思うが(小牧「データ分析法要説」によればWinerもそういっているらしい),この2つのどちらでもないケースも少なくないと思う。
そもそも,unweightedな平均を比較してよい理由がよくわからん。本来は常にlsmeansを使うべきなのではないか?
ほんとはこんな古い話題に頭を悩ませていないで,もうちょっと新しい方法を考えるとか(混合モデルを使うとか),あるいはもっとオカネになることを勉強するとか,あるいはもっと楽しいことを考えるとか...いろいろあるだろうに。知りもしない分野で専門家づらしている悲劇。この問題を解決したところで誰が喜ぶわけでもないという悲喜劇。
考えてみたら,こんな疑問はありふれたFAQのはずだ。どこかに解説論文があるにちがいない。悩んでいないでさっさと検索すべきだな。
2007年7月11日 (水)
集中講義で話の種に使おうと思うので,ここでメモしておく。
「日本は美しい」5割強、内閣府世論調査
内閣府は5日、安倍晋三首相が目指す国家像「美しい国」づくりに関する特別世論調査の結果をまとめた。今の日本を「美しい」とした人は10.6%で「どちらかというと美しい」の42.7%と合わせ5割強に上った。「日本の美しさとは何か」を複数回答で尋ねたところ、1位は山や森などの「自然」で 80.0%。伝統工芸などの「匠(たくみ)の技」が58.5%、田園・里山といった「景観」が52.8%で続いた。[...]
内閣府調査:過半数が「美しい国」 20、30代では逆転
内閣府は5日、安倍晋三首相が提唱する「美しい国」づくりに関する世論調査の結果を発表した。現在の日本を「美しい」と回答した人は、「どちらかというと美しい」(42.7%)も含めると53.3%と過半数を占めた。「美しくない」と回答した人は、「どちらかというと」(31.8%)を含めて43%だった。
ただ年齢別にみると、40代以上は「美しい」が過半数を占めたのに対し、20代の57.6%、30代の50.5%は「美しくない」と回答。若い世代は日本を美しく思っていない側面が浮き上がった。
一方、日本の美しさを複数回答で尋ねたところ、山や森、海などの「自然」が80%、伝統工芸や宮大工の技術など「匠(たくみ)の技」が58.5%、田園・里山の風景など「景観」が52.8%--などが上位だった。内閣府は「上位の自然や匠の技などに若者はなかなか関心を持ちにくいので、『美しくない』が多くなったのではないか」と分析している。[...]
日本は「美しい」53.3% 内閣府世論調査.
日本を美しいと考える人が53.3%、美しくないとの回答は43.0%であることが5日、内閣府が発表した「美しい国づくりに関する特別世論調査」で分かった。40~70歳代以上の過半数が「美しい」と答え、20~30歳代では過半数が「美しくない」とした。「重要と思う美しい国の姿」では「文化、伝統、自然、歴史を大切にする国」(47.5%)が最も多く、次いで「規律を知り、凛(りん)とした国」(22.6%)、「世界に信頼され、尊敬されるリーダーシップのある国」(16.7%)の順。[...]
「日本は美しい」53%=「美しくない」43%-内閣府調査
政府は5日、安倍晋三首相が政権構想の基盤に据える「美しい国づくり」に関する特別世論調査の結果を発表した。それによると、現在の日本について「美しい」と回答した人は53.3%だったのに対し、「美しくない」は43.0%に上った。若い世代で「美しくない」と答えた人が過半数を占めており、内閣府は「いじめや虐待などの報道に接し、現状に問題意識を持っている人が多い表れ」としている。
調査は、日本の「美しさ」に対する国民のイメージを探り、国内外に向けた日本の魅力発信などの施策づくりに役立てるのが狙い。5月24日から6月3日にかけ、3000人の成人男女を対象に実施し、有効回答率は60.9%だった。
「日本美しい」は1割強 内閣府が世論調査
内閣府は5日、安倍晋三首相が唱える「美しい国づくり」に関する特別世論調査の結果を発表した。日本の現状を「美しい」とした回答は10・6%にとどまり、「どちらかというと美しい」を合わせてようやく53・3%と半数を超えた。
「美しくない」は11・2%、「どちらかというと美しくない」は31・8%。40代以上は「美しい」「どちらかというと美しい」が過半数だったが、20-30代は逆に「美しくない」「どちらかというと美しくない」が過半数。内閣府は「特に若い世代が美しくないととらえている点をよく考慮し、今後の政策を考えたい」としている。
「日本の美しさとは何か」という質問(複数回答可)では、山や海など「自然」が80・0%でトップ。このほか伝統工芸など「匠の技」が58・5%、田園や街並みなど景観が52・8%、能や歌舞伎など「伝統文化」が50・8%だった。敬語や方言など「日本語」は32・8%にとどまった。
朝日,読売ではみつからなかった。内閣府のリリースはここ。
とにかく,誰かを馬鹿にするのだけはやめよう,と思う。それはなにも生まない。ただ自分の頭が良いような気がするだけ,ただ気分がよくなるだけだ。
なぜこんな調査が生まれるのか。それの結果はどのように流通し,どのように利用されていくか。そのことだけを考えたいと思う。
2007年6月 4日 (月)
先週だったか,新聞に子どもの生活についての調査研究が紹介されていた。いわく,小学5年生を対象にした調査で,起床時間と「学校が楽しいかどうか」との間に相関が見られた由。早起きの子どものほうが,学校を楽しいと感じている割合が高いのだそうだ。ふうん,と適当に読み流して,それきり忘れていた。
ところが,数日前にぼんやりネットを眺めていたら,この調査をぼろくそにやりこめている人がいた。あれこれ見てみると,そういうブログがたくさんあって(一例),ちょっと驚いた。なんというか,世の中には正義感に満ちた人が多い。
批判や罵倒の数々を眺めているうち,なにやら形容しがたい感情がこみ上げてくるのを感じて,自分でも意外であった。以来数日,このことをあれこれ考えていたのだが,これは誰が悪いという話ではなくて,構造的な問題なのではないか,と思い至った。
生活サイクルの地域差を指摘するものから,学者はみんなアホばかりだ式の悪口まで,ブログにみられる議論のレベルは様々だが,批判の主旨を煎じ詰めると,(1)標本に無作為性がない,(2)因果関係はわからない(早起きのせいで学校が楽しくなるわけではない),という二点に尽きるように思う。
(1)はまた別の話になるので横に置いておくとして,(2)については,なるほどその通りだ。起床時間と学校の楽しさに相関があるとしても,どちらが原因でどちらが結果かはわからないし,そもそもこの2つの変数は共になんらかの変数の影響下にあるのかもしれない(たとえば,東京圏よりも地方都市の子どものほうが早起きで,かつ学校を楽しく感じるのかもしれない)。ではこのツッコミは,この調査に対して(ないし報道に対して),果たして正当な批判となっているだろうか。
たとえば朝日新聞の記事(05/29)はこうだ。
早起きの子どもは学校が好きで、楽しいとも感じている――。早起きと学校好きの間にそんな関係があることが、教育学や食物学の専門家でつくる「子どもの生活リズム向上のための調査研究会」の調査でわかった。
調査の概要が述べられ,最後に
「研究会代表をつとめる明石要一・千葉大教授は「起床が早く、バランスのいい朝食を食べている家庭は、生活にリズムがある。学校も家庭も、もっとこの問題に関心を持ってほしい」と話す。
早起きの「せいで」学校が好きになるとは,どこにも書かれていない。他社の記事では別の知見が紹介されているが(朝食が和食の子どものほうが早起きだ,云々),書き方は同様である。記事で述べられているのはあくまで相関的知見であって,因果的知見ではない。「××な人は○○の傾向がある」という記述を「××であることは○○をもたらす」と勝手に読み替えるのは,あまりに軽率というものだ。そんな読み方が許されてしまうようでは,相関の記述などおよそ不可能になってしまう。
この調査の報告書を読んだわけではないけれども,生活スタイルと学校への態度の間に因果関係が主張されているとは思えない。横断調査から因果関係はわからない,というのは調査のイロハであり,研究者はもちろん新聞記者だって先刻ご承知である。鬼の首を取ったかのように悪口を書く前に,もう少し丁寧に文章を読んだほうがよいのではなかろうか?
と,いうのが最初に感じたことなのだが,あれこれ考え合わせると,この人たちの言うことにもそれなりの説得力はあるのかもしれない,と思う。
たとえば上記のように,早起きの「せいで」学校が好きになるわけじゃないだろう,と批判する人がいる。そんなことは記事のどこにも書かれていないわけで,あきらかに勇み足である。しかしもしこれらの報道を,多くの人が因果的説明として理解しているとしたらどうだろうか。現に,いまwebでこの調査について言及しているブログを検索してみたら,その半分は「くだらない調査だ」というツッコミだが,もう半分は「なるほど,規則正しい生活って大事だ」「やっぱり朝は和食にしようかしら」といった,驚くほど素直な感想なのである。こうしてみると,勇み足にも理由がないとはいえない。
この学者たちは学校の問題を家庭に押しつけようとしてるんじゃないかしら,と嫌悪感を示す人もいる。もちろんこれは,批判というよりは勘ぐりである。しかし,研究会代表である教育学の先生は,中教審分科会委員を勤める,文教政策に関わりのある学者である。この調査もおそらくは,文科省が只今鋭意推進中の「早寝早起き朝ごはん」国民運動と関係があるのだろう。決して無理な勘ぐりとはいえない。
というわけで,あちこちで目にする批判は,正当とはいえないけれども,社会的文脈を踏まえれば一定の意義を持っているのかもしれない,と思う。
にもかかわらず --- ここからが本題なのだが --- ブログをあれこれ眺めるうちに,なんともいえない感情がこみ上げてくる。ありのままに言ってしまえば,強い不快感といらだちを感じる。いったいなぜだろう?
上記調査についての各社の報道を,いまwebで眺めていて感じるのは,ああみんな上手く書くものだなあ,ということである。
日経の記事はこうだ:
主食と主菜、副菜、一汁の4品がそろった朝食を食べている小学5年生の61.8%が「学校がとても楽しい」と感じていることが28日、千葉大の明石要一教授(教育社会学)ら研究者グループが2006年に実施した調査でわかった。
あくまで相関の記述に留まっている。実に正しい文章である。しかし同時にこの記事は,「朝食が学校への態度に影響する」という因果関係を読み手にうまく暗示している。この因果関係は,家庭生活が大事だ,という社会的通念と合致しており,それゆえにわかりやすい。こういうところが,ああ上手いなあ,と思う。
書き手の立場で考えると,相関の記述だけではつまらないのである。人は常に説明を求める。学校が楽しいと感じる子どもの特徴について知りたい,などという奇特な人はいない。その子たちはなぜそう感じるのか,学校を楽しい場所にするためにはどうしたらよいのか。人は理解可能な原因,実行可能な方策を求める。だから書き手は,たとえそれが横断調査の結果に過ぎないとしても,つまり手元にあるのは相関的知見だけであるとしても,嘘にならない範囲内で,なんとかして因果的なニュアンスを醸し出そうとする。こうしてセクシーな報告ができあがる。
だから,たとえばこういう文章を書いてはいけない。
「学校がとても楽しい」と感じている小学5年生には,主食と主菜、副菜、一汁の4品がそろった朝食を食べている傾向があることがわかった。
同じく相関を記述しているのだが,このタイプの文章を読むと,多くの人が「わかりにくい」という(おかげで,俺は延々悩んだことがある)。正確には,わかりにくいのではない。ただセクシーさに欠けるのである。なぜなら,(社会的通念によって想定されるところの)結果側が先,原因側が後に書かれているせいで,因果的なニュアンスを読み取るのが難しくなっているからである。
さらに高度な例を朝日の記事にみることができる。先生のコメントの素晴らしさといったらない。「起床が早く、バランスのいい朝食を食べている家庭は、生活にリズムがある」 よく読むと,この文には特になにも述べていない。ある種の家庭のありかたを,「生活にリズムがある」という言葉で形容しているだけである。にもかかわらずこの文章は,ああ生活のリズムが大事だなあ,と読み手に感じさせてくれる。内容がないのにわかりやすさだけが感じられる。これが技術である。
では,責めるべきは新聞記者なのだろうか。彼らは文章上のテクニックによって,ただの相関関係を因果関係に見せかけ,「早寝早起き朝ごはん」国民運動のお先棒をかついでいるのだろうか。マクロにみれば,そういう批判も可能かもしれない。しかしミクロにみたとき,そこにあるのは単なる仕事熱心さだと思う。読み手の関心を少しでも惹き付けようとするのは,書き手にとって当然の工夫である。
教育学者たちを責めるべきだとも思えない。彼らがなにを推進しようとしているにせよ,子どもの家庭生活と学校生活の関係を調べる調査には一定の価値があると思う。そのメディア向けリリースの際に,「朝ごはんが子どもにとって大事だ」という信念なり,社会的通念なりが顔を出しても,それは仕方のないことだ。
この記事を読んで,ああ朝ご飯は大事だなあ,と素直に信じる人がいたとしても,その人を馬鹿にする気にはとてもなれない。調査結果からなにを読み取るのかはその人の勝手である。
では,ブログでこの調査を罵倒し,マスコミと学者と無知な大衆を馬鹿にする人たちはどうだろうか。上で考えたように,その(いささか軽率な)批判にも,ある種の意義があるのかもしれない。でも,彼らは結局のところなにも破壊していないし,なにも建設していない。
相関は因果を意味しない,という指摘は正しい。しかし,相関から因果を読み取ろうとする人々を押しとどめることはできない。新聞記事を読んで早起きは大事だと得心したお母さんは,なるほどあなたの仰る通りかもしれません,この調査結果は早起きが大事だということの直接の証拠にはなっていないんでしょうね,でもわたしやっぱり早起きって大事だと思うわ,というだろう。研究者たちにしたところで,仰るように学校の楽しさを支える因果的メカニズムについては今後の研究課題です,わざわざご指摘頂いてどうも,というのが落ちである。この手の批判者が何人いても,たとえば「早寝早起き朝ごはん」国民運動はとまらないのである。皮肉な言い方をすれば,そうやって批判することで自尊心を満たすことができたんだから,あなたもこの調査の受益者のひとりなんじゃないか,という気がしてしまう。
どこにも悪い人はいない。それぞれの行いは正しい。でもマクロにみると,つまらない調査が量産され,根拠のない因果的説明が漠然と宙を漂い,社会を不可思議な決定へと導いていく。あえていうならば,調査者も伝達者も受け手も,全員が共犯なのではないだろうか。
延々と書いてきたけれども,実はこの話はどうでもよくて,書きながら念頭にあるのは,いまの仕事であるところの市場調査のことである。調査会社,発注側の担当者,調査報告の受け手の全員が,誠実に調査にあたり誠実に報告し誠実にそれを批判し,でも結局はあいまいな共犯関係から抜け出ることができない,そんな事態がありうるのではないか,そのループから抜け出すためにはどうしたらいいのか,などと考えこむわけである。
2005年11月30日 (水)
勤め先の会社で,調査データをどう分析するかという相談をしていたら,相手がふとこんなことを云った。データを調べる前に,あらかじめ「見たいもの」を決めてしまうようなやり方は嫌なんです。なんだかそれって予定調和だという感じがする。
そうつぶやいた若い女性は,データ解析に関してはほぼnoviceだといってよい。しかし,(会社の先輩に対して大変失礼な言い方だが) とても勘の良い人で,明確で筋道だった問題意識を持っている人だった。
どんな話の流れの中でそんな言葉がでてきたのか,よく思い出せない。その時は特に強い印象を受けず,なにか適当な受け答えで済ませてしまったような気がする。ずっとあとになって,あの言葉は俺に対する間接的な批判ではなかったか,と考えるようになった。正確にいえば,それは意図的な批判ではない。そのときの文脈やそのあとのやりとりから考えても,その人自身は俺に対して反論する意図を全く持っていなかったし,その言葉も深い意味合いをこめたものではなかったと思う。しかし俺にしてみると,その人に対して俺が繰り返し強調していたことについて,その問題点を一言で言い当てられたような,首筋にそっとナイフを当てられたような気がしたのだった。
俺がその人に主張していたのはこういうことだ。ここにデータ行列があるから,それを虚心に眺め,なにか面白い事柄をみつけよう --- こういう発見的な方略は,魅力的ではあるけれども,勝算がほとんどない。まず「なにが見たいのか」を決めましょう。どんなナイーブな思いつきでもいい,分析に際しての視点を定めましょう。
俺の考え方は決して間違っていないと思う。何の予断も持っていないように思えても,実はデータを手にした段階で,我々は現象を捉えるなんらかの枠組みを持っているものだ。我々はその枠組みに沿って問いを立て,その枠組みに沿って結果を解釈する。だから,その枠組みを顕在化・明確化することがまず必要だし,それによって「見たいもの」は自ずから定まるはずだ。強い言い方をすれば,分析に際して「見たいもの」がはっきりしないというのは,当該の現象そのものについてよほど関心がないか,でなければ物事をきちんと考えていないということだと思う。
さらにいえば,実際の分析手順としてみても,ある程度までは仮説検証的なアプローチを採るのが現実的だ。データ行列が含んでいる情報はあまりに豊かであり,データをインタラクティブに視覚化して仮説探索していく作業は,仮説検証的な分析よりもはるかに高いスキルを必要とする。要するに,仮説を探すよりも検討する作業のほうがラクなのだ。考えてみればそれは当たり前の話で,仮説検証と仮説探索のちがいは,現象を抽象化するというしんどい作業をあらかじめ済ましておくかどうかというちがいでもある。
でもその一方で,あらかじめ視点を限定すればするほど,そこから得られる知見は痩せていく。現象駆動的な問題意識からスタートしている場合,確たる理論的背景がないこと自体は悪いことではないし,そのときデータとの対話の中で自分の分析枠組みを明確化していこうとするのはひとつの見識だし,そうすることによってしか得られないタイプの視点もあるはずだ。俺はそういう要素をできるだけ減らして,コストと納期を見積もりやすい分析へと向かおうとしていたわけだが,それが一種の出来レースだという批判は,なるほど一面の真実である。
というのは,ずいぶん奇麗な言い方だ。
要するに怖いのです。データと際限なく格闘する泥沼に突き進むのが。答えがないかもしれない問いに巻き込まれるのが。容赦なく時間だけが経ち,はっきりするのは自分の無能さだけ,そういう恐怖をあなたは知っていますか(誰に向かって訴えているんだかわからんが)。真実なんてどうだっていい,平和が欲しい,幸せになりたい。そういうお年頃なのです。
2005年10月10日 (月)
順序変数yが個人特性ηを測定しているとしよう。 ηのもとでyがc番目のカテゴリより上に落ちる確率P(y≧c|η)は, 比例オッズモデルなら
P(y≧c|η) = F[(カテゴリcの下側の閾値)+(傾き)×η]
と表現するところだし,IRTなら
P(y≧c|η) = F[(識別力)×(個人特性η-(カテゴリcの困難度))]
と表現するところだが,いったん連続的な潜在反応変数
y* = (切片ν) + (因子負荷λ)×(個人特性η) + (誤差ε)
を考えてやって,
P(y≧c|η) = F[(y* - カテゴリcの下側の閾値τ_c) / (誤差εのSD)]
と表現しても同じことである。ここでy*は,yの背後にある実質的に意味のある変数だと考えてもいいし,ただの計算上の道具だと割り切ってもかまわない。
y*は潜在変数だから,平均0,分散1と考えるのが普通だ。その場合は
(切片 ν) = 0
(因子負荷 λ の二乗) × (ηの分散 ψ) + (誤差の分散 θ) = 1
となる。でも,別にy*の分散は1でなくてもいいわけで,たとえばθが1だと考えたっていい。そこで,
Δ = 1 / (y*のSD)
をスケール・ファクタと呼ぶことにする。スケール・ファクタは,λとψとθをコミにしてあらわしたものである。単群の分析であれば,どんな値に決めても構わない。ここまでは,まあいいや。
これが多群の分析となると,話がややこしくなってくる。群によってλだかψだかθだかがちがってくる,と考えないといけないからだ。そこで,ふたつの路線が登場する。ひとつは,ある群のy*の分散を(つまりスケール・ファクタΔを)1にして,ほかの群のΔを推定する,という考え方で,これをdelta approachという。このアプローチの背後には,どうせ誤差分散θは群間でちがうんだからどうでもいいや,という考え方がある。いっぽう,誤差分散θがちがうかどうかに関心がある場合には,ある群のθを1にして他の群のθを推定する,という考え方もできる。これをtheta approachという。
モデルの推定上は前者のほうが都合が良いんだそうな(簡単だからだろうか)。
以上,Mplus Web Notes #4 より。カテゴリカル変数をつかったSEMについてわかりやすく説明したものが見つけられなくて困っていたのだが,これを読んでやっと少しだけ理解できた。Muthenさんの説明はなんでこんなにわかりやすいのだろうか。お菓子でも送りたい気分だ。
2005年9月26日 (月)
そんな分析では独立変数が他の変数とごっちゃになってしまっているですよ,ということの説明に小一時間をかけ,しかもまだ完全な理解を得ていない。話が通じない相手ではないのに,なぜだろうか。
(理由1) データの分析に際して問題意識を強く持っているから。それ自体はもちろん良いことなんだけど,往々にして自分の分析手法の欠陥が見えにくくなってしまうことが多いように思う。
(理由2) 学生ならば適当なところで納得してくれるが,オトナはそうではない。俺の説明能力は,俺が思っていたよりもはるかに低いのかもしれない。
話は違うが,屁が臭すぎて頭が痛い。自分の屁だから逃れようもない。どうすればよいのか。甘栗を食うのを止めれば済む問題なのか。