メイン > 論文:データ解析(-2014)
2014年12月 5日 (金)
Muthen, L.K., Muthen, B.O. (2009) How to use a monte carlo study to decide on sample size and determine power. Structural Equation Modeling, 9(4), 599-620.
哀れなSEMユーザのみなさんのために、Muthen導師夫妻が懇切丁寧に説明する啓蒙論文。題名のとおり、SEMのようなモデリングの際に必要なサンプルサイズはモンテカルロ・シミュレーションで決めろ、こうやって決めろ、という話である。よく言及される論文でもあるので、いちおうざっと目を通した。
例として、以下のモンテカルロ・スタディを行う。
ひとつめ、CFA。
- モデルを決める。ここでは2因子CFA、因子あたり連続指標5つ、因子間相関ありとしよう。以下、因子f1の指標をy1-y5, f2の指標をy6-y10とする。
- パラメータを決める。因子負荷$\lambda$はすべて0.8, 残差分散$\theta$はすべて0.36, 因子平均はどちらも0で分散$\Psi$はどちらも1 (例外は後述), 因子間相関0.25とする。指標の信頼性は、指標の分散のうち因子で説明できた部分の割合だから、$\lambda^2 \Psi / (\lambda^2 \Psi + \theta) = 0.64$となる。
- 反復数を決める。ここでは10000とする。
さて、ここで次の4つのバージョンをつくってみます。
- 欠損なし、正規分布。
- 欠損あり、正規分布。
- 欠損なし、非正規分布。
- 欠損あり、非正規分布。
欠損ありの場合、y5-y10は50%を欠損(MCAR)にする。非正規分布の場合、未知のクラスをふたつつくり、比率を12%と88%とする。クラス1のみ、f2の平均を15, 分散を5にする。
以下では因子間相関の検定力に注目する。測定誤差によって希薄化するので。
ふたつめ、成長モデル。
- モデルを決める。線形成長モデル、等間隔4時点で連続指標を測定(以下y1-y4)。以下の2種類をつくる。モデル1, 共変量なし。モデル2, 2値共変量がひとつあって、傾き因子と切片因子に効いている。
- パラメータを決める。切片因子の平均0, 分散$\Psi_i$は0.5, 傾き因子の平均0.2, 分散$\Psi_s$は0.1。モデル1における切片因子と傾き因子の共分散$\Psi_{is}$は0。指標の残差分散$\theta_t$はいずれも0.5。各指標のR二乗は、時間スコア$x_t = (0,1,2,3)$として次の式で計算できて
$R^2(y_t) = (\Psi_i + x^2 \Psi_s + 2x_t \Psi_{is}) / (\Psi_i + x^2 \Psi_s + 2x_t \Psi_{is} + \theta_t)$
y1から順に0.5,0.55,0.64,0.74になる。モデル2は、共変量が1となる割合を0.5、切片因子への回帰係数を0.5、切片因子の残差分散を0.25。傾き因子への回帰係数は後述、傾き因子の残差分散を0.09とする。 - 反復数を決める。ここでは10000とする。
さて、ここで次の5つのバージョンをつくってみます。
- モデル1。
- モデル2、共変量から傾き因子への回帰係数を0.2にする。
- モデル2、共変量から傾き因子への回帰係数を0.2にする。欠損あり。
- モデル2、共変量から傾き因子への回帰係数を0.1にする。
- モデル2、共変量から傾き因子への回帰係数を0.1にする。欠損あり。
欠損ありの場合、時点1から4までの欠損(MAR)を、共変量0のときに順に12%, 18%, 27%, 50%, 共変量1のときに12%, 38%, 50%, 78%とする(共変量でドロップアウトが変わる状況をシミュレーションしているのだ)。
以下では傾き因子への回帰係数の検定力に注目する。成長モデルでは傾きの群間差が問題になることが多いので。
さて、サンプルサイズをどうやって決めるか。以下の3つの基準を満たすサンプルサイズを探す。
- 全てのパラメータについて、パラメータとSEのバイアスが10%を超えないこと。
- 検定力に注目しているパラメータの、SEのバイアスが5%を超えないこと。
- 95%カバレッジ(95%信頼区間が真値を含んでいる反復の割合)が0.91~0.98であること。
... ってな感じで、結果を紹介。ま、結果はどうでもよくて、とにかくこういう風に話を進めていく、というデモンストレーションである。
当然ながら、導師はMplusのコードを公開してくださっている。ありがたいありがたい、南無南無。
読了:Muthen & Muthen (2009) 迷えるSEMユーザのためのサンプルサイズ決定ガイド
2014年11月27日 (木)
北條雅一(2001) 学力の決定要因: 経済学の視点から. 日本労働研究雑誌, 53(9), 16-27.
先日読んだAntonakis, et al.(2010) が強烈に2SLS推しだったので、実際に2SLSを使っている研究を見てみたいものだと思い、とりあえず見つけたもの。中等教育における学力の規定因についての実証研究である。
そうそう。10年ほど前、ちょっとした趣味で調べたことがあるのだけれど、学級サイズが学力に及ぼす効果って、意外にもはっきりしてないのである。社会的決定にエビデンスは大事だけど、エビデンスがいつも手に入るわけじゃない、という例のひとつでろう。
教育の生産関数分析(学力を規定する諸要因についての実証分析)は1966年アメリカのColeman報告がはしり。レビューにHanushek(1997, Edu.Eval.Policy Anal.)というのがある。研究が多いのは学級サイズの効果だが、結果はまちまち。操作変数法を使った因果分析はAngrist&Levy(1999,Q.J.Econ)が最初だそうで、海外でも案外歴史が浅いようだ。国内では2000年代後半以降。
この論文の著者はTIMSS(国際数学理科教育動向調査)を使った生産関数推定なんかをやっているそうで、この論文もTIMSS1999,2007の日本データを使っている。中二、公立校のみ。TIMSSの標本設計は学校-学級の層化二段抽出、学級の数は学校あたり1~2、抽出した学級の子どもは全員調べる。
以下のモデルを推定する。学校$s$の学級$c$の生徒$i$の数学ないし理科の標準化得点$A$について、
$A_{isc} = X_{isc} \beta + \alpha Z_{sc} + \varepsilon_{isc}$
説明変数ベクトル$X$は以下を含む。個人レベルでは、性別、生まれ月、家庭の蔵書数、所有物、父母の最終学歴。学級レベルでは、教師性別、修士号有無、教職年数。学校レベルでは、生徒数、都市規模、「経済的に恵まれない生徒の比率」(←具体的にはなんのことだろう?)、習熟度別授業実施有無。で、$Z$はその教科の学級規模。
本命は$\alpha$の推定なんだけど、あいにく学級規模$Z$には内生性がある。そこで操作変数法の登場である。法律では学級あたり生徒数は40人を標準にすることになっているので、学年生徒数を$E$、整数に丸める関数をintとして、学級規模サイズの予測値は
$Z^p_{sc} = \frac{E}{int[(E-1)/40] +1}$
これを実際の学級規模$Z_{sc}$の操作変数として2SLS推定。
1999データと2007データそれぞれについて、数学と理科の成績を説明。家庭変数の係数がより強くなっている由。残念ながら、やっぱし、そうなんですね。
学級規模の効果は有意でなかった。しかし著者は引き下がらず、個人変数と習熟度別授業実施有無の交互作用を片っ端から投入して再推定。あんまりきれいな結果じゃないけど、習熟度別授業をやると家庭環境の効きが弱くなる由。
感想:
- 操作変数がひとつだから、これだと丁度識別モデルだと思うんだけど...それでいいのか...
- 習熟度別授業有無も内生性があるのでは? 注によれば、実施有無を説明するプロビット回帰でどの説明変数も有意でなかったそうだが、それは内生性がないことに証拠になるだろうか...
- データの構造からいって階層モデルにするのが筋だと思うんだけど...「誤差項の学校内の相関に頑健な標準誤差」を推定したとあるが、これは具体的には何を指しているのか。不勉強でわからないぜ。
ま、専門家のなさったことだから、これで大丈夫なのだろう。
読了:北條(2001) 子どもの学力のモデルを2SLSで推定
2014年11月22日 (土)
Antonakis, J., Bendahan, S., Jacquart, P., Lalive, R. (2010) On making causal claims: A review and recommendations. The Leadership Quarterly. 21, 1086-1120.
社会科学の実証研究における因果推論についての長大なレビュー。数年前に途中で挫折した奴である。プリントアウトの束をめくると、前半には熱心な書き込みが多いのに、中盤ではなにやら変な生き物とかの落書きが増え、突如として誰かの電話番号がメモしてあって、そこから先には書き込みがない。そうそう、大手町の商業施設のカフェで読んでいて(なぜか思い出せないが)、お取引様から携帯に電話がかかってきて、受け答えしていたら「お客様、店内でお電話はおやめください」と叱られたのだ。云いたいことはわかるが、あのときは困った。
このたび最初からメモを取って読み直した。いやー、大変だった。これなら本一冊読んだ方がまだ楽だ。
イントロ
本論文の目的:
- 推定量についての因果的解釈は、どんなデザインのとき、またどんな推定方法の下で可能なのかを示す。
- 因果的主張をフィールドで検証するための方法をレビューする。
- リーダーシップ研究における因果的主張の方法論的厳密性について棚おろし[take stock]する。
1. 因果性とはなにか
いまここで関心があるのは、因果性についての哲学的基礎づけとかじゃなくて、how to measure the effect of a cause である。
Kenny["Correlation and Causality", 1979. Baron&KennyのKennyであろう]によれば、因果的効果の測定のためには、(a)xはyに時間的に先行し、(b)xはyと相関し、(c)xとyの関連性が他の原因で説明できない、ことが必要である。
(a)については、yからxへのフィードバックがあるかもしれないこと、あくまで必要条件であって十分条件でないことに注意。(b)は統計的な信頼性の問題。(c)はどっちかというとデザインや分析上の問題で、xの内生性という問題が関連してくる。
この論文で主に扱うのは(a)と(c)。
1.1 反事実的な議論
実験によって操作 x が 結果 y と相関したとしよう。処置群のひとがもし統制群だったら、その人の y は統制群の y になっていたはずか?[if the individuals who recieved the treatment had in fact not received it, what would we observe on y for those individuals? Or, if the individuals who did not receive the treatment had in fact received it, what would we have observed on y?] この反事実的な問いにイエスと答えられない場合(理論的な交換可能性がないとき)、因果効果の一致推定量を得るためにはセレクションのモデル化が必要になる。
2. ランダム化フィールド実験
因果推論のゴールド・スタンダードはランダム化デザインだ。なぜか?
二値の独立変数 x, 連続変数の共変量 z, 結果 y について、
$y_i = \beta_0 + \beta_1 x_i + \beta_2 z_i + e_i$
というANCOVAモデルを考えよう。係数のOLS推定における重要な想定は、潜在変数 e が x と無相関であるということ、つまり x の外生性である。もし外生性がなかったら x と y のあいだの関連性を調べるのは完全に無意味である。外生性を保証してくれるのがランダム化だ。言い換えると、OLSはセレクションがランダム割り付けによってなされていると想定している。
3. なぜ推定値の一致性が失われるのか
x に内生性が生じ、推定値が一致性を失う事情は多々ある。Shadish-Cook-Campbell本はこれを「内的妥当性」への脅威と呼んだ。
主要な5つの脅威は: 変数の無視、セレクションの無視、同時性、測定誤差、共通手法分散。さらに、統計的推論への脅威(標準誤差の妥当性の問題)と、同時方程式におけるモデルの誤指定をあわせて、計7個。順に説明していこう。
3.1 変数の無視
1) 説明変数の無視
リーダーシップ(y)をEQ(x)が予測するかという問題を調べたい。EQはIQ(z)と相関しているし、IQはリーダーシップを予測する。正しいモデルは
$y_i = \beta_0 + \beta_1 x_i + \beta_2 z_i + e_i$
ところがうっかりこういうモデルを推定しちゃったとしよう。
$y_i = \phi_0 + \phi_1 x_i + v_i$
いま
$z_i = \gamma_1 x_1 + u_1$
としよう。代入して
$y_i = \beta_0 + (\beta_1 + \beta_2 \gamma_1) x_i + (\beta_2 u_i + e_i)$
つまり、傾き$\phi_1$は zとx の相関($\gamma_1$) 次第でどうにでもなってしまう。
というわけで、予測子は足りないよりも入れすぎるほうがましである。要らない予測子を入れると効率性は下がるけど(標準誤差が上がる)、一致性のためなら安いものだ。
なお、残差にモデル化されていない線形性があるかどうかを調べるためのRESETテスト(regression-error-specification test)というのがあるから使うように。
2) 固定効果の無視
階層パネルデータについて考えよう。50個の企業がある。各企業に10人のリーダーがいる。リーダーのパフォーマンスをy, IQをxとする。正しいモデルが次のモデルだとしよう:
$y_{ij} = \beta_0 + \beta_1 x_{ij} + \sum_{k=2}^{50} \beta_k D_{kj} + e_{ij}$
ここで$D$は企業を表すダミー変数。企業によってIQはちがうだろうし、企業によってリーダーシップは違うだろうから、こうやって企業の固定効果をモデルにいれないと、$\beta_1$の推定値は一致性を失う。$x_{ij}$が$e_{ij}$に関して外生的であってもだめ。
3) 推定量についての仮定と合わないランダム効果を使う
[ちょっと意味がわからない箇所があり、ほとんど全訳してしまった]
モデル構築者が、レベル2(=企業レベル)の変数が y を予測するかどうかを決定したい場合、そのモデルはランダム効果推定量によって推定できる。ランダム効果推定量を用いれば、企業の間の切片のランダムな変動が許容される。マルチレベルモデリングの用語では、このモデルは「結果としての切片」と呼ばれている。
ランダム効果推定量は、企業の間の切片の異質性を固定効果によって明示的に推定するのではなく、リーダーのレベルでの y の差異(切片)を、企業の母集団から抽出された企業の間のランダムな効果として捉える。ここでランダム効果は、予測子とも撹乱項とも無相関であると仮定され、また各企業において一定であり、互いに独立に分布すると仮定される。これらの仮定に合致していないとき、推定値は一致性を失い、変数を無視したときと同じようにバイアスが生じる。
ランダム効果推定量を使う前に、ランダム効果が存在するかどうかをテストしなければならない。モデルをGLS推定した場合にはBreusch & Paganのラグランジュ乗数検定を、最尤推定したときはランダム効果の尤度比検定を用いる。後者は自由度1のカイ二乗検定で、有意な時にはランダム効果モデルが支持される。ここでは詳しくは触れないが、ランダム効果モデルの直接的な拡張として、群間での傾きの変動を許容するランダム係数モデルがある。ここで重要なのは、そういうモデルを使う前に、ランダム係数モデルとランダム効果モデルを比べる尤度比検定を行うことである。有意な時のみ、すなわち傾きが一定だという仮定が棄却されたときのみ、ランダム係数推定量を使うべきだ。
さて、ランダム効果推定量の利点(であると同時にアキレス腱)は、以下の定式化により、レベル2の変数(たとえば企業サイズ)を予測子に含めることができるという点である。
$y_{ij} = \beta_0 + \beta_1 x_{ij} + \sum_k^q \gamma_k z_{kj} + e_{ij} + u_j$
この式では、q個の予測子を含め、固定効果を取り除き、企業によって決まる誤差成分 u_j を含めている。
ランダム効果推定量は固定効果推定量より効率的である。なぜなら前者は推定されたパラメータの分散を最小化するようにデザインされているからだ(おおざっぱにいえば、企業のダミー変数を入れたときより独立変数の数が減っている)。しかし、想像に難くないことだが、固定効果推定量のような一致性がないかもしれないという深刻な代償を伴っている。すなわち、u がレベル1の予測子と相関しているかもしれない。
推定量が一致性を持つかどうかを調べるために、いわゆる"Hausman検定"を用いることができる。この検定は、ランダム効果モデルが維持できるかどうかを確かめるためには死活的に重要なのだが、計量経済学以外の分野ではあまり用いられていない。
Hausman検定が行っているのは、基本的には、固定効果推定量によるレベル1の推定値を、ランダム効果推定量による推定値と比較することである。もし推定値が有意に異なっていたら、ランダム効果推定量には一致性がなく、固定効果推定量を用いなければならない。u_jが予測子と相関しているせいで一致性が失われているにちがいないからである。ランダム効果推定量による推定値を信じてはならない。我々のライト・モチーフは「効率性より一致性が強い」である。
[...] なお、パラメータが複数あるときはSargen-Hansen検定というのもある。どちらもStataに入っている(我々のお勧めソフトである)。[...]
固定効果の無視という問題を回避し、かつレベル2の変数を含める方法として、すべてのレベル1共変量のクラスタ平均を含めるという手がある。クラスタ平均を予測子に含めてもいいし、レベル1共変量からひいてしまってもいい。固定効果を含めたのと同じく、レベル1パラメータの一致推定が可能になる。つまり、Hausman検定が有意である場合、クラスタ平均が u_j と相関しないとすれば、レベル1パラメータの一致推定値を得る方法として次の2つの式が使えるわけだ。
$y_{ij} = \beta_0 + \beta_1 x_{ij} + \beta_2 \bar{x}_j + \sum_k \gamma_k z_{kj} + e_{ij} + u_j$
$y_{ij} = \delta_0 + \delta_1 (x_{ij} - \bar{x}_j) + \sum_k \phi_k z_{kj} + w_{ij} + g_j$
2つの式で、クラスタ平均の係数の解釈は異なる。上の式では係数はbetween効果とwithin効果の差を示し、下の式では係数はbetween効果を示している[←ここの意味がよくわからない...]。しかしどちらにしても、$\beta_1$と$\delta_1$には一致性がある。
レベル2の変数が内生的だったら、このクラスタ平均のトリックは役に立たない。しかし、レベル2の共変量の外生的分散を調べることで、一致推定値を手に入れる方法がいくつか存在する。
4) セレクションの無視
$y_i = \beta_0 + \beta_1 x_i + \beta_2 z_i + e_i$
というモデルで、$x_i$ がランダム割り付けになっておらず、
$x^*_i = \gamma_0 + \sum_k^q \gamma_k z_{kj} + u_i$
が正の時に$x = 1$になるという場合を考えよう。$u$ と $e$ の相関$\rho_{e,u}$が0でないとき、$x$と$e$が相関してしまう。
大丈夫、解決策はある。セレクションを明示的にモデル化すればいいのだ。yが処置群でしか観察できなくても大丈夫。Heckmanはこれでノーベル経済学賞をもらったんだよ! [←ほんとにこう書いてある、感嘆符つきで]
よく似た問題としてセンサード標本がある。センサードとは、研究への参加においてセレクションがかかっていること。この場合もセレクションをモデル化すること。センサード回帰とか、トランケーテッド回帰とか、いろいろある。
3.2 同時性(Simultaneity)
上司が部下に対して罰を与えるかどうかを $x$, 部下のパフォーマンスを$y$とする。
$y_i = \beta_0 + \beta_1 x_i + e_i$
とモデルを組んだ。しかし実は上司のスタイルは部下のパフォーマンスの関数で
$x_i = \gamma_1 y_i + u_j$
だとしよう。$y$が$e$と相関してしまう。
3.3 測定誤差
正しいモデルが
$y_i = \beta_0 + \beta_1 x^*_i + e_i$
なのだけど、$x^*$が観察できず、かわりに
$x_i = x^*_i + u_i$
だけが観察できるとしよう。代入すると
$y_i = \beta_0 + \beta_1 x_i + (e_i - \beta_1 u_i)$
というわけで、$\beta_1$には一致性がない。このように、測定誤差も変数の無視(ここでは$u$の無視)という問題として捉えられる。[←なるほど、そりゃそうだ]
解決策はすごく簡単で、xの残差分散を (1-信頼性)x分散 に固定してやればよい。信頼性の推定値が必要になるが、検査再検査信頼性とか、クロンバックのアルファとかを使う手もあるし、理論的に推測してもいい。推定はStataなりMplusなりを使えば簡単だ。
3.4 共通ソース分散、共通手法分散
ソース(たとえば評定者)やデータ収集手法が共通であるせいで、$y$と$x$の両方が$q$に依存していること。これはすごく深刻な話だ。Spector(2006, Org.Res.Method)は共通手法分散の問題を都市伝説と呼んでいるが、全く同意できない。[←うわー、面白い。そんな意見があるのか。これは読みたいなあ]
共通手法分散のせいで係数はバイアスを受けるが、そのバイアスはプラスかもしれないし、意外なことにマイナスかもしれない。これはPodsakoffらのレビュー(2003, J.App.Psy.)でも指摘されていた点なのだが、その理由をきちんと説明しているものが見当たらない。以下で説明しよう。
なお、xとyを別ソース・別時点で測定するという手もあって、それはまあ間違ってはいないけど、サンプルサイズが小さくなる。
潜在共通因子をモデルにいれて説明するというやり方があって、Podsakoffらはこれを回避策のひとつとして示唆しているのだが[←そうなの? 確認しなきゃ]、われわれはこの手法を使うべきでないと考える。以下の架空例を読め。
いま、リーダーのスタイルを表す因子として「課題志向的リーダーシップの高さ」$\Xi_1$と「対人志向的リーダーシップの高さ」$\Xi_2$があるとしよう。で、実は「組織のリスクの程度」という測定されていない共通原因があって、これが$\Xi_1$に係数0.57で効き、$\Xi_2$に係数-0.57で効いている、としよう。リスクが高い場面では課題志向的リーダーシップが高まり対人志向的リーダーシップが低くなるわけだ。共通原因を制御したら因子間相関は0だということにしておく。
各因子をそれぞれを4つの指標で測っている。真の負荷はすべて0.96だとしよう。さらに、指標がタウ等価であること(=負荷が全部同じであること)をモデラーが知っているとしよう。サンプルサイズ10000。仮に共通原因変数が観測されていたら、モデルの適合度は文句なしに高い。因子間相関は 0 と推定される。
さて、共通原因変数の存在に気づいていないとしよう。このときもモデルの適合度は文句なしに高い。負荷はすべて0.96。しかし因子間相関は -0.32となる。このように、負のバイアスがかかることだってあるわけだ。
今度は、共通原因変数の存在にうすうす気づき、潜在変数を投入したとしよう。8指標がこの潜在変数に直接の負荷を持ち、係数は各4指標内で等値だと制約する。結果: やはり適合度は完璧なまま。$\Xi_1$への負荷は0.38, $\Xi_2$への負荷は0.87に下がり、因子間相関は0.19になってしまう。[←ちょ、ちょっと待って... ここで共通原因からの真のパスは$\Xi_1$, $\Xi_2$に刺さってんでしょう? なのになぜx1-x8にパスを刺すの? これは「共通原因をあらわす潜在変数を投入してもバイアスが消えない」という話じゃなくて、「共通原因をあらわす潜在変数を投入してもモデルを誤指定してたらアウト」というあたりまえの話になってないですか?]
整理しよう。評定者$i$が リーダー$j$(50名)について、そのなんらかのスタイル$x$とリーダーシップ$y$を評価している。あいにく両方の評定値に共通バイアス q が効いているとしよう。
$y^*_{ij} = \beta_0 + \beta_1 x^*_{ij} + \sum_{k=2}^{50} \beta_k D_{jk} + e_{ij}$
$y_{ij} = y^*_{ij} + \gamma_y q_{ij}$
$x_{ij} = x^*_{ij} + \gamma_x q_{ij}$
代入して整理すると
$y_{ij} = \beta_0 + \beta_1 x_{ij} + \sum_{k=2}^{50} \beta_k D_{jk} + (e_{ij} - \beta_1 \gamma_x q_{ij} + \gamma_y q_{ij})$
というわけで、$\beta_1$は一致性を失う。
解決策は? $q$を測定できれば話は簡単だが、まず無理だろう。我々はこう提案したい。我々の知る限りこれは世界初の提案だ。2SLSを使え! ...あとで説明しよう。
3.5 推論の一致性
ここまでの話とはちょっとちがって、標準誤差に一致性がない、という話。テクニカルな話題なので手短に述べよう。
回帰残差はiidでない場合について考える(Stataなら簡単にチェックできる)。まず、残差に等分散性がないとき、係数は一致推定量だけど標準誤差が一致性を失う。この場合は、Huber-White標準誤差(サンドイッチ標準誤差、ロバスト標準誤差ともいう)をつかわねばならない。クラスタを持つデータの場合も、標準誤差の推定に特別な方法を使わなければならない。
(本文29頁のうち、ここまでで13頁。死ぬー)
4. 因果性を推論するための諸手法
大きく分けて、統計的調整と準実験がある。
4.1 統計的調整
わかってる共変量は全部入れろ。傾向スコアを使うのもいいぞ。
4.2 準実験
1)同時方程式モデル
まずは二段階最小二乗法 (2SLS)について説明しよう。経済学者以外はほとんど使っていない。まことに由々しきことだ。
話を簡単にするために、$x$が連続変数の場合について考えよう。ボス$i$が、部下のリーダー一名について、その行動$x$とリーダーシップ$y$を評定する。統制変数は$c$個ある(リーダーの年齢とか)。あいにく$x$と$y$には共通ソース分散$q$が存在する。
$y_i = \beta_0 + \beta_1 x_i + \sum_{k=1}^{c} \gamma_k f_{ik} + (e_{ij} - \beta_1 \gamma_x q_{ij} + \gamma_y q_{ij})$
さてここで、$x$を強く予測し、$x$を通じてのみ$y$と関連し、そして$(e_{ij} - \beta_1 \gamma_x q_{ij} + \gamma_y q_{ij})$と関連していない$z$がみつかったとしよう。こういうのを道具変数という。たとえば、リーダーのIQがそれだとする。さらにもうひとつ、評定者とリーダーの距離$d$があって、これもリーダーシップに効いているとしよう。[←あれれ? よくわかんなくなってきたけど... まあいいや、とにかく道具変数が2つ手に入っているという話であろう]
これらを用いて$x$を予測する。これを第一段階の方程式という。ここでのポイントは、$c$個の統制変数を全部使うこと。
$x_i = \gamma_0 + \gamma_1 z_i + gamma_2 d_i + \sum_{k=1}^{c} \gamma_k f_{ik} + u_i$
この式で推定した $\hat{x}$を用いて、$y$を予測する。これが第二段階の方程式。
$y_i = \lambda_0 + \lambda_1 \hat{x}_i + \sum_{k=1}^{c} \theta_k f_{ik} + e_i$
こうして$\beta_1$の一致推定が手に入る。実際にはStataのようなソフトを使うように。
この手法のポイントは、$u$と$e$の相関を推定しているという点である。相関の有無はHausman内生性検定(Durbin-Wu-Hausman内生性検定)で検討できる。内生変数がひとつだったら、これは$u$と$e$の相関を推定するモデルとしないモデルを比べる自由度1のカイ二乗検定であり、SEMのソフトでも可能である。
心理学者がよくやる間違いは、$u$と$e$の相関を推定せずに同時方程式を推定しちゃうことだ。たとえばBaron&Kenny(1986)がそうだ [←おっとぉ... 喧嘩売り始めたね]。ああいうやりかたでメディエータをテストしている論文はたいてい間違っている。
2SLS推定は、いきなりSEMのソフトで最尤推定したり、3段階最小二乗法のような完全情報推定量を使うよりも安全だ。
1-1)同時方程式モデルにおける適合度の検討
[ここ、理解できずほぼ全訳してしまった]
上の例ではモデルの真実性[veracity]と道具変数の適切性をテストすることができる。たとえば、Stataのivreg2モジュールをつかって、道具変数が「強力」かどうかを検討することができる。同時に、メディエータの数よりも多くの道具変数があるとき、方程式のシステムを過剰同定する[overidentifying. なんかネガティブな語感があるので困るけど、識別性があるってことね]制約がありうるかについてテストすることも重要である。これは、示唆されているモデルと実際のモデルとの間に乖離が存在するかどうかを決めるテストである。本質的には、これらのテストが検討しているのは道具変数が$y$方程式の残差と相関しているかどうかである。読者にはすでに明白であろうが、この望ましくない状況を引き起こすのはモデルの誤指定である。それは推定値がバイアスを受けていること、よって解釈不能であることを意味する。従って、推定値について解釈する前にモデルを適合させなければならない。
上の例で方程式は過剰同定されていた(すなわち、内生的な予測子の数よりもひとつ多くの道具変数を得ていた)。従って自由度1のカイ二乗適合度検定が可能であった。もし道具変数がひとつだけだったら、モデルは丁度識別となってしまい、適合度検定はできないところだった(ただしHausman内生性検定はできる)。回帰モデルの文脈は、これらの適合度検定は、カイ二乗検定、Sargan検定, Hansen-Sargan検定、J検定と呼ばれている。これらはSEMソフトで普通使われているML推定の文脈における、カイ二乗適合度検定との直接的な類比物である。この検定でp値が有意になるということは、モデルが適合していないこと(つまりデータがモデルを棄却していること)を意味する。心理学・管理科学でこの検定は良く知られているが、しかししばしば無視されている。興味深いことに経済学者は適合度検定に注意を払う。もし有意だったら、モデルはよくないですね、で話が終わりになる(モデルの修正ないしよりよい道具変数の発見が必須になる)。経済学者はRMSEAやTLIのような近似的な適合度指標を使わない。これらの指標は、既知の分布による統計的検定ではなかったり、(RMSEAのように)カットオフ値が恣意的だったりする。
ある種の社会科学の領域では、大きな標本ではわずかな乖離でも検出されてしまい検定のp値は常に有意になってしまうだろうという理由によって、カイ二乗適合度検定にパスしていないモデルを受け入れてしまうのがあたりまえになっている。しかし経済学以外の研究者の中にも、このやりかたに深刻な疑問を投げかける人々が現れている。もしモデルの指定が正しければ、たとえ標本サイズが非常に大きくてもカイ二乗検定は棄却されないはずだ。カイ二乗検定は、ランダムな変動を踏まえ、偶然に起因するある程度の乖離を「許容する」検定である。また、カイ二乗検定は他のさまざまな近似的適合度指標と比べ、誤指定されたモデルの検出力が最も高い検定である。研究者はカイ二乗適合度検定に注意を払い、棄却されたモデルがさも受容可能であるかのように報告するのをやめるべきだ。
最後に、研究対象とする標本は因果的に等質でなければならない。因果的に等質な標本は無限ではない(従って、標本の大きさには限界が存在する)。多群モデル(モデレータ・モデル)であれ、MIMICモデルであれ、母集団における異質性の源を突き止めそれを制御することで、適合度を改善できるだろう。
1-2) PLS問題
PLSは使うな。あれは飽和モデルならOLSと同じだし、そうでない場合、適合性が検定できないから推定値がバイアスを受けていてもわからない。OLS, 2SLSや共分散ベースのSEMよりも良い、なんていうのは嘘で、収束しないことだってあるのだ。PLSユーザは「SEMは理論検証に優れ、いっぽうPLSはモデル構築初期の予測に優れている」というマントラを唱えるが、おまえらはSEMや2SLSじゃ予測ができないとぬかすのか。モデルを検証したいとは思いませんだなんて、自分ら頭おかしいんちゃうか。Hwang et al.(2010, JMR)のシミュレーション研究によれば、PLSのパフォーマンスはSEMより悪いんじゃコラ。分布の仮定がいらんとか小サンプルでもいけるとか抜かしよるが、そんなん2SLSかてそうなんじゃボケ[←とは書いてないけど、まあ大体そういう内容]
1-3) 道具変数の発見
リーダーシップ研究における道具変数の例: クロスセクショナル研究や縦断研究なら、年齢とか性別とかホルモンとか外見とかリーダーからの地理的距離とか。時間とか、特定のイベントによるショックとか。法とか文化要因とか。パネルデータなら、リーダーの固定効果とか、クラスタ平均とか。
とにかく大事なのは、e と相関しない変数であることだ。頑張って探して、過剰識別の検定にかけろ。
1-4) 共通手法分散の問題を2SLSで解く
例1. 2SLSを使った例。
前述の議論は理論的なものだったので、読者は2SLS推定量で因果的推定値を復元できるということを内心疑っているかもしれない[←よくおわかりで]。そこで、強い共通手法分散効果がある既知の構造からデータを生成してみよう。いま、内生的独立変数$x$, 従属変数$y$, ふたつの完全に測定された外生変数$m$と$n$、共通ソース効果$q$がある。データを生成する真のモデルは以下の通り。$e$と$u$は正規分布に従い互いに独立だとする。
$x = \alpha_0 + q + 0.8m + 0.8n + e$
$y = \beta_0 + q - 0.2x + u$
サイズ10000のデータを生成した。相関行列と単純統計量を示す[略]。これらの要約データをSEMのソフトに入れればML推定で以下と同じ推定値が出せる。
$y$が$x$に単純に回帰しているOLSモデルを推定してみよう。回帰係数の推定値は+0.11, あきらかに誤っている。真の値(-0.2)はこれより212.82%も低い! これこそが、$x$ に内生性を与えている式を無視したときの共通手法変数の悪影響である。すでに述べたように、バイアスを受けているOLS係数は、高すぎるかもしれないし、低すぎるかもしれないし、符号が異なるかもしれないし、有意でないかもしれない。共通手法分散は都市伝説どころではない。そんな意見そのものが声高な伝説なのだ。
このモデルの推定値、ならびに2本のOLS方程式に基づく既知モデルの推定値を示す[略]。後者では、内生変数の分散のソースが説明されているので、撹乱項の相関はなくて良い[←???]。正しい推定値(-0.2)が得られている。しかし共通原因 $q$はふつう直接に測定できないから、このモデルは実世界では推定できないだろう。
この問題の解決のためにかんたんに利用できる唯一の方法は、道具変数を用いたモデル化である。2SLS推定量によって、$m$と$n$に由来する分散の外生的ソースについて比べ、真の推定値を復元する。これらの外生変数は$q$とは相関しないし(従って$q$のないモデルにおいて$e$と相関しない)、ランダムに変動する$u$とも相関しない。それらは$x$と強く関連し、$x$を通じてのみ$y$に影響する。結果を示す[略]。$q$をモデルに入れていなくても2SLS推定量は関心ある推定値を正確に復元している(-0.20)。ただし、信頼区間は若干広い。すでに述べたように、効率性が減るという代償を支払わなければならない。2方程式モデルの場合、強力な道具変数があれば、2SLS推定量は3SLS、反復3SLS、ML, LIML推定量と類似した推定値を与える。
2SLS推定量の安定性を示すために、このデータ構造についてのモンテカルロ・シミュレーションを行った。1000回のシミュレーションで、平均は-0.20、95%信頼区間は-0.200から-0.199であった。Sarganの過剰識別カイ二乗検定では、道具変数は妥当であった(p=0.30。シミュレーションもこの知見を支持した。pの平均は0.32)。
さて、このモデルを管理科学・応用心理学における標準的アプローチで推定していたらどうなっていたか。つまり、推定量がなんtであれ、撹乱項間を無相関にしていたらどうなっていたか。このとき推定値は誤ったものになる(すなわち0.11、実際これはOLS推定量による推定値と同じである)。撹乱項間の相関を推定しないと、$x$と$y$の両方を予測する「共通ショック」は、モデルにおいて測定されておらず説明もされず、存在しないことになる。これはあまりに強すぎる仮定であり、こうした媒介モデルの文脈では誤っている。
例2. MLを使った例。
さきほどの例から、さらに次のことがわかる。共通ソース/手法の効果を明示的にモデル化しないと、真のパラメータ推定値は復元できない(たとえば手法因子をモデル化しようとしてもだめである。なぜなら手法因子が変数にどのように影響しているのかがわからないからである)[←ここの文意がわからない。原文: The previous demonstraion should now explain further that if the effect of a common source/method is not explicitly modeld, true parameter estimates cannot be recovered (e.g., by attempting to model a mehod factor, because how the method factor affects the variable is unknown to the researcher.)] 従って、この問題を制御する統計的方法として擁護できるのは、すでに示したように、道具変数を使う方法である。同じ手続きを、完全なSEMモデルへと拡張できる。3.4節と似た特徴づけに従い、簡単な例を示そう。社長のリーダーシップの実効性を従属変数$y$とし、それが2つの独立変数を持つとする。すべての指標は社長の行動について限定的な知識しか持たない投票者から得たものである。共通原因(たとえば社長への感情、ないし他のなんらかの共通原因メカニズム)があり、かつ共通原因と無相関な道具変数$z1, z2$がある(道具変数によるセレクションはないものとする)。$z1$は社長のIQ, $z2$は社長の神経症傾向で、相関はないものとする。$\Xi_1$は変革型リーダーシップ、$\Xi_2$は交流型リーダーシップであるとしよう。部下の中に社長が好きな人が多いほど、社長をカリスマ的だとみなす人が増え、社長を交流型だとみなす人が減る、しかしこれらのリーダーシップ・スタイルは社長のIQやパーソナリティの影響も受ける、というわけである。リーダーの個人差は外生的であり(遺伝子で決まっており)、他の因子とは独立に変動するものとする。
正しいモデル[共通原因も道具変数も測定変数として入っているモデル]を示す。完璧に適合している[...]。共通原因を外したモデルでも、撹乱項に相関を入れている限り、正しいパラメータ推定値が得られる[...]。道具変数を外して共通原因をいれたモデルでも正しい推定値が得られる。しかし両方外したモデルは、適合しているのに推定値が誤っている。この例が示しているのは、道具変数によって内生変数からバイアスを取り除くことができるということであり、同時に、モデルを正しく指定しているということが絶対的に重要だということである。なお、潜在共通因子をモデル化することによって正しい因果効果を復元しようとしてみたが、ヘイウッド解が得られてしまい、推定のためにyの分散を制約せざるを得なくなった。モデルの適合度は高かったが推定値は誤っていた。
以上の例示は、共通手法問題の解決、そして媒介モデルの正しい推定に新しい方向を提供していると考える。また、モデルを指定する際には統計的検定だけでなく理論に依拠しなければならないということ、一致推定値を得るために分散の外生的なソースをモデル化しなければならないこと、を示すことができたと思う。
4.3 回帰不連続モデル(RDD)
[共通手法分散の話で力尽きたので、ここからは簡単に...]
ランダム化実験では処置のセレクションがランダムなのに対し、RDDではセレクションが特定のカットオフで決まる。カットオフの閾値は明示的に観察されておりモデル化されている。カットオフ変数はプリテストないしなんらかの連続変数で、yとは相関していてもいなくてもよい。
RDDが一致推定値を与えることができるのは、群のセレクションが回帰方程式のなかに含まれている明示的に測定された基準に基づいており、撹乱項が群と相関する情報を持っていないからである。RDDの利点は数多い。政策の効率性を検証するためのフィールド状況で比較的に容易に実現できる。
[RDDのデモ。略]
4.4 差の差モデル
心理学でいうところのuntreated control group design with pre- and post-test。[モデルの説明。略] このモデルのポイントは、条件(処置群, 統制群)と時間(プリ, ポスト)の交互作用が外生的だという点である。つまり、群間差は安定的でなければならず、処理のタイミングは外生的でなければならない。[架空例。略]
4.5 セレクション・モデル(ヘックマン・モデル)
ヘックマン型の2ステップ・セレクションモデル。treatment effects modelともいう。まず群への参加をプロビット回帰し、次に処置の効果を推定する奴。その変種に、ヘックマンの2ステップモデルがある(一方の群だけ従属変数が観察されている奴)。[架空例。略]
4.6 その他の準実験デザイン
Cook-Campbell本(1979)とShadish-Cook-Campbell本(2002)を読むように。[←あれってCook-Campbell本の改訂新版だと思ってた...]
5&6. 管理科学・応用心理学における因果的推論の頑健性レビュー
リーダーシップの非実験研究の論文110本を集め、14個の基準についてコーディング[よくやるよ...]。少なく見ても66%の論文が、妥当性への脅威に正しく対処していない。特に、測定誤差、誤差の不等分散性、共通手法分散が深刻。
7. 考察
博士課程の教育に問題があるんじゃなかろうか。また、統計ソフト任せな分析やカンタンすぎる参考書のせいで「プッシュボタン統計学」症候群が蔓延しているのではなかろうか。[ここでひとしきりSPSSとAmosの悪口。StataとかSASとかRとかMplusとかLISRELとかEQSを使えよ、とのこと]
因果分析の十戒:
- 変数の無視によるバイアスを避けるために、適切なコントロール変数を含めること。もし適切なコントロール変数が同定できない、ないし測定できない場合は、パネルデータを手に入れ、分散の外生的ソース(道具変数)を用いて効果の一致推定値を求めよ。
- パネルデータを使うときは必ず固定効果を含めよ。ダミー変数を使ってもいいし、レベル1変数のクラスタ平均を使ってもいい。ランダム効果モデルを推定する際には、かならずその推定量が固定効果に関して一致性を持つことをHausman検定で確認すること。
- 独立変数の外生性を確認すること。それがなんらかの理由で内生的である場合は、道具変数を手に入れろ。
- 処置が無作為割付されていないとき、処置群のメンバーかどうかが内生的な時、標本に代表性がないときは、適切なセレクションモデル、ないし他の手法(差の差, 傾向スコア)を用いて群間の推定値を修正すること。
- 同時方程式モデルの場合は、過剰識別性検定(カイ二乗適合度検定)を用いてモデルが維持できるかどうかを決めること。過剰識別性検定に失敗したモデルの推定値は信用できないので解釈してはいけない。
- 独立変数が測定誤差を伴っている場合は、errors-in-variableを使って推定するか、道具変数を使って(もちろん2SLSモデルの文脈で適切に測定された変数でなければならない)測定バイアスを修正せよ。
- 共通手法バイアスを避けること。もし避けようがない場合には(2SLSモデルの文脈でいう)道具変数を使って一致推定値を得ること。
- 推論の一致性を確保するため[←パラメータ推定じゃなくてその標準誤差の一致性のことね]、残差がiidであるかどうかを調べることお。iidであることがわからない限り、ロバスト分散推定量をデフォルトにすること。パネルデータの場合はクラスタに対してロバストな分散推定量を使うか、group-specificな予測子を使うこと。
- 媒介モデルにおいては、内生的かもしれない予測子の撹乱項は相関させること。そしてHausman検定でメディエータが内生的かどうか調べること。
- 完全情報推定量(ML)を使うのは、推定値が2SLS推定量と変わらないときだけにせよ。PLSは使うな。
ついでにいうと、もっとモンテカルロ分析を使うべきだ[推定量の安定性が得られるサンプルサイズをモンテカルロシミュレーションで確認しろ、っていう意味かな]。
8. 結論
理論、分析、測定は正しく整合していなければならぬ、でないと実証的ゼリーの上に理論的摩天楼を立てる羽目になる。
感想:
- いやー、強烈に2SLS推し!であることに驚いた。なんだかよく知らないけど、計量経済学の教科書だけに出てくる、古い手法だという印象があったのだ(それゆえにこれまでノーマークであった)。この2SLSラヴっぷり、他の専門家からみてどうなんだろうなあ。よくわからないけど、ま、勉強する良い機会をもらったと考えよう。
- 共通手法分散の問題で、潜在変数として手法因子を入れる方法はなぜダメなのか、いまいち理解できなかった... 直感的にダメだろうという気もするし、ダメならダメで納得するのだけれど、ダメである理由が知りたい。
- 回帰不連続デザインでプリテストのスコアが測定誤差を持っている場合のくだり、どうも腑に落ちない。プリテストの真値が従属変数と正の相関を持っているとして、プリテストのスコアが閾値より下だった人を処置群、上だった人を統制群に割り付けたとき、もしプリテストのスコアに測定誤差があったら、平均への回帰が生じ、処置効果の推定量は正方向のバイアスを受けそうなものだ。著者によれば、それはプリテストスコアの偏回帰係数で吸収され、処置効果の推定値には影響しないとのことなのだが... うむむむ。やはりこういうレビューだけではなくて、きちんと勉強しないといけないな。
読了:Antonakis, Bendahan, Jacquart, & Lalive (2010) 無作為化実験できないあなたのための因果推論ガイド
2014年11月19日 (水)
村山航 (2012) 妥当性:概念の歴史的変遷と心理測定学的観点からの考察. 教育心理学年報, 51, 118-130.
ちょっと用事があって目を通した。かなり前に(前の前の勤務先の頃)、テスト学会のイベントで、著者による妥当性についての講演を拝聴したことがあって、大変勉強になったのだが、たぶんあの講演の論文化だと思う。
いくつかメモ:
- 妥当性のtrinitarian view (「妥当性には基準関連妥当性、構成概念妥当性、内容的妥当性の3つの側面があります」説)への対抗として、Messickの「妥当性ってのは構成概念妥当性だ」説が出てきたのだが、この観点からいえば、たとえば測定結果が他の集団に一般化できるかというような側面も構成概念妥当性のひとつなわけで、つまり信頼性も妥当性の証拠のひとつになる。
- いわゆる帯域幅-忠実度ジレンマに直面して、「多少信頼性が低くなっても幅広く項目を集めようぜ」ということがあるけど(あるある)、因子分析モデルに照らして考えるとおかしい。だって独自性を除去して共通分散だけみるわけだから。この手続きが悪いってわけじゃないけど、それを正当化するロジックを考えるのが難しいのである(←うむむむ...??? そうなのか...)。かんたんな解決策はないけど、構成概念は事前にできるだけ明確に定義しておいた方がいい。
- たいていの調査項目はメトリックがarbitraryで、構成概念と回答がどう対応してるのかはっきりしない(「満足だ」と「やや満足だ」がどうちがうのか誰にもわからない、という話である)。ってことは、たとえば交互作用がみつかってもそれは特性曲線のせいかもしれんわけである。こうした尺度の不定性の問題も妥当性のひとつの側面である(←あー、なるほど...)
Borsboomさんという、Messick流の構成概念妥当性概念をきつーく批判している人がいるけど(この人、なかなか面白いのだ)、2009年のSEM誌に"Educationnal Measurement" 4th ed. の書評という形で批判を書いているらしい。ちょっと読んでみたい。いや、待て、その後に出た著書が積んだままになっているような気が...
2014年11月14日 (金)
季節はめぐり、寒い冬が近づいているが、「ウェイトバックした集計表の検定」についてどなたかにご説明する、という機会も周期的にめぐってくる。というのは、私はたまたま市場調査に関連するお仕事で細々と暮らしており、市場調査の世界では消費者にアンケート調査かなんかをやることが多く、それを集計するときに「ウェイトバック」することが多く(すなわち、抽出確率が均等でない標本に基づき、確率ウェイティングによって母集団特性を推定することが多く)、しかし市販の教科書にはこの種の話題はあまり触れられておらず、皆さんもっと有益な話題を語るのに忙しく、こういう金にならない話についてお答えする暇人は少なく、日は昇り、また沈み、時移る... という事情がある。
この話題、あまりに定期的にめぐってくるので、「そんな検定、お使いの統計ソフトではたぶんできませんよ」という点と、「そもそもウェイトバックなんてしないほうがいいかもしれませんよ」という点については、かつてこのブログでくどくどと説明した。各界でご活躍の優秀な皆様が、どうか必要なタイミングで、これらの記事をみつけてくださいますように。図々しいけれど、ひとりでも多くの関係者の方に読んでいただければ幸いである。
さて、このたびまた同じご説明を行っていて、ふと思ったんだけど、確率ウェイティングの下で二群の割合の差を検定する手法って、なぜあんなにたくさんあるのだろうか? これがですね、案外たくさんあるのですよ。私の知る限り、大きく分けてカイ二乗検定のRao-Scott修正という方向とワルド検定という方向があり、それぞれにおいていくつものバージョンがある。なにがどう違うのか、実に面妖な話である。個々の手法についての説明ではなく、手法を比較したレビューのようなものはないかしらん?
Scott, A. (2007) Rao-Scott corrections and their impact. Proceedings of the Section on Survey Research Methods, American Statistical Association, 3514–3518.
というわけでwebを探していて目に留まった、「Rao-Scott修正」のScottさんご自身による文章。えーっと、2007年のアメリカ統計学会Joint Statistical MeetingsではRao先生の古稀をお祝いする招待セッションが開かれ、そこでScottさんが講演したようで、その要旨である。ほんとはレビュー論文を探すべきなのだろうけれど、すいません、そこまで本気じゃないんです。
ええと、Rao&Scott(1981JASA, 1984Annals of Stat.)はもう四半世紀も前のことだね、あの頃僕らは誰々や誰々と一緒に研究したよね、みんな若かったよね、というような思い出話があって...
セル数$T$の多元クロス表の、セル$t$の母比率を$\pi_t$とし、まとめてベクトルで$\pi$と表す。$\mu_t = log(\pi_t)$ として、次の対数線形モデルを考える(そうそう、Rao&Scott(1984)って、意外にもいきなり対数線形モデルから始まるんですよ...)。
$\mu = u(\theta) e + X \theta$
$\theta$は長さ$p$のパラメータ・ベクトル。$e$は長さ$T$のベクトルで要素は$1$。$u(\theta)$は定数で、$\pi_t$の合計が$1$になるように調整している。Xは$T$行$p$列の係数行列で、そのランクは$p < T-1$、$X^T e = 0$。これをモデル1と呼ぼう。
ベクトル$\theta$をふたつにわけ、上の$T-k$個を$\theta_1$, 下の$k$個を$\theta_2$とする。同様に$X$も $X = (X_1, X_2)$と分割する。で、下位モデル
$\mu = u_1 (\theta_1) e + X_1 \theta_1$
を考える。これをモデル2と呼ぼう。モデル2の適合度を調べれば、帰無仮説$H_0: \theta_2 = 0$について検定したことになる。典型的には、モデル2はクロス表の行と列が独立だというモデルである。
モデル1による$\pi_t$の最尤推定量を$\hat{\pi_t}$とする。単純無作為抽出であれば、標本比率$\hat{p}$について$X^T \hat{\pi} = X^T \hat{p}$である。モデル2による最尤推定量を$\hat{\pi}^*_t$とする。ピアソンのカイ二乗統計量は
$X^2_P = n \sum_t \frac{ (\hat{\pi}_t - \hat{\pi}^*_t)^2}{\hat{\pi}^*_t}$
尤度比統計量は
$G^2 = 2n \sum_t \hat{\pi}_t log(\frac{\hat{\pi}_t}{\hat{\pi}^*_t})$
どちらも帰無仮説のもとでカイ二乗分布に漸近的に従う。
さて。標本抽出デザインが複雑なとき、なにが起きるか。
母比率の推定量$\hat{p}$は、もはや標本比率でなく、もっと複雑ななにかである。期待できるのはせいぜい、$\hat{p}$が$\pi$の一致推定量になっていること、中心極限定理が成立してくれること、くらいである。$\sqrt{n} (\hat{p} - \pi)$が平均0の$T$変量正規分布に従うとし、その共分散行列を$V_p$としよう。
Rao&Scott(1981, 1984)で僕らは、$X^2_P$と$G^2$が帰無分布の下で、$\sum_i^k \delta_i Z^2_i$と同じ分布に従うことを示した。ここで$Z \sim N(0,1)$。$\delta_1, \ldots, \delta_k$は「一般化デザイン効果」と呼ばれていて... (求め方は省略)。というわけで、理屈からいえば、仮に$V_p$の推定値が手に入るなら、「一般化デザイン効果」の推定値が手に入り、帰無分布の下での$X^2_P$ないし$G^2$の分布が手に入り、検定できるわけである。
理屈はわかった。具体的にはどうしたらいいのか。
一般化デザイン効果の推定値の平均 $\bar{\delta} = \sum_1^k \hat{\delta_i}$を求める。で、サンプルサイズをこれで割って、いわゆる等価サンプルサイズ $\tilde{n} = n / \bar{\delta}$を求める。検定統計量$X^2_p$ないし$G^2$の式のなかの$n$を、この$\tilde{n}$で置き換えて修正しよう。これがRao-Scott修正である。
こうして得た$X^2_{RS}$ないし$G^2_{RS}$の、帰無仮説の下での分布をどうやって近似するか。3つのやりかたがある。
ひとつめ、単に自由度$k$のカイ二乗分布で近似する。これを一次のRS修正という。
ふたつめ、自由度 $k/c$のカイ二乗分布に$c$を掛ける。ただし、$c=\sum \delta^2_i / (k \bar{\delta}^2)$。これを二次のRS修正という。
みっつめ。どうにかして$\hat{V}_p$を手に入れる。たとえば$Cov(\hat{p})$を使う。で、そのランクを$\nu$とする。通常、$\nu$は(PSUの数)-(層の数)である。で、自由度$(k/c, \nu k / c)$のF分布に$k$を掛ける。何言ってんだかわかんないけど、とにかくそうなるんだそうである。
最後のやつが一番正確なのだが、あいにく$\hat{V}_p$は手に入らないことが多い。いっぽう一般化デザイン効果の平均値$\bar{\delta}$だけなら、セル比率と周辺比率の標準誤差から算出できる。なので一次のRS修正が使われることが多い(←なるほどー)。
RS修正の発表以後、一次のRS修正を改善しようという試みが多数行われてきたが、たいしたインパクトはなかった。RS修正の対抗馬はほかにいっぱいあったのだが("the Wald, Fay's Jackknife, and Bonferroni inequalities"と書いてある。最後のBonferroni法ってなんのことだろう...)、RS修正のわかりやすさには勝てない。
Rao&Scott(1981, 1984)の引用件数の推移をみてみよう(←さすがは統計学者、loess回帰しているぞ)。意図に反し、社会科学系ではあんまり使われていない。SPSSがRS修正の機能を積んでないからかなあ。(←そうなの? Complex Samplesパッケージには積んであるのかと思ってた。それともあのパッケージはユーザが少ないのかな)
ところで、一次のRS修正には、忘却されつつあるもうひとつの可能性(Scott & Rao, 1981)があった。ちょっとPRさせてください。たとえば、地域で層別した調査とか、多国間調査とか。あるいは、同一母集団に対する異なる調査とか、agreement between interviewers based on Mahalanobis’ interpenetrating subsamplesとか(←最後のやつがよくわからない。独立に抽出した二標本間でマッチングをかけるような状況だろうか)。そういう場面で、等質性を検定したいこと、あるよね? そんなときにも一次のRS修正が使えるのだ... 云々。
最後に、いろんな方面への拡張を紹介。ロジスティック回帰とか一般化線形モデルとか、ドメイン平均の検定とか。
私のような素人にも親しみやすい紹介であった。ほんとはワルド検定との比較について知りたかったんだけど、まあいいや。
読了:Scott(2007) 調査ウェイティングの下でのカイ二乗検定のRao-Scott修正について振り返る
永田靖(1998) 多重比較法の実際. 応用統計学, 27(2), 93-108.
多重比較についての教科書の定番、永田・吉田「統計的多重比較法の基礎」(1997)の出版後、そのフォローアップとして書かれた啓蒙論文。実務家からの10個の質問への回答という形で、非常にわかりやすく書かれている。大変勉強になる。
今日twitterで呟いている方がいたおかげで、はじめて知った... いやー、これはもっともっと早く読んでおくべきであった。
読了:永田(1998) 「統計的多重比較法の基礎」をめぐる10個の質疑応答
2014年11月10日 (月)
ふとしたきっかけで、市場調査会社に勤める若い友人から、こんな質問を受けた。細部を剥ぎ取って簡単にいえば、「探索的因子分析で得た因子得点を調べてみたら、varimax回転なのに因子得点は直交してないし、分散が1でもないんですけど...」。アカデミックなトレーニングを全く受けていないのに、この疑問である。弊社の同僚の話は内輪褒めになるからやめるけど、彼女といい、私の前職の調査会社の同僚たちといい、若い人はほんとに優秀で困ってしまう。大変失礼な言い方ですが、わたくし10年くらい前まで、市場調査会社の人ってのは、黒澤明「生きる」の市役所の窓口の人みたいな感じの、肘のところに黒い布巻いて、青焼きにむっつりとペンをいれたり、チャートの軸の目盛のラベルをピンセットで貼ったりしている人たちだと思ってました。実際には違いますよ、最近ではチャートは電子計算機で描きますし、リサーチャーはアクティブかつ優秀ですよ、少なくとも若い人は。
で、彼女には「因子分析モデルが正しければ漸近的にそうなるってことなんじゃない?そいで因子分析モデルなんてたいがい間違ってんだから、大いにずれててもしょうがないんじゃない?」という意味の返事をしたんだけど、本日別件の一仕事を終えてぼんやり夕空を眺めていたら、ふいに、ワタシ嘘ついちゃったんじゃないか、と。。。
DiStefano, C., Zhu, M., Mindrila, D. (2009) Understanding and using factor score: Considerations for the applied researcher. Practical Assessment, Research, & Evaluation. 14(20).
ネットで見つけた論文。掲載誌はよくわからないオープンジャーナルで、ためらったのだけど、第一著者は本当にUSCの助教授らしいし(教育研究)、google scholar様的には被引用度数がかなり多いので、まあ大丈夫だろう、と。
ええと、Psycinfoで探して数えたら、因子得点を使っている2000年代の229件の研究のうち、54%は探索的因子分析(EFA), 19%は確認的因子分析(CFA), 28%は不明だそうである。うーん、EFAが多いんだかそうでもないんだか、よくわかんないな。
著者らいわく、EFAでの因子得点の算出の方法にはnon-refinedとrefinedがある。前者は、負荷の高い項目を選んで生データを平均するとか、そういうローテクなやつ。標本に対して安定的である。後者はいわゆる因子得点で、メジャーな方法として、回帰法、Bartlett法、Anderson-Rubin法がある。どう違うかと申しますと... (これ院生時代に習ったっけ? たぶん習って忘れているのであろう)
ひとつめ、回帰法。発想としては、観察データから因子得点を予測する重回帰式を組む。因子数をm, 変数の数をnとする。ある個体について、標準化した観察ベクトルを$Z$(サイズ$1 \times n$)、回帰係数行列を$B$($n \times m$)として、因子得点は$F = ZB$。さて、この回帰係数行列$B$は、観察変数の相関行列を$R$、因子負荷行列を$A$、因子間相関行列を$\Phi$として、$B = R^{-1} A \Phi$とする。
この手続きは因子得点の推定値の妥当性を最大化することを目的にしていて(つまり、推定された因子得点と真の因子得点との相関を最大化することを目的にしていて)、因子得点の不偏推定にはなっていない。平均は0, 分散はその因子の全項目に対するSMCになる (あ、そうだ!そうでした!)。直交回転であっても因子得点の推定値は因子間で直交しない。
ふたつめ、Bartlett法。発想としては、独自因子を無視し、観察値と因子負荷から共通因子を再現しようとする。因子得点の分散を表す対角行列の逆行列を$U^{-2}$として、$F = Z U^{-2} A (A' U^{-2} A)^{-1}$。むむむ、なぜこうなるんだろう? いずれきちんと勉強しよう。
この手続きは、真の因子得点の不偏推定を提供する。妥当性も、最大ではないけど高い。さらに、直交回転の場合、他の因子の真の因子得点とは相関しないという特徴がある由。ただし、因子得点の推定値が因子間で直交するわけではない(そ、そうだったのか...)。平均は0, 分散はSMC。
みっつめ、Anderson-Rubin法。計算式は省略するけど(ちょっとややこしい)、これはBartlett法を修正したもので、平均は0, 分散は1, 直交回転なら推定された因子得点同士も無相関、という... 実に出来の良い子である。妥当性もそこそこ高いのだそうである。ただし、因子得点は不偏推定にはなっていない。また、直交回転のときに無相関になるのはあくまで推定された得点同士であり、ある因子についての推定された因子得点と他の因子の真の因子得点が無相関になるわけではない。
まとめると、妥当性は回帰法が最大、Bartlettが高、A&Rがそこそこ。直交回転の場合、ある因子の推定された得点が他の因子と無相関になるのはBartlett法、他の因子の推定された得点と無相関になるのはA&R。真の因子得点の不偏推定になっているのはBartlett。
最後に、著者のみなさまからのアドバイス。(1)因子得点は因子抽出手法や回転手法に対して敏感である。まずはEFAが受容できるかどうかを考え、しかる後に使うように。(2)そもそも因子分析ってのは解が不定であるということを肝に銘じるように。このへん、解の不定性の深刻さについて調べる方法について紹介されているのだが、Grice(2001, Psych. Methods)の素人向け簡略紹介らしいので、本家を読むことにしよう。(3)データの質。元データの分布、因子得点の分布をちゃんと見るように。(4)CFAを使え。
というわけで、EFAの因子得点に対するわたくしの理解が浅かったことがあきらかになった(なんとなくA&R法の挙動を前提にしてしまっていた)。仕事に害を及ぼす嘘ではなかったが、彼女に今度会ったら謝らないといけないな... その頃はもう覚えてないかもしれないけど。優秀な人は私と違って忙しいのだ。
読了:DiStefano, Zhu, Mindrila (2009) おまえら因子得点の求め方わかってんのか
2014年11月 6日 (木)
Hox, J.J., de Leeuw, E.D., Brinkhuis, M.J.S. (2010) Analysis models for comparative surveys. Harkness, J.A. et al. (eds.) Survey Methods in Multinational, Multiregional, and Multicultural Contexts. Chapter 21. John Wiley & Sons.
先日買った論文集から。別にいま読まなくてもいいんだけど、高い本を買ったモトを取らねばならぬがゆえに...
多国間調査に関するこの分厚い論文集の、分析のパートの各論のひとつ。著者らはユトレヒト大の人らしい。
冒頭でいわく、多国間比較調査には主に3つの統計的課題がある。その1、測定不変性。その2、ある国においてみられる個人レベルの関係性が他の国でもみられるか。その3、国レベルで安定的な関係性がみられるか。
これらの課題に対する武器は、まずは多群SEMである(IRTを含む)。でも国数が多くなると大変。次の武器は、国の効果を固定効果から変量効果に変えちまうこと、すなわちマルチレベル化である。20ヶ国もあれば国レベルでもモデリングが可能になる(←シミュレーション研究をやった由。Maas & Hox, 2005)。さらに最近では潜在クラスモデル(LCM)という手もある。
というわけで、本章では多群SEM, MSEM(マルチレベルSEM), LCMを紹介し比較します。
まずはSEMの説明。パス図で丸は潜在変数だよ、なんてところからはじめて、2頁で駆け足のSEM入門。いったい想定読者は誰なんだ。
で、多群SEMにおけるfunctional(factorial)/metric/scalar equivalenceの説明。残念ながら用語が統一されていないんだよね、云々。
次、MSEMの説明。一番ポピュラーなのは単変量の階層回帰で... これをMSEMに拡張できて... 云々。パス図はMuthen一派風に、レベルを点線で分け、下のレベルのランダム係数は黒丸、という描き方をしている。
次、LCMの説明。まず局所独立性とかの駆け足説明があって... 著者らがいわんとしているLCMとは、要するに因子負荷が潜在クラスによって異なるようなCFAのことで、著者らも途中でそう呼んでいるけど、潜在クラスSEMって呼ぶほうがわかりやすいかも。
簡単なシミュレーションの紹介。データ生成モデルを4指標1因子CFAとし、ある指標の負荷を半分の国でこっそり変えたり変えなかったりする。MVNな誤差を乗せて、国あたりn=1500, 国の数を20, 30, 40と動かす。metric equivalentな1因子CFAを推定したとき、パラメータ推定はどうなるか。
結果。データ生成モデルがmetric equivalentだったら、多群SEM, マルチレベルSEM, 1クラスLCAのいずれもうまくいく。ただし、国数が20だとMSEMでSEが過大評価される(悲観的な方向にバイアスがかかる)。いっぽう、データが実はmetric equivalentでなかったら、それに気づくのは難しい。多群SEMのみカイ二乗検定で引っかかるけど(サンプルサイズがでかいからさ、と無視されるでしょうね、普通)、適合度は下がんない。みなさい、大域的適合度を過信してはいかんですよ、とのこと。まぁね、そうかもね。でもこの実験だと、ひとつの指標の負荷だけが+0.5から+0.3にすり替えられているだけだから、まあしょうがないかな...
実データへの適用例。ESS(European Social Survey)、22ヶ国のデータ、約4万人。「宗教への関与」4項目を使う(11件法と7件法が混在)。先行研究では、部分測定不変な1因子モデルがあてはまるといわれている由。3つの方法それぞれで試す。面倒になってきたし、なにより眠いもので適当に読み飛ばした。まあそれぞれ長短あるよね、という話である。
最後にソフトウェア。Mplus最強!GLLAMM最強!との仰せでありました。GLLAMMってのはStataのパッケージ。
どのレベルの読者を想定しているのかよくわからない文章だったのだが、まぁ、後半の実データ分析例は、自分で分析してて困ったときに心の支えになるかも。ならないかも。
最後にちらっと触れられているけど、たとえばLCMをマルチレベル化したっていいわけで、SEMの枠組みでの多国間調査データ分析には、他にももっといろんな可能性があると思う。
読了:Hox, de Leeuw, Brinkhuis (2010) 国と国とを比較する方法を比較しよう (多群SEM vs. マルチレベルSEM vs. 潜在クラスモデル)
2014年10月31日 (金)
Braun, M., Johnson, T.P. (2010) An illustrative review of techniques for detecting inequivalences. Harkness, J.A. et al. (eds.) Survey Methods in Multinational, Multiregional, and Multicultural Contexts. Chapter 20. John Wiley & Sons.
仕事の都合でざっと目を通した。
この本は2008年にベルリンで開かれたInternational Conference on Survey Methods in Multinational, Multiregional, and Multicultural Contexts (3MC)というカンファレンスの論文集。この会議自体はAAPORとかASAとかの協賛で開かれたものだが、調べてみたら、現在はブリュッセルのComparative Survey Design and Implementation (CSDI) という組織が毎年ワークショップを開いており(来年は5月にロンドン)、2016年には第二回の3MCカンファレンスをシカゴで開くらしい。
この章は分析のパートの総論に相当していて、このあとに各論として、多群多レベルのSEMやLCAについての章、多項IRTでDIFを調べるという章、MMTM行列でなにかをどうにかしますという章(うぉう、LCA関連で名前をよく見るHagenaarsさんだ)、定量と定性をあわせてなにかをどうにかするという章が続く。
多国間調査のデータを国のあいだで比較できるか? それを調べる手法を片っ端から紹介する。例に使うデータはISSP国際比較調査のジェンダー役割の項目(4項目)と、ベンチマークに使うジェンダーイデオロギーの項目(1項目)。西ドイツ、US, カナダを比較する。
紹介する手法は...
- 回答カテゴリ(無回答を含む)への回答分布を比較する。
- 平均を比較する。
- ベンチマーク項目との相関を比較する。
- 説明変数との相関を比較する。例に挙げているのは年齢との相関。
- 交互作用プロット。具体的には、国を層、年代を横軸、回答の平均を縦軸、項目を線にした折れ線グラフ。
- 探索的因子分析。バリマクス回転後の第一因子負荷を比べている。
- 信頼性。アルファなんかを比べる。
- 多重コレスポンデンス分析 (MCA)。なにやんのかと思ったら、4項目の回答カテゴリ(5件法だから計20個)の布置を国別に描いて見比べるのである。定性的だねえ...
- 多次元尺度構成法 (MDS)。やはり布置を国別に見比べるのであろう。
- 多群CFA (やれやれ、やっとそれらしい話題になってきたぞ)。怪しい項目を外して適合度の変化を見たりしている。
- マルチレベルモデル。いきなり3pにわたって説明が繰り広げられている。著者らオススメ?の手続きについてメモしておくと... まずは従属変数だけで単純な分散成分モデルを組み、国内の分散と国間の分散を比べる。次に、個人レベルの説明変数を投入。最後に、国レベルの説明変数を投入。ここまでをランダム切片モデルでやる。ランダム傾きを導入するのはさらにその後だ、とのこと。うーん、仰りたいことはわかるけど、建前としては、モデル構築の順序は文化差についての実質的知識で決まる問題じゃないかしらん。
- 項目反応モデル。1パラメータIRTと2パラメータIRTのICCを国ごとに示している。単に見比べるだけ。通常の概説では2パラメータのモデルだけ紹介されることが多いと思うが、ここでは対等に扱われている。ヨーロッパの人はラッシュモデルが好きだと聞いたことがあるのだけど、ほんとかもしれない(第一著者の所属はドイツ)。
最後に星取表。表頭に{分布・平均・相関、EFA, 信頼性, MCAとMDS、多群CFA、マルチレベル, IRT}の7つをとり、表側に{クイックに概観できるか、国の数が多くても大丈夫か、個人を同定するか、国を通じた要約が出るか、項目レベルかテストレベルか}をとって表をつくっている。まあだいたい想像がつく内容なので省略。
途中でだんだん関心を失くして適当に目を通してしまった。まあいいや、次に行こう。
読了:Braun & Johnson (2010) 多国間調査のデータを国と国の間で比較できるかどうかを調べる方法を総ざらえ
Ram, N., Brose, A., Molenaar, P.C.M. (2013) Dynamic factor analysis: Modeling person-specific process. in Little, T.D. (ed.) The Oxford Handbook of Quantitative Methods in Psychology: Vol. 2: Statistical Analysis. Chapter 21. Oxford Univ. Press.
動的因子分析の解説。なんだか億劫で読んでいなかったのだが(第三著者の名前のせい。この先生の文章って難しいのだ)、整理の都合もあるので目を通した。
背景。
単一のヒトのオケージョンx変数行列を分析する方法としてはキャッテルのP-technique因子分析があった。その後、データの時間依存性を正面からモデル化する時系列手法が出てきた(Box-Jenkinsとか)。この2つを合わせたのがワシMolenaarの動的因子分析(DFA)じゃ。DFA的なモデルは状態空間モデルの枠組みで広く用いられておる。
えーと、個人レベルの行動の背後にある適応過程や制御過程に注目する、person-specificアプローチというのがあって(Nesselroadeという人の研究がいくつか挙げられている。発達研究かな)、ワシMolenaarはエルゴード定理の観点からその重要性をあきらかにしたのじゃ。云々。
技術的背景。
$p$変量の観察時系列を $y(t)$とする$(t = 1,2, \ldots, T)$。P-technique因子分析モデルは
$y(t) = \Lambda \eta(t) + \epsilon(t)$
ここで観察は時点間で独立だと仮定されている (←そうなのか、キャッテルは$\eta(t)$の時系列構造を考えたわけじゃなかったのか...)。
MolenaarのDFAだと、さらにこう考える:
$\eta(t) = B_1 \eta(t-1) + B_2 \eta(t-2) + \cdots + B_s \eta(t-s) + \zeta(t)$
潜在因子に自己回帰とクロス回帰を組むわけだ。これを$y(t)$の式に代入して
$y(t) = \Lambda [\zeta(t) + B_1 \eta(t-1) + \cdots + B_s \eta(t-s)] + \epsilon(t)$
一般化して
$y(t) = \Lambda_0 \eta(t) + \Lambda_1 \eta(t-1) + \cdots + \Lambda_s \eta(t-s) + \eta(t)$
そうか、$\eta(t)$に時系列構造を与えようが、$y(t)$にラグつき因子負荷を与えようが、結局は同じことか...
もっとも著者ら曰く、同じDFAであっても、configurationsのちがい、モデルが示唆する過程の本質のちがいによって、数多くの差が出てくる、とのこと。
DFAを行う5つのステップ。
ステップ1. リサーチ・クエスチョンを立てる。たとえば(←ということだと思うんだけど)、DFAは個人の安定性維持過程を調べるのに向いている。モデルのパラメータは均衡からの/への移動の定量化であるとみなすことができる(キャリーオーバーとかスピルオーバーとかバッファリングとか)。
ステップ2. 研究デザインとデータ収集。十分な長さのデータを、現象に照らして適切なタイム・スケールで、等間隔に採るべし。少なくとも100時点、パラメータあたり5時点はほしい。さらに、個人内の変動をちゃんと捉えていないと困る。
ステップ3. 変数選択とデータの前処理。SDが0.1を切る変数を抜くとか、8割がた同じ値である変数を抜くとか。問題は抜くべき変数が人によって違っていたときで、人ごとに抜くべき変数を抜く(人によって変数セットが変わってきちゃうけど)、抜くべき変数が多い人を丸ごと抜く、人も変数も抜いてどうにか綺麗に揃える、といった手がある。前処理の目標は弱定常性を確保すること(←おおっと...)。回帰で循環成分を抜くとかなんとか、手法はいっぱいある(Shumway & Stofferの教科書を読めとのこと)。
ステップ4. フィッティング。SEMのソフトでML推定する路線、カルマンフィルタを使う路線、ベイジアン路線、OLS路線など。
ステップ5. 個人差の検討。SEMの多群モデルで、2人のひとのパラメータが同じかどうか調べるとか、なんとか。
今後の課題。
その1、非定常性の問題。ここ、私にとっては深刻な話なのでメモすると...
発達研究ではintra-individual changeとintra-individual variabilityを区別する。従来、前者は成長曲線とかで、後者は弱定常性の仮定の下での動的過程として捉えられてきた。しかし残念ながら人間というシステムは定常でない。よってDFAのような定常モデル(←???)には限界があり、非定常性へと拡張しなければならない。
Kim & Nelson(1999, 書籍)は多レジーム状態空間モデルを示している。カテゴリカルなスイッチング変数 $S(t)$を考えて
$y (t) = \Lambda_{S(t)} \eta(t) + \epsilon(t)$
$\eta(t) = B_{1 S(t)} \eta(t-1) + \zeta(t)$
完全な時変パラメータに拡張することもできる。Molenaar et al.(2009, Dev.Psy.), Molenar & Ram(2009, 論文集)はカルマン・フィルタを使って
$y (t) = \Lambda(t) \eta(t) + \epsilon(t)$
$\eta(t) = B_1(t) \eta(t-1) + \zeta(t)$
ほかに状態空間モデルで循環成分を組み込んだ研究もある。云々。
著者らいわく「要約すると、非定常性は人間の機能の現実なのだからそれに取り組まねばならない。それが可能なモデルが利用可能だし、人間のデータに対して今や利用されつつある。このトレンドが続くなら - 語呂合わせになっちゃいましたが [mind the pun] -現実の生活を特徴づける複雑な変化を記述し予測する我々の能力は、ますます拡張するであろう」とのこと。
その2、適応のためのガイドの提供。モデルによって個人に対する適切な介入ができるようになるかも。
その3、個性記述フィルタ。指標のモデルは人によって違うけど背後のプロセスは人を問わず同じ、というようなモデルが組めるかも。云々。
よくわからなかった点:
著者らの発想では、DFAとはもともと弱定常性を持つ多変量時系列のための手法なんだけど、ここで弱定常性が要請されているのはなぜだろうか。私はあきらかに平均非定常な多変量時系列に関心があるので(消費者指標やマーケット指標のことを考えているから)、これは切実な疑問だ。
著者らの観点からは、弱定常性はそれがintra-individual variablityのモデルだという実質的解釈から要請されていたのであって、DFAモデルそのものからの要請ではないような気がする。DFAモデルのパラメータ推定という観点からは、まあ撹乱項の共分散は時間独立でないと困るけど、観察変数なり状態変数なりの期待値が時間独立であることは、最初からどうでもいいんじゃないですかね... だから、「DFAモデルは定常モデルだ、多レジームモデルや時変パラメータなどへの拡張が必要だ」というのは、言い方として正確なのかしらん、と... うううむ...
読了:Ram, Brose, Molenaar (2013) 動的因子分析による個人の心的過程のモデル化
2014年10月24日 (金)
Holmes, E.E., Ward, E.J., Scheuerell, M.D. (2014) Analysis of multivariate time-series using the MARSS package. version 3.9. Northwest Fisheries Science Center, Seattle, WA.
RのMARSSパッケージのユーザーズ・ガイドに相当する文書で、3部構成、全16章、200頁以上に及ぶ。MARSSパッケージとは要するに、多変量時系列の背後に少数の自己回帰系列を考える状態空間モデルのソフトで、いわゆる動的回帰やベクトル自己回帰を扱うことができる。パラメータ推定を著者らが提案している一種のEMアルゴリズムで行うのが特色。
第一部。
1章はイントロ。えーっと、MARSSのモデルは下記の通り。
状態方程式: $x_t = B_t x_{t-1} + u_t + C_t c_t + w_t$
状態方程式の撹乱項: $w_t \sim MVN(0, Q_t)$
観察方程式: $y_t = Z_t x_t + a_t + D_t d_t + v_t$
観察方程式の撹乱項: $v_t \sim MVN(0, R_t)$
初期状態: $x_1 \sim MVN(\pi, \Lambda)$ ないし $x_0 \sim MVN(\pi, \Lambda)$
時系列の長さを$T$, 状態変数を$m$本, 観察変数を$n$本とする。$c_t$, $d_t$は外生変数で、それぞれ$p$本、$q$本。観察変数$y_t$には欠損を許すが外生変数$c_t$, $d_t$には許さない。
章末に他のソフトの紹介が載っている。著者ら曰く、MARSSパッケージは速度を最適化してない、特に時点数が多いときには堪忍な、とのこと。
2章、関数紹介。主役はMARSS()関数である。3章は著者らが開発したEMアルゴリズムの説明(パス!)。
第二部。
4章がたぶんいちばん大事な章で、MARSS()に対するデータとモデルの渡し方。このパッケージの特徴として、渡すものはすべてユーザの責任で正しくつくらないといけない。
えーっと... データはn行T列の横長な行列で渡す。モデルは、dlmパッケージのdlmMod*()やKFASパッケージのSSM*()のようなヘルパー関数はなくて、自分でシステム行列を書きまくりリストにして渡す必要がある。モデルの要素は行列なのだが、なかに数値と文字列を混在させたいので、list()をmatrix()で並べるのが望ましい。つまり、たとえばmatrix(list(1, "a", "b"), 3, 1)ってな風に書けってことである。
MARSS()に渡すモデルにいれられる要素は以下の通り。初期状態 x0, V0を除き、すべて時間変動可能であって、そのときはarray()で渡すのだが(5.3節)、ややこしいので省略。ここでは時間不変の場合についてメモする。
- U: 状態に乗せる傾き$u_t$。m行1列の行列で渡す。たとえばU=matrix(list(0.01, "u1", "u2"), 3, 1)とすると、$x_t$の一本目には毎時点で0.01が, 二本目には毎時点で定数u1が、三本目には毎時点で定数u2が加算されることになる。ほかに、U="unequal", U="equal", U="zero"というショートカット表現がある。デフォルトはU="unequal"。
- A: 観察に乗せる傾き$a_t$。Uと同様に指定。さらに、A="scaling"というショートカットがある。こうすると、$a_t$の要素は通常は0となり、同一の状態変数に対して係数を持つ観察変数が複数個存在するときに限り、2本目以降の観察変数での要素が定数a1, a2, ... になる。デフォルトはA="scaling"。
- x0: 初期状態の平均$\pi$。Uと同様に指定。面白いことに、ここに変数名をつけてパラメータ扱いすることができるのである(つまり、初期状態の事前分布次第で結果が変わってきちゃうよね、という議論を回避できるわけだ)。デフォルトはよくわかんないんだけど(4.5節にはx0じゃなくてpiって書いてある...)、たぶんx0="unequal"だと思う。
- Q: 状態撹乱項の分散行列$Q_t$。m行m列の行列を渡す。気をつけないといけないのは、Q=diag(c("sa", "sa", "sb"))というような書き方をしてはいけないということ。Q=matrix(list(0), 3, 3)とやって、あとでdiag(Q)=c("sa", "sa", "sb")とするのはオッケー。ショートカットは"diagonal and equal", "diagonal and unequal", "unconstrained", "equalvarconv", "identity", "zero"。デフォルトは"diagonal and unequal"。
- R: 観察撹乱項の分散行列$R_t$。Qと同様。
- V0: 初期状態の分散行列$\Lambda$。Qと同様。V0の指定には細心の注意を払え、さもないと破壊的結果を招くぞ、とのこと。デフォルトは"zero", これは未知を表す由(えええ... それは教えてくれないとわかんないね...)
- B: 状態遷移行列$B$。Qと同様。数値をいれる場合、すべての固有値の絶対値が1以下になるようにしとかないといけない。デフォルトは"identity"。
- Z: 観察方程式における状態変数への係数行列$Z$。要するにこれはn行m列の行列で、頑張って作るしかないのだが、以下の場合は手が抜ける。(1)状態変数の数$m$と観察変数の数$n$が同じ場合。Qと同様の書式が使える。(2)$Z$はデザイン行列だという場合(つまり、要素は0か1で縦に合計すると必ず1だという場合)。このときは、factor()を使って謎めいた指定ができるのだが、さっぱり理解できないので省略。
- C, c, D, d: 4章には記載がないが、まあ使う段になればどうにかなるだろう。
- tinitx: 初期状態をt=0とするかt=1とするか。デフォルトはtinitx=1。
5章は、簡単なコード例(5.1節)、状態変数の数が観察変数の数と異なるコード例(5.2節)、時間変動パラメータのコード例(5.3節)、共変量$C, c, D, d$についての短い説明(5.4節)、結果のみかた(5.5節)、信頼区間の求め方(5.6節)、推定結果の取り出し方(5.7-5.9節)、パラメータのブートストラップ推定(5.10節)、初期状態をランダムに与えてモンテカルロ法で初期化する方法(5.11節)、シミュレーション用のデータ作成(5.12節)、ブートストラップAIC(5.13節)、収束条件について(5.14節)。
第三部。ここからは事例紹介の連続爆撃である。どの例も生態学(?)の話なので、ちょっと覚悟が必要だ。ざっとめくって、タイトルをメモしておくと、
- 6章: curruptedデータを使ったcountベースのpopulation viability分析。最初からナンノコッチャという感じだが、なにかの生き物の個体数を毎年数えているようなデータがあって、絶滅しないかどうか調べる、というような話らしい。モデルをみたら、単変量のローカル線形トレンドモデルで傾きが定数の奴だった。ちゃんと読んだらすごく勉強になりそう。読まないけど。
- 7章: 複数のsiteのデータを結合し、地域の個体数トレンドを推定する(populationの訳ってここでは個体数でいいのかしらん?)。観察変数は5本。状態変数はひとつからはじめて、だんだん複雑にしていく。これも面白そう... 読まないけど。
- 8章: 空間のpopulation structureと共分散を同定する。なにいってんだかわかんないけど、地域別にアザラシの個体数の時系列があって、地域がどう固まっているか、というようなことを調べたいらしい。これはめんどくさそうだ。ぜったい読まない。
- 9章: 動的因子分析(DFA)。正直なところこれが目当てで読み始めたのだが、きちんと読むには時間がかかるので(ここだけで18頁ある)、先に全体のメモを取っている次第である。
- 10章: ノイズの多い動物トラッキングデータの分析。えーっと、ビッグ・ママという愛称のウミガメの位置の時系列の分析らしい(観察変数は2本、状態変数も2本)。あー、そりゃ面白いな、ランダム・ウォークというか、ランダム・スイミングというか。読まないけどさ。
- 11章: 外れ値と構造的ブレークの検出。データはご存知ナイル川データ。これは仕事とも関係するので、こんどきちんと読もう。
- 12章: 共変量のとりこみ。季節効果の推定もこの枠組みで扱うわけで、いかん、ここは読まざるをえない...
- 13章: 種の相互作用の強さの推定。オオカミとヘラジカの個体数の時系列を分析する。ああそうか、多変量自己回帰(MAR)で扱えるわけだ、なるほどねー。こういうの、いつか仕事で使えるような気がするが、とりあえず後回し。
- 14章: 複数の時系列の統合。よくわかんないんだけど、ある種の個体数を陸から数えた時系列と空から数えた時系列があって...というような話らしい。一因子のDFAみたいなもんだろか。
- 15章: 単変量動的回帰モデル(DLM)。係数が時間変動する話なんでしょうね、読んでないけど。
- 16章: MARSSによるラグ-pモデル。AR(2)とかMAR(2)とかをどう扱うかという話らしい。
というわけで、これからどの章をきちんと読まねばならんか見当がついたので、とりあえず良しとしよう。疲れたし。
読了:Holmes, Ward, & Scheuerell (2014) MARSSパッケージで多変量時系列分析
ここんところの状態空間モデル祭りで目を通した論文から... 著者PetrisさんはRのdlmパッケージの作者で、著書の邦訳も出ている。
Petris, G., Petrone, S. (2011) State Space Models in R. Journal of Statistical Software. 41(4).
状態空間モデル用ソフトウェア特集号の記事のひとつ。この特集号の縛りで、前半はNileデータというデータセットの分析例。ご自身のdlmパッケージと、そのあとに出たKFASパッケージでの分析例を紹介しているのだけれど、KFASの仕様はその後大きく変わったようで、現時点ではあまり役に立たない。
後半では、まずdlmのウリであるベイズ流の推測について紹介。この辺、全然知らん話なのでちょっとメモしておくと...
観察データ$y_{1:n}$の下で、パラメータのベクトル$\psi$と状態系列$\alpha_{0:n}$の事後分布$\pi (\psi, \alpha_{0:n} | y_{1:n})$をベイズ推論したいわけだけど、ここで難しいのは、MCMCが事前分布やモデルにspecificになってしまい、一般的なアルゴリズムを組めない、という点。
ローカルレベルモデルのコード例を紹介。パラメータは不規則撹乱項の分散$\sigma^2_\epsilon$とレベル撹乱項の分散$\sigma^2_\xi$である。それぞれ事前分布は逆ガンマ分布と考え、dlmGibbsDIG()という関数で同時事後分布$\pi(\sigma^2_\epsilon, \sigma^2_\xi, \alpha_{0:n} | y_{1:n})$をGibbsサンプリングする。ただし、速度は遅く、主として教育用である由。
いっぽう、データとパラメータの下での状態の条件つき分布 $\pi (\alpha_{0:n} | \psi, y_{1:n})$からサンプリングするGibbsサンプラーなら一般的な形で作れる。やり方は2つあって、ひとつはForward-Filtering Backward-Sampling (FFBS)アルゴリズムというやり方、もう一つはsimulation smootherってやつ(Durbin&Koopman本に出てくる奴だ... たぶん一生理解できないだろう)。dlmパッケージはdlmBSample()という関数で前者を提供している由。なんだかわからんが、へーそうですか。
なお、オンラインでフィルタ化・予測するのに時点ごとにMCMCをやるのは現実的でない。これもいろいろやり方があるのだそうで、ひとつには、共役事前分布を使いさらにいくつか制約を受け入れれば、閉形式で解ける由。これをdiscount factors法というのだそうだ。dlmパッケージには入っていないが、別途ツールを配っている、とのこと。
最後に、介入変数を投入する例、モデルの合成の例、多変量時系列の例(KFAS)。
Petris, G. (2010) An R Package for Dynamic Linear Models. Journal of Statistical Software. 36(12).
上記論文の前年の、dlmパッケージについての紹介。ざざーっとめくっただけだけど、読了にしておく。コレスキー分解とかヘシアン行列とかいわれると、もう目が文字を受け付けなくなってしまうのですよ... なんだか洋菓子の名前みたいだなあ、お腹すいたなあ、なんて...
なお、動的線形モデルに関連するその他のパッケージとして挙げられていたのは、statパッケージのStructTS()、KalmanLike()とその仲間たち。dseパッケージ(多変量ARMAモデルなんかを扱うらしい。時間不変なモデルならおススメ、とのこと)。sspirパッケージ(調べてみたらCRANから消えていた)。
読了: Petris & Petrone (2011), Petris (2010) dlmパッケージとそのライバルたち
2014年9月23日 (火)
Commandeur, J.J.F., Koopman, S.J., Ooms, M. (2011) Statistical Software for State Space Methods. Journal of Statistical Software, 41(1).
JSSのこの号は状態空間モデル特集号だったようで、その巻頭論文。著者があのコマンダー&クープマンであることに気づき(翻訳書が出ている)、いちおう目を通そうかと...。
仕事の役には立たないけれど、歴史の話って、ちょっと面白いんですよね。ええと、状態空間モデルはもともと制御工学に由来しており、その発想は1960年のカルマンの論文までさかのぼり、1969年のアポロ11号の月着陸の際にも役に立ったそうです。いっぽう、時系列分析一般に広く適用されるようになったのは1980年代になってから、とのこと(ちなみにBox-Jenkinsモデルは1976年)。古いんだか新しいんだか。
2節は状態空間モデルの一般的解説。せっかくご説明いただいているので、ちょっとメモをとっておくと... まず、線形ガウシアンの状態空間モデルを一般的形式で示す。それから以下の特殊ケースを紹介: ローカルレベルモデル, ローカル線形トレンドモデル, 季節ダミー要素の導入, 周期性要素の導入。で、説明変数・媒介変数の導入。構造的アプローチへの展開 (いろんな観察不能要素についてそれぞれの説明モデルを組んで合体させる)。多変量時系列への展開(SURモデルとか)。いやー、教科書何章分もの内容を一気に説明されても...
3節は推定の話。前向きパス(カルマンフィルタ)と後ろ向きパス(状態平滑化と攪乱項平滑化)、とかなんとか... 4節はARIMA要素モデル。5節は非ガウシアン。すいません、後日きちんと勉強しますので、今日のところはお見逃しください。
で、ようやく本題。状態空間モデルのためのソフトウェアの星取り表。多変量モデル(MM)、正確な初期化(exact initialization, EI), 多変量時系列の単変量的扱い(UTMTS)、非線形非ガウシアンモデル(NLNGM)について扱えるかどうかを、以下の14のソフトについて整理。名前を聞いたこともないのもあって、へー、という感じ。全部メモしておくと(一部リンク付き):
- Eviews ... MM
- gretl ... MM, UTMTS (※全然知らなかったんだけど、GPLライセンスのソフトで、windows版もある。試しにダウンロードして動かしてみたら、なんとメニューが日本語化されていた。日本語の参考書さえある模様。いやー、世の中知らないことばかりだ...)
- MATLAB ... MM, EI, NLNGM
- R base ... どれもできない
- R + dlm ... MM
- R + KAFS ... 全部できる
- RATS ... MM, EI
- REGCMPNT ... EI (※Reg Componentsと読むらしい。ついレグ・シーエム・パンツって読んじゃった)
- SAS ... MM, EI (※えー? プロシジャはなによ? と思ったら、SAS/ETSを使うか、SAS/IMLで自分で組め、という話らしい)
- S-PLUS ... 全部できる
- SsfPack Basic ... MM, NLNGM
- SsfPack Extended ... 全部できる
- STAMP ... MM, EI, UTMTS
- Stata ... MM, EI, UTMTS
で、本特集号の各論文の構成。各論文はそれぞれに特定のソフトを解説しているのだが、著者らにそれぞれのソフトで同一のデータを分析してもらったそうだ。へー。
読了:Commandeur, Koopman, & Ooms (2011) 状態空間モデルのためのソフトウェア
2014年9月17日 (水)
Gilbert, P.D. & Meijer, E. (2005) Time series factor analysis with and application to measuring money. Research Report, University of Groningen.
Rの tsfa パッケージの基になっている論文。通常の動的因子分析(dynamic factor analysis, DFA)を改訂した時系列因子分析(time series factor analysis, TSFA)を提案する。
DFAという用語も結構あいまいに使われているので、ここで著者らがなにを想定しているのか、はっきりしないのだが... たぶん、因子負荷にはラグがなく因子得点に時系列構造があるようなモデル(先日読んだZhang, Hamaker, & Nesselroad(2008)いうところのdirect autoregressive factor score model)が念頭にあるのではないかと思う。
著者らいわく、ふつうのDFAは因子の時系列構造の指定に過度に依存する。いっぽう提案手法は最小限の想定しか置かない。
時点数を$T$, 因子数を$k$, 指標数を$M$とする。時点$t$における因子得点ベクトルを$\xi_t$, 指標の値のベクトルを$y_t$とする。提案モデルのうち測定モデルは
$y_t = \alpha_t + B \xi_t + \varepsilon_t$
なお、ある時点における$\xi_t$と$\varepsilon_t$は独立で、$\xi_t$は平均0, 共分散$\Gamma$, $\varepsilon_t$は平均0, 共分散$\Psi$とする。切片ベクトル$\alpha_t$さえ変動する点に注意。なんというか、ゆるゆるのモデルで、これでは推定できない。
差分オペレータ$D$を導入する。たとえば$Dy_t := y_t - y_{t-1}$である。$Dy_t$を分解して
$Dy_t = D\alpha_t + BD\xi_t + D\varepsilon_t$
で、以下の仮定を置く。略記するけど、$\lim$と書いているのはほんとはすべてplimで、下添え字は$T→\inf$。
- $D\alpha_t = \tau$。つまり、切片の差分は定数。
- $K := \lim \sum_t D\xi_t / T$が存在し有限である。
- $\lim \sum_t D\varepsilon_t / T = 0$。
- $\Phi := \lim \sum_t (D\xi_t - \kappa)(D\xi_t - \kappa)' / T$ が存在し有限かつ正定。
- $\Omega := \lim \sum_t D\varepsilon_t D\varepsilon'_t / T$ が存在し有限かつ正定。
- $\lim \sum_t (D\xi_t - \kappa) D\varepsilon'_t / T = 0$。
あ"あ"あ"あ"あ" (藤原竜也風の叫び)。時系列モデルに疎い私はもう頭が真っ白だが、著者らいわく、因子得点の差分 $D\xi_t$と 誤差の差分$D\varepsilon_t$が単位根を持たないことを求めているほかには、実質的にはほとんどなにも仮定していない、のだそうである。そうなんすか。
識別のためにもう少し制約を追加しないといけないようだが($\Omega$を対角行列とするとか)、まあとにかく、このモデルをどうにかして推定できちゃうそうである。因子得点も推定できるんだそうである。細かい説明は全然理解できないのだが、まあ、いいや。
後半は数値例。まず人工データへの適用例が載っているけど、パス。
実データへの適用例。著者らはカナダ銀行の人なので(論文が難しいわけだ)、そっち方面の話である。辞書を引き引き読んだ。
ええとですね。現在のmonetary aggregates(マネーサプライ。取引に用いられるカネがどの程度出回っているか)にはいろいろ問題がある。TSFAをつかい、これをpopulationにおけるfinancial assets(金融資産)の変化を説明する潜在変数に置き換えたい。
以下の6個のカテゴリの指標を使う: currency(通貨), personal chequing deposits(個人小切手預金), non-bank chequing deposits (ノンバンク小切手預金... なんのことだ一体?)、non-personal demand and notice deposits(非個人の要求払い預金と通知預金... 会社の普通預金のことかなあ)、non-personal term deposits (非個人の定期預金)、そしてinvestment (投資... ってどういうこと? 投資信託とか?)。1986年からの215ヶ月のデータ。なお、ここではいっさい季節調整しないが、してもよい、とのこと。
まず、差分指標の標本相関行列の固有値を見る(ちょちょちょっと待って, 6本のDy_t 時系列の相関行列ってことよね?)。順に2.08, 1.39, 0.85, 0.69, 0.65, 0.33。伝統に従い、固有値1で切って2因子としよう。直接オブリミン回転で解釈する。
云々。途中で嫌になったのでパス。
というわけで、ほとんど読んでないけど、読了にしておく。
要するに、差分データについて極力素直に因子分析するわけね。そういうモデルであったか。思ってたのと全然ちがったので、めくっておいてよかった。たぶん、比較的に本数が少なく、共分散が定常かどうかわからず、因子の時系列構造がさっぱりわからんような多変量時系列に向いている手法なのだと思う。
読了:Gilbert & Meijer (2005) 時系列因子分析TSFA
2014年9月16日 (火)
Brodensen, K.H., Gallusser, F., Koehler, J., Remy, N., Scott, S.L. (2014) Inferring Causal Impact Using Bayesian Structual Time-Series Models. Technical Report, Google.
先日Googleの人がリリースした、RのCausalImpactパッケージの基になっている論文。どこかに投稿中である由。
本当はパッケージをいじりながら慣れていけばいいんだろうけれど、どうしてもそういう勉強のしかたができなくて... こういうフォーマルな文章を先に読んでおかないと、落ち着かないのである。効率が悪いなあ、とため息。
えーっと、いまをときめくデータサイエンティスト(っておっしゃるんですかね)の皆様にではなく、私のような哀れな文系ユーザ向けに、このパッケージが持つ意味をどう説明するか ... と考えながら読んでいたのだが、要するにこういうことだと思う。
いま、あるブランドのためのなにかのマーケティング・アクションが行われたとしましょう。広告とか販促とか。で、なにか結果指標があるとしましょう。売上とかイメージとか。アクションの効果を推定するためにはどうするか。
一番簡単なのは、そのアクションが行われる前と後との間で、結果指標の変化を調べることである。話を簡単にするために、売上の差を調べる、ということにしましょう。
たちまち、次のような批判が生じる。アクションの前より後で売上が高くなったとして、それは季節のせいではないのか? アベノミクスのせいではないのか? そのほか、当該のアクションとは無関係なさまざまな要因のせいではないのか?
こういう批判にこたえるためには、「季節やらアベノミクスやらその他すべての要因において共通しているが、当該のアクションはなされていない」なんらかの比較対象が必要である。たとえば、競合ブランドの売上データだったり、当該ブランドの前年の売上データだったり、当該の広告を出稿していない地域における当該ブランドの売上データだったり。これをコントロールと呼ぶことにする。で、先ほど求めた前-後の売上の差と、コントロールにおける前-後の売上の差とを比べる。いわゆる「差の差を調べる」手法である。
問題は、都合の良いコントロールはなかなか手に入らないという点である。競合さんだって頑張っている。去年の僕らだって頑張った。広告を出稿しなかった地域があったら、それにはそれなりの事情がある。「差の差」が当該アクションの効果だけを表しているとは限らない。
...とお嘆きの皆様に対し、この論文はつぎのように提案する。よろしい、アクションの効果を推定してご覧にいれましょう。大丈夫、コントロールなんて要りません。ただし、「アクションの前の値」と「アクションの後の値」だけではだめ。長めの時系列データをください。特に、「アクションの前」についてはぜひ長めの時系列を。そして、あなたのブランドの結果指標(売上とか)に影響するであろう変数のデータを、片っ端から用意してください。
えーと、提案モデルは以下の通り。いやー、時系列構造モデルだなんて、生まれながらの文系である私がなんでこんな目に...
大枠として、以下の状態空間モデルを考える。
観察方程式: $y_t = Z^T_t \alpha_t + \epsilon_t$
状態方程式: $\alpha_{t+1}= T_t \alpha_t + R_t \eta_t$
観察値$y_t$はスカラー(ありがたいことに)。$Z_t$は長さ$d$の係数ベクトル。$\alpha_t$が長さ$d$の状態ベクトル。誤差項$\epsilon_t$は$N(0, \sigma^2_t)$に従う。
状態方程式のほうは、$T_t $が$d$行$d$列のブロック対角な遷移行列。$R_t$は$d$行$q$列のブロック対角な係数行列、$\eta_t$は長さ$q$のシステムエラーで(季節性とかね)、その拡散行列を$Q_t$とする (ブロック対角)。
この状態ベクトル$\alpha_t$にいろんな要素を突っ込んでいく。
ひとつめ、トレンド$\mu_t$。傾き$D$のAR(1) として、
$\mu_{t+1} = \mu_t + \delta_t + \eta_{\mu, t}$
$\delta{t+1} = D + \rho(\delta_t - D) + \eta_{\delta, t}$
ふたつめ、季節性。季節の数を$S$として、
$\gamma_{t+1} = - \sum_{s=0}^{S-2}\gamma_{t-s} + \eta_{\gamma, t}$
こういう季節性の表現を見るといつも泣きたくなるんだけど、著者様は素人向けに易しくかきなおしてくださっていて、たとえば春から順に1,2,3,4だとすると、$\gamma_{冬} = -1 * (\gamma_{秋}+\gamma_{夏}+\gamma_{春}) + (誤差項)$ だから、これでつじつまが合っているわけです。
みっつめ、係数が時間変動しない共変量ベクトル$x_t$の効果。これは、$\alpha_t$のほうに 値 1 の要素を突っ込んでおいて、$Z_t$のほうに$\beta^T x_t$を突っ込めばよろしい。ああそうか、なるほど。なお、論文ではラグつき共変量のことは考えてないけど、容易に拡張できる。
よっつめ、係数が時間変動する共変量ベクトル$x_t$の効果(ベクトルの長さを $J$とする)。ええと、いま効果を$x^T_t \beta_t$としましょう。$\beta_t$は長さ$J$の係数ベクトルで、これがランダムウォークすると考える。つまり各要素について
$\beta_{j, t+1} = \beta_{j, t} + \eta_{\beta, j, t}$
この$\beta_t$を$\alpha_t$に突っ込み、共変量$x_t$のほうを$Z_t$に突っ込めばよろしい。状態ベクトルの遷移行列$T_t$は$J$行$J$列の単位行列になる。(状態空間モデルの、こういうひっくり返った発想に慣れないんだよな...)。なお、共変量の係数は時間変動させないほうが簡単で、させちゃうにあたってはいろいろ工夫が要る由(動的潜在因子とか潜在閾値回帰とか)。よくわからんので省略。
このモデルをベイズ推定する。事前分布をいろいろ工夫するんだけど(共変量の係数には少数の変数を使うようにspike-and-slab分布をつかうとか)、省略。なんだかわからんが、とにかく推定できるんだそうです。へー、すごいですね。
さて、このモデルをどうやって使うかというと...
t=n の直後になんらかのアクションが行われていたとする。その場合、次の3つのステップを踏む。
- 時系列$y_{1:n}$をつかってモデルのパラメータを推定する。
- このモデルを使って、反事実的な時系列$\tilde{y}_{n+1:m}$の事後予測分布を求める。
- 各時点 $t$ について、この事後予測分布からドローした値と実際の$y_t$との差$\phi^{(\tau)}_t := y_t - \tilde{y}^{(\tau)}_t$を求め (上添字 ($\tau$) は$\tau$回目のドローであることを表す)、その分布を介入の因果効果の事後分布とする。なんだったら、時点$n+1$以降の全時点を通じた $\phi^{(\tau)}_t$の合計なり平均なりを求めてもよい。
後半は数値例。まず、2つの共変量に動的回帰する人工データの例。
それから実データ。google adwordsへの出稿がクライアントのwebサイトへのクリック数に及ぼした効果の推定。共変量はそのカテゴリのgoogle trend(なるほど)。出稿されていない地域をコントロールにした効果推定に近い結果が得られた、云々。なるほど、googleがこの研究をする理由がわかろうというものだ。
私の素人目には意外だったのだが、この提案では、市場に対する介入の効果をモデルのなかでexplicitに表現するつもりはさらさらないのである。なるほどねえ、そんなのモデル化するとなったら、そのたびに頭を使わないといけないもんね。
しっかし、パラメータ推定にあたっては基本的に介入前の時系列しか使えないわけで、いかにもgoogle的なデータリッチな発想だなあ、と呆然。マーケティング・リサーチの文脈では、ふつうマーケティング・アクションが起きる前の観察データはプアなので、こういうのを聞くとあっけにとられてしまう。
読了: Brodensen, et al. (2014) マーケティング・アクション前後の時系列からアクションの因果効果を推定するぜ by Google
2014年9月 9日 (火)
ある方に「私は未読ですがこんな論文があるようですよ」とお知らせしたのだが(畏れ多くも)、よく考えてみると、自分が読んでない資料を紹介するのはいかがなものか。私の最初の指導教官ならば、穏やかに「いやあ私にはよくわかりませんが、それは少し無責任な態度といえなくもないかもしれませんね」と仰るであろう。先生は謙虚さを煮詰めて温和さでコーティングしてスーツを着せたような方で、自著の内容について質問された際も「いやあ私にはよくわかりませんが」と前置きしたという逸話が残っているほどであり、従って発言の真意を知るのは素人には困難なのだが、もし上記のような発言があればそれは厳しいお叱りの言葉なのだ。
すいません師匠、読みますです、と心の中で勝手に叱られ勝手に恐縮して、印刷してみたら、これ、40ページもあるやんか...
Browne, M.W. (2001) An overview of analytic rotation in exploratory factor analysis. Multivariate Behavioral Research, 36(1), 111-150.
探索的因子分析における回転法のレビュー。いまホットな話題とは言い難いだろうが、実務で因子分析を使う人にとってはいまでも切実な話題である。そういえば先日も、市場調査会社のある優秀なリサーチャーに「バリマクス回転とエカマクス回転はどうちがうんですか」と正面から問われ、うろたえたものであった。(私の答え:「似たようなもんっすよ」)
冒頭で著者いわく、現状で一番使われている回転法は、直交ならバリマクス、斜交ならプロマクス、ちょっと詳しい人なら直接クオーティミンであろうとのこと。
まず記号の定義。$p \times m$の初期因子行列を$A$とする。$m \times m$ の変換行列を $T$とする。回転後の因子パターン行列$\Lambda$は
$\Lambda = A T$
準拠構造行列を $L$ とする。で、パターン行列なり構造行列なりの複雑性(opp.単純性)を表す連続的関数を最小化したい、というのがお題である。
回転後の因子間相関行列を$\Phi$とする。直交回転ならば、$T$は
$\Phi = T' T = I$
と制約される。制約の数は $m(m-1)/2$個。斜交回転ならば
diag($\Phi$) = diag($T^{-1} T^{-1'}$) = $I$
という制約がかかる(因子の分散を1にするため)。制約の数は$m$。このように、直交回転も斜交回転も$f(\Lambda)$の最小化であって、ちがいは制約の数に過ぎない。
因子行列の単純性とはなんぞや。Thurstone(1947)は5つの基準を挙げている:
- 各行がすくなくともひとつのゼロを持つ
- 各列がすくなくともm個のゼロを持つ
- 列のすべての対が、一方はゼロでなく他方はゼロである行をいくつか持つ
- (m>3のとき) 列のすべての対が、両方がゼロである行をいくつか持つ
- 列のすべての対が、どちらもゼロでない行をいくつか持つ
ただし、このうち単純構造の定義になっているのは最初の基準だけで、あとの4つは識別条件などである。
以下、$\Lambda$(ないし$L$) のある行における非ゼロ要素の数を、その変数の「複雑性」と呼ぶ。複雑性1の変数を「完全指標」と呼ぶ。すべての変数が完全指標だったら、それは完全クラスタ配置である(変数の排他的分類に成功しているわけだ)。これが単純性の行きつく先だ、と考える人が多い。しかしThurstoneの基準はもっとゆるい。
以下、有名無名とりまぜて、回転法の紹介。
1) Crawford-Ferguson基準。
まずは非負の要素{$s_1$, $s_2$, ...}を持つベクトル$s$について考える。その複雑性についてCarrollは次の指標を考えた:
$c(s) = \sum_j \sum_{l \neq j} s_j s_l$
つまり、要素のすべての対の積和である。下限 0 が得られるのは、非ゼロ要素がせいぜい1個までのときである。
因子負荷の平方の行列$S$について考える。行を$s_{i.}$, 列を$s_{.j}$で表す。各行の複雑性の総和と各列の複雑性の重み付け和
$f(L) = (1-\kappa) \sum_i c(s_{i.}) + \kappa \sum_j c(s_{.j})$
をCrawford-Ferguson基準という。
- 第一項は変数複雑性で、Thurstonの基準3, 4, 5に対応している。完全クラスタ配置のときはもちろん、Thurstonの基準1を満たしているだけで下限 0 が得られる。つまり、一般因子の有無に対してはinsensitiveである(←なるほど...)。
- 第二項は因子複雑性で、各列の非ゼロ要素が1個のときに下限 0 が得られる。これはThurstonの基準2に対応している。
このCrawford-Ferguson基準と直交制約を合わせると、いわゆるオーソマクス回転のファミリーが得られる。$\kappa=0$ならクオーティマクス、$\kappa=1/p$ならバリマクス、$\kappa=m/(2p)$ならエカマクスに等しい。ここまではCrawford-Ferguson(1970)よりも前に提案されていた。$k=(m-1)/(p+m-2)$ならパーシマクスで、$\Lambda$の全要素が等しいときに変数複雑性と因子複雑性の貢献が同じになるように配慮している。$k=1$なら因子パーシモニーで、これはあまり実用性がない。
斜交制約のみをかける場合も同様のファミリーを考えることができる。各手法のオリジナルの定式化と区別するために、頭にCF-をつけて、たとえばCF-varimaxなどという。ちなみに、オリジナルのバリマクスの定式化を斜交化しちゃうと因子間相関が1になっちゃうという問題が生じるのだが、CF-varimaxの斜交回転ではそういうことは起きない。
2) Geomin基準。
さきほどのCarrollの複雑性の関数は、Thurstonの発想とちょっとちがう。Thursonは基準1で、ゼロが1個でもあったらそりゃ単純だ、と考えていたのだ。そこで、非負の要素{$s_1$, $s_2$, ..., $s_m$}を持つベクトル$s$について、その複雑性を要素の総乗
$c(s) = s_1 s_2 s_3 ... s_m$
としよう。
で、準拠構造行列の複雑性を次のように定義する。まずすべての要素を平方する。行を$s_i$とする。各行の複雑性の総和
$f(L) = \sum_i c(s_i)$
を行列の複雑性とする。Thurstonはこれを最小化するアルゴリズムを考えたんだけど、うまくいかなかった。
その後Yates(1987)がこれを次のように書き換えた。因子パターン行列を使う。まずすべての要素を平方しておく。各行について複雑性を求め$1/m$乗する(つまりは各行内の幾何平均である)。これを足しあげる。
$f(\Lambda) = \sum_i c(s_i) ^{1/m}$
Yatesはこの式をちょいと加工して(省略)、うまく最小化できるようにした。これをGeomin基準という。
3) McCammonの最小エントロピー基準。
まずはエントロピーの定義から。合計1となるn個の非負要素からなるベクトル x について、エントロピーは
$Ent(x) = - \sum_i e(x_i)$
ただし$x_i = 0$のとき$e(x_i) = 0$, $x_i>0$のとき$e(x_i) = x_i ln(x_i)$である。どこかひとつが1(他はすべて0) のときに下限0が得られるわけで、その点ではCarrollの複雑性と同じである。
例によって、因子パターン行列の全要素を平方しておく。各要素を$s_{ij}$、行$i$ の総和を$S_{i.}$, 列$j$ の総和を$S_{.j}$、全総和を$S$として、
$f(\lambda) = -\sum_j \sum_i e(s_{ij}/S_{.j}) / -\sum_j e(S_{.j}/S)$
落ち着いて眺めると、要するに、列エントロピーの総和を、列和のエントロピーで割った値である。つまり、各因子が少数の高い負荷を持ち、他の負荷はすべて0、というときに小さくなる。これがMcCammon(1966)の最小エントロピー基準である。ちなみに直交回転でしか役に立たない。
4) McKeon(1968)のインフォマクス基準。
因子負荷行列の各要素を平方した行列を、あたかも2元クロス表のように捉え、連関の尤度比検定量を最大化する。うわあ、なんだそりゃ。数式は省略。
5) 部分的に特定したターゲットへと回転する方法。
CFAみたいに聞こえるが、ちょっと違うのである。たぶん一生使わないと思うので省略。
話かわって、初期行列の標準化。回転の前に初期因子行列$A$をなんらか標準化することが多い。2つの手法がある。
- Kaiser標準化。行方向の平方和がどの行でも同じになるようにする。変数の共通性に関わらず、すべての変数を平等に扱おうというわけである。
- Cureton & Mulaikの標準化(CM標準化)。なにやらよくわからん理屈によって、高い因子負荷をひとつだけ持っている変数を重視するように重み付けするそうである。超面倒そうなのでスキップ。
いずれもサンプルサイズが小さいときはやめといたほうが良い由。(これはSASのproc factorでいうところのNORM=オプションの話だと思う。SASの場合、NONE, KAISER, WEIGHT(CM標準化のこと), COVの4種類があって、デフォルトはKAISERである。)
数値計算の話。著者らはCEFAというプログラムを配っていて、この論文に載っている手法をカバーしている由。局所最適解に落ちないようにこんな工夫をしてます、云々。パス。
やれやれ。。。ここまでがレビューであった。
後半は数値例。疲れたので斜め読み。要点をメモしておくと、
- 完全クラスタ配置に近い配置であれば、どの方法でもうまくいく。
- そうでないときには、安定して大域最小解を示す手法が誤った解を示したり、良い解を示す手法が不安定だったりする。残念ながら、最良の手法はヒトの判断なしには選べない。
- CM標準化は善をなす場合と悪をなす場合がある。他の解と比較するように。
というわけで、この論文は探索的因子分析についてある程度知っている人向けのレビューであった。いきなりCrawford-Ferguson基準の観点から整理しちゃっていて、従来よく使われているプロマクス回転については説明がない。そのかわり最近のGeomin基準については丁寧な説明がある。
明日の実務に役立つアドバイスはないが、勉強にはなりました。ううむ、やっぱし銀の弾丸はないのか。
読了: Browne (2001) 探索的因子分析の回転法を総ざらえ
2014年8月28日 (木)
Flom, P.L., Cassell, D.L. (2007) Stopping stepwise: Why stepwise and similar selection methods are bad, and what you should use. The NorthEast SAS Users Group (NESUG), 2007.
単なるSASユーザ会の資料なのだが、読んだものはなんでも記録しておこう、ということで... 気分転換にディスプレイ上で読んだ奴。
タイトル通り、回帰分析におけるステップワイズ変数選択を批判(といっても、きちんとした説明とは言い難い)。代替案を紹介: (1)選択なんかしない(←はっはっは)、(2)実質的な知識で選ぶ、(3)たくさんモデルをつくって、係数をAICかなんかで重みづけ平均する、(4)選ばないでPLS回帰、(5)LASSO、(6)LAR、(7)クロスバリデーション(代替案というかなんというか...)。で、最近のSAS/STATに載っているGLMSELECTプロシジャの紹介。
ごくごく粗っぽい内容で、特に読まなきゃいけないようなものでもないんだけど(すいません)、実務家らしいユーモラスな言い回しが何個かあって面白かった。"Solving statistical problems without context is like boxing while blindfolded. You might hit your opponent in the nose, or you might break your hand on the ring post." だってさ。
ともあれ、この分野についてはHastie&Friedmanの本 (こないだ翻訳が出たやつかな)、Harrellの本、Burnham & Andersonの本、あたりを参照すると良さそうだ。調べたらどれも良いお値段だ、参るなあ...
読了: Flom & Cassell (2007) ステップワイズ変数選択は使うな (でもGLMSELECTは使っていいよ)
2014年8月24日 (日)
金曜の夜にwebをぼんやり眺めていて、因果推論の巨匠 Pearl 先生が公開しておられるすごく面白い文章を見つけた。難解をもって知られる主著"Causality"の第二版に収録されている文章で、第一版の訳書にはみあたらない。
あまりに面白い文章なので、ずるずるとメモをとっていたら、結局だいたい訳出してしまった。貴重な休日の午後を費やし、俺はいったいなにをしておったのか、と窓の外が暗くなってから我に返ったが、あとの祭りとはこのことである。実際、今日は近所で夏祭りがあったらしい。
せっかくなのでメモを以下に載せておきます。ご関心あるかたはぜひ原文にあたってくださいませ。
この文章、博士論文の審査という架空の場面で書かれてはいるが、データから因果的主張を引き出そうとするすべての人に関係する内容だと思う。
アンケート調査を一発やって、SEMのモデルを組んで、ここをどうにかすればここがきっとこうなるでしょう、云々... とやたらに強気な主張をするタイプの分析者に対して「なんだかなあ」というモヤモヤ感を抱いたことのある、全国1000万人(推定)のリサーチ関係者のみなさん、これはホントに勉強になります。
意地悪であったはずのEX博士が、紙面の都合からか途中から急に物わかり良くなっちゃうところも見所であります。
敵対的な審査者との対話、あるいは SEM サバイバル・キット
話を簡単にするために、次のように想定しよう。あなたの論文の中に出てくるモデルは、次の 2 本の式からなっている。
y = bx + e1 (1)
z = cy + e2 (2)
e2 と x は無相関である。あなたの論文はパラメータ c の推定を主題にしており、あなたは最善の SEM 手法によって満足のいく推定値を得た。c=0.78 という推定値である。さらに、あなたはこの知見について因果的な解釈をおこなった。
さて、意地悪な審査者、EX博士があなたの解釈について質問を始める。
EX博士: あなたがいう「 c について因果的に解釈できる」というのは、どういう意味ですか?
あなた: y の 1 単位の変化が、Z の期待値 E(Z) における c 単位の変化をもたらす、という意味です。
EX博士: その「変化」とか「もたらす」というのはいやな感じですね。科学的にいきましょう。あなたが言っているのは E(Z|y) = cy + a っていうこと? それならわかります。Z の y の下での条件つき期待値 E(Z|y) は数学的にきちんと定義できるし、それをデータから推定する方法もわかる。でも「変化」とか「もたらす」というのはわけがわからない。
あなた: 私は実際に「変化」という意味で言っております。「条件つき期待値における増大」という意味ではありません。私が言っているのはこういうことです。いま、y をなんらかの定数 y1 に固定する物理的な手段があったとします。そしてその定数を y1 から y2 に変化させることができるとします。そのとき、E(Z)において観察される変化は c(y2-y1) でしょう、ということです。
EX博士: いやいや、それはちょっと形而上学的な話になってませんか? 私は統計学の講義で「固定する」なんて言葉を聞いたことがないよ。
あなた: あ、すみません、先生は統計学がご専門ですね。でしたら先程の解釈を次のように言い換えさせてください。いま y を無作為に割り付けた統制実験を行うことが可能だとして、統制群の y を y1 に、実験群の y を y2 にセットしたとします。このとき、E(Z)において観察される差は、y1 と y2 がなんであれ、(統制群と実験群におけるzの測定値をZ1とZ2として) E(Z2) - E(Z1) = c(y2 - y1) であろう、ということです。[脚注: EX博士が「あなたの主張はそれだけ?」と尋ねたら、こう付け加えること。付け加えますと、確率変数 Z1 - cy1 の分布が確率変数 Z2 - cy2 の分布と同じであろう、ということです。]
EX博士: だいぶわかりやすくなってはきたけれど、でもひっかかりますね。あなたの話は途中ですごくジャンプしているように思える。あなたのデータは実験によるものではないし、あなたの研究のどこにも実験なんて出てこない。あなたは、観察研究から得たデータをSEMのソフトでどうにかすれば、無作為化統制実験から得られるであろう結果を予測できる、といいたいの? 冗談でしょう! 実験研究をそんなSEMの魔法に置き換えることができたら、国中でどれだけの予算が削減できると思う?
あなた: 魔法じゃありません、先生、易しい論理です。SEMのソフトを使った私の分析のインプットにあたるものは、非実験データだけではありません。インプットは2つの要素からなっています。すなわち、データと因果的想定です。私の結論はこの2つの要素からの論理的帰結です。標準的な実験研究には2つめの要素が欠けていて、だから実験研究にはお金がかかるのです。
EX博士: なに的想定だって? 「因果的」? そんな変な言葉は聞いたこともない。私たちはふつう、想定を数学的に表現します、同時密度の条件とか、共分散行列の特性といった形で。あなたの想定を数学的に表現してもらえますか。
あなた: 因果的想定というのはそういうものではないのです。密度関数や共分散行列と言った語彙では表現できません。ですから、そのかわりにモデルで表現しているのです
EX博士: 式(1)(2)のことですね。新しい語彙なんて見当たらないけど。ただの数式じゃないですか。
あなた: 先生、これは通常の算術的な数式ではありません。これは「構造方程式」です。正しく読めば、ここから一連の想定を読み取れます。それらは先生もよくご存じの、母集団に対して仮説的な無作為実験を行った結果についての諸想定です。私たちはそれらを「因果的」想定、ないし「モデリング上の」想定と呼んでいます、そちらのほうが良い言い方なので。ですが、それらはさまざまな無作為化実験のもとで母集団がどのように振る舞うかということについての諸想定として理解できます。
EX博士: ちょっと待って! あなたがいう因果的想定というのがなんなのか、だんだんわかりかけてきたけど、そのせいで余計に混乱してきた。いいですか、無作為化実験の下での母集団の振る舞いについて、あなたがなんらか想定することができるなら、なぜわざわざ研究しなきゃならないの? 「yを無作為に割り付けた無作為化実験で、E(Z)において観察される差は c'(y2-y1) だ」(c'は適当な数字) と直接想定しちゃえば、なにも何ヶ月も苦労してデータを集めたり分析したりしなくて済むじゃないですか。もしあなたが検証されていない想定から話を始めるのであれば、いっそE(Z2) - E(Z1) = c'(y2-y1)という想定から話を始めてしまえばいい。前者を信じてくれる人なら後者も信じてくれるでしょう。
EX博士: そうではありません、先生。私のモデリング上の想定は、研究の結論である E(Z2) - E(Z1) = 0.78(y2 - y1) という言明よりもはるかに弱い想定です。
- 第一に、私の結論は量的なもので、c=0.78 という特定の値にコミットしていますが、いっぽう私のモデリング上の想定は質的なものです。
- 第二に、先生を含め多くの研究者にとって、私の想定は受け入れやすいものだと思います。なぜなら、それらは世界がどのようになっているかという常識的理解と一般的な理論的知識に合致しているからです。
- 第三に、私の想定のうち大部分は、y の無作為割り付けを含まない実験によって検証可能なものです。つまり、yの無作為割り付けが高価ないし不可能であるとしても、もう少し手を付けやすい他の変数を統制することで想定を検証できるわけです。
- 最後に、これは私の研究にはあてはまらない点なのですが、モデリング上の想定は非実験研究で検証可能ななんらかの統計的含意を持っていることが多く、もしその検証が成功すれば(これを「適合」といいます)、そのことによってそれらの想定の妥当性がさらに確認できたことになるからです。
EX博士: 面白くなってきましたね。ではその「因果的」想定、モデリング上の想定とやらをみせてもらいましょうか。それが弱い想定かどうか判断しましょう。
あなた: 承知しました、ではモデルをご覧ください。ここで、
- z は、最終試験における学生の得点
- y は、学生が宿題に費やした時間
- x は、(教師がアナウンスした)最終評価における宿題のウェイト
です。このモデルを論文に書いたとき、私は心のなかに2つの無作為化実験を思い描いていました。一つ目は x が無作為割り付けされる実験で(つまり、教師が宿題のウェイトを無作為に割り付ける実験)、二つ目は宿題に費やした時間 (y) が無作為に割り付けられる実験です。これらの実験について考える際に私が設定していた想定とは:
- 1. yに関する線形性と除外: E(Y2) - E(Y1) = b(x2 - x1)、ただしbは未知 (Y2とY1は、アナウンスされた宿題のウェイトがそれぞれx2, x1であるときの宿題所要時間)。また、この式からzを除外することで、私は得点 z が yに影響しないと想定していることになります。そう想定する理由は、y が決定される時点で z は未知だからです。
- 2. zに関する線形性と除外: すべての x について E(Z2) - E(Z1) = c(y2 - y1)、ただし c は未知。言い換えれば、xは yを経由して z に影響するかもしれないが、それを別にすれば z には影響しない、という想定です。
付け加えますと、非実験研究という条件の下で x を支配する、測定されていない諸要因についても私は質的な想定を行っています。すなわち、x と z の両方に影響する共通の原因はないという想定です。
EX先生、ここまでの想定になにか反論をお持ちですか?
EX博士: いいでしょう、それらの想定が弱いものだということには同意します。あなたの論文の結論である言明 E(Z2) - E(Z1) = 0.78(y2 - y1) に比べればね。こういう弱い想定によって、(実験場面における) 宿題の得点への実際の影響についての大胆な予測を支持することができるというのは面白いと思います。しかし、あなたがいうところの原因についての常識的な想定には、まだ納得できません。宿題の重要性を強調する教師は、同時に情熱的で効果的な教師でもあり、そのためあなたの想定に反し、e2 (ここには教授の質といった要因が含まれています) は x と相関しているのではないでしょうか。
あなた: EX先生、先生もSEMのリサーチャーのような話し方をなさるようになりましたね。手法と哲学を攻撃する代わりに、私たちはいまや実質的な諸問題について議論し始めています... たとえば、教師が効果的である程度と、その教師が宿題に付与するウェイトとのあいだに相関がないと想定するのは合理的か、といった問題についての議論です。私は個人的には、宿題を気に掛けずにはいられない立派な教師に出会いましたし、またその逆の教師にも出会いました。
しかし、私の論文はそのことについての論文ではないです。私は、教師が効果的である程度が、教師が宿題を重視するかどうかと相関していない、とは主張していません。その問題については、他の研究者が今後検証してくれればと思っています(あるいは、すでに検証されているかもしれませんね?)。私が主張しているのは次の点に過ぎません。教師が効果的である程度と教師が宿題を重視する程度とが無相関であるという想定を受け入れる研究者であれば、その想定とデータから論理的に次の結論が導かれるということに関心を持つでしょう。すなわち、宿題にかける時間が一日あたり1時間増えれば、得点が(平均して)0.78点増大する、という結論です。そして私のこの主張は、もし宿題の量(y)を無作為に割り付けた統制実験が可能ならば、実証的に検証できる主張です。
EX博士: あなたは自分のモデリング上の想定が真だと主張しているわけではなくて、単にそのもっともらしさについて述べ、その副産物について説明しているだけだ、というわけですね。それはよかった。そう言われると反論できません。しかし、今度は別の質問があります。あなたはさっき、あなたのモデルは統計的な含意を持たない、だからデータとの適合性という観点から検証することはできない、といいましたね。なぜそうだとわかったのですか? それは問題にはならないのですか?
あなた: そうだとわかったのは、私がグラフをみて欠けているリンクについて検討したからです。d-分離と呼ばれる基準を用いれば (11.1.2節「涙なしのd-分離」を参照)、SEMを用いる研究者は、グラフを一目見ただけで、グラフに対応するモデルが変数間の偏相関を消失させる形式でのなんらかの制約を含意しているかどうかを決定することができます。統計的含意は(すべてではありませんが)たいていの場合この性質を持っています。私たちの例では、モデルは共分散行列についてのいかなる制約も含意していません。ですから、それはどんなデータに対しても完全に適合し得ます。私たちはこういうモデルを「飽和している」と呼んでいます。
SEMの研究者のなかには、統計的検定の伝統を振り払えず、モデルが飽和していることをモデルの欠陥であるとみなす人もいます。でもそれは正しくありません。飽和したモデルを手にしているということは、ただ単に、その研究者がありそうもない因果的想定を行うのを避けたいと思っているということ、彼ないし彼女が持ちたいと思っている弱い想定があまりに弱すぎて統計的含意を生み出せないということ、を意味しているのです。こういう保守的な態度を非難してはいけません、むしろ褒めるべきです。
もちろん、自分のモデルが飽和していなかったら... たとえば e1 と e2 が無相関だったら、それは私は喜ぶだろうと思いますよ。でもここではそれは事実ではありません。常識的に考えて e1 と e2 は相関しています。データからもそれは伺えます。試しに cov(e1, e2)=0 という想定を置いてみたのですが、適合度はひどかったです。「飽和していない」モデルだという称号を手に入れるためだけに、保証のない想定を行ってもよいものでしょうか? いいえ! むしろ私は、合理的な想定を行い有益な結論を得て、私の結果と私の想定を並べて報告することを選びます。
EX博士: でも、同じくらいのもっともらしさを持った想定に基づく飽和したモデルが他にも存在し、そのモデルからは c の異なる値が導かれるとしたらどうですか? あなたの当初の想定のうちいくつかが間違っていて、そのため c=0.78 というあなたの結論も間違っている、という可能性については気になりませんか? あなたがあるモデルではなく別のモデルを選び取るとき、それを助けてくれるものはデータにはないわけだから。
あなた: その問題についてはとても気にしています。実のところ、こうした競合モデルのすべてについて、その構造をすぐに列挙することができます。たとえば、図11.15の2つのモデルがそれですし[xからzへの片矢印パスがあるモデルと、xとzのあいだに両矢印パスがあるモデル]、他にも挙げることができます(ここでもd-分離基準を用いることができます)。しかし、ご注意いただきたいのですが、競合モデルが存在するからといって、「モデルMの質的想定を受け入れる研究者ならば c=0.78 という結論を受け入れざるをえない」という先程の私の主張がいささかも弱まるわけではありません。この主張は論理的にみて無敵のままです。それだけではありません。この主張は、それぞれの競合するモデルからの結論を、そのモデルの背後にある想定と一緒に報告することで、さらに精緻化することができます。結論はこんな形になります:
もし想定集合 A1を受け入れるならば、c=c1 が含意される。
もし想定集合 A2を受け入れるならば、c=c2 が含意される。
...
EX博士: わかりました。でも、そうした条件付きの言明を超えて先に進み、さまざまな想定集合のなかからどれを選ぶかを決めるということに踏み込みたい場合、その試みを支援してくれるSEMの手法はないのですか? 統計学において通常直面する問題では、競合する2つの仮説は、いかに弱いものであろうが、なんらかの検証にはかけられるものですが。
あなた: これが統計的データ分析とSEMの根本的なちがいです。統計的仮説とは、定義上、統計的手法によって検証可能なものです。いっぽうSEMのモデルは因果的な想定に依存しており、それらの想定は定義上、統計的検証ができません。もし2つの競合モデルが飽和していたら、私たちにできることは結論を上で述べたような条件付きの形で報告することだけですし、そのことがあらかじめわかるわけです。しかし、もしその競合が、同じぐらいのもっともらしさを持ちつつも統計的には異なるモデル間の競合であるならば、私たちはモデル選択という一世紀にも及ぶ古い問題に直面することになります。モデル選択に関しては、これまでにAICのようなさまざまな選択基準が提案されてきました。しかしここでは、モデル選択という問題に新しい因果的な変化が生じています... ここでの私たちのミッションは、適合度を最大化することでも予測力を最大化することでもなく、cといった因果的パラメータの推定をより信頼できるものにすることだからです。全く新しい問題領域が登場したわけです(Pearl, 2004を参照)。
EX博士: 興味深いですね。私の同僚の統計学者たちがSEMの方法論に出会ったとき、混乱し疑い深くなり、敵意さえ持った理由がわかりました (たとえば Freedman 1987; Holland 1988; Wermuth 1992)。最後の質問です。あなたはさっき、私が統計学者だといことを知ってから無作為化試験の話を始めましたね。統計学者ではない人に対しては、あなたはSEMの戦略をどう説明するのですか?
あなた: 平易なことばでこういいます。「もし私たちが、yをなんらかの定数y1に固定する物理的手段を持っており、その定数を y1 から y2に変えることができるとしたら、そのとき E(Z)において観察される変化は c(y2 - y1)でしょう」と。たいていの人は「固定する」ということがどういうことかを知っています。なぜなら、それは政策決定者の心についての概念だからです。たとえば、宿題が成績に与える効果について関心を持っている教師は、宿題の無作為割り付けという観点から考えたりはしません。無作為割り付けとは、固定することの効果を予測するための間接的手段に過ぎません。
実際には、私が話す相手が本当に賢明な人であるならば (多くの統計学者がそうです)、反事実的な語彙に訴えて次のように言うことさえあります。たとえば、宿題に y 時間を費やした後で試験で z 点を取った生徒は、もし宿題に y+1 時間かけていたら z+c 点とっていたはずだ、と。正直にいえば、式 z = cy + e2 を書いたとき(ここで e2 は生徒のそのほか全ての特性を表し、モデルにおいては変数名を与えられず、y の影響は受けません)、私が心に抱いていたのは、本当はこの考え方なのです。私はE(Z)については考えもしません。単にある典型的な生徒の z について考えます。
反事実的条件は、科学的関係の意味を表現するために我々が持っている最も正確な言語的道具です。しかし、統計学者と話すときには、私は反事実的条件には触れないようにしています。残念ながら統計学者は決定論的な概念や即座に検証できないような概念に疑いを持つ傾向があり、そして反事実的条件はそういう概念だからです (Dawid 2000; Pearl 2000)。
EX博士: SEMについていろいろ教えてくれてありがとう。質問は以上です。
あなた: 恐縮です。
Pearl(2009) 敵対的な審査者との対話、あるいは SEM サバイバル・キット
2014年8月 8日 (金)
先日、勤務先の若い人に、重回帰や分散分析でいうところの交互作用(interaction)についてちょっと話す機会があったのだけれど、説明する順序をぼんやり考えていて、ふと疑問に思ったことがあった。
交互作用というのは統計的現象の名前で、それを引き起こすメカニズムは多様である。たとえば、 $X_2$ が$X_1$にとってのモデレータになっていたら交互作用が生じる (誤差項を省いて $Y = a + bX_1, b = c + dX_2$とか)。$X_2$が$X_1$にとってのメディエータになっていても交互作用が生じることはある ($Y = a + b_1 X_1 + b_2 X_2, X_2 = c + dX_1$とか)。$X_1$と$X_2$の線形和がある閾値を超えると発火する二値潜在変数があって、それが$Y$にボーナスを与えるので結果的に交互作用が生じる、なんていう状況も容易に想像できる($Y = a + b_1 X_2 + b_2 X_2 + b_3C$, $logit(Prob(C=1))=c + d_1X_1 + d_2X_2$とか)。他にもいっぱいありそうだ。いったい何種類あるんだろう? 類型化できないものかしらん。
VanderWeele, T.J., & Knol, M.J. (2014) A tutorial on interaction. Epidemiological Methods.
... というようなことを考えながらwebを眺めていて拾った、近刊の論文。掲載誌はまだ3号しか出ていないオープン誌で、性質がよくわからないのだが、ハーバード大の疫学部門の紀要みたいなものなのかなあ?
タイトル通り、疫学における交互作用についての啓蒙論文。えらく長いのだが(著者も前半と後半にわけて読んだほうがいいよといっている)、現実逃避の一環として持ち歩いてだらだらめくり、なんとなく読み終えてしまった。
まず前半。わりかし易しい内容である。
交互作用について調べる動機はたくさんある。まず、介入のためのリソースが限られているので、介入の効果が大きい下位集団を特定したいから(←マーケティングでいうところのセグメンテーションとターゲティングですね)。アウトカムを引き起こすメカニズムについて洞察を得たいから。主効果を調べる際の検定力を上げたいから。あるリスク要因に対する介入が不可能なので、せめて交互作用のある共変量に介入してどうにかしたいから。そして、単にモデルの適合度をあげたいから。
交互作用をどうやって測るか。二値アウトカム$D$について考える。原因変数として$G, E$があって(とりあえず2値だとして)、$Prob(D=1 | G=g, E=e)$ を$p_{ge}$と略記する。交絡とか共変量調整とかは当面忘れよう。大きく分けてふたつの測り方がある。
- 加法的に測る。効果を確率の差で測るなら、交互作用とは$p_{11}-p_{00}$ と $(p_{10}-p_{00})+(p_{01}-p_{00})$ との差である。つまりは$p_{11}-p_{10}-p_{01}+p_{00}$である。
- 乗法的に測る。効果を確率の比で測るなら、交互作用とは$(p_{11} p_{00})/(p_{10} p_{01}$)である。$p_{00}$をベースにとったリスク比を$RR_{ge}$と書けば、交互作用とは$RR_{11}/(RR_{10} RR_{01})$である。
加法的交互作用と乗法的交互作用が逆になったり、一方ではあるのに他方ではなかったり、ということはごくあたりまえに起きる。たとえば、非喫煙者の肺がんリスクがアスベスト非曝露で0.1%, 曝露で0.7%, 喫煙者では非曝露で1.0%, 曝露で4.5%だとしよう。加法的にみれば交互作用は4.5-1.0-0.7+0.1=2.9で、2要因が揃うとリスクが上積みされることになるし、乗法的にみれば(4.5x0.1)/(0.7x1.0)=0.45/0.7=0.64で、2要因が揃うとリスクが割り引かれることになる。
どっちを使うべきかは後述するが、公衆衛生上の観点からは、ふつうは加法的に測ったほうがよい。なお、
- ケース・コントロール研究だとオッズ比を使うので、交互作用を$OR_{11}/(OR_{10} OR_{01})$として乗法的に測ることがある。
- リスク比しかわからないけど交互作用は加法的に測りたい、という場合もある。上の加法的交互作用を$p_{00}$で割ると$RR_{11}-RR_{10}-RR_{01}-1$。これはrelative excess risk due to interaction (RERI), ないしinteraction constract ratio (ICR)と呼ばれている(←へー)。$p_{00}$が既知でない限りRERIのサイズの評価は困難だが、すくなくとも加法的交互作用の向きはわかる。なお、RRのかわりにORをつかうこともある。
現実の場面では、なにかのモデルを通じて交互作用を測ることも多い。信頼区間がわかるので気分がいい。たとえば
$p_{ge} = \alpha_0 + \alpha_1 g + \alpha_2 e + \alpha_3 eg$
$log(p_{ge}) = \beta_0 + \beta_1 g + \beta_2 e + \beta_3 eg$
$logit(p_{ge}) = \gamma_0 + \gamma_1 g + \gamma_2 e + \gamma_3 eg$
いうまでもなく線形モデルの $\alpha_3$ は $p_{11}-p_{10}-p_{01}+p_{00}$である。対数線形モデルの主効果 $\beta_1$ と $\beta_2$ は対数リスク比で、$\beta_3$は$RR_{11}/(RR_{10} RR_{01})$の対数である。ロジスティックモデルの主効果$\gamma_1, \gamma_2$は対数オッズ比で、$\gamma_3$は$OR_{11}/(OR_{10} OR_{01})$の対数である。
上の3本のモデルのうち最初の2本は、共変量をいれたとき(とくに連続的共変量をいれたとき)ML推定が収束しないことがある。だから3本目のロジスティックモデルが良く使われている。だけど加法的交互作用をみることも大事だ。そこで! ロジスティックモデルで推定した交互作用パラメータと信頼区間をRERIに変換する方法を伝授するぜ!
共変量入りのロジスティックモデル
$logit(P(D=1|G=g,E=e,C=c) = \gamma_0 + \gamma_1 g + \gamma_2 e + \gamma_3 eg + \gamma'_4 c$
を考えると、ORベースのRERIは
$RERI = OR_{11} - OR_{10} - OR_{01} + 1 = exp(\gamma_1+\gamma_2+\gamma_3) - exp(\gamma_1) - exp(\gamma_2) + 1$
だ。標準誤差を求めるSASとStataのコードを付録に載せたから使ってくれ! Excelシートも別途配ってるから持ってってくれ!
なになに、コホート研究でアウトカムがレアじゃないから、ORベースじゃなくてRRベースのRERIを使いたいって? オーケー、そんなら対数線形モデルを使いたまえ。収束しないって? ポワソンモデルという手もあるから使ってみてくれ。weightingアプローチというのもあるから俺の論文を読んでくれ。
なになに、曝露が二値じゃないって? 気にすんな、考え方は同じだ。ただし、RERIの算出はややこしくなるから注意な。それからEとGがどこからどこに動くと考えるかでRERIが変わってくるから注意な。グッドラック! (柳澤慎吾風に)
(前半戦がまだまだ続くので、テンションを元に戻して)
交互作用を加法的に測るか乗法的に測るかという話に戻ろう。ベストアンサーは「両方のやり方で測る」である。しかし実際にはロジスティックモデルで乗法的に測っていることが多い。これは由々しき事態だと思っておる。
加法的交互作用を支持する理由は:
- 公衆衛生上の観点からは、どっちのサブグループに介入したら何人助かるかに関心がもたれるから。
- 単に統計的な交互作用を調べるのではなく、mechanisticな交互作用について調べる場合。つまり、「2つの曝露が揃わないと発症しない」人がいるかどうかを調べる場合。
- 加法的交互作用の検出よりもパワフルだから。
乗法的交互作用を支持する理由は:
- 簡単だから。ロジスティック回帰のソフトは入手しやすいし。
- リスク差よりもリスク比・オッズ比のほうがheterogeneity が小さい、という説がある。そんなことが一般的にいえるかどうかはわからないのだけれど、もしそれが本当で、かつそれがなんらかの生物学的な仕組みの反映だとするならば、そのときはそりゃあ乗法的に測りたいとおもうわね。
- 疫学の教科書によっては、「因果性の評価」には比がふさわしい、と書いてあるのもある。この発想はCornfield et al.(1959)による喫煙と肺がんの研究にまでさかのぼることができるのだそうだ。もっとも、落ち着いて考えてみると、一概には言いがたい。
というわけで、ベスト・アンサーは「両方測れ」だ。原則的には、一方の方法でふたつの曝露の効果が見つかったら、他方の方法では交互作用も必ず見つかるわけで(←絵を描いてみて納得。そりゃそうだ)、交互作用の有無を単純に問うてはならない。最初に分析の目的をきちんと定めることが重要なのだ (←なるほど...)。
そのほかの話題。
- 交絡の話。たとえば薬の効き目が患者の髪の色によって違うとしよう。投薬有無がなにかと交絡しているかもしれない。そこで、共変量を入れて交絡を統制した(ないし投薬有無を無作為化した)。さて、ここで得られた交互作用は、髪の色で定義された層の間で投薬の効果が異なるという意味では正しい。しかし、ホントに髪の色が投薬の効果に影響しているのかどうかはわからないし、髪の色に介入して投薬の効果を最大化できるかどうかもわからない。こういう交互作用を「効果の異質性」とか「効果の修飾」という。
さて、実は投薬の効果に影響しているのはなにかの遺伝子で、髪の色はその代理変数だ、ということがわかったとする。ここまで来たのを「因果的交互作用」と呼ぶ。
実際にはこれらの用語はあいまいに使われているので、目くじら立ててもしかたないんだけど、とにかく、ある統計的な交互作用があるとき、どちらの変数も交絡の可能性があるか、片方だけ交絡が統制されているか、両方とも統制されているか、という点を区別することが大事である。 - 報告のしかた。上の喫煙とアスベストの話で言うと、アスベストのリスク比を喫煙者と非喫煙者のそれぞれについて報告する、というのはよくない。ベースラインが比較できないから。非喫煙非曝露を参照水準にして3つのリスク比を報告すること。云々。
- サブグループ間で効果の向きがちがうことを、特に「質的交互作用」とか「クロスオーバー交互作用」ということがある(←医学統計に特有な言い回しじゃないかしらん...)。この場合、仮にリソースが無限大でも全体に介入してはいけないわけで、その発見はより重要である。質的交互作用の存在について検定する方法もある。云々。
- mechanisticな交互作用について。これは「2つの曝露が揃わないと発症しない」交互作用のことで、sufficient cause 交互作用、相乗作用 (synergism) ともいう。$p_{11}-p_{10}-p_{01} \gt 0$ということだから、これはただの正の加法的交互作用よりも狭い概念である。以下、あんまり関心ないのでパス。
ふぅー。以上が前半戦。
後半戦はマニアックな話が多いし、やたらに眠いので流し読みになってしまった。
- mechanisticな交互作用がある場合でさえ、うかつにそれを「生物学的交互作用」とか「機能的交互作用」なんていわないように。遺伝要因G1とG2があり、G1=1のときにプロテイン1が作られず、G2=1のときにプロテイン2が作られないとしよう。で、どちらのプロテインも存在しないときにアウトカムDが発生しうる、としよう。これはmechanisticな交互作用だが、プロテインが生理学的に交互作用してアウトカムが発生してるわけじゃない(そもそもプロテインは存在してないんだから)。云々、云々。(←なんだか言葉遊びのようで実感が持てないが、生物系の人にとっては切実な話なのかな)
- 二つの曝露が揃うことによるリスク差なりリスク比なりオッズ比なりを、2つの曝露変数とその交互作用の計3つに分解する、という話。
- ケース・オンリー・デザイン。仮にケースだけが手に入っていたとしても、2つの曝露変数の独立性が仮定できるなら、交互作用は曝露変数のクロス表のみから推定できる。つまり、喫煙有無となにかの遺伝子型が独立だとして、肺がん患者だけを調べれば、肺がんに対する喫煙と遺伝子型の交互作用がわかるわけだ。(←意外に簡単で拍子抜けした。なにか仕事にいかせないかなあ...)
- アウトカムが連続変数だったらどうなるか。もはや加法的か乗法的かという問題はがらっと様相を変えてしまい、アウトカムの分布に依存して決めたほうが良い話になる。
- 層別する共変量の候補が複数あるとき、介入すべきサブグループを同定する、という問題。これは面白いのでちゃんとメモしておこう。
まず考えられるのは、実質的知識でもって共変量を選ぶ方法。それから、ひとつづつ共変量を選んで層別し交互作用を調べていく方法(なんならボンフェローニ法で調整する)。共変量が連続変数だと厄介である。
そこで登場するのが「効果スコア」という考え方。対象者を曝露群と非曝露群にわけ、それぞれについて、共変量でアウトカムを説明する回帰モデルをつくる(全然ちがうモデルでかまわない)。で、各対象者について、この2つのモデルでアウトカムを予測し、予測値の差を「効果スコア」と呼ぶ。で、効果スコアがある閾値を越えている人をターゲットにする。Zao et al.(2013, JASA)というのを読めとのこと。
このアプローチの難点は、オーバーフィッティングとモデルの誤指定。いずれも対策が提案されている由。Cai et al.(2011, Biostatistics)というのを読めとのこと。
ううむ、そんな発想があるのか。。。たしかに、モデリング上は曝露変数と共変量との交互作用を無視しているけど、結果的に交互作用を見つけていることになるわけだ。。。 - 交絡に対する敏感性の分析の話。パス。
- 交互作用の検定力と標本サイズ算出の話。パス。
やれやれ、長かった。
一番面白く勉強になったのはやはり、著者が力を入れて書いている加法的交互作用と乗法的交互作用の話であった。私の勤め先の仕事でいうと、2時点間の確率変化を条件間で比較するときにこの話が火を噴く。リスク差を比べるのとリスク比を比べるのでは別の結果になってしまうという問題は、多くの人を混乱の淵に叩き込む。差をみるか比をみるかってのはすごく慎重に決めないといけないのだ。
読了:VanderWeele & Knol (2014) ハーバード「交互作用」灼熱教室
2014年8月 6日 (水)
Guyon, I., Elisseeff, A. (2003) An introduction to variable and feature selection. Journal of Machine Learning Research, 3, 1157-1182.
題名通り、変数選択(特徴選択)についての啓蒙的レビュー。変数選択特集号の巻頭論文である。雑誌の性質はよくわからないけど、この論文は被引用頻度がものすごく高いらしい。どこかでみかけた「データマイニング必読論文」リストでも、たしか筆頭に挙げられていたと思う。
こういう工学分野の文章は苦手なんだけど、勤務先の仕事ときわめて密接に関連する話題なので、メモをとりながら頑張って読了。
1. イントロダクション
最近は数百~数万個の変数を扱う研究が増えている。その典型例は遺伝子選択とテキスト分類である。変数選択はデータ視覚化とデータ理解を促進し、測定・貯蔵の必要を減らし、訓練時間をへらし、次元の呪いを克服して予測成績を向上させる。
この特集号の研究は主に、予測のために有用な特徴の選択という課題について扱っている(opp. 関連する変数をすべて見つける課題)。従って、冗長な変数を除外するという点が問題になる。
まず変数選択のためのチェックリストを挙げよう。
- 領域知識を持っているか? 持っていたら、アドホックな特徴のセットをつくれ。
- 特徴は同じ基準で測られているか? でなければ基準化を検討せよ。
- 特長に相互依存性はありそうか? もしそうなら、連言特徴なり特徴の積なりを可能な限り含めよ。
- 入力変数を極力減らす必要はあるか? もしないなら、選言特徴なり特徴の重み付け合計なりを可能な限り含めよ。
- 特徴をそれぞれ評価したいか? もしそうなら変数ランキングをやれ。でなければまずベースラインの結果を得よ。
- 予測変数が必要か? そうでないなら中止せよ。
- データは「汚い」かもしれないか(無意味な入力パターンとか、ノイズのある出力とか)? もしそうなら変数ランキングをつかって外れ値を見つけよ。
- 最初に試すべきことが分かっているか? そうでないならまずは線形予測を試せ。プローブ法を停止規準にした前向き選択法か L0ノルム最小化法を使え。さらに、同じ性質の予測変数を追加して特徴のサブセットを大きくしていけ。それで成績が上がるようなら非線形予測を試せ。
- 変数選択の新しいアイデア、時間、計算資源、十分な事例を持っているか? もしそうなら、いろいろ試してモデル選択をやれ。
- 安定した解がほしいか? もしそうなら、サブサンプルをとってブートストラップしろ。
2. 変数ランキング
入力変数を$x_1, \ldots, x_n$, 出力変数を $y$ とする。変数ランキングとは、$x_i$ と $y$ だけを関数に放り込んで、$x_i$ の価値を表すスコアを出す方法で、変数が直交であればランキング上位の変数群を予測子として選ぶのが最適だし、そうでなくてもランキングがあるとなにかと便利である。
ランキングの方法としては、$y$との相関を調べるとか、$y$が質的だったらROC曲線のAUCとか。情報理論的な基準を使うという手もある。良くつかわれるのは相互情報量。すなわち、$p(x, y) log \{ p(x, y) /( p(x)p(y) ) \}$ を$x, y$について積分したもの。$x,y$がともに離散変数の場合ならいいけど(積分の代わりに総和すればよい)、連続変数の場合は厄介で、正規近似すると相関係数みたいなものになってしまうので、離散化するか、Parzen windowsというようなノンパラ手法で近似するのだそうだ(←へぇー。カーネル密度推定のことかしらん?)
3. 事例
- ランキングに基づく変数選択は冗長な変数セットをもたらしかねないわけだが、しかし、いっけん冗長な変数でも、それを追加することでノイズ縮減とより良い分類が得られることがある... という例を3つ紹介。ええと、2変数2クラス(散布図上で右上と左下)の分類課題で、クラス内で無相関の場合、クラス内で相関+1に近い場合(この場合はさすがに1変数でよろしい)、クラス内で相関-1に近い場合。いずれも周辺分布は同じなので、結局、各変数を単独に評価していると最適な変数群を選び損ねるかもしれないわけだ。
- とはいえ、ランキングで役に立たなそうな変数をフィルタアウトしたいと思うのが人情なのだが(オーバーフィッティングが怖いからね)、しかしいっけん役に立たなそうな変数でも実は役に立つことがある... という例を2つ紹介。ええと、2変数2クラス(散布図上で左右)の分類課題でクラス内で相関がある場合と (なるほど、周辺からみると縦軸は役立たずにみえる)、2変数4クラスの分類課題でクラスがXORに並んでいる場合(当然ながら、周辺からみると縦軸でも横軸でもクラス判別できない)。
4. 変数サブセットの選択
この辺からだんだん未知の話になってくるので、メモも怪しいのだけれど... ええと、変数選択法は次の3つに分類できる。
- フィルター。前処理の段階で変数を選択する。ランキング上位の変数セットを選ぶとか。
- ラッパー。いま関心を持っている学習器(決定木とかナイーブ・ベイズとか最小二乗線形予測とかSVMとか)をそのままブラックボックスとして使い、所与の変数セットにスコアを与える。実際には、すべての変数セットを総当たりするのはふつう無理なので、探索方略をいろいろ工夫する(Kohavi & John, 1997, AI を読めとのこと)。もっとも、オーバーフィッティングの恐怖という意味では、精緻な探索方略よりも貪欲探索が良い。
- エンベデッド。学習のプロセスにおいて変数を選択する。ラッパーより効率が良い。このアイデア、別に新しいものではなくて、たとえばCARTはエンベデッド法である。
うーむ。全変数を叩き込んだランダム・フォレストで変数重要性を評価し、上位の変数を選んでモデリングするというのはどれになるんだろう。フィルター法だということになるんだろうなあ。
著者いわく、フィルター法をバカにしてはいけない。たとえば、まず線形予測を仮定してラッパー法とかエンベデッド法で変数選択し、やおら非線形予測モデルを組む、とか(前半戦がフィルターになっているわけだ)。情報理論的なフィルターというのもある(マルコフ・ブランケット)。この辺、私には難しいので中略。
以下、エンベデッド法についての話題。貪欲探索を用いるエンベデッド法の場合、変数追加なり削除なりによる目的関数の変化を予測するわけだが、その方法は3つある。
- ほんとに追加・削除してみて、目的関数の変化を調べる。
- 削除の場合、コスト関数の二次近似を求める方法がある。
- 目的関数における変数の敏感性を調べる(←これも削除の場合かな?)
目的関数とは、要するに適合度と変数数を組み合わせたものである。これを直接に最適化して、その結果として変数セットを得ようという方法もある。L0ノルム最小化とか(...難しいので中略)。
5. 特徴構築と空間次元縮約
変数を選ぶんじゃなくて特徴を作り直しちゃうという手もある。これは本来、領域知識が活躍する状況特有的な手法だが、一般的手法がたくさん提案されている。
特徴構築には二つの目的がある。データの再現と予測の効率化である。前者は教師なしの問題、後者は教師つきの問題である。そもそもの問題が予測なのに、教師なしな視点が入ってくるのは変な感じだが、著者いわく、場合によってはそうする理由がある。たとえば、教師なしの特徴構築のほうがオーバーフィッティングに強い。
特徴構築の方法としては...
- クラスタリング。階層的クラスタリングやk-means法なんかで変数をクラスタリングし、セントロイドを特徴にしちゃうわけだ。テキスト処理で用いられることが多い(語のクラスタリング)。
- 行列因子化。特異値分解しちゃうとか。
- 教師つきの特徴選択。ニューラルネットワークの中間層とか。ほかにも2つ紹介されているけど、難しいのでパス。
6. バリデーションの方法
えーと、モデル選択と最終モデル評価は別の問題である。後者の場合、原則として評価用のデータを別に用意する必要がある。ここで論じるのはモデル選択における交差検証の話。
- よく用いられるのはleave-one-out法だが、楽観的な結果になりがち。
- 最近ではmetric-based法というのがあって、ある変数セットを使ったモデルとその部分セットを使ったモデルについて、正解ラベルのないデータでのモデル間の差が訓練データでのモデル間の差に比べて大きいとき、これって小さいモデルのほうがいいんじゃね?と考える由。ふうん。
- プローブ法というのもある。簡単にいっちゃうと、データの中に乱数をいれておいて(これがプローブ)、前向き変数選択でこれが選ばれちゃったらストップ、というようなアイデア。(←なるほどねー。ランダム・フォレストのパーミュテーション重要性みたいなものか)
7. 発展的トピックと未解決の問題
- 変数選択における分散の問題。変数選択が安定しているとは限らないわけで、ブートストラップ法で調べるとか、「ベイジアン変数選択」(←ナンダソレハ)というようなアイデアがある。
- 他の変数がある文脈における変数ランキング。最近傍アルゴリズムによるランキング、なんていう提案がある由。
- 教師なし変数選択。信頼性とかスムーズネスとか、そういう基準で変数選択するという提案があるのだそうだ。
- 前向き選択がよいか後向き選択がよいか。後向き選択のほうがよいという意見がある($x_1, x_2, x_3$があって、最良解は$x_1とx_2$、次が$x_3$のみという場合、前向き選択だと$x_3$だけで停止するから)。
- 多クラス分類。2クラス分類から簡単に拡張できる方法と(フィッシャー基準でのランキングとかね。結局ANOVAのF値だから)、そうでもない方法がある。
- 特徴選択と特長構築の関係は、パターン選択とパターン構築の関係に等しい。とかなんとか。
- 単に予測するんじゃなくて、結果を引き起こす因果メカニズムについて推測する、という問題。このxはyの原因なのか結果なのか、というような。(←そりゃ難しそうですね...)
8. 結論
変数選択の手法は発展を遂げ、洗練されたラッパー法やエンベデッド法が登場しているが、そういうのを使ったほうが良いかどうかは場合による。次元の呪いやオーバーフィッティングは依然として怖い。だから、まずはベースラインとして、ランキングか前向き/後向き法で変数選択した線形予測をするのがお勧め。
...やれやれ、終わったぞ。
いっけん難しそうであったが、意外に平易でコンパクトなレビューで、大変助かりました。細部については理解できないところも多いのだが、この論文で勉強するような話ではなかろう。
読了:Guyon & Elisseeff (2003) 変数選択入門
2014年7月15日 (火)
Nicodemus, K.K. (2011) On the stability and ranking of predictors from random forest variable importance measures. Briefings in Bioinformatics. 12(4), 369-373.
先に読んだ Colle & Urrea (2010) への反論に相当するレター。著者はその前に読んだStroblさんの共同研究者らしい。なるほど、どうやらパーミュテーション・ベースの変数重要度をめぐって陣営が分かれているらしい。
Colle & Urrea はMDA (パーミュテーションで測るmean decrease accuracy) よりMDG (mean decrease Gini) のほうが安定しているっていうけど、MDGはカテゴリ数が多い変数で大きくなるし、予測子の間の相関によってバイアスを受ける。彼らの使ったデータの変数はSNPsだから、カテゴリ数が変数によってちがうし、ナントカカントカ(理解不能)のせいで相関がある。安定してりゃいいってもんじゃないよ。
(いま調べてみたら、ゲノムの塩基配列のなかで変異がみられる場所のことをSNPというのだそうだ。知らんがな。生まれながらの文系なのに、なんでこんなの話を読まねばならんのか)
それに、安定性について考えるんならカテゴリごとの頻度が大事よ。MDGはカテゴリの頻度分布によって影響されちゃうのだ。というわけで、人工データによるシミュレーションでMDAの有用性を示している。面倒になっちゃったのでメモは省略。
読了:Nicodemus (2011) ランダム・フォレストにおけるパーミュテーション・ベースの変数重要度に着せられた汚名をそそぐ
Calle, M.L., Urrea, V. (2010) Stability of Random Forest importance measures. Briefings in Bioinformatics. 12(1), 86-89.
この雑誌に載った論文についてコメントしたレター。掲載誌はどういう性質のものだかわからない(IF 5.3だそうだが、この分野でこれは高いのか低いのか見当がつかない)。
その論文(Boulesteix & Slawski, 2009)は、膀胱がんの罹患性と予後における遺伝的要素を同定するためにランダム・フォレストを使っていたのだそうだ。で、ランダム・フォレストの変数重要性指標としては、mean decrease accuracy (MDA) と mean decrease Gini (MDG)、特に前者が広く使われており、その論文でもこの両方を使っていた由。MDAというのは予測の正確さに対する当該変数の貢献をパーミュテーションで測った指標、MDGというのはその変数によるGini指標の低下を測った指標。
さて、MDAやMDGはどのくらいあてになるものだろうか。調べてみました。
別の実データを使い、ジャックナイフ法で安定性を調べてみた。MDGはそこそこ安定しておるが、MDAはぜ・ん・ぜ・ん安定していない。
正解がわかっているデータでシミュレーションしてみた。MDAは滅茶苦茶に成績が悪い。
MDAがひどかった理由を考えるに、当該変数 X 以外の変数の値のせいであろう。つまり、The variables that are below X and their values can vary substantially from one tree to another and from one individual to another だからであろう。(←申し訳ございませんが、これが理由の説明になっているのかどうかさっぱり理解できない。それってMDGでも同じことじゃない???)
読了:Calle & Urrea (2010) ランダム・フォレストにおけるパーミュテーション・ベースの変数重要度はあてにならない
読んだものは何でもメモしておこう、ということで...
Strobl, C., Hothorn, T., Zeileis, A. (2009) Party on! A new, conditional variable-importance measure for random forests available in the party package. The R Journal, 1(2).
著者らはRのpartyパッケージの開発者。分類木・回帰木(rpartパッケージ)やランダム・フォレスト(randomForestパッケージ)の標準的手法では、連続変数やカテゴリ数の多いカテゴリカル変数が選ばれやすくなる。さらに、予測子に相関がある場合、従来の重要性指標にはバイアスが生じる。partyパッケージではこれらの問題に対処したぞ。という記事。
ええと... 復習しておくと、分類木で分岐点を計算するときに良く用いられる方法のひとつは、Gini指標を最小化する分岐点を探すことだ。ノード t に落ちた個体がクラス $i$ に属する確率を $p(i | t)$ として、Gini指標とは
$GI = 1 - \sum_i [ p( i | t) ]^2 $
である。
著者いわく... Gini指標に基づく変数重要度は予測子のカテゴリ数や尺度がちがうときにバイアスがかかる。そこで使われているのがパーミュテーション重要度である。予測子のパーミュテーション重要度とは、out-of-bagケース(学習に使ってないケース)に対する正分類率と、当該の予測子の値だけをぐちゃぐちゃにかきまぜたときの正分類率との差である。ただし、randomForestではこれをSEで割った値(z得点)を重要度としている。
さて、パーミュテーション重要度は相関なんかと同じく、周辺的(marginal)な重要性指標である。つまり、ある変数がそれ自体の効果を持っていないに他の予測子と相関しているせいで重要度が高くなる、ということがありうる。この点、偏相関や偏回帰係数のような条件つき(conditional)な重要性指標とは異なる。
そこで我々(Strobl et al., 2008, BMC Bioinformatics)は条件つきパーミュテーション重要度を提案している。これはですね、データを共変量Zで層別し、層のなかだけでかきまぜるのである。Zに含める変数、ならびに連続変数の場合の離散化は、ランダム・フォレストのそれぞれの木で決める。この機能はpartyのvarimp()に積んである。
ユーザへのアドバイス。
- すべての予測子が同じ型だったら、randomForestパッケージを使おうがpartyパッケージを使おうがかまわない(前者のほうが計算が速い)。Gini重要性でもパーミュテーション重要性でもオッケー。
- 型が違ったら、partyパッケージのcforest()、パーミュテーション重要性 varimp() を使え。
- 予測子が相関していたら、周辺的重要性を使うべきか条件つき重要性を使うべきか考えろ。どっちもpartyパッケージのvarimp()に積んであるぞ。
- 話はそれるが、変数選択のパラメータ mtry のデフォルトは、randomForest()ではfloor(sqrt(ncol(x)))だがcforest()では5に固定だかんな、気をつけろよ。
- 重要度を読み込む前に、シードを変えて走らせるのを忘れんなよ!じゃあな!
読了:Strobl, Hothorn, Zeileis (2009) ランダム・フォレストにおけるパーミュテーション・ベースの変数重要度の新手法
こんなことを書くと年寄りだと馬鹿にされちゃうかもしれないんですけど、ふだんRというオープンソースのソフトウェアを使っていて、やはりふと不安になることがある。このパッケージ、本当に正しい結果を返してくれているのだろうか、という不安である。たとえばMASSパッケージやsurvivalパッケージのような標準パッケージならともかく、歴史の浅いマイナーなパッケージの場合、プログラムが多少誤っていたとしてもなかなか気づかれないだろうし、開発者はテヘペロで済ませてしまうのではなかろうか。その点、プロプライエンタリな分析ソフトの老舗・SASならば、万が一プロシジャがちょっとしたバグを含んでいたりマニュアルに誤りがあることが露見しようものならば、嵐のようなフラッシュと怒号の中で役員たちが泣き崩れ、開発者とその一族郎党犬猫に至るまでが釜ゆでの刑に処せられ、ノースカロライナ州の本社敷地にまたひとつ慰霊碑が立つ。(すいません嘘です)
というわけで、ふだん使っているRパッケージについては、なにかこうオフィシャルな... っていうんですかね、そういう種類の文章に目を通しておこないと、なんだか落ち着かない。もちろん、別に読んだからどうってことはないんだけど、まあ気持ちの問題である。
Karatzoglou, A., Meyer, D., Hornik, K. (2006) Support Vector Machines in R. Journal of Statistical Software, 15(9).
サポート・ベクター・マシンのRパッケージを比較した論文。最初にSVMの原理を説明(だんだん頭が煮えてくる)、さまざまなカーネルを紹介(だんだんどうでもよくなってくる)、そして実データを用いながら各パッケージの特徴を詳細に紹介(もはやほとんど理解できない)。速度を比較し、最後にまとめの比較表。
紹介されているのは、kernlabパッケージのksvm(), e1071パッケージのsvm(), klaRパッケージのsvmlight(), svmpathパッケージのsvmpath()。うぐぐぐ。なんだかよくわからんが、まあ素人はkernlabかe1071を使っていればいいのだろうか。前者はカーネルがいろいろ選べる、後者はスパース・マトリクスがそのまま食える、とかなんとか。
読了:Karatzoglou, Meyer, Hornik (2006) サポート・ベクター・マシンのRパッケージ品定め
2014年7月 9日 (水)
伊庭幸人(2006) ベイズ統計の流行の背後にあるもの. 電子情報通信学会技術研究報告. ニューロコンピューティング. 106(279), 61-66.
いつも拝読しているブログの記事で紹介されていた論文。読んでみたいなあ、ciniiで読めるのか、ログインしてみよう... と流れるようにクリックしていて、あっというまに購入してしまった(もちろん私費である)。怖い~cinii怖い~。
学会の招待講演の原稿らしく、ちょっとくだけた感じの文章であった。
途中で「カーネルしおまねき」っていうイラストが出てくる(カーネルトリックを使う場合カーネルの設計が重要、つまり最初が大変になるという主旨で、片方のハサミがすごく大きいカニが描かれる)。なぜにカニ?と思って検索してみたら、シオマネキって、片手がほんとに大きいのね! 知らなかった。名前からして、扇で優雅に潮を招くような感じの、もうちょっと優雅な姿を想像していた。
ええと、内容のほうは難しくてわからない部分も多く、特に最後の「生成モデルと判別モデル」のところが私には難解だったのだが、でも勉強になりました。
著者のいう生成的モデリングというのは、データの生成過程全体をモデリングし、観測値の同時分布の式をベイズの定理でひっくり返してパラメータを推定するという方針のことを指している。いっぽう判別モデリングとは、必要な部分だけモデル化するアプローチで、たとえば分類だったら観測値の下でのクラス所属確率を直接にモデル化する。ううむ、難しいなあ。たとえば顧客満足とか製品選好の研究で、満足なり選好なりを生成する心的過程を包括的に捉えんという意気込みの下、壮大なSEMのモデルを組んだ末に最尤推定することがあるけど、ああいうのはどっちなんだろう?
2014年7月 7日 (月)
Zhang, Z., Hamaker, E.L., Nesselroade, J.R. (2008) Comparisons for four methods for estimating a dynamic factor model. Structural Equation Modeling, 15, 377-402.
いわゆる動的因子分析のうち、測定モデルにはラグがはいらないが因子が自己回帰するモデル(direct autoregressive factor score model; DAFSモデル)の推定方法を比較しました、という論文。えーと、時点 $t$ における観察変数のベクトル $y_t$ について
$y_t = \Lambda f_t + e_t$
$f_t = \sum_s B_s f_{t-s} + v_t$
という感じのモデルである。
比較する推定方法は次の4つ。
- KF: 状態空間表現に書き換え、カルマン・フィルタをつかって最尤推定。延々アルゴリズムが説明されている... やめて、死んじゃいそう...
- BT: ブロック・トープリッツ行列を起こして最尤推定。そもそもブロック・トープリッツ行列とはなにか、というところからはじめて、実はここでの最尤推定は独立性の仮定に反していて、まあ大丈夫だといわれているんだけど適合度指標はあてにならなくて、とかなんとか ... やめて、死んじゃううう...
- BE: Gibbsサンプリングでベイズ推定。なにをどうサンプリングするか云々と、これまた延々と説明されていて... 死ぐぅぅぅぅ...
- LS: Browne & Zhang が唱えた最小二乗推定。いい加減にしねえかこの野郎。
というわけで、中身はよくわかっていないのだが、いいよもう!一生パッケージユーザのまま生きていくから!
で、シミュレーション。2因子6指標ラグ1のモデルで、時系列の長さと測定誤差分散を動かす。細かいところは読み飛ばしたが、KFはDolan(2005)のMKFM2というプログラム、BTはDFAというプログラムで行列を作ってMplusで推定、BEはWinBUGS、LSはBrowne & Zhang のDyFAというプログラムを使った由。探したところ、コードをこちらに公開しておられる。
結果は... いろいろ説明してあるけどパス。要するに、どれでもまあ似たようなもんなので、あなたが使いやすい奴を使いなさい、とのことであった。
読了: Zhang, Hamaker, & Nesselroade (2008) 動的因子分析の地上最強の推定方法はどれだ
2014年7月 6日 (日)
Molenaar, P.C.M., Ram, N. (2009) Advances in dynamic factor analysis of psychological processes. Valsiner et al.(eds), "Dynamic Process Methodology in the Social and Developmental Sciences." Chapter 12.
先日読んだDu & Kamakura でお勧めされていた、動的因子分析についてのレビュー。苦手分野なので、メモを取りながら読んだ。
著者らいわく:
心理学における統計的分析は、ふつう標本における個人差の構造を分析しそれを母集団に一般化するわけだけど[←スキナリアンの方は異論がおありでしょうね]、それらは対象者の等質性という想定に依存している。この想定は古典的エルゴード定理に基づいている。(←ここで放り投げて寝ちゃおうかと思ったけど、我慢我慢)
たとえば時間に注目しよう。心理学が探求しているのは、知覚、感情、認知、生理、などの下位システムを含む高次元の動的システムである。システムの振る舞いを特徴づける時間依存変数の集合は、ある高次元空間における座標として表現できる。この空間のことを行動空間と呼ぼう。
行動空間において個人間変動は以下のようにして定義される:
- 変数の固定された下位集合を選択し、
- 固定された測定時点をひとつないし複数個選択し、
- その変数のその時点の得点の、対象者を通じた変動を決定する。
これに対し、個人内変動は以下のように定義される:
- 変数の固定された下位集合を選択し、
- ある固定された対象者を選択し、
- その変数におけるその対象者の得点の、時点を通じた変動を定義する。
前者はCattellいうところのRテクニック、後者はPテクニックである。
プロセスが定常で(つまり平均が一定で系列的依存性が時間不変)、かつそれぞれの個人が同一のダイナミクスに従っているとき、このプロセスはエルゴード性があるという。Rテクニックの結果とPテクニックの結果に法則的な関係が生じるのは、エルゴード性が満たされているとき、そのときに限られる。これが古典的エルゴード定理である。
古典的エルゴード定理は心理学における統計手法すべてに影響する。たとえば、発達過程は定常でない。研究者は平均における変化について考えるが、本当は変化というのは分散や系列的依存性のなかにひそんでいるのかもしれないのだ。
さて、動的因子分析とは単一の被験者の多変量時系列の因子分析である。これはCattellのPテクニックの一般化である。Pテクニック因子分析についてはMolennar & Nesselroade (2008, MBR)をみよ。
時点 $t$ における $p$ 個の変量のベクトル $y(t)$ について考える。時点 $t$ におけるその平均を $E[y(t)] = \mu(t)$ とする。時点$t_1$と$t_2$の系列共分散を $\Sigma(t_1, t_2) = cov[ y(t_1), y(t_2)' ]$ とする。$\mu(t)$が定数で、$\Sigma(t_1, t_2)$が $t_1-t_2=u $にのみ依存していたら、$y(t)$は弱定常であるという。
心理学において最初に動的因子分析を用いたのはワシじゃ(Molenaar, 1985)。あれは弱定常多変量ガウシアン時系列のモデルじゃった。
$y(t) = \mu + \Lambda(0) \eta(t) + \Lambda(1) \eta(t-1) + \ldots + \Lambda(s) \eta(t-s) + \epsilon(t)$
$\eta(t)$は$q$個の因子系列。$\Lambda(u)$は$(p,q)$行列でラグ$u$の因子負荷を表す。$\Lambda(0) \eta(t)$ から $\Lambda(s) \eta(t-s)$までの線形結合を畳み込みという。
なお、$s=0 $のケース、すなわち
$y(t) = \Lambda(0) \eta(t) + \epsilon(t)$
は状態空間モデルとかプロセス因子モデルとか言われておる。
共分散については
$cov[ \epsilon(t), \epsilon(t-1)' ] = diag-\Theta(u)$
$cov[ \eta(t), \eta(t-1)' ] = \Psi(u)$
と考えておった。$diag-A$ってのは正方対角行列のことね。
ちょっとややこしい話になるが、ラグの最大値 $s$ が$0$以上であり、かつすべての$\Lambda(u)$ を自由推定する場合、$\eta(t)$の共分散関数は識別できなくなる。そこでワシは
$cov[ \eta(t), \eta(t-1) ] = \delta(u) I_q $
とした。$\delta(u)$はクロネッカーのデルタってやつで、$u=0$のとき$1$, でなければ$0$である。つまり、$\eta(t)$はランダム・ショック、ないしホワイト・ノイズだとしたのである。もっとも他の定式化も可能である。Molennar & Nesselroade (2001, Psychometrika)をみよ。
いっぽう、ラグの最大値が$0$だったら(状態空間モデル)、ないし検証的なモデルで$\Lambda(u)$ が固定されていたら、$\eta(t)$の共分散関数は識別可能となる。このときは$\Psi(u)$を自由推定できる、ないし$\eta(t)$のパラメトリック時系列モデルを推定できる(自己回帰モデル $\eta(t) = B \eta(t-1) + \zeta (t)$ とかね)。
状態空間モデルを考えちゃうのは都合は良いが、$\eta(t)$が$y(t)$に及ぼす効果が遅延している場合には不適切で、お勧めできない。いっぽう、$\eta(t)$と$y(t)$のあいだにあんまりヤヤコシイ関係を考えなくてもいい。(実例省略)
こういう定常多変量ガウシアン時系列モデルを推定する方法はいろいろあって:
- ブロック・トープリッツ行列に基づく方法。そのへんのSEMのソフトで推定できる。またBrowne & Zhang はDyFAというプログラムを作っていて、これはブロック・トープリッツ行列を使わず、自己相関関数に直接フィッティングする。
- 状態空間モデルだったら、ローデータの尤度についてのEMアルゴリズムという手がある。Hamaker, Doran, Molenaar(2005,MBR)とか。
- 離散フーリエ変換を使い、一連のfrequency-dependent complex-valued factor modelを作る(←???)。これは通常の最尤法因子分析で推定できる。
- 潜在因子系列だけではなく未知パラメータを含む状態空間モデルに書き直して拡張カルマンフィルタを使う。
ここで動的因子分析のイノベーティブな応用をご紹介しよう。複数の対象者から得た多変量時系列を使い、個人記述的な観察から法則定立的な関係性を導き出すのだ。(→以下、ご自身の研究の紹介。妊娠中の気分の変化の分析。ブロック・トープリッツ行列を使う。原論文がどれなのかいまいちはっきりしないんだけど、たぶんNesselroade, et al.(2007, Measurement)。省略)
さあ、こんどは定常性の問題を考えよう。定常性をどうやって検証したら良いか、また非定常系列をどうモデル化するか。
状態空間に基づき、こう考えよう。
$y(t) = \Lambda[\theta(t)] \eta(t) + v(t)$
$\eta(t+1) = B[\theta(t)] \eta(t) + \zeta(t+1)$
$\theta(t+1) = \theta(t) + \xi(t+1)$
$\theta(t)$は長さ $r$ の時間変動パラメータ・ベクトルで、ガウシアン・ホワイトノイズ $\xi(t)$ によってランダム・ウォークする。因子負荷も自己回帰ウェイトも $\theta(t)$ に依存する。共分散行列は以下の通りとする。(←なんでこんなややこしい記号の振り方をするんですかね。$\xi$の共分散を$diag-\Xi$にすりゃいいのに)
$cov[ v(t), v(t-u)' ] = \delta(u) diag-\Xi$
$cov[ \zeta(t), \zeta(t-u)' ] = \delta(u) diag-\Psi$
$cov[ \xi(t), \xi(t-u)' ] = \delta(u) diag-\Phi$
推定にはEMアルゴリズムと拡張カルマンフィルタを使う... (略)。シミュレーションの結果を見てくれたまえ... (略)。
まとめ。動的因子分析の将来はチャレンジングである。非エルゴード的な心理過程の研究においては、古典的エルゴード定理により、個人内変動の構造に焦点を当てなければならんからである。云々、云々。
いやー、Molenaar先生という方の癖なのかもしれないけど、ちょっと肩肘張った感じの文章で辛かった。
いちばん勉強になった点は... Molenaar先生に由来するといわれているタイプの動的因子分析では、潜在変数と観測変数の間にラグ付きのパスをひきまくり、たくさんのパス係数(因子負荷)を推定するのだけれど、しかし潜在変数の時系列には構造を考えない。これは「しょせん人間なんて根っこのところでは定常で、変動なんてただのホワイトノイズさ、でも指標においていろいろ遅延が生じるせいで、見た目上複雑な時系列的連関を示す多変量時系列が生まれちゃうのさ」というシニカルな視点があるのかと思っていた。なんというか、強力な仮定の下での分析だなあ、という印象だったのである。
でもこの論文での説明をみる限り、まず最初に「観測変数がそれぞれ異なる遅延を抱えている」という実質的な信念があって、それを探索するためにとりあえず時系列構造のない潜在変数系列を考えるけど、でもそれは方便で、もし遅延の構造について見通しが立ったら、因子負荷行列に検証的な制約を与え潜在変数についての時系列モデルを組むのも良い... という感じだ。いやー、なんか君のことを誤解してたような気がするよピーター。(←大きな態度)
読了:Molenaar & Ram (2009) 動的因子分析レビュー
2014年6月28日 (土)
Du, R.Y., Kamakura, W. (2012) Quantitative Trendspotting. Journal of Marketing Research, 49, 514-536.
我にGoogle Trend かそんな感じのなにかを与えよ。さすれば動的因子分析(DFA)によって消費者トレンドを抽出してごらんにいれよう... という論文。
魅力的な題名に惹かれてざっと目を通していたのだけど、都合によりきちんと読みなおした。いやあ、これ、面白い。
まずはDFAを使った研究のレビュー。実用例は少ないという印象があったのだが、やはり少ないっす。
- もともとDFAは計量経済学から出てきたのだそうだ。知らなかった。Gweke (1977), Engle & Watson (1981, JASA), Harvey (1989, 書籍), Litkepolh(1991, 書籍"Introduction to Multiple Time Series Analysis") が挙げられている。
- 計量心理では、Molenaar(1985,Psychometrika)が早い。ある対象者の複数の生理指標の時系列分析に使った由。ほかにMolenaar, Gooijer, Schmitz(1992,Psychometrika).
- Zuur, et al.(2003, Environmetrics): 生物・環境系の多変量時系列から、共通の軌跡を見つけるという話だそうだ。
- Ludvigson & Ng (2007, J.Financial Econ.): 株式市場の研究。あー、そうか。いかにもありそうな話だ。
- Aruoba, Diebold, Scott (2009, J.Business & Econ. Stat.): ビジネス環境についてのaggregateレベルでの多変量時系列をリアルタイムで追いかけて... という話らしい。ほへー。
- Doz & Lenglart (2001): これもリアルタイムの話。欧州の産業調査から得た30本の時系列を一因子DFAで追いかけ、周期変動を見つける。
著者は触れてないけど、社会心理方面ではDFAを使った研究がそこそこあるんじゃないかしらん。前にEmotionに載っているのを読んだことがある。前の前の職場でぼーっとしてた頃だ、懐かしい。
近年の進展については、Croux, et al.(2004, J. Econometrics), Molenaar & Ram (2009, 論文集)をみよとのこと。後者のほう、面白そう。
著者らいわく、マーケティング分野で使っているのを見たことがない由。そうなんですか?
著者らいわく、おおざっぱにいってDFAには二種類ある。
- ひとつは、状態空間モデルでいうところの観測方程式 (SEMでいう測定モデルね) は普通の因子分析モデルであって、時点 $t$ の観測値は時点 t の因子によって決まるのだが、状態方程式 (SEMでいう構造モデルね)のほうにラグがはいってくる、というもの。Engle & Watson, Zuur, et al. などがそうで、本論文もこのタイプ。
- もうひとつは、状態方程式のほうにはラグは入らず、観察方程式のほうにラグがはいるもの。例として、Sargent & Sims(1977), Forni et al(2000, Rev. Econ. Stat.), Stock & Watson(2002, J.Business & Econ. Stat.).
本研究で、なぜベクトル自己回帰(VAR)とかベクトル自己回帰移動平均(VARMA)を使わないのかというと、時系列の本数がやたらに多くなったときに耐えられないから。最近ではBayesian VARというのがあるけど、事前分布を決めるのが難しいし、本研究では共通のトレンド曲線を抽出するのが目的なのに、そういうのを出力してくれない。
で、著者らが開発したstructural DFA (SDFA) のご紹介。なんでstructuralかというと、構造モデルのほうを単なる自己回帰とかにしないで、計量経済でいうところの構造的時系列分析をやるからだ、との仰せである。あああ、苦手な話になってきた...
時点 $t$ における、$n$ 個の指標のベクトルを $y_t$ とする。これを次の順に分解する。
- $y_t = B + L f_t + u_t$. $f_t$が因子のベクトルである。$u_t$ は平均$0$, 分散$\Sigma_u$の正規分布。以下、誤差項については同様なので省略する。
- $f_t = \alpha_t + \gamma_t$. $\alpha_t$はトレンド要因、$\gamma_t$が季節要因。
- $\alpha_t = \alpha_{t-1} + \beta_{t-1} + \epsilon_t$. でました、一次ラグの登場です。$\beta_t$ がトレンドの傾きである。
- $\beta_t = \beta_{t-1} + \delta_{t-1} + \eta_t$. $\delta_t$ はトレンドの傾きの変化。
- $\delta_t = \delta_{t-1} + \zeta_t$. やれやれ、やっとランダムウォークになりました。
- $\gamma_t = -\sum_{j=1}^{s-1} \gamma_{t-j} + \xi_t$. 変形すると$\sum_{j=0}^{s-1} \gamma_{t-j} = \xi_t$, つまり任意の$s$期を足しあげると期待値$0$になるわけで、なるほど季節要因である。
いまここで、$\gamma_t$ を取っ払い、3本目を単純化して$\alpha_t = \epsilon_t$ としたら、これは通常の因子分析である。$\alpha_t = \alpha_{t-1} + \epsilon_t$ としたら普通のDFAである。
分析例。Google Trendで、自動車ブランド38個のUSでの検索数の、約6年間の時系列曲線を取得。推定手続きは付録を読めとのこと、一応めくってみたが、カルマンフィルタとか出てきて頭痛くなりそうなのでパス。BICでもって7因子解を採用。バリマクス回転。
因子の解釈は順に、
- 「外国車マス」(ホンダ、ニッサン、トヨタ、VW, Miniなど)、
- 「米国車マス」(シボレー、フォード、クライスラーなど)、
- 「欧州車高級」(ポルシェ、MB, BMWなど。ニッサンのインフィニティも負荷が高い)、
- 「GM車の生き残った奴」(ビュイックなど)、
- 「レクサス」(レクサスが正の負荷、Ramが負の負荷を持つ)、
- 「スバル」(スバルが正の負荷、マツダとサターンが負の負荷を持つ)、
- 「GMの打ち切られた奴といすず」(サーブ、ハマー、いすずなどが正の負荷、ヒュンダイ、キア、スズキが負の負荷を持つ)。
うーむ、負の負荷ってのはなかなか解釈が難しいっすね。
\alpha_t をみると、経済情勢からみていかにもそれらしい曲線になっている...云々。因子7は低落のトレンドにあって、つまりいすずの検索数が減るのと裏返しに韓国車とスズキの検索数が増えているわけである。$\beta_t, \delta_t$ に分解して観察すると...云々。
綺麗に分解しているので今後を予測するのも簡単で、ホールドアウトの予測は、ARIMA, VAR(1), Bayesian VAR(1)より良かった由。とはいえ、これは使ったデータがこの手法向きだったということだろう。著者らも、将来予測は主目的ではないし、ARIMAみたいな手法のほうがうまくいくこともあるだろう、と述べている。
各ブランドの実際の月次売上を説明してみると、そのブランドの検索数で説明するより、7因子を全部使った回帰式で説明したほうが、決定係数が劇的に高い。なるほどねえ、これは面白いなあ。著者らいわく、これは自分たちもちょっとびっくりで、一般化できるか要検討だとのこと。
トレンドへのショック、すなわち$\epsilon_t$を見てみると、数か所だけ0から大きく離れる箇所がある。たとえば、「米国車マス」と「GM車の生き残った奴」が2005年6月ごろにどーんと正に振れていて、ちょうどこの時期に大規模な割引があったのだそうだ。直後に負に振り戻しており、つまりは売上を先食いしたのでしょう、とのこと。
さらには、\alpha_tを失業率、ACSI, ガソリン価格などで説明するモデルを組んで、インパルス応答関数を出したりなんかして... ガソリン価格が上がると米国車マスは下がり外国車マスが上がるが、どちらも2か月しか続かない、とか... 個別の検索数の残差項 u_t の曲線の形状も個々の会社の事情でいちいち説明できるとか...
いやあ、もうお腹一杯です。さすがはアメリカの研究者、肉食ってる人は違うなあ。
というわけで、ものすごく!面白い論文であった。仕事でこういうものすごく大きなパネルデータを扱うことがあるのだけど、DFAを探索的に使う、というのは不思議なくらいに思いつかなかった。DFAって因子負荷については確認的に制約するのだという気がしていたのだ。
あれこれ応用を思い浮かべて、読み進めるのに困るくらいだったのだが、あまりに仕事に密着しすぎているので、ちょっとここには書けない。
文系読者ならではの素朴な疑問としては... もしこういう分析を明日までにやれといわれたら、まず時点xブランド名の行列を素直にEFAにかけ、得られた因子得点についてやおら時系列分析を始めるだろう、と思う。もちろんパラメータ推定や標準誤差の推定にはバイアスがかかるだろうけど、それはいったいどのくらい深刻なのだろうか。直感的には、個々のブランドの独自性が小さく、因子数が正しく、かつ因子数がブランド数に対して十分に少なければ、こういう二段階作戦でもたいして問題なかったりしませんかね... そんなことないですかね?
さらなる素朴な疑問として... データの性質によるとは思うけど、季節変動の分離は因子分析の前にやった方がよかないか。 たとえばメーカーの決算期を反映した季節変動があるかもしれないし。そんなので因子が形成されちゃったらたまんない。
それから... 著者も最後に述べているけど、因子構造が変わっちゃったことにどうやって気が付くか、という問題は面白いなあ。誰か頭の良い人が考えてくれるといいんだけど。
論文の内容からは離れるけど、こういう多変量時系列から因子を抽出するのがアリならば、潜在クラスを抽出するのもアリだろう。全然気がつかなかったけど、もっと時点数が少なくて本数が多いパネルデータに、LCGMなりGMMなりを適用する、というのもオオアリだし、 McArdleのLDSMなんてまさにぴったりだ。具体的にはいいにくいけど、そういうデータ、メーカーのマーケターもある種の調査会社のみなさんも、毎日触っているではないか。
私はある時期、朝から晩まで子どもの学力の成長モデルのことばかり考えて過ごしていたことがあるので、この種の視点には相当アンテナが立っている方だと思っていたけど、恥ずかしながら、この論文は目から鱗であった。いやあ、良い研究というのは素晴らしいものである。
読了:Du & Kamakura (2012) 多変量時系列のなかに消費者トレンドをみつける
2014年6月24日 (火)
Grun, B., Hornik, K. (2001) topicmodels: An R package for fitting topic models. Journal of Statistical Software, 40, 13.
Rの topicmodels パッケージの解説。ぱらぱらめくっただけだけど、整理の都合上読了にしておく。
細かいことだけど、モデル選択のくだりで説明されているperplexityについてメモ(これ、訳語はあるのかしらん?)。単語集合$w$のperplexityは
$Perplexity(w) = \exp \{ - \log(p(w)) / \sum_d \sum_j n^{(jd)} \}$
$n^{(jd)}$というのは文書dで語jが出現する回数。ホールドアウトした$w$に対してperplexityが低いとありがたい。ふうん。要するに、語の尤度を均して負にしたようなもんだろうな。
読了: Grun & Hornik (2001) topicmodels パッケージ
2014年6月17日 (火)
Muthen, B., & Asparouhov, T. (Forthcoming) Causal effects in mediation modeling: An introduction with applications to latent variables. Structural Equation Modeling.
Muthen先生、哀れなSEMユーザたち向けに、近年の因果推論研究に基づく、媒介変数があるときの因果効果の推定について解説するの巻。と同時に、先日リリースされたMplus 7.2の新機能、MODEL INDIRECTセクションにおける MOD 文右辺のカッコ指定についての紹介でもある。
近年の因果推論研究ってのは、counterfactualな概念が出てくるというような意味合いではないかと思うのだけれど...。Robins, Greenland, Pearl, VanderWeele, Vansteelandt, Imai ほかの研究、とある。(←これ、どういう順序かしらん。年齢の高い順だったりして、ははは)
さあ、導師が誇る素人向け説明パワーが火を噴くぞ、と期待したのだが、目を通した限りでは、ちょっとわかりにくい。草稿だからかもしれない(誤字もあるし)。途中でちょっと混乱してしまったので、Appendixを参照して話を先取りしておくと、要するにこういう話である。
処理条件と統制条件を比較する実験を考える。 アウトカム Y は処理の有無 x の関数と考えられるので、Y(x) と書く。処理の総合効果とは、共変量を固定した下での(←以下省略)、Y(処理) の期待値と Y(統制) の期待値との差である。
さて、媒介変数 M があるとしよう。Yは処理の有無とMの関数で、Mもまた処理の有無の関数である。総合効果は Y(処理, M(処理)) の期待値と Y(統制、M(統制))の期待値との差である。ではここで間接効果とはなにか。
ふたつの考え方がある。ひとつは Y(処理, M(処理)) の期待値と Y(処理, M(統制)) の期待値との差だという見方で、Muthen先生はこれを total の間接効果と呼ぶ。もうひとつは、Y(統制, M(処理)) の期待値と Y(統制, M(統制))の期待値の差だという見方で、先生はこれを pure の間接効果と呼ぶ。
些細な違いというなかれ、場合によっては、これは実質的な違いを生むのだ。
本文に戻ると ... まずは、問題を直観的にわかりやすい形でご説明します、とのこと。
例1, 処理変数-連続媒介変数の交互作用。
次のようなモデルを考える。外生二値変数 $x$ から 連続変数 $m$ にパスが刺さっており (係数 $\gamma_1$), $m$ から 連続変数 $y$ にパスが刺さっている($\beta_1$)。また、$x$ から直接 $y$ に刺さるパスもある ($\beta_2$)。ランダム化統制試験で処理の効果を媒介する変数があるというような場合だ。さらに、$y$ に対して $m$ と $x$ の交互作用効果がある($\beta_3$)。嫌なモデルだが、まあ現実的ではある。
$x$ で条件づけた $y$ の期待値は、$m, y$ の切片をそれぞれ $\gamma_0, \beta_0$ として
$E(y | x) $
$= \beta_0 $
$+ \beta_1 \gamma_0$
$+ \beta_1 \gamma_1 x $ (←A)
$+ \beta_3 \gamma_0 x$ (←B)
$+ \beta_3 \gamma_1 x^2$ (←C)
$+ \beta_2 x$ (←B)
上式の C の項は、$\beta_3 m x$ の $m$ に $\gamma_1 x$ を代入したものである。
さあ、$x$ の $y$ に対する間接効果と直接効果はどうなるでしょうか。
上式の項のうち A は、$m$ を経由しているパスに対応しているから、これは間接効果である。またBは、$m$ を通っていないから、これは直接効果である。問題はCだ。ふつうに考えれば間接効果だが ($m$ を通っている面があるから)、$m$ によって引き起こされている効果だけを間接効果というのだ、という観点からは直接効果である ($m$ を通っていない面もあるから)。
項Cを含めた間接効果を Total Natural Indirect Effect (TNIE), 含めない間接効果を Pure Natural Indirect Effect (PNIE)という。また項Cを含めた直接効果をPure Natural Direct Effect (PNDE), 含めない直接効果を Total Natural Direct Effect (TNDE)という。もちろん
Total Effect = PNDE + TNIE = TNDE + PNIE
である。
例2, 上のモデルで、$y$ が二値だったとき。
例によって、二値変数 $y$ の裏には連続潜在変数 $y*$がいて、$y*$がある閾値を超えたら $y=1$になるのだと考える。これは $y$ のプロビット回帰モデルだと考えてもロジスティック回帰モデルだと考えてもいい (誤差分布についての仮定のちがいにすぎない)。
話を簡単にするために、交互作用項を取り払って
$E(y* | x) = \beta_0 + \beta_1 \gamma_0 + \beta_1 \gamma_1 x + \beta_2 x$
$V(y* | x) = \beta^2_1 \sigma^2_2 + c$
ここで $\sigma^2$ は $m$ の残差分散。$c$ は $y$ の残差分散で、プロビット回帰では1, ロジスティック回帰では $\pi^2/3$ と仮定される。面倒なので、以下プロビット回帰についてのみ考える。
さて、効果の定義は結構ややこしい。従属変数は $y*$ だ、と割り切っちゃえば話は簡単である。SEMユーザはふつうそう考えますね、ロジスティック回帰モデルの偏回帰係数に注目するわけだから。でも、因果効果の研究者は、従属変数が $y$ だというところにこだわる。すると、標準正規分布関数を $\Phi$ として
$P (y = 1 | x) = P(y*>0 | x) = \Phi[ E(y*|x) / \sqrt( V(y* | x) ) ] $
と、やたらにややこしくなる。
$E(y* | x)$ のみに注目して、
$x = 1$ のとき、$\beta_0 + \beta_1 \gamma_0 + \beta_1 \gamma_1 + \beta_2 $
$x = 0$ のとき、$\beta_0 + \beta_1 \gamma_0 $
この差が総合効果である。問題は間接効果だ。
$x = 1$ のとき、$\beta_0 + \beta_1 \gamma_0 + \beta_1 \gamma_1 $
$x = 0$ のとき、$\beta_0 + \beta_1 \gamma_0 $
この差が間接効果だという見方と、
$x = 1$ のとき、$\beta_0 + \beta_1 \gamma_0 + \beta_2 + \beta_1 \gamma_1 $
$x = 0$ のとき、$\beta_0 + \beta_1 \gamma_0 + \beta_2 $
この差が間接効果だという見方ができる。どちらも差は $\beta_1 \gamma_1$ でしょう? と思うところだが (ここですごく混乱した)、今問題にしているのは期待値そのものの差ではなく、それらを標準正規分布関数に放り込んで得た確率の差なので、どちらの見方をとるかによって話が変わってくるのである。前者の定式化がPNIE, 後者の定式化がTNIEである。
例3はYがカウントだったらという話(省略)。いったいなにを説明しようとしているのか、ここまで読んでようやくわかってきた...。いわゆる間接効果と直接効果というのが意外にあいまいな概念なので、反事実的な概念を用いて、PNIEとTNDEとして再定義しているのだ。
フォーマルな議論に突入。
対象者 $i$について、処理変数 $X$ と 媒介変数 $M$がそれぞれ $x, m$ にセットされたときの潜在的アウトカムを $Y_i (x, m)$ とする。実際には、$i$ についていろんな $x, m$ の下でのアウトカムを観察できるわけではないので、これは反事実的な概念である。
直接効果の定義について考える。簡略のため $x$ は0 ないし 1とする。
- controlled direct effect: $CDE (m) = E[ Y(1,m) - Y(0,m) ]$. 媒介変数がなんらかの値に固定された状態での処理の効果だ。行動科学ではあまり役に立たないが、政策評価においては意味を持つことがある由(うーん、どういう場面だろう)。
- pure natutal direct effect: $PNDE = E [ Y(1, M(0)) - Y(0, M(0)) ]$. 処理がなされたけど、(なんらかの理由で)媒介変数は変わらなかった、という場合の処理の効果。なるほど。
- total natual direct effect : $TNDE = E [ Y(1, M(1)) - Y(0, M(1)) ]$.
対応する間接効果の定義を考える。
- total natural indirect effect: $TNIE = E[ Y(1, M(1)) - Y(1, M(0)) ]$. 「処理はなされたけどなんらかの理由で媒介変数が変わらなかったとき」をベースラインにとった処理の効果である。PNDEと足すと総合効果になる。
- pure natual indirect effect: $PNIE = E[ Y(0, M(1)) - Y(0, M(0)) ]$. TNDEと足すと総合効果になる。
以上を上記の例1, 例2に当てはめて説明している。メモは省略。
後半は、$X, M, Y$ が潜在変数である場合の話。
媒介変数が潜在変数だと何が起きるか。媒介変数が単一の観察変数(測定誤差を含む) である場合、複数の観察変数の合計である場合、複数の観察変数で測定される潜在変数である場合、を比較するモンテカルロ・シミュレーションを紹介。項目の信頼性と項目数を動かし、TNIE, PNDEの推定バイアスを調べている。信頼性が低いとTNIEは小さめ、PNDEは大きめに歪む。複数の項目を足しあげても少ししか改善しない。しかし潜在変数にするとこのバイアスを取り除くことができる。
ほかに実際のランダム化フィールド実験データの再解析例が載っているけど、パス。
というわけで、SEMユーザの諸君、因果推論研究を学びなさい、勉強になりますよ。それから測定誤差には気をつけなさい。という論文であった。ハハァー、勉強になりましたですー(平伏)。
読了: Muthen & Asparouhov (Forthcoming) SEMユーザの諸君に贈る、直接効果・間接効果への反事実的アプローチ
2014年4月 2日 (水)
Millsap, R.E. (2007) Invariance in measurement and prediction revisited. Psychometrika, 72, 4, 461-473.
あいまいな記憶なんだけど、しばらく前に著者が学会で来日した際、測定不変性と予測不変性はふつう両立しない、これすっごく大事な話なのになぜかみんなわかってない、あたしの論文が難しすぎたんじゃないかと反省している、みんなも反省するようにね、というような内容を喋っておられた。場内は結構盛り上がっていたんだけど、私は前提になっている「大事な話」がよく理解できず、ぽかんとしていた。
でもそのことはなんとなく心に残っていて、Millsapさんの最近の著書にも目を通したのだけれど、やっぱりこの点についてはよく理解できなかった。このたび整理のついでに、論文のほうに再挑戦。
指標群Xと潜在変数との間の群間測定不変性と、そのXのなかにはいっている変数同士の回帰モデルにおける係数の群間不変性は、ふつう両立しない、という話である。そういうもんか...
で、そうなる理由についての説明を小一時間かけて頑張って読んだけど、学力不足のせいか、なにか見落としているのか、やっぱりどうしても理解できなかった。一行一行は難しい話ではないのに。とても残念だ。
でもまあ、この論文の主旨はあの講演と同じく「すでにこのことを指摘してるのになんでみんな理解してくれないの」という点にあるので(難しいからだと思いますよ、先生!!)、前の論文を読めばきっとわかるのであろう。そう信じたい。Millsap(1995, MBR), Millsap(1998, MBR) というあたりを読めばいいらしい。でも、すいません、とりあえず他の著者のを探します。
読了:Millsap(2007) 測定不変性と予測不変性は両立しないことをなぜみんなわかってくれないのかしら
2014年3月26日 (水)
いわゆる「ウェイト・バック集計」、すなわち確率ウェイティングの下でデータ集計を行ったとき、ついでに平均や割合の差について検定をしようとすると、標準誤差はどうやって求めるのかという問題が生じる。確率ウェイトがごくシンプルなデザインに由来している場合は簡単で、たとえば層別一段抽出で層サイズが大きい場合であれば、層ごとに求めた標準誤差を合成すれば済むだろうと思うのだが、往々にして層は小さくウェイトは複雑である。テーラー展開か、リサンプリングか、はたまたロバスト推定か。ああ、嫌だ嫌だ、どうしたなら検定も信頼区間もない、静かな、静かな、データも何もぼうつとして物思ひのない處へ行かれるであらう (by 樋口一葉)。
ところがある種のソフトウェアを見ていると、ややこしいことを考えないで、いわゆる有効ベース(この論文でいう等価標本サイズ)という考え方に基づき、あっさり検定統計量を修正してしまうものがある。ケースに付与されたウェイトの相対分散に応じて、標本サイズを一律に割り引いてしまうのである。わかりやすくていいけれど、でもそれってどうなの? というのが、ずっと疑問であった。
Potthoff, R.F., Woodbury, M.A., Manton, K.G. (1992) "Equivalent sample size" and "Equivalent degrees of freedom" refinements for inference using survey weights under superpopulation models. Journal of American Statistical Association, 87(418), 383-396.
というわけで、当該のソフトウェア(名前を挙げちゃうと、SPSS Data Collection)のマニュアルで引用されている論文。何年も前から積んであったのだけど、ここんところ確率ウェイティング関連の資料をめくっていたので、ついでに目を通しておくことにした。こういう話題は、いったん飽きたら本当に面倒になってしまうから。
まず、概論。
超母集団(母集団の母集団)という概念を導入する。この観点からいえば、確率的変動性(とでも訳せばいいのかしらん。stochasticity)にはふたつのソースがある。(1)超母集団の確率構造によって仮定されたもの。たとえば測定の変動性。(2)調査プロセスにおけるランダム化選択によって導入されたもの。つまり、仮に全数調査を行ったところで(1)は残り、推定量の分散は0にならないわけだ。
サイズ $N$ の有限母集団からのサイズ $n$ の標本を考える。個体 $i$ のウェイトを $W_i$ とする。その由来は問わないけど、確率変数ではなく固定されていると考えることにする(そうしないとややこしくなるから)。合計を$W_{sum}$とする。
いま、個体 $i$ の測定値 $y_i$ について
$m_i = E( y_i ) $
$v_i = var( y_i ) $
と考える。さらに、
$m = (1 / W_{sum} ) \sum_i W_i m_i $
$v = (1 / \sum_i W^2_i) \sum_i W^2_i v_i$
とする。$m$ の推定量
$\hat{m} = (1/ W.) \sum_i W_i y_i $
について考えよう。その分散は
$var(\hat{m}) = (\sum_i W^2_i / W^2_{sum}) v$
さて、上記4本の式を書き換える。まず、ウェイト値の合計の二乗をウェイト値の二乗の合計で割って
$\hat{n} = W^2_{sum} / \sum_i W^2_i $
ウェイト値の合計をいったん1にし、これにこの値を掛けて、新しいウェイト値をつくる。
$w_i = (\hat{n} / W_{sum}) W_i$
すると、4本の式はそれぞれ
$m = (1 / \hat{n}) \sum_i w_i m_i$
$v = (1 / \hat{n}) \sum_i w^2_i v_i$
$\hat{m} = (1 / \hat{n}) \sum_i w_i y_i$
$var(\hat{m}) = v / \hat{n}$
となる。このように、$\hat{n}$ は「等価標本サイズ」とでも呼ぶべきものになっている。なるほどねえ、鮮やかなものだ。
$v$ の推定量としては
$\hat{v} = 1 / (\hat{n} - 1) \sum_i w_i (y_i - \hat{m})$
を使えばいいんだけど、これが $v$ の不偏推定量になるのは、$v_i = v$ かつ $m_i = m$ のとき、つまり個体が等質なときである。そうでない場合、$E(\hat{v})$は $v$ より大き目、つまり保守的な推定量になる。
信頼区間を求めたり検定したりする際には、自由度も修正しないといけない(ああ、そうか...)。どうやるのか延々説明してあるんだけど、面倒なので省略。そのほか、$v_i$ が変動している場合に $E(\hat{v})$ がとる範囲、$y_i$ が二値だった場合はどうなるか、などなど。省略。
以下、各論。$v_i$ がなにか別の変数に比例していたらどうか。クラスタ抽出の場合はどうか。事後層別の場合のウェイト値の決め方。クラスタ抽出と事後層別の両方の場合はどうか。層別抽出の場合に限定したもっと良い方法。一元配置分散分析。$k \times 2$ 対応表での $k$ 群の等質性の検定。全部適当に読み飛ばしました。ごめんなさい、疲れました。
というわけで、超母集団という概念に基づき、確率ウェイトつきデータを簡単に集計・分析するための「等価標本サイズ」「等価自由度」の求め方が示されているわけだが、細かい理屈はとても面倒そうなのであった。でもまあ、母集団分布についての一切の仮定抜き、というところは気分がいいですね。他の標準誤差推定と比べるとどうなのか、知りたいものだ。
細かい話だけど、当該のソフトは標本サイズだけでなく自由度も修正してんのか、という点が気になった。マニュアルではどうもよくわからない。
読了:Potthoff, Woodbury, Manton (1992) 調査ウェイトつきデータの分析における「等価標本サイズ」「等価自由度」
2014年3月23日 (日)
人々がどこかにお出かけしたり、おいしいものを食べたり、立派なことを言ったりしている間に、暗がりでジミーな論文をジトジトと読んでいるのでありました。魅力的な人物とは言いがたいね。
Patterson, B.H., Dayton, C.M., Graubard, B.I. (2002) Latent Class Analysis of Complex Sample Survey Data: Application to Dietary Data. Journal of the American Statistical Association, 97(459).
えーと、複雑な標本デザインのデータについての潜在クラス分析(LCA)の方法を考えました、という論文。
アメリカには全国レベルでの食生活調査がいくつかあって、たとえば何日かにわたって、過去24時間に野菜を食べた回数を聴取したりしている。そこで、潜在クラス分析によるデータ縮約を提案したい。ところがそういう調査は標本抽出デザインが複雑だ。というモチベーションがある由。著者らいわく、LCAに標本抽出デザインを組み込んだ報告はこれまでに見当たらないが(そうなんですか?)、回帰分析ではすでにある、とのこと。Korn & Graubard(1999, "Analysis of Health Surveys")というのが挙げられている。
$J$ 項目の「食べた回数」設問への対象者 $i$ のベクトルを $Y_i$ とする。$j$ 番目の回答は 1から$R_j$までの離散値をとる。$L$個の潜在クラスを考え、$l$ 番目の潜在クラス $c_l$ のサイズを $\theta_l$ とし、そのメンバーが項目 $j$ に対して回答 $r$ を返す確率を $\alpha_{lkr}$とする。
通常の潜在クラスモデル (LCM) であれば、
$Pr(Y_i | c_l) = \prod_j \prod_r \alpha_{lkr}^{\delta_{ijr} }$
である($\delta_{ijr}$ は$y_{ij} = r$ のときに1, そうでないときに0)。対数尤度は
$\Lambda = \sum_i ln \sum_l \theta_l Pr(Y_i | c_l) $
上の式を放り込んで
$\Lambda = \sum_i \ln \{ \sum_l \theta_l \prod_j \prod_r \alpha_{lkr}^{\delta_{ijr}} \}$
シンプルだ。世の中の調査がみんな単純無作為抽出ならよかったのにね。
さてここで、対象者 $i$ がウェイト $w_i$ を持っている。疑似対数尤度は
$\Lambda = \sum_i w_i \ln \{ \sum_l \theta_l \prod_j \prod_r \alpha_{lkr}^{\delta_{ijr}} \}$
これを最大化する$\theta, \alpha$は母パラメータの一致推定量になることが示されている(Pfeffermann(1993) が挙げられている)。標準誤差の推定は難しくて(CSFIIのデザインにはクラスタも入っているので特に)、ごちゃごちゃ書いてあるけど、要するにジャックナイフ推定しますということなので、省略。実はそこんところが、この論文の売りらしいんだけど...どうもすいません。
実データへの適用例。Continuing Survey of Food Intakes by Individuals (CSFII) という調査のデータを使う。多段の層別抽出で、ケースにウェイトがついている。野菜を食べた回数を4日分聴取している。食べた/食べないの二値に落として、weighted, unweightedそれぞれで2クラス解を推定。「野菜食べないクラス」のサイズが、unweightedよりweightedのほうで大幅に小さくなった。とかなんとか。そのほか、デザイン効果(deff)で標準誤差の見当をつけちゃだめだとか、Wald検定しましたとか、いろいろ説明してあるけど、スキップ。標準誤差のジャックナイフ推定の妥当性を示すためにシミュレーションしているけど、スキップ。どうもすいません。
考察。ウェイティングすべきかせざるべきかという問題には長い歴史がある(以下を挙げている: Brewer & Mellor 1973; Smith 1976JRSS, 1984JRSS; Hansen, Madow, & Tepping 1983JASS; Fienberg 1989 in "Panel Surveys"; Kalton 1989 in "Panel Surveys"; Korn & Graubard 1995JRSS, 1995 Am.Stat.)。考慮すべき点は次の4つだろう:
- 目的は分析か記述か(←曖昧な言い方だと思うけど、どうやら共変量なしのLCMのような測定モデルを指して記述といっているらしい)。
- 要らないウェイティングをやっちゃったときのinefficiencyが、推定する効果に対して小さいか。
- ウェイティングしないときのバイアスの大きさ。
- 標本デザインについて十分な情報はあるか、また、ウェイティングせず標本デザインをモデル化するための変数が手に入るか。
云々、云々。。。
著者の先生方には大変申し訳ないんだけど、実はこの論文自体にはなんの関心もなくて、このあとのディスカッションが面白そうなので仕方なく読んだのである。この論文に対する4組の研究者によるコメントと、著者らによる返答がついている。主な論点をメモ。リングサイドよ、ゴングを鳴らせ!
- Carriquiry, A.L. & Nusser, S.M.のコメント:
- 食べた/食べなかったの二値に落とさないほうがいいんじゃない?
- クラス数を2にした根拠は? 「4変数しかないから」というのは答えになってない。なんか制約かければいいじゃん。
- 潜在クラスじゃなくて、「消費の確率分布」それ自体を推定するアプローチもあってよ?
- Elliott, M.R. & Sammel, M.D. のコメント:
- 食べた/食べなかったの二値に落とさないほうがいいんじゃない? クラス数も増やせると思うよ?
- こういうときは、個々の対象者についてクラス所属確率を求め、その分布を示すといい。(実際にやって見せて)ほら、weightedの結果のほうが、所属確率がきれいに分かれてるし、デモグラ特性と強く関連しているでしょう? (←親切なコメントだああ)
- ウェイティングするかしないかという風に二択で考えなくてもよい。ベイジアン・アプローチはどうよ(後述)。クラス数もチェックできるしさ。
- Seastrom, S.R.のコメント: ぜひ他の領域でもやってみてくださいな。教育とか。
- Latend Gold 開発元、Vermunt, J.K. さんのコメント。これがもう、たった1ページ強だけど、最凶の殴り込みなのである。
- そもそもウェイティングしないほうがいいんじゃないか(後述)。
- ウェイティングするとして、標準誤差の推定はジャックナイフ法じゃなくてロバスト推定量をつかったほうがよい。著者らは知らんようだが市販のソフトで算出できる。計算時間もかからない。
- すでに、ポワソン・サンプリングの下でのウェイティングつき対数線形モデルのML推定量が提案されている。潜在クラスモデルってのは不完全表の対数線形モデルなんだから、この方法が使える。実際試してみたら、著者らの推定値とほぼ同じ結果が得られた。さらに著者らの方法とちがい、モデルの適合度を標準的な方法で調べられる。尤度比検定をやってみたら、2クラス解は適合してなかったよ。
- 標本抽出デザインにクラスタが入っていたら、ふつうはランダム効果モデルを使うものだ。試してみなきゃ。(実際にやって見せて)著者らのデータではクラスタ間でクラス割合のちがいはなかったよ。
- データをよくみると、ちがう時点で4回聴取したってのは、実は同じ時点の6回の聴取のうち、各対象者は2回が欠損、ということなんですね。だったらそういう風に分析しなきゃ。(実際にやって見せて)ほら、季節効果があるのがわかるでしょう。
怖えーー! Vermunt怖えーー!
特に面白かった2つの指摘について詳しくメモしておく。まず、Elliott & Sammel のベイジアン・アプローチの話。
母平均の推測について考えよう。標本 $s$ が標本抽出デザインによって$H$個の層にわけられており、母集団における層のサイズはわかっているものとする。層 $h$ の位置パラメータ $\mu_h = E(y_{hi} | \mu_h)$ が、平均 $\mu$, 分散 $\tau^2$ の事前分布を持っていると考える。
$\tau^2=\inf$ のとき、個々の $\mu_h$ は固定された独立な量で、層を通じた情報の共有はなく、母平均 $E(\bar{Y} | y \in s)$ の事後平均は、完全にウェイティングされた平均推定量 $\bar{y}_w = \sum_i w_i y_i / \sum_i w_i$ で与えられる。
同様に、$\tau^2=0$ のとき、すべての $\mu_h$ は $\mu$ と同じことになり、$E(\bar{Y} | y)$ は全層をプールしたウェイティングされていない平均推定量で与えられる。
$0 < \tau^2 < \inf$ とすれば、$E(\bar{Y} | y)$ の推定量は、不偏性と分散最小性の間のトレードオフを調整したものになり、平均平方誤差を小さくすることができる。このように、事前平均と分散に構造を与えることで、バイアスと分散のトレードオフを手元にあるデザインとデータ構造に対してチューニングすることができる(Elliott & Little, 2000)。
このアプローチを拡張して、次の階層モデルを考える。二値の指標 $Y_{ij}$ について(※読みにくいので左辺を括弧でくくった)、
$(Y_{hij} | c_l, \alpha_{hlj}) \sim BERNOULLI(\alpha_{hlj})$
$(\alpha_{hlj} | c_l) \sim BETA(a_{lj}, b_{lj})$
$(c_l | \theta_{hl}) \sim MULTINOMIAL(1, \theta_{hl}, L)$
$(\theta_{hl}) \sim DIRICHLET(d_1, ..., d_L)$
云々。という風に、素知らぬ顔で階層ベイズモデルを持ち出す。なるほどね。でもちょっと面倒くさすぎる。。。
ふたつめ。Vermuntの原理的な批判。
彼らが示した事例において、weightedの解がunweightedの解よりもより良いと云っていいものかどうか、私にはよくわからない。
話を明確にするためには、潜在クラスモデルの2種類のパラメータを区別しておくことが大事だ。すなわち、潜在クラスの比率 $\theta_l$ と、項目の条件つき確率 $\alpha_{ijr}$ である。確かに、もし抽出ウェイトと相関する諸特性がクラスのメンバーシップとも相関していたら、$\theta_l$ のunweightedの推定値はバイアスを受ける。しかし注意すべきは、標準的な潜在クラス分析で得られた結果が妥当なのは、母集団が$\alpha_{ijr}$ について等質である場合に限られるという点である。仮にこの仮定が維持されているなら、$\alpha_{ijr}$ の推定の際に抽出ウェイトを使う必要はない。仮にこの仮定が維持されていないなら、抽出ウェイトを使っても問題は解決されない。$\alpha_{ijr}$ の異質性を、適切なグルーピング変数を導入した多群潜在クラス分析で取り扱わなけばならない。
weightedの分析では標準誤差が大きくなる。だから私はunweightedの$\alpha_{ijr}$のほうがよいと思う。unweightの$\theta_l$はバイアスを受けるかもしれないが、それは$\alpha_{ijr}$をunweightedのML推定値に固定した上で、潜在クラス確率を(たとえば疑似ML推定で)再推定すれば修正できる。
そうそうそう! まさにそう思うんですよ! 私が確率ウェイティングつきの多変量解析に対してふだん感じている違和感はまさにこれだ。ありがとうVermunt先生。やっと巡り会えたという感動でいっぱいです。
さて、著者らの返答。Vermuntの原理的批判に対する返答だけメモしておく。
一般に、モデルが「正しく」指定されているかどうかを知ることは不可能だ。仮に可能であったとしても、その「正しい」モデルはむやみに複雑で解釈困難かもしれない。モデルが間違っている場合、Vermuntの2段階アプローチは「センサス」モデル(仮に母集団全体が標本になっていたら得られていたであろうモデル)を推定していない。
これに対して、我々のweighted疑似尤度アプローチは、センサスモデルを推定している。このアプローチは、仮にモデルが間違っていても、異なる確率標本デザインからの推定値が平均してだいたい同じになるという利点を持っている。Vermuntの示唆する、まず等質な群を同定して項目の条件つき確率の異質性を取扱い次に多群潜在クラスモデルを用いるというやりかたは、現実性に欠け実行困難であるように思われる。
うーん... そうかなあ...
$\alpha_{ijr}$の異質性はないと信じる、というのはひとつの立派な考え方だと思う。異質性を正面からモデル化するというのも、実行可能性は別にして、もちろん立派な考え方だ。いっぽう、著者らの言い分はこうだ。「異質性があるかもしれないけど、まあそれは気にしないことにして、抽出デザインに起因するバイアスに対して頑健な推定値を求めましょう」。うーん、それってどうなんだろう...
彼らのアプローチは結局のところ異質性を無視しているわけだ。そのことによってミスリーディングな結果を得てしまう危険性は、ウェイティングしようがしまいが変わらない。この話、とどのつまりは、(異質性がないという前提が正しい場合の)標準誤差を犠牲にして、(前提が間違っている場合の)抽出デザインに対する頑健性を得たいですか? という問いに帰着するのではなかろうか。私の個人的な感覚としては、答えはNoだ...
もっとも、彼らのいう「センサス・モデル」つまり「単純無作為標本の下で推定されていたであろうモデル」に、常になんらかの認識的価値が認められるのならば(実際には異質性が存在するのにそれを無視してしまっていた残念な場合においてさえ!)、そのときには彼らの手法には価値があるということになろう。かつてわたくしの元上司様は、「それが現象理解や意思決定の役に立つかどうかを別にして、手続き的に正しい結果を提出すればよい、あとのことは知らない」という市場調査会社の姿勢を指してシニカルに「コンナンデマシタケド」と呼んでいて、笑ってしまったのだが、私がいま想像できないだけで、そういう姿勢が求められる場面もあるかもしれない。うーむ。
というわけで、「多変量解析での確率ウェイティングってなんなの?」というちょっとしたマイ・ブームのために、資料を手当たり次第にめくっていたのだけど、だんだん考え方が自分なりに整理できてきたような気がするので、そろそろ打ち止めにしておこう。
読了:Patterson, Dayton, Graubard (2002) 複雑な標本抽出デザインのデータに対する潜在クラス分析 (仁義なき質疑応答つき)
2014年3月21日 (金)
いわゆる「ウェイト・バック集計」関連の論文を集めてはパラパラめくる今日この頃である。ちょっと飽きてきた。
Asparouhov, T. (2005) Sampling weights in latent variable modeling. Structural Equation Modeling, 12(3), 411-434.
著者はMuthen導師の弟子でMplus開発チームの人。確率ウェイティングを伴う潜在変数モデルの推定について、Mplusがお勧めする疑似最尤法(PML)、LISRELなどで用いられている重みつき最尤法(WML)、そして重みつき最小二乗法(WLS)を比較する、という内容。Mplusといってもversion 3だけど。
主旨そのものは、ふうん... としかいいようがないんだけど、シミュレーションの部分が面白かったのでメモ。
まず本題のほう。
PMLもWMLも、重みつき対数尤度(ケースの対数尤度にケースのウェイトを掛けて合計したもの)を最大化するという点では変わらない。従ってパラメータ推定値は同一である。ちがうのは、推定量の共分散行列の推定方法である(なんだか超複雑な式がツラッと書いてあるけど、みなかったことにします)。よくわかんないけど、WMLというのは、まず重みつき標本統計量(平均と共分散)を求め、それに対してモデルを通常のML法でフィッティングするのと同じことなのだそうだ。本文の途中の説明では、「WMLというのは確率ウェイトをうっかり頻度ウェイトだと解釈したようなものだ」という記述もある。あー、なるほどね... これは目から鱗だ。
WLSというのはカテゴリカル変数に対しても使える奴。まず切片や閾値や傾きについてのみ重みつき対数尤度を最大化し、推定値を固定して次に相関について重みつき対数尤度を最大化し... という面倒な手順を踏んでいる由。
なおPMLとは、MplusでいうところのMLR推定量のことで、MLM, MLMVもこれに近い。WLSとはWLS, WLSM, WLSMV, ULSのこと。
いくつかのシミュレーションを紹介。最後に、成長モデルについてMplus(MLR推定量), MLwiN, HLMを比較している。SASのproc mixedはHLMと同じらしい。うーん、他のソフトのことは知らないけど、SASのproc mixedのweight文は確率ウェイトを意味していないことがあきらかだから(いわゆるanalytic weight、測定値の誤差分散の逆数だと思う)、フェアな比較なのかどうかわからないけど... とにかくMplusの推定値が一番よかった由。とはいえ脚注によれば、LISRELやHLMではその後のバージョンアップによってもっと良い出力が出せるようになったそうだ。
で、話をシミュレーションに戻すと... 一因子確認的因子分析(PML, WML)、潜在クラス分析(PML, WML)、カテゴリカル変数の一因子因子分析(WLS)、その「標本抽出がクラスタ抽出だったら」版(WLS), の4つについてシミュレーションする。まず適当な母集団モデルをつくって、つぎに標本抽出モデルをつくる、という手順。後者のモデルは、標本抽出の確率が指標によって決まるようなモデルである。どちらのモデルについても、パラメータをあれこれ動かしてみたりはしない、あっさりしたデモンストレーションなのだが、こんな選択バイアスがかかったら多変量解析の結果はどうなるでしょうか? という頭の体操として、面白く読んだ。
例題。連続変数5項目の一因子因子分析。真のモデルは、どの項目も負荷1, 切片0.3, 残差分散1, 因子分散0.8とする。で、ケースの抽出確率を1/(1+exp(-項目1))とする。項目1の値が高い人をオーバーサンプリングしているわけだ。ちなみにn=1000。さて、得られたデータをウェイティング抜きで因子分析する。項目1の負荷を1に固定して識別させる。さあ、推定結果はどうなるか? 昼飯後のコーヒーショップでここまで読んで、あわてて頁を伏せ、目を閉じて考え始めたら、すこし居眠りしてしまった。
正解。当然ながら、項目1の切片はやたらに高くなり(バイアスは+0.6)。残差分散はやたらに低くなる(-0.15)。他の項目も、切片はかなり高くなるが(+0.26くらい)、残差分散は影響されない。で、他の項目の因子負荷が高くなり(+0.16くらい)、因子分散は低くなる(-0.28)。なるほどー。
というわけで、面白かったんだけど、いろいろ考えさせられる面もあった。
潜在変数モデルにおける確率ウェイティングの出番、つまり「標本抽出確率の不均一性でバイアスが生まれており、確率ウェイティングでそのバイアスを除去できる」状況とは、いったいどんな状況だろうか。この論文では、「データの発生メカニズム自体に異質性はないけど、調査項目による標本選択が生じている」状況を想定しているわけだけど、現実の場面でそういうことは起きるだろうか。
調査データの分析で単純な確率ウェイティングが用いられる二大場面は、非比例層別抽出、ならびに(たとえば調査無回答に対処するための)事後層別、だと思う。ふつう層別変数は対象者のデモグラフィック属性などで、調査項目や潜在変数からみると共変量だから、不均一な抽出による選択バイアスは、潜在変数の分布特性(たとえば因子分散)の推定には効いても、測定モデルのパラメータ(たとえば因子負荷)には効かないのではないかと思う。実際この論文でも、潜在クラス分析のシミュレーションのくだりで、抽出確率が(潜在クラスの指標となる項目ではなく)潜在クラスの予測子によって決まっている場合、選択バイアスは閾値の推定には効かない、と紹介している。もっとも閾値の分散の推定においては、ウェイティングを伴う正しい推定方式が必要になるわけだけど。
層別変数が共変量ではなく、調査項目から見た結果変数になっている、というケースもあり得なくはない。たとえば、ある製品カテゴリに対する態度の調査で、ユーザと非ユーザに標本サイズを割りつけている場合がそれだ。でもこういう場合、そもそも各層の標本抽出確率がわからないので(潜在的消費者におけるユーザの割合がわからない)、ウェイティングしたくてもできない、ということが少なくない。それに、わざわざ指標と関連した層別を行っているからには、それらの層を通じた共通モデルという想定そのものが疑わしいことが多いと思う。ユーザと非ユーザでは態度の構造が違うだろう。
そんなこんなで、因子分析や潜在クラス分析で確率ウェイティングをかけたい、どうしてもかけたい!という事態が、ちょっと想像しにくいように思うのだが、うーん、どうなんですかね。もっとも、これは私がパラメータ推定にばかり目を向けているからで、パラメータの信頼区間やモデルのカイ二乗値に強い関心があれば、話は少し変わってくるだろう。
読了:Asparouhov(2005) 因子分析・潜在クラス分析における確率ウェイティング(または: Mplus 3はこんなにすごいんだぜ)
2014年3月18日 (火)
Pearl (2014) Understanding Simpson's Paradox. The American Statistician, 68(1), 8-13.
因果推論の巨匠Pearl先生、シンプソン・パラドクスについて語るの巻。
シンプソン・パラドクスとはすなわち、二元クロス表における連関が、第三の変数で層別すると消えたり方向が逆になったりする... という話。統計や調査法の本によく登場する有名な現象である。こう表現してしまうとつまらなく聞こえるけど、はじめて実物をみたら、それはもうビビりますよ。講義やセミナーなどでみせると、何人かは身を乗り出して食いついて下さる、良い題材である。
Pearl先生いわく:
あるパラドクスが解けていると主張するためには、以下の基準をクリアしなければならない。(1)その現象が驚きをもたらす理由を説明できること。(2)パラドクスが現れるシナリオと現れないシナリオを区別できること。(3)それが現れるシナリオにおける意思決定の正解を示し、数学的に証明すること。
この基準に照らせば、シンプソン・パラドクスはもう「解けている」。順に示しましょう。
(1)について。シンプソンのパラドクスがパラドクスとみなされるのは、その現象が私たちが抱いている次の因果的信念と衝突するからだ: 「それぞれの下位母集団において事象Bの確率を増大させる行為Aは、それが下位母集団の分布を変えない限り、母集団全体においてもBの確率を増大させるはずだ」。著書"Causality"ではこれを"sure-thing"の定理と呼んでいる。つまり、シンプソンのパラドクスの驚きは、統計的連関に因果的解釈を与えてしまうという私たちの傾向性と、私たちの因果的直観に起因している。
(2)について。シナリオは有向非循環グラフ(DAG)によって表現できる。シンプソン・パラドクスが起きるシナリオとそうでないシナリオもDAGで区別できる。
(3)について。伝家の宝刀do-calculusで説明できる。しかしdo-calculusをご存じない読者の皆様のために(←今日はやけに親切ですね先生)、ここではシミュレーションによって説明しよう... というわけで、バックドア基準のかんたんなご紹介。
Pearl先生のこういう非専門家向けの文章は、読みやすくて面白い。この論文も、出先での時間待ちのあいだに楽しく読んだ。なのに、主著"Causality"ときたら、なぜあんなにわかりにくいんですかね...
この論文、いちおうはArmistedという人の批判論文への返答という形をとっているのだけれど、本文中では全く言及がなく、最後に短くコメントしているのみ。いわく:はいはい、あなたの云っていることは正しいでしょうよ。XとYのクロス表をZで層別しようがしまいがお好きなように。どんな集計表だってなにかの役には立つでしょう。でも、Yに対するXの総合効果に関心があるならば、みるべき表は、Zで層別した表かしない表のどちらか一方に決まります。という、言い回しは優しいけど、ほとんど相手にしていない感じの返答であった。そりゃそうですよね先生! Armistedの批判が批判になっているのかどうか理解できず不安だったのだけど、ひと安心。虎の威を借る狐とはこのことである。
読了:Pearl (2014) シンプソン・パラドクスよ、お前はもう解けている
2015/06/10 追記: 一年以上前に書いたこの記事を自分で読み返していたら、シミュレーションのコードは汚いわ、結果を読み違えているわで、いやあ、こっぱずかしい... 以下、書き直しました。
Spencer, D. (2000) An approximate design effect for unequal weighting when measurements may correlate with selection probabilities. Survey Methodology, 26(2), 137-138.
最近読んだ何本かの論文で引用されていたので、ついでに目を通した。
抽出確率が不均一な調査デザインのデータにおいては、バイアスを取り除くために集計の際に確率ウェイティングを行うことがあるが、その副作用として母集団パラメータの推定精度が低下する。この推定精度の低下を、推定量の分散と「単純無作為抽出の場合における推定量の分散」との比で表してデザイン効果と呼ぶ。
Kishの有名な近似式によれば、母平均推測における層別抽出のデザイン効果は、ウェイト値の相対分散を$rvw$として$1+rvw$である。しかし、Kishの近似式は抽出確率と無関連な変数の集計を想定している。抽出確率と関連している変数については、推定精度はむしろ向上する場合さえある。そういう場合の近似式をご提案します、という短い報告。
母集団サイズを$N$とする。ケースをひとつ抽出したときそれがケース$i$である確率を$P_i$とする。当然、母集団を通した$P_i$の平均は$1/N$になる。ケース$i$の測定値を$y_i$とする。
いま、母集団において回帰式
$y_i = \alpha + \beta P_i + \epsilon_i$
が成り立っているとしよう。
以下、母分散を$\sigma^2$, 母相関を$\rho$で表す。原文ではそのあとに添え字がついているけど($\sigma^2_y$とか)、わかりにくいのでかっこに入れて示す($\sigma^2[y]$とする)。
サンプルサイズ$n$の標本について考える。以下ではウェイトを、(抽出確率)*(標本サイズ)の逆数、すなわち$w_i = 1/(n P_i)$と表現する。
母集団合計$Y$の推定について考える。推定量は
$\hat{Y} = \sum^n_i w_i y_i$
その分散は
$V(\hat{Y}) = (1/n) \sum^N_i P_i (y_i / P_i - Y)^2$
ここにさっきの回帰式を放り込むと下式となる由。母集団を通じた$w_i$の平均を$\bar{W}$として、
$V(\hat{y})$
$= \alpha^2 N(\bar{W}-N/n)$
$+ (1-\rho^2[y, P]) \sigma^2[y] N \bar{W}$
$+ N \rho[\epsilon^2, w] \sigma[\epsilon^2] \sigma[w]$
$+ 2 \alpha N \rho[\epsilon, w] \sigma[\epsilon] \sigma[w]$
導出過程を追いかけてないけど、信じますよ、先生。
さて、さきほどの回帰式が測定値$y_i$と抽出確率$P_i$ の関係をうまく捉えているならば、それがどんな関係であろうが(関係があろうがなかろうが)、残差項とウェイトは無相関である。すると、上式の$\rho[\epsilon^2, w], \rho_[\epsilon, w]$が$0$になるから、
$V(\hat{y}) = \alpha^2 N(\bar{W}-N/n) + (1-\rho^2[y, P]) \sigma^2[y] N \bar{W}$
いっぽう、単純無作為抽出の場合の分散は (話を簡単にするために復元抽出だとして)
$V(\hat{y}) = (1/n) N^2 \sigma^2[y]$
この比をとったのがデザイン効果だ。すなわち
$deff = (\alpha/\sigma[y])^2 (n \bar{W} / N - 1) + (1-\rho^2[y, P]) n \bar{W} / N$
このデザイン効果の推定値は、結局
$(\hat\alpha/\hat\sigma[y])^2 (rvw) + (1-\hat\rho^2[y, P]) (1+rvw)$
となる由。Kishが想定した$y$と$P$が無相関な状況では、$\hat\alpha$も$0$に近くなるから、結局
$1 + rvw$
となるわけで、つじつまが合っている。
...という主旨の論文であった。
へー、そうなの?と思って、ちょっと実験してみた。
母集団が5つの層から構成されていると考える。層の構成比は1:2:3:4:5とする。各層の母平均をいろいろ操作し、次の3つを比較した。
- 単純無作為抽出による母平均の推測。
- 各層のサンプルサイズを層の構成比に比例させた層別抽出による母平均の推測。
- 各層のサンプルサイズを等しくした層別抽出による母平均の推測と、Spencerのデザイン効果の推測(Kishのデザイン効果は母平均がどうであろうが1.222となる)。
サンプルサイズは100。測定値は(母平均)+(SD1の正規ノイズ)として生成した。試行数5万のモンテカルロ・シミュレーション。シミュレーションのRコードはこちらにございます。コーディングが下手なのはお慰みで。
結果はこうなりました。クリックで拡大表示されるはず。
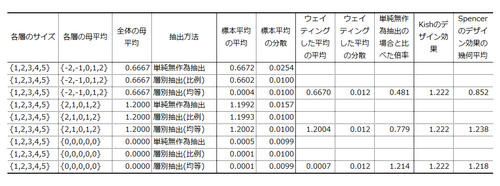
シナリオ1. Spencerのデザイン効果の活躍が期待される状況。各層の母平均を{-2,-1,0,+1,+2}とし、全体の母平均(0.6667)を推測した。単純無作為抽出による標本平均は分散0.0254。これに対し、層別抽出(比例)による標本平均は分散0.0100。層別抽出(均等)による母平均の推定値(つまりウェイティングした平均)は分散0.0122。単純無作為抽出に比べて分散が0.481倍に激減している。層が測定値と抽出確率の両方と強く関連しているので、層別抽出が猛烈な威力を発揮したわけだ。
層別抽出の毎試行ごとにSpencerのデザイン効果を算出してみると、その幾何平均は0.852であった。Kishのデザイン効果(1.222)は推定量の分散の減少を捉えることができないが、Spencerのデザイン効果も減少の大きさを捉えきれていない。なぜだろう?
シナリオ2. Spencerくんの手にも負えないであろう状況。各層の母平均を{+2,+1,0,+1,+2}としてみる(全体の母平均は1.2)。単純無作為抽出では、標本平均の分散は0.0157。層別抽出(比例)では分散0.0100。層別抽出(均等)では分散0.0122。単純無作為抽出に比べて分散が0.779倍に減少している。さきほどと同様、層別抽出にしておいてよかった、というケースである。
Spencerのデザイン効果の幾何平均は1.2380。Kishのデザイン効果はもちろんSpencerのデザイン効果も、標準誤差の減少を捉えられない。測定値と抽出確率のあいだに強い関係があるのだが、それが非線形であるためだろう。
シナリオ3. Kish先生のやり方でよさそうな状況。各層の母平均を{0,0,0,0,0}としてみた(全体の母平均はもちろん0)。単純無作為抽出では、標本平均の平均は分散は0.0099。層別抽出(比例)では分散0.0100。層別抽出(均等)では分散0.0120。要りもしないウェイティングをしたせいで、標準誤差が1.214倍に拡大してしまったわけだ。
Spencerのデザイン効果の幾何平均は1.218であった。この状況なら、Kishのデザイン効果(1.222)もSpencerのデザイン効果も、まあまああたっている。
うーむ。シナリオ 1 における推定量の分散の減少を捉えきれないとすると、Spencerの近似式が役に立つのは一体どういうときなのか、いまいちわからなくなってきた。
読了:Spencer(2000) 抽出確率が測定値と相関している標本におけるデザイン効果の推測
2014年3月12日 (水)
またもや「ウェイトバック集計」関連の論文。非比例層別抽出のような、個体のあいだで標本抽出確率が均一でない標本があるとき、確率ウェイティングの下での集計・検定を行うことは多いけど、では回帰分析や因子分析も「ウェイトバック」すべきか。これは大変難しい問題で、いつも答えに困る。厄介なことに、最近はソフトウェアが進歩して、単に「できません」と答えるわけにもいかなくなっている...
Muthen, B., & Satorra, A. (1995) Complex sample data in structural equation modeling. Sociological Methodology, 25, 267-316.
確率ウェイトつきの調査データに対する多変量解析についての概観が読みたくてめくった。掲載誌は年報のような感じ。
いやはや、長くて難しい内容であった。困るなあベン、もっと易しく書いてくれないとさあ。(←論文を何本も読んだのでもはやマブダチである。俺の中ではな)
まず、先行研究概観。complex sample design のデータ解析手法は2つに分けられる。
- aggregated analysis. 通常のパラメータ推定値を算出するけど、標準誤差や適合度を調整する。
- disaggregate analysis. 抽出構造を反映した新しいパラメータを導入する。
別の観点からは次の2つに分けられる。
- design-based approaches. 標本抽出論で発展してきた。有限母集団の特性の推定に関心がある。
- model-based approaches. ふつうの統計モデリング。なんらかの(超)母集団モデルを仮定し、そこから推定量を引き出す。
先日読んだGelmanさんも云ってたけど、いわゆるモデル・ベースのアプローチだって標本抽出デザインについての情報を使っているのだから、なんだか変な区別なんですけどね。まあこの業界の常識的区別なのであろう。以上の区別については、Skinner, Holt, Smith, eds.(1989) "Analysis of Complex Surveys"を参照せよとのこと。
で、先行研究を、単変量のデザイン・ベース、単変量のモデル・ベース、多変量、の3節に分けて紹介。
- 単変量のデザイン・ベース。これが一番多い。パラメータ推定の際にウェイトを使う。標準誤差の算出方法は4つある。(1)テーラー展開。(2)balanced repeated replication (BBR)。(3)ジャックナイフ法。(4)ブートストラップ法。レビューとして以下を参照せよとのこと: Wolter (1985) "Introduction to variance estimation"; Rust(1985, J.Official Stat.)。ぜってーよまねー。4つの方法の性能を比較した研究がいくつもあるらしいが、結局のところ、どれでも良いらしい。
- 単変量のモデル・ベース。さらに二つに分けられる。逆にいうと、この二つの両方を扱った研究はない。
- 抽出確率の不均一性を考慮する研究。母平均推定についてはLittle(1983JASA), 回帰モデリングについてはHolt, Smith & Winter (1980JRSS), Nathan & Holt(1980JRSS), Pfeffermann & Holmes(1985JRSS), Pfefferman & LaVange(1989, in Skinner et al.(eds))がある。デザイン・ベースの方法と比べてMSEが小さいよ、という研究が多い。残差分布の層間異質性をモデル化する研究もある(階層ベイズモデルみたいなものだろうか? Little (1989)というのが挙げられている)。
- クラスタを考慮する研究。古典としてScott & Smith (1969)というのがある。クラスタ内相関をモデル化する分散成分モデルであったそうだ。以来、山ほど研究がある由。面倒なので省略するけど、教育研究での例として(学級がクラスタね)、Bock(1989, 書籍), Bryk & Raudenbush (1992, 書籍), それからLongfordという人のNAEPの研究が挙げられている。よくわからんけど、それって階層回帰モデルの話そのものではないかしらん。
- 多変量。研究は少ないが、以下の2つの領域で出現している。
- 対数線形モデル。ここ、面白いので丁寧に。研究例として、Freeman et al.(1976), Landis et al.(1987), Rao & Thomas (1988, Sociological Methodology) がある。これらの研究は、抽出確率の不均一性とクラスタリングの両方を考慮している。パラメータ推定や仮説検定にはGLSを使う。標本統計量 s (ここでは比率のベクトル)の共分散行列を、ウェイト行列Wで近似するという作戦である。Wの作り方として、Landisらはテイラー展開、Rao & Thomas はジャックナイフやBRRを使っている。また、Rao-Scottの「一般化deff行列」を使う方法、Fayのジャックナイフ・カイ二乗検定、Rao-ScottによるSRSカイ二乗の修正方法、などがある。ひえー。Rao & Thomas (1988)を参照せよとのこと。
- SEM。この辺はいまはちょっと古くなっていると思うので、省略。
以上はこの論文のほんの序盤で、ここからが本題。まず、SEMを一般的に定式化し、complex sampleに対するaggregatedのモデルとdisaggregatedのモデルを定式化する。それも正規性がある場合とない場合の両方について。正直いって私の能力の及ぶところではないので、パス。
で、モンテカルロ・シミュレーション。層やクラスタが出てくるややこしい標本抽出デザインのデータに対する回帰分析と因子分析について、(1)正規性を仮定したML推定(SRSを想定)、(2)robust normal theory に基づく推定(すなわちデザイン・ベース)、(3)マルチレベルモデル(すなわちモデル・ベース)の3つの性能を比較。(2)(3)の性能がいいね、云々。根気が尽きたのでパス。
というわけで、大部分はパラパラとめくっただけだけど、目的は達したので、読了ということにしておいてやろう。なんだかあれだな、散々殴られた挙句に「今日はこのくらいにしておいてやるか」と言い捨てて立ち去るチンピラみたいだな。
読了:Muthen & Satorra (1995) 複雑な標本抽出デザインのデータに対するSEM
2014年3月11日 (火)
ひょんなことから、いわゆるウェイト・バック集計について考える機会があった(年に何回かそういうことがある)。ふと思いついて、日本語での解説をwebで探してみたら、みつかるページはピンキリである。大変失礼ながら、かなりイイカゲンな説明が多い。「ウェイトバック後のサンプル数」とか。それはいったいなんだ。
OJTというのはあてにならないもので、いま関わっている市場調査の分野を見ていると、経験を積んだ優秀なリサーチャーの方でも、この話に関しては結構怪しげな考え方をすることがある。性別や年齢のような共変量について、母集団の構成比率と標本の構成比率とを事後層別ウェイティングで揃えることは、それが可能な限りにおいて常に善である、とか。そんなことはない。一般に確率ウェイティングは推定量の分散を増大させる。個別の調査データ解析にとってホントに大事なのは不偏推定ではなく推定誤差の最小化なのだ。デザイン効果やeffective sample sizeって聞いたことないんですかね? ... と思ったところで、ハタと気が付いた。ごめんなさい、私もいまいちよくわかってないです。お世辞にも得意分野とはいえない。
Park, I. & Lee, H. (2001) The design effect : Do we know all about it? Proceedings of the Annual Meeting of the American Statistical Association. 2001.
というわけで反省して、昼飯のついでにいくつかの資料に目を通した、そのなかの一本。ASAのProceedingsだけど、タイトルがそのものずばりだったので。著者らはWestat社の人。
まず、デザイン効果の小史。
- design effectという考え方を最初に提出したのはCornfieldという人である[Kishではないのね!!]。彼の定義では、ある複雑な抽出デザインの効率は、「ある統計量の、単純無作為非復元抽出(srswor)の下での分散と、同じ標本サイズの複雑なデザインの下での分散との比」である。この逆数がdesign effectと呼ばれた。
- design effectが有名になったのは、Kish(1965)"Survey Sampling"からである[8章2節。私が持っている1995年版でもそうだ。なんてこったい、大幅改定されているものだとばかり思っていたぞ]。彼の定義では、「標本の分散の、同じ要素数の単純無作為標本の分散に対する比」。たとえば、ある複雑なデザインにおける母平均 $\bar{Y}$ の推定値 $\bar{y}$について、design effectは
$Deff = Var(\bar{y}) / \{ (1-f) S^2_y / n \}$
ここで $n$ は標本サイズ、$S^2_y$ は母分散 (標本分散ではない)。$f$ は標本割合で、単に有限母集団修正をしているだけである。 - Deffは抽出デザインによっても異なるし推定量によっても異なる。Sarndal et al.(1992) "Model Assisted Survey Sampling"は次のように定式化している。デザインを $p$, 母集団パラメータを $\theta$, その推定量を $\hat{\theta}$ として、
$Deff(p, \hat{\theta}) = Var_p(\hat{\theta}) / Var_{srswor}(\hat{\theta}')$
ここで $\hat{\theta}'$はsrsworの下での推定量で、通常 $\hat{\theta}$ とは異なる。たとえば、母平均の推定ならば、$\hat{\theta}=\sum w_i y_i /\sum w_i, \hat{\theta}' = \sum y_i / n$ であろう。 - Kish(1992)では新たにDeftが提案された。これは、非復元抽出ではなく復元抽出(srswr)を分母にとったもの。
$Deft(p, \hat{\theta}) = \sqrt{ Var_p(\hat{\theta}) / Var_{srswr}(\hat{\theta}') }$
Sarndalらとちがって平方根がついている。調査データ分析の専用ソフトであるWesVarやSUDAANでは、$Deft^2$ をDeffと呼んでいる由。 - Kish(1987)は、ウェイト値と $y$が無相関のときの平均のDeftの近似式として下式を示している:
$Deft^2(p, \hat{\bar{Y}}) = { 1 + \rho (\bar{b} - 1) } (1+cv^2_w)$
ここで $\rho$ は級内相関、$\bar{b}$ はクラスタサイズの平均, $cv^2_w$ はウェイト値の相対分散である。ウェイト値と $y$ に相関がある場合の修正式はSpencer(2000, Survey Methodology)によって提案されている。
さて。母集団パラメータとして合計 $Y$ と 平均 $\bar{Y}$ に注目しよう。複雑な抽出デザインにおいて、合計の不偏推定量は $\hat{Y} = \sum w_i y_i$ (w_iはどなたかが宜しく作ってくれたとして)、平均の不偏推定量は $\hat{\bar{Y}} = \sum w_i y_i / \sum w_i$ である。良く似ている。しかし、$Deft(p, \hat{Y})$ と $Deft(p, \hat{\bar{Y}})$ は全然違っている。前者のDeftはとても大きい。
Kish(1995)はこういっている。「Deftは要素の変動性($S^2_y / n$)のむこうにある標本デザインの効果を表現するために用いられる。そのために、測定単位と標本サイズの両方を剰余変数として除外するのである。測定単位 $S_y$ とサンプルサイズ $n$ を取り除くことで、標本誤差におけるデザインの効果が他の統計量や他の変数に一般化できるようになる。同じ調査のなかでも、異なる調査の間でさえ」。この言葉は $\hat{\bar{Y}}$ についてはだいたい正しいが、$\hat{Y}$ については正しくない。
というわけで、この論文の本題は、合計に対するdesign effectの話であった。そうタイトルに書いといてほしいなあ。
有限母集団 $U$ からの、ある複雑なデザインによる標本サイズ $n$ の復元抽出を考えよう。要素 $k$ の値を $y_k$ とする。$k$ の抽出確率を $p_k$ とし、$U$ を通じて $\sum p_k = 1$ と基準化する。$i$ 番目に抽出された単位を $k_i$ とする。$y_{k_i}$ とか書くのが面倒なので $y_i$ と書く。
母合計 $Y = \sum y_k$ の推定量は
$\hat{Y} = 1/n \sum_i y_i / p_i$
これをHansen-Hurwitz推定量という(へー。知らなかった)。その分散は、
$Var(\hat{Y}) = 1/n \sum_U (1/p_i) (y_i - p_i Y)^2$
いっぽう、母平均 $\bar{Y} = Y / N$ の推定量は、
$\hat{\bar{Y}} = \hat{Y} / \hat{N}$
ただし、$\hat{N} = \sum_i (1/np_i)$ である。
式の展開は端折って、それぞれのDeftは以下のようになる由。$N$ が十分大きいとして、
$Deft^2 (\hat{Y}) \approx { \sum_U (1/p_i) (y_i - p_i Y)^2 } / {\sum_U N (y_i - \bar{Y})^2 }$
$Deft^2 (\hat{\bar{Y}}) \approx { \sum_U (1/p_i) (y_i - \bar{Y})^2 } / {\sum_U N (y_i - \bar{Y})^2 }$
ここで $p_i$ と $y_i$ の無相関を仮定すると、二本目の式はKishの与えた有名な近似式 1 + ($w_i$の相対分散) に帰着する。
さて、上の二本の式を整理すると、結局
$Deft^2 (\hat{Y}) - Deft^2 (\hat{\bar{Y}}) = (1/CV_y^2) {\sum_U (1/p_i) (p_i - \bar{P})^2 - (2/Y) \sum_U (1/p_i) (y_i - \bar{Y})(p_i - \bar{P}) }$
ただし $CV_y = S_y / \bar{Y}$。つまり、合計に対するデザイン効果は、平均に対するデザイン効果よりも大きくなる。その増分は、$y$ の分散が小さいとき、$p_i$ の分散が大きいとき、$p_i$ と $y_i$ の相関がないとき、に大きくなる。へえー。
最後に、Spencer(2000)による修正式が合計に対しては当てはまらない、という説明。それからデータ例。読み飛ばした。
結論。合計の推定におけるデザイン効果はKishの説明とは異なり、変数の分散や変数と抽出確率との相関に依存するから注意しないといけない。云々。
ある複雑なデザインの調査データを集計する際に、確率ウェイティングを行うかどうか悩む場合がある。その判断の手がかりになるのが、確率ウェイティングによる推定精度の低下の評価、すなわちデザイン効果の推定である。いっぽう集計の際には、確率ウェイティングだけでなく、頻度について母集団サイズへの拡大推計を行うこともある。この2つは全然別の事柄だから、まず確率ウェイティングの是非について考え、ウェイティングするかどうか決め、割合を求め、それに母集団サイズを掛ければいいや、と思っていた。でもこの論文によれば、母集団における頻度を統計量と捉えたとき、その推定量におけるデザイン効果は平均のデザイン効果より大きくなるわけだ。ということは、拡大推計を行う際はそのことを考慮して、ウェイティングの是非をよりシビアに判断する必要がある、ということになりそうだ。うううむ。そうなのか。あとでよく考えてみよう。とにかく、意外な面で勉強になりました。
ところで、この文章によれば、KishがDeftを提案したのは1992年の論文"Weighting for Unequal P_i"である。この論文はかなり前に読んだのだけど、デザイン効果についての突っ込んだ議論はなかったし、記憶が正しければそもそもDeftなんて出てこなかったように思う。著者らはなにかと勘違いしているのではないだろうか。調べてみると、1995年の"Methods for Design Effects"という論文が怪しい。掲載誌はどちらもJ. Official Statisticsだし。
読了: Park & Lee (2001) デザイン効果、その知られざる真実
2014年3月 7日 (金)
因果推論の巨匠 J. Pearl 先生が「こんどこんな論文書いたから読んでね」と下書きを公開する→たまたま気づいて、いつか読もうと印刷して机に積む→しばらく放置→整理の都合でぱらぱらとめくったら、これが面白そう→いや待て、修正が済んだやつがもう雑誌に載っているんじゃないかと探す→American Statisticianの最新号に載っていて、前後の論文含めPDFが無料公開されていることに気づく→あろうことか下書きとは主旨が変わって、誰かのPearl批判論文への返答という位置づけになっている→仕方がないのでその批判論文を読み始める→さっぱり理解できず困惑する(イマココ)
Armisted, T.W. (2014) Resurrecting the Third Variable: A critiquie of Pearl's causal analysis of Simpson's paradox. American Statistician, 68(1), 1-7.
というわけで、この雑誌の最新号に載っているシンプソン・パラドクスについてのやりとりの、最初の論文。
ええと... 因果推論の巨匠 Pearl 先生に言わせれば(著書"Causality")、シンプソン・パラドクスはパラドクスではない。因果性の問題として考えるべき問題を、そう考えそこねていることに由来する混乱に過ぎない。いっぽう著者はこの考え方を批判する。どう批判するかというと、ええと、ええと...
まずはこんな例から。Lindley&Novick(1981) というのが挙げた例だそうだ。
全体:
治療あり... 治癒20名, 非治癒20名, 治癒率50%
治療なし... 治癒16名, 非治癒24名, 治癒率40%
男性:
治療あり... 治癒18名, 非治癒12名, 治癒率60%
治療なし... 治癒7名, 非治癒3名, 治癒率70%
女性:
治療あり... 治癒2名, 非治癒8名, 治癒率20%
治療なし... 治癒9名, 非治癒21名, 治癒率30%
全体をみると治療ありのほうが治癒率が高い。しかし性で層別すると、どちらの層でも治療なしのほうが治癒率が高い。シンプソン・パラドクスである。
Pearlの説明はこうだ。この例で、全体の表は性別情報がないときの治療の「証拠の重み」を示しているに過ぎない。治療の効果を示しているのは層別した表である。いっぽう、「男性」「女性」を「低血圧も治った」「低血圧は治ってない」に書き換えた場合はどうか。その場合は全体の表のほうをみないといけない。なぜなら低血圧が治ったかどうかは治療の結果だからだ。つまり、性というcausalな変数では層別すべきだが、低血圧が治ったかというnoncausalな変数では層別してはいけない。
いっぽうLindleyらの説明は少しちがう。この例では全体ではなく男女で層別した表のほうをみないといけないんだけど、それは性別と治療有無が交絡しているからである。性別を低血圧に書き換えた例ならば、全体の表も層別した表も、それぞれに価値がある(ここがPearlとちがう)。
著者らもこの立場を支持する。つまり、第三の変数で層別すべきかどうかは、それがcausalな変数かどうかでは決まらない。
なぜか?
なぜならば... という説明がなされているのだけれど、これがさっぱり理解できない。難しいことが書かれているわけでないのだが、読み返しても話のポイントが掴めないのである。著者のかたは、変数間の因果関係が分かっているとき (DAGが描けるとき) に因果関係の方向と強さを調べるという状況と、それ以外の多種多様な状況とをごっちゃにしているのではないかと思うのだけれど... きっと私がなにか理解し損ねているのだと思う。
2014年3月 1日 (土)
佐藤俊哉 (1993) 疫学研究における生物統計手法. 日本統計学会誌, 22(3), 493-513.
疫学(というか、リスク要因への曝露の効果の研究) における統計手法についての啓蒙的レビュー。仕事上でちょっと悩んでいることがあって、頭を整理したくて読んだ。著者はなにしろ、他の惑星の卒論発表会に招かれ、思わず正論を述べて「しまりす」くんの大学卒業を阻止するという、非情にして怖れを知らない先生であって(「宇宙怪人しまりす」シリーズを参照)、啓蒙的文章に関してこの先生の名前は私のなかで絶対のブランドなのである。
いくつかメモ:
- 層別解析で、効果の方向が層によって異なるときを「質的な交互作用」、方向がすべての層で同じときを「量的な交互作用」「効果の修飾」というのだそうだ。へぇー、はじめて聞いた...
- 層別において、層の数が少なくて層のサイズが大きいことをlarge-strata, ケースのマッチングのように層の数が多くて層のサイズが小さいことをsparse-dataと呼ぶ由。この分野でいうsparseってそういう意味だったのか...
- 疾病発生割合をモデル化する手法として、ロジスティック回帰のほかに、additive risk model (条件つき確率そのものをモデル化する), relative risk model (その対数をモデル化する), が紹介されている。additive risk model が「絶対リスクモデル」と表記されているのだけど、なぜ「加法」とかじゃなくて「絶対」っていうのかしらん。
- 疾病発生率のモデル化として、Cox回帰、exess risk model, 集計データに対するポワソン回帰が紹介されている。exess risk modelというのは、購買間隔の分析に使うadditive risk modelとどう違うのだろうか。放射線被曝や職業曝露のモデル化で用いられるそうだが、この分野ではなぜCox回帰を使わないのかなあ。今度調べておこう。
- 「最近になって提案された研究デザイン」として、nested case-control, case-cohort, two stage case-control が紹介されているのだけれど、nested case-controlもcase-cohortも、コホートの全メンバーの曝露情報を収集→フォローアップ→一部について詳細な情報を収集、というデザインなので、広義にはtwo stage case-controlなのだそうだ。ふうん。
- 測定誤差の話がちらっと紹介されているのだけれど、アウトカムのnondifferentialな誤分類(その起こりやすさが曝露と関係ない誤分類) であっても、変数が複数あったり二値変数じゃなかったりすると、効果が(弱くなる方向にではなく)強くなる方向にバイアスがかかることがあるのだそうだ。えええ、なんで??? Dosmeci, et al. (1990, Am.J.Epidemiology) というのを読むといいらしい。
最後の今後の展望のところで、「少し技術的な問題としては、疾病発生割合の差や比、疾病発生率の差に関する回帰モデルの開発が、特にsparse-dataについて、望まれる」とある。まさにそういうのを探してるんです...
読了:佐藤 (1993) しまりすのための曝露効果研究法レビュー
2014年2月28日 (金)
たとえば、消費者を集めてきて2グループに分け、片方のグループにだけある商品の広告かなにか(A)を見せたのち、全員にその商品を買いたいかどうかを尋ねたら、買いたいと答えた人の割合は、見せてない群では10%, 見せた群では20%でした。で、同じ商品について、別の時期に別の広告かなにか(B)で実験したら、見せてない群では30% (なにか事情があって上がったんでしょうね)、見せた群では45%でした。
さあ、どちらの広告が効果があったでしょうか? 何の因果か、私は日頃こういうことばっかり考えて細々と暮らしている。
ひとつの答え方は、Aは10% vs. 20%で10%の上昇、Bは30% vs. 45%で15%の上昇、だからBのほうが効果があった、というものである。いわゆる「リスク差」に注目した考え方だ。
もうひとつの答え方は、Aは10%が20%になったんだから2.0倍、Bは30%が45%になったんだから1.5倍、だからAのほうが効果があった、というものである。「リスク比」に注目した考え方だ。
もしかすると、ややこしいことを考える人がいて、Aは (0.2/0.8) / (0.1/0.9) = 2.25, Bは (0.45/0.55) / (0.3/0.7) = 1.91, だからAのほうが効果があった、というようなことを言い出すかもしれない。「オッズ比」に注目した考え方である。
仕事とはいえ、毎日毎日こんな細かいことをちまちまと考えて一生を終えるのか... と、哀しい気持ちになる人もいるかもしれない。そういう人は私の心の友です。心の友というのは概して役に立たないものだ。
Walter, S.D. (2000) Choice of effect measure for epidemiological data. J. Clinical Epidemiology, 53, 931-939.
そんなこんなで、頭を整理したくて読んだ。つくづく思うんだけど、二値のアウトカムに対する因果的効果を定量化したい、原因変数と共変量は明確だ、という場面では、疫学の道具立ての豊かさにはもう絶対にかなわない。さらに、医学関係者はなにしろ人数が多いので、優れた解説にも事欠かない。読まなきゃ損である。と、景気をつけて...
リスク差とかリスク比とかオッズ比とかの効果指標についてレビューします、という論文。
2つの群におけるイベント生起率を$P_1, P_2$とする。とりあえず、$P_1$を処置群、$P_2$を統制群としておく。良くつかわれる効果指標は:
- リスク差 $RD = P_2 - P_1$
- リスク比 $RR = P_1 / P_2$
- 相対リスク減少 $RRR = (P_2 - P_1) / P_2$
- オッズ比 $OR = (P_1 / (1-P_1)) / (P_2 / (1-P_2))$
- 治療必要数 $NNT = 1/ (P_2 - P_1)$
云うまでもなく、$RRR=1-RR, NNT=1/RD$である。
RRとORが全然ちがう指標である点に注意。ORの批判者たちはそこを見逃している(暗黙のうちにRRを基準にして考えている)。
効果指標に求められる特性のそれぞれについて、RD, RR, ORを比べてみよう。
- 単純であること。RDとRRが該当。ORはわかりにくい。
- 対称的であること(成功と失敗を入れ替えても影響されないこと)。RDとORが該当。
- それが一定である時、生起率は0と1のあいだであること。ORのみが該当(たとえば、RD=0.1, P_2 < 0.1だったらP_1は負になってしまう)。
- 不偏推定が可能であること。RDが該当。
- 小サンプルでも効率的に推定できること。ORが該当。
- 生物学的モデルに基づいていること。すべて該当。(RD, RRはポワソンモデルと整合する。ORは、2つの正規分布の下でカットポイントを決めて判別したとき、カットポイントを問わずほぼ一定になる)。
ついでにいえば、ORは事前オッズに掛ければ事後オッズになるし、2x2クロス表の超幾何分布のパラメータだし、多元クロス表の分析の基盤だし、後向き研究でも前向き研究でもクロスセクショナル研究でも推定できるし...(と、贔屓の引き倒し気味の説明が並んでいる)。
そのほか、RD, RR, ORのそれぞれを固定したままP_2を動かすとP_1はどうなるか(P_2が極端でない限りどの指標もたいして変わらない)、実データ例において層によって値が変わらないのは3つの指標のうちどれだったか(どれも一定ではなかった)、といったデモンストレーションが紹介されている。省略。
考察。
RD, RR, ORのどれを使うべきかはアプリオリには決められない。手元のデータに照らし、ベースライン・リスク(P_2)が変わっても変動しない指標を選ぶのがよいでしょう。まあ単一の研究じゃなかなか決められないと思うけどね。階層混合モデルで検証すればいいんじゃないですか。(←面倒なことを軽く云うねえ、とちょっと笑ってしまった。実例としてThomas(1981, Biometrics)というのが挙げられている。要旨を読むと、どうやら生存時間モデルで任意の関数形について尤度を出しますというような話らしい。そんなんよう読みませんわ)
統計的データ解析とリスク・コミュニケーションは分けて考えましょう。後者は分析のあとで考えればよい。たとえば、分析はOR, コミュニケーションはRR、というように使い分ければいいんじゃないですか。
云々。
著者は「RRの観点からORをけなすな」とずいぶんお怒りだけど、その背後には、医学関係者は因果的効果をRRで捉えるのに慣れていて、ORはケース・コントロール研究における(rare disease assumptionの下での)RRの近似として用いられてきた、といういきさつがあるのだろうと思う。
この話に限らず、一般に「どういう指標が良いか」という議論になったときには、(1)ユーザの受け取り方に注目する論点、(2)データの発生メカニズムに注目する論点、(3)指標の統計的性質に注目する論点、の3つが入り乱れるように思う。私は心の中でひそかに、(1)を右翼、(2)を左翼、(3)を小役人と呼んでいる。この分類でいうと、この著者は右翼的な論点を切り離し、小役人的な論点では決着がつかないと主張する左翼で、でも「イベントの生起メカニズムについて実質科学的に熟考しなさい」というようなラディカル左翼ではなく、「安定しているはずの時に安定している指標を選びなさい」というデータ寄りの視点に重きをおく、ということだと思う。実際には判断が難しいという点では五十歩百歩だと思うけど。
この論文で一番面白かったのは、解析上の良し悪しとコミュニケーション上の良し悪しは別の問題だ、というくだり。なるほど一理あると思う。実際には、分析と報告とを綺麗に分けるのが難しいこともあるけれど、考え方としては正しい。ロスマンだったかしら、RRは臨床家の発想で、RDは公衆衛生の発想だ... というようなことを書いていて、感心したことがあったのだけど、そういうのも、きっとコミュニケーション上の問題だということになるのだろう。
最後に紹介されていたけど、医者が効果指標をどう受け取るかという研究があって、RRRで示すと効果は大きめに受け取られるのだそうだ。へぇー。
読了: Walter (2000) リスク比 vs リスク差 vs オッズ比
2014年2月27日 (木)
Barratt, P. (2007) Structural equation modelling: Adjudging model fit. Personality and Individual Differences. 42, 815-824.
この雑誌のこの号はSEMについての特集号で、編集委員の問題提起に対して9人の専門家がコメントする、という構成であった。たまたま入手したまま放置していたのだけど、このたびファイルを整理していて、問題提起の要旨を読んでみたら、これが妙に面白くて... PDFをずるずるとスクロールして本文も読み終えてしまった。こんなことしている場合じゃないんだけどな。
SEMでは、データに対するモデルの不適合度を調べるためにカイ二乗検定を行う。これはかの悪名高きNHSTであって(みんな大好きな「検定」のこと)、本来は帰無仮説を支持することはできないのだが(つまり、モデルがデータに適合していることを示す証拠にはならないが)、その目的で使われている。サンプルサイズが大きくなればちょっとした不適合でも有意になってしまう、という問題点がある。
これに対して、カイ二乗検定統計量をサンプルサイズや変数の数や自由度などで調整した適合度指標をつくろうという考え方もある。そういうのは距離とか相関係数みたいなもので、読み方がむずかしい。Bentlerさんたちは読み方のゴールデン・ルールをつくろうとしていて、Hu, Li, & Bentler (1999, SEM) がその「聖書」となっている(RMSEAは0.05以下じゃなきゃ、というような話ですね)。しかあし! 最近の研究はそういう閾値の有用性を疑問視している(挙げられているのは: Beauducel & Wittmann(2005, SEM), Fan & Sivo(2005, SEM); Marsh, Hau, & Wen(2004, SEM); Yuan(2005, Multivariate Behav. Res.))。そもそも、そうした適合度指標の使われ方も、NHST的な二択ツールに堕落しているではないか。
科学の他の領域であれば、モデルの適合度は説明・予測の良さの観点から評価される。交差妥当化とか、情報量基準とか。SEMの世界の問題は、モデルが「因果メカニズムを近似している」というときの「近似」ということばの意味を誰も知らないという点にある。RMSEA=0.08のモデルを受け入れたらなにが困るのか、説明できますか? 適合度は予測の正確さではないのに、みんなそう勘違いしている。
項目反応理論をごらんなさい。同じ潜在変数モデリングでも、あれは測定志向のよりしんどい世界なのに(in the more demanding measurement-oriented area of LV), 「近似的に適合」(approximate fit)なんていう概念は存在すらしません。適合するかしないかしないかどっちかなんです(←いや先生、それとこれとは...)。ANOVAをごらんなさい、DIFをごらんなさい。approximate mean difference とかapproximate biasとか、聞いたことありますか? それがあなた、マーケティングとか組織心理学とか個人差研究なんかだと、急にapproximate fit が最重要議題になっちゃうんです。論理的とはいえませんね。
とはいえ、SEM自体は有用なツールである。使用にあたっては以下の点を推奨する。
- カイ二乗検定を必ず報告すること。「サンプルサイズが大きすぎるから有意になっちゃうんだ」なんていう寝言は10000ケースくらい集めてから言え。
- 十分なサンプルサイズを得ること。母集団がよほど小さい場合やよほど均質な場合はともかく、200以下のSEMの論文なんてリジェクトします。あなたたちに荷が重いことは重々わかっているからあまり言いたくないんだけど(ほんとにこう書いてある)、Muthen & Muthen (2002, SEM)を読んでモンテカルロ法で検定力を調べなさい。
- カイ二乗検定で棄却されちゃったら、(a)まずは、あなたが使った推定法(ML法とか)の前提が正しいかどうかチェックしなさい。多変量正規性とか。(b) そのチェックに通ったら、モデルをそのまま報告してその意義を論じなさい。(c) ないし、残差行列を調べてモデルを改善していきなさい。
- カイ二乗検定の結果を無視するなら、まずその根拠を述べなさい。適合度指標の「ゴールデン・ルール」とか「誰々がこういっている」基準は許しません。本当云うと、私は適合度指標なんてみんな禁止したい。その上で、(a) もしモデルの結果を定量的に評価できるならば、交差妥当化で予測の正確性を示し、情報量基準でモデルの倹約性を示しなさい。(b) CFAのような結果のないモデルの場合は、残差行列の分析によってカイ二乗検定を無視する理由を示すか、なんらかの外的基準を探しなさい。Reise, Widaman & Pugh (1993, Psych. Bul.)はCFAモデルの評価には理論や主観的判断が説得力が大事だといっているが、そんなのはでたらめです。
いやー、楽しくなっちゃってどんどんメモしちゃったけど、原文にはもっとキツイことが書いてあります。結局のところ、SEMユーザはモデル構築が大変な作業だということを理解する気がないんだよ、なあんて。ははははは。
著者が全力で批判している適合度指標とは、GFIとかCFIとかRMSEAとかのことで、BICやAICは原理的にはオッケーなのであろう。解釈上のゴールデン・ルールもないしね。
この論文にコメントしている9人は、Bentler (ははは), Goffin, Hayduk et al., Markland, Miles & Shevlin, Millsap, Mulaik, Steiger. 読んでないけど、いずれもかなり否定的な模様。元論文の話の進め方が雑なぶん、論点が多岐にわたりそうで (適合度指標の是非, ゴールデン・ルールの是非、NHST批判, カイ二乗検定の是非、モデル構築に実質科学的推論がどこまで必要か、云々...)、どうにも面倒くさそうだ。よほど時間ができたら、ということで...
読了: Barrett (2007) 私はSEMの適合度指標を禁止したい
2014年2月25日 (火)
Gelman, A. (2007) Struggles with survey weighting and regression modeling. Statistical Science. 22(2), 153-164. (with commentaries)
調査ウェイティング(確率ウェイティング)に関する論文。これまでに三回ほどトライし、そのたびに途中で挫折した、いわくつきの難敵。このたび細かくメモを取りながら読んで、ようやく読了。疲れた。
Gelman先生いわく。
調査ウェイティング、それはゴミ屋敷だ("Survey weighting is a mess")。単純な平均や割合の推定を別にすれば、ウェイトをどう使えばいいのかはっきりしないことが多い。平均の標準誤差さえややこしい。魅力的な代替案として、ウェイティングのかわりに回帰モデリングをするという手があるが、膨大な交互作用をどう扱うかによって結果はどうにでも変わってしまう。本論文は、標本と母集団の間の差を調整するひとつの戦略として、事後層別と階層回帰の併用を提案する。
通常、モデルに基づく推測というものは、データ収集時のデザインが「無視可能」だと暗黙のうちに想定している。つまり、回帰の文脈からいえば、標本抽出なり無回答なりに影響するすべての変数が含まれているという想定であり、標本抽出の文脈でいえば、事後層別セルのなかで抽出確率が等しいという想定である。
ここで、ウェイティングと事後層別を統一的に扱う枠組みを導入しておこう。
まず事後層別について。$X$が離散的だとして、その可能なカテゴリを事後層別セルとよび、$j$ 番目のセルの母集団サイズを$N_j$, 標本サイズを$n_j$とする。どの事後層別セルでもデータは単純無作為抽出 (SRS) だと考える。標本サイズの割り当て方はこの話とは無関係である (古典的な層別抽出も事後層別の一種と考えるわけだ)。$N_j$ は既知だとしよう (未知な場合も多いが、その推定の話は脇に置いておく)。
任意の変数の母平均
$\theta = (\sum N_j \theta_j) / (\sum N_j)$
の推定値は
$\hat\theta^{PS} = (\sum N_j \hat\theta_j) / (\sum N_j) $
である。
次にウェイティングについて。
個体ウェイトを $w_i$ として、
$\bar{y} = (\sum w_i y_i) / (\sum w_i)$
ここでややこしいのは、事後層別でないウェイティングがあるという点だ。たとえば、電話調査で世帯当たり電話回線数の逆数をウェイトにするような場合がそれだ(ウェイト値はデータと無関係に決まる)。でも、こういう固定ウェイトを使っていると、世帯当たり電話回線数と無回答の間に関係があったときにバイアスが生じる。本論文ではそういうのもみんな事後層別に組み込んだ場合を考える(つまり、固定ウェイトを使わず、世帯当たり電話回線数で事後層別する場合について考える)。
さて。
サーヴェイ・データからの母平均の推定のためにウェイトつき平均を用いるのは標準的だが、回帰のような複雑な分析の場合にどうすべきかは明確でない(※レビューとして以下が挙げられている: DuMouchel & Duncan, 1983 JASA; Kish, 1992; Pfeffermann ,1993 Int.Stat.Rev.)。
抽出確率が$X$に依存しており、$y$は$X$と$z$に依存しているとしよう。$y$の$z$への回帰を正しく推定するためには、$y$を$X$と$z$に回帰すればよい。ところが$z$も$X$と関係しているかもしれない。とすると、交互作用項をいれないといけないかもしれない。
たとえば、標本における男女の割合が母集団における割合に一致させてある調査を考えよう。$y$を収入の対数、$z$を身長とする。
まず、収入の身長への回帰係数に関心がある場合。我々はかつて以下の推定式を得た(※$male$ってのは男性である時に1, 女性である時に0となる変数):
$y = 8.4 + 0.017 z - 0.079 male + 0.007 z \times male + error$
身長$z$が与えられた時、年収の対数の期待値は
$E(y | z) = 8.4 + 0.017 z - 0.079 E(male|身長=z) + 0.007 z \times E(male|身長=z)$
今度は、白人と非白人のあいだの年収の平均的な違いに関心がある場合。推定された回帰式は
$y = 9.5 - 0.02 white + 0.20 male + 0.41 white \times male + error$
年収の対数の期待値の差は
$E(y | white = 1) - E(y | white = 0)$
$= -0.02 + 0.20 {(E(male|white=1) - E(male|white=0)} + 0.41 E(male|white=1)$
このように、交互作用項をいれたが最後、$z$なり$white$なりの係数だけみているわけにはいかないのである。(←長い説明だったわりには単純な話だ... それともなにか見落としているのだろうか?)
いよいよ本題。
New York City Social Indicators Surveyを例に挙げよう。「ニューヨークの成人は健康な状態にあると思う」という回答の割合に注目する。電話回線数、家族構成、エスニシティ、年齢、教育の分布が母集団に合うようにウェイティングして集計すると、1999年の割合は75%, 2001年の割合は78%。ちょっと増えているようだ。では、どのくらい増えているのか。ふたつの答えがある。
- 単純に差をとる。差は3.4%。
- 2年分のローデータを縦に積む。1999年データで0, 2001年データで1となるダミー変数をつける。で、この変数、ならびにウェイティングに用いた変数群 (電話線の数, 家族構成, ...) を独立変数にした回帰式を推定する。年度ダミー変数の係数は6.6%。
どちらが正しいのか? この例に限って言えば、諸事情により前者のほうが正しいと思う。でも一般には後者の方法のほうが好まれるだろう。以下では事後層別の下で正しい答えを与えてくれて、より複雑な推定対象にもスムーズに一般化できるアプローチについて考えよう。
まず、古典的なモデル。
- もっとも単純な考え方は完全な事後層別である。つまり、セル推定値 $\hat\theta_j$ としてセル平均 $\bar{y}_j$ を使って
$\displaystyle \hat\theta^{PS} = \frac{\sum N_j \bar{y}_j}{\sum N_j}$
これは、すべての事後層化セルを表すインジケータを含めた回帰だとみることができる。 - 全然ウェイティングしないという考え方もある。これは、定数項のみの回帰だと考えることができる。
- この2つの中間地点にあるのが、層別変数群をいれるが交互作用項はいれない回帰である。
三番目の路線について。層別変数がk個あり、そのデータ行列がXであるとしよう。回帰モデルは
$y \sim N(X \beta, \sigma^2_y I) $
$\hat\beta = (X' X)^{-1} X' y $
J個の事後層化セルの母集団サイズのベクトルを $N^{POP}$, 層別変数の行列を $X^{POP}$とする。セル平均の推定値は $X^{POP} \hat\beta$ だ。では母平均の推定値はどうなるか。それはセル平均の推定値の加重平均であるから
$\displaystyle \hat\theta^{PS} = \frac{1}{N} \sum N_j (X^{POP} \hat\beta)$
$\hat\beta$を代入して
$\displaystyle \hat\theta^{PS} = \frac{1}{N} (N^{POP})' X^{POP} (X'X)^{-1} X' y$
これを $\displaystyle \hat\theta^{POP} = \frac{1}{n} \sum w_i y_i$ と書きなおそう。$w$ は
$\displaystyle w = (\frac{n}{N} (N^{POP})' X^{POP} (X'X)^{-1} X') '$
$w$の合計は $n$ になる。つまり、これもウェイティングだと捉えることができる。なお、$w$はデータとモデルに依存しているが$y$には依存していない点に注意。(←おおおー。なるほど...)
次に、著者が提案する階層モデル。セル平均 $\hat\theta_j$ を階層モデルで推定する。モデルは
$y \sim N(X \beta, \Sigma_y)$
$\beta$の事前分布は
$\beta \sim N(0, \Sigma_\beta)$
とすると (...中略...) とまあこのように、母平均の推定値は、これこれの式で求めた $w$ によってウェイティングした集計値になる。この方法なら、層別変数間の交互作用項もがんがん叩き込める。
ここで $w$ は $y$ の分布にも依存している点に注意 ($y$の層内分散と層間分散に依存する由)。従って、注目している変数が変われば $w$ も変わる。(←なるほど...)
考察。
もともとウェイティングには次の欠点がある。(1)回帰係数のような複雑な推定対象に対してどうウェイティングすればいいのかわからない。(2)標準誤差の推定が困難。(3)ウェイト値をつくるのが大変。層別変数を選んだり、交互作用をどこまでいれるかきめたり、セルをプールしたりウェイト値を切り詰めたり。
いっぽうモデリング路線ににも欠点がある。ちょっとした調査でも、層別変数をいれたモデルはえらく複雑になる。
本論文で提案したような、信頼がおけてかつ簡単な統合的アプローチの開発が求められている。云々。
いやー、疲れた。
もともとこの論文を読もうとしていたのは、平均や割合のウェイティングと、もっと複雑な統計量のウェイティングを統一的に扱う枠組みに関心があったからであった。そうした具体的な展開はなかったので、その点では期待通りではなかったけれど、勉強になったので良しとしよう。特に、回帰モデルによる共変量調整とウェイティングによる調整の関係を整理するところが大変勉強になった。これまで誤解していた点に気が付いた。
この論文、5人の研究者によるコメントと返答がついているのだが(Bell & Cohen, Breidt & Opsomer, Little, Lohr, Pfeffermann)、力尽きたのでパラパラめくっただけ。返答のほうにはこんなことが書いてあった: 私はウェイティング路線やモデリング路線に対していささか悲観的すぎたかもしれない。優秀なリサーチャーなら適切なウェイトを決められるかもしれないし、標準誤差だってジャックナイフ法とかでうまく求められるかもしれませんわね。またモデリングの際にはブートストラップ法などが助けになるかもしれませんわね。云々。
2022/08/13 追記: 再読し、メモを取り直しました。
読了: Gelman (2007) ウェイティングと回帰モデリングを巡る悪戦苦闘
2014年2月24日 (月)
Reise, S.P., Widaman, K.F., Pugh, R.H. (1993) Confirmatory factor analysis and item response theory: Two approacehs for exploring measurement invariance. Psychological Bulletin, 114(3), 552-566.
測定不変性の検討方法についての論文。
えーと、まかり間違ってこのブログに目を留められた奇特な方のためにご紹介いたしますと、たとえば、同じ調査を日本と中国でやりました。調査票の翻訳には十分気を配ったんですけど、果たして回答を比較しちゃっていいものなのでしょうか? 日本ではこの項目への回答が対象者の××という特性の程度をあらわしていると考えられているのですが、中国でもそうなんでしょうか?... というようなのが、測定不変性(measurement invariance)という問題である。市場調査に関わる方であれば、これがものすごく深刻な話題であることをご理解いただけると思います。
その割には、測定不変性の実証的検討について関心を持つ実務家は、不思議に少ない、というか、恥ずかしながらお目にかかったことがない(以前お世話になっていた教育測定の会社は別にして)。もしかすると、なにか言霊信仰のようなものがあるのかもしれない。「測定不変性」とひとたび口に出すだけで、その深刻さが現実となり、異なる集団の間で調査結果を比較できなくなり、商売あがったり、というような。
まあいいや。測定不変性を検討する際の二大流派、CFA(確認的因子分析)とIRT(項目反応理論)のそれぞれについて、その使い方を示します、という論文であった。えー? 2パラメータIRTはカテゴリカルCFAと同じことでしょ、そんな細かいことを... と思って放っておいた論文なのだが、ふと見たら、いつのまにか「必ず読むこと」というタグが付いている。なぜ・いつ付けたんだか、全然記憶にない。困るなあ、こういうの...
CFAといっても、カテゴリカルCFAがIRTと等しいというような話ではなくて、あくまで線形なCFAの話なのであった。
まずCFA。$n$個の項目への反応のベクトル $X$ を次のようにモデル化する:
$X = \Lambda \xi + \delta$
$\xi$は$r$個の潜在変数得点のベクトル、$\Lambda$はサイズ$n \times r$の負荷行列である。途中はしょりまして、標本共分散行列を$S$として
$S \sim \hat{\Lambda} \hat{\Phi} \hat{\Lambda}' + \hat{\Psi}$
$\Phi$は潜在変数の共分散行列、\Psiは誤差の共分散行列である。多群に拡張して
$S_g \sim \hat{\Lambda}_g \hat{\Phi}_g \hat{\Lambda}'_g + \hat{\Psi}_g$
この文脈における測定不変性は、$\Lambda_g$がどこまで群間で等しいか、という問題になる。
実例。1因子5項目(5件法リッカート)の不安尺度。中国とアメリカの標本を比較。カイ二乗検定で$\hat{\Lambda}_g$ 全体の等値制約を棄却。修正指標で部分測定不変モデルを作る手順を示している。この頃はこういうチュートリアルがまだ少なかったのであろう。眠いので省略。適合度指標はカイ二乗のほかにTLI, noncentrality index, RMSEAを使っている。
次、IRT。5件法なのでSamejimaモデルを使う(懐かしい...)。潜在変数 $\theta$の下で 反応 $x$ がカテゴリ $k$ に落ちる確率は、
$P(x = k | \theta) = P*(j-1) - P*(j)$
$P*$ は項目反応関数で、j番目の閾値を上回る確率は
$P*(j) = 1 / (1 + exp[-a (\theta - b_j) ])$
識別性$a$, 困難度$b$の意味についての懇切丁寧な説明があって(省略)... IRTの文脈では、測定不変性とは各項目の$a, b_1, b_2, b_3, b_4$が群間で等しいかという問題である(DIFって奴ですね)。適合度の指標としては -2*対数尤度を使う。MULTILOGの出力ではこれを$G^2$という由。また、個人レベルでperson-fit統計量を調べる。項目反応関数の下でのある対象者の反応の尤度を標準化した値を $Z_l$ 統計量と呼び、person-fitの下で$N(0,1)$に従うのだそうだ。へぇー。
というわけで、実例に突入。ところで、多群CFAならば、識別のためにどこかの群の因子分散を1に固定したり、どこかの項目の因子負荷に等値制約をかけたりするけど、多群IRTではどうやるのか。著者いわく、こういう話は計量心理学の外側ではあまり紹介されないので、ゆっくりご説明しましょう。ちょっとそこに座んなさい。(←とは書いてないけど)
「各群の$\theta$の分散を1にする」作戦はもちろん使えない(パラメータ$a, b$が比較できなくなる)。「どこかの項目のパラメータを群間等値にする」作戦もある。この哀れな生贄をアンカー・テストという。でも、どの項目を生贄にするかをどうやって決めるのか。
そこで次の作戦を採る。USと中国の対象者をたて積みにし、USの対象者は項目1~5に、中国の対象者は項目6~10に回答したのだ、と考える(他の項目への回答は欠損になる)。USブロックの$\theta$の分布を平均0, 分散1に固定する。中国ブロックの$\theta$の平均は自由推定、分散は適当な値に固定する。これをもってベースライン・モデル、すなわち群間等値制約のないモデルとみなす。云々。うっわー、めんどくさいー。
そんなこんなで、手間暇かけて部分測定不変モデルを構築する手順を示している。
考察。
- CFAでは潜在変数と反応の線形な関係が仮定されている。IRTではそうではない。もっとも、これから非線形的な因子分析モデルの研究が進むだろう。
- 潜在変数の推定には、測定不変じゃない項目でも有用だが、潜在変数の分布を比較するためには測定不変な項目がいくつか必要である。これはCFAでもIRTでもかわらない。
- CFAのほうがモデルの指定が楽。段階反応IRTで多群分析をやろうと思ったらMULTILOGが必要で、使い方が難しい。(←この論文の当時の話でありましょう)
- IRTの適合度指標はCFAほどリッチじゃない。とかなんとか。
なんで2013年になってこんな論文を読んでんだか、と面倒になってきて、途中から読み飛ばしてしまった。思うにこの時代には、「測定不変でない項目は分析からまるごと除外しなきゃいけない」というような通念があって、それがこの論文のひとつの仮想敵だったのかもしれない。よくわかんないけど。
ま、いいや。person-fit についての知識が足りない、というのがこの度の教訓であった。
読了: Reise, Widaman, Pugh (1993) 測定不変性の検討:CFA vs IRT
2014年2月20日 (木)
Muthen, B. (1994) Multilevel Covariance Structure Analysis. Socilogical Methods & Research, 22(3), 376-398.
仕事で階層因子分析モデルを組んでいて、混乱しちゃうことがあったので、頭を整理するために読んだ。導師Muthen, 哀れな文系ユーザ向けに、共分散構造分析(というかCFA)において階層データを正しく扱う必要性を説くの巻。導師は素人向け説明の達人であらせられるので、こういうのは読まなきゃ損である。ま、ちょっと古い論文ではあるけれど。
えーっと... まず階層CFAモデルの概説。順を追って懇切丁寧に説明しておられて、頭が下がります。
結局のところ、こういうモデル。群 $g$ に属する個人 $i$ の観察値ベクトルを y_{gi}として
$y_{gi} = \nu + \Lambda_B \eta_{Bg} +\epsilon_{Bg} +\Lambda_W \eta_{Wgi} + \epsilon_{Wgi}$
$\eta$が因子、$\Lambda$が負荷である。
で、このモデルをふつうのSEMのソフトで推定する方法を紹介。要するに、観察変数$y_1, y_2, \ldots$が潜在変数$y_{B1}, y_{B2}, \ldots$を持ち(係数は固定)、観察変数には $\eta_W$からパスが刺さり、潜在変数には $\eta_B$ からパスが刺さる、というモデルである。推定方法として、導師が提案するMUML推定量を紹介。これはFIMLの近似だが、計算が簡単である由。このへん読み飛ばしちゃったけど、まあいいや。いまでは導師自らが開発したMplusで簡単にFIML推定できてしまう。
導師お勧めの手順は以下の通り。
- まずは階層を無視してCFA。モデルの適合度はインフレを起こすけど、あたりをつけるぶんには構わない。
- 各変数について級内相関を推定する。ここでいう級内相関とは、群間の母分散を$\sigma^2_B$, 群内の母分散を$\sigma^2_W$として $\sigma^2_B / (\sigma^2_B + \sigma^2_W)$ のこと。これがいずれも 0 に近かったら、階層を気にすることはないわけだ。$\sigma^2_W$はプールした群内分散$ s^2_{PW}$で推定すればよい。いっぽう $\sigma^2_B$の推定量は、群間分散$s^2_B$じゃなくて、クラスサイズを $c$ として $(s^2_B - s^2_{PW}) / c$ になる(ああそうか、1要因のANOVAだと思えばいいのか)。ま、級内相関も、いまではMplusがさっと出してくれるけど。
- プールした群内共分散行列 $S_{PW}$について、ふつうのCFAを行う。 $S_{PW}$は群内の母共分散行列 $\Sigma_W$の推定量だから、理屈の上からいえば、それは 群間共分散行列 $\Sigma_B$ に制約をかけなかったときの階層CFAに等しいし、実際にも近いパラメータ推定値になる。サンプルサイズはN-(群の数)とすること。GLS推定でもML推定でもよろしい。
- 順番からいえば、次は群間構造の推定だが、これは結構難しい。群間共分散行列 $S_B$ は、群間の母共分散行列 $\Sigma_B$ の推定量ではなく、$c \Sigma_B + \Sigma_W$ の推定量なのだ (群内分散が大きいと群間分散も大きい)。従って $S_B$を分析するのはお勧めでない由。
- 以上を踏まえて、ちゃんとした階層CFAをやる。(なーんだ、結局やるのか)
後半は分析例。生徒の算数の成績データ(6項目)の1因子CFAで、学級を無視した分析が項目の信頼性(共通性のことであろう)を過大評価してしまうことを示している。あー、なるほど。素朴に言えば、学級の効果のせいで項目間相関がインフレを起こすわけだ。
とかなんとか。適当に読み飛ばしちゃったけど、勉強になりました。ちょっと古めの論文を読むのもそれはそれで良いかもしれない。
読了: Muthen (1994) 階層共分散構造分析へのご招待
2014年2月14日 (金)
Behar, R., Grima, P., Marco-Almagro, L. (2013) Twenty-five analogies for explaining statistical concepts. American Statistician, 67(1), 44-48.
昼飯のついでに読んだ記事。統計学を教えるとき、ちょっと気の利いたたとえ話なんかがあると、講義も面白くなり出席者も目を覚まそうというものですよね、そこで入門講義に便利なアナロジーをまとめてみました、という内容。American Statisticianという雑誌にはTeacher's Cornerというページがあって、ときどきこういうのが載る。適当に意訳しながらメモしておくと...
- 氷山。海面上の一角しか見えないけど、実は巨大である。統計学も同じこと。メディアに出てくるスポーツやらなんやらの統計ばっかりじゃないんですよ。
- 指名手配の似顔絵。あの絵を描く担当者は、あいまいな情報のなかから鍵になる要素を選び出して形にする術を知っている。データの分析も同じこと。データ全体をうまく記述する指標を選びましょう。
- 火星人の身長。その平均が50インチだったとして、さあ地球人より背が高いでしょうか、低いでしょうか。実は大多数は80インチ以上だったりするかもしれないですよね。平均だけでは不十分ですよ。
- 平均のことだけ考えているとひどい目にあうかもしれないよ、というジョーク集。台所で頭をオーブンに足を冷蔵庫に突っ込めば、体全体でみたら適温ですよ、などなど、いまいち笑えない冗談が4つ紹介されている。
- シーソー。大人と子供が両側に座ってバランスを取りたかったら、大人はずっと中心寄りに座らないといけないですよね。ドットプロットもこれと同じ。平均で支えられているシーソーのようなものです。
- 火星人のバスケット・チーム。火星人の身長が、平均55インチ、SD8インチの正規分布に従うとしましょう。地球人と試合したら勝つのはどっち? 地球人の選手が身長80インチくらいあったとしても(すなわち、地球人の身長が平均68インチ、SDが3インチの正規分布に従うとして、平均+3SD以上だったとしても)、もし火星人が平均+4SD以上の選手を送り出して来たら、きっと負けちゃいますね。(←このたとえ話、一体なにが面白いのかわからない...別に正規分布に従っていなくてもその通りですよね...)
- 高速道路のクルマの速度。速度制限サインの効き目を調べるために、通過する自動車の速度を測定しました。平均はだいたい時速50マイルでした。ところが10マイルで走る車が一台、90マイルで走る車が一台ありました。前者はきっとトラクターだからどうでもよい、問題は後者ですよね。異常値というのもそういうもので、値だけでは決められないのです。
- 音楽の種類。知っている人が聴いたら「あ、ボレロだ」とわかるけど、知らない人が聴いたらボレロもサルサもルンバも区別がないですよね。確率変数というのもそのようなものです。知らない人にとってはどれも似たようなものだけど、統計学の知識があれば、正規分布とか二項分布といった区別がつくのです。
- 完全な球体。地球は完全な球体ですか? 太陽は? ビリアードの球は? 完全な球体なんてどこにも存在しませんよね。統計モデルもそういうものです。
- 1ダースの卵の重さ。そのバラツキは、1個の卵の重さを量ってそれを12倍した値のばらつきとは違いますよね? このように、同一の確率分布に従うk個のランダムな値を合計したものは、1つの値をk倍したものとは異なります。
- 的(まと)。推定量が不偏であるということは、弾が的の中心のまわりに当たるということ、推定量の分散が小さいということは、弾がまとまった場所に当たるということです。不偏であることが常に最良とは限りません。
- 裁判。裁判の目的は、被告が無実だということの論証ではなく、無実だという仮説と矛盾する証拠があるかどうかし調べることです。証拠がないなら有罪にはなりませんが、被告の潔白が証明されたわけではありません。帰無仮説も同じことです。
- 指の本数。有意水準5%というのは、ただのキリのよい数字です。私たちの手に指が6本あったら、きっと6%になっていたでしょう。
- 傘を忘れることと、見通しのきかない山道で反対車線を走ること。降水確率が10%の日、家に傘を忘れたら取りに戻りますか? 戻らないでしょう? 見通しのきかない山道で、対向車が来る確率が低いからといって、反対車線を走りますか? 走らないでしょう? 全ての決定において誤りの確率を揃えようとするのはおかしいです。
- X線写真。お医者さんはX線写真を見るとき、健康な人のX線写真を思い浮かべ、それと比較します。これが基準分布です。幸運にも、既知の確率分布が基準分布のとき、検定統計量のある値がそれに合致している程度を定量化することができます。これがp値です。
- 双眼鏡の倍率。サンプルサイズとはそのようなものです。
- 100回のうち95回、本当のことをいう人。信頼区間とはそのようなものです。
- 正しい推定を出力するコンピュータの数。コンピュータ・ルームで各学生に正規乱数列を与えて、たとえば50%信頼区間を計算させます。で、真の平均を伝え、自分が求めた信頼区間のなかにそれが入っていた学生に挙手させると、だいたい5割くらいの学生が手を挙げるでしょう。
- スープを味見するスプーン。スープの味見は小さじで十分。鍋が大きくても関係ありません。サンプルサイズと母集団とはそのようなものです。
- 鍋をよくかき混ぜること。味見の際に大事なのはそれです。標本は無作為でなければなりません。
- 川の深さ。川を歩いて渡るとしましょう。どこかに足がつかない箇所があるとわかったら、その他の場所の水深を調べても仕方がありません。このように、サンプルサイズを増やすことが推定値の有用性を高めるとは限りません。
- 血液検査。血液型を調べる場合、たった一滴の血液で十分です。どの血液の一滴を調べても同じだからです。このように、パラメータの推定に必要なサンプルサイズは、母集団における変動の大きさによって決まります。
- 消防士の数と火災被害。集まった消防士の数が多い火事ほど被害も大きいでしょうが、そこに因果関係はありません。このように、相関と因果は異なります。
- 試験のためのコンサルタント。あなたはいま試験を受けなければなりません。出題範囲には100個の事柄が含まれていて、あなたはどれも知りません(←すごい状況だ)。そこで、友達を二人連れて行くことを許可します。どんな友達を連れて行きますか? まず一人目は、たくさんの事柄を知っている友達を選びましょう。では二人目は? 2番目に物知りな友達じゃなくて、1番目の友達が知らないことを知っている友達を選ぶのがよいでしょう。回帰における変数選択とはそのようなものです。
- ゴミを捨てるとき。大事なものを捨ててしまわないよう注意しましょう。残差もそれと同じ。大事な情報が含まれていないかどうか注意しましょう。
25個もあるなら、少しはこみいった話も出てくるかと思ったのだが、案外に入門も入門レベルな話題ばかりであった。統計学を教えているピンからキリまでのいろんな人に、「講義用の必殺のジョークをひとつ教えてください」という郵送調査をやったら、いろいろ面白かろう。
読了:Behar, Grima, & Marco-Almagro (2013) 統計学を教えるための25のたとえ話
2014年2月11日 (火)
Toomet, O., Henningsen, A. (2008) Sample selection models in R: Package sampleSelection. Journal of Statistical Software, 27(7).
Heckman型の標本選択の下での回帰モデルを推定するRパッケージ sampleSelection の紹介。実際にはJSSの論文ではなく、その改訂版であるvignetteを読んだ。ま、めくっただけだけど。
二段階推定と最尤推定の両方に対応。そのほか、Tobit-5という、(標本選択じゃなくて)結果変数が2つの潜在変数のあいだで切り替わるモデルも推定できる由。ふーん。
読了: Toomet & Henningsen (2008) sampleSelectionパッケージ
Puhani, P.A. (2002) The Heckman correction for sample selection and its critique. Journal of Economic Survey, 14(1), 53-68.
先に目を通したBushway, Johnson, Slocum (2007) で何度も引用されていた論文。面白そうなので目を通した。
まず、Heckmanの二段階推定についての簡にして要を得た説明(計量経済学の和書など読んでないで、まずこれを読めばよかった...)。次に、批判者の論点を紹介。
批判その一、Two-part model。Heckmanは選択バイアスの下で観察される従属変数 $y_1$を
$y^*_1 = x'_1 \beta_1 + u_1$
$y_1 = y^*_1 if y^*_2 > 0$
$\ldots$
という風にモデル化したわけだが(個体を表す添字 $i$ を略記)、そうじゃなくて最初から
$y^*_1 | y^*_2 = x'_1 \beta_1 + u_1$
$y_1 = y^*_1 if y^*_2 > 0$
$\ldots$
という風に考える。こういう考え方をTwo-part model(TPM)という。著者いわく、TPMを支持する意見はさらに3つに分かれる。
- TPMは$y^*_1$の条件付き期待値についてのモデルだ。我々が関心を持っているのはそれでしょ?
- TPMはHeckmanと同じく、選択の過程をモデル化しており、違いは分布の想定だけだ。TPMでは$y^*_1$のunconditionalな残差分布として混合分布を想定していることになるのだ。
- Heckmanのモデルの$x'_1$も、TPMでの$x'_1$も、まあ似たようなもんじゃないですか、という実に荒っぽいご意見。
批判その二。Heckmanの方法では、上のモデルに加えて
$y^*_2 = x'_2 \beta_2 + u_2$
というモデルを立て、ここから逆ミルズ比を求め、従属変数が観察されているサブサンプルのOLS回帰式に放り込む。でも、$x_2$ が$x_1$と異なる変数を含んでいない限り (exclusion restrictionsって奴ですね)、逆ミルズ比は$x_1$と高い相関を持ち、従ってマルチコが生じる。
批判その三。$u_1$と$u_2$について二変量正規分布を想定するのは強すぎる。セミ・パラないしノン・パラな方法を使うべし。
さて、Heckmanの二段階推定(ないし、FIMLによる一発推定)と、サブサンプルのOLSを比較したモンテカルロ・シミュレーション研究がすでにたくさんある由。それらの結果を表にしてまとめましたのでご覧ください、というのがこの論文のメインディッシュ。著者のまとめによれば、とにかくexclusion restrictionsを与えよう、それが無理なら、単にサブサンプルでOLS推定したほうがいいんじゃない? とのこと。
プラクティカルなアドバイスに関しては、この後に出たBushwayらのレビューのほうが詳しいんだけど、説明がわかりやすくて、勉強になりましたです。
読了: Puhani (2002) ヘックマンの二段階推定とその批判
勤務先の仕事の関係で、延々と続くデータの前処理を心を無にして片付けながら、ひょっとしたらこの話ってHeckmanじゃない?という疑念が心に浮かぶのを、いやいやそんなことはない、とあわてて打ち消した。いよいよ分析に入ってみると、誰がどうみてもHeckman。どこからどう考えてもHeckman。いやいや!固定観念に縛られてはならないぞ、適切に変数変換すればいいんじゃないか、実はトービット変数だと捉えられないか、欠損のあるSEMの枠組みで行けないか、潜在混合回帰ではどうか、いっそ回帰から離れてみてはどうか、この際データ解析をやめちゃえば...と、散々頭を捻ったが、どんなにごまかしてみても、絵に描いたようなHeckmanとしかいいようがない。計量経済学の教科書に出てくる、回帰モデルにおける選択バイアスの修正(「Heckmanの二段階推定」、またの名をヘキット)を、そっくりそのまま実場面に移したような状況である。嗚呼...
つまらない言い訳だけど、心理学出身者はあんな手法は習わないし使わない。さらにいえば、ふだん使わない手法に手を出すのは、加齢とともにだんだん億劫になってくるのである。
Bushway, S., Johnson, B.D, Slocum, L.A. (2007) Is the magic still there? The use of the Heckman two-step correction for selection bias in criminology. Journal of Quantitative Criminology, 23(2), 151-178.
というわけで、計量経済学の教科書を引っ張り出して付け焼き刃の勉強を済ませ、そのついでに読んでみた論文。人文社会系研究者(すなわち、数学がすごく得意とはいえない人たち)向けの啓蒙的レビューだなんて、誂えたような塩梅である。
なんでも、犯罪の研究ではHeckmanの二段階推定を使うことがすごく多いのだそうだ。なんで?と疑問符で一杯になったが、読み進めてみると、この分野ではたとえば懲役刑の年数を従属変数にした回帰モデルを組んだりするらしい。なるほど、懲役刑になったケースだけを取り出して調べていると、選択バイアスを受けるわけだ。
で、著者らいわく、犯罪研究におけるHeckmanの手法の適用は誤用に満ちている。その例:
- Heckmanの方法では、従属変数が観察されるかどうかを説明するプロビット回帰と、観察された従属変数の値を説明する線形回帰モデルの二本を推定するんだけど、前者のモデルでプロビットじゃなくてロジットを使ってしまっている。(←正直、そんな細かいことを...と思っちゃいました。すいません)
- 二値の従属変数に対してHeckmanの二段階推定を使ってしまっている。(それは確かにやばそうですね)
- Heckmanの方法では、二本目の線形回帰モデルに一本目のモデルから求めた変数を入れるんだけど(逆ミルズ比。要するに観察されるかどうかのハザード比みたいなものだと思う)、そのかわりに観察される確率をいれちゃっている。
- 標準誤差の算出の仕方を間違えている。ちゃんとしたソフトを使いなさい。
その他、二段階推定だけじゃなくて最尤法(FIML)も使いなさい、できるかぎり「プロビット回帰モデルのほうにだけいれる独立変数」を用意しなさい(exclusion restrictionsというそうだ。むしろそれがなくても解が得られるというところがマジカルである)、選択バイアスの大きさを評価する指標があるから使いなさい、云々という仰せでありました。
こういう方法論レビューって、たいてい「統計ソフトのアウトプットを盲目的に使うのはやめなさい」というアドバイスが含まれるものだが、このレビューではむしろ「ちゃんと統計ソフト使って計算しなさい」というアドバイスになっているところが面白い。犯罪を研究している人だって統計ソフトは使うだろうから、おそらくソフトの種類の問題であろう。
読了: Bushway, Johnson, Slocum (2007) 魔法じゃないのよヘキットは
2014年1月27日 (月)
Wickham, H. (submitted) Tidy data. Journal of Statistical Software.
reshape, reshape2, ggplot2, plyr, RStudioなどで知られるR界の怪人(?) Wickhamさんが最近書いたドラフト。先日リリースされた爆速集計パッケージ(dplyr)の使い方を覚えようと思ってwebを眺めてたら、まあ最初にこれを読んでくれよとの仰せなので、はぁそうですか、と真面目に目を通したのである。でもこれ、dplyrとはあんまり関係ないんじゃないですかね...
著者の考えるところの標準的なデータ形式、すなわちtidy dataについて説明する内容であった。tidy dataとは、変数が列で、オブザベーションが行で、データベースでいうところの正規化されたテーブルを指す概念。ある対象についての時系列が横に並んでいるようなやつは、従ってtidyではない (時間という変数が列になってないから)。はいはい...
読了:Wickham (submitted) きれいなデータとはなんぞや
2014年1月11日 (土)
Wehrens, R., Buydens, L.M.C. (2007) Self- and Super-ornizing Maps in R: The kohonen Package. Journal of Statistical Software, 21(5).
自己組織化マップのRパッケージはいくつかあるけど、そのうちkohonenパッケージについての紹介。ざざざーっと目を通しただけ。パッケージを使う前にこういうのをめくらないと、なんだか落ち着かないのである。気が小さいというか、なんというか。
このパッケージには、ふつうの教師なし学習の関数 som(), 教師あり学習のxyf(), bdk()があるけど、結局これらは複数の層のマッピングを同時に行う supersom() の特殊ケースなのだそうだ。さらにsupersom()は欠損値も扱える由。へー。
読了: Wehrens & Buydens (2007) kohonenパッケージ
2013年11月 5日 (火)
Asparouhov, T., Muthen, B. (2013) Multiple-group factor analysis alignment. Mplus Web Notes, 18. www.statmodel.com.
ここしばらく、仕事方面でちょっと珍しいくらいのドタバタが続いていて、休みになるとてきめんに体調を崩すものだから、急ぐ用事のない論文など読んでいる暇はほとんどなかったし、めくっても端から忘れてしまった。ようやく少しだけ一息ついたので、リハビリのつもりで目を通した論文。やれやれ。
SEMソフトウェアMplusの最新バージョンに搭載された、多群モデルでのalignmentオプションについての解説。いまのところMplusの資料扱いだが、Structural Equation Modeling誌に受理されている由。
どういう話かというと... PISAやTIMSSや、世界XXヶ国調査なあんていうような、群の数がすごく多い多群データに対する確認的因子分析では、教科書的に尤度比検定でちまちま測定不変を確かめたり等価制約を緩和したりすんの、現実的じゃないでしょ? もっと便利な方法を考えたから使ってね、という趣旨。
1因子の多群因子分析モデルについて考える。群 $g$ に属する 対象者 $i$ の 項目 $p$ における値を $y_{ipg}$ とする。因子得点を $\eta$, 負荷を$\lambda$, 切片を$\nu$で表記して、
$y_{ipg} = \nu_{pg} + \lambda_{pg} \eta_{ig} + \varepsilon_{ipg}$
まず、いわゆるconfigural model、すなわち切片 $\nu_{pg}$ と負荷 $\lambda_{pg}$を群ごとに自由推定するモデルについて推定する(M0と呼ぶ)。識別の都合上、因子平均 $\alpha_g$を0, 因子分散 $\psi_g$を1とするのが通常のお約束である。推定された切片を$\nu_{pg, 0}$, 負荷を$\lambda_{pg, 0}$とする。
さて、$\alpha_g=0, \psi_g=1$としたけれども、これらをどう変えようが、切片と負荷を
$\nu_{pg,1} = \nu_{pg,0} - \alpha_g ( \lambda_{pg,0} / \sqrt{\psi_g} )$
$\lambda_{pg,1} = \lambda_{pg,0} / \sqrt{\psi_g}$
とすれば、そのモデルはM0と同じ尤度を持つ。そりゃそうだ。
そこで! 群間の測定変動の大きさを表現する関数を考え、これを最小化する $\lambda$と$\nu$をみつけましょう、というのがalignmentアプローチ。な・る・ほ・ど-。論文でも触れているけど、これ、因子の回転の話とよく似ている。回転の場合は解釈しやすさを目指して因子負荷を変えていくけれど、ここでは群間の測定不変を目指して因子分散と因子平均を変えていくわけである。
最小化する損失関数は、
$F = \sum_p \sum_{g1 \lt g2} \omega_{g1, g2} f(\lambda{pg_1,1} - \lambda{pg_2,1}) + \sum_p \sum_{g1 \lt g2} \omega_{g1, g2} f(\nu{pg_1,1} - \nu{pg_2,1}) $
つまり、「ある項目に注目し、ある2群のペアについて、負荷の差と切片の差を求めなさい。それぞれを関数 $f$ で変換しなさい。それにそのペア特有な重みを掛けなさい。これを全項目、全ペアで足しあげなさい」という関数である。重みをつけるのは群サイズがちがうかもしれないからで、$\omega_{g1, g2}$は群サイズの積の平方根とする。
ここで関数 $f(x)$ のことを component loss function (CLF) という由。微分する都合で $f(x) = \sqrt{\sqrt{ x^2 + \epsilon}}$ とするけど($\epsilon$はすごく小さな定数)、気持ちとしては $f(x) = \sqrt{ |x| }$ である。平方根をとっているのは、「たくさんの項目でパラメータがそれなりに群間で類似させたい」というより、「少数の項目は大きくずれてかまわないから、たいていの項目を群間でぴったり揃えたい」からである由。識別の都合上、各群の因子分散の積を1とする。因子平均は、最初の群を0に固定するか (FIXED), 全部自由推定する(FREE)。
以上をベイズ推定する。ベイジアンでないと解けないというわけじゃないけど、そっちのほうが柔軟だから、という理由らしい。なおベイジアンといっても、M0のときは正直に無情報事前分布を使う手と(configural method)、M0の段階で事前分布に強い群間相関を入れちゃう手がある(BSEM method)。
論文後半は、シミュレーションを3つ、実データへの適用をひとつ。FREEとFIXEDのどっちがいいか、とかなんとか(どうも一概にはいえないらしい)。面倒なので読み飛ばした。
結論:
- 群の数が多いときに便利。
- 探索的方法であるととらえることもできる。ちょうどEFAのあとでCFAをやるように、この方法のあとで多群のCFAに移るがよろし。
- この方法の対抗馬は、群をクラスタに見立ててランダム切片とランダム負荷を導入したマルチレベルモデルだが、こっちのほうが気が利いている、というテクニカル・ペーパーを別途書いたので読むように。もっとも、群の数が100を超えるくらいに多かったり、測定不変のパターンが明確でない場合には不利だけど。
- 限界: 多因子モデルに拡張することはできるが、cross-loadingは許されない。共変量つきのCFAモデルもだめ。いまのところ変数は連続か二値でないとだめ(このへん、だんだんMplusの実装の説明になっているような気が...)。
- 今後の課題: Exploratory SEM(ESEM)への拡張、パラメータのバイアスの性質についてのさらなる検討。それから、この方法が前提にしている「データにはなんらかのほぼ測定不変なパターンがあるはずや」(なぜか関西弁)という想定が破られていないかどうかを調べる方法の開発。たとえば、実は測定不変な指標のほうがごく少ないという場合でも、この方法では一番シンプルで一番測定不変っぽいモデルが示唆されてしまう、という問題があるわけだ。
いやあ、素晴らしい。こいつは便利そうだ。マルチ・カントリー調査データの分析で測定不変の問題に直面するたびに、まさにこういう風な、たとえば「10ヶ国を通してみたときこの項目は抜いたほうがいいっすね」といえるような探索的手法があるといいなあと思っていたのである。そういうニーズを抱えていたのが自分だけでなかったとわかって、とてもうれしい。そりゃそうだよね! ちまちま制約緩和なんて、やってらんないよね!
cross-loadingが許されないというところがちょっとつらいが、自分の仕事に直接に役に立ちそうな手法であった。さっそく試させて頂こう。いやあ、ありがたい、ありがたい。
読了: Asparouhov & Muthen (2013) たくさんの群を通じて測定不変な因子分析モデルを手っ取り早くつくる新手法
2013年7月12日 (金)
Vaupel, J.W., Yashin, A.I. (1985) Heterogeneity's ruses: Some surprising effects of selection on population dynamics. The American Statistician, 39(3), 176-185
生存時間分析において、集団レベルのハザード曲線は、それを構成するどの個人のハザード関数とも全く異なる可能性がある。ハザード関数に個人差があると、集団の中でセレクションが起きてしまうからである。一番単純な例を挙げれば、全員のハザードが時間独立な定数だとしても、その値が高い群と低い群が混在していると、前者の割合はどんどん減るから、集団のハザードは時間とともに低下することになる。ましてや、各群のハザード関数の形状が違ってたりなんかした日には、とんでもない複雑な曲線が出現するわけで...
という話を、手を変え品を変え縷々説明した論文。先日読んだSinger & Willett 本で紹介されていたのがきっかけで探してみたら、冒頭の事例が面白く、これは読まねばならん、と印刷した。以来、ずっとカバンに入っていたのだが、読み進めども読み進めども似たような例が立ちはだかり、だんだん頭に入らなくなってしまった。数行進むだけで猛烈な睡魔が。
というわけで、後半は全然頭にはいっていないけど、整理の都合上読了にしておく。ゴメンナサイ。
このトシに至って、なおこうやって勉強してるのって、無理があるのかしらん。。。ううむ。
読了:Vaupel & Yashin (1995) ハザードの個人差が我々をたぶらかす(というような話)
2013年6月26日 (水)
Tan, P.N., Kumar, V., Srivastava, J. (2004) Selecting the right objective measure for association analysis. Information Systems, 29, 293-313.
先日読んだ Lenca et al. (2008)に引き続き、ふたつの二値変数AとBのあいだの関連性の指標を比較検討する研究。とりあげる指標は:
- ファイ係数
- Goodman-Kruskalのラムダ
- オッズ比
- YuleのQ
- YuleのY
- カッパ
- 相互情報量
- J指標(相互情報量と同じくエントロピー系の指標である由)
- ジニ係数
- サポート
- 確信度(=max(P(B|A), P(A|B))、つまり、いわゆる確信度を行側からと列側からの両方で求め、大きいほうを採っている)。
- Laplace(確信度系の指標)
- Conviction(確信度系)
- Interest(式をみたらリフトのことだった)
- コサイン
- Piatetsky-Shapiro(確信度系)
- Certainty factor(確信度系)
- Added Value( =max(P(B|A)-P(B), P(A|B)-P(A))。中心化した確信度)
- Collective Strength(なんだかわからんがこれも確信度系らしい)
- Jaccard
- Krosgen(上述のAdded Valueを基準化したもの)。
で、こうした指標に期待される性質として、著者らは以下を挙げる。
- Piatetuky-Shapiro(1991, in "Knowledge Discovery in Databases")が挙げた3つの特徴。
- AとBが統計的に独立な時に 0 (ないし、基準化すれば0) となること。
- P(A)とP(B)を固定したとき、P(A, B)とともに単調増加すること。
- P(A,B)とP(B)、ないしP(A,B)とP(A)を固定したとき、残るP(A)ないしP(B)とともに単調減少すること。
- 対称性。つまり、2x2のクロス表を転置しても値が変わらないこと。もっとも、ルール発見という観点からはむしろ変わってくれたほうがよいわけで (if A then B とif B then Aでは違っていて当然だから)、だから必須の特徴とは言いがたい。この論文では、そもそも指標の定義の段階で、どの指標も対称的になるようにしている。
- 行/列の尺度不変性。つまり、行なり列なりをそれぞれ定数倍しても値がかわらないこと。通過できるのは、オッズ比、YuleのQ、YuleのY、のみ。
- 1行目と2行目をいれかえたとき、値は元の値に-1を掛けたものになっていてほしい。これを通過できるのは、ファイ係数、オッズ比(基準化していれば)、YuleのQとY、Piatetsky-Shapiro, Collective strength(基準化していれば)。
- 1行目と2行目を入れ替え、さらに1列目と2列目を入れ替えたとき、値はそのままでいてほしい。これが破られちゃうようじゃかなり困ったことになると思ったが(ローデータのコードを反転させるだけで値が変わることになる)、サポートやJaccard係数だけでなく、コサインもリフトもこれを破っている(ああ、そうか。反省)。もっともバスケット分析のような場面では、「購入」間の関連性と「非購入」間の関連性は異なっているのが自然だけど。
- not Aかつnot Bのセルを変えても値が変わらないこと。つまり、共起は表すけど共-不起は表さないこと。通過するのは、サポート、Jaccard係数、そしてコサイン(うわあ、そうか。反省)。
以上の性質でもって指標を分類すると、以下の6グループにわけられる。
- オッズ比、YuleのQ, YuleのY。
- コサインとJaccard。
- サポートとLaplace。
- ファイ係数、collective strength, Piatetsuky, Shapiro。
- ジニ係数とラムダ。
- リフト、Added value, Klosgen。
- 相互情報量、Certainty factor, カッパ。
著者いわく、3, 6, 7番目のグループはなんだかよくわからんけど、きっと注目した性質が足りないからでしょう、とのこと。
論文の残りの部分は...
- 無数の変数ペアに以上の指標を適用する前に、サポートで足切りすることが多いけど、そうすると何が起きるか。まず、負の連関が見つけられなくなる(そりゃそうだ)。さらに、サポートの天井を設けてしまうと、いろんな指標が類似してくる。
- 周辺分布がいずれも50%になるよう標準化すると何がおきるか。標準化の手順による。いろんな表を用意し、MostellerのIPFという反復的な手順で標準化すると、オッズ比は維持され、すべての指標の値の順位がオッズ比に一致するようになる。他の手順だとまた異なる。云々。
- データセットから少数のクロス表を抽出し、専門家に関連性を評定させ、それに合った指標を選ぶアルゴリズムの提案。面白いことを考えるなあ。
前半がとても勉強になった。いろいろと 反省すること 多かりし。
よくわからないのだが、情報工学の方面では、新しいアルゴリズムかなにかを提案しないと論文になりにくいのかしらん。最後のトピックは論文化のためのツケタリではないかと思う。前半のレビューだけで十分に貢献しているのに。根拠レスな言いたい放題がまかりとおる領域ももちろん不健全だが、こういうのはこういうので、ちょっと健康的ではないような気が...
読了: Tan, Kumar, & Srivastava (2004) 2x2クロス表の関連性指標を品定め
2013年6月20日 (木)
Masyn, E. M. (2008) Modeling measurement error in event occurrence for single, non-recurring events in discrete-time survival analysis. in Hancock, G.R, & Samuelson, K. M. (eds.) Advances in Latent Variable Mixture Models. 105-145.
イベントの発生時間の測定誤差を考慮した離散時間生存モデルについての論文。マニアックな話だと思って避けていたのだが、実際にイベントのタイミングに関する問題に取り組んでいて、これは結構切実な問題だと気がついた。文字通り患者の死亡をモデリングする生存モデルならばともかく、応用場面ではイベントがある時点で生じたのかどうかはっきりしないことも少なくない。それに、著者はMuthenさんのお弟子さんだから、きっとmplusのコード例を示してくれるだろうと思って。
えーっと、この話の第一のポイントは、イベント・ヒストリーを一次のマルコフ過程として捉える、という点である。
ある人はある時点においてpre-event, event, post-eventの3つの状態のいずれかを持つ、と考える。それぞれを0,1,2と表す。時点 0 においては全員が 0 である。eventはひとりに一回限りしか起きないものとする。
時点 j (=1,...,J)における状態を表すカテゴリカル変数を E_j とする。時点 j-1 から j への E の遷移確率行列 をT_{(j)(j-1)}とする。
まず、j=1の遷移行列は? そもそも E_0 = 0 なので、1行2列で済んでしまう。これを[1 - P_h (1), P_h (1)] とする。P_h(1)というのは、さっきがpre-eventだったときにいまeventが起きる確率、つまりはハザードである。
j=2 の遷移行列は? 2行3列になる。1行目が[1 - P_h (2), P_h (2), 0]。2行目が [0, 0, 1]。
j>2の遷移行列はどうなるか。3行3列になる。1行目が[1 - P_h (j), P_h (j), 0]。2行目と3行目がともに [0, 0, 1]。当たり前の話ではあるが、結局どの遷移行列もパラメータひとつ、すなわちハザードしか持っていない。
このマルコフ連鎖を多項ロジスティック回帰で表現する。一般に多項ロジスティック回帰は
Prob(C=k | x ) = exp (\alpha_k + \beta_k x) / (分母は省略)
共変量 x を直前の状態 E_{j-1} とみなす。最初のレベルを参照レベルとみなすことにして、E_{j-1}を2つのダミー変数で表現し、
Prob(E_j = k | E_{j-1}) = exp( \alpha_{jk} + \beta_{jk1} I(E_{j-1} = 1) + beta_{jk2} I(E_{j-1}=2) ) / (分母省略)
要するに、遷移行列を回帰パラメータ \alpha と \beta に分解していくわけである。ここに2番目のポイントがある。ハザードだけを分解するんじゃなくて、遷移行列のすべての要素 (j>2なら 3*3=9個) をそれぞれ分解するのである。たとえば、0から2への遷移確率は 0 だが、これが
Prob(E_j = 2 | E_{j-1}) = exp( \alpha_{j2} ) / (分母省略)
と分解されるわけである。\alpha_{j2} を十分に 0 から離れた負の値にすれば、0を近似できる。\alpha と \betaはあわせて6個しかないので (本来 9 個だけど、最初のレベルは参照レベルと決めたから、\alpha_{j0}, \beta_{j01}, \beta_{j02}は 0 である)、無事に識別できる。
さて、これが最後のポイントなのだが、ここまでに出てきた E_j は実はカテゴリカル潜在変数でした、と考える。それぞれの E_j は二値指標 U_j を持っている。誤差がなければ、E_j =0 のとき U_j = 0, 1 のとき 1, 2 のとき 2 である。
これも無理矢理にロジスティック回帰で表現してしまう。
Prob (U_j = 1 | E_j = k) = 1 / {1 + exp(\omega_{jk}) }
測定誤差を考えない場合は、\omega_{j0}と\omega_{j2}は十分大きな正の定数(たとえば+20)、\omega_{j1} は十分大きな負の定数とする。測定誤差を考慮する場合は... \omegaを推定するのかと思ったが、さすがにそれは無理らしい。でも、たとえば先行研究から、ROC曲線でいうところの特異度(すなわち、E_jが1でないときにU_jが0となる確率) が0.8だと仮定できるのならば、\omega_{j0} = \omega_{j2} = logit(0.8) = 1.386 とすればよい、とのこと。
というわけで、苦労の末、すべてが潜在クラス変数の多項ロジスティック回帰でもって表現できた(つまり、mplusで推定できる形になった)わけである。測定誤差も考慮できるようになった。やれやれ。
イベント時間に対する共変量 x は、潜在クラス変数 E_1, E_2, ..., E_j に対する説明変数となる。ただし、E_{j-1}=0のときじゃないとE_j に効かないなので、
Prob (E_j = k | E_{j-1}, x) = exp( \alpha_{jk} + \beta_{jk1} I(E_{j-1} = 1) + beta_{jk2} I(E_{j-1}=2) + \gamma_{jk} x I(E_{j-1}=0) ) / (分母省略)
として、さらに \gamma_{j0} = \gamma_{j2} = 1 と固定する。ああ面倒くさい。
そのほか、ベースライン・ハザードを変えて共変量の係数の復元を調べるシミュレーションとか、ある時点の観察指標が複数ある場合の話(ちょっと面白い...)などがあったけど、パス。
末尾にmplusのコードがついているのだが、これが初見ではまったく意味不明な代物で、本文を読んで見直してようやく腑に落ちた。潜在クラスを時点数だけ導入する、信じられないくらいに壮大なモデルである。識別できるんだろうけど、推定にどれだけ時間がかかるやら。。。ともあれ、勉強になりました。
読了: Masyn (2008) イベント発生時間の測定誤差を考慮した離散時間生存モデルを一次マルコフモデルでつくろう (というか、Mplusでつくろう)
2013年6月19日 (水)
Hahsler, M., & Chelluboina, S. (2011). Visualizing Association Rules: Introduction to the R-extension Package arulesViz.
アソシエーション分析用Rパッケージ arules の派生パッケージで、抽出したルールの可視化を担当してくださる arulesViz の説明書。読んだものはなんでも記録しておくことにしたいのでここに書くけど、これ、論文でもなんでもないぞ...
アソシエーション・ルールってどうやったら格好良く見せられるのかなあと思って目を通した。やっぱりgephi でネットワークグラフを描くのが一番かっこいいんだけど、ほかにもいろいろな(ヘンな)見せ方がある。みんな苦労しているんだなあ。
読了: Hahsler & Chelluboina (2011) arulesVizパッケージ
2013年6月18日 (火)
Lenca, P., Myer, P., Vaillant, B., Lallich, S. (2008) On selecting interestingness measures for association rules: User oriented description and multiple criteria decision aid. European Journal of Operational Research, 184(2), 610–626.
アソシエーション分析で、発見したルールの興味深さを評価するための指標がいっぱい提案されているので、比較しましょう。という話が載っている論文。ほんとはLallich, Teytaud, Prudhomme(2007)の同趣旨の論文を読み始めたんだけど、前半で話についていけなくなってあきらめた(後半ではなんかFDRみたいな統計的手法を提案しているのに。残念)。なんだか腹が立つので、もうすこしユーザ向けに書かれたのを探して読んだ次第。よく見たら、著者名がだぶっている。
ええと、背景としては... アソシエーション分析では巨大な出現行列からルールを抽出するが、有名な Aprioriアルゴリズムでは、
- まず閾値以上のsupport(同時出現割合) を持つアイテムセットを抽出し、
- そのアイテムセットをAとBに分け、閾値以上のconfidence (Aの出現割合に対するA&Bの同時出現割合の比) を持つ規則 if A then B を生成する。
このやりかただと規則がたくさん生成されちゃうので、なんらかのかたちでのフィルタリングが必要になる。主観的にやる方法もあるが(Silberschantz & Tuzhilin, 1995, Chap.; Liu, Hsu, Chen, 1997, Conf.; Liu, Hsu, Chen, Ma, 2007, IEEE-IS を参照せよとのこと)、ここではデータに基づきルールの興味深さを評価する指標について考える。
検討する指標は以下の通り。以下、A=1 かつ B=1 の頻度をNab, 割合を Pabと書く。A=1 かつ B=0 の頻度と割合は Nab', Pab' と書く。A=1 の頻度と割合は単に Na, Pa と書く。Aの下でのBの割合 Pab/Pa を Pb/a と略記する。各指標についてのコメントにはLallich, Teytaud, Prudhomme(2007)のものも交じっている。
まず、よく使うやつ:
- support: Pab. 独立な時にPa Pb。
- confidence: Pb/a. 独立な時にPb。
以下、confidenceを変換した指標。
- Lift: (Pb/a) / Pb = Pab / (Pa Pb). confidenceのPbに対する比。A→Bの事例数(Pab)が、AとBが独立である場合に期待される事例数(Pa Pb)に比べて何倍あるか、とも解釈できる。独立な時に1。
- centered confidence: Pb/a - Pb. confidenceとPbとの差。独立な時に0。
- Piatetshky-Shapiro: n Pa (Pb/a - Pb) = n (Pab - Pa Pb). centered confidenceをさらに(n Pa)倍。対称的。独立な時に0。
- Zhang: (Pab - Pa Pb) / Max(Pab Pb', Pb Pab'). こうなると直感的にわかる意味はない。Piatetsky-Shapiroを、下限が-1, 上限が+1となるよう調整した指標。独立な時に0。
- Loevinger: (Pb/a - Pb) / Pb'. centered confidenceの、Pb'に対する比。独立なときに0。
- ピアソンの相関係数: (Pab - Pa Pb) / sqrt( Pa Pa' Pb Pb'). Piatetsky-Shapiroの変換だといえる。対称的。独立なときに0。
- カッパ係数: 2 (Pab - Pa Pb)/(Pa + Pb ^ 2 Pa Pb). よくみると、これもPiatetsky-Shapiroみたいなものだ。独立なときに0。
- implication index: sqrt(n) (Pab' - Pa Pb') / sqrt(Pa Pb'). これはA→Bの反事例に注目していて、AとB'についてのPiatetsky-Shapiroを変換した指標になっている。独立な時に0。A→Bの興味深さの指標 として使う際は-1を掛ける。
- least contradiction: (Pab - Pab') / Pb. これもconfidence系の指標である由。独立な時にはNa(Nb-Nb')/(N Nb)となる由。なんでこんなん提案したのかな...
- Sebag and Schoenauer: Pab / Pab'. AのもとでのBのオッズ。confidenceの単調増加変換になっている。独立な時は Nb/Nb' となる。
- examples and counter-examples rate: 1 - (Pab' / Pab). AのもとでのB'のオッズを1から引いた値。confidenceの単調増加変換になっている。独立な時は(Nb-Nb')/Nb となる。
- information gain: log (Pab / (Pa Pb)). Liftの対数。独立なときは0になる。
- Laplace: (Pb/a + (1/(n Pa)) / (1 + (2/(n Pa)). これもconfidenceの系列で、nを考慮にいれている由。独立な時は...ややこしいので省略。
その他の指標:
- ベイズ・ファクター: (Pab Pb')/(Pab' Pb) = {(Pb/a) / (Pb'/a)}/(Pb / Pb') = (Pa/b) / (Pa/b'). AのもとでのBのオッズの、全体におけるBのオッズに対する比。独立なときに1。
- conviction: (Pa Pb') / Pab'. A→Bの反事例数が、AとBが独立である場合に期待される事例数(Pa Pb')に比べて何分の一か。独立な時に1。
- intensity of implication: Prob[ N(0,1) >= (implication index) ]. 独立な時に0.5。
- Probabilistc discriminant index: Prob[ N(0,1) > (implication index)^{CR/\Beta} ]. ヤヤコシイので省略。
- truncated entropic intensity of implication: ものすごくヤヤコシイので省略。
で、これらの指標を以下の基準で採点する。
- 非対称性。A→Bの興味深さとB→Aの興味深さが同じ指標(sym)より、異なる指標(asym)がのぞましい。
- Nbとともに減少するか(dec), 減少しないか(no-dec)。(ここ、よくわからない。Nab, Nab', Na'b'が一定の時、Na'bが大きいほどA→Bの興味深さは下がるから、Nbが大きいときのほうが興味深さは下がってほしい、というようなことだろうか?)
- 独立性。AとBが独立な時に定数であってほしい(cst)。変化されると困る(var)。
- 反事例 Nab' がゼロのときにどうなるか。できれば最大値ないし無限大になってほしい(cst)。そうでないと困る(var)。
- Pab'がゼロに近いときにどうなるか。普通に考えれば、ゼロから離れるにつれて興味深さは下がりそうだが(linear)、ちょっとゼロから離れていても依然として興味深いからあんまり値が下がってくれては困る(concave)、という見方と、いやさっさと下がってほしい(convex)、という見方がある。
- Nに対する敏感性。Nが大きいときに指標も大きくなってほしいという見方(stat)と、変わらないでほしいという見方(desc)があるだろう。
- 閾値が決めやすいほうがいい。そこで、NaとNbを固定したときの、AとBが独立だという帰無仮説の棄却閾を求めることが簡単か(easy), 難しいか(hard)に注目する。
- 意味がわかりやすいかどうか。a,b,cの三段階。
以上の基準で各指標を採点する。たとえば、ベイズファクターはasym, dec, cst, cst, convex, desc, easy, a. だそうだ。liftは、sym, dex, cst, var, linear, desc, easy, a。
この論文の本題は実はここからで、この採点表を主成分分析かなにかにかけて、指標を空間にマッピングし、データマイニング・ユーザの好みを聴取して選好ベクトルを描きいれ、あなたはこの指標をお使いなさいとレコメンドする... という、いささか斜め上の方向に突っ走っていくのである。それはそれで面白いんだけど、いま関心ないのでパス。
アソシエーション分析で使う指標が気持ち悪くて、もやもやしていたんだけど、その理由が自分なりに整理できたので、得るところ大きかった。
読了:Lenca, et al.(2008) アソシエーション・ルールの興味深さの指標
2013年6月16日 (日)
Goethals, B., Zaki, M. (2004) Advances in frequent itemset mining implementations: Report on FIMI'03. SIGKDD Explorations. 6(1), 109-117.
R の arules パッケージの解説書に、アソシエーション・ルール抽出のアルゴリズムについてはこれを参照せよ、と書いてあった資料。全然読むつもりなかったんだけど、なんとなく探してみたら、想像とは全然異なる気楽な内容だったので...
アソシエーション分析の鍵となる頻出アイテムセット・マイニングについてはいろんな研究者がいろんなアルゴリズムを発表してるので、同じデータセット、同じPCで解かせてみて、どれが最強か決着をつけようじゃないか。というので著者らが勝手に開催した世界選手権の報告であった。超難解なレビュー論文を想像していたので、ちょっと笑ってしまった。いや、研究者の方にとっては真剣な話なんでしょうけど。
18個のプログラムに対して、14個のデータ行列を与え、解を求められるかどうか、そして所要時間を計る。frequent itemsetsの抽出, closed itemsetsの抽出, maximal itemsetsの抽出、という3つの競技部門を用意。難しい記号で書いてあるもんでよくわかんないんだけど、どうやら、順に「俺のsupportは閾値を超えている」「俺のsupportは閾値を超えており俺の上位集合は俺よりもsupportが低い」「俺のsupportは閾値を超えており俺の上位集合は閾値を超えていない」というような意味らしい。
細かいところはよくわかんないんだけど、Grahne&ZhuさんのFPナントカシリーズが優勝だそうです。なんだかわかんないけどおめでとうございます。
... アソシエーション分析のために、主要なアルゴリズムの特徴についてきちんと勉強しておこうかと思ってたんだけど、これを読んだら、そこんところはどうでもいいような気がしてきた(叱られちゃうかもしれないけど)。頑張れ研究者のみなさん、って感じだ。
読了: Goethals & Zaki (2004) 頻出アイテムセット・マイニングの世界最強アルゴリズムを決める選手権2003
2013年6月15日 (土)
Hahsler, M., Grun, B., Hornik, K., Buchta, C. (2005) Introduction to arules - A computational environment for mining association rules and frequent item set.
アソシエーション・ルールとか、そういう機械学習的なやつって、昔から苦手なんだけど、仕事のことなので好き嫌いばかりもいっていられない。というわけで読んだ資料。アソシエーション分析のためのRパッケージ arules の解説。パッケージについていた解説書を読んだのだが、著者らの同題の論文が J. Stat. Software に載っている(そっちのほうが短い)。
えーと、アソシエーション分析ってのは... 巨大な二値データ行列から項目間のif-thenルールを抽出する、というのがお題である。オブザベーションがバスケット、項目が商品アイテム、値が買う/買わないに相当しており、この出現行列から「ビールを買うやつはほにゃららを買う」というようなルールを抽出したいわけだ。基本的に標本特性の話ばかりで、確率分布を推定しようとか、そういう発想はさわやかなまでに欠如している。
arulesパッケージは抽出アルゴリズムとしてaprioriとeclatを搭載。前者は幅優先探索、後者は深さ優先探索とのこと。結果が具体的にどう変わってくるのか知りたかったんだけど、書いてなかった。アルゴリズムの比較についてはGoethals & Zaki (2004) というのを読めとのこと。ご親切にありがとう、読まないけどな。
ほかにも、データ操作や視覚化のための機能をいろいろ積んでいる。知らなかった。アソシエーション分析とは無関係な場面でも、とても便利そうだ。
アソシエーション分析の方面では、ルール if X then Y に含まれるアイテム集合{X, Y}の全事例における同時出現割合をsupport、Xの出現で条件づけたYの出現割合をconfidence、Yの出現割合に対する confidence の比 (すなわち、supprtをXの出現割合とYの出現割合の積で割った値) を lift と呼ぶ。その影響かどうかわからないんだけど、ふたつの二値項目のあいだの因果的関連の強さについて調べている際に (広告接触と購入意向の関連とか)、この lift を用いて分析している例を、何度か見たことがある。
正直いって気持ち悪くて仕方がない。lift は リスク比でもオッズ比でもない。liftはいうなれば、曝露条件下の発症リスクの、全体の発症リスクに対する比だ。リスク比 (非曝露下での発症リスクに対する比) が一定ならば、曝露割合が上がるほど lift は1に近づくはずじゃないですか? 接触率の低い広告のほうが効果があると判断されやすくなりかねない。なんでこんな指標をつかうのかしらん。
読了: Hahsler et al. (2005) arulesパッケージ
2013年6月14日 (金)
Jain, D.C. & Vilcassim, N.J. (1991) Investigating household purchase timing decision: A conditional hazard function approach. Marketing Science, 10(1), 1-23.
世帯の購買記録に生存モデル(比例ハザードモデル)をあてはめた古典的研究としてよく引用されている論文。めんどくさそうで腰が引けていたのだが、これだけ引用されているんだから仕方ない、と覚悟して読んだ。
まず、ベースライン・ハザード関数 $h_0(t)$ をすごく一般的に、次のように定式化する:
$\displaystyle h_0(t) = \exp \left( \gamma_0 + \sum_{k=1}^K \gamma_k \frac{t^\lambda_k - 1}{\lambda_k} \right)$
うんざりして投げ出しそうになったが... イベント間隔時間 $t$ を パラメータ $\lambda_1, \lambda_2, \ldots$でそれぞれBox-Cox変換し、重み $\gamma_1, \gamma_2, \ldots$ をつけて足しあげている。なんでこんなケッタイなことをしているのかというと、過去に用いられてきたいろいろな確率分布を一発で表したいからである。たとえば、$\gamma$ をすべて 0 にすれば、ベースライン・ハザードは定数、確率分布は指数分布となる。$\gamma_1$だけ残して残りを0にし、 $\lambda_1$を十分に小さくすれば、ワイブル分布。この調子で、ゴンペルツ分布、Erlang-2分布もいけるとのこと。しらんがな。
このベースライン・ハザードに、カレンダー時間$\tau$に依存する共変量 $X_1(\tau), X_2(\tau), \ldots$ の効果 $\exp( \sum_j X_j (\tau) \beta_j )$ と、世帯間異質性 $\exp( c \theta )$を掛けてハザード関数にする。$\theta$ は世帯間でのみ動く確率変数。
推定方法は飛ばし読み。異質性の推定に関しては、例によってHeckman-Singer のサポート・ポイントという考え方が出てくる。でたな経済学者め。こうなったら意地でも勉強してやるもんか。きっと潜在クラスみたいなものにちがいない。
データはIRIの世帯購買記録 (マーケティング変数つきのスキャンパネルデータであろう)。カテゴリは粉コーヒーとインスタント・コーヒー。それぞれ、結構買っている166世帯, 427世帯について分析する。共変量は、ディスプレイ、チラシ、メーカーのクーポン、店舗クーポン、値引き、前回購買のボリューム(買い置き有無の代理指標として)、世帯人数、夫の雇用。70日まで推定する。
結果は... 異質性の項をいれるといれないではベースラインハザードの形状が変わる。いずれにしろ非単調。指数もワイブルもゴンペルツも二次もErlang2もうまくフィットせず、ノンパラに推定するのが良い。云々。途中から死ぬほどめんどくさくなって、ぱらぱらめくっただけ。
前に読んだSeetharaman&Chintagunta(2003) に照らして考えると、そもそもスーパーでのカテゴリ購買間隔について日次をメトリックにした生存モデルをつくって良いのかどうかが怪しい、といえるだろう。ある日にカテゴリ購買が起きていないのは、スーパーに行かなかったからかもしれないし、行ったけど買わなかったからかもしれない。ずいぶん意味合いがちがう。
素朴すぎる疑問かもしれないけど... この論文の先行研究概観をみると、EhrenbergのNBDを使った集計レベルモデル(なんと1959年)にはじまり、たいていの研究が購買間隔に一定の確率分布をあてはめようと試みている。でも、マーケティング・ミクス変数の効果を推定するということが主目的ならば、Cox回帰でもって、ベースライン・ハザード自体を推定することなしに共変量の効果を推定したほうがスマートだ。なぜこの分野では最初からそういう話にならなかったのだろうか? Cox回帰自体の歴史はかなり古いはずなのに...
などといいつつ、ほんとに適当にめくって済ませた論文であった。ここ数ヶ月、寝ても覚めても生存モデルについて考えているので、少々飽きてきた、という面もある。
読了: Jain & Vilcassim (1991) 購買タイミングの比例ハザードモデル (クラシカル・バージョン)
2013年6月12日 (水)
Bieman, C. (2006) Chinese Whispers - an Efficient Graph Clustering Algorithm and its Application to Natural Language Processing Problems. Proceedings of the HLT-NAACL-06 Workshop on Textgraphs.
ネットワーク・グラフの可視化・分析ソフトにgephiというのがあって、使いこなしているとは言い難いけど、しばらく前から愛用している。あのポヨンポヨンと動く感じがたまらない。ときどき落ちたり固まったりするところも愛嬌があってよい。例えていえば、ちょっとおっちょこちょいな巨乳の眼鏡っ子という感じだ。(なにを云っているのだ私は)
そのgephiに、ネットワーククラスタリングのためのChinese Whispersという機能が搭載されている。クラスタリングに関連する資料を読んでいて突然に気になったんだけど、あのChinese Whispersってなんだ? 中国人のささやき? 耳元で謝謝とか呟くのか? チャイナドレスのお姉さんが? ずいぶん色っぽいではないか。
...というわけで引用文献をめくってみた。正直、論文の本題にはあまり関心がない。すいません。
基本的には、非階層的なハード・パーティショニングのアルゴリズムである。最初は全ノードが各自のクラスに属する。で、全ノードをランダムな順序で抽出し、「近隣ノードにおける上位クラス」に所属させる。全部回ったらまた繰り返す。という、超簡単なアルゴリズムだが、巨大なネットワークでもすごく速くクラスタリングできるのだそうだ。もっとも、常に収束するとは限らないけど。
肝心の、命名の由来だが... 英語では「伝言ゲーム」のことをChinese Whispersというのだそうです。英和辞典にも載っていた。がっくり。
読了: Bieman (2006) チャイニーズ・ウィスパー・アルゴリズム
Kalinka, A.T., Tomancak, P. (2011) linkcomm: an R package for the genratino, visualization, and analysis of link communities in networks of artitrary size and type. Bioinformatics. 27(14), 2011-2012.
webを眺めていたら、職業:データサイエンティスト、という方が書いているブログがあって、勉強になるなあと思って読んでたのだが(というか、データサイエンティストってほんとにいるんだ、とびっくり。一角獣みたいな伝説的存在かと思っていた)、その方がlinkcommというRパッケージを紹介されていた。なんですかそれは? というわけで、探して読んでみた。開発者によるたった2ページの紹介記事。
えーっと、ネットワークを下位のコミュニティへとクラスタリングしていく手法なんだけど、ノードの類似性じゃなくてリンクの類似性を考える。ノード k から i へのノードと k から j へのノードがあったとして、i の一次近隣ノードと j の一次近隣ノードのjaccard係数をリンク間の類似性とする、というのが基本アイデア(前になにかで読んだことがあるなあと思ったら、やはりAhnというポスドクの人のNatureの論文だ)。重みや向きを持つリンクにも拡張できる。でもって階層クラスタリングを行う。いろんな視覚化手法を積んでて、楽しそう。
読了: Kalinka & Tomancak (2011) linkcommパッケージ
2013年6月 8日 (土)
Beck, N., Katz, J.N., Tucker, R. (1998) Taking time seriously: Time-series-cross-section analysis with a binary dependent variable. American Journal of Political Science. 42(4), 1260-1288.
Singer & Willett の縦断データ解析本を読んでいて、へえー、と感心した箇所があって(離散時間ハザードモデルでのcloglog リンクとlogitリンクのちがいについての説明)、そこで引用されていたのでちょっと読んでみた。えーと、論文の主旨は「BTSCSデータの正しくて簡単な分析方法を教えてやるよ」とのこと。
BTSCSデータ? はあ? と思ったが、binary time-series cross-sectionデータ、つまり「従属変数が二値な時系列クロスセクションデータ」の略で、どうやら政治学の分野ではよく用いる略語らしい。いろんなジャーゴンがあるものだなあと感心。
「時系列クロスセクション」って、世間一般ではパネルデータっていいませんか? と思ったのだが、「パネル」というときには時点が少なく個体数が多い場合を指し(そういえばそういう語感ですね)、いっぽう「時系列クロスセクション」は時点が多く個体数が少ない場合を指す由。要するに、多変量時系列データが数セット縦積みになっていることをいうのであろう。そういえば前に習ったような気もする。往時茫々...
なんでも、BTSCSデータ(舌がもつれそうですね) は国際関係の研究ではよくあるデータ形式なのだそうで、たとえばいくつかの二か国間関係に注目し、国のペアx年をオブザベーション、「軍事衝突がおきた」とか政治の仕組みとかを変数にとったデータをつくって、政治がどうだったら軍事衝突が起きやすい、なんていう分析をするのだそうだ。ほー。
で、多くの研究者が「軍事衝突が起きた」を従属変数、政治についてのの変数群を独立変数にとった単純な回帰モデルをつくってしまっている(ロジスティック回帰とかプロビット回帰とかで)。でもオブザベーション間に自己相関があるから、標準誤差がすごく過小評価されてしまう。危険を感じてハザードモデルを使う人もいるけど、数が少ない。
そこで著者らいわく、勉強しなくていいからこれだけは覚えておけ。ある単位期間にイベントが起きる確率のことをハザードという。ふつうは連続時間上で測ったイベントヒストリーデータを用いてハザードをモデル化する。ところがイベント時間の測定が離散時間上でなされている場合もあって、そういうのをgrouped durationという。で、BTSCSデータ (覚えにくいですね) はまさにgrouped duration データそのものである。
連続時間ハザードモデルとしてもっとも良くつかわれているのはCox比例ハザードモデルで、個体 i, 時点 s , 共変量 \bm{x}_{i,s} におけるハザードは
h (s | \bm{x}_{i,s}) = h_0(s) exp( \bm{x}_{i,s} \beta)
これが離散時間になると、
h (t | \bm{x}_{i,t}) = 1 - exp( -exp(\bm{x}_{i,s} \beta + \kappa_{t-t_0}) )
となる由。
あれれ? \kappaってなに? と思ったので、Appendixの説明を追ってみた。まず時点 t における生存確率は
S(t) = exp( -\int_0^t h(\tau) d\tau )
以下、めんどくさいので添字 i を略記する。時点 t_k - 1 から t_k までのハザードは
h(t_k) = 1 - exp ( -\int_{t_k -1}^{t_k} h(\tau) d\tau)
\bm{x}が期間中に変わらないとして、h(\tau) = h_0(\tau) exp( \bm{x}_{t_k} \beta)を代入し、係数の部分を積分記号の外に出して
h(t_k) = 1 - exp ( -exp( \bm{x}_{t_k} \beta) \int_{t_k -1}^{t_k} h_0(\tau) d\tau)
どうせベースラインハザード関数 h_0(t)は未知なんだから、積分記号以降を \alpha_{t_k} として
h(t_k) = 1 - exp ( -exp( \bm{x}_{t_k} \beta) \alpha_{t_k})
ここまでは思いついたのだが、さらに \kappa_{t_k} = log(\alpha_{t_k}) として
h(t_k) = 1 - exp ( -exp( \bm{x}_{t_k} \beta + \kappa_{t_k}))
で、多重イベントの場合に対応できるように、前のイベントの生起時間を t_0 とし、\kappaの添え字はt_0からの差にしているのであった。
というわけで、t-t_0 の上限の個数だけダミー変数をつくりなさい。で、前のイベントからの時間をこのダミー行列で表現しなさい(前のイベントから3年たっていたら3列目を1にする)。このダミー行列を独立変数にいれなさい(切片項の推定はやめなさい)。さすればこれらの変数の係数が \kappaの推定値となり、正しい分析ができるであろう。との仰せである。
...この論文ではgrouped PHM、つまり離散時間で測定されたイベントヒストリーデータにわざわざ連続時間ハザードモデルをあてはめている作戦をとっているわけだけど、するとハザード関数が 1-exp(-exp(...))となり、cloglogリンクのモデルになってしまう。でも、もし時間が本当に離散的に動いていたら logit リンクでよかったわけだ。ベースライン・ハザード関数をパラメトリックに指定する場合であれば、マジメに clogclog をつかう動機もまだ理解できるが、そうでないなら logit リンクで問題ないのではなかろうか? ...実のところ、この疑問が頭にあって、読んでみた論文であった。というわけで、面白いのはここからである。
著者らいわく、ハザードが50%を越えなければ、どっちを使ったって大差ない。そして軍事衝突はそんなには起きない。だからロジットリンクを使っちゃいなさい(おおっと...)。すなわち
h(t | \bm{x}_{i,t}) = 1 / { 1 + exp( -(\bm{x}_{i,t} \beta + \kappa_{t-t_0}) ) }
さすればお手元のソフトで簡単に分析できちゃうであろう、とのこと。意外に簡単なお返事で拍子抜け。
その他の話題としては...このようにモデルにダミー変数を入れる必要があるか、尤度比検定で決めること(ベースラインハザードが定数だというのならそれはそれでハッピーだから)。入れるんなら全部入れること。ただし、全てのダミー変数をほんとに入れるよりも自然二次スプラインを使うのがお勧め(つくりかたはソフトに載ってるでしょ、とのこと)。ある個体の2回目以降のイベントが一回目よりも起こりやすい(にくい)と仮定する場合にどうするか(「いま何番目の生起待ちか」という変数をいれちゃうのが簡単)。左打ち切りがあったらどうするか(たいした問題ではない由)。時間変動する独立変数があったらダミー変数と相関してしまうけどどうするか(困るしかない)。欠損があったらどうするか(困れ)。云々。
最後に分析例。単純なロジットモデルと、持続時間のダミー変数をいれたモデルでは、係数の推定値がずいぶんちがう。ああ、そりゃそうだろうな、前の戦争がどのくらい前だったかで戦争の起こりやすさは変わりそうだし、政治のしくみも変わりそうだ。その他、いろいろ分析しているけどパス。
実のところ、この論文の主張は単に「イベント持続時間を考慮せよ」であって、誤差の自己相関を積極的にモデル化するという話ではない。著者らいわく、そういうアドバイスは容易だが実現は難しい。我々は実現を重んじているのだ、とのこと。
というわけで、とても親切な啓蒙論文であった。ありがたいです。それから、政治学者はそんなに数学に強くないということがわかった。ありがたいです。
読了:Beck, Katz, & Tucker (1998) 政治学者のためのとっても簡単なイベントヒストリー分析
2013年5月 4日 (土)
Seetharaman, P.B., (2004) The additive risk model for purchase timing. Marketing Science, 23(2), 234-242.
購買間隔のモデリングにおける、Cox比例ハザードモデル(PHM)、加法リスクモデル(ARM), 加速故障時間モデル(AFTM)のパフォーマンスを比較します、という論文。
著者いわく... 世帯の購買間隔のモデリングに際してもっともよく使われているのはPHMだ。ベースライン・ハザード関数としてよく用いられるのは、Erlang-2、ワイブル分布、対数ロジスティック分布、ゴンペルツ分布など。quadratic Box-Coxや Expo-powerが使われることもある (それぞれ Jain & Vilcassim 1991 Marketing Sci., Saha & Hilton 1997 Economic Letters をみよとのこと)。また離散時間PHMが用いられることもある (Helsen & Schmittlein 1993 Marketing Sci. をみよとのこと)。適用例は山ほどある。素晴らしい。しかあし、PHMにつきものの「マーケティング変数の影響が乗法的だ」という仮定は検証されていない。いっぽう、ARMを使った論文は、領域問わずに探しても90年以降たったの9本しかみあたらない。ひどいじゃないか。とのこと。
ARMとAFTMってのはどういうのかというと... 前回購買からの経過時間を t , 共変量(価格とか) の行ベクトルを X_t として、世帯 i のハザード関数を
h_i (t, X_t) = h_i (t) + exp(X_t \beta)
とするのが ARM である(PHMではかけ算にするところを足し算にする)。以下、これを離散時間にして(grouped ARM)、ベースライン・ハザードは対数ロジスティック分布にして、s個のサポートで個人差を表現するモデルを使う。
AFTMは、ハザードをベースライン・ハザードと共変量の効果にわけて考えず、ハザードそのものを共変量の関数にする。えーっと、対数ロジスティック関数はスケールをa, 形状をbとして
f(x) = [ (b/a)(x/a)^{b-1} ]/[ 1 + (x/a)^b]^2
だが (いまwikipediaで調べました)、本文中のハザード関数は、このxをt、bを\alpha, 1/aをX_tの線形関数 \gamma_0 + X_t \gamma_1 としたものになっているようだ。
データはIRIのスキャナパネルデータ。洗濯洗剤、ペーパータオル、トイレットペーパーの購買にあてはめる。共変量は価格、ディスプレイ、チラシ。なんだか既視感があると思ったが、これきっとSeetharaman & Chintagunta (2003)と同じデータだ。あの論文を読んだときも悩んだのだが、購買は日次でわかっているんだけど、モデル推定時は週次データにして使っているんだと思う。
推定の結果は... モデルの適合度やホールドアウトへの予測は、ARM, PHM, AFTMの順に良い。推定されたベースライン・ハザード関数の形状はだいたい同じで、だいたい10日目くらいまで急上昇、あとはなだらかに低下。共変量の係数をみると、PHMだけなんだかヘン(価格の係数が正になってしまうサポートがある)。サポートをつぶした価格弾力性の時系列曲線を求めると、ARMとAFTMでは解釈可能な曲線が得られたが、PHMではずっと 0 近辺になってしまった。ベースライン・ハザード関数を対数ロジスティックから他の形状に切り替えると(指数、Erlang-2、ワイブル、expo-powerを試している)、ARMではどの形状でも結果は大差がないが、PHMでは大きく変わってしまった。というわけで、ARMは優れています。とのこと。
前回同様、とてもわかりやすい論文で、勉強になった。Marketing Scienceって、高級スーツを着たエリート様が偉そうな理屈で素人をたぶらかすというイメージがあるんだけど、こういうシンプルかつクリアな内容の論文も載るんですね。(←素朴すぎる感想だ)
わかりやすかったおかげで、いろいろと疑問がわいた。第一に、ある統計モデルをデータにあてはめることの善し悪しの評価には、(1)データのあてはまりのよさや予測の良さ、(2)パラメータが安定していて筋が通っているか、そして(3)そのモデルそのものが背景知識と整合しているか、の3つの側面があると思う。この論文では、(1)の面ではARM, PHM, AFTMの順に良いということがわかり、(2)の面ではPHMがちょっとまずいということがわかった。でも、(3)の側面はいったいどうなっちゃったんだろう。「マーケティング変数が購買確率に加法的に効くかそれとも乗法的に効くか」という根本的な疑問に対しては、もっと心理的な観点からの議論、たとえば「購買時意思決定のほにゃららモデルに照らして考えれば、マーケティング変数はやっぱし加法的(or 乗法的)に効くと考えたほうが筋が通ってんじゃないですかねえ」というような議論があっても良さそなものだと思うのだけれど...
第二に、「PHMがモデルのspecificationに対してセンシティブである」というのは、果たしてPHMの悪口になっているのかしらん。それはもちろん実務的にはですね、細かいオプションを多少変えても結果がロバストなモデルのほうが、非常に助かります。そのぶん早くうちに帰れるというものだ。でもそれは内輪話であって、いま池から神様が現れて、君が落としたモデルは正しく指定すれば正しい結果が得られるが間違って指定すると間違った結果が得られるモデルかい? それとも指定に関わらずずーっとロバストに間違っちゃうモデルかい? と聞かれたら、そのときはやっぱり、前者が欲しいと答えるべきだと思うわけである。ARMとPHMのどっちがいいかというのは、結局はシミュレーション研究でないとカタがつかない問題なのではないかという気がする。
読了:Seetharaman(2004) 購買データを分析するみなさん、比例ハザードモデルばっかり使ってないで加法リスクモデルをお使いなさい
2013年5月 3日 (金)
Manchanda, P., Dube, J.P., Goh, K.Y., & Chitagunta, P.K. (2006) The effect of banner advertising on internet purchasing. Jounral of Marketing Research, 43(1), 98-108.
話題自体には関心がないのだが、Grover & Vriens (eds) の生存モデルの章で、時間変動共変量をいれた比例ハザードモデルのHB推定の例として挙げられていたので目を通した。第一著者は前に読んだ、複数カテゴリ購買についての(なんだか腑に落ちなかった)論文の第一著者で、少々腰が引けたが、背に腹は代えられない。いまは何でもいいから情報がほしいのだ。
バナー広告がネット通販に及ぼす影響を、アクセスログと購買データで調べる。どうでもいいけど、結論を先にいえば、大事なのは露出であってクリックはどうでもよかった、効果には個人差があるのでちゃんとターゲティングしたほうがいい、トライアル購買に対する効果とリピート購買に対する効果は異なる、云々。
あるネット通販専業会社のデータを使う。販売しているカテゴリはヘルスケア・化粧品・非処方薬。データはクッキー単位のアクセスログで、自社サイトへのアクセスと購買、自社サイトおよび他のサイトにおけるバナー広告の表示とクリックがわかる(出稿先の8割をカバーしている由)。これを週ごとの離散データにして分析する(週当たり購買は多くて1回となるよう前処理する)。書いてないけど、観察打ち切りのことは考えなくていいらしい。
消費者 $i$ の $j$ 回目の購買について考える。前回の購買からの経過時間を $t_{ij}$ とする。時点 $t$ におけるハザード関数を $h(t)$ として、生存関数は
$S(t_{ij}) = \exp( - \int_0^{t_ij} h(u) du )$
これを離散化する。前回の購買からの観察期間を十分に長く取り、それを $J$ 個の区間に分割する。で、まず共変量のことは脇において、各区間におけるベースライン・ハザードの積分が定数だと考える(ピースワイズ指数ハザードモデル)。つまり、
$\int_{(t-1)_{ij}}^{t_{ij}} h(u) du = \exp(\lambda_j) $
$(t-1)_{ij}$ というのがわかりにくいけど、これは「その区間の左端」という意味らしい。
よし、次は共変量だ。比例ハザードモデルで考える。消費者 $i$ の $j$ 回目の購買までの間隔における $p$ 個目の共変量を $x_{pij}$ として、
$\int_{(t-1)_{ij}}^{t_{ij}} h(u) du = \exp[ \lambda_j + \sum_{p=1} (x_{pij} \beta_{pi}) ]$
ベースラインを表す $\lambda_j$ は時点ごとに異なるが異質性はなく、共変量の係数 $\beta_{pi}$ は異質性があるが時間独立である。
これを階層ベイズモデルに放り込む。
$\Psi_j = log(\lambda_j)$ が $MVN(\Psi_0, V_\Psi)$ に従うと仮定する (なぜこういう風に仮定するのだろう?)。$\beta_{pi}$のベクトルが$\beta_i = \beta_0 + \nu_i$と分解され、$\nu_i$ は$N(0, V_\beta)$に従うと仮定する。$\beta_0$と$V_\beta$の事前分布はそれぞれMVN, 逆ウィシャート分布とする。$\Psi_0, V_\Psi$ もハイパーパラメータだと思うんだけど、事前分布は書いてない。
以上のモデルを推定する。共変量として、バナー広告を見た回数の対数(LVIEWNUM)、その種類(ADNUM)、サイト数(SITENUM)、ユニークなページ数(PAGENUM)を使用。推定の結果、\Psi_j の分布の時系列変動は複雑で、ああピースワイズにしといてよかった、とのこと。共変量の係数はADNUMのみ負で、これはメッセージがバラバラだからじゃないか、とのこと。云々云々。
推定結果についていろいろ分析していて、そこがこの論文の肝だと思うけど、いまんところ関心がないし、ほんとに頭が痛くなってきたのでスキップ。
拝察するに、購買間隔に対する週単位の比例ハザードモデル、ベースラインハザードはノンパラメトリック、打ち切りなし、共変量はすべて時間依存、共変量の係数に消費者間異質性を想定。ということだと思うのだが... 正しいだろうか。
想像するに、この通販業者にだってきっとロイヤル顧客とそうでない顧客がいて、共変量ではそれを説明できないくらいのばらつきがあるだろう(共変量は要するにすべてWebアクセスにすぎない)。だから、モデルのなかに「買いやすさ」というか、消費者間異質性があって時間独立な切片(frailty)を入れといたほうが気が利いているのではないか、と心配してしまったのだが... きっとなにか読み落としているのだろう。
読了:Manchanda, Dube, Goh, & Chitagunta (2006) ネット通販におけるバナー広告の効果を生存モデルで推定
Muthen, B. & Masyn, K. (2005) Discrete-time survival mixture analysis. Journal of Educatonal and Behavioral Statistics, 30(1), 27-58.
離散時間生存モデルについての解説論文。とはいえ、なにしろ著者が著者だから、一般化された潜在変数モデル(mplusモデル)のなかで捉えて混合分布を使いましょうという話になる。長めの論文だけど、雑誌名に勇気づけられて読んだ。私の乏しい経験からいって、教育系の学術誌に載ったテクニカルな論文は、統計初心者むけに易しく説明してくれることが多い。(ついでにいえば、一番易しく書かれているのは臨床心理系だと思う。拝察するに、かの業界には「ふざけんな、もし数学が得意だったら医学部に行ってたよチクショウ」という人が多いからではないかしらん)
離散時間生存モデルの長所として、著者らは以下の3点を挙げている:
- 時間依存共変量を入れやすい。
- 比例ハザード性の仮定がいらない。
- "easily allow for unstructured as well as structured estimation of the hazard function at each discrete point." 読み進めてみると、unstructured/structuredというのは時点ごとのハザードになんらかの制約がかかっているかどうかという意味らしい。
まず生存モデルについて。離散確率変数であるところの時間を T、時点 j におけるハザードを h_j とする。生存確率は S_j = \prod_{k=1}^j (1-h_k) 。ある人について考えると、
- 打ち切りに遭遇せず、イベントが時点 j において起きた場合、その尤度は P(T=j) = h_j S_{j-1}。
- 時点 j でドロップアウトした場合、その尤度は P(T>j-1) = S_{j-1}。
- 観察期間終了による打ち切りが起きた場合、最終観察時点の次の時点を j と呼べば、尤度は P(T>j-1) = S_{j-1}。
したがって、観察インジケータを \delta として、尤度は
l = h_j^\delta \prod_{k=1}^{j-1} (1-h_k)
標本全体の尤度は、全個人についての上の尤度の総積である。
このハザードの推定について考えると、時間が離散的なので、各時点のハザードの標本推定値 (周辺ハザード) は単に、生きていた人における死んだ人の割合だ。簡単でよろしい。ハザードと共変量との関係を調べる際には、たとえばロジスティック・ハザード関数を使う。個人 i, 時点 j のハザードを h_{ij}、時間依存共変量ベクトルを z_{ij}、時間独立共変量ベクトルを x_i として、
h_{ij} = 1 / (1 + exp(-logit_{ij}))
logit_{ij} = \beta_j + \kappa'_{zj} z{ij} + \kappa'_{xj} x_i
このふたつの \kappaから添字 j を外して係数を時間独立にしたやつを、比例ハザードオッズモデルという由。ふうん。
次に、mplusモデルのご紹介。共変量 x_i を持つ個人 i が属する潜在クラス c_i が k である確率を多項ロジスティックモデルで表して
P(c_i =K | x_i) \prop exp(\alpha_{c_k} + \gamma'_{c_k} x_i)
mplusでは最後のクラス K を基準クラスにするので、\alpha_{c_K} = 0, \gamma_{c_k} = 0 である。
局所独立なクラス指標として二値変数ベクトル u_i を考え、その背後にある連続的潜在変数ベクトルを u^*_i 、閾値ベクトルを \tau とする。例によって、測定方程式は、切片を抜いて
u^*_i = \Lambda_k \eta_k + \Kappa_k x_i
構造方程式は、潜在変数間のパスを無視して
\eta_k =\alpha_k + \Gamma_k x_i
ああ、めんどくさい、詳細略。
この枠組みに離散時間生存モデルをどうやって取り込むか。ひとことでいうと、時点の数だけ変数をつくり、多変量データにしてしまう。
時点 j においてイベントが起きたかどうかを二値変数 u_j で表す。ただし、もうイベントが起きちゃってるか、すでにドロップアウトが起きている場合は欠損にする(打ち切りが必ず欠損で表現されるという話ではない。最後の観察時点までイベントが起きなかったら、u_j はすべて 0 になる)。打ち切りが無情報である限り、このデータの欠損はMARである (ああ、なるほどね...)。したがって、ある人について考えると、
- 打ち切りに遭遇せず、イベントが時点 j において起きた場合、その尤度は P(T=j) = P(u_j=1) \prod_{k=1}^{j-1} P(u_k =0)。
- 時点 j でドロップアウトした場合、その尤度は P(T>j-1) = \prod_{k=1}^{j-1} P(u_k =0)。
したがって、観察インジケータを \delta として、尤度は
l = P(u_j=1)^delta \prod_{k=1}^{j-1} P(u_k =0)
最初に定式化したモデルと同じである。だから、h_j の最尤推定値は P(u_j=1) の最尤推定値と等しい。面倒なので省略するけど、さっき考えた h_{ij}と共変量のあいだのロジスティック・ハザードモデルも、mplusモデルでうまく表現できる。
共変量がないとき、ハザードになんらかの制約をかけないかぎり、このモデルの自由度は0である。したがって潜在クラスを導入するには、ハザードに制約をかけるか、共変量を導入する必要がある。たとえば、観察期間終了による打ち切りの一部に「ハザードがどの時点でも0」であるような人がいると考える場合 (生存モデルではこういうのを長期生存者というそうだ)、それは「全時点で閾値が無限大、共変量の係数\kappaも潜在変数の係数\lambdaも0」という潜在クラスとして表現できるが、この潜在クラスを組み込んだモデルは共変量なしには識別できない(観察期間終了による打ち切りのうち誰が長期生存者なのかわからない、ということかしらん?)。
事例は2つ。ひとつめは、刑務所から出てきてから再犯するまでのモデルで、共変量は出所後の財政的支援の有無(時間独立。実はこれ、制御変数である。すごい実験だなあ...)。まず比例ハザードオッズ性を確認する。仮に共変量の係数を時間依存だと考えると、u のひとつひとつに x から直接に矢印が刺さるモデルになる。いっぽう比例ハザードオッズ性を想定し、共変量の係数が時間独立だと考えれば、uのすべてにまず \eta から矢印が刺さり、xからは \etaに矢印が刺さるモデルになる(おおおお...)。後者のモデルの適合が良かったので、さらにハザードを個人内で一定にしたモデルと比較する。ええと、すべてのuの切片を等しく、かつ係数も等しくするんでしょうね。このモデルも適合が良い。これを採用した由。
ふたつめは、入学してから退学するまでのモデル。共変量は攻撃的行動なのだけど、測定誤差を含んでいるので、そっちはそっちで潜在クラス成長モデルを組み同時推定する。潜在クラスも潜在変数も2つある。すいません、精力不足で付き合えません。
うーむ。。。再犯の事例を読んでいて混乱してしまったが、発想をガラッと切り替えないといけないと気がついた。Muthenさんたちの枠組みで見た離散時間生存モデルは、パス図で書くとなんだか平凡なCFAやLCAのようにみえるが、要するにハザードの潜在成長モデルなのだ。潜在変数\etaは、因子というより成長曲線のパラメータだ(実際、推定結果の表の見出しにはツルッと"growth factor"と書いてある)。だから、潜在成長モデルについて考えるときに必要な、あの発想の転換を思い出さないといけない。そのことに気がついただけでも、目を通した価値があった。ということにしておこう。
読了:Muthen & Masyn (2005) 離散時間生存モデルへの招待
2013年4月28日 (日)
Asparouhov, T., Masyn, K., Muthen, B. (2006) Continuous time survival in latent variable models. Proceedings of the Joint Statistical Meeting 2006, ASA Biometrics section, 180-187.
連続時間生存モデルを潜在変数モデリングの枠組み(というかMplusの枠組み)へと一般化します、という内容。著者らはMuthen導師とその弟子たち。仕事の都合で、メモをとりながら必死に読んだ。
潜在変数モデリングにCox比例ハザードモデル(PHM)を組み込んだ先例としてはLarsen(2004, 2005, ともにBiometrics)というのがあり、本論文はその拡張である由。へー。
まずPHMの説明。いわく、PHMには2種類ある。
- 「完全にノンパラなPHM」。え、PHMはセミパラメトリックでしょう? と思ってしまうが、著者らがいいたいのはそういうことではなくて、ベースライン・ハザード関数を出成りで決める(経過時点ごとに推定する)ことを指している。これをCox回帰という。推定の方法には、Breslow尤度アプローチ(プロファイル尤度アプローチ)というのと、Coxのアプローチ(部分尤度アプローチ)があるが、この2つは結局同じことである。なにがなんだかわからんが、そうですか。
- 「パラメトリックなPHM」。著者の言い方では、ベースライン・ハザード関数として指定した区間を持つ階段関数を用いる場合がこれにあたる。階段関数のパラメータ(段数だけある)の推定方法には2種類ある。ひとつは普通のパラメータとして扱う方法で、SEが出るし、形状に制約が掛けられるし、有限混合モデルのときに不変性制約を掛けられる。でも段数が多いと大変。もうひとつは局外パラメータとして扱うことで、計算が楽である由。どう計算すんのかよくわかんないけど、まあいいや。
後者のアイデアは強力で、たとえばワイブル分布を近似することもできる。ワイブル分布は、パラメータを$(\alpha, s)$として
$\delta(t) = \alpha s (\alpha t)^{s-1}$
である。これを近似するためには、まず時間をみじん切りにする。生存時間の上限を$M$、みじん切りにしてできた区間数を$Q$とする (50か100もあればよろしい由)。幅は $h=M/Q$。$i$ 番目の区間の真ん中の時間は $t'= h ( i- 0.5 )$。これを上の式の $t$ に代入した値を、その区間の高さ $h_i$ にすればよい。すなわち
$h_i = \alpha s ( \alpha (M/Q) (i-0.5) )^{s-1} $
という制約をかければいいわけだ。
Cox回帰だろうがパラメトリックPHMだろうが、尤度関数は変わらない。時間を$T$, 生存関数を$S(T)$, ベースラインハザード関数を $\lambda(T)$, 共変量とその係数を $\beta X$, 打ち切りインジケータを $\delta$ として、尤度関数は
$L (T) = (\lambda(T) exp(\beta X))^{1-\delta} S(T)$
こうやってきれいに書いちゃうと簡単にみえますけどね。
ここまでは、まあ前説である。いよいよ本題の、生存時間モデルを潜在変数モデルの枠組みに統合するという話。
まず記号の準備。いきなり大仕掛けになって... クラスタ $j$ の 個体 $i$ の、$r$個目のイベント時間変数の時点 $t$ におけるハザードを $h_{rij}(t)$, $p$個目の従属変数の値を $y_{pij}$、彼が属している潜在クラス$(1,...,L)$を $C_{ij}$とする。$y_{pij}$ が順序変数だった場合も考慮し、その背後に潜在連続変数 $y^*_{pij}$ を想定する($y^*_{pij}$について正規分布を仮定すればプロビット回帰である)。$y_{pij}$が連続変数だったらそのまま $y^*_{pij}=y_{pij}$ とする。これをベクトル表記して $y^*_{ij}$ とする。共変量のベクトルを $x_{ij}$ とする。
まずふつうの従属変数について。潜在変数のベクトルを $\eta_{ij}$ として、測定方程式は
$[y^*_{ij} | C_{ij} = c] =\nu_{cj} + \Lambda_{ij} \eta_{ij} + \epsilon_{ij}$
構造方程式は
$[\eta_{ij} = | C_{ij} = c] = \mu_{cj} + B_{cj} \eta_{ij} + \gamma_{cj} x_{ij} + \zeta_{ij}$
でもって、
$C(C_{ij} = c) ∝ exp(\alpha_{cj} + \beta_{cj} x_{ij})$
いつものmplusモデルと比べると、測定方程式から x_{ij} が抜けているなあ。
お待ちかねの生存時間モデルは、
$[h_{rij} (t) | C_{ij} = c] = \lambda_{rc}(t) Exp( \iota_{rcj} + \gamma_{rcj} x_{ij} + \kappa_{rcf} \eta_{ij})$
この式を見た瞬間に、この論文読むのやめようかと思いましたが、よく見るとそんなに難しいことはいっていない。要するにPHMだ。
以下、モデル識別のための制約の話と(例, 実際にはクラスごとの\iota_{rcj}は推定できない)、マルチレベルへの拡張の話が続くが、省略。
この枠組みで既存のいろんな生存モデルが説明できます、というわけで、3つの例を挙げている。
- ひとつめは frailty モデル。つい先日はじめて知ったのだが、ふつうのPHMのハザード関数
$h(t) = h_0(t) exp(\beta' x)$
に、共変量の項に個体間異質性を表す切片項を取り込んで($\beta$は変えない)、個体 i について
$h_i (t) = h_0(t) exp(\beta' x_i + u_i)$
としたのをfrailtyモデルというらしい。へーへーへー。知らなかったー。専門家でもなんでもないので、こういうときは気楽である。frailty ってなんて訳せばいいのかわからない。
この論文で挙げている frailty モデルは、異なるイベント時間変数 $T_1$ と $T_2$ が相関しているという例(夫の生存時間と妻の生存時間とか)。Clayton(1988)という人は、個体 $i$ におけるそれぞれのハザードを $h_{1i}(t), h_{2i}(t)$として
$h_{1i}(t) = \xi_i \lambda_1 (t)$
$h_{2i}(t) = \xi_i \lambda_2 (t)$
とモデル化したが($\xi_i$ は平均1のガンマ分布)、Mplus的観点からは、共変量がなくて切片がなくて潜在変数があってその係数が 1 、というPHM
$h_{1i}(t) = exp(\eta_i) \lambda_1 (t)$
$h_{2i}(t) = exp(\eta_i) \lambda_2 (t)$
で捉えることになる。Claytonとは分布の仮定が異なるが($\eta_i$は正規分布)、ま、結局は似たようなものだ。なお、このモデルについて人工データでシミュレーションすると、パラメトリックPHMアプローチのほうが若干優れていた、でもノンパラと比較することが大事だ、云々。 - ふたつめは 2レベルのfrailtyモデル。面倒くさいので飛ばし読み。
- みっつめは時間変動共変量。さあ、ややこしい話になってまいりました...
話を簡単にするためイベント時間変数を1つに絞る。共変量 $x_{ij}$ と 潜在変数 $\eta_{ij}$を時間依存にして、
$[h_{ij} (t) | C_{ij} = c] = \lambda_{c}(t) Exp( \iota_{cj} + \gamma_{cj} x_{ijt} + \kappa_{cf} \eta_{ijt})$
原文では $\iota, \gamma, \kappa$に添え字 $r$ が残っているけど、誤植だと思う。
で、共変量と潜在変数の値が、時点 $d_1, \ldots, d_K$ でがらっと変わると仮定する。深呼吸して、- まずは$0$から$d_1$までしか観察しないイベント時間変数 $T_1$ について考える。それは, もし本来のイベント時間 $T$ が $d_1$を超えていたら $d_1$で打ち切られ (打ち切りインジケータは $1$)、そうでなかったら $T$ となる(打ち切りインジケータは本来のインジケータ) ようなイベント時間変数である。
- $d_1$から$d_2$までしか観察しないイベント時間変数 $T_2$ について考える。それは、もし本来のイベント時間 $T$ が $d_2$を超えていたら $d_2$ で打ち切られ (打ち切りインジケータは$1$)、$d_1$を下回っていたら欠損となり(打ち切りインジケータも欠損)、どちらでもなかったら $T$となる(打ち切りインジケータは本来のインジケータ)ようなイベント時間変数である。
- ...以下同文。
要するに, つぎの3つの条件を考えればいいわけだ。
- $d_k \lt T$ のとき, $T_k = d_k - d_{k-1}, \delta_k = 1$
- $d_k \lt d_{k-1}$ のとき、$T_k = missing, \delta_k = missing$
- どちらでもないとき、$T_k = T - d_{k-1}, \delta_k = \delta$
先生、もうお腹いっぱいなんですが... 残る話題は3つ。
- 混合モデルにおけるLarsenのアプローチとMplusのアプローチのちがいについて。著者らいわく、たとえばクラスによって異なるハザード関数を推定するとき、Larsenはクラス間でベースライン・ハザード関数の比例性を仮定する ($\lambda_2(t) = \alpha \lambda_1(t)$ というように)。いっぽうMplus的には、クラス間のちがいにそういう制約を掛ける必要がない。さらに、仮に比例性が成り立っていたとしても、Mplus的アプローチのほうが精度が良い(へええ?)。なお、混合モデルの場合、潜在クラスごとに比例ハザード性があればよいのであって、全体で比例ハザード性が成り立っている必要はない(なるほど)。
- 離散時間生存モデルとのちがいについて。連続的なイベント時間変数 $T$ があるとき、連続時間生存モデルを使おうが、細かく区切って離散時間モデルを使おうが、細かく区切ってなおも連続時間生存モデルを使おうが、区切りが十分細かければ、結果はたいして変わらない由(離散時間モデルは推定が大変になるけど)。
- 推定手法間の比較。SASのPHREGプロシジャは、Breslowの部分尤度アプローチ、Efron尤度アプローチ、正確尤度アプローチ、離散尤度アプローチ、を搭載している。いっぽうMplusはBreslowのプロファイル尤度アプローチと離散のふたつを搭載。シミュレーションしてみると、連続時間の場合はどれもたいしてかわらない。離散時間の場合はSASのEfronと正確法がちょっと有利。Mplusが積んでいる方法だけで比べると(だって奴らには潜在変数が扱えないもんね、とのこと)、データがほんとにカテゴリカルで、かつカテゴリ数が20以下だったら、離散時間としてモデリングした方がよい。サンプルサイズが大きいときには特にそう。いっぽう他の場合には、Breslowアプローチのほうが良い。
いやー、疲れたけど、ほんとに助かった。Mplusを使っていてわからなかったことがいっぱいあったのだが (例, なぜ「パラメトリックPHM」なのにベースライン・ハザードがなだらかにならないのか)、この文章のおかげでようやく理解できた。
それにしても、Muthen一家の論文は、私のような素人にとってもほんとにわかりやすい。お歳暮でも贈りたいところだ。
読了: Asparouhov, Masyn, & Muthen (2006) さあSEMで生存時間をモデリングしようじゃないか
2013年4月25日 (木)
あるときある消費者が買い物に行きましたとか、あるカテゴリの商品を買いましたとか、そういう現象を時間軸上で統計的にモデル化しようとするとき、ひとつのアプローチはそれを交通事故のような現象だと捉えることだけれど、買い物は交通事故と違ってその人の前日までの買い物に影響されるので、その履歴を考慮しないのはもったいない。とくに最近ではID-POSやらなんやらで、個人ベースのデータがあふれているので、もう少し工夫しようと欲が出るのが人情である。
そういうときに用いられるのが、生存時間分析で使われる比例ハザードモデルである。いわば購買を死に見立てた生存モデルだ。マーケティング・サイエンスというと派手派手しいけど、このように道具は医学統計から借りてきたものだったりするので、あまりびびってもいけないと思う。
Seetharaman, P.B., & Chintagunta, P.K. (2003) The propotional hazard model for purchase timing: A comparison of alternative specifications. Journal of Business & Economic Statistics. 21(3), 368-382.
購買タイミングに対する比例ハザードモデル(PHM)を比較検討。仕事の都合で読んだ。
実データを使って以下の5点について検証する。
- 時間が連続的な普通のPHMと、時間を離散的にしたPHMのどっちがいいか。
- パラメトリックPHMでベースライン・ハザードとして用いる関数はどれがいいか。指数とかワイブルとか対数ロジスティックとか。
- 普通のPHMと競合リスクモデルのどっちがいいか。
- パラメトリックPHMとノンパラメトリックPHM(ベースライン・ハザードを出成りで決める奴)のどっちがいいか。
- ふつうのPHMと対象者間異質性つきPHMのどっちがいいか。
というわけで、以下のモデルを用意する。時点を t , 共変量を X_t とする。
- ふつうのPHM。ハザード関数(つまり瞬間購買確率)は
h(t, X_t) = h(t) * e^{X_t \beta}
ベースライン・ハザード関数 h(t) としてはワイブル分布が用いられることが一番多いのだそうだ。ふうん。
以降の話のためにちょっと丁寧に追っていくと、時点 t に購買が生じる確率密度関数を f(t, X_t), その累積密度関数を F(t, X_t) として、生存関数は S(t, X_t) = 1- F(t, X_t)。ハザード関数との間には h(t, X_t) = f(t, X_t) / S(t, X_t) という関係がある (生きている人でないと死ねないので)。これを解くと、
S(t, X_t) = e^{-\int_0^t h(u) * e^{X_t \beta} du}
となる。うんざりするような式だけど、要するに生存関数はexp(-累積ハザード関数)です, 累積ハザード関数はハザード関数の積分です、ということであろう。 - 離散時間PHM。grouped PHMともいう由。時間 t を離散的に扱う("measured in the time interval of shopping trips (usually weeks)"とのこと)。生存関数は
S(t, X_t) = e^{-\sum_{u=1}^t e^{X_u \beta} \int^u_{u-1} h(w) dw}
連続的PHMの生存関数の \int_0^t ... du が \sum_{u=1}^t ... に書き換えられ、e^{X_t \beta} が e^{X_u \beta} に書き換えられ、瞬間のハザードであった h(u) が期間のハザード \int^u_{u-1} h(w) dw に書き換えられているわけだ。ここからハザード関数を逆算すると
Pr (t, X_t) = 1 - e^{ -e^{X_t \beta} \int^t_{t-1} h(u) du }
となる由。mplus でも離散時間生存モデルを推定できるけど(成長曲線モデルみたいにアウトカムを時点別に変数にする)、それと同じことなのかどうか、よくわからない。 - 上記の2つのモデルの、ベースライン・ハザード関数を変えた奴を用意する。ワイブル分布のほかに、指数分布(ハザード関数は定数。つまりはメモリレスなモデルだ)、Erlang-2(ハザード関数は単調増加)、対数ロジスティック、expo-powerを試す。
- 競合リスクモデル。離散時間PHMに基づき、ある製品を前の期に買っていた場合のハザードと買っていなかった場合のハザードを別々に推定する(Pr (t, X_t) の式のなかの、共変量の係数 \beta とベースライン・ハザード関数 h() の両方を別々に推定する)。他の問題での使用例はあるが、購買タイミングのデータで推定するのはこの論文が初めてである由。
- ノンパラメトリックPHM。ハザード関数は
Pr (t, X_t) = 1 - e^{ -e^{X_t \beta + \alpha_t}}
となる。時点の効果 \alpha_t を時点の数だけ推定するわけだ。 - 上記のモデルのすべてに世帯間異質性を組み込む。モデルのパラメータ(せっかくなのですべてのパラメータ)が、世帯間で多変量離散分布に従うと仮定する。どうやらその潜在クラスのことをサポートというらしい (知らなんだ...)。連続時間PHMと離散時間PHMでは\betaとh()をサポートごとに推定。競合リスクモデルでは \betaとh()をサポートごとにふたつづつ推定。ノンパラPHMでは\betaと\alpha_tを全部サポートごとに推定。
実データはIRIのスキャナー・パネル・データ。買い物行動の発生ではなく、洗濯洗剤とペーパータオルの購買をモデル化する。共変量は、価格、ディスプレイ、チラシ、インベントリー(世帯内の買い置きのことであろう。どうやって調べたんだろう...)。すべて最尤法で推定。ええと、連続時間PHM, 離散時間PHM, 競合リスクモデルのそれぞれについてハザード分布が5通り、ノンパラPHM(100時点)と合わせて16個。さらに異質性を組み込んだやつも推定するわけだ。で、モデルのSBC (BICのことであろう)を比較する。
結果は...
- 離散時間PHMはうまくいくが連続時間PHMはうまくいかない(共変量の符号が変になる)。これは、連続時間PHMが「買い物に行ったけど買わなかった」と「買い物に行っていない」を区別していないからである 。
- ベースライン・ハザードとしてはexpo-powerがお勧め。
- 競合リスクモデルはうまくいき、前期で購買したときと非購買だったときで共変量の効果がちがっており、豊かな知見が得られた。
- わざわざノンパラPHMを推定してもたいしたメリットはない。
- 異質性を組み込むと(サポートは3つ)、あてはまりは良く、ベースライン・ハザードの水準と形状がサポート間で大きく変わった。
今後の課題としては... 最尤法で推定したけど今後はMCMCが有望。異質性についてはHB推定が有望。時間変動共変量だけでなく時間不変共変量についても要検討。離散PHMについては連続的確率密度だけでなく離散的確率密度も要検討。パラメータが非定常である場合も要検討。PHMと加法リスクモデル(ARM)との比較も要検討。
離散時間PHMを導入するところで派手につまづいてしまい、読むのに時間がかかった。わからなくなったのは、離散時間PHMを実データを当てはめる際に t をどのように離散化したのか、という点だ。散々悩んだのだが、おそらくほんとに週で区切ったのではないかと思う。とすると、「この週は買い物にいかなかった」人が少数ながらも生じてしまい、結局は「買い物に行ったけど買わなかった」と「買い物に行っていない」の区別がつかなくなるのではないか、という疑問が残っているのだが...。
上記の混乱は私の予備知識が足りないからであって、総じてとてもわかりやすく、非常に勉強になる論文だった。説明がきびきびしていて、実にありがたい。ここ数日で何本か読んだ類似の論文と同じことを説明していても、こちらのほうが断然わかりやすい。他の学者さんたちにも見習ってほしいよ。
前々から不思議に思っていたのだけれど、ID-POSやスキャナー・パネルのデータを使ってブランド購買をモデル化する際、往々にして当該カテゴリの購入記録だけを抽出して分析しているように思う。でも、ある来店におけるカテゴリ非購買には複数種類あるから(カテゴリがほしくなかった、買いたいブランドがなかった)、それらのちがいを考慮しないと、ブランド購買のモデルにバイアスが生じるのではないか、という疑問があった。この論文はカテゴリ購買タイミングのモデルだけれど、単位期間におけるカテゴリ非購買に複数種類あり(非来店、来店非購買)、それが共変量の効果にバイアスをもたらすという点で、結局は同じ問題を抱えているわけだ。おかげで霧が晴れたような思いである。やっぱし、見よう見まねではなくて、ちゃんと勉強せんといかんね。
読了:Seetharaman & Chintagunta (2003) 購買タイミングの比例ハザードモデル
2013年4月19日 (金)
Telang, R., Boadwright, P., Mukhopachyay, T. (2004) A mixture model for internet search-engine visits. Journal of Marketing Research, 41(2), 206-214.
仕事の都合で目を通した。購買でも店舗訪問でもいいから、繰り返し生起する行動の間隔を生存モデルで分析した実例を読みたかったのである。きっとこの分野の方には基礎知識に属する話だろうから、ちょっと恥ずかしいんだけど。
えーと、論文の主旨としては... NBD(負の二項分布)やPHM(比例ハザードモデル)に基づく購買間隔の確率モデルがいまいち使われていないのは(←そうなんですか?)、購買の周期性 periodicity を説明できないからだ。そこで,周期性を取り込んだモデルを作ってごらんに入れましょう、とのこと。
基本的なアイデアは次の通り。24時間の周期性を想定し、日内の確率分布としてラプラス分布を想定し(正規分布より裾が厚い)、それを24時間で切り落とし横につなぐ。数式をちゃんと追いかけてないけど、24時間周期の波型になるような確率密度分布をつくるのであろう。これをf_{TL}(t)とする。式で書くとすごくややこしい。
で、ある人のある時点の訪問有無は、確率pで(この周期と無関係に)ある確率密度分布 f_B(t)に従い,確率(1-p)でこの確率密度分布 f_{TL}(t)に従うと考え、混合分布 f_M(t)を導出する。これをハザード関数 h_0(t) に変換し、これをベースライン・ハザードにしたPHMをつくる... というのが基本アイデア。
PHMには共変量を突っ込むだけでなく、pやらf_B(t)のパラメータや共変量の係数やらについても消費者間異質性も入れ込む。ここの部分、support-pointという考え方が出てきて、どうやら潜在クラスのようなテクニックらしいのだが、予備知識がなくてよく理解できなかった。Heckman&Singer(1984, Econometrica), Jain & Vilcassim (1991, Marketing Sci.)を読めとのこと。絶対読まないと思いますが。
で、実データへの適用。126人の1年間のインターネット利用ログを用い、検索エンジンへの訪問を抽出。リストにgoogleが入っていないところに時代を感じる。共変量として、検索エンジンの累積利用回数 (ネット利用経験とともに検索の頻度は下がる、という仮説があったのだそうだ。これも時代だなあ)、検索エンジンサービスの検索以外の機能の利用回数、これらの交互作用。f_B(t)として、ワイブル、対数ロジスティック、expo-power, Conway-Maxwell-Poisson (なんだそれは) の4つを試す。さらに、f_{TL}(t)を入れる奴といれない奴を試す。
結果は ... f_{TL}(t)をいれたほうがよかった。セグメント数は2がよくて、周期性が強い人と弱い人に分かれた。f_B(t)としてはexpo-powerがよかった。共変量の効果はどうのこうの。ホールドアウトに対するヒット率はどうのこうの(面倒なのでスキップ)。
細かいところがどうもよく理解できなかった。これって、前回のアクセスから24時間後に「そろそろまたアクセスすんじゃないの」と勘繰るモデルなのだろうか? それとも「こいつはだいたい毎晩何時ごろにアクセスしよるわい」と推定するモデルなのか? そこさえ確信が持てない(前者だとすると、購買ならばともかくwebアクセスの分析としてはちょっと現実味がないなあ...)。この辺は著者のせいというより、私の読解の不足のせいだと思う。顔洗って出直して来いってことでしょうね。
読了:Telang, et. al. (2004) 検索エンジンへの訪問(とかそういう感じのなにか) の間隔を説明する周期性つきの生存モデル
2013年3月13日 (水)
Greenleaf, E.A. (1992) Improving rating scale measures by detecting and correcting bias components in some response styles. Journal of Marketing Research, 29(2), 176-88.
x件尺度の調査項目への回答における回答スタイルの影響についての実証研究として、よく引用されているらしき論文。先日用事があって大急ぎでめくった資料のなかの一本。なんだかちょっと腹が立ったので最後まで目を通した。
回答スタイルとして黙従傾向(yea-saying)と個人内SDの大きさに注目。たとえば、ある調査におけるyea-sayer (なんでもyes方向に回答しちゃう人) は、ほんとにすべての項目に対してポジティブな態度を持っている人なのかもしれないし、単にそういう回答バイアスを持っている人なのかもしれない。この二つが分離できないと、なにかと困る。分離してみましょう。という主旨。ただし、仮に回答スタイルの影響を受けない外的基準が手に入っていたら... という、いささか現実味のない状況についての話である。
対象者 i が行動項目 k について示す行動頻度 B_{ik}(これが外的基準)についてのモデルをつくる。態度項目 j への反応を A_{ij}, 反応の個人内平均を M_i, 個人内SDを S_i として、
B_{ik} = \alpha_0
+ \alpha_1 A_{ij}
+ \alpha_2 M_i
+ \alpha_3 (S_i - S_{med})
+ \alpha_4 (S_i - S_{med})(A_{ij} - M_i)
+ \epsilon_{ik}
S_{med}というのは個人内SD S_i の標本中央値。5つ目の交互作用項がわかりにくいけど、以下のような理屈である。話を単純にするために、態度項目と行動項目に正の相関がある場合についてのみ考える。つまり、\alpha_1は正。
- yea-sayingが回答バイアスを含んでいたら、\alpha_2は負になるはずだ(H1)。
- 個人内SDの大きさが回答バイアスを含んでいたら、個人内SDが大きい人が(S_i - S_{med}が大)、その人の平均より高めの回答をしたとき(A_{ij} - M_iが正)、その回答は割り引かなければいけないわけだから、\alpha_4は負になるはずだ(H2)。
さらに、こんなモデルもつくる。態度項目への回答を個人内で標準化したスコア A^*_{ij} = (A_{ij} - M_i) / S_i をつかって、
B_{ik} = \delta_0
+ \delta_1 A^*_{ij}
+ \delta_2 M_i
+ \delta_3 (S_i - S_{med})
+ \delta_4 (S_i - S_{med})(A^*_{ij})
+ \epsilon_{ik}
さっきと同様、\delta_1は正として、
- yea-sayingがその人の態度についての情報をなにがしか含んでいるならば、\delta_2は正になるはずだ(H3)。
- 個人内SDの大きさがの人の態度についての情報をなにがしか含んでいるならば、\delta_4は正になるはずだ(H4)。
うーん、こういう「白じゃなかったらそれは黒だ」的仮説設定はあんまり好きになれないのだが、well-formedではある。
というわけで、アメリカの広告代理店がやった大規模な郵送調査データで検証する。さまざまな6件法態度項目が224項目、いろんな行動の頻度の聴取が127項目はいっていた由。それでいて回収率81%って、どんな調査なんだか...。
まず、態度項目から個人内平均と個人内SDを求める。年齢、性別、年収との関連はあったが、行動項目との相関はなかった由。よかったですね、そこが崩れると、この話、滅茶苦茶になってしまう。
次に、態度項目と行動項目を突合せ、関連が強くて筋もとおっているペアを49個つくって、それぞれのペアに上記の2つのモデルを当てはめOLS推定する。その結果、
- \alpha_1と\alpha_2の符号が逆になった(H1を支持した)のは、21ペア。
- \alpha_1と\alpha_4の符号が逆になった(H2を支持した)のは、43ペア。
- \delta_1と\delta_2の符号が一致した(H3を支持した)のは、38ペア。
- \delta_1と\delta_4の符号が一致した(H4を支持した)のは、39ペア。
まとめていうと、yea-sayingってのはバイアスではない(H1, H3は不支持)、個人内SDは部分的にバイアスだが、それだけじゃない。とのこと。
では、個人内SDに起因するバイアスを除去してみましょう、というので、以下の指標をつくる。
A^{**}_{ij} = w_i A_{ij} + w_2 ( (A_{ij} - M_i) / (S_i / S_{med}) + M_i)
ただし w_1 + w_2 = 1。右辺第二項は、回答を個人内平均に向かって縮小してやった値で、その縮小率は個人内SDとその標本中央値の比で決める、という主旨である。
この指標のw_1を0.25刻みで動かしながら、下のモデルに当てはめたところ
B_{ik} = \gamma_0
+ \gamma_1 A^{**}_{ij}
+ \gamma_2 (S_i - S_{med})
+ \gamma_3 (S_i - S_{med})(A^{**}_{ij} - M_i)
+ \epsilon_{ik}
w_1 = 0.5のとき、R^2が最大になり、\gamma_1と\gamma_3の符号が一致するペアはだいたい半分(28ペア)になった。
よしよしこれで修正できたぞ、というわけで(信じるって素晴らしいなあ)、修正によって生じるインパクトを2例示す。12個の態度項目から2つの主成分を抽出し、対象者を各主成分の上位10%/中位80%/下位10%に分類する分析を、修正前と修正後で比較すると、修正によって上位/下位群から出て行った人と入ってきた人の年齢・教育水準が違う、とか。クラスタ分析だったらどうだったか、とか。このへんは、まあ実務家むけのデモンストレーションのつもりだろう。
著者が想定している回答スタイルは、Baumgartner&Steenkamp(2001) がいうところのARS, ERS, MPRだと思う。なにもそれだけがバイアスの源じゃないだろうと思うが、もともと回答スタイルの実証研究には、問題とする回答スタイルを各研究者が好き勝手に定義しちゃうという悪弊があるものなので、ここでそれをあげつらっても仕方ない。ひとつの横断調査データのなかから態度項目と行動項目のペアを見つけ、ひとたび見つけるやいなや「この行動はこの態度で予測できるはずだ」と信じる、というのも相当強引なアプローチだと思うけど、それもまあいいとしよう。態度から行動を予測するにあたり、「態度の個人内偏差と個人内SDの交互作用項が負に効いたらそれはERSバイアスの証拠だ」という理屈も、多重共線性の心配はないのかしらんと不思議だが、まあよしとしよう。
いっちばん引っかかるのは、交互作用項の係数の大きさではなく、符号にのみ注目していることだ。「49個のモデルのうちそれが負になったのは何個」だなんて、1992年に至って、なぜそんなローテクな話を? さっぱりわからない。個々のモデルについて効果量を求めるのが筋だろうに。
後半の、回答スタイルがセグメンテーション・スタディを歪めるという例示も、ちゃんと読んでないけど、ちょっとげんなりする。著者が示しているのは、ある指標群をつかった対象者分類と、その指標群をちょっぴり変換した(回答の個人内分散が大きい人の回答を個人内平均に向かって少しずらした)指標群をつかった対象者分類が、デモグラフィック特性の観点から異なっていました、という話だ。それは要するに、回答の個人内分散がデモグラフィック特性によって異なるということだろう。だったらなぜそれを直接示してくれないのかと思う。わざわざセグメンテーションの文脈に持ち込むのは、なにかこの論文誌のお作法のようなものなのだろうか。
素直に考えれば、たとえばある人がなんでもyes方向に回答しちゃったとして、それはその人がほんとに全項目についてポジティブな態度を持っていることを表しているのかもしれないし、単にそういう回答スタイルの人なのかもしれない。それは常に両方ありうることで、どっちかだけが正しい、なんてことはありえないだろうと思うのである。だから「yea-sayingは回答バイアスを含んでいるか否か」というような、白か黒かという仮説設定自体が、ああ論文のための仮説、研究のための研究だなあ、という気がする。
現実には、回答スタイルらしきものはいつも存在する。その効果を全然除去しないのも困るし、完璧に除去しちゃうのも困る。そのさじ加減を決めるのが一番の悩みどころだし、その合理的な方法こそが、回答スタイル研究に強く期待されるところだろう。この論文でいえば、w_1の値を決めるところがそれだ。ところがこの先生ときたら、w_1を0から1まで0.25刻みで動かし、たった5通り試しただけで、よしw_1=0.5だと決めてしまう。なんだかなあ、もう...
などとぼやきつつ最後のパラグラフまで読んでから気が付いたのだが、よく引用されているのはこの論文じゃなくて、著者が同じ年にPublic Opinion Quarterlyに載せたほうだ。ガアアアッデム...
読了:Greenleaf(1992) 回答スタイル由来のバイアスを検出・補正する
2012年11月 9日 (金)
de Leeuw, J. & Mair, P. (2009) Multidimensional scaling using majorization: SMACOF in R. Journal of Statistical Software, 31(3).
RのMDS用パッケージ SMACOF の解説。仕事の都合で読んだ。
このパッケージは,計量的・非計量的MDSの解を求める際にSMACOF(Scaling by majorizing a complicated function)という方法で目的関数を最適化する。その仕組みは,えーっと... 真面目に数式を追いかけたのだが,途中で落ちこぼれた。まあ,これはさすがに仕方ない,私の能力を超えている。
それはともかく,高根のALSCALのような他の方法と比べた利用上の得失について,教えてくれたら助かったんだけどなあ。そのへんは,Cox&Cox(2001) という本を読めとのことであった。
読了:de Leeuw & Mair (2009) パッケージSMACOF
2012年11月 7日 (水)
Bacher, J., Wenzig, K. ,Vogler, M. (2004) SPSS TwoStep Cluster: A first evaluation. Albeits- und Diskussionpapiere 2004-2. Universität Erlangen-Nürnberg.
みんな大好きな SPSS Statistics に搭載されている、TwoStep Clusterという謎のクラスタ分析手法についての解説と検証。仕事の都合で読んだ。最近はどうかしらないけど、もともとSPSSはTwoStep Clusterの詳細な中身を開示していなかったように思う。
前半は解説。TwoStep Clusterというのはデータマイニングでいうところの BIRCH クラスタリングなのだろうと思っていたのだが、細かいところはちがうのかもしれない。直接参考にすべきは開発者たちが書いた Chiu et al.(2001) だそうだが(SPSSのマニュアルで引用されている奴)、どうやらそこにも具体的な実装上のパラメータは説明がないらしく、著者はSPSSのサポートに細かく問い合わせて解明している。さぞや面倒であったことだろう。
後半はシミュレーション。斜め読みだけど、潜在クラス分析(Latent Gold)と比べて性能が悪い。特に変数の尺度が混在しているときに悪い由。まあ、潜在クラス分析とは扱えるデータサイズがちがうわけで、単純に比較してはいかんのだろう。
それよりも... シミュレーションはSPSS 11.5のドイツ語版でやったのだが、SPSS 12のドイツ語版でやっても、さらにSPSS 11.5の英語版でやっても、違う結果になった由。サポートいわく、たぶんアルゴリズムを改善したんでしょう、とのことだそうだ。そういうところが、ヤなんだよなあ....
読了:Bacher et al.(2004) SPSS TwoStep Clusterの謎を解く
神嶌敏弘(2002) データマイニング分野のクラスタリング手法(1). 人工知能学会誌、18(1), 59-65.
神嶌敏弘(2003) データマイニング分野のクラスタリング手法(2). 人工知能学会誌、18(2), 170-176.
題名のとおり、クラスタリング手法のレビュー。階層クラスタリングやk-means、その利用上の注意点からはじめて、モデルベースの方法、PAM, BIRCHなどを経て、なんだかわからんがすごそうな手法へと話が広がっていく。仕事の調べもののついでに読んだのだが、大変勉強になりました。もっと早く読んでおけばよかった。
読了:神嶌(2002,2003) データマイニング分野のクラスタリング手法
2012年10月26日 (金)
Mac Nally, R., & Walsh, C.J. (2004) Hierarchical partitioning public-domain software. Biodeversity and Conservation, 13, 659-660.
Hierarchical partitioningについて勉強しようと思って入手してみたら、「こんどRでhier.partというパッケージをつくったからみんな使ってねーん」というだけの、実質1pに満たない、ただのお知らせであった。これがoriginal paperになっているのって,どういうことよ... 暴動を起こしたい気分です。
読了:Mac Nally & Walsh (2004) hier.partをつくったから使ってね(あるいは,業績リストを長くする方法)
2012年10月19日 (金)
Bas, D. & Boyaci (2007) Modeling and optimization I: Usability of response surface methodology. Journal of Food Engineering. 78, 836-845.
食品科学の分野での、応答曲面モデル(RSM)をつかった研究のレビュー。ずっと前に欲しい資料リストにいれていて、そのまま忘れていたのだが、このたび必要な論文をかき集めた際にうっかり一緒に入手してしまい、もったいないので目を通した。著者はトルコの方で、Basのsの下にはヒゲがついており、Boyaciのiには点がない。世界は広いなあ。
まず、RSMについてざっと紹介。次に、先行研究(だいたい'00年代の)をひとつひとつ取り上げ、不備をぐりぐりと指摘する。楽しそうなのだが、残念ながらすべての例について、単語が全くわからず、したがって実質的な中身がさっぱりわからない。いきなり"... worked on lipase catalyzed biochemical reaction, incorporation of docosahexaenoic acid into borage oil" なんて言われても、なんの呪文かと... (いまこの行に限って辞書を引き引き推測するに、リパーゼというものをつかって、ドコサヘキサエン酸というものを、ルリジサ油というものに混ぜるかなにかなさろうという話であろう。世界は広いなあ)
しょうがないから総評のところだけメモしておくと... 全般に独立変数についての予備調査が足りない。そのせいで最適点を見つけ損ねている研究が多い。また、データにあるすべての変数を二次多項式に放り込んではいけない。変数のとる範囲を調整するとか、次数の検討とか、変数の変換とかが大事。というような仰せである模様。よくわかんないけど。
ほんとは応答曲面モデルでパラメータを最適化するための実験計画のレビューを期待していたのだけど、触れていなかった。Myers & Montgomery を読むしかないか...
読了:Bas & Bayoci (2007) 応答曲面モデルの使用例レビュー
2012年10月18日 (木)
Crown, W.H. (2010) There's a reason they call them dummy variable: A note on the use of structural equation techniques in comparative effectiveness research. Pharmacoeconomics, 28(10), 947-955.
タイトルがあんまり魅力的なので、ついうっかり入手してしまった。観察研究で介入効果を推定する際、一本の回帰式に介入有無のダミー変数をいれることが多いけど、もっとましな方法がいっぱいあるのですよ、という啓蒙論文。紹介されているのは、構造方程式モデル(あまりピンとこなかったのだけど、多母集団モデルのことなのかしらん)、regression-based decomposition methods (えーっと、賃金格差の研究なんかでよく使う、男の回帰モデルに女の平均ベクトルを突っ込むようなやつだと思う。「要因分析」と訳すのだろうか)、傾向スコア、道具的変数、事前-事後データのdifference-in-difference分析。それぞれの説明が短くて、かえって混乱してしまった。
関係ないけど... この論文のタイトルにあるCER(比較効果研究)という言葉、オバマ政権の医療制度改革の話の中でよく出てくるけど、あれってなんなんだろう、EBMやヘルス・テクノロジー・アセスメントとどうちがうのかしらん。ど素人の漠然とした印象では、CERが一番サツバツとした雰囲気の用語だという気がするんだけど... 似た言葉がいっぱいあって困るなあ。
2012年10月11日 (木)
Unlu, A., Kiefer, T., Dzhafarov, E.N. (2009) Fechnerian scaling in R: The package fechner. Journal of Statistical Software, 31(6).
客観的にはたいしたことないんだろうけど、主観的には「年に一度」級の、ややこしいデータ解析の課題を抱えていて、どうアプローチすればよいのか思い悩んでいる。たまたま R のfechnerパッケージというのをみつけて、なんだかわかんないけど、これだ!これでブレイクスルーだ!と喜んだが、ちゃんと読んでみたら、もう全くのぬか喜びであった。全然関係ないじゃん。まあ、せっかく目を通したので記録しておく。
ええと、Fechnerというのは、心理学の入門コースに出てくる19世紀の哲学者、フェヒナーさんのこと。Fechnarian scalingというのは耳慣れない言葉だが、Dzhafarovさんという人が提唱している考え方らしい。素人目には非計量的MDSみたいなものなのだけれど、いわく、全く違うアプローチなのだそうであります。
いま n 個の対象があって,すべての2個の間の弁別確率,ないしそれに類するなんらかの非類似性が与えられているとする。この正方行列に基づいて対象に数量を与えようとする手法としては、すでにMDSがあるけれど,Fechnerian scalingはそれより制約が緩い。対角要素が 0 でなかろうが,非対称であろうが,A-B間非類似性とB-C間非類似性の和がA-C間非類似性より小さかろうが、いっこうに構わない。ただ以下の条件さえ満たしていればよいのである。
- 任意の対象 i が,それとの非類似性がほかのすべての対象との非類似性よりも小さい対象 j をひとつだけ持っていること。この j を,i の主観的等価点(PSE)と呼ぶ(うわー,精神物理学だ...)。
- i のPSE が jだったら,jのPSEはiであること。
えーと,要するに,正方行列の各行に最小値がひとつだけあり,その値はその列での最小値でもある,ということですかね。この制約をregular minimalityという由。
で、この条件が満たされているとき,対象間に計量心理学的な距離を与えることができるんだそうだ... このパッケージはその計算をやってくれるのだそうだ...
細かいところを読んでいないせいだろうけど、どういうときにどういう風に便利なのか、全くわからなかった。いきなりRのパッケージの説明を読んでいるのが悪いのだろう。
読了:Unlu, A. et al. (2009) 「フェヒナリアン尺度構成」をやりたい人にとっては夢のようなRパッケージ
Theil, H. (1987) How many bits of information does an independent variable yield in a multiple regression?, Statistics & Probability Letters, 6, 107-108.
重要性についての研究をあれこれ調べていると、統計学方面では重回帰の決定係数を独立変数へと分配するというタイプの提案が脈々と続いているのだが(それにどんな意味があるのかは別にして)、この論文もそのひとつ。
よく引用されているようなので、国会図書館に籠って資料探しした際についでに手に入れてみたら、たった2pのノートであった。別にいま読むことはないのだが、積読リストが1行でも短くなるとうれしいので、さっさと読了。
重回帰モデルの重相関係数をR、従属変数 X_0 と 独立変数X_1, X_2, ..., X_p との相関係数をそれぞれ r_{01}, r_{02}, ..., r_{0p}、X_2を取り除いた X_0とX_1の偏相関係数を r_{01|2}とする("|"は原文では\cdotだが、読みにくいので略記する)。ここで下式が成り立つ:
1 - R^2 = (1 - r^2_{01}) (1 - r^2_{02|1}) \cdots (1 - r^2_{0p|12\cdots(p-1)})
両辺について2を底にした対数をとる。I(x) = -log_2 (1-x) と略記することにして、
I(R^2) = I(r^2_{01}) + I(r^2_{02|1}) + \cdots + I(r^2_{0p|12\cdots(p-1)})
I(R^2)は, 独立変数群によって与えられた X_0 のふるまいについての情報の量を、ビットを単位として表したものであるといえる。上式はこれを独立変数に分配している。つまり、重回帰式における独立変数の重要性を求めたことになる。
実際には、独立変数にはふつう順序がないので、Kruskal(1987)にならって、独立変数のすべての順列をつかったp!本の式をつくり、結果を平均すると良いでしょう、とのこと。
このアイデアの特長は:
- Kruskal流のアプローチを、情報理論における情報量の加法性という性質で自然にサポートしている。
- Kruskalのアプローチでは、すべての順列について平均してはじめて重要性が決まるのだが(えーと、そうだっけ?)、このアプローチでは各順列について決まる。
- この重要性は相対的な指標ではなく、ビット単位で表現される絶対的な指標だ。
- R^2より I(R^2)のほうが自然だ。R^2=0.98, 0.99, 0.999というのはほとんど同じだが、I(R^2)=5.64, 6.64, 9.97 というのはずいぶん違うでしょ?
う・う・む。。。
読了:Theil(1987):決定係数を分配する方法(情報量バージョン)
2012年10月 3日 (水)
Haaijer, R., Kamakura, W., Wedel, M. (2001) The 'no-choice' alternative in conjoint choice experiments. International Jounal of Market Research, 43(1), 93-106.
離散選択型コンジョイント・モデルで「どれも選ばない」選択肢をどう扱うか、あれこれ考えていたらだんだん混乱してきちゃったので、頭を整理するために他のを脇にどけて急遽読んだ。基礎ができていないと、これだから、もう。
著者らいわく、「どれも選ばない」の扱い方には2種類ある。
- 多項ロジットモデルに、「どれも選ばない」選択肢の効用を表す定数をいれる。えーと、それってつまり、「どれも選ばない」選択肢でのみ 1 になるような属性があると考える、ということですよね?
- 入れ子型多項ロジットモデル。「どれも選ばない」という(選択肢がひとつしかはいっていない)ネストと、「どれが選ぶ」というネストがあると考える。
後者のモデルはむやみにややこしくなっちゃうんじゃないかと思ったが、案外そうでもない。まず、「どれか選ぶ」ネスト内のモデルは通常の選択モデルと変わらない。「どれも選ばない」ネスト内の選択モデルはいらない。ネスト n の選択確率は,ネストn' 内の全選択肢の効用の総和をV_{n'}として、
P(n) = exp(\lambda V_n) / \sum_{n'} exp(\lambda V_{n'})
となる。\lambdaをdissimilarity coefficientと呼ぶ由 (これが 1 ならば通常の多項ロジットモデル)。というわけで、パラメータは 1 つしか増えていない。「どれも選ばない」つき多項ロジットモデルと同じである。
2つの実データセットについて、「どれも選ばない」つき多項ロジットモデル、入れ子型多項ロジットモデル、ふつうの多項ロジットモデル(「どれも選ばない」選択肢はすべての属性のダミー変数を 0 にして表現する)、の3つを比較。当然ながら、ふつうの多項ロジットモデルは歪む (線形推定している属性があるときは特に)。どちらのデータセットでも、「どれも選ばない」つき多項ロジットモデルの適合度が良かった由。
著者らいわく、「どれも選ばない」つき多項ロジットモデルがよいか、入れ子型多項ロジットモデルがよいかは、回答者が「どれも選ばない」選択肢を選んでいる理由によって決まる。回答者がまずどれか選ぶかどうかを決め、次にどれを選ぶかを決めている場合は、入れ子型多項ロジットモデルがよい。いっぽう、回答者がどれも魅力に感じないせいで「どれも選ばない」を選んでいる場合には(もしくは、選ぶのが難しくて「どれも選ばない」に逃げている場合には)、「どれも選ばない」つき多項ロジットモデルがよい。逆に言えば、両方のモデルを当てはめて適合度を比較すれば、回答者がどっちの方略を用いているのかについての示唆が得られる。。。とのこと。
うーむ、筋は通っているけど、ちょっと思弁的な感じがする。それって実証できる話じゃないですかね。選択課題とプロトコル分析を組み合わせるとかで。
読了:Haaijer, Kamakura & Wedel (2001) 選択型コンジョイント分析における「どれも選ばない」選択肢の扱い方
2012年9月29日 (土)
Howell, W. (2011) CBC/HB, bayesm and other alternatives for bayesian analysis of tradeoff data. Proceedings of Sawtooth Software Conference 2011, 355-364.
仕事の都合で目を通した。コンジョイント課題の実データ,maxdiff課題(best-worst課題)の人工データと実データを用い、階層ベイズ法による個人効用推定をいくつかのソフトで試して比較しましたという報告。コンジョイント分析のソフトで知られるSawtooth社のユーザ会発表資料。著者はHarris Interactive社のえらい人。
ソフトは、Rのbayesmパッケージ、WinBUGSとOpenBUGS、Sawtooth社のCBC/HB、そしてHarrisのソフト(HIhbmkl)。計算速度、モデルの対数尤度、ホールドアウトでのヒット率などを比較する。
Rではbayesm::rmnlIndepMetrop()を使っている(名前からして,独立連鎖メトロポリス・ヘイスティングス・アルゴリズムで多項ロジットモデルを推定する関数であろう)。なんでrhierMnlRWMixture()を使わないのかと思ったら、CBC/HBはむしろrmnlIndepMetrop()に近いらしい。そうなんすか? 難しくってよくわかんないや。
CBC/HBがもうぶっちぎりで速い由。それはいいとしても、対数尤度やヒット率が結構違うというのにびっくり。怖いなあ。
読了:Howell (2011) CBC/HB とそのライバルたち
2012年9月19日 (水)
バタバタしている時には論文など読めないし,従ってメモも取れないが,不思議なもので,根を詰めて論文を読みあさっているときも,なにやら面倒に感じてメモをとれなくなる。これは何日か前に書きつけていたものだが,他に何を読んだのか思い出せない。困ったものだ。
Little, R. (2006) Calibrated Bayes: A Bayes/Frequentist roadmap. The American Statistician, 60(3), 213-223.
良く知らないけど、著者は偉い人だと思う (Little & Rubin のLittleであろう)。Rubinたちは統計学での古典的な頻度主義アプローチとベイジアン・アプローチとを融合したcalibrated bayesianアプローチというのを唱えているのだそうで、それを紹介した論文。大会の招待講演が基になっているようで、変なイラストがついていたりして、楽しい。
ここでいう頻度主義とは、未知パタメータΘについての仮説検定なり信頼区間なりを、反復抽出下での統計量の分布から引き出そうとする立場のこと。ベイジアンとは、データについてのなんらかのモデルとΘの事前分布に基づき、Θの事後分布についての推論をしようとする立場のことで、事前分布をどう基礎づけているかはこの際問わない。漸近的な最尤推論はベイジアンに分類される由(Θの区間を信頼区間ではなく信用区間として捉えているから)。
著者いわく、たいていの統計学者はその場その場で役に立つほうのアプローチを採ればいいやと考えており、2つのアプローチに橋渡しをしようとは思っていない。でもアナタ、アプローチが2つあるということは誠に困ったことなのですよ、と著者は多数の事例を挙げて説得にかかる。たとえば平均の区間推定で、n=7 で標本平均が 1、SDが 1 だったとき、95%信頼区間は母分散未知として 1±0.92, 母分散 1.5 として 1±1.11 だが (ジェフリーズ事前分布を用いたベイズ信用区間もそうなる)、「母分散が1.5より大」であることが既知の場合、それを生かした信頼区間の求め方はわからない(ベイズ信用区間なら 1±1.45)... などなど。
それぞれのアプローチの長所と短所を整理すると... 頻度主義アプローチの短所として以下の点が挙げられる:
- prescriptiveでない。たとえば「最小二乗の原理」というのは、推論手続きの特性評価をしてくれるだけで、推論システムそのものを一般的に提供してくれるわけではない。
- 不完全である。ベーレンス・フィッシャー問題を見よ(等分散性が仮定できない二群の平均の差の正確な信頼区間は求められない)。
- あいまいである。2x2クロス表の独立性の検定では、ピアソンのカイ二乗検定、イエーツ補正つき検定、フィッシャーの正確検定があって、使い分けに明確な合意がない。
- 尤度原理に反する(尤度が同じなら含まれている情報も同じだ、という原理に反する)。コインを投げて表が出る確率をΘとする。「12回投げる」実験で3回表が出たら、尤度は L ∝ Θ^3 (1-Θ)^3。「3回表が出るまで投げ続ける」実験が12回で済んだ場合、尤度はやっぱり L ∝ Θ^3 (1-Θ)^3。ところがΘ<1/2を対立仮説とした片側検定の正確 p 値は、前者と後者で異なる(前者は二項分布、後者は負の二項分布から求めるから。おおお、気づかなかったー)。
いっぽうベイジアンアプローチの短所としては以下の点が挙げられる。なお、「確率の定義と事前分布の選択が主観的だ」というよくある批判に著者は同意しない(頻度主義アプローチだって場合によっては主観的だから)。
- モデル(尤度関数と事前分布)を完全に指定しないといけない。
- 提供される答えが多すぎる。つまり、事前分布次第で答えが大きく変わってしまう。
- モデルがまずいと答えもまずい。頻度主義アプローチの場合、特性の良い手続きを探すということがモデルの誤指定に対するある程度の予防となっているわけだが、ベイジアン・アプローチの場合、モデルを間違えたら一巻の終わりである。そしてモデルというものは、多かれ少なかれ常に間違っているものだ(ここで層別抽出についての簡単で面白い事例を紹介)。過激な主観ベイジアンならばそれも良しとするところだろうが、科学的推論に対するアプローチとしてはちょっと厳しい。それにそういう人たちだって、実際にはデータをこっそり覗き見してからモデルを決めてんじゃじゃないですかね、とのこと。ははは。
さて、calibrated Bayesianとは... 頻度主義者はモデル形成と評価に強く、ベイジアンはモデル下での推論に強いんだから、両方をいいとこどりしましょう、というアプローチである。Box(1980)という人はこう定式化しているのだそうだ:
p (Y, Θ | M) = p (Y | M) p (Θ | Y, M)
右辺第2項のp (Θ | Y, M)、すなわちデータYとモデルMの下でのパラメータΘの事後分布が、パラメータ推論の基盤となる。第1項の p (Y | M) の検討、すなわちモデルMの下でのデータYの周辺分布の検討が、Mのチェックを意味する(ここで頻度主義の考え方が導入される)。この両方が大事なわけだ。
といわれてもピンとこないけど、実例としては... 2x2クロス表の独立性の検定の場合、結局はベイズ信用区間を出すんだけど、ジェフリーズ事前分布を採用して良かったかどうかをフィッシャーの正確検定でチェックする (ええー???)。平均の区間推定の場合、結局はベイズ信用区間を求めるんだけど、ジェフリーズ事前分布を採用して標本分散の事後予測分布を出し、手元の標本分散が得られる確率がそれに照らして低すぎないか検定する(ええー???)。などなど。
最後に、calibrated Bayesの立場からの統計教育への提言: 修士課程でベイズ統計を必修にしなさい。統計手法よりも統計モデリングを重視しなさい。モデル適合度の評価にもっと注意を向けなさい(フィッシャー流の有意性検定を含む)。
実例のくだり,胡瓜の酢のものをクリームシチューにいれましょうなんて云われたような感じで、面食らったのだけど。。。要するに、基本的にはベイジアン、でも尤度関数と事前分布のチェックの際には頻度主義的アプローチもアリ、という立場であろう。
読了:Little (2006) 古典的統計学とベイズ統計学の折衷派宣言
2012年8月24日 (金)
Boettcher, S.G., Dethlefsen, C. (2003) deal: A package for Learning Bayesian Networks. Journal of Statistical Software, 8(20).
Rのベイジアン・ネットワーク用パッケージ deal の紹介。構造学習はスコア法。離散変量と連続変量の混在を許す。
散在する数式をみて、こりゃ読んでもわけわからんだろうと予期していたのだが、やっぱりわけわかんなかった。Master Prior ってなによ...泣いちゃうぞ...
それにしても、Rのパッケージはなにかしらの紹介論文をめくった後でないと本気で使う気になれない、というのは、ちょっと頭が固すぎるんだろうなあ。
読了:Boettcher & Dethlefsen (2003) dealパッケージ
2012年8月21日 (火)
Shadish, W.R. & Sullivan, K.J. (2012) Theories of causation in psychological science. Cooper, H., et al. (eds.), "APA Handbook of Research Methods in Psychology," Volume 1, Chapter 2. American Psychological Association.
心理学の研究者向けに(つまりは非専門家向けに)、Campbell, Rubin, Pearlらの因果推論の考え方を比較して紹介する論文。Pearlさんご自身がblogで紹介しているのを見つけて読んだ。
データ解析の文脈で因果推論について考えるとき、最近はRubinやPearlの道具立てについて理解することが必須となっているようである。とはいえ、素人向けの解説は多くないし、RubinのアプローチとPearlのアプローチを比較してくれる解説はさらに少ない。また、もともと心理学ではCampbellが提案した概念が有名で(内的妥当性と外的妥当性とか)、考えてみればこういうのも因果推論のための一種のガイドラインなのだが、正面からの解説はやはり多くない。というわけで、これはとても貴重なレビューだと思う。勉強になりましたです。
前半は3つのアプローチの紹介。書き方からして、Pearl流のアプローチが一番理解しにくいとお感じになられているようで、ご親切に重要キーワード・リストまでつくってくださっている(ちょっと笑ってしまった)。なお選定された重要キーワードは、ノード、エッジ、有向エッジ、双方向エッジ、DAG、親・子・先祖・子孫、合流点、d分離、バックドアパス、バックドア基準、fork of mutual dependence, inverted fork of mutual causation, そしてdo(x)オペレータである。
後半は、いくつかの側面について3つのアプローチを比較する。理解できなかった箇所も多いのだが、いちおうメモしておく。なお、著者らはCampbell流、Rubin流、Pearl流の因果モデルをそれぞれCCM, RCM, PCMと略記している。
- 哲学的側面...
- CCMは概念的・哲学的スコープがもっとも広い。CCMはミルの因果の哲学、ならびに実験研究の方法論と結びついている。またポパーに従い、仮説の反証という考え方を重視し、対立的説明を常に歓迎する。CCMは人間の可謬性を強調する。
- RCMは哲学とあまり結びついていない。RCMを反事実的な因果理論として捉える人は多いが、Rubin自身は自分のモデルをpotential outcomeという概念を用いた形式的な統計モデルと捉えている(potential outcomeは原理的には観察可能であり、実験において観察されないときに反事実になるのであって、それ自体は反事実ではない)。また反証という考え方もあまり重視されない。
- PCMは因果の記述ではなく説明を重視する。たしかにd分離やdo(x)オペレータは因果の記述のためのルールだが、PCMはむしろDAGの構築に焦点を当てている(ある意味でCCMやRCMより野心的である)。PCMはランダム化実験をなんら特別視しない。
- 効果の定義...
- CCMではもともと効果の定義があいまいだった。たいていの場合、効果は2つの事実のあいだの差(ランダム化試験における処理群と統制群の差)として捉えられていた。
- RCMは効果の定義がすごく明確。
- PCMにおける効果の定義は、DAGを構成する方程式を解き、do(x)オペレータを用いてX=xがYの確率分布の空間に与える効果を推定することに依存している。その意味ではCCMと似ている。しかし、PCMでは効果をX=x_0とX=x_1の間の効果の差として定義することもできる。
- CCMとRCMは、問題を統計で解決することよりもデザインで解決することを好むが、PCMは両方を同じくらい重視する。また、CCMとRCMは、選択バイアスが未知である状況で分析者が正しいDAGをつくれるかという点について懐疑的である。
- 原因の理論...
- CCMは原因についての理論に注目する。いっぽうRCMやPCMは原因にあまり注意を向けない。RCMは効果推定に焦点を絞っているし、PCMの文脈では原因は単なる記号ないし仮説例である。
- CCMは、原因の構成概念的妥当性を確立するために、単なる実験的操作についての知識以上のものを求める。Campbellにいわせれば、実験的操作なんていうのは処理という概念のごく一部にすぎない。実験における処理とは、さまざまな要素からなる多次元的なパッケージなのだ。原因とは、研究者が注目している特徴を含むさまざま特徴の集合体である(なにしろCampbellは社会心理学者なのである。社会心理学では、その実験的操作は理論的関心の対象である構成概念をほんとに反映しているのか、というところで揉めることが多い)。
- CCMとPCMは、操作不能なものも原因になりうると考える(ナントカ遺伝子とか)。RCMはこの点についてあいまいで、そこが論争の種になっている。
- 因果の一般化 (外的妥当性と構成概念妥当性) ...
- CCMは、構成概念妥当性と外的妥当性というかたちで、一般化可能性に強い関心を持つ。もともとCampbellは、一般化可能性は大事ですというだけで、それを研究する方法はMTMM行列くらいしか持ち合わせていなかった。Cook&Campbell(1979)になると構成概念妥当性の理論が拡張され、知見の一般化の方法はランダムサンプリング以外にもあるということになり、Shadish et al.(2002), Cook(2004)に至る。いまではメタ分析やメディエータの分析が重要になっている。
- RCMはメタ分析やメディエータの分析に貢献してきたが、因果の一般化という問題に直接かかわることはめったにない。数少ない例外として、メタ分析における応答曲面分析についてのRubinの研究(Rubin, 1990, 1992)がある (←ナンダソレハ...)
- PCMは因果の一般化という問題に直接かかわらない。ただし、因果的説明が一般化の鍵になるという意味で、DAGが一般化のための道具になることはありうる。
- 定量化...
- 定量化についてはPCMとRCMのほうがCCMより先を行っている(Rubinは統計学者、Pearlはコンピュータ科学者だから、当然である)。だがしかあし、CCMの影響下で開発されたMTMM行列の分析や回帰分断デザインを忘れてはいかん。云々。
- デザインと分析...
- CCMとRCMはどちらもデザインの良さを重視するが、CCMはデザイン、RCMは分析により焦点を当てる(例外は傾向スコアによるマッチング)。この二つは補完的である。
- PCMはデザイン(ランダム化実験かどうかとか)に関心を持たない。CCMやRCMとはちがい、非ランダム化実験でもランダム化デザインと同じ結果を得たい... というような発想はない。PCMは分析、ないしDAGを構築するための概念的作業に焦点を当てる。ただし、ここでいう概念的作業は、RCMがテストをバランス化させる際と同じく、結果についての知識なしに行われる作業であり、その意味ではデザインの問題である。
- まとめ...
- 3つのアプローチはあまりに言葉がちがいすぎるので、どんな研究者でも、3つのアプローチすべてを十分に理解した上で比較評価することはできないだろう(←えーっ)。
- CCMの中心的概念は妥当性への脅威を評価することだが、定量的評価の方法は提供してくれない。
- RCMでは「強い無視可能性」という想定が重要だが、RCMの内部ではそれを検証できない。また、良い観察研究のデザインとはどんなデザインかという点について十分な注意を払っていない。
- PCMでは、正しいDAGをどうやってつくるのかがわからない。また実践での成功事例が少ない。
...とかなんとか。途中で力尽きて、流し読みになってしまった。
哲学的側面のところでのコメントが面白かった:
皮肉なことに、この「我々は常に誤りうる」という感覚こそが、おそらくもっとも理論から実践へと移しにくい特徴なのである。いま準実験デザインの活用を声高に宣言している研究者の多くに、Campbellは欠陥を見出したであろう。傾向スコア分析を用いている研究者の多くは、「強い無視可能性」などの諸想定があてはまっているかどうかにあまり注意を向けない。因果推論を正当化する根拠としてPCMを引き合いに出しながら、モデルがもっともらしいことが大事だという点には触れない、という人はさらに多いだろう。かつてCampbell(1994)はこう言った:「私の方法論的勧告は、それを引用する人はあまりに多く、それに従う人はあまりに少なかった」
うわあ、あっちこっち痛い...耳とか胸とか...
読了:Shadish & Sullivan (2012) Cambell vs. Rubin vs. Pearl, 統計的因果推論の頂上決戦
2012年8月10日 (金)
Scrutari, M. (2010) Learning Bayesian Network with the bnlearn R Package. Journal of Statistical Software, 35(3).
Hojsgaard, S. (2012) Graphical Independence Networks with the gRain Package for R. Journal of Statistical Software, 46(10).
Rのベイジアン・ネットワーク用パッケージの解説。仕事の都合でめくった。
前者はbnlearn, 後者はgRainの解説。ほかにdealというのも有名らしいが、良い解説がみあたらなかった。どちらもきちんと読んでないけど、整理の都合上、読了にしておく。
ぱらぱらめくった感じでは、構造学習の局面ではbnlearnのほうが便利そうだし、手法をいっぱい搭載してて、楽しそうだ。Pearl流のICアルゴリズムしかないのかと思ったら、スコア法もできるらしい(山登り法)。いっぽう、できあがったモデルを使って確率推論する局面では、gRainのほうが便利そう。bnlearnのほうは、ネットワークの一部のノードに証拠をセットして他のノードの確率を推論する方法がよくわからなかった。ひょっとして、条件つき確率表から手計算で出せってことかしらん?
たまたまHorjgaard, Edwards, Lauritzen "Graphical Models with R"という本を買ったばかりだったのだが、第一著者は上記論文の著者でgRainの開発者であった。本のほうを読めばよかったかも。さらに第二著者は、私が気に入っている MIM というソフトの開発者であった。バージョンアップがストップしていると思ったら...
読了:Scrutari(2010) bnlearnパッケージ; Hojsgaard(2012) gRainパッケージ
2012年7月10日 (火)
Marcoulides, G.A., Saunders, C. (2006) PLS: A silver bullet? MIS Quarterly, 20(2), iii-ix.
MIS Quarterly (MISはmanagement information systemの略) という雑誌にはときどきデータ解析の論文が載っているようで、特にPLSモデリングに関する論文を目にすることが多いような気がする。この文章は、2006年にエディタのMarcoulidesさん(SEMの有名な研究者だと思う)が巻頭コメントとして載せたもので、8頁を費やしつつも主旨は非常にシンプル。いわく... たとえばFalk&Miller(1992)の入門書には、PLSではサンプルサイズがそんなに重要でないなどと書いてあり、こういう意見を真に受けた投稿が最近増えていて困っている。審査で潰しているが追いつかない。「我々がこのエディトリアルを書いているのは、情報科学コミュニテイにおいてみられる、サンプルサイズが小さいときでもPLSなら使えるという誤った信念を打倒するためである。」はっはっは。
PLSだろうがなんだろうがサンプルサイズは大事なんだよ、各自モンテカルロ・シミュレーションで検定力を調べろよ、という仰せなのだが、その模範例として実演しておられるのが、2因子CFAの因子間相関の検定力という例。算出に使っているのはmplusである。思わず「節子、それPLSとちゃう、普通のSEMや」と呟いた。
研究者へのガイドラインとして、著者らは以下の点を挙げている。
- 現時点での理論的知識のすべてと整合するモデルを提案し、その理論を検証するためにデータを集めなさい。(→言うは易いが行うは難い、ですね...)
- ちゃんとデータをスクリーニングしなさい。
- モデルに出てくるすべての変数についてその計量心理的特性を検討しなさい。(→いかにも著者が云いそうなことだが、この分野の人にとっては耳が痛い指摘なのかも)
- モデルのなかで検討しているすべての変数の間で、関係性と効果の強さを調べなさい。(→たとえば因子間相関を調べているとき、因子の測定がプアだったら大きなサンプルが必要になる、というような話)
- ちゃんと信頼区間を求めなさい。
- 検定力を調べて報告しなさい。
読了: Marcoulides, & Saunders (2006) PLSは銀の弾丸ではない
2012年7月 2日 (月)
Greenland, S. (1989) Modeling and variable selection in epidemiologic analysis. American Journal of Public Health, 79(3), 340-349.
回帰モデリング(ロジスティック回帰とかCox回帰とかも含む)における諸注意事項をまとめたコメンタリー。重回帰の変数選択をクラシカルかつスマートにやることが鍵になるような仕事を抱えていて、面倒な作業の山の前でだんだん士気が落ちてきたので、気分転換のつもりで読んだのだけれど、これがまた面倒な内容で、ますます士気が落ちた。なんでこんな古いのを読まねばならんのかとも思うが、ステップワイズ変数選択がなぜ悪いかというような「枯れた」話題になると、新しい文献にはかえって説明が見つからないのである。
変数選択のところで面白かったのは、変数の有意性に基づくステップワイズ選択と、Change-in-esimate法でのステップワイズ選択を比較しているところ。後者は、独立変数のなかに注目している奴があって(これを投入することは確定している)、その係数が変わるかどうかで他の変数(共変量)の投入の是非を判断するやりかた。そういうやり方があることは知っていたが、伝統的な変数選択法と比較しようという発想がなかった(まるきり違う話題だと思ってた)。思うに、疫学では独立変数がリスク要因への曝露変数と共変量とにアプリオリに分かれていて、「曝露の効果を正しく推定するためにどうやって共変量を選択するか」という点だけが問題になるから、この二つの手法は同じ目的を持つことになるのだろう。機械的な変数選択そのものが良くないという話を別にすれば、Change-in-esimate法のほうが優れている由。いまちょっと調べてみたら、SASのproc regやproc glmselectではできないようだが、誰かがつくったマクロがあるらしい。Rではどうだかよくわかんなかった。
読了:Greenland (1989) 疫学における回帰モデルと変数選択
2012年6月12日 (火)
Curran, P.J., Bauer, D.J. (2007) Building path diagrams for multilevel models. Psychological Methods, 12(3), 283-297.
ここんとこちょっとバタバタしていたもので,気分転換に,積んである資料の山のなかからなるべくどうでもよさそうな奴を選んで手に取った。
マルチレベル・モデル(multilevel model)をパス図で描く方法を提案する論文。いったいどうやって描けばいいんだろうかと,前から気になっていたのである。Muthenさんたちは,ランダム係数をパスの上の黒丸で描いたり,階層ごとにパス図を書いて点線で区切ったりしているけど,ああいうの,他の人が描いているのをみたことがないような気がする。
このような,いっちゃなんだがどうでもいいような話についても,さすがに著者らはちゃあんとレビューしていて,
- Bauer(2003), Curran(2003), Mehta&Neale(2005): ふつうSEMの描き方で無理矢理描いている。でも直観的にわかりにくい。たとえば,ランダム効果は因子負荷が『定義』変数と呼ばれる観察変数によって定義されているような潜在変数としてあらわされている。他の観察変数は箱であらわされてるし,他の潜在変数はランダム効果でない。(←おまえはいったい何をいっているんだ、と思ったが、Mehta&Neale(2005)の図を見たら著者の言っている意味がわかった。図を言葉で言い表すのはムズカシイ...)
- McArdle&Hamagami(1996): 多群SEMの描き方で描いている。ファントム潜在変数を使わないといけないので,やっぱりわかりにくい。
- McDonalds(1994), Muthen&Muthen(2003), Muthen&Satorra(1989), Skrondal&Rabe-Hesketh(2005): 独自システムを提案。しかし,一番典型的なマルチレベルモデル(ランダム係数で潜在変数がない)を描くのにあまり使われていない。そういうモデルのためには大げさだし,方程式をそのまま図に翻訳していないからであろう。
というわけで、著者の提案は以下の通り。基本的にSEMのパス図の描き方と同じなのだが、次の点が違う:
- 円は潜在変数じゃなくてランダム係数をあらわす。円は必ず片矢印の上に重ねて描く。
- 三角形の内側に 1 と書いて切片をあらわす。この1に添え字がついていたらレベルをあらわす。たとえば,1に添え字2がついていたらレベル2の切片。
- 箱の内側の変数名が,ふつうのフォントだったら中心化なし,太字だったら群平均中心化,イタリックだったら全平均中心化。
図の例をみてみると、円が潜在変数ではないというのは意外に違和感がないが(円は必ず線に重なっているので、見まちがえる心配はない)、結局レベルを添え字で表しているところがわかりにくい...方程式との整合性を重んじると、こうなるのは仕方ないんだろうけど。
事例がいくつか紹介されていたんだけど、睡眠不足のせいもあり、数行ごとに意識が遠のくような感じで、結局全部流し読み。まあ、しょうがないや。次に行こう。
読了:Curran&Bauer(2007) マルチレベル・モデルをパス図で描く方法
2012年5月20日 (日)
Biondi-Zoccai, G., et al. (2011) Are propensity scores really superior to standard multivariable analysis? Contemporary Clinical Trials, 32, 731-740.
「傾向スコアが標準的な多変量解析よりも優れているってホントですか?」。いやあ,魅力的な題名をつけるのって大事だなあ。
医療系の論文を読んでいるときに時々面食らうのだけれど、かの世界にはどうやら「統計的手法,それは要因の因果的効果の定量的推定のための手法だ,ほかになにがあろうか」という暗黙の前提があるようで、この論文も、題名には書いてないけど、要するに準実験デザインにおいて共変量を事後的・統計的に調整するための諸手法のレビューである。掲載誌の性質がよくわからなかったのだけど,どちらかといえば統計ユーザ向けの啓蒙的概観であった。仕事の都合で取り寄せて読了。
標準的な多変量解析ってなんのことよ、という疑問がたちまち湧くが、まあ有り体にいえばそれはロジスティック回帰とCox回帰のことである。もっとも,著者はわざわざ以下の手法を例示していて,レベルが揃っていないので気持ち悪いのだが、臨床研究でどのくらい使われているかというコメントが面白いのでメモ。
- Bayesian methods ... いきなりなんのことかという感じだが、「単純なモデルから複雑なモデルに至るまでの複数のパラメータを、MCMCで事後確率分布を生成して評価する手法」と書いているから、まあなんというか、モデルのパラメータのベイズ流推定というような漠とした意味合いで書いておられるのであろう。occasionally used とのこと。
- Bootstrap ... occasionally used. (コレ、アルファベット順であることに、いま気が付いた...)
- CART ... rarely used.
- Cox比例ハザードモデル ... frequently used.
- 判別分析 ... rarely used.
- 正確法(exact methods) ... rarely used.
- 道具変数分析 ... 計量経済学なんかで良く出てくる IVのことですね。rarely used.
- ロジスティック回帰 ... frequently used.
- マッチング ... occasionally used.
- 混合効果分析 ... 「通常、特定のリンク関数を持つ一般化回帰モデルとともに用いられる」と書いているから、階層回帰モデルが念頭にあるのだと思う。occasionally used.
- 傾向スコア ... frequently used.
- 層別 (stratification) ... rarely used.
へえー。傾向スコアが良くつかわれているのと、SEMやIVが使われていないのが面白いと思った。前に仕事の関係で、朝から晩まで図書館にこもってリハビリテーション関連の日本語論文をめくりまくったことがあるのだけど、そのときの印象では、共変量調整の手法としてはマッチング、層別、ロジスティック回帰、Cox回帰の順にfrequently usedで、あとはみなrarelyないしneverという感じだった。もっとも10年くらい前の話だけど(嗚呼...)。
で,前半はロジスティック回帰・Cox回帰の注意点(多重共線性の話とか,変数選択の話とか,比例ハザード性の話とか),後半は傾向スコア調整の注意点。傾向スコア算出のためのモデルの適合を調べるのはHosmer-Lemeshow検定,判別能を調べるのはc-統計量を使うのが一般的だが,これには批判もある由(Weitzan, et al., 2005, Pharmacoepidemiol Drug Saf.; とはいえ著者らはこの研究に対して否定的)。
(※私のような哀れなユーザがなにかの拍子にこのブログを見るかも知れないので,ご参考までに書き留めておくと,c-統計量というのはですね,ROC曲線の下面積のことらしいです。同じことを別の名前で呼ぶのはやめてほしいですよね,まったく)
いざ傾向スコアを求めたとして,それを使った共変量調整の仕方にもいろいろあるが,代表的手法であるマッチングについて著者らは否定的な書き方をしているて,しかしじゃあなにがいいかという話には触れていなかった。きっと山ほど議論があるのだろう。
肝心の「どっちが良いか」という問題については,Cepeda et al.(2003, Am. J. Epidemiol.)というシミュレーション研究に全面的に依拠している。いわく,事象生起数が共変量の数の8~10倍以下のときは傾向スコアが有利になり,もっと多い場合にはロジスティック回帰やCox回帰が有利になる由。ううむ,シミュレーションの詳細がわかんないので気持ち悪い。元の論文を読んだ方がよさそうだ。
えーと,それから,Gelman-Hill本のChap.2をさきほど読了。いやはや,くどい!! どこまで読めるか,ますます自信がなくなってきた。
読了: Biondi-Zoccaqi, G., et al. (2011) 傾向スコア vs. その他大勢
2012年5月18日 (金)
Sekohn, J.S. (2011) Multivariate and propensity score matching software with automated balance optimization: The matching package for R. Journal of Statistical Software, 42(7).
RのMatchingパッケージの解説。仕事の都合で読んだ。
ちょっと誤解していたのだが,このパッケージはあくまでマッチングのための機能を提供しているのであって,たとえば共変量の調整のために傾向スコアでマッチングするとして,傾向スコアそのものの算出をやってくれるわけではない。
傾向スコアやマハラノビス距離をつかったマッチングだけではなく,genetic matchingという機能も提供している由。使う予定がないので読み飛ばしちゃったけど。
読了:Sekhon(2011) RのMatchingパッケージ
2012年5月17日 (木)
星野・岡田(2006) 傾向スコアを用いた共変量調整による因果効果の推定と臨床医学・疫学・薬学・公衆衛生分野での応用について. 保健医療科学, 55.
仕事の都合で読んだ。たぶん再読だと思う。わかりやすい名解説。
それから、BMJの論文と, Social Indicaters Res.の論文。勤務先の仕事と近すぎて、ちょっとここには書きにくい。そうだ、それからGelman&Hill のChap.1を読んだっけ。全25章、気力が続くかどうか怪しいところだ。
2012年5月14日 (月)
Baltas, G., & Doyle, P. (2001) Random utility models in marketing research: A survey. Journal of Business Research, 51, 115-125.
離散選択のランダム効用モデルについてざざざーっと概観する論文。長く積読リストに入っていたのを、ようやく読了。
ここでいうランダム効用モデルというのは、てっきり属性の部分効用が消費者間で異なるような離散選択モデルのことを云っているのだと思ったのだが(だって、回帰分析におけるランダム係数モデルってのはそういうのじゃないですか)、そうじゃなくて、選択肢の全体効用に確率的な項が入っているモデルはなんであれランダム効用モデルなのであった。
著者いわく... そもそも、選択モデルの誤差項がIID(独立に同一の確率分布に従うこと)でなくなる理由は、おおきく3つある: (a)観察されていない製品属性, (b)観察されていないtaste heterogeneity(個人間ないし個人内で)、(c)個人内ダイナミクス。この3つを区別することが大事である。
そんなこんなで、著者らはランダム効用モデルを次の4つの観点で分類する。
- (a)製品の観察されていない異質性の扱い方、
- (b)tasteにおける観察されていない個人内異質性の扱い方、
- (c)個人内ダイナミクスの扱い方、
- (d)選択集合の異質性の扱い方。
(a)に対する対処をみると、ランダム効用モデルはIIA型モデルと非IIA型モデルにわけることができる。(a-1)前者は事実上、多項ロジット(MNL)モデルのこと。後者としては、まず一般化極値(GEV)モデル。そのなかで標準的で使いやすいのは(a-2)入れ子型ロジット(NMNL)モデルだが、選択肢の階層をアプリオリに与えなければならない。(a-3)分散不均一極値(HEV)モデルは製品間の誤差分散・共分散を製品間で変えることができるモデルだが、あんまり使われていない。いっぽう、もっとintellectually appealingなのは(a-4)多項プロビット(MNP)モデルなのだが、あいにく計算が大変。
(b)に対する対処には、観察されている属性についてのtasteにおける異質性への対処という面と、選択肢そのものへのtasteにおける異質性への対処という面がある。つまり、対象者 i の選択肢 j の効用をV_{ij}, 共変量を X_{ij} として、V_{ij} = \alpha_j + X_{ij} \beta + \epsilon_{ij} と書いたとき、\betaが人によって違うかもしれないという話と、\alpha_j が人によって違うかもしれないという話があるわけだ。さて対処法としては、
- (b-1)説明変数として個人特性や購買記録を入れてしまうやりかた、
- (b-2)潜在クラスモデルなどを使ってセグメントに分けちゃうやりかた、
- (b-3)個人ごとに係数を固定効果として推定するやりかた、
- (b-4)個人ごとに係数をランダム効果として推定するやりかた、
にわけられる。
個人の係数を固定効果として推定する方法には3つある。
- (b-3-1)正面から個人ごとに推定する。もちろん無理がありすぎる。
- (b-3-2)conditional MLアプローチ。...恥ずかしながら、このくだりは意味がよくわからなかった。\alpha_{ij}が決まれば\beta_j が決まる、というような仮定を置くのだろうか。Chamberlain(1980, Rev. Econ. Stud.), Jones & Landwehr(1988, Market. Sci.)というのが挙げられている。
- (b-3-3)ベイジアンアプローチ。そうか、個人レベルの係数をリッチな購買記録でベイズ更新していくとすると、これは固定効果モデルに分類されるのか。
個人の係数をランダム効果として推定する方法は2つに分けられる。
- (b-4-1)係数の連続分布を仮定するモデル。分布を正しく仮定することが重要になる。
- (b-4-2)係数の離散確率分布を仮定するモデル。潜在クラスモデルと似ているが、解釈が異なる。潜在クラスモデルでは少数の等質な集団を仮定しているわけだが、ここでは連続分布を離散分布で近似しているに過ぎない。ふーん。
(c)の問題はさらに次の2つに分けられる。
- (c-1)状態依存性によって生じる個人内異質性。対処のためには、過去の選択をダミー変数としていれたり、過去の選択記録を要約する変数をいれたりすることが多い。
- (c-2)選好の短期的な慣性によって生じる個人内異質性。経済学ではこういうのをhabit persistenceという由。
... このくだりもよくわからなかったのだが、属性の部分効用がなにかの要因によって時間的に変化しちゃうようなホンモノの個人内異質性のモデル化は、この2つとはまた別の問題だ、という理解であっているだろうか。Roy, Chintagunta, Haldar(1996, Market. Sci.)をみよとのこと。
(d)について。選択集合の異質性の問題をランダム効用モデルに統合すべきかどうかは意見が分かれるところで、最近のトレンドは、選択集合を観察不能な潜在変数とみて確率的に定式化するアプローチである由。
先行研究例の列挙を主眼においた、ざざざーっとした書き方だったので、ついついざざざーっと読んじゃいましたが、頭の整理になりました。
読了:Baltas & Doyle (2001) ランダム効果モデルレビュー
2012年5月 5日 (土)
McArdle, J.J. (1984) On the madness in his method: R. B. Cattell's contributions to structural equation modeling. Multivariate Behavioral Research, 19, 245-267.
「彼は50年以上も前にSEMのテクニックを使っていたのだ!」というわけで,歴史的心理学者Raymond B. Cattellの因子分析についての膨大な業績を,現代のSEMの観点から振り返る,という酔狂な論文。
先日,キャッテルのData boxという概念に興味を引かれて資料を検索していて,つい魔が差して国会図書館関西館に複写依頼を出してしまったもの。いつもながら丁寧な複写で,ほんとに頭が下がります。そのお気遣いを無にしないためにも,はい,ちゃんと読みますです。
題名は一体どういう意味だろうと不思議に思ったのだが,ハムレットのなかでポローニアスが"Though this be madness, yet there is method in't"と独白する場面があって(手元の小田島訳では「気ちがいのことばとはいえ,筋がとおっておるわい」),これに由来する"There's method in his madness"という慣用句があって(ランダムハウス英語辞典では「狂ってはいるが言うことの筋道は通っている」),それに由来しているらしい。
著者はキャッテルの考え方に潜む尽きせぬ革新性のことをmadnessと呼んでいる(もちろん誉めているのである)。
キャッテルの因子分析アプローチと現代のSEMの考え方を,モデルのSpecification, Estimation, Comparison, Substance(理論的含意の導出)の4段階に分けて比較している。文章があまりに文学的なので参った。著者は成長曲線モデルの研究で有名な人だと思うけど,なんというか,若気の至り,という感じの文章である。
知識不足もあって,内容をよく理解できたとはいえないんだけど,キャッテルは決して統計家ではなく,あらゆる場面において実質科学的推論をすごく重視していたのだ,ということが,なんとなくわかったような。というより,ここまでが統計的推論でここから実質科学的推論,というような線引き自体が,キャッテルさんにとっては意味をなさなかったのかもしれないなあ。
読了:McArdle(1984) R.B.キャッテル,狂気の筋道
2012年4月25日 (水)
Andrews, R.L. & Currim, I.S. (2003) A comparison of segment retention criteria for finite mixture logit models. Journal of Marketing Research, 40(2), 235-243.
データ分類手法のひとつである有限混合モデル(潜在クラスモデル)では、モデル適合度指標をつかってクラス数を推定できるが、その指標のパフォーマンスを比較いたしました、という論文。類似の研究はいくつもあると思うのだが、この論文では、店舗スキャナ・データに多項ロジット選択モデルをあてはめ、顧客の選好の異質性を有限混合モデルで説明する、という状況に焦点を当てている。すごく狭い話ではあるが、そういうモデルを組む人にとっては大事な問題だ。
比較する指標は次の7つ。モデルの対数尤度をL, パラメータ数をkとして、
- AIC = -2L + 2k。
- AIC3 = -2L + 3k。Bozdoganという人が提案している由。なんで3になるのか、理屈はさっぱりわからないが、とにかく有限混合モデルでは3になるのだそうです。
- CAIC = -2L + k[(log n)+1]。nはサンプルサイズ。
- ICOMPという指標。AICみたいなもんだが、対数尤度に対するペナルティを、パラメータ数ではなく推定されたフィッシャー情報行列で決めるらしい。なんだかよくわからんが、パラメータ数が多すぎるモデルだけではなく、パラメータ推定の分散が大きすぎるモデルにもペナルティが課せられるのだそうだ。これもBozdoganという人が提案している由。
- SchwarzのBIC。
- 妥当化用サンプルでの対数尤度(LOGLV)。これが最大になるまでセグメント数を増やしていく。
- NECという指標。クラス数SのモデルのエントロピーをE(S)、対数尤度をL(S)としたとき、E(S)/(L(S)-L(1))だそうだ。クラス間の分離が大きいときに大きくなる理屈である。これが最大になるまでセグメント数を増やしていく。
シミュレーションは... 予測子は2値変数2つ、連続変数1つ(プロモーションと価格のつもり)。要因は、真のクラス数(2,3)、世帯レベル係数(クラス内でガンマ分布に従う)の平均のクラス間の差(3水準)、世帯数(100,300)、世帯当たり購入数平均(5,10)、選択肢数(3,6)、誤差分散(2水準)、最小のクラスのサイズ(3水準)。各組み合わせについて3個のデータセットを生成し、正しいセグメント数を復元できたかどうかを調べる。
その結果、総じてAIC3が優れていた由。へええー。
この論文を読んでいてふと思い出したのだが、ずっと前にフジテレビ制作の「ウゴウゴルーガ」という子ども向け番組があった。もう何年もテレビを見ない生活なのだが、ああいう面白い番組はいまあるのかしらん。あの番組のなかで、洋式便器の中のウンチがこちらに向かって、低いくぐもった声で文脈とは無関係なうんちくを垂れ、「~は~らしいぞ」と言い終わるか終わらないかのうちにザバーッと水流に流されていく、という非常にシュールなショートアニメがあったと思う。あれのスマフォ・アプリをつくったらちょっと面白いかもしれない。設定で「マーケティングデータ解析」を選択し、画面上のウンチをタップすると、「購買ログに有限混合多項ロジット選択モデルを適用するときは、AICにパラメータ数を足した値が最小になるクラス数を選ぶといいらしいぞ」ザバーッ、なんてね。
読了:Andrews & Currim (2003) 有限混合多項ロジット選択モデルのクラス数推定にはAIC3がいいらしいぞ (ザバーッ)
Revelle, W. (2009) Personality structure and measurement: The contributions of Raymond Cattell. British Jounral of Psychology, 100, 253-257.
なんで心理学の論文など読んでいるのかさっぱりわからないが、なんとなく目を通したもの。
この雑誌の100巻(つまり創刊100年)の記念号で、心理学史上に残る偉大な論文(Watson, Bartlett, Piaget, Cattell, Gibson)を採録し解説を付す、という企画があった模様で、これはCattellの1946年の論文"Personality structure and measurement"の解説として、キャッテル先生の偉業を短く振り返る記事。先日たまたま三相データについてちょっと調べていて、実は50年代のキャッテルの研究にすでに詳細な議論があるのだと知り、へええ、ずいぶん古くから話なんだなあ、と感心してるときにみつけた。著者についてはよく知らないが、Ortonyと共著があり、Rのpsychパッケージの開発にも関わっているようだ。
なんでも、1946年のこの論文においてすでにキャッテルはpersons, test, occsionsの3相からなる"data box"という概念を打ち出しているのだそうだ。66年にはこれにbackgroundとobserversを追加して5相に増やしている。78年に至るまで先生は理論の修正を続け、用語もどんどん変えておられる由。やーめーてー。
読了: Revelle (2009) 嗚呼Cattellは偉かった
2012年4月23日 (月)
Andrews, R.L., Ainslie, A., & Currim, I.S. (2002) An empirical comparison of logit choice models with discrete versus continuous representations of heterogeneity. Journal of Marketing Research, 39(4), 479-487.
さっわやかなまでにテックニカルな論文。複雑な社会現象に正面から取り組むのも立派だけど、こういう話も気楽でよろしい。胸に一陣の風が吹き込むようだ。というか、どうでもいい話をテキトウな態度でフガフガと読むのは良い気晴らしになる。
えーと、この論文の掲載号に著者らはもう一本載せていて(Andrews, Ansari, & Currim, 2002)、メトリックなコンジョイント分析において有限混合モデルを使った場合と階層ベイズモデルを使った場合とを比較しているのだそうだ。個人パラメータの復元やホールドアウトの予測という観点からは、まあ似たようなもんである由。で、本論文はタイトルの通り、ロジット選択モデルについて同じことを調べます、という研究。今度はコンジョイント分析じゃなくて、ホーム・スキャン・パネル・データに選択モデルを当てはめる場合を想定してシミュレーションするわけだ。このバットで馬を殴り殺したから今度は鹿を殴り殺してみよう、というような話だ(←???)。いやー、いいなあー、この論文量産システム、すっばらしいなあー。
手続きの詳細はもう一本のほうの論文を読めとのことで、正確にはわからないのだが、推察するにこういうことだろう。次のような人工的な購買データをつくる。それは架空の(たとえば)400世帯の,世帯あたり(たとえば)15回の買い物データで,各世帯は各買い物において架空の5つのブランドのいずれかを購入する。各買い物において,それぞれのブランドは,価格,店内ディスプレイ有無,チラシ広告有無,の3つの値を持っている(ランダムに生成)。これら3つの変数の値と(重みは各データセットに対してランダムに付与),その世帯にとってのブランド部分効用の和によって,各ブランドの全体効用が決まり,選択も決まる。世帯は(たとえば)3つのクラスにわかれており,各クラスごとに,ブランド部分効用の分布が決まっている。というようなデータセットを,実験計画に従って生成しまくる。要因は,クラス数(1,2,3)、クラス間の分離の程度(2水準)、ブランドの部分効用の分布(正規分布,ガンマ分布)とその分散(2水準)、世帯数(75,200,400)、世帯当たり購買数(3,10,15)、誤差分散(2水準)。すべての組み合わせ(360)についてひとつづつデータセットをつくり,それに有限混合ロジットモデル(FM),ならびに階層ベイズ推定した混合ロジットモデル(HB)を当てはめる。ここでいうFMモデルとは、世帯パラメータの分散がクラス内で0であるモデルのことで(クラス数はBICとかで推測する)、つまりFMでは世帯間異質性を離散的に捉え、HBでは連続的に捉えていることになる。で、成績指標として、世帯パラメータのRMSE、モデルの適合度(対数尤度, BIC)、ホールドアウトでの対数尤度とブランド選択率予測値を求め、データセットごとの成績をANOVAで分析する。
結果は適当に飛ばし読みしてしまったが、ひとことでいえば、世帯当たり購入数3の条件ではHBはボロボロ。うーむ、消費者あたりのデータが少なくてもHB推定はできちゃうけど、あんましあてにならない、ってことですね。反省。いっぽう、購入数が増えればFMもHBも大差ない由。
論文末尾で著者らいわく、「分析者が消費者異質性を連続的に表現するモデルを好むか離散的に表現するモデルを好むかは、その人の意見と個人的好みの問題だが、主観的な議論と思索よりは実証的証拠のようが説得的だから、さらなる実証研究がなされるといいなあと思う」とのこと。ふーん。
読了: Andrews, Ainslie, & Currim (2002) 有限混合モデル vs. 階層ベイズモデル ~選択データ分析での対決~
2012年4月20日 (金)
Cartwright, N. (2011) A philosopher's view of the long road from RCTs to effectiveness. Lancet, 377, 1400-1401.
著者はイギリスの哲学者で、いま調べたら著書の邦訳はないようだけど、たしか有名な人だと思う。この人がある論文集に、"Predicting 'It will work for us': Way beyond statistics" というすごく面白そうなタイトルの論文を寄せていて、それを読み始めたのだが、数ページでさっぱりわけがわからなくなってしまった。単にあきらめるだけだと気分が悪いので、代わりにこの人がランセットに寄せた短いコメントを読んでお茶を濁す次第。ところが、医学者向けに平易に書かれたこの文章でさえ難しくて、長々とメモをとってしまった。
因果的主張に際してランダム化統制試験(RCTs)が優れているといわれる、その理由はなにか? 根本的な理由が二つある。(1)理想的なRCTsは因果的な結論の決め手になる[clinch] ことができるから。(2)理想的なRCTsはself-validatingだから。
まずひとつめについて:
手法のなかには、結論に対して単に証拠を提供する[vouch for]だけのものもある。ある知見が仮説に証拠を提供しているとみなされるためにはなにが必要かを正確に述べるのは難しいが[althogh it is problematic to say exactly what it takes for a finding to vouch for a hypothesis]、一般的にいえば、少なくとも、その仮説なしにはその知見は驚くべきものであり、その仮説の下ではその仮説は驚くべきものではない、ということが必要だろう。また手法のなかには、[証拠を提供するだけでなく、] 理想的には[in the ideal] その結論の決め手になる [clinch] ものもある。つまり、もしその手法を定義している諸想定が満たされているならば、肯定的な結果がその結論を演繹的に含意するような手法である。理想的なRCT(すなわち、必要な前提がすべて満たされているRCT)は、ひとつの決め手[a clincher]である。大まかにいえば、RCTの論理はある一般的な形而上的前提を想定している: 確率的依存性は因果的説明を要求する[calls for]という前提である(前提1)。実験デザインはもうひとつの前提を保証する働きをする: アウトカムに因果的に関連している、処理(そしてその下流にある諸効果)以外のすべての特徴が、処理群と統制群の間で同じ分布をしているという前提である(前提2)。そして、もしそのアウトカムが統制群よりも処理群においてよりprobableであるならば(前提3)、可能な唯一の説明は、処理群のなかの幾人かのメンバーにおいてその処理がアウトカムを引き起こした、という説明である。
EBMは、さまざまなvouching evidencesではなくclinchersに焦点をあてるという性質を持っている。おそらくはvouching evidenceを扱うためのチェックリストがないからだろう。しかし、clincherはRCTだけではない。ケース・コントロール研究のような非実験的データや確立した理論からの演繹もclincherになれる。RCTが他とちがうのは、2つめの特徴、つまりself-validatingであるという特徴である。
いかなる手法も、そこからの結論を担保[warrant]するためにあらかじめ満たす必要がある諸想定を持っている。[...] RCTのデザインには、形而上的想定[前提1のことであろう]は別にして、前提2と3を支持[support]してくれるもの(保証[guarantee]してくれるものではない)が組み込まれている[built right into]。処理の施行の監視、ブラインド化、無作為割付、などなどが前提2を支持し、観察された頻度から確率を推論するための技法(たとえば標本サイズが大きいこととか)が前提3を支持する。このように、RCTsはself-validatingである。
self-validationは美徳ではあるが、しかし必須ではない。RCT以外の研究デザインであっても、十分な情報があれば因果的結論を支持できる。
さて、ここからが本題である。ここまでの話はすべて、「処理群のなかの幾人かのメンバーにおいてその処理がアウトカムを引き起こした」という因果的主張、つまり"it-works-somewhere"という主張を支持することについての話だ。いっぽう我々が求めているのは、処理が我々の状況において望ましいアウトカムを引き起こすという因果的主張、つまり"it-will-work-for-us"という主張を支持することだ。著者はこの主張を"efficacy claim"と呼んでいる。
it-works-somewhereからit-will-work-for-usを引き出すために必要なのは、「その処理がそのアウトカムをreliably promoteしている」という主張である。ここで"reliably promote"というのは、大まかにいって、「さまざまな環境を通じて、処理が存在しないときよりも存在するときのほうがそのアウトカムがたくさん生じる」ということである。著者はこの主張を"capacity claim"と呼んでいる。
ところが問題は、"it-works-somewhere"と"reliably promote"(capacity claim)だけから"it-will-work-for-us"(effecacy claim)を引き出せないという点である。なぜなら、我々はさらに、我々の状況が必要なhelping factorsをすべて含んでいるということを知っていないといけないし、逆方向の圧倒的な原因がないということを知っていないといけない。さらに、capacity claimを担保するのは難しいし、なにが担保になるかを述べてくれる方法論もない。capacity claimを支持してくれるのは、結局は、処理がアウトカムを生み出す理由についての一般的な理解である。
というわけで、RCTが支持してくれるのは"it-works-somewhere"であって、そこから"it-will-work-for-us"を引き出すためには、capacity claimを理論的に担保するというmessyな問題に取り組まなければならないということを心に刻みなさい。云々。
やれやれ。苦労して読んだわりには、いまいち話のポイントがつかめなかった。この文章を読む限り、著者のいうcapacity claimというのはいわゆる外的妥当性のことだろうと思うのだが、先に読みかけて挫折した論文のabstractには、'external validty' is the wrong way to characterize the problem なあんて書いてある。なんでだろう。
読了:Cartwright (2011) 「こうなってる」から「こうするといいよ」への長い道
2012年4月 9日 (月)
von Davier, M., Gonzalez, E., & Mislevy, R.J. (2009) What are plausible values and why are they useful? IERI Monograph, 2, 9-36.
たまには目の前の仕事と無関係な話を読みたくなり目を通した。 いますぐに関係ないとはいえ、このさき役に立ちそうな気もするし。
PISAやTIMSSといった大規模教育測定の話のなかでときどき見かける、plausible value (PV)という概念についての解説。なんて訳せばいいのかわからないが、いまwebで調べたら「推算値」と訳している人がいた。
IERIというのはアメリカのETSと、アムステルダムのIEA (Int. assoc. for the Evaluation of Educational Achievement)というところが共同でやってる組織らしい。第1, 第2著者はETSの人。三人目のMislevyという人がこの概念の主唱者だと思う。
すごくわかりやすい説明であった。PVってのは要するに、項目反応理論でいうところの潜在特性 Θ の事後分布を個人ごとに推定し、そこからランダム・ドローした値のことらしい。個人の分析ではなく集団特性の分析に用いるもので、ランダム・ドローした値の平均や分散は、Θの点推定値の平均や分散とはちがって不偏推定量となる。ふつうはこれを5セット繰り返し集計値を併合して精度を上げる由。なお、複数回ランダム・ドローした値の個人別平均値を使うのは誤り。
なあんだ、こないだ調べた潜在クラスモデルにおけるpseudo-class drawとそっくりな話ではないか。もっとエキゾチックな話題かと思ってた、意外なり。
いまやってる市場調査関連の仕事に当てはめて考えると、たとえばwebでのサーベイ調査で、ある事柄への態度をあれやこれや調べて集団レベルで比較したい、ほんとは100項目くらい調べて因子分析でもしたいんだけど、回答負荷の観点から泣く泣く項目を減らしましょう、などという場合がある。別に個々人に全部答えてもらう必要はないじゃん、PISAみたいに項目をブロックにわけてブックレットをつくってもいいし、なんならランダムに項目を出したっていいじゃん... と思うのだが、これがなかなか受け入れてもらえない。まあ、全国学力テストでさえ全員に同じ項目を与えてしまうお国柄だから、しょうがないかなと思っていたのだが、ひょっとしたら、全項目を聴取しなくても個々人の因子得点推定が可能ですと説得するより、個々人は無理だがPVってのがありますよと説明したほうが、ピンときたりするかしらん? うーむ、そんなわけないか。この論文とは全然関係ない話だな。
読了: von Davier, Gonzalez, & Mislevy (2009) Plausible values とはなんぞや
2012年4月 3日 (火)
Johnston, B. & Schwartz, C. (1977) The analysis of an unbalanced paired comparison experiment by multiple regression. Journal of the Royal Statistical Society, Series C (Applied Statistics), 26(2), 136-142.
いわゆるシェッフェの一対比較法では,t 個の刺激から2つを取り出す t(t-1) 個のペアに対して被験者を割り当てるが,解説書の計算例では決まってきれいに均等割り当てされている。unbalancedな場合についての解説はないものかと,あれこれ探してみたものの,少なくとも日本語では全然見あたらなかった。実務場面では毎度そうそうきれいには割り付けられないだろうから,これはどう考えてもFAQだろうと思うのだが。私の探し方が悪いのかしらん。
仕方がないので,解説書の手順に頼らずに自力でどうにかしようと覚悟し,その練習のために読んだ。unbalancedだったり妙な欠損があったりする,やたらに複雑なデザインの一対比較課題を挙げ,重回帰でパラメータ推定してみせるという,チュートリアル的な論文。
記号が死ぬほどまどろっこしく,嫌々メモを取りながら読んだ。
対象者 k が刺激 i を r番目 (r={1,2}) にみたときの評価を
X_{irk} = \mu + \tau_i + \phi_r + \alpha_{ir} + \psi_{irk}
とする。\tauは刺激の効果、\phiは提示順序の効果、\alphaは刺激と提示順序の交互作用,\psiは誤差。刺激 i と j の一対比較評価 Y_{ijk} は X_{i1k} - X{j2k} 、すなわち
Y_{ijk} = (\tau_i - \tau_j) + (\phi_1 - \phi_2) + (\alpha_{i1} - \alpha_{j2}) + (\psi_{i1k} - \psi_{j2k})
である。\phi_1 - \phi_2を \phi, \alpha_{i1} - \alpha_{j2}を (\tau\phi)_{ij},\psi_{i1k} - \psi_{j2k}を \psi_{k(ij)}と書く (あああ...キタナイ...)。さらに刺激の組み合わせの効果 \gamma_{ij}を追加する。結局
Y_{ijk} = \phi + (\tau_i - \tau_j) + \gamma_{ij} + (\tau\phi)_{ij} + \psi_{k(ij)} (ただし i \neq j )
である。この式に以下の制約がかかる。
- \sum tau_i = 0。
- \sum_i \gamma_{ij} = 0。
- \gamma_{ij} = - \gamma_{ji}。組み合わせの効果だから。
- (\tau\phi)_{ij} = (\tau\phi)_{ji}。順序効果だから。
さて,深呼吸して,式の右辺をダミー変数W_0, W_1, ...の線形和に書き下す。刺激数が3の場合,
- \phi は \phi W_0 と書き換える。W_0は常に1。
- (\tau_i - \tau_j) は \tau_1 W_1 + \tau_2 W_2 + \tau_3 W_3 と書き換えることができる。ここでW_1, W_2, W_3は{-1, 0, 1}の3値をとるダミー変数で,たとえば刺激(1,2)の比較の場合はW_1 = 1, W_2 = -1 となる。制約1より,\tau_3 = -(\tau_1+\tau_2) だから,これは\tau_1 (W_1-W_3) + \tau_2 (W_1 - W_3) とも書ける。結局,W_1-W_3と,W_1-W_3という2つのダミー変数を考えればいいわけだ。これをW'_1, W'_2 とする。
- \gamma_{ij} は \gamma_{12} W_4 + \gamma_{21} W_5 + ... + \gamma_{32} W9。制約2と3を合わせると,\gamma_{12}さえ決まっちゃえば,\gamma_{21} = -\gamma_{12}, \gamma_{13} = -\gamma_{12}という風に,残り全部が決まってしまう。結局,\gamma_{12} (W_4 - W_5 - W_6 + W_7 + W_8 - W_9) となり,ある1つのダミー変数だけについて考えればよいことになる。これを W'_3とする。
- (\tau\phi)_{ij} は (\tau\phi)_{12} W_{10} + ... + (\tau\phi)_{32} W_{15}。めんどくさいから省略するが,結局 W_{10}+W_{11}-W_{12}-W_{13} と -W_{12}-W_{13}+W_{14}+W_{15} という2つのダミー変数について考えればよいことになる。これをW'_4, W'_5とする。
というわけで,このモデルは結局のところW'_1, W'_2, ..., W'_5 という5つの謎のダミー変数の重回帰として推定できるわけだ。こうすれば,unbalancedな場合でも容易に推定できる。
そのほか,データに構造的欠損があった場合はどうするか (交絡しちゃった交互作用項を外しなさい),被験者内要因や被験者間要因を追加するにはどうするか(ややこしくなるけど頑張りなさい),といった例が紹介されている。根気が尽きて飛ばし読み..
なんで1977年に書かれたあまり有名でない論文なんぞをネチョネチョと読んでいるのかと,どんよりした気分になってきたのだが,ま,ダミー変数の作り方がわかったのでよしとしよう。
それにしても,以前から疑問に思っていることがあって... 官能検査関係の本を読んでいると,シェッフェの一対比較法と並んで,芳賀の変法とか浦の変法とか中屋の変法といったアレンジが載っている。あれ,別に国際的に有名な手法というわけではないと思うが,どうなんだろう。諸外国ではどういう方法を使っているのだろうか。日本国内で日本ローカルな手法が広く使われているというのは,そのこと自体を悪いといってはいけないのだろうけど(数量化理論が好きな人とかが怒り出しそうだし),なにか取り残されているのではないかしらんと,ちょっと不安になる事態ではある。
読了:Johnston & Schwartz (1977) 不釣り合い型な一対比較実験データを重回帰で分析してみせよう
2012年3月26日 (月)
Vermunt, J.K. (2010) Latent class modeling with covariates: Two improved three-step approaches. Political Analysis. 18(4), 450-469.
先日読んだ Clark & Muthen (2009)に引き続き、潜在クラスと共変量の関係を調べる方法について。こんどは Latent Gold 開発者のVermuntさんの論文。ここでthree-step approachesといっているのは、要するに「分類してから分析」作戦のことで、潜在クラスモデル構築、対象者の分類、共変量と所属先の関係を調べる、で計3ステップになる。Clarkらが比較していた5つの方法のうち、pseudo-class drawを除く4つが検討範囲で、そのかわり所属確率でウェイティングする手法の改善案が2つ提案されている。
第一の改善案は... Clarkらは引用していなかったが(なぜだろうか)、もともと Bolck, Croon, & Hagenaars(2004, Political Analysis) の方法というのがある。潜在クラスをX, 指標のベクトルをY, LCAモデルによって推定された所属クラスをWとする。対象者 i のカテゴリカル共変量群のベクトルが Z_i であるとき、彼がクラス s に分類される確率は、「Z_i の下で彼がクラス t に属する確率」と「クラス t に属する人が Y を示す確率」と「Yを示した人が s に分類される確率」の積の和、つまり
P(W = s | Z_i) = \sum_t \sum_Y P(X=t | Z_i) P(Y | X=t) P(W=s | Y)
これを整理すると
P(W = s | Z_i) = \sum_t P(X=t | Z_i) P(W=s | X=t)
後ろのほうは誤判別率で、LCAではふつう所属確率の経験分布から推定する。要するに、P(W=s | Z_i) は P(X=t | Z_i)を誤判別率P(W=s | X=t)を重みにして結合したものになっている。いま、左辺のP(W=s | Z_i), 右辺のP(X = t | Z_i), 誤判別率 P(W=s | X=t) がそれぞれ行列 E, A, Dの要素であるとすると
E = A D
Dに逆行列がある限り
A = E D^{-1}
そこで、共変量ベクトルが取りうる値のパターンを行, Wを列にとったクロス表を N とし(ここにEの情報がはいっている)、N* = N D^{-1} をAの推定値としましょう... というのがBolckらのアイデア。尤度関数に書き換えると、ウェイティングしたロジスティック回帰になっているんだそうだ(数式を追いかけるのが面倒になってきた...)。で、Vermuntさんが提案しているのは、この方法をちょっと変えて、共変量が量的である場合にも対応できるようにしたもの。
第二の改善案は ... 上記のように、
P(W = s | Z_i) = \sum_t P(X=t | Z_i) P(W=s | X=t)
である。いっぽう、思い返せば共変量つきLCAモデルは
P(Y_i | Z_i) = \sum_t P(X=t | Z_i) P(Y_i | X=t)
だ。つまり前者は、指標がひとつしかなくて(Wのこと)、かつ誤判別率が既知であるようなLCAモデルとして解くことができる、というアイデア。なるほど。ステップ1とステップ3で別のLCAモデルを推定するわけだ。
どちらにしても、誤判別率P(W=s | X=t) を経験分布から推定しているせいで、標準誤差は多少なりとも過小評価されるはずなのだが、シミュレーションによれば(適当に飛ばし読み)、どちらもBolckらの方法よりは良いのだそうな。ついでに実データへの適用例をLatent Goldのシンタクス付きで示している(こちらも飛ばし読み。すいません)。
私のような素人からみると、西海岸のMuthenさんたち(Mplus製造元)や東海岸のCollinsさんたち(proc lca製造元)の論文と、オランダのVermuntさんたち(Latent Gold製造元)の論文は、内容がとても近いことが多いように思えるのだが、相互引用はなぜか少ない。研究分野の違いだろうか。
Mplusで誤判別率既知のLCAをどう書けばいいのか、知りたいところだが... Muthen先生はきっと「pseudo-class drawにしとけ」と仰せだろうなあ。
読了:Vermunt (2010) 潜在クラスと他の変数との関係を調べる方法 (蘭学バージョン)
Royston, P. (1993) A pocket-calculator algorithm for the Shapiro-Francia test for non-normality: An application to medicine. Statistics in Medicine, 12, 181-184.
題名の通り、経験分布の正規性を検定する手法のひとつであるShapiro-FranciaのW'統計量を関数電卓レベルで簡単に計算する方法。しばらく前に仕事の都合で読んだ(というメモがさっき出てきた)。
Rのnortestパッケージの挙動について知りたくて、引用されていたこの文献に目を通したのだが、W'というのは要するに正規確率プロット上の相関の二乗だから、Excelさえ使えるなら実にどうでもいい話である。
読了:Royston (1993) 電卓でできる Shapiro-Francia 検定 (電卓でやりたいかどうかは別として)
2012年3月23日 (金)
Abdi, H. (2007) Partial least square regression. in Salkind, N. (ed.) Encyclopedia of Measurement and Statistics. Thousand Oaks, CA: Sage.
PLS回帰の理屈についてぼんやり考えごとをしていて、なにがなんだかわけがわからなくなってしまったので、頭を整理するために読んだ。
著者の説明を抜粋すると...
個体数を$I$, $K$個の従属変数の行列を $Y$, $J$個の独立変数の行列を$X$とする。まず
$X = T P'$
と分解する。ここで$T$の列は直交。$T$が得点行列、$P$が負荷行列である。で、
$\hat{Y} = T B C'$
とする。$B$は対角行列で、この対角成分を回帰ウェイトという。また、$C$を$Y$のウェイト行列という。
さて、上記を満たす$T$は無数にあるが、PLS回帰では、正規化されたベクトル$w, c$について、$t = X w, u=Y c$としたときの$t' u$が最大になるようにする。ここで$t$と$u$を第1潜在ベクトルという。で、$X, Y$のそれぞれから第1潜在ベクトルを取り除く。これを繰り返して、第2,3,...の潜在ベクトルを求めていく。
具体的なアルゴリズムは次の通り。ベクトル$t, p, c$を行列$T, P, C$に格納し、$b$を行列$B$の対角成分に格納する。$X$の平方和のうちこの潜在ベクトルで説明できているのが$p'p$であり、$Y$の平方和のうちこの潜在ベクトルで説明できているのが$b^2$である。以上を$E$が空になるまで繰り返す。
- $X, Y$を標準化し$E, F$とする。
- 乱数ベクトル$u$を用意し、
- Step 1. $E' u$を求め、これを分散1に基準化して$w$ とする。これが$X$のウェイト。
- Step 2. $E w$を求め、これを基準化して$t$とする。これが$X$の得点。
- Step 3. $F' t$を求め、これを基準化して$c$とする。これが$Y$のウェイト。
- Step 4. $u = Fc$を求める。これが$Y$の得点。これを$t$が収束するまで反復する。
- スカラー$b = t' u$、$X$の負荷$p = E't$を求める。
- $E - t p'$を新しい$E$に、$F - b t c'$を新しい$F$にする。
ここでは反復計算で説明されているけれど(NIPALSアルゴリズムという奴だろう)、ウェイト$w, c$を$X'Y$の特異値分解で説明することもできる。$w$はひとつめの左特異ベクトル、$c$はひとつめの右特異ベクトルのことだと思うのだが... 論文中の説明では左右が逆になっている。なんでだろう。
ちなみに、先日読んだMevik & Wehrens (2007)の説明はこうだ。
ベクトル$w, t, p, q$をそれぞれ行列$W, T, P, Q$に格納する。以上を繰り返す。
- $X, Y$を標準化し$E, F$とする(標準化しなくてもよい)。
- $X'Y$を特異値分解し、ひとつめの左特異ベクトルを$w$, ひとつめの右特異ベクトルを$q$とする。これで$E$と$F$をそれぞれ重みづける: $t=Ew, u=Fq$。これが$X$と$Y$の得点。ここで$t, u$を分散1に基準化してもよい。
- $X$の負荷$p = E't$, $Y$の負荷$q =F't$を求める。
- $E - t p'$を新しい$E$に、$F - t q'$を新しい$F$にする。
記号の使い方が微妙に異なる。だいたいなんで$q$が二回出てくるんだ。頭が痛いよう。
ついでに調べたら、SAS 9.3 User's Guideでの説明はこんな感じ。
標準化ずみのデータ行列$X_0, Y_0$について、$X_0$の線形結合$t =X_0 w$を考える。ここで$t$を得点ベクトル、$w$をウェイトベクトルという。この$t$で$X_0, Y_0$を説明する回帰モデルを考える:
$\hat{X_0} = t p'$
$\hat{Y_0} = t c'$
ここでベクトル $p, c$をそれぞれ$X$の負荷、$Y$の負荷という。
$p'=(t't)^{-1} t' X_0$
$c'=(t't)^{-1}t' Y_0$
となる。
さて、$t$は次のようにして決める。反応のなんらかの線形結合$u = Y_0 q$に対し、共分散$t'u$が最大になるようにする。これは、$X$のウェイト$w$と、$Y$のウェイト$q$を、共分散行列$X'_0 Y_0$のひとつめの左特異ベクトルとひとつめの右特異ベクトルに比例させるということでもある。
SASのマニュアルは時として、素人を殺す気じゃないかというくらいに難しく書いてあるのだが、これは案外わかりやすいなあ。
自分なりに整理すると...$X, Y$を標準化済みデータ行列とする。$X$をXウェイトで線形結合してX得点, $Y$をXウェイトで線形結合してY得点をつくる。XウェイトとYウェイトは、$X$と$Y$の共分散行列の左特異値ベクトルと右特異値ベクトルで、そうするとX得点とY得点の共分散が最大になる。さて、X得点を説明変数、$X$を目的変数にした回帰式の係数がX負荷。X得点を説明変数、(Y得点をすっ飛ばして)$Y$を目的変数にした回帰式の係数がY負荷。
- AbdiさんはX得点を$t$, Y得点を$u$, Xウェイトを$w$, Yウェイトを$c$、X負荷を$p$と書いている。Y負荷については書いていないが、$bc$がそれにあたる。で、$b$のことを"回帰ウェイト"と呼んでいる。
- Mevik & Wehrensは、X得点を$t$, Y得点を$u$, Xウェイトを$w$, Yウェイトを(ひとつめの)$q$、X負荷を$p$, Y負荷を(ふたつめの)$q$と書いている。
- SAS先生は、X得点を$t$, Y得点を$u$, Xウェイトを$w$, Yウェイトを$q$, X負荷を$p$, Y負荷を$c$と書いている。
Clark, S., & Muthen, B. (2009) Relating latent class analysis results to variables not included in the analysis. Submitted for publication.
未公刊のdraftらしいのだが、MplusでLCAを行うという話のなかでよく引き合いに出されるので、ざっと目を通した。第一著者の修論かなにかかしらん。
潜在クラス分析で個体を分類した際、次に問題になるのは、潜在クラスの説明変数になっているかもしれない変数(共変量)とクラスとの関係を調べることである。えーっと、市場調査におけるアドホックなセグメンテーションの例でいえば、なにかの項目群への回答によって調査対象者をセグメントに分けてから、デモグラフィック特性とセグメントのクロス表をみる、というのがそれですね。しかし、所属先クラス別に共変量の分布を調べるのは、実はあまりうまいやり方ではない、かもしれない。あるクラスに分類された個体のなかには、所属確率が1に近い個体もあれば低めな個体もあるからだ。じゃあどうすればいいか、という研究。
実データ(2つ)とシミュレーションで、5つの方法を比較する。(1)クラス別に共変量の分布を調べて比較。(2)各クラスへの所属確率のロジットを目的変数、共変量を説明変数にした回帰。(3)所属先を目的変数、共変量を説明変数にした回帰を、所属確率でウェイティング。(4)pseudo-class drawという方法。所属確率の分布に従って個体を抽出し、得られたクラスについて共変量の分布を比べる。最近Mplusに追加された「AUXILIARY= ほにゃらら(r)」ってのがこれであろう。(5)「分類してから分析」という発想を悔い改め、LCAモデルのなかに共変量を入れて一発推定。
推定として(5)が正しいことはわかっているけど、潜在クラスの解釈が難しくなるわけで(その分類はいったい何に基づく分類なんですか?という話になる)、焦点は(1)-(4)のうち少しでもましなものを選ぶことである。例によって、シミュレーションの部分は斜め読みで済ませた。すいません。
著者らいわく、もしLCAのエントロピーが高かったら(0.80以上とか)、所属先クラスをつかっちゃってかまわない。いっぽうエントロピーが低い場合は、(1)-(4)のどの方法でも、標準誤差を低めに推定してしまうことになる由。というわけで、お勧めの手順は以下の通り: まず、共変量抜きでLCA。次に、共変量群が潜在クラスに効いてるかどうか、pseudo-class Waldテストで確認。もし効いていたら、pseudo-class回帰で共変量を絞り込む。そして最後に、効いている共変量をモデルに投入して再推定。
実のところ、潜在クラスがなんらかのアウトカムの説明変数になっているかもしれない場合について知りたかったんだけど、まあ勉強になったからいいや。そういう話としてはPetras & Masyn(2009)というのが引用されているが、成長混合モデルの文脈での研究らしい。
読了: Clark & Muthen (2009) 潜在クラスと他の変数との関係を調べる方法
DeMaris, A. (2002) Explained variance in logistic regression: A monte carlo study of proposed measures. Sciological Methods & Research, 31(1), 27-74.
ロジスティック回帰のいろんな説明率指標をシミュレーションで比較する研究。先日読んだMittlbock & Schemper (1996) と同趣旨だが、もっときちんとやりました、という主旨。
著者によると、ロジスティック回帰における説明率には、「分散の説明率」という考え方と「リスクの説明率」という考え方があるのだそうだ。前者は、従属変数の分散と、モデルの誤差分散との比に注目する考え方。いっぽう後者は、 平均 \pi のベルヌーイ分布の分散は \pi(1-\pi) にきまってんだから、(全体の生起率)x(1-全体の生起率)と、(予測された生起率)x(1-予測された生起率)の平均との比をみればいいんだ、という考え方。この二つは、従属変数をどう捉えるかというちがいであって、たとえば「医者が患者の抑うつの有無を診断した」場合は前者が自然だし(従属変数はたまたま二値になっているだけで、抑うつの程度という連続的な潜在変数の代理変数だから)、「未成年者が妊娠した」場合は後者のほうが自然である由(従属変数は本質的に二値だから)。ふうん...
で、次の8つの指標のふるまいをシミュレーションで比較する。
- 委細構わず、二値従属変数とロジスティック回帰モデルで予測した生起確率との相関をとって二乗する。Mittlbock & Schemperでいうr^2。
- McKelvey & Zavoina(1975)の指標。ロジスティック回帰モデルで求めた各個体のロジットの分散を、(ロジットの分散)+(誤差分散の推定値)で割る。誤差分散の推定値は(全体における生起率の二乗/3)。
- 尤度比指標。たぶん、McFaddenのpseudo R^2のこと。
- Aldrich & Nelson(1984)の指標。モデルのカイ二乗値(つまり、モデルの尤度とナルモデルの尤度の比を-2倍したもの)を、(モデルのカイ二乗値)+(サンプルサイズ) で割る。最大値は1にならない。
- 上の指標を最大値で割ったやつ。
- 一般化R二乗。Mittlbock & Schemperでいう尤度比R^2のこと。最大値は1にならない。
- 上の指標を最大値で割ったやつ。NegelkerkeのR^2のこと。
- 「リスクの説明率」の標本推定量。たぶんMittlbock & Schemperに出てきたGiniのconcentration measureと同じなんじゃないかと思う。
シミュレーションのところから面倒になっちゃって飛ばし読み。「分散の説明率」の観点からはMcKelvey & Zavoinaが、「リスクの説明率」の観点からはリスクの説明率の標本推定量なり単純な相関なりがよかったそうだ。ふうん。
きちんと読んでいないのになんだけど、「リスクの説明率」という考え方がどうもよくわからない。事象が生じる周辺確率を\pi, モデルによる予測確率を (\pi | x) としたとき、リスクの説明率とは 1 - E[\pi(1-\pi)|x] / \pi(1-\pi) だ。当たり外れは一切気にせずに、どんな個体に関しても予測確率1(ないし0)を吐き出し続ければ、説明率100%の予測モデルが作れたことになるわけで、それはさすがに頽廃的なのではないかと... まあ、背景についてもうちょっと勉強しろってことでしょうね。Korn&Simon(1991, American Statistician)というのが引用されている。
読了:Demaris(2002) ロジスティック回帰の説明率指標をもっときちんと品定め
2012年3月13日 (火)
Mittlbock, M., & Schemper, M. (1996) Explained variation for logistic regression. Statistics in Medicine, 15, 1987-1997.
ロジスティック回帰分析のアウトプットには,なんか変な$R^2$がいろいろはいっているんだけど,あれっていったいなんなんだろうなあ,と前から不思議に思っていた。このたび関連する話題についてちょっと考える機会があったので,適当に論文を見繕って読んでみた。12種類の$R^2$指標を比較しました,という論文。そんなにあるのか。
12種類の$R^2$指標は,大きくいえば3グループにわかれる。ええと,個体$i$が持つ従属変数の値を$y_i (=\{0,1\})$とする。$y_i = 1$を仮に成功と呼ぶとして,全体における成功率を$\bar{p}$とする。また,独立変数の値を$x_i$とし、ロジスティック回帰モデルで推定された各個体の成功率を$\hat{p}_i$とする。
最初のグループは,$y_i$と$\hat{p}_i$の相関の二乗に基づく指標。
- $y$が二値であることは気にせずに、単純にPeasonの相関係数を二乗する。($r^2$)
- Spearmanの相関係数を二乗。($r^2_s$)
- Kendallの$\tau_a$を二乗。($\tau^2_a$)
- Kendallの$\tau_b$を二乗。($\tau^2_b$)
- Somersの$D$を二乗。($D^2_{\hat{p}y}$)
- Goodman-Kruskalの$\gamma$を二乗。($\gamma^2$)
順位相関係数を手当たり次第に集めてきて二乗しました、という感じですね。3番目以降はまあどれも似たような指標である(いずれも計算式の分子は同じ)。
第二のグループは,yの分散の縮減率に基づく指標。一般化していうと,conditionalな残差を表すなんらかの指標 $D(y_i|x_i)$の合計と、unconditionalな残差を表すなんらかの指標$D(y_i)$の合計を出して、比をとって1から引くタイプの指標である。
- yが二値であることなど気にせず、ふつうの回帰モデルと同じように,$D(y_i)=(y_i-\bar{p})^2$, $D(y_i|x_i)=(y_i-\hat{p}_i)^2$とする。($R^2_{SS}$)
- ロジスティック回帰モデルを信じれば、unconditionalな残差の分散の期待値は $\bar{p}(1-\bar{p})$、conditionalな残差の分散の期待値は$\hat{p}_i(1-\hat{p}_i)$なわけだから、これを$D(y_i), D(y_i|x_i)$として用いる。これをGiniのconcentration measureという。へー。($R^2_G$)
- アタリハズレだけに注目し、unconditionalな残差の絶対値$|y_i-\bar{p}|$と、conditionalな残差の絶対値$|y_i-\hat{p}_i|$を、なにかのカットオフ(たとえば0.5)よりも上か下かで二値変数に落としてしまい、これを$D(y_i)$, $D(y_i|x_i)$として用いる。モデルのせいでハズレ率がどれだけ減ったか、だけに注目するわけだ。ずいぶん荒っぽい話だなあと驚いたが、これはGoodman-Kruskalの$\lambda$と等価である由。ほー。 ($R^2_{CER}$)
- 残差指標をエントロピーとして捉える。$D(y_i)=-(y_i \log \bar{p} + (1-y_i) \log (1-\bar{p}))$, $D(y_i|x_i)=-(y_i \log \hat{p}_i + (1-y_i) \log (1-\hat{p}_i))$。前者の和は -(ナルモデルの対数尤度)、後者の和は -(モデルの対数尤度)となる(これを2倍したのが、ソフトの出力に出てくるところのモデルのデビアンスであろう)。で,これを引き算してカイ二乗検定するんじゃなくて,比をとって1から引く。こうして求めた$R^2$は、McFaddenのpseudo $R^2$というのと等価である由。($R^2_E$)
最後のグループは,モデルの尤度に基づく指標。
- さっきのは1-(対数尤度の比)だったが、今度は1-(尤度の比)^{2/n}とする。つまり、どれだけ尤度が上がったかを一人あたり幾何平均で出すわけだ。これを尤度比$R^2$、ないしCox-Snellの$R^2$という。($R^2_{LR}$)
- 仮に完全にフィットしているモデルでも,$R^2_{LR}$は1にならない。それじゃ使いにくかろうというので、$R^2_{LR}$をその最大値,すなわち1-(ナルモデルの尤度)^{2/n}でさらに割ってやる。実にムリヤリ感あふれるアプローチだが、これがあの,SPSSとかで出てくる,Negelkerkeの$R^2$なのだそうだ。へえええ! ($R^2_{CU}$)
いま調べたら、SAS 9.22のproc logisticでは、$R^2_{LR}$が"RSquare"というラベルで、$R^2_{CU}$が"Max-rescaled RSquare"というラベルで出力されるらしい。
なんだかもうお腹一杯だが,論文のほうはここからが本番で,いろいろデータをつくっては12種類の$R^2$を求め,挙動を比較している。著者らいわく,
- 直観的にわかりやすいか
- ロジスティック回帰の性質とつじつまがあうか
- 0から1まで動くか
- ふつうの線形回帰モデルがうまく当てはまるようなデータでは線形回帰モデルの$R^2$と同じような値になるか
という4つの基準で検討すると,
- $R^2_E, R^2_{LR}, R^2_{CU}$は直観的に理解しにくい。
- $R^2_{CER}$や順位相関係数系の方法はロジスティック回帰とつじつまがあわない。
- $r^2_S$, $\tau$系, $R^2_{LR}$は完全にフィットしても1にならない。
- たいていの手法は線形回帰の$R^2$とずれる。
というわけで,消去法で結局$r^2, R^2_{SS}, R^2_{G}$が残ることになる。結局のところ,$y_i$が二値変数であることを無視しちゃった方がいいね,という,ちょっと奇妙な結論である。
勉強にはなったけど。。。ロジスティック回帰モデルのときも,慣れ親しんだ$R^2$のような奴が欲しいよ欲しいよ欲しいよ,というのがこの論文の前提になっているところがポイントだと思う。この前提そのものが,なんだかちょっとワガママなような気がしてならない。なんというかその,海外旅行先で味噌汁飲みたい,といっているように聞こえる。いや,それは飲みたいですけどね,私も。
それはまあいいや。ともかく,Negelkerkeの$R^2$というのが意外に無茶な発想で作られている,という点を学んだのが収穫であった。私の知る狭い範囲の話だが,Negelkerkeの指標はよくみかけるような気がする。SPSSが出力するせいかもしれない。
読了:Mittlbock & Schemper (1996) ロジスティック回帰の説明率指標を品定め
2012年3月 2日 (金)
Rothman, K.J. (1990) No adjustments are needed for multiple comparisons. Epidemiology, 1(1), 43-46.
多重比較法そのものに対する批判としてよく引用されている論文。著者は「ロスマンの疫学」でおなじみの超偉い人。掲載されたのは雑誌Epidemiologyの創刊号で、エディターは先生ご自身である。創刊号になんか書いたらなあかんな、よしこれを機にひとつ無知蒙昧を正しておいてやるか... という感じだったのかも。なにしろロスマン先生は仮説検定にも一家言お持ちの方なのだ(そのせいで起きた波紋についての楽しい論文を読んだことがある)。
先生いわく、多重比較法は次の2つの不適切な思い込みに基づいている。(1)「異常な知見はたいてい偶然によるものだ」(Chance not only can cause the unusual finding in principle, but it does cause many or most such findings)。(2)「偶然によって引き起こされたものに目印をつけ今後の探求に供したいと思っている人はいない」(No one would want to earmark for further investigation something caused by chance)。
含蓄がありすぎる表現で困っちゃうのだが、もっと散文的に言い換えると、こういうことだと思う。(1)多重比較法が仮定する帰無仮説はおかしい。(2)ひとつひとつの比較はそれぞれに価値がある。
論点(1)について。正確を期するために抜き書きすると、"The isolated null hypothesis between two variables serves as a useful statistical contrivance for postulating probability models. [...] Any argument in favor of adjustments for multiple comparisons, however, requires an extension of the concept of the isolated null hypothesis. The formal premise for such adjuestments is the much broader hypothesis that there is no association between any pair of variables under observation, and that only purely random processes govern the variability of all the observations in hand." つまり、多重比較法には次の2つの特徴があるとロスマン先生は考えている。(1-1)「すべての比較において差がない」という帰無仮説を仮定している。(1-2)帰無仮説の下で各比較における誤差が独立だと仮定している。
先生はどちらの特徴を批判しているのだろうか。確信が持てないのだが、両方ではないかという気がする。(1-1)を批判しているように見える箇所: "The null hypothesis relating a specific pair of variables may be only a statistical contrivance, but at least it can have a scientific counterpart that might be true. The universal null hypothesis implied not only that variable number six is unrelated to variable number 13 for the data in hand, but also that observed phenomena exhibit a general disconnectivity that contradicts everything we know". (1-2)を批判しているようにみえる箇所: "the generalization to a universal null hypothesis has profound implications for empirical science. Whereas we can imagine individual pairs of variables that may not be related to one another, no empiricist could comfortably presume that randomness underlies the variability of all observations".
論点(2)について。我々は予測できない分散をchanceのせいにする傾向があるけれど、そもそもchanceという言葉は現象の説明ではない。それはいつの日か因果的な説明が可能な現象かもしれない。かつて肺がんの発症はchance phenomenonだったが、いまでは大部分が説明できるではないか。多重比較の調整は、せっかく観察された関連性にchanceという名前を付け、それを覆い隠してしまうことで、科学にダメージを与える。調整しないと誤った知見が得られてしまう、だって? 誤りは科学という試行錯誤のプロセスにつきものだ。観察の増大に伴い観察のprivilegeにペナルティを課そうという多重比較の発想は論理的におかしい。"Science comprises a multitude of comparisons, and this simple fact in itself is no cause for alarm".
うーむ。正直なところ、よく理解できなかった。ひとことでいうと、論点(1)の批判のスコープがわからない。恥ずかしいけれども、今後の勉強のために、よくわからなかった点を書き出しておく。
(1-1)についていえば、
- 先生の批判はたとえば1要因実験での水準間比較にも及ぶのか。及ぶとなると、1元配置分散分析でF検定を行うのもおかしいことになる(帰無仮説は「すべての水準のあいだで差がない」だから)。及ばないとなると、多重比較批判としてはすごーく狭い話をしていたことになってしまう。
- この批判が対象としている多重比較手法はなにか。細かい話だけど、たいていの多重比較法は、ロスマン先生の言うような「すべての比較において差がない」という帰無仮説は特に仮定していないと思う。「すべての比較において本当は差がないにも関わらずどこかで有意差を見つけてしまう確率」(Type I FWE)ではなく、「本当は差がない比較のいずれかにおいて有意差を見つけてしまう確率」の、多様な母数配置を通じた最大値(最大Type I FWE)をコントロールするのが普通である。そういう手法ならみなオッケーなのか。
(1-2)についてもよくわからない。
- たとえば1要因4水準の実験計画で、水準1と2、3と4、の2つの対比についてシェフェ法で多重比較する人に向かって、なお「比較の間で誤差が独立でないかも」と批判するならば、分散分析さえ許されないことになると思うけど、そういう理解でよいのか。
- たとえばボンフェローニ法は「和事象の確率は事象の確率の和以下である」という性質に基づいており、比較のあいだで誤差に独立性があろうがなかろうがこの性質は成り立つ。ボンフェローニ法にも批判は及ぶのか。
いっぽう、論点(2)については納得。でも、いやいや実証研究ってのはもっと別のプロセスでもありうるのよ、 たとえば説明はどうでもよくて、取り急ぎ差がありそうな比較をスクリーニングしたいこともあるじゃないの... と開き直る人が出てくるだろうと思う。先日S. Goodmanという人の論文を読んで、なんだか霧が晴れたような気がしたんだけど、Goodmanさんの言い方を借りればロスマン先生は「ある差についての科学的説明の良さを判断する我々の能力を信頼している人」であり、そしてその暖かい信頼は必ずしも自明ではないのではないかしらん。
この論文、ネットでPDFをみつけたはいいが、スキャンの質が悪くて読みにくく、目が悪くなりそうなので途中であきらめて、国会図書館関西館に郵送複写依頼を出した。その後自分のなかで多重比較のブームが過ぎ去り、すっかり忘れたころになってポストに入っていた。
毎度のことながら、国会図書館の複写担当の方はコピーを実に丁寧に送ってきてくださる。そうする規則があるというより、日本の学術研究を支えているという誇りをもって業務に携わっておられるということだろう、と想像する。私は全然支えてないですけど。いつもすみません、感謝感謝。
2012年2月22日 (水)
初級の教科書に書いてある簡単な話であって、よく知っているつもりで暮らしているのだが、よくよく考えてみると全然簡単な話ではない... という事柄が、世の中には多々ある。統計学の教科書もまた,そうした話題にあふれていると思う。もっとも、それをうかつに口にすると、思ってもみない人に予想もできない形でバカにされることがあるので、ほんとうは黙っていたほうが面倒がないのだけれど。
統計的多重比較法というのもそういう話題の一つであって(少なくとも私にとっては)、教科書を勉強しているぶんには平和なのだけれど,現実のデータ解析の文脈に当てはめて考えると、これが非常に難しい(少なくとも私にとっては)。先日もそう思い知らされる出来事があった。仕事の関係で、「いったい多重比較はどんなときに行うべきなんですか?」と真正面から問われ、言葉に詰まってしまったのである。「なぜ」とか「どうやって」ではなくて、いつ、と問われているところが厄介である。
もし木で鼻を括ったようなお返事でよろしければ、とりあえずは「(maximum) Type I familywise error rateをコントロールすべきとき」と答え、戸惑う相手にType I FWEとはなにかをくどくどと説明して,相手がうんざりするのを待てばよい。しかし、相手が本当に知りたいこと、私たち統計手法ユーザが本当に知りたいことは、「私たちが (maximum) Type I FWEをコントロールすべきなのはいかなる状況においてか」なのである。これはものすごく難しい... 少なくとも私にとっては。
Bender, R. & Lange, S. (2001) Adjusting for multiple testing - When and how? Journal of Clinical Epidemiology, 54, 343-349.
多重比較全般に関する臨床疫学者向けの啓蒙論文。類似の文献は山ほどあるのだが、とりあえずタイトルが魅力的なものから読んでみた。先生方、タイトルは大事ですよ。
「多重比較はいつ必要か」という問いに対して、著者らは比較的に穏健な、悪く言えば煮え切らない立場をとっていて、「そもそも多重比較に調整なんて要らねえよ」というロスマン流の極左的(?)批判は採らないが、多重性の調整は常にいつでもぜったい必要だという極右的(?)主張にも組しない。検証研究の場合は必要だけど、探索研究の場合にはそうでもない、とのこと。なぜなら、探索研究では仮説がデータ依存的で、仮説検定は意思決定ではなく記述のための道具にすぎないだろうから、との仰せである。ううむ...
そもそも記述のために検定なんか使うなという反論がありそうだが、それはまた別の話になるので置いておくとしても、検証と探索というのは理念型であって、たいていのデータ解析はその両極の間をうろうろしているのだから、そうやって彷徨っている哀れなユーザ向けに、課題状況と多重性調整との関係をどう捉えればよいのか、もう少しアドバイスを頂けるとうれしかったです。適応分野をある程度狭めたうえで、きちんと理詰めで考えていけば、検証-探索というラフな場合分けではなく、もう少し踏み込んだ処方箋がありうるのではないかしらん。ま、自分で考えろってことですね。
ちらっと紹介されていた、長期臨床試験の中間解析の話題が興味深かった。P値がどうだったら試験を中断するか、という話。なるほどー、そういう話題があるんですね。
Perneger, T.V. (1998) What's wrong with Bonferroni adjustments. British Medical Journal, 316, 1236-1238.
多重比較についての議論の際によく引用されているようなので、ついでにざっと目を通してみた。Bonferroni調整はよくない、なぜなら(1)ユニバーサルな帰無仮説にはふつう関心がないから、(2)Type II エラーが増えるから、(3)ファミリーに含めるべき比較の定義が恣意的だから。そもそも多重比較法のロジックはNeyman-Pearson的意思決定支援の枠組みのなかで考案されたものであって、エビデンス評価のためには推定とか尤度比とかベイズ流の手法とかを使うべきだ。云々。
Bonferroni調整の話がまっすぐ多重比較全般の話につながっちゃうので、アレレ? という感じだが、やはり後の号でそういうコメントが載った模様。
この記事,google scholarでは1939件引用されていることになっている。BMJであることを考慮しても,これはかなり多いほうだと思う。ソーシャルメディアでは短くて乱暴な発言のほうが拡散されやすかったりするけど、学術論文にもちょっとそういう面があるかもしれない。
Goodman, S. N. (1998) Multiple comparisons, explained. American Journal of Epidemiology, 147(9), 807-812.
この雑誌上で多重比較の意義について論争があったようで(Savitz & Olshan,1995, Thumpson, 1997)、その2論文に対するコメント。元論文を読んでいないので文脈がわからない箇所があるし,書き方がちょっとくどすぎるようにも思うのだが,それでも大変面白かった。
著者いわく、多重比較をめぐる論争は、科学的方法とはなにかという大問題に関わっている(おっと,大きく出ましたね)。Fisherにとってp値とは、観察データと単一の帰無仮説との間の統計的な距離であり、統計的な証拠の強さの指標であった。いっぽうNeyman-Pearsonにとっては、p値は単なるerror rateである。彼らにいわせれば、科学が演繹的・客観的確率のみに基づく推論システムに基づく限り、証拠の強さを測る方法はないし、特定の仮説の真偽の判定は許されない。純粋に演繹的な推論システムはデータから仮説へという帰納的なはたらきを持たないからである。しかし、科学を推論の営みではなく、固定されたルール群に従う「帰納的行動」の営みとして扱うことならできる。このように科学のスコープを狭く限定する見方は、ポパー、カルナップ、ヘンペルといった同時代の科学哲学者たちと通じるものであった。
Neyman-Pearsonの枠組みのなかでは、仮説検定が現在のように普及する理由はない。にもかかわらずp値がこんなに広まってしまったのは、それがあたかも証拠の強さを測っているような顔をしているから、証拠によって事後的に測られたType I error rateであるようにみえるからである。p値は証拠とエラーのふたまたをかけている。そのごまかしを露呈させるのが、たとえば多重比較の状況なのである。
ある研究の中で500個の比較について検定したとしよう。有意水準5%なら、ほんとはどこにも差がなくたって、平均25個の有意差が得られる。いま20個得られたとしよう。これは偶然によるものだと「説明」できる。500個の比較のいずこにも差がないという帰無仮説をANOVAで検定すれば、総体としての結果はこの帰無仮説から離れていないということになろう。これに対して、いやいや、ひとつひとつの比較は認識論的にみて質的に違うものなのだから、依然として個別の比較のp値なり尤度比なりを求めることには意義がある、という見方もできる。この2つの立場の対立の根底にある本当の問題は、証拠の強さの評価の方法としてp値が良いかどうかとか、いや尤度比やベイズファクターを使ったほうがいいんだとか、そうということではない。むしろ、我々がいろいろな比較を認識論的に区別できると信じるかどうか、すなわち、ある差についての科学的説明の良さを判断する能力が我々にあると信じるかどうか、がキーポイントなのである。
な・る・ほ・ど... 探索か検証かという区別よりも、こっちのほうがはるかに腑に落ちる。大変勉強になった。
2012年2月 5日 (日)
Chintagunta, P.K. & Dong, X. (2006) "Hazard/survival models in marketing". in Grover, R. & Vriens (eds), The Handbook of Marketing Research: Uses, Misuses, and Future Advances, Sage.
マーケティング分野における生存時間分析についての入門的紹介。仕事の都合で目を通した。
こういう初学者向けの解説を探す際は,多少無理してでも英語の文章を探した方が効率が良いことが多いと思うのだが(日本人の先生が書いたものだと,ものすごく易しい文章や,ご自分の研究紹介になってしまいがちだから),この章はまさに良い解説の見本みたいなもので,感銘した。比例ハザードモデルと加法リスクモデルと加速故障モデルの含意の違いについて,数式いっさいなしで簡潔に説明するくだり,ほんとに勉強になりました。そういうことだったのか。
読了:Chintagunta & Dong (2006) マーケティングにおける生存モデル
2012年2月 3日 (金)
Mevik, B., & Wehrens, R. (2007) The pls Package: Principal Component and Partial Least Squares Regression in R. Journal of Statistical Software, 18(2).
仕事の都合で読んだ。R の pls パッケージの紹介。SASのproc plsに相当する。
PLS回帰は,途中でどの行列を圧縮するか,どのタイミングで標準化するか,といった細かいやりかたの揺れのせいで,ちがう実装のあいだで結果を比較するのが難しいんだそうだ。勘弁してよ...
読了:Mevik & Wehrens (2007) pls パッケージ
2012年1月31日 (火)
Pearl, J. (2012) The causal foundation of structural equation modeling. Technical Paper, R-370, UCLA Cognitive Systems Laboratory.
先週読んだ Bollen & Pearl が勉強になったので,試しに読んでみた。こちらは近刊の"Handbook of Structural Equation Modeling"の一章となる模様。しばらく前からテクニカル・ペーパーとして回覧されていて,SEM関連のメーリング・リストでは大変な議論を呼んでいた(ちゃんとフォローしとけばよかった)。
Pearlの統計的因果推論の諸概念を,ノン・パラメトリックSEMの枠組みで説明している論文。d-分離とか,バックドア基準とか,直接効果と間接効果とか。残念ながら,後半でだんだん頭に入らなくなってきて,途中をちょっと飛ばし読みしてしまった。そういうのが一番いけないんだけど。
Pearl先生は"Causality"という大冊を著しておられ,初版は翻訳も出ているのだから,本でちゃんと勉強すればいいんだけど,非常に敷居が高く感じられてしまい,こうやって周辺の解説論文などをおそるおそる読んでいる次第なのである。せっかく買った翻訳本は,机の脇でホコリをかぶっている...
2012年1月24日 (火)
Bollen, K.A., & Pearl, J. (2012) Eight myths about causality and structural equation models. Technical Report, R-393, UCLA Cognitive Systems Laboratory.
SEMの超偉い人であるBollen先生と、因果推論の超偉い人であるPearl先生は、このたびSpringerから出る"Handbook of Causal Analysis for Social Research"という本に共著で一章を書くのだが、その下書きをただいまテクニカル・レポートとして回覧中。これから改訂されるんだから、ほんとは最終稿になってから読んだほうがいいんだけど、タイトルが魅力的なのでついつい目を通した。
著者らのいう「因果性とSEMにまつわる8つの神話」とは:
1. 「SEMは関連性に基づいて因果関係を確立することを目指している」。SEMは因果的仮定に基づいて行われる、というのが正しい。著者らいわく、この誤りが広まっている理由は、まず人々が因果的仮定と統計的仮定の区別がついていないから、さらにSEMユーザがモデルにいれている因果的仮定を明確にしていないことが多いから、ではないかとのこと。
2. 「SEMと回帰は本質的に等しい」。これは間違い。たとえば、回帰の誤差項は単にYの実現値と予測値のずれだが、構造方程式における誤差項は固有の確率的要素である。前者は定義上Yと直交するが、後者の性質は因果的仮定によって決まる。
3. 「操作なくして因果なし」("No causation without manipulation")。もちろんこのモットーも著者らの受け入れるところではない。もっとも、こういうHolland-Rubin流の強い立場に立つ人が、その立場からSEMを使っても全然かまわないわけだが。
4.「SEMよりNeyman-Rubinの潜在反応モデルのほうが理にかなっている」。この項は、Rubinさんの一連のSEM批判に対する応答。Rubinの考え方をきちんと勉強してないので、理解できたかどうか怪しい...
5. 「SEMは非線形的な因果関係には向いていない」。二次関数への拡張、二値・順序・多項変数などへの近年の拡張をみよ。また、Pearlのdoオペレータをつかった新しい定式化をみよ。とのこと。後者は不勉強でよくわからなかった。
6. 「SEMはランダム化実験にはあまり役に立たない」。いやいやとんでもない、というので、一例として、操作変数と操作チェック用指標と結果指標を組み込んだちっちゃなSEMモデルの紹介。
7. 「SEMは媒介分析には使えない」。なんでも、Rubinさんたちはprincipal strata という考え方に基づく媒介効果の分析を提案しているのだそうで、この項はそのアプローチへの批判であった。モトネタを全然知らないので、もうなにがなんだか。
8. 「SEMによる理論検証は部分的検証に過ぎない」。そもそもどんな因果的仮定だってそれ単独では検証できない。SEMは検証可能な範囲の理論的含意を検証するための最良の方法だ。尤度比に始まる一連の適合度指標をみよ、Bollenの検証的テトラッド・テストをみよ、偏相関による条件つき独立性のテストをみよ、BollenのModel implied instrumental variables アプローチ (なんすかそれは) をみよ、云々。モデルの大域的テストのみに関心を寄せ局所的テストを無視するSEMユーザにも問題がある由。
素人ながら想像するに、1とか6とかについてはたぶん異論がないところで,揉めるのはきっと3とか4とか7とかであろう。このへん、勉強してみたいのは山々だが...ううむ。
読了:Bollen&Pearl (2012) SEMの8つの神話
2012年1月 7日 (土)
Garland, R. (1991) The mid-point on a rating scale: Is it desirable? Marketing Bulletin, 2, 66-70.
リッカート尺度について考える機会があったので目を通した。Marketing Bulletinというのはニュージーランドのオープンアクセス誌らしい。この論文は前から気になっていたもので、でも掲載誌の性質がよくわからないので後回しになっていたのであった。Google Scholar様によれば、この雑誌にこれまで掲載されたなかで引用回数が一番多いのがこの論文である。
調査対象者に食品の成分表示の重要性について評定させる。一方の群は"very important", "important", "neither important nor unimportant", "unimportant", "not at all important"の5件法。他方の群は、中央("neither...")を抜いた4件法。回答の分布を群間で比較すると、5件法群で真ん中は14%。4件法群では中央がなくなった代わりに"unimportant"が8ポイント上昇する("important"は逆に3ポイント減る)。つまり集計値で見る限り、4件法のほうがネガティブにシフトしたわけだ。著者いわく、社会的な望ましさによるバイアスを最小化するためには中央を取り除いたほうがいいとのこと。
ぜ・ん・ぜ・ん・納得できない。5件法と4件法の違いが回答の社会的望ましさ(SDR)と関係しているという根拠はどこにあるのか。著者も触れているように、4件法にしたせいで回答分布がポジティブにシフトした例だって報告されているのだ。
そもそも、集計値レベルの分析で良しとするその発想がわからない。SDRとの関係を主張するなら、個人データに基づいてSDR傾向との相関を調べるのが筋だし、4件法と5件法のどっちがdesirableかを問題にしたいのなら、やはり個人データに基づいて検査再検査信頼性や基準関連妥当性を調べるのが筋でしょうに。
この論文のすごく魅力的なタイトルによって我々が期待するのは、結局のところ 5件法がいいのか4件法がいいのか、という疑問に対するなんらかの示唆であろう。さて,結論部分で著者が書いているのは: The debate continues and the explicit offer of a mid-point is largely one of individual researcher preference. ぐぬぬぬぬ。
読了:Garland(1991) 5件法評定と4件法評定のどっちがいいか
2012年1月 6日 (金)
Carifio, J. & Perla, R. (2008) Resolving the 50-year debate around using and misusing Likert scales. Medical Education, 42. 1150-1152.
たった2頁のコメンタリー。なぜか忘れたが国会図書館でコピーしていた(きっとタイトルがすごく魅力的だったからだろう)。リッカート尺度についてちょっと考える用事があったので、ついでに目を通した。
リッカート尺度(いわゆるx件法評定ですね)で得たデータは「順序尺度だからノンパラメトリックな統計量で分析しなければいけない」という立場と、「いや複数項目を合成するんであれば間隔尺度とみなすことができて、だからパラメトリックな統計量で分析してよい」(平均とかSDとかですね)という立場とがあって、このMedical Educationという雑誌で論争があったりしたんだそうだ。へえー。
で、著者いわく... F検定は順序尺度データに対して頑健だということがシミュレーション研究でわかっている。また、まあ8項目くらいあればその合成得点は間隔尺度の性質を持つということが経験的に知られている。つまり上記の論争については後者に軍配があがる。むしろ問題は、前者の立場がどこから生まれてきたかだ。これはもともStevensの、項目が順序尺度なら合成得点も順序尺度だという論理的な議論に基づいている。でも分子が原子と違う性質を持つのは医学者なら誰でも知っているでしょう。論理的議論よりも経験的議論のほうを重視すべきだ。云々。
うーん... なんだか話がずれているような気がする。俺の怪しい理解によれば、Likert scaleという言葉はちょっとあいまいに使われていて、伝統的な態度尺度構成法のひとつであるところの、x件法評定項目を使ったmethod of summated ratingsを指す場合と、転じてx件法評定項目そのもののことを指す場合があるように思う。著者が誤った見解として引き合いに出しているJamieson(2004)をザーッとナナメ読みしたのだけれど、Jamiesonさんが考えているのは後者のこと(したがって基本的には単一項目の分析のこと)、いっぽう著者がいっているのは前者のこと(したがって合成得点の分析のこと)じゃないのかという気がする。論争の途中経過を読んでいないので、なんともいえないが。
もうひとつ気になったのは、単一項目の分析について著者が Analysing a single Likert item [...] is a practice that should only occur very rarely とあっさり切り捨てていることで、医学研究ではほんとにそうなんですか? という疑問がある。たとえば特定の疾患のQOL評価では、複数項目を聴取するもののキーになるのはたった1項目、ということがあると思うけど、ああいうのはvery rareなのか。まあ、よく知らないけど、少なくとも質問紙調査全体に一般化できる主張ではないですね。。
読了:Carifio & Perla (2008) X件法尺度についての論争に決着をつけてみせよう
2011年12月28日 (水)
Vermunt, J.K., & Magidson, J. (2005). Factor Analysis with categorical indicators: A comparison between traditional and latent class approaches. In A. Van der Ark, M.A. Croon and K. Sijtsma (eds.), New Developments in Categorical Data Analysis for the Social and Behavioral Sciences, 41-62. Mahwah: Erlbaum.
仕事の都合で読んだ。付け焼刃もいいところだが、仕事が押して会社に泊まり込んだのに(やれやれ) 計算が終わらないので結構ヒマ、という事情もある。
カテゴリカル指標の因子分析のかわりに、複数の潜在クラス変数を想定するという方法があって、Latent Goldの開発者Vermuntさんはこれをlatent class factor analysis (LCFA)と呼んでいる。なるほど、名義変数への拡張が容易になるから、動機としてはよくわかる。で、この論文の主旨は、(1) たとえ指標がすべて二値であっても、因子分析ではわからないことがLCFAでわかったりするよ。(2)LCFAのアウトプットは指標に対するロジットモデルの係数になってしまってややこしいので、まずモデルを推定し、次に推定された所属クラス(ダミー変数にする)を独立変数、指標の値そのもの(多値のときはダミー変数にする)を従属変数にした線形回帰モデル(!)を推定し、その係数を因子負荷に見立てれば結果を因子分析っぽく表現できて都合がいいよ。
便利かもしれないけどずいぶん荒っぽい話だなあとびっくりしたが、きっとLatentGoldでは実際にそういう出力が出るのであろう。
論文の主旨はともかく、VermuntさんのいうLCFAと、Mplusの開発者MuthenさんがいうLCFAがちがうということに気が付いたので、その点が収穫であった。Vermuntさんがいっているのは、ちょうど因子分析で指標の背後にk個の連続的潜在変数を想定するように、k個のカテゴリカル潜在変数を想定することだ(各潜在変数のクラス数が2ならば(2^k)個のジョイント・クラスを推定することになる)。いっぽうMuthenさんがいうLCFAは、指標群の背後に連続的潜在変数とカテゴリカル潜在変数の両方を想定するタイプのモデルだと思う。
読了:Vermunt & Magidson (2005) 潜在クラス因子分析は素敵だ
2011年12月27日 (火)
Armstrong, J.S. (2012) Illustions in regression analysis. International Journal of Forecasting, forthcoming.
著者はマーケティングの予測手法研究の偉い人。この論文は先日読んだ Soyer & Hogarth へのコメンタリーで、昔話と冗談を交えたうんちく話という感じ。
面白かったところをメモ:
- とにかく先生は、変数選択はデータに基づかずアプリオリにやんなさい、と強調しておられる。ステップワイズ変数選択はもちろん、モデル比較もデータマイニング手法ももってのほか。さらには、回帰式に3つ以上変数をいれてはいけません、とのこと。ううむ。
- 回帰分析による予測の正確性の過信につながる幻想として、先生は次の5つを挙げている:複雑さの幻想(複雑なほうがよいわけではない)、回帰モデルがあれば十分だという幻想(複数の手法を併用すべきだ)、回帰が最良線形不偏推定量を与えるという幻想、統計的統制という幻想、「適合しているモデルは正確だ」幻想。
- 意思決定における回帰分析の利用につきまとう幻想として、先生は2つ挙げておられる: 統計的有意性の幻想("One might also ask if there is a study wherein statistical significance improves decision-making" とのこと。そうかもね)、相関を因果性と取り違えてしまう根強い幻想。
先生が推薦するところの、事前知識をフル活用したアプリオリな手法として、index method というのが紹介されているのだけれど、説明が短くてよくわからなかった。Armstrong & Graefe (2011, J. Business Res.)がreferされているが、先生はやたらに著作の多い方らしいから、きっと他のにも書いてあるだろう。
読了: Armstrong(2012) 回帰分析にまつわる幻想
2011年12月24日 (土)
Soyer, E., & Hogarth, R. (2012) The illusion of predictability: How regression statistics mislead experts. International Journal of Forecasting, forthcoming.
経済学者たちに回帰分析についてのクイズを送りつけ,どう間違えるのか調べました,という論文。性格わるー。たのしー。
クイズはこんな感じ。経済学の論文風のフォーマットで単回帰分析の結果を見せて (たとえば,回帰式 Y=0.32 +1.001X, YのSDは40.78, R^2は0.50)、
- Q1: 95%の確率でY>0となる最低のXは?
- Q2: X=0である別のYよりもYが95%の確率で大きくなる最低のXは?
- Q3: βの95%信頼区間が(0.936, 1.067)、X=1であるとき、Y>0.936となる確率は?
- Q4: X=1のとき、Y>1.001となる確率は?
えーと,正解は... まず標準誤差(SER) = sqrt((40.78^2)*(0.50))=29 を求めておいて,
- Q1: (0.32 + 1.001X)/SER = 1.645 となるX, すなわち47。
- Q2: (Y_i | X_i=c)と(Y_i | X_i = 0) という2つの独立な確率変数の差の分布について問われているんだから,答えは(0.32 + 1.001X)/sqrt(SER^2+SER^2) = 1.645 となるX, すなわち67。
- Q3: (0.32 + 1.001*1)+残差が0.936を上回る確率,つまり残差が0.936-(0.32 + 1.001*1)=-0.385を上回る確率を問われているんだから,答えはN(0,1)で-0.385/SER=-0.013より右側の面積,すなわち0.51。
- Q4: 残差が1.001-(0.32 + 1.001*1)=-0.32を上回る確率は,N(0,1)で-0.32/SER=-0.01より右の面積,すなわち0.50。
さて,その結果は... Q1, Q2に対してはすごく小さな値,Q3に対しては大きな値を答える人が多い。ところがQ4はだいたい当たる。Q3の0.936とQ4の1.001には大して差がないのに。
著者らいわく,回答者は誤差項のことを忘れがちである。だからQ1, Q2では必要なXを小さめに見積もる。いっぽう係数の誤差については敏感である。だからQ3では確率を高めに見積もる(βの信頼区間の教示に引きずられて,という意味であろうか)。
さて,この傾向は,問題文の係数の値を変えても,R^2を下げても変わらない。一緒に散布図をみせても変わらない。ところが,回帰分析の結果の表をみせずに散布図だけをみせると,正解率は急上昇する。ただし回答者は「回帰係数をみせてくんないと困るよ」と文句を云う(面白い!)。
著者らいわく,この問いは経済学者にとって確かにトリッキーだったかもしれない。彼らはふだん,変数の有意性について検討するために回帰分析を使っているからだ。しかし,彼らがつくったモデルは予測ツールとして意思決定に用いられることがありうる。だから,回帰分析の結果から,たとえばある政策が「平均的に」ポジティブな影響をもたらすかどうかを読み取れることだけでなく,その政策のせいでネガティブな影響を受ける人がどのくらいいるかを読み取れることも大事なのである。改善策としては,単にモデルを示すだけでなくシミュレーションも示すのがいいんじゃないか。云々。
仕事からの逃避でぱらぱらめくっていたんだけど,いやあ,面白かった。俺自身は経済学のことはさっぱり疎いし,関心もあまりないのだが,回帰モデルのような統計モデルが人々に illusion of predictability を与えるというのは常日頃から痛感するところである。逆に実務家の方で「統計学なんてテンで当てにならねぇよバーカバーカ」と言い放つ方が時々いらっしゃるけれど,あれもまたこのillusionの反動なのではないかと思う次第である。
話の本筋からは離れるけれど,予測を巡るこのバイアスは,昔のTversky & Kahnemanとかによってすでに指摘されていたりしないのかしらん? で,もっと一般的な認知法則の発現例として説明できたりしないのかしらん? 代表性ヒューリスティクスとか。
読了: Soyer & Hogarth (2012) 経済学者が回帰分析に抱く幻想
2011年12月22日 (木)
Castro, S.L. (2002) Data analytic methods for the analysis of multilevel questions: A comparison of intraclass correlation coefficiens, r_{wg(j)}, hierarchical linear modeling, within- and between-analysis, and random group resampling. The Leadership Quarterly, 13, 69-93.
階層的データのいろんな分析手法を紹介し、同じデータに適用して結果を比較してみせる啓蒙論文。扱われているのは、級内相関係数(ICC), Jamesらのr_{wg(j)}, 階層線形モデル (HLM)、within- and between-analysis(WABA), それからrandom group resamplingというなにやらbootstrapみたいな手法。
WABAについて知りたくてざざざーっと目を通した。他の話題は完全に飛ばし読み。ICCだとかgeneralizability theoryだとかなんとか、ああいうの昔っから大の苦手なのである。
WABAはFred Dansereauという組織研究の先生が唱えている方法らしく、これはなかなか面白そうなのだが、日本語での説明はどこかの紀要の簡単な紹介くらいしか見当たらない。この論文によれば、どうやら分散分析で全平方和を分解するような感じで、全体の相関係数を階層に分解していくらしい。へー。詳しくは Dansereau et al. (1984, 書籍), Yammarino & Markham(1992, J. Applied Psych.), George & James(1993, J. Applied Psych.), Schriesheim(1995, Leadership Qtr.), Yammarino(1998, Leadership Qtr.) あたりをみよ、とのこと。どうやらメジャーな方法とは言い難そうだ。
階層的データ分析についてはちょっと面白い経験をしたことがあって... 前に市場調査の業界団体が統計手法のセミナーを主催したことがあり、私もちょっとだけ喋らせて頂いたのだが(思えば申し訳のないことだ)、ある講師の方がHLMを紹介しておられて、ちょっと気づかないような面白い話題もあり、勉強になった。で、客席には当時の勤務先の社員も何人かいたのだけれど、あとになって,先日のセミナーの内容を報告しなければならない、ついてはあの階層の話がよくわからなかったんですが...という。内容がわからないというより、実務における必要性がぴんとこない、というのである。いやいやこんなに身近な話はないのよ... と力説してみたのだが、いまいち納得してもらえなかった。
これは聞き手の問題でもなければ(優秀な人であった)、説明が下手だからでもなく(私の説明はともかく、講師の方の説明はとてもわかりやすかった)、なにかもっと本質的な事情があるのではないかと思う。もしかすると、「なぜデータの階層性を無視してはいけないのか」という話は、データの分析を通じて得られる知見の(外見上の)豊かさと直接に関係しないから、実際にその手のデータと向き合って半泣きになるような目に合わないことには、その必要性を実感しにくいのかもしれない。そう考えてみると、データ解析にも派手な話題と地味な話題がありそうですね。どうせ勉強するのならもっと派手目な話題のほうが、人生少しは楽しいかもしれない。
2011年12月19日 (月)
基本的にはヒマ・ライフを謳歌しているように思うのだが,先週は「年に一度」級の忙しさで,なにかをきちんと読むどころの騒ぎではなかった。これは飯のついでに目を通した論文。
Bennett, C.M., Baird, A.A., Miller, M.B., Wolford, G.L. (2010) Neural correlates of interspecies perspective taking in the post-mortem Atlantic Salmon: An Argument For Proper Multiple Comparisons Correction. Journal of Serendipitous and unexpected results, 1(1), 1-5.
鮭の死体をfMRIに入れて社会的視点取得課題を与えたら、なんと脳のある部位が活性化しました、とのこと。ははは。もちろんこれはプラクティカル・ジョークで、ちゃんと多重比較法を使って検定しないと変な結果が出ますよ、という主旨である。
twitterである方が呟いていたのを見て知った論文。掲載誌はこれから創刊するオープンアクセス誌だそうで、どこまで本気なのかよくわからない。
正しい分析方法として、ボンフェローニ法のようなfamily-wise error rate調整とあわせて、false discovery rate (FDR)調整も紹介されていた。fMRIのソフトにはFDRの機能が入っているのもあるんだそうだ。FDRって統計学の本でしか読んだことがなかったのだが、実際に使われているんだなあ。以前から一度使ってみたいと思っているのだが、まだ機会がない。
そういえば先日、知人に「市場調査であんまり多重比較法使わないのはなぜだろうね?」と尋ねられ、仮にそうだとしたらそれにはいろいろと理由はあるんだろうけど、検定力の低下もそのひとつかもなあ、と思った。FDRには一定のニーズがあるかもしれないと思う。
それにしても、なぜ鮭だったのかしらん。鮭鍋パーティでも開いたのだろうか。
読了:Bennett, et al. (2010) 死んでるシャケの脳活動
2011年12月10日 (土)
Martin, A.D., Quinn, K.M., Park, J.H. (2011) MCMCpack: Markov Chain Monte Carlo in R. J. Statistical Software, 42(9).
RのMCMCpackパッケージの解説。回帰モデル(ロジスティック, プロビット, ポワソンを含む)、IRTモデルや因子モデル、変化点モデルなどのMCMC推定が可能とのこと。
こういうの、ふつうは使いながら覚えるものだと思うのだが、私は先にトリセツを読まないとなんとなく落ち着かないのである。損な性分だ。
読了: Martin, et al. (2011) MCMCpack
2011年12月 3日 (土)
Koppelman, F.S., Wen, C.H. (2000) The paired combinatorial logit model: properties, estimation and application. Transportation Research Part B, 34, 75-89.
離散選択モデルのひとつであるpaired combinatorial logit モデル (PCLモデル) がいかに優れておるか、という論文。PCLモデルとは、multinominal logitモデルのIIA特性を緩和したモデルのひとつで、nested logit モデルをさらに大げさにしたような奴。選択肢のすべてのペアがそれぞれひとつのネストをつくっていると考える。選択肢が3つあったら、選択肢1はネスト{1,2}とネスト{1,3}に属しているわけだ。
恥ずかしながらこの論文を見つけたときは、paired combinatorial logitだって!! そんな手法があるのか!! nested logit とちがって事前に構造を決めなくていいじゃん!! やったぜ俺!! 検索の天才!! と思ったのである。で、喜び勇んで読み始めたら、だんだん疑念がわいてきて... 先日どさっと買い込んだ本のなかの一冊、たぶん有名な教科書であるTrain(2009)を調べたら、ちゃあんと載ってました。この論文の著者の研究も引用されてました。離散選択モデルの世界では有名なモデルなのであった。よく知らない分野の話を毎度付け焼刃で勉強しているから、こういうナサケナイ目にあうのである。というわけで,意気消沈して後半から流し読み。
ところで、ずぶの素人としては、そうまでしてIIA特性を緩和したいんならさっさと多項プロビットモデルを使えばいいんじゃないですか? 早いPC買ってきてシミュレーションでガンガン解けばいいんじゃないですか?という気がするのだが、その道の方々にはなにかしらの事情があるのだろう。ぼんやりディスプレイを眺めて待ってんのが嫌だとか。閉形式のほうがクールだとか。
里村卓也(2008) 消費者の理論的選択モデルに関する考察. 三田商学研究, 51(4), 121-133.
ネットで拾った論文。私がお名前を知っているくらいだから、著者はマーケティング研究の分野で有名な研究者だと思う。前半は経済学的な観点からの、予算制約下での効用最大化モデルの紹介。複数商品の選択もカバーできる(バラエティ・シーキングの分析に使われている由)。後半は選択の文脈効果を統一的に説明する数理モデルの紹介。Busemeyerのdecision field theoryの拡張とか(ムズカシイ...)。
論文の主旨からは外れるのだが、マーケティングの分野で用いられるモデルを誘導型(reduced form)と構造型(structural form)に区別しているところ、勉強になった。前者は「理論を用いてデータ間の関係を記述し、その後はその理論にたちもどらずに誘導されたモデルだけからデータを解析する方法」。ただし、「理論モデルを利用することなく統計モデルとデータだけを利用して知見を得ようとするデータ主導の方法」を含めることもある。後者は「企業や消費者の意思決定過程をモデル化し、統計モデルとデータからモデルの同定を行う」方法。
なるほどねえ、便利な用語だなあ、と腑に落ちたのだが、具体例に当てはめて考えると、これは案外ややこしい話だと思った。いい例ではないかもしれないが、ある事柄についての態度項目についての探索的因子分析を行う人のなかには「各項目への回答はその回答者が持っている少数個の潜在的態度を反映しているのだ」と心的な反応生成メカニズムに踏み込んで解釈する真剣な人と、「なんでもいいから似た項目がまとまればいいや」とか「回答の傾向が少数の因子得点に縮約できればハッピー」としか考えていない呑気な人がいると思う。因子分析モデルは前者の人にとっては構造型、後者の人にとっては誘導型ということになろうか。このように、同じ数理モデルが異なる思惑で用いられている例を、ほかにもたくさん挙げることができるだろう。さらにややこしいと思うのは、特定の理論的見地が深く刻み込まれているモデルがその理論抜きで使われている場合で、たとえば、消費者の補償型購買意思決定など露ほども信じていないけど、コンジョイント分析で売上シミュレーションしちゃう、なんていうのがそれだと思う。
気になって、引用されているChintagunta et.al.(2006)の該当箇所も読んでみたのだが、彼らが書いているように、これは relative weights placed on data fitting [...] versus relying on theory in building an econometric modelという話なのですね。モデルが2つのタイプにパキッと分かれるというより、theory-drivenとdata-drivenの連続体上に位置するという感じの話なのだろうと思った。と同時に、ある人が道具として使うモデルの成り立ちと、その人のアプローチとは分けて考えたほうがいいなあ、などと思った。
こんなことについてあれこれ考えてしまったのは、ぼんやりしているとついつい理論的負荷を帯びまくった構造型モデルのほうがカッコいいように思えるからであって(理由1:理論さえ正しければ外挿的予測が可能だから; 理由2:なんか頭良さそうにみえるから)、要するにちょっと動揺しただけである。
読了:里村(2008) 消費者の理論的選択モデル; Koppelman&Wen(2000) paired combinatorial logit モデル
2011年12月 2日 (金)
ただいま 「なんであれ読んだものは記録」 強化期間中につき,論文のメモを二件。すぐに飽きるような気がしてきたが。
土田尚弘(2010)「マーケティング・サイエンスにおける離散選択モデルの展望」, 経営と制度, 8, 63-91.
掲載誌は首都大の経営学専攻の紀要。著者は朝野先生のお弟子さんだと思う。こういうレビュー論文、ほんっとに、ものすごく助かります。ありがたや、ありがたや。
選択モデルの誤差項に相関を許すかどうかと、そのモデルがIIA特性を持たないかどうかは同じではない由。知らなかったー。
Temme, D., Paulssen, M., Dannewald, T. (2008) Incorporating latent variables into discrete choice models: A simultaneous estimation approach using SEM software. BuR – Business Research, 1, 220-237.
できれば新しいことは勉強したくないわけですよ! いまさら何を学んだってどうなるものでもないんだから! 手早く済ませて酒でも飲みたいのですよ! という心の叫びに従って読んだ論文。あれもこれも全部Mplusだけで済ませることができたら助かるなあと思って。掲載誌はドイツのオープンアクセス誌で、どういう位置づけの雑誌なのかわからない。
個人属性を表す潜在変数を効用の説明変数にした離散選択モデルをMplusでつくったよ、という内容。Mplusは名義尺度の従属変数をそのまま扱えるから、まあそりゃできるでしょうね、という話ではある。事例は交通手段の選択で、中身には全然関心ないので飛ばし読み。好きな乗り物に乗らせとけばいいじゃないですか。
要するにSEMと多項ロジットモデルを合わせましたという話であって、てっきり有限混合分布が出てきたりIIA特性の緩和の話が出てくるのかと思っていたのだが、その実例は結局出てこなかった。がっくり。ま、スクリプトが載っていたから、いずれなにか助かることがないとも限らない。
論文の趣旨からはちょっと離れるが... 離散選択モデルのマーケティング分野での適用としては、コンジョイント分析とスキャンデータの分析が思い浮かぶが、前者の場合はたいてい、まずは選択データで個人レベルの部分効用を求めましょう、しかるのちにそれと個人属性との関係を調べましょう、という風に考えると思う。選択モデルに個人属性を埋め込んで同時推定したほうが洒落てるじゃんと思い、実際それに近いことを周囲に提案したこともあるのだが、そんなんワケワカランからやだ、という反応であった。ま、その気持ちもわかる。そんなこんなで、そもそも同時推定を誰がいつ必要としているのか、という点についても考える必要があると思う。
いま調べたら、第一著者は前に読んだ順序尺度指標の測定不変性についての論文の著者でもあった... どうもお世話になってます。
読了:土田(2010)「MSにおける離散選択モデルの展望」; Temme, et.al. (2008) 「潜在変数入りの離散選択モデルをSEMのソフトで同時推定」
2011年11月30日 (水)
大した仕事をしているわけでもないのに,なんだかんだとバタバタしていて,読みたいものもろくに読めないし,読んでも記録する暇がない,という日々であった。情けないことだ。
久々に面白い論文を読んだので,これを機に,ちゃんと一々記録するように心がけたいと思う。
Muthen, B., Asparouhov, T. (in press) Bayesian SEM: A more flexible representation of substantive theory. Psychological Methods.
SEM方面の神様Muthen先生による、SEMのパラメータ推定をベイズ流にやるとこんなに素敵なことがあるよ、Mplusに実装したから使ってね、という論文。数理技術的な理屈はパスして、ユーザにとっての利点の話に徹している。
子のたまわく、ベイズ流アプローチの利点は4つ。(1)パラメータ推定やモデル適合についてもっといろいろわかります。(2)小標本でも優れたパフォーマンス。(3)計算も楽。(4)これまでに作れなかったモデルが作れます(ランダム変化点モデルとか)。
論文中の説明はCFAが中心。常識的には、CFAモデルは因子パターン行列にある程度ゼロを埋めないと識別できないが、ベイズ流にいえばこれはその箇所に平均ゼロ分散ゼロの事前分布を与えることに相当している。で,かわりに多少の分散を持つ事前分布を与えたってMCMCは収束する。こうして,分析者の知識に応じてゼロ埋めなしのCFAモデルが推定できる。先生はこういうのをBSEMと呼んでおられる。EFAとCFAのあいだを埋めるような使い方ができるわけだ。
残差相関もBSEMでモデリングできる。(1)残差共分散行列を対角じゃない行列と対角行列に分解し、前者について逆ウィシャート事前分布を与えるやりかた、(2)残差共分散行列そのものに逆ウィシャート事前分布を与えるやりかた、(3)個々の残差共分散に正規事前分布を与えるやりかた、がある由。
後半は実データとシミュレーションによるデモ。面白かったのは... 各因子が5つの指標を負荷0.8で持つ単純構造の3因子CFAモデルを考え、n=100のデータをつくり、正しいCFAモデルを当てはめて推定する。ML推定での尤度比検定でモデルが棄却されちゃう確率は? 有意水準5%ならまあ5%くらいだろう、nが大きいとカイ二乗値はデカくなりすぎるというけど、まあn=100なら大丈夫かな... と思ったのだが、この論文によれば実に17%である由。真の因子負荷がほんとに単純構造ならば、この確率はむしろnが大きいときに5%に近づく(なるほど)。なおベイズ流アプローチ(無情報事前分布を使用)ならば、nに関わらず3%くらい。
では、不幸にして真の構造にcross-loadingがあった場合はどうか。負荷0.1を持つ指標が3つあるとき、モデルが棄却されてしまう確率は、n=100で23%, n=400だと実に46%。たった0.1の負荷ごときで、こいつはちょっと厳しすぎるんじゃないですかね、という話である。ベイズ流アプローチならば、それぞれ6%、26%とのこと。
読了:Muthen&Asparouhov(in press) ベイジアンSEM
2011年6月24日 (金)
Calder, B., Phillips, L., Tybout, A. (1982) The concept of external validity. Journal of Consumer Research, 9(3), pp. 240-244.
Lynch, J. (1983) The role of external validity in theoretical research. Journal of Consumer Research, 10(1), pp. 109-111.
Calder, B., Phillips, L., Tybout, A. (1983) Beyond external validity. Journal of Consumer Research, 10(1), pp.112-114.
個々の理論検証的研究においては外的妥当性はそんなに大事じゃないよ、という短い意見論文→引き合いに出されたLynchさんの反論→返答、という一連のやりとり。Campbellの外的妥当性/内的妥当性の区別について調べたかっただけなのに... 読みながらだんだん関心をなくしてしまってナナメ読み。
読了: Calder, Phillips, Tybout (1982), Lynch(1983) 外的妥当性は重要か論争
2011年6月15日 (水)
Strauss, M.E., Smith, G.T. (2009) Construct validity: Advances in theory and methodology. Annual Review of Clinical Psychology, 5, 1-25.
測定の妥当性についての最近の展開を知りたくて読んだレビュー。なにか資料を探していて、clinical psychology関係の雑誌の論文をみつけると、やったあ、って思いますね。概して数学が苦手な臨床心理学関係者向けに、親切な書き方になっていることが多いように思うもので。。。すみません、失礼をお許しください。
妥当性研究の歴史のあたりについてメモ:
- 初期の妥当性研究として知られているのが、米陸軍のWoodworth Personal Data Sheet(1919)。これは情緒的安定性の測定で、まず神経症患者のケース記録から項目を集め、次に健常者の回答に基いて項目を削った。この手順からみて、測定の妥当性についての考慮があったわけだ。しかしなにぶんにも精神病理学的知識が不十分な時代の話であり、神経症という概念も精緻化されておらず、出来上がった116項目はあまりに多様であった。また、きちんとした外的基準もなかった。
- 20世紀中盤まで、測定の妥当性はもっぱら予測的妥当性として理解されていた。Anastasi(1950)というひとはこう書いているそうだ:「テストの妥当性を客観的に調べることができるのは、それが明確に定義された基準についての測定である限りにおいてである。テストがその外的基準以外のなにかを測っているという主張は、なんであれただの思索にすぎない」。ううむ、強気だなあ。このアプローチは心理検査に多大な影響を与えた。たとえば、広く用いられている性格検査のひとつであるMMPIの項目は外的基準の予測という観点で選ばれている。いっぽう、こういう基準関連主義にはふたつの限界がある:(1)外的基準には妥当性があることが前提となっている。(2)理論の発展に寄与しない。
- 50年代から上記(2)のタイプの批判が高まり、Meehl&ChallmanによるAPA心理検査部会勧告に結実する(1954)。構成概念妥当性という概念の登場である。
- 臨床心理の分野では、50年代の4つの研究が理論展開の原動力となった。
- MacCorqudale & Meehl(1948)による仮説的構成概念の基礎づけ。
- Cronback & Meehl (1955)による構成概念妥当化の方法論の定式化。妥当化が演繹的プロセスであることが強調された。
- Loevinger(1957)による理論構築のなかでの妥当化の役割の定式化。構成概念妥当性は予測的妥当性・併存的妥当性と内容的妥当性を包含する概念であるということになった。
- Campbell & Fiske(1959) による、MTMM行列による妥当化の提唱。収束的妥当性と弁別的妥当性の区別がここで登場した(Campbellらはこの段階ではどちらも同程度に重視している。のちに収束的妥当性のほうをより重視するようになった)。
- Cronback & Meehl(1955)にいわせれば、妥当化(validation)とは結果ではなくプロセスであるわけで、だからある測定の妥当性が「示されました」という言い方はおかしい。
どうやら、構成概念妥当性を「ザ・妥当性」として包括的に捉える考え方は、すでに50年代からあったらしい。では、よく本に載っている「妥当性には基準関連妥当性と内容的妥当性と構成概念妥当性があります」という話はどこからやってきたのだろうか。あれこそAPAの基準が典拠だと思うのだが。よくわからんなあ。
ほかに面白かった話:
- Whitely(1983, Psych.Bull)は、妥当性をnomothetic spanとconstruct representationの二面に分けて考えようと主張している由。前者は他の概念との相関、後者は測定の基盤にある心的メカニズムを指すらしい。これは話の整理に役立つなあ。今の仕事の関連でも、このふたつがごっちゃになって混乱することがあると思う。
- ずっと前にBorsboomという若い人の、「法則定立ネットワークだのなんだのって奴らはみなアホだ」と関係者に喧嘩を吹っ掛けるような論文をみた覚えがあるが、著者らは一部賛成、しかし「理論たるものは明確に定式化されてないといけない」という点には反対、である由。
- 論文の後半はMTMM行列の分析の最近の進展について。いずれも知らない話ばかりだったが、いずれ必要になったら読み直そう、と流し読み。
最近折にふれて、前の勤務先(市場調査の会社)で働きはじめた5年前のことを思い出す。市場調査のことなんてもちろん全然知らなかったから、いろいろ戸惑うことが多かったものだ。そのころ面食らったことのひとつに、たとえば集計値の信頼区間の話をしているときに、まあ「買いたい」と答えた人が必ず買うとも限らないんだから、購入意向の信頼区間なんて考えたってねえ... などという話を始める人がいる、ということだった。いやいや、犬は犬で猫は猫、信頼性は信頼性で妥当性は妥当性でしょう、ちがう話をごっちゃにする人に明日はないですよ、と思わず憤ったわけだが、長年この仕事をしていた人でさえそうだということは、この混乱にもなにかしら俺の知らない背景と意義があるはずだし、第一、ちがう話をきちんと分けたからといって、俺に輝かしい明日が開けるわけでもない。
まあそれはともかく、そのとき思ったのは、どうやらこの業界では測定の信頼性と妥当性をあまり区別していない人が多いようだ、ということだったのだが、それがなぜなのかが不思議であった。というのは、そのまた前のご奉公先(教育産業)で会った人々のことを思い出すと、データ解析についてのトレーニングなど受けていなくても、この手の話には理解が速く的確であったように思うからだ。いまにして思えば、主に集団レベルの特性に関心を持つ消費者調査の関係者と、たとえ集計値をみていても本質的には個々人に関心を持つ教育関係者の違いかもしれない。
読了:Strauss & Smith (2009) 構成概念妥当性レビュー
2011年6月 9日 (木)
Bentler, P.M. (2010) SEM with simplicity and accuracy. Journal of Consumer Psychology, 20(2), 215-220.
昼休みには仕事と関係ない本を持ち歩くことが多いのだが、いま読んでいる本がちょっと面倒な内容だもんで,どうもその気になれず、かわりにこれに目を通した。うーむ、現実逃避だなあ。。。
えーと、このJ. Consumer Psychologyという雑誌に(かなりマイナーな雑誌だと思う)、2009年にIacobucciさんという方がSEMの啓蒙論文を書いた。市場調査の有名な教科書を書いた方ですね。タイトルは"Everything you always wanted to know about SEM but were afraid to ask"、ウディ・アレンのもじりであろうか。ところがこの論文が、古参のソフトウェアLISRELに準拠し、ギリシャ文字てんこ盛りのヤヤコシイ書き方をしているのだそうで、これではいかん、わしがもっともっと簡単に説明してみせよう... と、かのBentler先生がおんみずから乗り出してきてお書きになった、超簡単なSEM入門。「簡単な」というのは、要するに「わしが開発したEQSに準拠して」ということである。はっはっは。
ついでに元論文の誤りや不十分さを指摘する記述があったが,そちらは元論文が手元にないのでよくわからなかった。そのほかのコメントは,IacobucchさんはLMのような修正指標の使用について否定的だがわしはそうは思わん,ランダム欠損に対するわがtwo-stage ML法の威力を知るがよい,などなど。ははぁー(平伏)。
読了: Bentler(2010) SEMについて簡単かつ正確に語ろう
2011年6月 8日 (水)
Friedman, L. & Wall, M. (2005) Graphical views of suppression and multicollinearity in multiple linear regression. The American Statistician, 59(2), 127-136.
机に積んである資料の山にちょっと飽き飽きしてきたので、息抜きとしてぜんぜん関係ないやつに目を通した。以前読みかけて途中で放置していた論文。たしか、講義だか社内研修だかの準備で、抑制変数という言葉の定義について調べているときに見つけた論文だったと思う。
重回帰における抑制と多重共線性についてわかりやすく説明する図示手法をご提案します、という内容。知っている人はみんな知っている抑制という概念だが(そりゃそうか),これが案外あいまいなものであって、著者らの整理によれば:
- 抑制についての最初のフォーマルな議論は Horst(1941) という文献なのだそうで、そこでは(1)従属変数と相関がなく、(2)他の独立変数と相関し、(3)重回帰に投入するとR^2が増える、ような変数のことを抑制変数と呼んでいる。これが古典的な定義らしい。Cohen&Cohenの重回帰の教科書(2003, 3rd ed.) もだいたいそんな感じ。
- Darlington(1968, Psych. Bull.)は、独立変数と従属変数との相関はすべて非負なのに偏回帰係数が負になる場合を指して抑制と呼んだ。Conger(1974)はこれを拡張し、相関の正負を問わず、「それを重回帰式に含めることで他の変数(群)の予測的妥当性が高くなる」ような変数を指して抑制変数と呼んだ。Tzelgov & Stern (1978, Edu. Psych. Measurement) もこのラインで、「すべての独立変数において、従属変数との相関の絶対値よりも偏回帰係数の絶対値のほうが大きい」場合を指して抑制と呼んでいる。
- いっぽうVelicer(1978)はもっと限定的に、「独立変数と従属変数との単相関の二乗の和より、重回帰のR^2のほうが大きい」場合のみを指して抑制と呼んでいる。
著者らはVelicerのいうところの抑制を「拡張」、拡張ではないがTzelgov & Sternのいうところの抑制であることを「抑制」、他の場合を「冗長」と呼ぶ。で、X1, X2, Y の3変数を考え、YとX1, YとX2の相関を固定し、X1とX2の相関を横軸、R^2や標準偏回帰係数を縦軸にとったグラフを描き、抑制・拡張・冗長がいつ起きるのかを図示する。
なんというか、頭の体操としては面白かったのだけれど。。。この論文の視点は、所与の相関行列のもとで重回帰式の振る舞いを調べる、というものである。たとえば、X1とYの相関を+0.8, X2とYの相関を0に固定し、X1とX2の相関を動かしたら、重回帰のR^2はどうなるか? X2とYとの相関が+0.4だったら? という風に考えていくのである。正解は「X1とX2の相関が0から離れるほど高くなる」「+0.6から離れるほど高くなる」。納得するために、コーヒー片手にしばしベランダで外を眺めなければならなかった。
いやはや、こういう考え方ってかえってわかりにくくないですか? 所与のパスモデルのもとでの相関行列と重回帰式の振る舞いについて考えるほうが、どうみてもわかりやすいと思うんだけど。そんなことないっすかね。単に俺の修行不足だろうか。
読了:Friedman & Wall (2005) 重回帰における抑制と多重共線性の図示
2011年5月30日 (月)
原因の有無を行、結果の有無を列にとった2x2分割表に基づいて因果的効果の強さを調べるとき、各行ごとに結果が生じた割合を求め,行のあいだでその比をとることが多い。疫学でいうところの相対リスク(RR)である。
しかし,列周辺度数が固定されている場合には相対リスクは求められない。たとえば,結果が生じた人を100人,生じなかった人を100人集めてきました,というような場合がそうだ(医学の分野ではこういうのをケースコントロール研究という)。その場合は代用としてオッズ比を使いなさい、とモノの本には書いてある。オッズ比とは,行ごとに右の列と左の列の比を求め,行のあいだでその比をとったもののこと。これはカテゴリカルデータ分析の初歩的な知識で、俺も社員研修などでは必ず話す。
しかし、オッズ比が相対リスクを近似するのは、結果の生起割合が0に近い場合に限られる(rare disease assumption)。そりゃ医学統計の人はいいでしょう,結果はたいてい発症や死亡で、生起割合はたいてい低いから。でも調査データ分析一般において,いったい生起割合がどのくらい低ければ、オッズ比を相対リスクとして解釈してかまわないのか? 自分のなかであいまいなままやりすごしていたのだが、たまたまその話を解説している記事があったので読んでみた。3頁の短い記事だが、かまうものか、なんでも記録しておくのだ。
Davies, H.T.O, Crombie, I.K., Tavakoli, M. (1998) When can odds ratios mislead? British Medical Journal, 316, 989-991.
オッズ比はRRよりも極端な方向にずれる。つまり、(a)1を下回る場合はRRより小さく、(b)1を上回る場合にはRRより大きい。著者いわく、(a)の場合、解釈上の実害はさほどない(0.5を半分にしたって0.25、数字がそんなにかわらないから)。しかし(b)の場合には誤解を生むことがある(2の倍は4、数字が大きく変わる)。
オッズ比とRRのずれは、原因がないときの生起割合(初期リスク)が大きいほど大きくなり、オッズ比が1から離れている時ほど大きくなる。オッズ比が1より大きい場合、だいたいの目安として、初期リスクとオッズ比をかけた値が100%以下なら、オッズ比はRRの2倍以下におさまっている... とのこと。
いまwebでみたら,この記事には批判コメントが寄せられていて,いわく,著者らはデザインのことをちゃんと考えていない。そもそも実験やコホート研究ならばRRを算出すればよい。いっぽうケースコントロール研究の場合,対照群を適切に抽出しているならば(incidence density sampling),生起割合が高くったってオッズ比はRRを表す。
ちょっと検索してみたところ,rare disease assumptionは古典的な固定コホートを前提にした議論で,動的コホートを前提にした議論では,ケースコントロール研究のデータが曝露オッズを保持したまま抽出されているのなら,生起割合がどうであれオッズ比はすなわちRRである由(Greenland&Thomas,1982)。。。そういえばこの話,前にどこかで読んだような気がしてきた。勉強してもなかなか身に付かない。イヤになっちゃうなあ。
読了:Davies, et. al. (1998) オッズ比がまずいのはどんなとき?
2011年5月26日 (木)
Hayduk,L., Cummings, G., Stratkotter, R., Nimmo, M., Grygoryev, K., Dosman, D., Gillespie, M., Pazderka-Robinson, H., Boadu, K. (2003) Pearl's d-separation: One more step into causal thinking. Structrual Equation Modeling, 10(2), 289-311.
統計データから因果関係を推測するという分野では、最近はPearlの枠組みについて学ぶのがもはや必須となっている模様なのだが、あいにく用語が独特で、俺のようなど素人には非常にハードルが高い。
よく引用されるPearl (2000) "Causality"には邦訳まで出ていて、仕方がないので大枚はたいて買い込んだものの、たとえば,重要概念であるd-分離(有向分離)についてのPearlの定義はこんな感じである:
道pが次の条件のいずれかを満たすとき,道pは頂点集合Zによって有向分離される(あるいはブロックされる)という。
(1)道pは,ある頂点mがZに含まれるような連鎖経路 i → m → j あるいは分岐経路 i ← m → j を含む。
(2)道pは,mもその子孫もZに含まれないような合流経路(または合流) i → m ← j を含む。
集合ZがXの頂点とYの頂点の間の全ての道をブロックするとき,集合ZはXとYを有向分離するという。(黒木訳「統計的因果推論」pp.16-17)
あはははははは。
この論文は哀れなSEMユーザに向けて,ただd-分離という概念だけについて,20頁近くを費やして徹底的な解説をお送りする,というもの。あんたらこれをきっかけにPearlの本を読むがいいさ,というきわめて啓蒙的かつお節介な論文である。Pearlの邦訳書にトライする前の景気づけに,と思って目を通した。
Hayduk先生は読者の知識レベルをちょっと低めに見積もっておられるようで... なんというか,内容よりも説明のテクニックについて学ぶところ多かった。いま俺は市場調査に関連する仕事をしているが,調査結果を解釈する人("リサーチャー")は日々多次元クロス表と悪戦苦闘している。それはそれで素晴らしいことではあるものの,あまりに無原則にデータを層別するのはselection biasの観点からみて危険なのであって,そのあたりの事情を理解してもらうにはどうしたらよいかと,あれこれ試行錯誤したことがあった。この論文では,(1)x+y=zとなるような3つの調査項目の実例を挙げ,(2)x, y, zからなる立方体のなかに平面z=x+yを描き,(3)任意のz=cについて立方体を水平に切り,その断面においてはy=-x+cであることを図示し,(4)つまりうかつにzで層別するとxとyのあいだに見かけ上の負の相関が生じるのです... というやりかたでビジュアルに説明している。これが案外わかりやすい。こういう絵を描けばよかったか。
この論文を読んでいちばん驚いたのは:パキスタンでテロリストに殺害されたダニエル・パールというジャーナリストがいたけれど,あの人はPearl 教授の息子さんだったのだそうだ。知らなかった。。。
読了:Hayduk,L.,et.al.(2003) d-分離:一歩進んだ因果的思考
2011年5月24日 (火)
Bollen, K.A., Ting, K. (2000) A Tetrad test for causal indicators. Psychological Methods, 5(1), 3-22.
統計的因果探索の有力株のひとつと名高い(そのわりにはあんまり使われていない)アプローチとして、CMUのTETRADプロジェクトがある。面白そうだからちょっと勉強しようと思って読んだ論文、なのだけれど、おなじTetradでもこれはconfirmatoryな使い方で、CMUのexploratoryな使い方とは方向性がちがう。。。ということに途中で気が付いた。アホだ。
昨年、前勤務先での出張の移動中にだいたい読み終えていたのだが、新幹線の揺れが気持ちよかったらしく、書き込みのメモの字からみて完全に夢うつつだったようだし、中身を全然覚えていない。整理がつかないのでこのたび再読した。つくづくアホだ。
BollenのCTA(confirmatory tetrad analysis)の基盤となる vanishing tetrad test を提案する論文。
いまここに変数が4つあるとする。2変数のペアは6個。6つの共分散のうち4つを取りだし、たとえば以下のように組み合わせたものをテトラッドという。変数$x_i$と$x_j$の母共分散を$\sigma_{ij}$として、
$\tau_{1234} = \sigma_{12} \sigma_{34} - \sigma_{13} \sigma_{24}$
つまり、4つの変数を正方形に並べ、頂点を結ぶ線分で共分散を表すとして、このテトラッドは2本の縦線の積から2本の横線の積を引いたものである。テトラッドにはこのほかに、$\tau_{1342}$と$\tau_{1423}$がある。ええと、前者は縦線の積と斜め線の積の差、後者は横線の積と斜め線の積の差ですね。
そんなことを考えてお前は何が楽しいのかという感じだが、面白いのはここからである。
- この4つの変数があるひとつの潜在変数のreflectiveな指標であるとしよう。つまり、潜在変数から指標に向かって4本の矢印が伸びているとする。潜在変数の分散を$\Phi$、負荷を$\lambda_1, \lambda_2, \ldots$とすると、$\sigma_{ij}=\lambda_i \lambda_j \Phi $であるから、右辺の項はすべて$\lambda_1 \lambda_2 \lambda_3 \lambda_4 \Phi^2$となり、3つのテトラッドはすべて差引0になる。これをvanishing tetradという。個々の変数の負荷がなんであれ、誤差(独自因子)がどうであれ、テトラッドはとにかく消える、というところがポイントである。
- こんどは、この4つの変数がある潜在変数のformativeな指標であったとしよう。つまり、潜在変数から矢印が伸びているのではなく、潜在変数に向かって矢印が伸びている場合だ。このときは、変数間の共分散はどんな値であってもおかしくないので、全変数が互いに独立でない限り(そしてよほど運が悪くない限り)、どのテトラッドも消滅しない。
モデル構築の際、指標が潜在変数に対してreflectiveかformativeかというのは、一義的には概念上の問題である。潜在変数が動いたせいで指標が動くなら前者、逆なら後者だ。しかし現実にはどちらとも決めかねることが多いわけで、データからサポートを得たいと考えるのは人情である。一方、一般的な共分散構造分析の枠組みでは、矢印の向きを決める方法はない(ネストしてないから尤度比検定はできない)。そこでテトラッドを使えば、すくなくとも「4つ全部がreflective」か「4つ全部がformative」かという二択の問題については、3つの標本テトラッドを観察することによって判断できるわけだ。
これを一般化してモデルの検証に使う、というのがCTAのアイデアである。指標が4つより多い場合にも少ない場合にも一般化できるし、矢印の向きだけでなく誤差相関の有無についても検討できる。
ただし、CTAを使えばすべての矢印の向きがわかるという夢のような話ではない。たとえば「4つの指標のうち1つだけがformative」な場合も、やはり3つのテトラッドが消失するわけで、「4つ全部がreflective」な場合と区別することができない。また、仮に指標がformativeであることがわかったとして、そういうモデルがSEMで識別可能かどうかはまた別の問題である。
第二著者がSASマクロを配布している模様。Rのパッケージがあるかどうかはわからない。一度つかってみたいなあ。
読了:Bollen & Ting (2000) 因果指標のテトラッド・テスト
2011年5月10日 (火)
動機や中身は問わず,とにかく論文と名の付くものを読んだら漏れなく記録しておこう。という,何度かめの決意を胸にして...
Wickham, H. (2007) Reshaping Data with the reshape Package. Journal of Statistical Software, 21(12).
Wickham, H. (2011) The Split-Apply-Combine Strategy for Data Analysis. Journal of Statistical Software, 40(1).
前者はRのreshapeパッケージ,後者はplyrパッケージについての解説で,統計学ではなくむしろデータ整形に属する内容。著者はRの世界では有名な人らしい。GGobi の関係者でもあるようだ。
reshapeパッケージというのは,たとえばフィールド{ID, X1, X2, ..., Xk} を持つ100行のデータセットがあるとき,それをまず {ID, varname, value}の3列のみを持つ100*k行のすごく縦長なデータセットに変換してしまい(これをmeltという),そこから必要に応じてデータ行列なり集計表なりを生成すると便利だ (これをcastという) ... というアイデアに基づくデータ整形パッケージ。ながらくSASをつかっているなかで,このような手順でデータを整形することが多かったので,そう悪い発想でもなかったのか,我が意を得たり,という気分である。やたらに行数が多いデータ行列ができるわけで,SASの場合はデータセットへのアクセスに時間を食うのがネックだったのだが,Rはどんなデータセットであれまるごとメモリに展開してしまうようだから,あまり問題にならないのだろう。
plyrパッケージというのは... Rを使い始めて日が浅いけど,いまもっともウンザリしているのがデータの層別処理のわかりにくさだ。apply系だのaggregateだのbyだの,たくさん関数があってどれも微妙に挙動がちがう。このパッケージはもっと整理された体系を提供してくれているようで,いっそ標準の関数は見捨ててこのパッケージだけ使い倒そうかと思い読んでみた。もっとも,このパッケージにもそれはそれでちょっとクセがある模様だ。
論文の最後に標準の関数との対応関係が整理されていて,その記述のおかげで頭が整理できたので,ま,読んでよかったということにしておこう。
見知らぬソフトウェアを新たに使いはじめ,ここがわかりにくい!ここがウンザリだ!と不平不満たらたらなのだが,冷静になってみれば,Rは確かによくできている。俺のような初心者にとってもなかなかわかりやすい代物だ。なにしろ,これまで使っていたSASのことを想えば... ああ,proc tabulate の奇妙さときたら,ODSの取って付けた感ときたら,マクロ言語の冗談じみたわかりにくさときたら。もっとも,いまはあのごった煮がちょっと懐かしいのだけれど。
読了:Wickham(2007) Rのreshapeパッケージ; Wickham(2011) Rのplyrパッケージ
2010年12月23日 (木)
何度かめの決意だけど,どんなものであれ読んだ論文は記録しておこう。
Scrutari, M., Strimmer, K. (in press) "Introduction to Graphical Modelling." In Balding, D.J., et. al. (eds.) Handbook of Statistical Systems Biology. Wiley.
arXivで拾った論文。いわゆるグラフィカル・モデリングとベイジアン・ネットワークの関係を整理したくて目を通した。事例としてmicroarrayの話をされても,いったいなんのことだか見当がつかないのだが(今調べたら「多数のDNA断片をプラスチックやガラス等の基板上に高密度に配置した分析器具のこと」だそうな。そういわれても困る),ま,分かる範囲では勉強になったのでよしとしよう。
この論文ではグラフィカル・モデルをマルコフ・ネットワーク(無向)とベイジアン・ネットワーク(有向)のふたつに分類していてるが,前者が正確にはなにを指しているのか,よくわからなかった。偏相関行列に基づき共分散選択する奴なんかがそれだと思うのだが。Whittaker(1990)を読んだほうが良さそうだ。ベイジアン・ネットワークにだってマルコフ性はあるだろうに,変な呼び方だ。
読了:Scrutari&Strimmer(in press) グラフィカル・モデリング入門
2010年10月12日 (火)
Srinivasan, V., Abeele, P.V., Butaye, I. (1989) The factor structure of multidimensional response to marketing stimuli: A comparison of two approaches. Marketing Science, 8(1), 78-88.
勤務先の仕事でアレコレ思い悩むことがあって,さんざん探した末にようやく見つけた論文。いまの悩みにジャスト・フィット,とても助かった論文なのだが,世間がソーシャルだマーケティング3.0だっていっているときに,1989年の論文を見つけて喜んでいる俺っていったい。。。
複数の刺激を対象者に提示し,各刺激に対して複数項目への反応を測定すると,刺激×対象者×項目の三相データが得られる(値が箱の形に並ぶ)。このデータを二相に落として因子分析する際には,以下の3つのアプローチがある。
- total analysis ... 全刺激・全対象者を縦積みにしたローデータから得た共変動行列 T の因子分析。
- within analysis ... 刺激ごとに求めた共変動行列 W1, W2, ... を足し上げた行列 W の因子分析。
- among analysis ...縦積みローデータにおけるすべての値を,その刺激の平均に置き換えたデータから得た共変動行列 A の因子分析。
ここで T = W + A である。では,3つのアプローチの長所と短所は? ... という論文。
なお,上の「共変動行列」は,原文ではtotal sum of square and cross product matrix。対角要素が項目の偏差平方和,非対角要素が2項目の偏差の積和である行列のこと。共分散行列をデータサイズ倍したものだといってもよいだろう。なんといえばわからないので「共変動行列」と書いたが,そんな用語があるのかどうか知らない。まあとにかく,分散分析の古い用語でいえば,Totalは全変動,Withinは級内変動,Amongは級間変動を相手にするわけだ。
この論文自体は因子分析に焦点を当てているが,論文の主旨は因子分析に限らず,項目間相関に基づくすべての分析手法に当てはまるのではないかと思う。そこで勝手に一般化すると,こういうことになるだろう:
調査対象者100人に5つの製品なり広告なりを提示し,それぞれについて複数項目への反応を得た。項目間の相関を調べる際,次の3つのアプローチがある。
- 個々の製品のローデータを縦積みしたデータ(500行)から相関を求める。これが著者のいうTotal分析。
- 個々の製品のローデータ(100行)から別々に5つの相関係数を求める。著者の言うWithin分析に近い。
- 個々の製品における平均値の行列(5行)から相関を求める。著者のいうAmong分析に近い。
当然ながら,3つのアプローチは分析に用いる情報が全く異なる。Among分析はある製品に対する反応の個人差を無視しているし,Within分析は各製品の特徴のちがいを無視している。Total分析は両方を反映しているが,逆にいえばどちらを反映しているのか定かでない。では,どのアプローチが良いだろうか? ... こうして考えると,これはすごく身近な問題ですね。
さて著者いわく,対象者の反応構造には以下の基盤がある。
- (a)「意味的類似性」。すなわち,2項目が同じ構成概念の指標だと2項目間に相関が生じる。たとえば,クルマの修理回数と信頼性は高い負の相関を持つ。
- (b)「構成概念間の因果関係の知覚に基づく認知的整合性」。2項目が別の構成概念を表しているとき,2つの構成概念に因果関係があると知覚されていると,2項目に相関が生じる。たとえば,クルマの大きさと燃費。
- (c)「環境的相関に基づく認知的連関」。これがなかなか厄介な概念なのだが,どうやら,2項目が別の構成概念を表しており,2つの構成概念の間に因果関係は知覚されていないのだが,世の中において2つの構成概念間にたまたま相関があるものだから(それがなぜかは別にして),その結果として2項目間に相関が生じる... ということらしい。例に挙がっているのは,クルマがヨーロッパ車であることとスポーツ車であること,とか,広告がeye catchingであることとinformativeであること,とか。対象者にとってはeye catchingとinformativeの間に因果関係はないが,実際にはeye catchingにするためには文字を減らさねばならず,そのためinformativeは犠牲になる,したがって広告テストにおいてeys catchingとinformativeの間に負の相関が生じる,という話であろう。
さらに,相関の分析には以下の考慮事項がある。
- (d)データサイズ。足りないと困る。
- (e)刺激に対する親近性。ハロー効果とか。
- (f)等質性。刺激によって構造が違うと困る。
- (g)反応傾向。どんな項目にも高く(低く)反応する対象者がいると,項目間に相関が生じる。
- (h)分散。そもそも項目に十分な分散がないと,まともな相関は得られない。
さて,withinとamongを比較すると ... (a)(b)はどちらにも反映される。(c)の影響はamongで大。(d)もamongで深刻だ(そりゃそうだ,製品数がデータサイズになるのだから)。(e)はどちらにも影響する。(f)はwithinでは要チェック,いっぽうamongではどうチェックしたらいいのかわからない。(g)はwithinで深刻。(h)はどちらでも深刻で,withinでは十分な個人差,amongでは十分な刺激差が必要になる。
で,著者らの主張は。。。もちろんどれが優れているとはいえないんだけど,within分析はもっと使われてよいのではないでしょうか。いっぽう,対象者間分散と刺激間分散を無条件にプールして良いような場合であれば,Total分析(ないし,三相因子分析とかPARAFACとか)がいいけれど,そういう場面って少ないんじゃないですか。とのこと。論文には出てこないけど,平均構造を導入した多母集団因子分析は,著者らのいうwithin分析にあたるだろう。
論文の後半は,広告テストの実データを用いて3つのアプローチの結果を比較しているんだけど,そこはつまんないので流し読み。
俺が因子分析の文脈を離れて,やたらに一般化して考えているせいかもしれないんだけど,著者らの発想にいまいち共感できないところがある。
はっきり書いてないけれど,著者にとっての分析対象は(a)(b)に基づく項目間構造にほかならないのではないかと思う。で,著者らが思うに,その構造は,各製品に対する対象者の反応の構造(W1, W2, ...)にも,製品の平均値の構造(A)にも,したがって全体の構造(T)にも,等しく表れているはずなのである。著者らにとっての問題は,T, W, Aのどの行列を調べればうまく真の構造にたどり着けるかということだ。(c)「環境的相関に基づく認知的連関」や(f)「等質性」は,その障害物に過ぎないのだ。
なるほど,そういう見方もあるだろう。問題は,そういう見方が適切であるような状況がどこまで一般的か,ということだ。ほかの状況を想像することだって容易である。たとえば,(a)(b)だけでなく(c)「環境的相関に基づく認知的連関」にも等しく関心がもたれるケース。広告制作者にとっては,「これまでの広告を見る限り,eye catchingとinformativeとは両立しない」と気がつくことに,大きな意味があるかもしれない(それが消費者の広告認知メカニズムにおける因果関係なのか,世の中たまたまそうなっているからなのか,そんなちがいはどうでもいいよ,と思うかもしれない)。あるいは,(f)「等質性」がないこと,つまり各刺激に対する反応の構造が異なることが前提であるようなケース。たとえば製品テストにおいて,構成概念間の因果関係(b)がどの製品でも同じだとしたら,それはどの製品でも目指すべき改善方向は同じだということを意味する。それはちょっと変なのではないだろうか? 女の子A, B, Cさんのセクシャル・アピールは肌の露出によって生じているから,同一市場で競合する女の子Dさん,あなたももうちょい露出なさい,というようなものだ。彼女の場合,黒スーツに眼鏡をかけたほうがかえって色っぽいかもしれないのに。
結局のところ,これは分析の前提と目的の問題である。total/within/amongは,特定の前提のもとで,特定の目的に奉仕したりしなかったりするのである。だから,分析アプローチの処方箋をつくるためには,具体的な課題状況に即し,そこの状況で求められうる分析目的を精緻に定義しなければならない。たとえば,著者らはWithin分析は市場の現状に縛られないという意味で新製品開発に有益ではないかと示唆しているが,新製品開発においては市場の現状を知ることだって大事だろう。つまり「新製品開発」という言葉が広すぎるわけで,コレコレな新製品開発の局面において,コレコレな前提の下では,コレコレについて知るためにwithin分析を行いましょう,というところまで詰めないと,処方箋にはならないのである。。。などと書いているうちに,だんだんご奉公先の仕事の話に近づいてきてしまったので,このへんでストップ。
読了:Srinivasan, et.al. (1989) 三相データをどうやって二相に落とすか
2010年5月26日 (水)
Wu, W.W. (2010) Linking Bayesian networks and PLS path modeling for causal analysis. Expert Systems with Applications, 37, 134-139.
sem-netで挙げられていたので気づき,著者にお願いして送っていただいた(ありがとうございました)。台湾の方で,中大に居られた由。
まずベイジアン・ネットワーク(BN)で因果構造を探索し,その構造をつかってPLSパスモデルをつくりました,という事例。ソフトはwekaとSmartPLSを使っている。冒頭のレビューのところ,とても助かる。
このアプローチは,グラフィカル・モデリング(GM)で構造をつくってSEMでパラメータ推定,というアプローチと似たようなものだと思う。いつも疑問に思うのだけれど,GMなりBNなりで因果構造を探索するとき,複数の変数がなにかの潜在変数の多重指標になっている可能性がある場合は,どういう手順を取るのがよいか。サーヴェイ・データの場合はそういう可能性が高いと思うので。
読了:Wu(2010) ベイジアン・ネットワークからPLSパスモデリングへ
2010年5月 6日 (木)
Magidson, J., & Vermunt, J.K. (2002) Latent class models for clustering: A comparison with k-means. Canadian Journal of Marketing Research, 20, 22-44.
著者はLatentGoldの開発者。潜在クラス分析とk-means法のパフォーマンスを比較した論文。2クラスを想定し,独立な正規乱数で人工データ(量的2変数)をクラス別に生成しておいて,両方の手法で分類する。潜在クラス分析のほうが全然良かったです,とのこと。
よくわからん。局所独立で,正規性があって,クラス内分散が等しい人工データに対して,局所独立性と正規性と等分散性を仮定したモデルベース分析が良いパフォーマンスを示すのは当然ではなかろうか。むしろ問題は,モデルの想定が正しくないときのパフォーマンスだと思うのだが。。。ま,2手法の違いを要約してくれている箇所は助かるので,良しとしよう。
正直言ってちょっと疲れてきた... どこかで休日をつくりたい。
読了:Magidson&Vermunt(2002) 潜在クラスモデルでクラスタリング
2010年5月 5日 (水)
Wedel, M., DeSarbo, W.S. (2002) Mixture Regression Models. in Hagenaars&McCutcheon (eds) "Applied Latent Class Analysis," Cambridge Univ. Press. Chapter 13.
潜在クラスモデルの論文集のなかの,混合回帰モデル(指標間の回帰モデルの係数について混合分布を想定するモデル)の章。意外に薄い内容で拍子抜け。でも,混合回帰モデルをつかった研究の一覧が載っているのはありがたい。
この論文集はこれでやめにして,別のを読むことにしよう。
読了:Wedel & DeSarbo (2002) 混合回帰モデル
2010年4月16日 (金)
Vermunt, J.K., Magidson, J. (2002) Latent class cluster analysis. in Hagenaars & McCutcheon (eds) "Applied Latent Class Analysis," Cambridge Univ. Press. Chapter 3.
潜在クラス論文集の第三弾。表題は「潜在クラスでクラスタ分析」という程度の意味で,量的指標と質的指標を統合的に扱う枠組みの紹介。著者はLatent Gold の開発者だと思う。事例のところで死ぬほど眠くなり,かっぱえびせん並の速度でボトルガムを口に放り込みつつ斜め読み。
わかりやすい解説であった。あいにく頭が悪いもんで,クラス内共分散行列の固有値分解のくだりがよく理解できなかったが,これは元の論文にあたることにしよう。残りの章はかなりspecificな話題なので(3パラメータ・ロジスティック潜在クラスだとか),混合回帰の章だけ目を通して,あとはもう少しマーケティング寄りの文献にあたったほうがいいかも。
はじめて潜在クラス分析を使ったとき,潜在クラスのpredictorである外生変数と,潜在クラスによって予測される内生変数(ないし潜在クラスの指標)が実質的にどうちがうのかがわからず,丸一日頭を抱えたことがあった。SEM関係のMLやMplusのサポート掲示板でもなんどか見かけた質問なので,初学者のFAQなのだろう。この論文には実にあっさりと,まあ似たようなもんよ,と書いてあった。ある意味,これは適切かつ親切なコメントだと思う。最初からそこで悩むのは生産的でない。やれやれ... よく「データの分析には経験が重要だ」なんていうけど,あれは実務家の願望に過ぎないんじゃないかなあ。多くの事柄は実務を通じて身につけるよりも活字で学んだ方が早い。
読了:Vermunt&Magidson(2002) 潜在クラスでクラスタ分析
McCutcheon, A.L. (2002) Basic Concepts and Procedures in Single- and Multiple-Group Latent Class Analysis. in Hagenaars & McCutcheon (eds) "Applied Latent Class Analysis," Cambridge Univ. Press. Chapter 2.
潜在クラスモデル論文集の2章。1章はえらい人のありがたい章という感じで,こっちがほんとのイントロダクションに相当するようだ。潜在クラスモデルの基礎的概念についてわかりやすく説明している。推定アルゴリズム(EMとニュートン・ラフソン)や適合度指標についても触れている。途中でめんどくさくなって斜め読みしちゃったけど。
潜在クラス変数をX, そのカテゴリカルな指標をA,Bとしたとき,潜在クラスモデルを
$P(A=i \ and \ B=j \ and \ X=t)$
$= P(X=t) P(A=i|X=t) P(B=j|X=t)$
というふうに,条件つき確率の積として定式化している本がある。また,2次までしか交互作用がない対数線型モデルとして,
$ln(f^{ABX}_{ijt}) = \lambda + \lambda^X_t + \lambda^A_i + \lambda^B_j + \lambda^{AX}_{it} + \lambda^{BX}_{jt}$
というふうに定式化しているものもある。俺はどっちかというと後者のほうがしっくりくるのだが,A*Bの二元クロス表から考えると,前者のほうが直観的にわかりやすいだろう。とにかく,本や論文によって定式化の方法がちがうので,いささか混乱していた。
しかしこの論文によると,両方の定式化ができるというのが潜在クラスモデルの価値を高めているとのこと。どっちの定式化でも同じ事なんだけど,一方では簡単に記述しやすい制約が,他方では記述しにくかったりするのだそうだ。その例として挙げられているのが,ある潜在クラスの下でのある指標の条件つき確率が0か1だ,という決定論的な制約。確率による定式化なら,$P(A=1|X=1) =1$ というふうに簡単に書けるが,対数線型モデルだと$\exp(\lambda^A_i + \lambda^{AX}_{it})=0$ ということになり,係数が負の無限大になってしまう。なるほどねえ... もっとも,そんな制約がいつ必要になるのか想像がつかないが。
ほんとはこんな論文を読んでいる場合ではない。潜在クラス分析関係で目を通したい資料は山積みになっているし,ほかにも「読みます!」と約束した資料があるし,そもそも講義の準備をせなばならん。ま・ず・い。。。
読了:McCutcheon(2002) 潜在クラスモデル入門
2010年4月15日 (木)
Blodgett, J.G., Anderson, R.D. (2000) A Bayesian network model of the consumer complaint process. Journal of Service Research, 2(4), 321-338.
マーケティング領域向けに,ベイジアン・ネットワークはこんなに便利ですよ,と宣伝する論文。このたび急遽ベイジアン・ネットワークの勉強をする羽目になり(「急遽××の勉強をする羽目」ばっかりだなあ),書籍には出てこない泥臭い話を読みたくて目を通した。とはいえ,これも一種の啓蒙論文なのだが。
小売店に不満を持った顧客について,クレームをつけるかどうか,今後の購入意向,他人にその店のことを話すか,などを予測するベイジアン・ネットワークを構築する。事前知識でもって決め打ちした有向非巡回グラフにデータを与えて学習させている。意外なことに,構造探索の話は全然出てこなかった。マーケティング分野の実務家はむしろそっちに関心を持つのではないかと思うのだが。
いろいろ不思議に思ったことが多かったので,二,三メモしておくが,ひょっとしたらとんでもない無知をさらすことになるかも...
- このモデルでは「クレームをつける」ノードに向かって「クレームをつけることへの態度」「問題の統制可能性の知覚」「成功の見込み」の三つのノードからパスが伸びている。すべて二値変数なので,「クレームをつける」について2^3=8行の条件つき確率表を推定していることになる。そこには線形モデルで言うところの主効果も交互作用も表現されているはずだ(という理解であっているのだろうか?)。ところがこの論文の考察においては,3つのノードをひとつずつ固定して条件つき確率の変化を調べている(2*3=6行の表について考察している)。主効果しか調べていないわけだ。しかし,ほんとに面白いのは交互作用かもしれない。たとえば「クレームをつけるのが恥ずかしくない人は,店舗に責任があろうが,文句をつけても改善されそうにないことであろうが,もう見境なくクレームをつけちゃうのだ」とか。それに,仮に交互作用に関心がないとしても,もし交互作用が存在するなら,それは主効果の大きさについての実質的解釈が難しいということを意味すると思う(交互作用のせいで主効果がなくなる場合だってあるわけだから)。
- モデルから得られた知見として,「クレームをつけない」条件下での「二度とその店舗で買わない」確率は4%,つまり「クレームをつけない不満客は逃げる」という言い伝えは正しくないのだ,と述べているのだが... そもそも「二度とその店舗で買わない」事前確率が5%なのだ。小売店に不満を持った顧客のうち,逃げるのはたった5%? これは対象者条件(不満を持った人)が緩すぎるか,「逃げていく」の操作的定義(「二度とその店舗で買わない」という回答)がきつすぎるのではなかろうか。
これは本題から離れるが。。。モデル内の変数のうち「店舗へのloyalty」などの5つの変数は多重指標を持つ構成概念であり,7件法のlikert法項目を各概念あたり3つくらい持っている。で,ベイジアンネットワークに乗せるために,レベルを離散的に表現する変数を前もって生成する。たとえば「店舗へのloyalty」ならば,「そのお店は私のお気に入りのお店です」といった項目が4つあり,それらの項目の回答で,対象者をloyalty高群と低群に分類するわけである。α係数は0.7くらい。7件法の回答はとりあえず間隔尺度データとみなすとして,さて,どうするか。
もし俺なら,PCAなり1因子CFAなりをやって,第一因子得点の高低で分けると思う。いっぽう著者らは,各指標の標準化得点を用い,k-means法で2群に分けている。k-means法を使った理由は(1)平均がきれいに違うグループをつくれるから,(2)あとで別のデータをモデルに投入するときに判別分析を使えばいいので楽だから,(3)ソフトが簡単に手に入るから,とのこと。うーむ。。。そのセンスがいまいちわからない。うまく整理できないのだが,なんだか引っかかる。
読了:Blodgett&Anderson(2000) ベイジアン・ネットワークで顧客不満の分析
2010年4月 8日 (木)
Goodman, L.A. (2002) Latent class analysis: The empirical study of latent types, latent variables, and latent structures. in Hagenaars&McCutcheon (eds) "Applied Latent Class Analysis," Cambridge Univ. Press. Chapter 1.
ちょっと事情があって,急遽潜在クラス分析の勉強をしなければならないことになり,いつか役に立つだろうと思って買ってあった論文集を,あわてて読み始めた次第。せっかくなので記録しておこう。
これは1章の概説論文,というか,どうやら超えらい人による「重し」的な章らしい。よく見たら,50年代から業績がある人だ。
前半では,2x2クロス表を例にとって潜在クラスという概念を説明。とてもわかりやすい。中盤,実は潜在クラスという考え方は哲学者のパースにまでさかのぼることができて...という話になって,へええ,と感心ながら読んでたら,突然難しくなり,ついて行けなくなった。悲しい。
落ち込んで編者の巻頭言をめくっていたら,Goodmanの章は含蓄が深いから,この本を読み終えてから読み直すがよろしかろう,との仰せであった。はい,そうします。
2010年3月28日 (日)
勤め先で真面目な話をしていて,ああ,あの用語,あの概念を会話に使うことができたら,どんなにか話が早いのに。。。とイライラすることがある。7割くらいはデータ解析系の用語,残りは心理学の用語である。もっとも他の人だって,ああマーケティング理論のあの用語が使えたらとか,経営学のこの用語がとか,前職のあの通用語がとか母国語のこの単語がとか,あのアニメの面白さがなぜお前らわからんのかとか,いいから早くうちに帰りたいとか(あ,これは俺だ),人それぞれにユニークないらだちを感じているのだろう。突き詰めて云えば,等しくどうでもいい話ですね。
それはともかく,目上・目下問わず上司同僚取引先問わず,俺と会話する可能性のある人をあまねく誘拐して無人島の研修室に監禁し,この概念を理解するまでは解放しない,というような機会がもし与えられたら(ずいぶん大きな態度だが),その概念として何を選ぶべきか。
大勢様を誘拐しておきながら急に話が小さくなってなんだが,一つだけ選ぶとするならそれはinteractionだなあ,と最近考えるようになった。要因間のinteraction(交互作用),行為者間のinteraction(相互作用)。こんな平易な概念ひとつで,物事の見通しがぐっと良くなる。俺はいま,いわゆる質問紙調査に関わる仕事をすることが多いのだが,この分野においてさえ,実験計画でいう交互作用の概念が定着すれば,いろいろな事柄がもっとスムーズに進むように思われてならない。
たとえば調査設計。なにかの事柄について質問紙調査を行い,集計表を男女間で比べたい,また年代(2水準だとしよう)の間でも比べたい,必要な集計表についてはN=100を確保したい。全体の標本サイズはどれだけ必要か? 「男女×年代の4セルについて各50,計200」という答えと,「セルあたり100,計400」という答えがありうる。周囲を観察していると,どちらの答えを採るべきか,ベテランの方はその場その場で直感的に判断できるが,その根拠をきちんと説明できる人は少ない。おかげで,調査設計に必要なのはやはり豊富な経験です,というような話になってしまう。ああ,interactionという概念さえあれば。集計対象の変数群に対して性別と年代が及ぼす効果を考えたとき,そこにinteractionがないと思うなら前者の答え,あるかもと思うなら後者の答えになるのだ。
あるいは統計的推論。データの分析にかなりの経験を持っている人でさえ,covariateとmediatorとmoderatorのちがい,特にmoderatorという概念(つまりはinteractionという概念)があいまいなばかりに,大混乱を引き起こすことが多い。あばたと出っ歯のどっちがまずいかという議論の最中に,いやいや「惚れてしまえばあばたもえくぼ」っていうじゃない,現象はすごく複雑なんだから答えなんか出せっこないよ。。。などという話を持ち出し,善男善女を混乱と無気力に突き落とす人がいる。ああ,moderatorという概念さえあれば。肌の凹凸から美しさ知覚へと伸びるパスに,恋愛というmoderatorが突き刺さっていると考えれば済む話ではないか。問題は現象が複雑すぎることではなく,現象を捉える概念的道具が不足していることにあるのだ。
というわけで,俺の心の平安と残業縮小のため,interactionという概念を周囲に少しでも普及させようと考え,うまいやり方を探してあれこれ資料をあさっている。とはいえ,世の中のありようにはそれなりの理由があるものなので,俺が努力したところで自己満足に過ぎないんだけど,まあとにかく,その一環で読んだ論文。
Holmbeck, G.N. (1997) Toward terminological, conceptual, and statistical clarity in the study of mediators and moderators: Example from child-clinical and pediatric psychology literatures. J. Consulting and Clinical Psychology. 65(9), 599-610.
発達臨床研究向けの啓蒙論文。semnet MLでみつけて読んでみた。
mediator(中間変数)とmoderator(調整変数)のちがいについて懇切丁寧に説明した後,それぞれを実証的に検証する手続きを紹介。moderatorの検証方法は,そのまま回帰式に放り込んで交互作用項を推定するやりかたと,moderatorで群分けしてSEMモデルを群間比較する方法の二種類。で,当該業界における先行研究を間違った奴と正しい奴に分け,前者の論文の一言一句をぐりぐりと批判する,という性格の悪い論文。楽しい。
取り上げている研究では,大ざっぱにいって子どもの不適応がoutcome, ストレス因子がそのpredictorで,そこにコーピングとか認知過程とか家庭の機能とかが絡んでくる。で,たとえばコーピング方略が調整変数であるという仮説を立てておきながら,検証においてはそれが中間変数かどうかを調べていたり,その逆だったり。。。という研究が,ほらこんなに多いのですよ,そもそもコーピング研究初期の重要文献であるLazarus&Folkman(1984)にしてからがそうなのです,みなさん頭を整理してください。という主旨の論文であった。
moderatorとはなにかを説明するうまいやり方を探していたので,その意味ではあまり役に立たなかった。理論的説明はBaron&Kenny(1986JPSP)に依拠しているので,そっちを読んだようがよかったかも。でも,なぜみんなこんなに間違えちゃうのか,と考察しているところは勉強になった。著者いわく,それは時間的先行と因果的先行をごっちゃにしているからではないか,とのこと。たとえば,ストレスA,対処方略B,不適応Cについて考えているとしよう。理論的には,「ストレスにさらされても適切な対処方略があれば不適応は生じない」と,Bをmoderatorだと正しく捉えている。しかし,時間的にはA→B→Cとつながっているので,間違ってそういうパス図を書いてしまい,実証研究ではついついBをmediator扱いして検証してしまう。。。ということだと思う。なるほど。生起順序と因果的メカニズムを分けることは大事だなあ。
この論文を読んだのは待ち合わせ中の新宿の喫茶店だったのだが,向かいのテーブルではTV番組制作会社の人に向かって有名スポーツ選手の奥さんがセレブ話を語り倒しており,右のテーブルでは二人の老人が200万の手形を巡って激しくもめており,左のテーブルでは若いカップルがジクジクと泣きながら血みどろの言い争いを続けていた。どれにも聞き耳を立てていませんよと示すため,俺は小声で論文の文章を音読していた。ウェイターはなかなか水を注ぎにこなかった。気持ちはわかる。
読了:Holmbeck(1997) 中間変数と媒介変数のちがい
2010年3月 4日 (木)
これは1月上旬に読んだ論文。メモだけとって,そのまま忘れていた。
ほかにも何本か読んだような気がするんだけど。。。
Jaccard, J., Becker, M.A., Wood, G. (1984) Pairwise multiple comparison procedures: A review. Psychological Bulletin, 96(3), 589-596.
多重比較の手法を比較した研究のレビュー。被験者間計画,被験者内計画,混合計画の3つに分け,さらにそれぞれをoptimalな状況(正規・等分散・等サイズ)とそうでない状況とに分けて整理している。optimalでない状況で被験者内要因の多重比較をする際にはボンフェローニ法がよろしい,とか。
仕事の都合で目を通した論文。ほんとは多重比較の手法比較において検定力をどう定義するかを知りたかったのだが,そういう話は載っていなかった。手法間の良し悪しについていえば,多重比較の世界は進歩が速いようなので,84年時点でのレビューを読むことにどれだけ意味があるのか。。。時間の無駄遣いだったかも。
2009年12月10日 (木)
Kromrey, J., Hogarty, K.Y. (2000) Problems with probabilistic hindsight: A comparison of methods for retrospective statistical power analysis. Multiple Linear Regression Viewpoints, 26(2).
ここんところ,事後的効果量に関する文献を読みあさっていたが,いいかげん飽きてきた。。。これはせっかく集めたので一応目を通してみた論文。もうこれでやめにしようと思う。
みたこともない誌名だが,American Educational Research Assoc. のGLM分科会で出している雑誌らしい。細かいところはすっとばして読了。著者らはたしか,SASのユーザ会でも同じような発表をしていたと思う。
標本効果量に基づく検定力算出を支持する立場に立ち,標本効果量をそのまま母効果量とみなすことによって生じる偏りをどうやって補正するかを検討している。非心パラメータ(母効果量)の推定量として,プラグイン推定量,不偏推定量,パーセンタイル推定量の3つがあるのだそうで,それらの偏り・標準誤差・信頼区間をシミュレーションで比較する。一長一短である由。
先日読んだHoenig&Heisey(2001)は,まさにこの論文のようなタイプの研究を次のように批判している。
実験後の検定力分析を「改善する」ためのさまざまな提案がなされてきた。たとえば,一般的な効果量(例,非心パラメータ)の推定値が偏っているからその偏りを補正しようとか,検定力算出において使用されている標準誤差は正確にはわかっていないので実験後の検定力推定量の信頼区間を算出しようなどという提案である。奇妙な話だ。検定の結果を評価する際には検定力について検討することを求めるのに,検定力が適切かどうかを評価(検定)する際には,「検定力の適切さ」の検定の検定力について考慮しようとは思わず,推論の枠組みを信頼区間ベースの枠組みに切り替えてしまうのである。これらの提案は,根底にある「検定力アプローチのパラドクス」[検定力が高いことが,棄却されなかった帰無仮説を支持する証拠の強さを意味しないというパラドクス]を解決するための役には立たないという点で,不十分なものである。
。。。なんだかこっちのほうが説得力があるなあ。
Faul, F., Erdfelder, E., Buchner, A., Lang, A.G. (2009) Statistical power analyses using G*Power 3.1: Test for correlation and regression analyses. Behavior Research Methods, 41, 1149-1160.
いつのまにかリリースされていたG*Power 3.1の新機能についての紹介論文。なんと,このブログを読んだ友人のIくんがわざわざメールで教えてくれた。感謝,感謝です。
G*Power 3.1では,いまやロジスティック回帰やポワソン回帰の係数についての検定の検定力まで計算できるのである。俺には当面使い道がなさそうだけど,そんなものまで計算できちゃうとは驚きだ。早速インストールしました。
このブログを誰が読んでいるのかわからないが,ひょっとすると検索エンジン経由で誰かの役に立つかもしれないので,最近の痛恨の体験談を書いておこう。特定の標本サイズと母効果量の下での検定力を求める,というような課題ではなくて,たとえば任意の標本サイズから検定力を引く表といったような,いろいろな場合についての検定力の一覧表をつくるためにはどうしたらよいか? てっきりG*Powerでは無理だと思いこみ,そういうときはSASのpowerプロシジャを使っていた。アサハカであった。あとで気がついたのだが,最初に出てくるメインウィンドウではなく,X-Yプロットのウィンドウで,好きな一覧表を一発でつくれるのだ。気づかないよ,そんなの。。。
2009年12月 9日 (水)
ただいま「データ集めてから求める検定力ってなんなの」ブームにつき,論文を4本。最初は仕事の都合だったんだけど,途中から趣味になってきました。
Onwuegbuzie, A., Leech, N.L. (2004) Post hoc power: A concept whose time has come. Understanding Statistics, 3(4), 201-230.
先日読んだHoenig&Heisey(2001)とは逆で,標本効果量に基づく検定力算出を支持する立場。
話がすごくややこしいのだが,彼らが支持する"post hoc power"というのは,SPSSでいうところのobserved powerのこと,G*Powerの開発者がいうところのretrospective powerのこと,すなわち標本効果量に基づく検定力のことであり,Hoenig&Heiseyがコテンパンにけなしているアイデアである。いっぽうG*Powerでいうところの"post hoc power"は,標本特性値を使うというニュアンスはさらさらなくて,単に「母効果量から逆算した検定力」という意味であり,この論文の著者らの呼び方でいえばa priori powerなのである。
うぎー。わけわかんなくなってきたので,最近読んだ3本の論文を整理しておこう。とにかく! 標本サイズ・有意水準・母効果量・検定力の4つのうち3つが決まれば,残りのひとつが決まる。以下の論文で問題になっているのは,どんな効果量を使って検定力を求め,それをどう使うか,である。大きく分けると,標本効果量で検定力を求めることに賛成する人と反対する人がいる。
- 賛成派:Onwuegbuzie&Leech(2004)
- 事前知識に基づき母効果量を設定して求めた検定力をa priori powerと呼ぶ。
- 「所与の標本から得た効果量を母効果量とみなして求めた検定力」をpost hoc powerと呼ぶ。実際には,標本効果量は母効果量とは異なるので,検定力の推定値も正確でない。しかし,検定の結果が有意でなかったとき,この検定力が高ければ,「有意な結果にならなかったのは検定力が低かったせいじゃない」と主張できる。
- 反対派:Hoenig & Heisey (2001)
- 「所与の標本から得た効果量を母効果量とみなして求めた検定力」をobserved powerと呼ぶ。それをつかって手元の証拠の強さを判断するのは間違いである。
- 「指定した検定力を達成する最小の効果量」をdetectable effect sizeと呼ぶ。それを「検定が有意でなかったときの真の効果量の上限」とみなすのは間違いである。
- 実質科学的に意味のある効果量をbiologically significant effect sizeと呼ぶ。それを検出するための検定力が高いことを,「検定が有意でなかったときに帰無仮説を支持するための証拠が強いこと」とみなすのは間違いである。
- 反対派:Faul et.al.(2007)
- 「所与の標本から得た効果量を母効果量とみなして求めた検定力」をretrospective powerないしobserved powerと呼ぶ。実際には,標本効果量は母効果量とは異なるし,不偏な推定量でもない。だから,それを使ってある分析で得られている検定力を判断するのは間違いである。この点でHoenig & Heisey(2001)に同意。
- 事前知識に基づき母効果量を設定して求めた検定力をpost hoc powerと呼ぶ。
O'Keefe, D.J. (2007) Post hoc power, observed power, a priori power, retrospective power, prospective power, achieved power: Sorting out appropriate use of statistical power analysis. Communication Methods and Measure, 1(4), 291-299.
上記論文のメモをとったあとで読み始めた論文。こっちを先に読めばよかった。このタイトルのくどさ,ちょっと可笑しい。
検定力関連の話がややこしくなっているのはソフトウェアに責任の一端がある,とのこと。G*Powerの"a priori power"と"post hoc power"は,実験前・実験後という区別とはなんら関係ない。これはユーザにはわかりにくい。またSPSSの"observed power"は,あたかも実際に得られた検定力を測定しているようにみえてわかりにくい。
"post hoc" power, "observed" power, "retrospective" power, "achieved" power, "prospective" poser, "a priori" power,こういった呼び方は止めよう。これらは混乱を招きかねない略記法であり,算出された検定力の基にある具体的な値についてきちんと記述するのを妨げる。あなたの検定力の計算が,観察された標本効果量を母集団の効果として使用しているのならば,そういいなさい。post hoc powerなんていうな。
なるほどね。
著者らは基本的にHoenig &Heisey(2001)の線に従い,「標本効果量に基づく検定力」の有用性を否定する立場である。Onwuegbuzie & Leech(2004)のいう「有意差が得られなかったらpost hoc powerを求めましょう」というアドバイスはナンセンスである由。
とはいえ,反対派も一枚岩ではないようだ。
この検定力[標本効果量に基づく検定力]が提供してくれるのは次の疑問への答えである。「仮に,母集団の効果が観察された標本における効果と全く同じならば,統計的に有意な結果を得る確率はどのくらいか?」 しかし,この問いにはほとんど意味がない。
しかし,次の疑問であれば話は別だ。「理論的な理由,先行研究の結果,実務的重要性などに基づき,母集団におけるなんらかの値を仮定しよう。その場合,統計的に有意な結果を得る確率はどのくらいか?」 この疑問に対する答えは,事実を観察する前だろうが後だろうが有用でありうる。たとえば以下のように:「先行研究では平均してr=.40の効果を得ています。母集団における効果を.40と仮定すれば,我々は高い検定力を確保しているわけです。ですから,このたび有意な効果が得られなかったという事実には意味があります」
上記引用の後半で著者らが支持しているのは,「目指す効果量を検出するための検定力が高いこと」を「検定が有意でなかったときに帰無仮説を支持するための証拠が強いこと」と捉える見方,すなわちHoenig & Heisey (2001)が批判するところのbiologically significant effect sizeアプローチではなかろうか?
Colegrave, N., Ruxton, G.D. (2003)Confidence intervals are a more useful complement to nonsignificant tests than are power calculations. Behavioral Ecology, 14(3), 446-450.
Hoenig & Heisey(2001)を掲載誌読者向けにやさしく解説した啓蒙的コメント。
Hoenigらの論文を読んでて最後まで理解できなかったのは下記の記述なのだが
2つの実験[2つの1標本Z検定]の例に戻ろう。実験1のほうが有意性に近かった(Zp1>Zp2)。さらに,推定された効果量は2つの実験の間で同じ,サンプルサイズも同じだったとしよう。このことはσ1<σ2であったことを意味する。
この部分,著者らの説明では
上で述べた実験[2標本Z検定]を繰り返す場合について考えよう。同じサンプルサイズでもう一度実験し,実験1と全く同じ平均差を得たとする。唯一のちがいは,実験1ではp=0.09だったのに対し,実験2ではp=0.21であったという点である。[...]サンプルサイズと効果量がかわらないのに,p値が高くなったということは,分散が実験1よりも大きいということだ。
やっぱりわからん。わたくし,平均の差の検定における効果量とは平均の差をそのSDで割ったものだとばかり思っていましたよ??? どうやら上記の引用部分で,彼らは効果量ということばをなにか違う意味で使っているらしい。。。母平均の差そのものを指して使っているのだろうか?
Lenth, R.V. (2007) Post Hoc Power: Tables and Commentary. Technical Report 378, Dept. Statistics and Actuarial Science, Univ. Iowa.
この論文もHoenig & Heisey(2001)のラインで,Onwuegbuzie & Leech(2004)を名指しで逐一批判している。また,実際に標本効果量に基づく検定力とp値との関係を大きな数表で示している。ある程度Nが大きくなってしまうと,p値さえ決まればNとは無関係に検定力が決まってしまうのだそうだ。
著者らの主張は,検定力はとにかくprospectiveなものだ,というもの。もしそれがretrospectiveな概念でありうるというならば,使えるデータを全部使わないとおかしい。というわけで,著者はpost hoc powerの大統一公式(grand unified formula)なるものを提案している。従来のpost hoc powerの欠点,それは検定の結果を無視していたことでありました。そこで,post hoc powerを次のように一般的に定義しましょう: post hoc power = Prob(H0を棄却する|利用可能なデータ)。この公式は衝撃的に簡潔で,誰にでも覚えられる。検定の結果が有意であるときの検定力は1, 有意でないときの検定力は0なのである。。。とのこと。ははは。
ときどき,資格試験とか院試のための勉強ノートを自分のブログに載せている人を見かけて,物好きなひとだなあ,と呆れていたのだが。。。いま俺がやっていることって,まさにそれそのものですね。
まあとにかく,事後的検定力についてある程度理解できたような気がするので,そろそろこの関係の論文を読むのはやめにしておこう。
2009年12月 8日 (火)
Hoenig, J.M., Heisey, D.M. (2001) The abuse of power: The pervasive fallacy of power calculations for data analysis. American Statistician, 55(1), 19-24.
先日読んだG*Powerの紹介論文で引用されていた論文。
帰無仮説が棄却されなかった場合の検定力分析の適用例には主に2種類ある。一つ目は,検定統計量の観察値に関して検定力を計算することだ。つまり,観察された処理効果と変動が真のパラメータ値と等しいと想定して,帰無仮説が棄却される確率を計算することである。これは「観察された検定力」と呼ばれるものである。SPSSのような統計ソフトウェアは,データ分析と一緒に観察された検定力を出力する。観察された検定力の支持者は,もし統計的有意性が見出されず,しかし観察された効果量に対する検定力が高い場合には,それは帰無仮説が真であるという証拠となる,と論じる。[...]
観察された検定力は,その支持者たちの目標を決して達成できない。なぜなら,ある検定において観察された有意水準(「p値」)が観察された検定力を決定するからである。いかなる検定においても,観察された検定力はp値と一対一に対応する関数なのだ。p値は[0,1]のあいだに落ちる確率変数である。p値の累積分布関数(CDF)をPr(P≦p) = G_δ(p)と表現しよう(δはパラメータ値)。さて,既知のσを持つ正規分布から得られているデータについて,H_0:μ≦0とH_α:μ>0とを比較する一標本Z検定について考えよう。δ=√n * μ / σ とすると,G_δ(p)=1-Φ(Z_p-δ) である (Z_pは標準正規分布の100(1-p)番目のパーセンタイル)。ここでZ_pは観察された統計量である。p値も観察された検定力も,G_δ(p)から得られる。p値を得るにはμ=0とすればよい。つまり,G_0(p) = 1-Φ(Z_p) = pである。観察された検定力を得るには,パラメータの値を観察された統計量の値にして,P<αとなるパーセンタイルを調べればよい。つまり,観察された検定力はG_Zp (α) = 1-Φ(Z_α-Z_p)から得られる。このように,観察された検定力は,p値によって完全に決定されている。結果の解釈にはなにも付け加えてくれない。[...]
観察された検定力が有用でないという可能性に言及した人は多いが,観察された検定力という考え方の致命的な論理的欠陥について触れている人は少ない。次の場合について考えてみよう。2つの実験を行い,どちらでも帰無仮説が棄却されなかった。観察された検定力は実験1のほうが大きかった。観察された検定力の支持者なら,実験1のほうが帰無仮説を支持する強い証拠を与えている,と解釈するだろう。彼らの論理はこうだ。「検定力が低いということは,帰無仮説からの真の乖離を検出することに失敗しているのかもしれない。いっぽう,高い検定力があるにもかかわらず帰無仮説の棄却に失敗したということは,帰無仮説はおそらく真,ないし真に近いということだ」 この理屈がナンセンスであることは簡単にみてとれる。上述の片側Z検定について考えよう。実験1と実験2で観察された検定統計量をZp1, Zp2とする。観察された検定力が実験1のほうで大きかったということは,観察された統計力G_Zp(α)はZの単調増加関数だから,Zp1>Zp2ということだ。p値を統計的証拠として用いる通常の考え方に従えば,実験1のほうが,帰無仮説に反する強い証拠を与えていることになる。これは先に述べた検定力解釈と矛盾する。以下ではこの不適切な解釈のことを「検定力アプローチのパラドクス」と呼ぶことにする。すなわち,検定力が高いことが,棄却されなかった帰無仮説を支持する証拠の強さを意味しない,というパラドクスである。
事後的な検定力計算の二つ目の適用例は,特定の検定力(たとえば.9)が得られるであろう仮説的な真の差を見つけること,すなわち「検出可能な効果量」を決定することである。この手法は,ある実験の結果として帰無仮説が棄却できなかったときに,観察された変動に基づき検定力が.9になるような効果量を求める,という形で適用される。この手法の支持者は,「検出可能な効果量」を真の効果量の上限として捉える。つまり,検定力が高いなら,有意性に達しなかった以上,真の状態が検出可能な状態に近いとは思えない,というわけである。検出可能な効果量が帰無仮説に近いほど,結果は帰無仮説を強く支持する証拠であるとみなされる。たとえば,H_0:μ≦0とH_α:μ>0とを比較する一標本Z検定において,平均1.4, 平均の標準誤差 1 を得たとする。Z=1.4, P=.08となり,α=.05において有意でない。仮に真のμが3.29であるならば(SEは1であるとしよう)。H0を棄却する検定力は.95である。従って,3.29が真の平均の上限とみなされる。
「検出可能な効果量」アプローチの変形のひとつに,「生物学的に有意な効果量」アプローチがある。生物学的に重要であるとみなされるなんらかの効果量について,その検定力を求めるアプローチである。帰無仮説からの意味ある乖離を検出するための検定力が高いほど,帰無仮説が棄却されなかったことが,真の状態が帰無仮説に近いということを示す強い証拠であるとみなされる。
これらの推論アプローチが明示的に正当化されたことはこれまでに一度もない。Cohen(1988)は以下のように述べている。いま,帰無仮説からの乖離Δを検出する検定力1-βが高くなるように研究を設計し,かつ帰無仮説を棄却することに失敗したとしよう。この場合,真のパラメータ値が帰無仮説の前後Δぶんの範囲に落ちているという結論が「水準βで有意になる。このように,リスクαを伴って帰無仮説を棄却するのと同じ論理に従い,リスクβを伴って,効果量=Δという仮説ではなく帰無仮説を支持することができる。」[...] さらにCohenは,「統計的演繹による「証明」は確率的なものだ」と述べている。彼はどうやら,パラメータの真の値についての確率的言明を行っているようだ(古典的な統計学の文脈では不適切な言明である)。さらにいえば,彼の手続きでは特定され固定された検定力を達成すべく,実験を実施する前にサンプルサイズが決められるのであるから,彼の議論は実際の検定力が意図された検定力と等しいと想定していることになる。実験の結果がどうであれβの値は更新されないのだから,彼の手続きでは,効果量と標本変動についての実験的証拠が無視されているといってよい。[...]
「検出可能な効果量」アプローチと「生物学的に有意な効果量」アプローチは,「観察された効果量」アプローチよりも魅力的だ,とみなす人が多い。しかし,これらのアプローチもまた,「検定力アプローチのパラドクス」という致命的問題から逃れられない。2つの実験の例に戻ろう。実験1のほうが有意性に近かった(Zp1>Zp2)。さらに,推定された効果量は2つの実験の間で同じ,サンプルサイズも同じだったとしよう。このことはσ1<σ2であったことを意味する。求められている検定力水準をΠ_αとすると,求められている検出可能な効果量ρを得るためには,式Π_α=1-Φ(Z_α - √n * ρ / σ)を解けばよい。この式をみるとわかるように,検出可能な効果量は実験1のほうが小さい。いかなる効果量に対しても,検定力は実験1のほうが小さくなるだろう。以上の結果から,実験1のほうが帰無仮説を支持する強い証拠を提供している,という意味不明な結論が得られる(実験1は,検定力は高いのに有意差が得られなかった実験だからである)。これは実験結果(p値)の標準的な解釈と矛盾する。[...]
恥ずかしながら,一番肝心であると思われる部分の議論(上記引用の最終段落)がよく理解できなかったので,その部分のメモを取り始め,それでも分からないのでさかのぼってメモを取り。。。ずるずる悩んでいるうちに,いつのまにかこんなに訳文を作ってしまった。思い詰めるとついつい訳してしまうのは悪い癖だ。しかも,まだ理解できていない。情けない。
2つの一標本Z検定のあいだで,推定された効果量が同じ,サンプルサイズも同じだったら,検定統計量も同じでは??? なにか俺が勘違いしているんだろうけど。。。うーむ。
なお,こうした議論について「アホだなあ。。。事後分布を得ることだけに焦点を当てれば,問題全体が無意味になるだろうに」と感じるであろうベイジアンの皆様(ほんとにこう書いてある)に対する返答としては,リアル・ワールドにおけるデータ解析は当面は頻度主義のままだろうから,頻度主義の枠組みのなかでできる限り適切な分析をすることが重要なのです,とのことであった。そうそう,そうですよね。
ユーザに対するアドバイスとしては,もっと信頼区間を使え,とのことであった。いっちゃなんだが,伝統芸能のようなアドバイスだ。ずいぶん前からいろんな人がそう云っているけど,その割には世の中変わらないですよね。
2009年12月 7日 (月)
Faul, F., Erdfelder, E., Lang, A.G., Buchner, A. (2007) G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175-191.
フリーの検定力算出ソフト G*Power 3のマニュアルに相当する論文。
SPSSの出力で,検定と同時にその検定において「観察された」検定力が表示されているのをたまに目にすることがある(調べてみたら,MANOVAコマンドがそうらしい)。あれってなんだか変だなあと,漠然と不思議に思っていた。このたび勤務先で,ややこしい検定の検定力を求めるという用事があって(たまにはそういうこともある),あれこれ考えているうちにこの疑問が再燃した。だって,差の検定の検定力を求めるためには,まず検出すべき差の定義が必要なはずではないですか。その差とはあくまで母集団における差であって,標本において観察された差ではないのだ。いったいどうすれば,検定力を「観察」できるのか?
この疑問についてどこを調べたらいいのかわからなかったので(Cohenの本を調べればいいんだろうけど,面倒だったので),ためしにいつも使っているソフトについての紹介論文を読んでみた。G*Powerにもpost hoc power analysisという機能があるので,その説明を読めばいいや,と思ったのである。
どんぴしゃでした。G*Powerでいうpost hoc power analysisは,有意水準と母集団効果量とサンプルサイズから検定力を算出することを指す。いっぽう,SPSSなどが行っているのはretrospective power analysisと呼ばれるもので,標本における効果量を母集団における効果量とみなし,それを検出するにあたっての検定力を求める。これはいろんな人に批判されている考え方なのだそうだ。なるほどー。
2009年11月19日 (木)
宮代隆平,松井知己 (2006) ここまで解ける整数計画. システム/制御/情報 : システム制御情報学会誌, 50(9).
昨年,勤務先の仕事の都合で組み合わせ最適化について勉強する羽目になった。勉強するといっても,素人向け入門書を読みかじる程度なのだが,この入門書というのがどれもギリシャ語のような按配なのである。途中で何度か半泣きになった。
そのプロセスでもっとも役に立ったのが,意外にも,ネットで拾ったこの文献であった。いまでもことあるごとに読み返している。感謝の意を込めてメモしておく。
変数間の関係に線形な制約が課せられていて,それらの制約を満たす値の組を見つけるような課題のことを線形計画問題という。最近は技術が進歩して,ソフトウェア(ソルバー)が大変優秀だし,フリーのソルバーさえ存在する。で,変数(の一部)が整数であることが求められている場合を,特に整数計画問題という。普通の線形計画問題より,整数計画問題のほうがはるかに難しい。使えるソルバーはすごく高価だし,フリーのソルバーはオモチャ並みの性能しか持たない。
資料を読みかじっていてびっくりしたのは,この分野には素人考えでは想像もつかないような不思議なノウハウがある,というところ。たとえば,制約式が少ないほど速く解けそうなものだが,そうともいえない。冗長な制約を重ねて定義すると遅くなりそうなものだが,これがそうでもない。また,この論文によれば,単に許容解がひとつわかればいいという場合でも,嘘でもいいからなにかの目的関数の最小化を目指したほうが速く解けるし,目的関数の係数がばらばらの値であるほうが速く解けたりするんだそうだ。わけわからんなあ。
整数計画問題がうまく解けない場合の対処策には,大きく分けて(1)あきらめる,(2)あきらめない,のふたつの方法がある由。ははは。で,後者を選ぶ場合には,緩和課題(変数を整数ではなく実数にしてしまった課題ということだと思う)を解いて,(1)その最適解で,値が0ないし1になっている変数の個数をみる,(2)最適解発見までの時間をみる,(3)最適解が元の整数計画課題の何割くらいになっているかどうかをみる...のがお勧めだそうだ。(3)の意味がよくわかんないんだけど...すでに整数計画問題で最適解が得られている場合の話であろう。
2009/12/20追記
著者の松井先生からご教示を頂くことができました。上記(3)は,すでに小さめの整数計画問題で解を得ているとき,その目的関数の値に対して,その問題を実数に緩和した問題の目的関数の値がどのくらい小さいかを調べる,ということだそうです。なるほど。。。
松井先生,親切なご教示,誠にありがとうございました。
久保幹雄 (2006) 数理計画ソルバーを用いたメタ解法. システム/制御/情報 : システム制御情報学会誌, 50(9).
最適化の問題へのアプローチには,線形計画法で最適解を求めるやり方と,メタ・ヒューリスティクス(汎用的なヒューリスティクスのこと。局所探索とか焼きなまし法とか)を使って近似的な解を探索するやり方がある。本屋であれこれ探していて,線形計画の本には線形計画,メタ解法の本にはメタ解法のことしか書いてないことに気が付いた。なんでもいいから解き方を教えてくださいよ,というアサハカな立場からみると,この状況はかなり不思議であった。
先週たまたま見つけたのが,上記と同じ特集号に載ったこの論文。内容は難しすぎて手に負えない部分が多いのだが,冒頭2ページの概観を読んで,霧が晴れるような思いであった。著者らによれば,整数計画ソルバーで解く方法のほうが実務的汎用性がある。メタ解法は問題の構造を正しく捉えないと設計できないし,ちょっと問題が変化しただけで位置からやり直しになってしまいかねない。いうなれば,ソルバーは万能ナイフ,メタ解法は日本刀や中華包丁のようなもの。で,このふたつの技術はほとんど独立のグループによって研究されており,あまり接点がないのだそうだ。
なるほど。。。ことばから受ける印象では,メタ解法のほうが汎用的,という感じだが,現実にはそうでもないんですね。先週から遺伝的アルゴリズムの入門書を何冊か読みかじっていたのだけれど,どうやらポイントはアルゴリズムそのものより,課題の構造をうまく捉えた遺伝子型の設計にあるようで,これは案外に名人芸の世界なんじゃないか,と混乱していたところであった。この論文のおかげで,疑問が氷解した思いである。
(で,この著者の名前に惹かれて久保&ペドロソ(2009)を買い込んだら,その第三章がこの論文の中身と同じだった。やられたぜ)
思うに,こういう素人向け啓蒙論文を書いたところで,あまり業績評価にはつながらないのではないだろうか。そういう点でも,著者の先生方に感謝。それともORの世界では,こういう啓蒙も研究者の大事な仕事だと認められているのだろうか。そうだといいんですが。
2009年10月28日 (水)
Muthen, B.O. (2002) Beyond SEM: General letent variable modeling. Behaviormetrika, 29(1), 81-117.
Mplusの開発者Muthenさんが,Mplusの背後にある理論的フレームワークについて説明した論文。潜在変数として連続変数とカテゴリカル変数の両方を考え,かつ共変量を考えることで,従来のSEMで捉えられるモデルはもちろん,潜在クラスモデル,成長曲線モデル,項目反応モデル,階層モデル,離散時間生存モデルなどなどの多様な分析手法をぜーんぶひとつの枠組みで捉えることができるのですよ。という主旨。
この論文は前の会社に勤めたばかりのころに読み始め,あまりに難しくて途中で挫折したのであった。で,先日ちょっと頭を整理したくてぱらぱらめくっていたら,これが意外にもわかりやすく,途中ちょっと飛ばしたものの,気がついたら読み終えていた。狐につままれたような感じだ。俺なりに多少は成長したのか。。。いや,きっと論文を読むときの態度が変わったのだろう。適当に流し読みするようになったというか,関与が下がったというか。
これはよく引用される論文だと思うが(Google scholarではただいま200件),よくみたら,掲載誌は日本の行動計量学会の英文誌である。へー。
2009年10月21日 (水)
先日片側検定について調べていたときに読んだ論文。ほかにも読んだような気がするんだけど。。。
Liu, T., Stone, C.C. (1999) A critique of one-tailed hypothesis test procedures in business and economics statistics textbooks. J. Economic Education, 30(1), 59-63.
Lombardi, C.M., Hurlbert, S.H. (2009) Misprescription and misuse of one-tailed tests. Austral Ecology, 34(4), 447-468.
面倒なところを飛ばしてしまったが(非同等性試験のあたりとか),俺のなかでの片側検定ブーム(?)が過ぎ去ってしまったような気がするので,これは読了にしちゃおう。
2009年9月10日 (木)
二群の比率の差の検定法としてFisherの正確検定が広く知られている。俺も学生のときに習った。この方法には,2x2クロス表の周辺度数をすべて固定して考えるという特徴がある。有名な紅茶実験を例に挙げると,Fisher先生は紅茶のカップを8つ用意し,うち4つには紅茶を先に,残りの4つにはミルクを先に注いだ。で,農業試験場の同僚の女性がこれらを飲み比べ,どのカップで紅茶が先に注がれたかを言い当てようとした。さて,このとき同僚の女性は,紅茶を先に注いだカップが8つのうち4つだということをあらかじめ知っている。つまり,正解を行,女性の回答を列に置いた2x2クロス表を考えると,女性の舌が正確だろうがいい加減だろうが,行周辺度数も列周辺度数も4であることはあらかじめ決まっているわけである。この事実がFisherの正確検定の基盤になる。
しかし,我々が二群の比率の差を調べる際,各群のサイズ(行周辺度数)はあらかじめ固定されているとしても,両群あわせた比率(列周辺度数)は固定されていないのが普通である。紅茶実験のたとえでいえば,同僚の女性が「紅茶を先に注いだカップが何杯あるのか」さえ知らされていない状況に相当する。こうした問題にFisherの正確検定を適用するということは,本来固定されていない周辺度数を固定して考えてしまっているわけだ。これはなんだか変じゃないか?。。。という疑問を,院生のころから漠然と胸に抱いていたのだけれど,そういう難しいことにはあまり立ち入らないようにしようと思っていた。なんといっても,統計学は苦手なのだ。
このたび仕事の都合で,ちょっと正確検定のことを調べていて知ったのだが,上の疑問は古典的な議論の種なのだそうで,すでに膨大な論争の積み重ねがあるらしい。ふうん。
哲学的論争だけではなく,具体的な検定手法としても,Fisherの方法とちがって列周辺度数を固定しないタイプの正確検定(これをunconditionalな検定という)がいろいろ提案されているのだそうである。Fisher法は保守的であることが知られているが,これは周辺度数をすべて固定した上で数え上げているからであり(検定統計量が過度に離散的になる),unconditionalな手法ならば少しはマシになるだろう,と期待されているわけである。へー。
Mehrotra, D.V., Chan, I.S.F., Berger, R.L. (2003) A cautionary note on exact unconditional inference for a difference between two independent binomial proportions. Biometrics, 59, 441-450.
というわけで,たまたま拾った論文に目を通してみた。11種類の検定手法について,実質的なType I Error率や検定力を比較している。その内訳は,まずconditionalな検定としてFisherの正確検定。unconditionalな検定として,Suissa&Shuster(1985)が提案した2種類の方法,Santner&Snell(1980)の方法,Boshloo(1970)の方法,そしてこれら4つの方法をBerger&Boos(1994)に基づいてそれぞれ改訂したもの4種類,以上あわせて8種類(やれやれ,いろいろあるものですね)。最後に漸近的手法として,Pearsonのカイ二乗検定ともう一種類。
結論としては,状況によって手法の良し悪しは大きく変わるし,unconditionalな手法の検定力が高いとは限らない由。一般的なお勧めは,Boshlooの方法,その改訂版,Sussa&Shusterの"Z-pooled"法の3つだそうだ。ほー。
論文の本筋とは離れるが,帰宅する電車のなかでこの論文をめくっていて,表のなかのある箇所に目を吸い寄せられ,あまりの意外さに茫然としてしまった。またもや勉強不足をさらすようで,ここにセキララに書くのはちょっと勇気がいるのだが...
独立な2群間の比率の差の検定について考える。Pearsonのカイ二乗検定,各群N=150,両側検定,α=.05とする。さて,実は母比率は両群ともに50%であるとしよう。このとき,誤って有意差が得られてしまう確率は?
そりゃもちろん5%であろう,というのが俺の答えである。αとはType I Errorの確率,つまり「帰無仮説が真のときに誤って棄却する確率」だ。もし母比率が等しい,つまり帰無仮説が真ならば,そのとき有意差が得られる確率とは,すなわちαにほかならない。そうですよね? このように信じ込んで,わたくし,これまでのうのうと生きて参りました。
ああ,俺と同じように答える人が多からんことを。あなたたちは私の心の友である。そして心の友よ,我々は深く反省すべきだ。この論文のTable 1.によれば,正解は5.7%である。
(正直いって信じられなかったので,翌朝簡単なシミュレーションのコードを書いて確かめてみた。嘘じゃありませんでした。二項乱数を使って100万試行繰り返したところ,有意差が得られたのは56,357試行であった)
このズレは,検定統計量の分布をカイ二乗分布で近似している点に由来する。セルの期待度数が5を下回っているときにこの近似が成立しないことは良く知られているが,それどころか,N=300という大きな標本サイズにおいてさえ,カイ二乗検定の実質的なαは名目上のαをかなり上回ってしまうことがあるのだ。いやあ驚いた,思ってもみなかった。
そんならコンピュータにモノを言わせて,大標本においてもバンバン正確検定を使い倒せばよいのかといえば,もちろんそういう問題でもない。上の状況でFisherの正確検定を使うと,その実質的αは4.3%。こんどは過度に保守的になってしまう。そこで上記のような研究が登場するわけである。比率の差の検定というオーソドックスな問題にも,意外な難しさがあるんだなあ。いやいや,勉強になりました。
2009年9月 6日 (日)
勤め先で検定力関数のグラフを描く用事があった。サンプルサイズを横軸に,仮説検定で得られる検定力を縦軸にプロットした折れ線グラフ。たまにはそういう変わった仕事もある。
必要なグラフは描けたので,戯れにパラメータをいろいろ変えてみては,グラフの様子が変化するのを,頬杖をついてぼんやり眺めていた。ふつうの検定力関数は滑らかな単調増加曲線だが,パラメータによってはガタガタの階段状になったり,ノコギリの歯みたいな形になったりする。ふうん,面白いなあ。さて,昼飯でも食いに行くか,と席を立った。で,ぼーっと外に出て,ぼけーっと交差点をわたり,ぼんやりコーヒーを啜っているあたりで,はた,と気が付いた。
ノコギリの歯?! それはつまりその,サンプルサイズを増やすと検定力が下がることがある,ということですか? ま・さ・か,そんなはずがない。。。
このブログを誰が読んでいるのかわからないが,なかには俺の同類,すなわち自分に統計学の知識が欠けていることを認めたがらない哀れな解析ユーザもいるだろう。そういう人はきっと,やれやれ,こいつ幻覚でも見るようになったか,と思うに違いない。
証拠を載せておこう。下に貼ったのは独立二群間の比率差の検定における検定力曲線(母比率60%と50%,α=.05,標本サイズは群間で等しい)。いまG*Power3で描いた。
このグラフはFisherの正確検定の場合。たとえばN=18(群あたりN=9)の場合の検定力は3%,N=20の場合の検定力は2%であり,二例ふやしたせいで検定力が落ちてしまう,ということがわかる。こういうことがあるんですね。専門家には鼻で笑われちゃうかもしれないけど,俺は驚いた。これで統計学の講義などやってたんだから,ホントに申し訳ない。言い訳になりますが,心理学出身者は正確検定なんてあんまり使わないんです。
しばらく考えて自分なりにようやく納得したのだが,このからくりは,棄却のための臨界値を決めるとき,与えられたNの下でα=.05以下となる上限を求める,という点に由来するんじゃないかと思う。その結果として達成されるactualなαは往々にして.05を下回ってしまう。上記の例の場合,α=.05, N=20の下で,実際のαは実に.012である。名目的なα=.05からのギャップが大きい分だけ,無駄に保守的になっている,つまり,検定力を失っていることになる。
というわけで,このような例はFisherの正確検定に限らず,検定統計量の分布が離散的なときには常に生じうる。いっぽう下のグラフのように,Pearsonのカイ二乗検定のような漸近法では生じない。
ついでに関連論文を一本読んでみた。ここまでくると,仕事に役立つわけではないので,純粋に趣味というべきである。
Chernick,M.R., Liu,C.Y. (2002) The Saw-Toothed Behavior of Power versus Sample Size and Software Solutions: Single Binomial Proportion Using Exact Methods. The American Statistician. 56(2), 149-155.
SAS のマニュアルで引用されていた論文。検定力関数がノコギリ状になることがある点を指摘したうえで,市販ソフトがそれにどう対応しているかを紹介している。問題はノコギリ状になることそのものではなく,検定力からサンプルサイズを決定する際に,ソフトがちゃんと事態を説明してくれるか,という点にあるようだ。つまり,たとえば「ご指定の検定力を達成するためにはN=18必要です」と出力されたとして,読み手はうっかり「なるほど,N=18以上あればいいんだな」と思ってしまうが,実はそうではないかもしれない。ソフトはそのことをちゃんと教えてくれるか,ということである。なるほどね,そういう業界の人にとってはシビアな話であろう。
なお,取り上げられていたソフトはnQuery Advisor, Power and Precision, StatXact, PASS, UnifyPow。最後のやつはSASのマクロで,SAS 9.1から実装されたPOWERプロシジャの元になったらしい。
2009年8月24日 (月)
Hahn, C., Johnson, M.D., Herrmann, A., Huber, F. (2002) Capturing customer heterogeneity using a finite mixture PLS approach. Schmalenbach Business Review, 54, 243-269.
FIMIX-PLS法の解説論文。SmartPLSのBBSで紹介されていた。掲載誌はどういう雑誌なのか見当がつかないが,名前からすると「一橋ビジネスレビュー」みたいなもんかしらん。Webcatでみると所蔵図書館が110館もあるから,きっと有名な雑誌なのだろう。
たとえば,顧客満足度について共分散構造分析のモデルを組んだとしよう。で,よくよく考えると顧客のなかにも異質性があるはずで,ある人々においては従業員の礼儀正しさから顧客満足に伸びるパスの係数が高いだろうし,別の人々においては店舗の品揃えのパス係数が高いだろう,というようなことを考えたとしよう。この場合,思いつくデモグラ変数で対象者を分けて,群ごとにパス係数を推定したりするのがオーソドックスなやり方だが,うまい切り口が見つかるかどうかは運次第だし,実は「男30代と女50代は従業員重視」が正解でした!。。。などという場合には,もうほとんどお手上げである。そこで登場するのが,有限混合分布モデルをつかって,対象者を潜在クラスにわけつつかつクラスによって異なる係数を推定する,というやり方である。
いっぽう,顧客満足度のモデリングでよく使われる手法には,普通の共分散構造分析のほかにPLSモデリングもある。では,有限混合分布モデルをつかった PLSモデリングはできないのだろうか?できますとも,FIMIX-PLSをごらんあれ,というのがこの論文の主旨。数式のところは飛ばして読んだが,勉強になりました。
アメリカのコンビニ顧客満足度調査データを使い,係数の異なる5つのセグメントを求めて見せる。デモグラ変数でアプリオリに層別した分析をいくらやっても,このセグメントに到達するのは難しい由。
このモデルでは,顧客満足に対して10個の潜在変数からのパスが刺さっている。クラス数を変えながらパス係数を推定していくのだが,その際,どのクラスでも係数はすべて0以上,という制約をかけてしまう。著者らはこの制約の下での解を局所最適解と呼び,異なる初期値から繰り返し計算して,解が同じだったらそれは大域最適であるとみなしている。要するに,潜在変数は互いに独立だ,真の重回帰係数はすべて0以上になるはずだ,と前提しているわけだ。えええ?重回帰係数の符号が直感と逆向きになるのは,独立変数間に因果関係があることの証拠かもしれないではないか。Store LayoutとSafetyなんて,いかにも複雑な因果関係がありそうだから,どちらかの直接効果が負になってもおかしくない(店内の安全性さえ確保されていれば,棚のレイアウトはむしろ入り組んでいたほうが顧客満足が高い,とか)。解釈は難しいけど,それはそれで大事な知見ではないですか。
そもそも,論文の主旨は有限混合分布に基づくセグメンテーションにあるのであって,独立変数が互いに独立だという想定は別に要らないのではないか? なにもそんな制約をかけなくてもいいじゃん,と思ったのだが,察するに,こういう手続きを踏まないと負の係数が出まくってしまい,結果を解釈できなかったのかも。
セグメンテーション後の分析が勉強になった。各対象者の事後確率を従属変数,デモグラ情報を独立変数にした回帰モデルを組む。なるほど,分類結果とデモグラのクロス表を取るよりも気が利いている。もっとも実務の文脈では,個人にセグメント番号ではなく所属確率が割り当てられるというのは,ちょっと受け入れられにくそうだ。(あとでSmartPLSのBBSを眺めていたら,そういうことを書いている人がいた)
クラス数を決定する際に,どの適合度指標をみればよいのか(AIC, BIC, CAIC, ENのどれが良いか)を知りたかったのだが,書いてなかった。ま,全部みろってことかしらね。
2009年5月 6日 (水)
Mulaik, S.A., Millsap, R.E. (2000) Doing the four-step right. Structural Equation Modeling. 7(1), 36-73.
Hayduk&Glaser(2000)への返答論文。元論文と同様,論点が多岐にわたりすぎていて,どうにもついて行けないのだけれど,読んだ範囲内では,まあそう答えるだろうな,という内容であった。EFAで正しい因子数を知ることができるなどと主張した覚えはない由。
SEM誌のこの号は,Hayduk&Glaserをめぐる討論論文集になっている。他の人のコメントとか,Haydukらの再批判なども載っているようだ。でもそっちを読むより,非常に良く引用されるAnderson&Gerbing(1988)を先に読んだ方がいいんじゃないか,という気がしてきた。いかにいい加減なやり方で目を通しているとはいえ,長い論文を読むのは,やっぱり面倒なのである。
文献を読んだらすぐにメモを取らないと,どんどん忘れてしまう。。。いったい何をやっているんだろうか。砂浜に城を建てるような案配だ。
2009年4月22日 (水)
Hayduk, L.A., Glaser, D.N.(2000) Jiving the four-step, waltzing around factor analysis, and other serious fun. Strucural Equation Modeling. 7(1), 1-35.
SEMNETメーリングリストでの議論を基にした論文。長い長い論文だったが,書き方がカジュアルというか冗長なので,読むのは案外ラクだった。
題名にあるfour-stepというのは,あるSEMのモデルをつくるとき,(1)EFAモデル, (2)CFAモデル, (3)SEMモデルの順に制約をかけながら進んでいくやり方のこと。CFAモデルの適合度が低かったら測定部分の問題,SEMモデルの適合度が低かったら構造部分の問題,つまりこのやり方なら測定と構造を分離して検証できることになる。この考え方を著者らは徹底的に批判するが,その最大のポイントは,因子数が正しいかどうかは誰にもわからない,という点。
four-stepはいわれているほど正しくないよ,という論文であって,four-stepよりも良い方法があるよという論文ではなかった。それはいいとしても,いったんfour-step擁護者の主張をすごく拡大解釈しておいて,やおらそれを叩くというあたりが,なんだか筋の悪い議論に思えて仕方がない。適合度指標だけで正しい因子数を求めることが出来ると思っている人が,ほんとにいるんだろうか?
2009年2月22日 (日)
Glockner-Rist, A., & Hoijtink, H. (2003) The best of both worlds: Factor analysis of dichotomous data using item response theory and structual equation modeling. Structural Equation Modeling, 10(4), 544-565.
順序尺度の変数が指標になっている多母集団SEMモデルで測定不変性を調べる方法(←あまりに長いのでこのブログの前の記事からコピー)についての論文,第三弾。SEM的アプローチとIRT的アプローチは結局同じものなのよ,という啓蒙論文。
群間で指標の因子負荷や閾値が違うかどうか(IRTでいうところのDIF)を調べる方法として,多群分析のほかにMIMICモデルを組む方法も紹介されていた。男女の2群のモデルを組むのではなく,性別という共変量を投入して,性別から指標へのパスを引いていくわけである。ふつうのSEMでは見たことがあったが,順序尺度のSEMでもその手はアリなのだな。
わざわざSEM誌の論文などという面倒なものに手を出しているのは,多群分析でpartial invariantなモデルをつくるとき(一部の指標の負荷や閾値が群間で異なるモデルをつくるとき),制約を置いたりはずしたりしていくのは閾値を先にするのがよいか負荷を先にするのがよいか,といういささかマニアックな話に関心があったからである。この論文は「閾値を決めるのが先」と示唆してはいるものの(備忘のため書いておくとp.555),そうするのがよいというエビデンスを示しているわけではなかった。なあんだ。
まあいいや,この話題について調べるのはそろそろ打ち止めにしておこう。
先週のとある日,諸般の事情でもう眠くて眠くて,もう机に頭をぶつけそうだ,という時間帯があった。いまデータの分析をしたら絶対に間違えると思い,仕事を中断しコーヒーをすすりながらこの論文を読んだ次第である。おかげで内容が全然頭に残っていない。手元にあるコピーにはあちこちに俺の字で書き込みがあるのだが,全然覚えていない箇所が多い。いかんなあ。
2009年2月13日 (金)
Millsap, R. & Tein, J.Y. (2004) Assessing factorial invariance in ordered-categorical measures. Multivariate Behavioral Research. 39(3), 479-515.
順序尺度の変数が指標になっている多母集団SEMモデルで測定不変性を調べる方法(長い...)についての論文,第二弾。イキオイがついているうちに,と思って目を通した。
論文の焦点は,測定不変性を調べる具体的な順序というよりも,モデルの同定条件にあるようであった。関心のあるところを抜き書き:
順序カテゴリカル指標がp個あるとする。k番目の群に属するi番目の人のj番目の指標の得点をX_{ijk}とする。どの指標も値\{0,1,...,c\}を取り,その値は潜在反応変数X^*_{ijk}と閾値\nu_{jk1},...\nu_{jk(c-1)}で決まるものとする。潜在反応変数の平均ベクトルを\mu^*_k,潜在反応変数の共分散行列を\Sigma^*_k,因子分析モデル(因子数r)の項目切片ベクトルを\tau_k, 因子パターン行列を\Lambda_k, 独自因子の分散をあらわす対角行列を\Theta_k, 因子共分散行列を\Phi_k,因子平均行列を\kappa_kとする。
順序カテゴリカル指標の多群因子分析におけるモデル同定のためには,たとえば以下の手順に従うと良い。
因子構造が1因子構造ないし単純構造の場合:
- ある群で,潜在反応変数の平均を0,分散を1に固定する(\mu^*_k=0, Diag(\Sigma^*_k)=I)。これでこの群の閾値パラメータを同定できる。
- 上の群で因子平均を0に固定する(\kappa_k=0)。
- すべての群で,項目切片を0に固定する(\tau_k=0)。また,各因子について1項目選び,負荷を1に固定する(この項目のことを基準変量と呼ぶことにする)。
- あるmを選び(二値変数の場合にはm=1),すべての項目についてm番目の閾値に群間等値制約を置く(\nu_{jkm}=\nu_{jm})。さらに,それぞれの基準変量については,もうひとつの閾値についても群間等値制約を置く。二値変数の場合は,基準変量の潜在反応変数の分散を(たとえば)1に固定する。
p+r個の閾値を不変にするだけでよく,基準変量のすべての閾値を不変にするわけではないことに注意。また,因子平均,因子共分散行列,独自因子分散を制約していないことに注意。
因子構造が1因子構造でも単純構造でもない場合,モデル同定の十分条件は指標が量的な場合でさえあきらかでないが,同定の問題を量的な場合と同じところにまで持っていくためには:
- ある群で,潜在反応変数の平均を0,分散を1に固定する(\mu^*_k=0, Diag(\Sigma^*_k)=I)。これでこの群の閾値パラメータを同定できる。
- 上の群で因子平均を0に固定する(\kappa_k=0)。
- すべての群で,項目切片を0に固定する(\tau_k=0)。また,各群のパターン行列に制約を置いて,回転の観点から見てユニークであるようにする。その方法はいろいろあるが,一般的なやり方は,r個の項目を選び,そのr行からできる行列を単位行列にすることである[その因子にしか負荷を持たない項目を確保し,それを基準変量にするということだろうな]。
- ふたつのmを選び(項目が二値の場合にはm=1だけ),すべての項目について,m番目の閾値に群間等値制約を置く(\nu_{jkm}=\nu_{jm})。項目が二値の場合は,さらにすべての潜在反応変数の分散を1に固定する(Diag(\Sigma^*_k)=I)。
測定不変性の検討という観点から見ると,潜在反応変数の分散を1に固定してしまうことには欠点がある。独自因子の共分散行列\Theta_kの不変性を評価するのが難しくなってしまうのである。たとえば,負荷\Lambda_kが不変で,すべての群の潜在反応変数の分散が1に固定されているとしよう。このとき,共通因子の共分散行列\Phi_kが群間で異なれば,独自因子の共分散行列\Theta_kも群間で異なってしまう。この問題を避けるためのもうひとつの方法は,独自因子の分散を1にしてしまうことである(\Theta_k=I)。Mplusではこの制約を「シータ・パラメータ化」と呼んでいる。測定不変性の検討に際しては,連続潜在変数の分散の不変性に関心があるのでない限り,「シータ・パラメータ化」が適切である。
測定不変性の検討に際しては,まず負荷の不変性を検討し,それから閾値の不変性を検討し,最後に独自因子分散の不変性を検討する,という順番が想定されているようであった(先週読んだTemme(2006)の意見と異なる)。もっとも,その順番が良いのだという明確な議論はなかったように思う。
LISRELをつかったときとMplusをつかったときのモデルの違いについて詳細な説明があった。LISRELの部分は飛ばして読んだので詳しくはわからないが,閾値の指定があまり細かくできないので,この問題についてはMplusのほうが有利らしい。
Millsap先生はwebでこの論文のMplusのシンタクスを配っておられる。神のような人だ。
去年,非常勤先の講義に,友人のKくんがデータを取りに来たので,ついでに研究の話を喋ってもらい,さらには昼飯をつきあってもらった。その際,論文を手に入れるのが大変なんだよね,という話をしたら,国会図書館で手に入りますよ,とKくんがいう。いやいや,実は国会図書館の雑誌って案外そろってないのよ,と偉そうなことを云ったが,実は関西館の郵送取り寄せのことしか頭になかった。で,このあいだ国会図書館のwebをよくよく見てみたら,なんと,東京館に足を運べば館内端末からものすごくたくさんの雑誌に全文アクセスできるし,一枚20円くらいで印刷もできるのであった。知らなかった。嘘ついちゃった。
で,今週時間を作って会社を抜け出し,上記論文をはじめ,手に入れたかった論文を10本ほど印刷してきた。国会図書館は事実上の初体験(二十年ほど前に行ったかもしれないが,記憶にない)。ロッカーにカバンを預け,妙なビニール袋に手荷物を入れるあたりから,もうワクワクしてしまった。大きな図書館は,大きいというだけでなんだか楽しい。あの立ち入り禁止の暗い階段を間違えて下りたら,村上春樹の小説みたいに,謎の老人に監禁されて無理矢理読書させられ,あとで脳みそをちゅうちゅうと吸われちゃったりして。。。などと空想が膨らむ。今度は勤務時間じゃないときに,ゆっくり探検してみたいものだ。
2009年2月10日 (火)
Temme, D. (2006) "Assessing measurement invariance of ordinal indicators in cross-national research." in Diehl, S., & Terlutter, R. (eds.) "International Advertising and Communication: Current Insights and Empirical Findings." pp. 455-472. Gabler.
仕事の都合で読んだ。順序変数が指標になっているモデルの測定不変性を検討する方法について悩んでいたら,sem-netでまさにその質問をしている人がいて,Millsap&Tein(2004)とともにこの論文がお勧めされていた。とても急いでいたので,購入申請を出し,この章だけPDFを買い,プリンタが吐き出してくるその横で大急ぎで読んだ。論文を見つけてから読み始めるまで5分足らず。あっちこっち図書館を探したりするのが馬鹿馬鹿しくなってしまう。
多母集団のSEMで測定不変性を検討する手順としては,まず因子負荷に群間等値制約を置いたモデルと置かないモデルを比較するのが普通だと思う。前者が勝って(metric invariance)なおかつ因子平均を比較したいときになってはじめて,項目の切片に群間等値制約を置こうかどうしようか(scalar invariance)という話になる。んじゃないでしょうか。
指標が二値変数や順序変数のときは,項目の切片のかわりに閾値が登場するが,metric invarianceの検討にあたっては,因子負荷と閾値の両方について考えないといけない。MplusのマニュアルやサポートBBSを読んでいると,かのMuthen導師は閾値と負荷は常にタンデムで扱うべきだと強硬に主張しておられる。等値制約するんなら両方そうしなきゃいけないし,自由推定するんなら両方そうしなきゃいけない,ということだ。カテゴリカルSEMの日本語の解説はなかなか見当たらないんだけど,豊田本(疑問編)の説明もそんな風な感じだった。
IRTでいうところの項目曲線は,SEMでいうところの閾値と負荷のどっちかが変わるだけで変わってしまうわけだから,まあそういうもんかなあ,という気もする。しかし,これはなかなか不便な話だ。プラクティカルにいえば,完全な測定不変性が確保できなくても,特定の項目について部分的に等値制約を緩め,なんとかpartial invarianceに辿り着きたいというのが人情である。その際,緩和するパラメータはなるべく少なく済ませたい。それに,もし閾値だけ等値なまま負荷だけ自由推定できたら,群間での負荷のちがいについて解釈しやすいではないか。
導師夫妻には怒られちゃうかもしれないけど,この論文によれば,そういう手順もアリなんだそうである。ただし直観に反して,まず負荷に群間等値制約を置いて閾値の不変性を検討し,次に閾値に群間等値制約を置ける項目について負荷の不変性を検討する,という順序が良いのだそうだ。実際の分析例でも,閾値も負荷も群間等値な指標,閾値が群間等値で負荷がちがう指標,閾値がちがって負荷が群間等値な指標の3つが混在したCFAモデルをつくってみせている。へー。
ともあれ,Muthen&Asparouhov(MplusのWeb Note 4),Millsap&Tein(2004), Glockner-Rist&Hoijtink(2003),あたりがこの話題の基本文献であることがわかった。読まないといけないなあ。たぶん読まないけど。
あれこれ悩んだせいで締め切り間際になってしまい,会社に泊まりこむ羽目になってしまった。その後の週末にたっぷり寝たんだけど,なんだか疲れが取れない。そういうお年頃なのである。
2008年12月15日 (月)
Grewal, R., Cote, J.A., Baumgartner, H. (2004) Multicollinearity and measurement error in structural equation models: Implications for theory testing. Marketing Science, 23(4), 219-529.
構造モデルが重回帰になっているような簡単なSEMモデルを想定し(例:4つの潜在変数からひとつの潜在変数にパスが伸びているモデル。各潜在変数は4つの指標を持つ),{潜在変数間の相関,測定誤差の大きさ,目的変数のR2,真のパス係数のパターン,標本サイズ}を操作してモンテカルロ・シミュレーションを行い,パス係数の有意性検定での検定力を推定しました。検定力は潜在変数間の相関が高いときに下がりますが,測定誤差の大きさ,R2の低さ,標本サイズの小ささによっても下がりました。という論文。
重回帰における多重共線性の問題は広く知られているが,SEMでの構造方程式での多重共線性については,なぜかあまり気にする人がいないように思う。このたび仕事の関係でそのあたりについて悩むところあったので,ネットで探して読んでみた。所詮シミュレーション研究だから,ああそういう状況ではそうなるんですかというしかないんだけど,勉強にはなりました。
この論文が示しているように,たとえばLV1とLV2のそれぞれからLV3にパスが伸びているSEMモデルで,それらしいパス係数が推定されていても(そしてまともな適合度が得られていても),実はLV1とLV2の間に高い相関があったりすると,そこんとこの係数に限り信頼できないかもしれないわけだ。なるほど,気をつけないといけない。たいていのアウトプットでは,潜在変数間の相関なんていちいち書かないし。
SEMによって測定誤差を分離することができるのだ,という一般的解説が頭にあったので,測定誤差が大きいときに多重共線性の問題が深刻になるという話は,ちょっと思いつかなかった。なるほどなあ。その点を確認するためには,Fornell&Larcker(1981)のAVEという統計量と,潜在変数間相関の二乗とを比較するのがよいそうだ。よくわからないけど,どうやらAVEとはある潜在変数が配下の指標の分散を説明している割合のようなものらしい。要するに,弁別的妥当性がない多重指標モデルはまずいということなんだろうな。
潜在変数間の相関があまりに高いときには,潜在変数間にパスを引くのをあきらめ,潜在変数間の相関行列を分析せよとのこと(構造モデルを取り除いて,ただの測定モデルにしちゃうわけだ)。なるほどなあとは思うが,そこからどう進めばよいのか...因子間相関行列をグラフィカルモデリングに持ち込むという例が,しばらく前の心研に出ていたが,相関が高すぎる場合はうまくいかないだろうし...
2008年11月21日 (金)
Fornell, C. (1994) "Partial Least Squares" in Bagozzi, R.(ed.) "Advanced Methods of Marketing Research." Wiley.
仕事でPLSモデリングについて急遽理論武装する必要が生じ,上司様の蔵書を引っ張り出して目を通した。前に同じような都合でChinによる解説を読んだことがあるのだが,あれよりもわかりやすいような気がする。
共分散構造分析の解説書はいまや汗牛充棟という様子だが,PLSモデリングについての日本語の解説をまだみたことがない(PLS回帰を分析化学の手法として解説しているものは多いけど)。なぜだろうか? 間違いなくニーズがあると思うのに。
ふつうのSEMを見慣れた目からすると,PLSによるSEMは謎めいた手法で,びっくりするくらい小さな標本サイズで推定できてしまうし,分布についての仮定がないし(多変量正規性から離れてもロバストだという話ではなく,そもそも仮定がないのだ),適合度に相当する概念がないし...不思議だけど,実用性が高いし,すごく面白い。
ほかに何本かデータ解析方面の論文を読んだような気がするが,思い出せない。うーん,よくないなあ。
2008年10月27日 (月)
Cote, J.A., Buckley, M.R. (1988) Measurement Error and Theory Testing in Consumer Research: An illustration of the Importance of Construct Validation. Journal of Consumer Research, 14(4), 579-582.
相関の希薄化についての短い啓蒙論文なのだが,ちょっと面白いのは,どのくらい希薄化するかをむりやり定量的に一般化してみせているところ。なんでも著者らのメタ分析(JMR,1987)によれば,態度指標における真の(traitの)分散は30%, 手法による分散は41%, 行動指標における真の分散は42%, 手法による分散は26%,手法の相関が0.55だそうな。ここから算出するに,態度指標と行動指標の標本相関は,仮に真の相関が1.00だとして0.53, 逆に0.00だとして0.18となる由。ちょっとした数字の遊びだが,こうしてデモンストレーションされるとインパクトがあるなあ。仕事には使えないけど,研修のネタにつかえそうだ。
2008年10月21日 (火)
Cohen, J. (1992) A power primer. Psychological Bulletin, 1992, 112(1), 155-159.
仕事の都合で,効果量についてあわてて勉強する羽目に。正直,よく知らんのである。別に心理学の論文書く訳じゃないからどうでもいいと思って,油断していた。
とりあえず,有名な先生が書いた啓蒙論文を拾ってきて目を通したところ,さあこれからだ,というところでいきなり最終ページに到達してしまい,ちょっと呆然。効果量が出てくる主な文脈として,(1)サンプルサイズを決めたり検定力を求めたりするとき,(2)個別の研究で検定のかわりに,(3)メタ分析のとき,の3つがあると思うが,この論文は(1)だけに焦点を当てた内容であった。(2)の方向の説明が欲しかったのに。がっくりしたが,読み終えるまで気がつかない方がどうかしている。
よく効果量の説明で,Cohenの提唱する基準(小0.2, 中0.5, 大0.8)ってのが出てくるけど,その根拠はどこにあるのかしらん。この論文にも出てきたけど,特に説明はない。やっぱり本を読まなきゃいけないようだ。Cohen先生も, For readers who find this [simplest explanation] inadequate, I unhesitatingly recommend Cohen(1988) なあんて書いておられる。うーん,こういうときのunhesitatinglyってのは,ちょっとユーモラスなニュアンスがあるのかな,そうでもないのかな。
Fern, E.F., Monroe, K.B. (1996) Effect-size estimate: Issues and problems in interpretation. J. Consumer Research, 23, 1996.
(2)のタイプの論文。これは消費者行動系の雑誌論文なので,職場で堂々とめくっていたのだが(別に誰も気にしちゃいないと思うけど),今度は眠くて参った。
内容は,まず効果量指標のレビュー(案外いっぱいあるのだ。ただの平均差の効果量さえ3種類もあるぞ)。それから効果量に影響する様々な要因についてのレビュー(指標の信頼性とか,標本の等質性とか,尺度の水準数とかなんとか)。途中で面倒になっちゃって,適当に読み飛ばしてしまった。
効果量は重要性の指標ではない。効果量に実質的な有意性とか重要性とかを帰属させようとする人への最良のアドバイスは「やめとけ」だ,とのこと。いや,正論ですけどね。じゃあ重要性を求めろっていわれたら,どうすりゃいいのさ。
いまこれを書くためにぱらぱらめくってみたら,読んだ覚えのない面白いことが書いてあって,こりゃよほどいい加減にめくったな,と反省。これではただの自己満足だ。
標本サイズのくだりで,こんな事が書いてあった。有意な結果が得られたとき,その標本サイズが小さいとその結果を当てにしない人が多いが,これは伝統的な観点からは理屈に合わない(効果量はむしろ大きいわけだから)。しかしベイジアンの観点からみると,効果が同じなら大標本のほうがより証拠として価値がある,という見方は正しいのだそうだ。この話,前にどこかで(たぶん別の文脈で)読んだことがあるんだけど,どこだっただろうか? 思い出せなくて気持ちが悪い。
2008年7月20日 (日)
相対的重要度関連の論文を2本。
Pratt, J.W. (1987) Dividing the indivisible: Using simple symmetry to partition variance explained. Proceedings of the second international Tampere conference in statistics. 245-260.
学会のproceedingsだが,あまりによく引用されるので,非常勤先の図書館で取り寄せてもらった。
重回帰における独立変数の重要性の指標は標準偏回帰係数×相関係数だ,ということを公理的に証明(!)してみせた論文。残念ながら,さっぱりわかんなかった。
この指標はシンプルだし,和が決定係数に一致するので都合がよいのだけれど,もっともあからさまな難点は,ともすれば負になってしまうというところだろう。著者にいわせれば,負になるのは現象があまりに複雑だということを示しているのだそうだが。。。そんなことをいわれてもね。
Kruskal, W. (1984) Concepts of relative importance. Questiio, 8(1), 39-45.
クラスカルによる初期のレビュー。この雑誌もなんだかよくわからない(スペイン語圏の大学の紀要かしらん)。
うーん,こんなマイナーな論文をのんびり読んでいても埒があかないぞ。
2008年6月29日 (日)
Kruskal, W. & Majors, R. (1989) Concepts of relative importance in recent scientific literature. The American Statistician, 43(1), 2-6.
タイトルに重要性ということばが入っている論文を集めて,重要性をどうやって調べているかを集計した報告。統計的有意性に頼っている論文が多い由。ふーん。
Gustafsson, A. & Johnson, M.D. (2004) Determining Attribute Importance in a Service Satisfaction Model. J. Service Research, 7(2), 124-141.
独立変数の重要性を調べる手法を比較した論文。サービス満足度・ロイヤリティと属性評価のデータについて,PLSモデル,主成分回帰モデル,重回帰モデル,NPE(単相関みたいなもの),重要性の直接評定を比較する。手法を評価する指標は,分散の説明率とか,重要性と重要性の順位の関係が線形になるかどうか(診断性の指標である由。よくわからん)とか,負の係数が出るかどうかとか。
手法を評価する方法がいまいちわからなかったのだが。。。統計的指標は経験された満足に対する属性の重要性をうまく示し,いっぽう主観的指標はロイヤリティに対する属性の重要性をうまく示す由。なるほど,重要性測定手法の良し悪しは,目的変数の生成メカニズムによっても変わるわけだな。
Bring, J. (1994) How to standardize regression coefficients. The American Statistician, 48(3), 209-213.
重回帰式における独立変数の重要性の指標として標準偏回帰係数を使うのは筋が通りません。X1の偏回帰係数は「X2, X3...が固定されたときになにが起きるか」をあらわしますが,X2, X3, ...が固定されちゃったらX1のSDも変わります。ですから偏回帰係数を全体のX1のSDで割る(標準偏回帰係数)のではなく,X2, X3, ...を固定したときのX1のSD,つまり偏SDで割るべきなのです。云々。
ウプサラ大の院生さんが書いた論文。この雑誌は啓蒙的な論文が多いような印象があるのだが,心理学でいうAmerican Psychologistみたいなもんなんだろうか?
論文中には独立変数の重要性がどうこうという話が出てくるが,そもそも偏回帰係数ベースの指標が重要性をあらわしうるのか,という議論は避けていて,あくまで偏回帰係数を重要性指標とみなすにあたっての正しい標準化について述べた論文であった。なるほど,それはそれでわかりやすい。
数学がからきし駄目なのでよくわかんないんだけど,この人がお勧めしている新しい標準偏回帰係数というのは,きっとTypeIII平方和とか部分相関係数みたいなものなのであろう。
2008年6月 3日 (火)
Gromping, U. (2007). Estimators of Relative Importance in Linear Regression Based on Variance Decomposition. The American Statistician 61, 139-147.
相対的重要度についての論文。著者はRのrelimpというパッケージの作者でもある。
Kruskal流のall subset regressionと,それを改善したというFeldmanのProportional marginal variance decomposition(PMVD)というアプローチを比較する。X1がX2を経由してYに影響しているとき(SEM風にいえば,X1に間接効果があって直接効果がないとき),X1はKruskal的な重要度は持つが,Feldmanのアプローチだと重要度が0になるのだそうだ。それはまあ,なんというか,良し悪しですわね。
数学にはからきし弱いもので,Feldmanの提案の中身についてはさっぱりわからない。webで説明を公開しているが,査読論文ではない(この論文で引用されているのもdraftみたいなやつだ)。Feldmanさんに直接問い合わせてみたが(どうもありがとうございました),現時点でもそうらしい。これじゃ引用されにくいだろう,もったいないなあ,と思ったが,この方は自営の統計コンサルタントらしく,webには「PMVDによるヘッジファンドの分析をご提供します」などとハナヤカなことが書いてあるから,全然もったいなくないんだろうな。
この論文には後にMenardという人がコメントを寄せていて,いわく,all subset regressionだのPMVDだのと大変な計算をしなくても,単に偏回帰係数×相関係数なりなんなりを重要度とみなせばいいじゃん,運悪く偏回帰係数が負になっちゃったら絶対値にすればいいじゃん,とのことであった。いやいや,いまそういう話をしてないでしょう,と笑ってしまったが(著者もコテンパンな感じの返答をしている),この人とてプロのstatisticianなわけであって。。。要するに,想定している課題状況がちがうんじゃないかと思う。
2008年5月20日 (火)
都合により論文漬けの一日であった。
Lebreton, J.M., Ployhart, R.E. Ladd, R.T. (2004) A Monte Carlo Comparison of Relative Importance Methodologies. Organizational Research Methods. 7(3), 258-282.
相対的重要度の特集号に載った論文。相関や偏回帰係数やJohnsonのepsilonのうち,相対的重要度指標として良いのはどれかを調べるために,指標の数や基準関連妥当性や多重共線性や単純構造の有無などを直交計画で動かしてモンテカルロシミュレーションをおこなう。
シミュレーションのやりかたは勉強になったけど。。。うーん。この論文が調べているのは要するに,Budescuのdominance 指標と近い振る舞いをするのはどの指標か,ということなのである。そこんところに納得できるかどうかで,評価が分かれると思う。
論文の前半で,いかにdominance指標が重要度の指標として優れているかを力説しているのだけれど,それは結局重要度の定義によって決まることなんじゃないか,という気がして仕方がない。というか,独立変数間の関係についての洞察を求めず,ただ重要度のランク付けを求めるという態度そのものが,データ解析の視点としていかがなものか,という気がしてしまう。
Budescu, D.V., Azen, R. (2004) Beyond Global Measures of Relative Importance: Some Insights from Dominance Analysis. Organizational Research Methods. 7(3), 341-350.
同じ特集号の巻末論文。dominance analysisの使い方あれこれの紹介とか,今後の展開の紹介とか(従属変数が複数の場合とか)。
dominance analysisでは,行にサブモデル(独立変数がp個あったら2^p-1行),列に独立変数(p列),セルに「そのサブモデルに当該の独立変数を入れた場合と抜いた場合のR2の差」を入れた表をつくるが,その表からいろいろな定性的情報が読み取れるよ,というくだりがあった。「X1を考慮したときはX2よりもX3が重要だけど,考慮しないときはX2のほうが重要なのね」とか。
そういった情報がどのくらい有り難いのか,仮に有り難いとしてそれを読み取るために最適な方法がdominance analysisの表なのかどうか,俺にはどうもよくわからないのだけれど(graphical modelingのほうがいい場合もありそうだ),それはともかく,ここで示唆されている方向は,ただ重要度のランク付けを求めるんじゃなくて独立変数間の関係について探索しなさい,ということだと思う。
我が意を得たりという気分だが,でもそういう探索のためには,単相関と偏回帰係数を両にらみしつつ考えるような,ローテクな方法でも十分役に立つんじゃないだろうか? 相対的重要度指標の価値はどこにあるんだろうか,と再び考え込んでしまう。うーん。
2008年5月19日 (月)
仕事の都合で,相対的重要度関係の論文を二本。
Budescu, D.V. (1993) Dominance analysis: A new approach to the problem of relative importance of predictors in multiple regression. Psychological Bulletin, 114(3), 542-551.
重回帰をベースに独立変数の相対的重要度を求める方法としてはKruskalの方法が有名だが(p個の変数のうち任意個を用いる重回帰式を片っ端から求め,2^p-1本の式を通じた偏回帰係数の二乗の平均を求める),その系統の方法で一番評判が良いのが,どうやらBudescuらのdominance analysisらしい。この方法が初お目見えした論文。
この段階では,著者はp個の変数を強い順に並べることだけを考えているようで,仮にうまく順番がつけられたら重要度の定量的な評価はKruskalに近い方法でやる,とのこと(偏回帰係数じゃなくて部分相関係数の二乗の平均を求める)。運悪く順番がつけられなかったら,重要度は付与できないと思し召せ,ということらしい。そりゃあちょっとストイックだなあ。前に読んだJohnsonのレビュー論文には,この論文のあとで著者らは態度を軟化させた,というようなことが書いてあったと思う。
Courville, T., & Thompson, B. (2001) Use of structure coefficients in published multiple regression articles: beta is not enough. Educational and Psychological Measurement, 61(2), 229-248.
調査データで重回帰をやるときは,偏回帰係数だけではなくて構造係数(xとy-hatの相関係数)もみておかないとダメですよ,という啓蒙的解説が前半。後半は,Journal of Applied Psychologyから実際の論文例を挙げて片っ端から批判していく。大変失礼ながら,ヒマな人たちだなあ,と思ってしまった。うむむ,申し訳ありません。
相対的重要度関係の論文は,Organizational Research Methodsとか,Educational and Psychological Measurementとか,ナニソレ?というジャーナルに載っていることが多くて,入手に困っていた。ところがつい数日前,Sage発行の雑誌の論文は,今月いっぱい全て無料でダウンロードできることを発見。神の恩寵というか,読まない言い訳ができなくなったというか。。。
2008年5月 8日 (木)
Lehmann, D.R. (2006) Using Regression to answer "What if." in Grover, R. & Vriens, M. (eds.) "The handbook of marketing research," Chapter 13.
かなり間が空いたが,ハンドブック一人読書会の第三弾。
回帰の初歩の章だから甘くみていたが,経済統計系の慣れない用語がでてきてちょっと戸惑った(弾力性とか,Hausman検定とか)。まあきっと経済系の人だって,それはそれで知らない話があるだろう,と自分を慰める次第だが,でも重回帰の周辺で,心理学出身の人が知ってて経済学出身の人がよく知らない話題ってあるんだろうか? bとβとどっちがいいか,なんていう話がそうか? なんだかつまんない話題だなあ。
Iyengar, R., & Gupta, S. (2006) Advanced Regression Models. in Grover, R. & Vriens, M. (eds.) "The handbook of marketing research," Chapter 14.
第四弾。判別分析,ロジスティック回帰,多項ロジット,多項プロビット,それからちょっぴりトービット分析の話。
多項選択のモデルとして多項ロジットモデルと多項プロビットモデルが用いられているが,前者はIIA仮定の下にあるので,各選択肢に影響している未知の因子が相関しているような場合には後者を選べとのこと。そ,そうなんですか。リンク関数の指定それ自体はただの趣味の問題かと思っていた。よくわかんないけど,張り切ってプロビット関数を使ったところで,誤差の共分散を推定しないモデルを作っちゃったら同じことじゃないかしらん。
2008年5月 7日 (水)
用事があって,信頼区間についての論文を三本読んだ。
Rouder, J.N., & Morey, R.D. (2005) Relational and Arelational Confidence Intervals: A Comment on Fidler, Thomason, Cumming, Finch, and Leeman (2004). Psychological Science, 16(1), 77-79.
前に読んだ論文(なんと,もう3年前か)へのコメント。平均の信頼区間は記述的には有用だが,条件間の比較の際にはわかりにくいよ,云々。
Fidler, F., Thomason, N., Cumming, G., Finch, S., & Leeman, J. (2005) Still Much to Learn About Confidence Intervals. Reply to Rouder and Morey (2005). Psychological Science 16 (6) , 494-495.
そんなことないよ,云々という返答。言葉尻がちがうだけで,云っていることは大体同じみたいだ。
Cumming, G., & Finch, S. (2005) Inference by Eye: Confidence Intervals and How to Read Pictures of Data. American Psychologist 60(2), 170-180.
信頼区間を図示しましょうという啓蒙論文。
信頼区間を正しく説明する文章の例を挙げているところが面白かったので,抜き書き:
- (This is our favorite:) Our CI is a range of plausible value for \mu. Values outside the CI are relatively implausible.
- We can be 95% confident that our CI includes \mu.
- Our data are compatible with any value of \mu within the CI but relatively incompatible with any value outside it.
- The lower limit is a likely lower bound estimate of the parameter; the upper limit a likely upper bound.
SEをエラーバーにしたときの図の読み方について,ごくごく初歩的な勘違いをしていたことに気が付いた(あまりに初歩的な勘違いなので恥ずかしくて書けない)。この著者らには「科学者がいかに信頼区間のエラーバーを読み間違えているか」という実証研究もあって,なあんだみんなわかってないのねえ,なんて笑いながら読んだ覚えさえあるのに。。。気が付いてちょっと悲鳴をあげてしまった。誰かに嘘を教えていたりはしないと思うのだが。。。うわああん。。。
2008年4月 6日 (日)
Eltinge, J. (2001) "Diagnostics for the Practical Effects of Nonresponse Adjustment Methods." in Groves, R.M. et. al (eds.) "Survey Nonresponse", Wiley.
無回答の補正だかなにかのために,調査データになんらかのウェイティングをするとして,そのウェイト値の算出方法が2種類あるとき,どっちがいいかを決めるためにはどうしたらいいか,という話。信頼区間や検定力曲線を比較する。
この度入手した調査無回答の論文集のなかの一編(まさか自分がそんな本を読むことになるとは。もうなにがなんだか)。数学的にはあんまり高度ではない章なので,目を通してみたのだが,うーむ,これはほんとにマニアックな話だ。
そういえば先日,まったく未知の方から,このブログを経由してコーヒーミルを買ったのは私です,と名乗るメールを頂いた。ウェイティングについて検索していてこのブログをごらんになった由。てっきり知人の誰かだと思っていたので,驚いたのなんの。。。世の中なにがあるかわからない。
2008年3月 9日 (日)
Little, R.J.A., Vartivarian, S. (2005) Does weighting for nonresponse increase the variance of survey means? Survey Methodology, 31(2), 161-168.
いま手元にないのであいまいなのだが。。。無回答の補正のためになんらかの補助変数をつかってウェイトバックしたとき,統計量の偏りは減るが分散は大きくなる,と一般に考えられているが,一概にそうとはいえません,という内容であった。偏りが除去できるかどうかは補助変数と無回答との関連性によって決まり,分散がどうなるかは補助変数と集計対象の変数との関連性によって決まる,とのことである。なるほど,そうだろうなあという話だが,きちんと数式とシミュレーションで示してくれているので,勉強になった。
ここ数ヶ月,ずうっと調査データのウェイティングのことについて考えていた。あれこれ読みかじって改めて痛感したのは,俺には数学のスキルが圧倒的に足りない,ということであった。正直,これではいくら勉強したって埒があかない。これからどうやって生きていけばいいんでしょうかねえ。
いくら文献を読み漁ってもきりがないので,もうこれはこの辺にして別のことを考えよう,と金曜夜に決意した。散乱した資料を整理するついでに,あとで読むつもりだったこの論文に目を通した。雑誌はカナダの学会誌で,マイナー誌なので後回しにしていたのである。これを先に読んでおけばよかったなあ。
ウェイティングは偏りの除去のためにある,というのが直観的な理解だが,「集計対象の変数と強く関連しているが無回答とは関連しない」補助変数でウェイティングすると,無回答による偏りは除去できないが統計量の分散を小さくすることができるわけだ。実際の調査では,非回収誤差はしょうがないけど分散は小さくしたい,という不思議な状況も少なくない(トラッキング調査とか。とにかく経年で不安定なのが困る)。そんなとき,「ウェイティングによって非回収誤差を取り除きましょう」などと云いつつ,良さそうなデモグラフィック属性でツルッと事後層化ウェイティングを掛けてしまう,という方法も可能なわけだな。
この論文も含め,このたびウェイティングをめぐる議論を読んでいて不思議だったのは,みんな特定の調査変数の統計量を真値に近づけることばかり考えているという点だ。実際の集計では,ウェイト値はいったん決めたらすべての変数に対して用いるわけで,どの変数でもMSEがそこそこ小さい,というようなウェイト値が望ましいのではないかと思うのだが。。。まあそれは,俺の視野がそういう多目的的な調査に向いているからかもしれない。
2008年2月26日 (火)
Kish, L. (1992) Weighting for unequal Pi. Journal of Official Statistics, 8(2), 183-200.
こないだ読んだASAの大会発表を論文化したもの。こないだ仕事で読んだ。
それにしても,標本ウェイト関連の文献はたいてい平均や比についてのみ取り扱っていて,analytical な統計量(回帰係数とか)についての議論がなかなか見当たらない。たまに見つけても,やたら難しくて歯が立たない。参るなあ。。。こんな勉強に時間を取られていても仕方ないのに。
2008年1月15日 (火)
Potter, F.J. (1990). "A study of procedures to identify and trim extreme sampling weights." Proceedings of the Section on Survey Research Methods, American Statistical Association, 225-230.
仕事の空き時間に読んだ。
層別抽出とか事後層化とかで,各ケースを抽出確率の逆数でウェイティングして集計するとき,不幸にして抽出確率が小さい層があったりすると,ウェイトがすごく大きくなっちゃって困る。そこで,ある基準を上回ったウェイト値はトリミングしちゃおうという発想が出てくる。その基準を決める方法として,
- 既存の方法を2つ紹介します(MSEの推定値を最小にする方法,NAEPで使われている方法)。
- さらに新手法を二つご提案します(テイラー級数を使う方法,ウェイトの理論分布を使う方法)。
4つの手法をARFデータに適用して結果を比較してみました。という内容。
ARF(Area Resource File)というのは米保健社会福祉省による大規模データベースらしい。実データに適用したところで優劣はいまいちはっきりしないわけだが(そりゃそうだよな),論文の主旨はむしろ4つの手法を並べてみせるところにあるようだ。
テイラー級数を使う方法とMSEを最小化する方法は,ターゲットになる調査変数が同定されているときの話である。調査データにウェイティングするとき,なにが主要な調査変数かは決まっていないのが普通だろうし,もし決まっているのならマルチレベルモデルをつくればいいんじゃないかと思う。というわけで,適用範囲がかなり狭いような気がする。いっぽう,ウェイト分布を使うやり方は魅力的だけど,あいにく難解なもので(ウェイト値はベータ分布に従うと仮定すると...云々。降参),実装しているソフトがないことにはお手上げである。それにNAEP方式でやってもさほど変わらないそうだから,だったらNAEP方式でやればいいやね。
NAEP(全米の学力テスト)で使っている方式とは:ウェイト値はすべて二乗する。その平均のc倍を基準と定める(cは分布をみて決めればよい。NAEPでは10)。基準を上回っているウェイト値は基準まで切り詰め,その分ほかのウェイト値を底上げして(平均が変わらないように),やおら基準を再計算する。これを繰り返す。んだそうな。案外ローテクだなあ。
PotterというのはRTI internatinalというところのひとで,ここはSUDAANという複雑な調査データの分析に特化したソフトをつくっているから,きっとその開発関係者なのであろう。それにしても,延々と検索してもこの種の議論が公的調査の文脈でしかみつからないのが不思議である。マーケティングリサーチでも同じ事が起きるだろうに。みなさんどうしておられるんですかね。想像するに,こんな勉強をしている暇があったら,もっとお金儲けに直結したことを考えた方が良いのであろう。いくら勉強しても統計学者になれるわけではなし。。。
SUDAANをgoogleで検索すると,日本語で言及しているページもあることはあるのだが,最初に出てくるのは大洗町の割烹「寿多庵」である。アンコウ鍋か,いいなあ。。。
2007年12月 5日 (水)
Kish, L. (1990). "Weighting: Why, When and How?" Proceedings of the Section on Survey Research Methods, American Statistical Association, 121-130.
ここんところ,全訳しかねない勢いで読んでいた論文(いや待て,これは査読論文でさえないぞ。なぜこんなに時間をかけているんだ?)。ASAのwebページで公開されていた。
市場調査の会社に拾って頂いたところ,もう親の仇かっていうくらいにデータをウェイティングするので驚いた。そのわりには,ウェイティングについてのまとまった解説がなかなか見当たらないので困っていたのである。市場調査分野の日本語の解説に至っては,ことごとくレベルが低すぎて,実務上の疑問にさっぱり答えてくれない。たとえば,事後層化ウェイトが極端に大きくなってしまったらどうするか。そもそも,なにをもって極端に大きいというべきか。誰か答えられるだろうか? 日本語で解説しているのをみたことがないぞ。
ひとくちに調査データのウェイトつき集計といっても,その内実は実に多様である。Kishによれば,ウェイトを使う理由は7種類あるんだそうである(層への非比例配分,フレームの不備,無回答,統計的調整,標本結合,コントロール用統計表をつかった調整,非確率標本の確率標本への調整)。やれやれ,やっと頭が整理できた。
2007年11月28日 (水)
Lilien, G.L., & Rangaswamy, A. (2006) Marketing decision support models. in Grover, R. & Vriens, M. (eds.) "The handbook of marketing research," Chapter 12.
ハンドブック一人読書会の第二弾。これはマーケティング・リサーチの本だから,勤務時間中と通勤時間でしか読まないぞ,とルールを決めていたのだが,さすがに実現困難であり,早々に破ってしまった。業界団体の大会の開始待ちのため,ホテルの茶店で時間を潰した際に読了。会社員の鏡だねえ。
テクニカルな話はごく一部。広告投入量と売り上げの関係を示すというような,市場反応の簡単なモデルのバリエーションを紹介(ADBUDGモデルってどう発音するんだろうか)。個人ベースのモデル構築の話は1/2頁だけ。なあんだ,つまんないの。
残りの話はすべて,マーケティング意思決定を支援する情報システムはかくあるべし,という非常に一般的な話であった。将来のマーケティング工学は,(アナリストにではなく)一般従業員に対し,(予測や最適化に留まらず)説明を提供してくれる,(グループウェアを越えた)知的決定モデルへと進化するのだそうである。それはすごいですね。市場調査会社なんていらなくなっちまいますね。あーあ。
いや,たった二章で挫折するわけにはいかん。馬鹿高い本だったのだ,意地でも読まねば。
2007年11月19日 (月)
Smith, S.M., & Albaum, G.S. (2006) Basic Data Analysis. in Grover, R. & Vriens, M. (eds.) "The handbook of marketing research," Chapter 11.
私費で買っちゃったので,暇を見つけてちびちび読んでいくことにした。31章もあるから途中で挫折しそうだが。そういえば一昨年,"New methods for the analysis of change"のひとり読書会をはじめたのだが,数章読んだところで転職してしまい,本は前の勤務先に置いてきてしまった。心残りだが,私費で気軽に買い直せるほど安い本ではないし。いつもこんなんばっかしだ。
とりあえず,一番つまんなさそうな章を読んでみた。クロス表とか相関とか検定とか。ほんとにつまんなかったけど,この種の本にはこういう章も必要であろう。
2007年8月 2日 (木)
Xiong, R. & Meullenet, J. (2006) A PLS dummy variable approach to assess the impact of jar attributes on liking. Food Quality and Preference, 17(3-4), 188-198.
JAR尺度の変数を独立変数にして回帰モデルをつくる方法を提案した論文。著者様に送ってもらった。感謝感謝。
ここでいうJAR尺度(just-about-right scale)というのは,このジュースの甘さは「弱すぎる - ちょうどよい - 強すぎる」のどれですか,というような評定尺度のこと。回答者に理想像を直接尋ねているわけで,いつも使えるわけではないと思うが,こういう訊き方が自然な場合もあるだろう。食品の評価とか。
製品への全体的好意度評価と属性評価を得て,改善すべき属性を調べましょう,というような場面で,属性評価がJAR尺度だと厄介である(好意度との関係はどうみても逆V字型だから)。簡単なやりかたは,まず属性評価で回答者を3群にわけ(「弱すぎる」群,「ちょうどよい」群,「強すぎる」群),各群で好意度の平均を求め,たとえば「弱すぎる」群の好意度平均が「ちょうどよい」群よりも大きく下がっていたら,その属性はもっと強くしなくっちゃね,というような見方である。しかしこれでは単一の属性だけを相手にしていて,属性間の相関をみていない。そうではなくて重回帰モデルをつくろう,というのがこの論文の目的。
内容は以下のとおり(なぜかデスマス調で):
JAR尺度を2つのダミー変数(「弱すぎる」と「強すぎる」)で表現しましょう。JAR5件尺度の評定項目があったら,そこから「弱すぎる」変数(値は順に{-2,-1,0,0,0})と「強すぎる」変数({0,0,0,1,2})をつくるのです。こうしてk属性から2k個の変数をつくり,これを回帰モデルの独立変数にしましょう(回帰の手法はなんでもいいけど,まあPLS回帰だということにしておきましょう)。
たとえばその製品の甘さが十分に強いときは,「弱すぎる」と答える人は少ないし,「弱すぎる」ダミー変数の係数は小さくなります。そんなわけで,どうみても2k個全部はいらないでしょうから,ジャックナイフ法で変数を落とします(「弱すぎる」と答えた人が少なかったら落とす,というルールでもいいけど,ジャックナイフ法のほうがよいでしょう)。その結果をFモデルと呼ぶことにします。
さて,「弱すぎる」変数と「強すぎる」変数の両方が生き残る属性があったら,その2つのかわりに,「弱すぎるか強すぎる」変数({-2,-1,0,-1,-2})をいれる手もあります。これをRモデルと呼ぶことにします。FモデルとRモデルの両方で残差を求め,paired t-test をやって,残差の平均が小さいほうのモデルを採用するのがよいでしょう。
うまくモデルができたら,その切片は「全属性をうまく改善できた暁にどれだけの好意度上昇が期待できるか」を示します。ここから予測値の平均値を引けば,改善による好意度上昇の最大幅がわかります。
ご厚意で送ってもらっといてなんだが,いろいろ納得いかない点がある。
まずテクニカルな点では,FモデルとRモデルをつくるくだりがよく理解できない。「弱すぎる」変数と「強すぎる」変数の両方が生き残った属性が複数ある場合,Fモデルはそれらすべてについて,好意度に対する逆V字型が左右非対称だと考え,いっぽうRモデルはそれらすべてについて左右対称だと考えていることになる。しかし,それぞれの属性について左右対称かどうかを別々に検討するほうが,もっと自然なのではなかろうか。
概念的な疑問もある。JAR尺度でわざわざ重回帰モデルをつくろうとする,その動機がよくわからない。考えられる動機は,(1)全属性が「ちょうどよい」になったときの好意度を予測する,(2)好意度を向上させるための改善点を探す,(3)消費者の選好の構造をモデル化する,の3つだと思うのだが,どれもいまひとつ共感できないのである。
- (1)についていえば,全属性が「ちょうどよい」になりうるかどうかが怪しい。製品の属性は往々にしてトレードオフの関係にあるものだからだ。あまりに非現実的な条件下での従属変数の値を予測しても仕方がないと思う。
- もし主な動機が(2)ならば,「弱すぎる」ダミー変数と「強すぎる」ダミー変数の両方が生き残った属性,つまり好意度との関係が明確な逆V字型である属性は,モデルから抜いてしまってかまわないと思う。それがどんなに重要な属性であれ,改善しようがないからだ。いま「強すぎる」と答えた人が4割,「弱すぎる」と答えた人が4割いて,好意度の平均は同程度にかなり低いとしよう。それはとても大事な属性だろうけれども,強くすればいいのか弱くすればいいのか見当がつかない。そんな属性をPLS回帰モデルに投入することには,どういうメリットがあるのだろうか。
- いっぽう(3)の観点からは,なるほど,改善不可能な属性であってもモデルに投入すべきだ。しかしその場合は,好意度への回帰モデルの係数を推定する前に,属性間の因果関係を含めたモデルを探索するのが本筋だと思う。その際にもこの論文でいうダミー変数が役に立つのかどうか,よくわからない。JAR属性同士の関係は逆V字型にならないからだ。
だんだん勤め先の仕事の話そのものになってきてしまい差し障りがあるので,このへんでストップ。ともあれ,あれこれ考えさせられる論文であった。日本にこういう研究をしている人はいないのかしらん。
2007年7月22日 (日)
Chin, W.W. (1998) Issues and Opinion on Structural Equation Modeling. Management Information Systems Quarterly, 22(1)
どういう雑誌か知らないが,全文がwebで公開されている。SEMの使い方についてまとめた短いコメント。会社で変なときに待ち時間が出来たので,その隙に目を通した。
formativeな指標はふつうのSEMではモデリングできないので,PLSをつかえ,とのこと。そんなあ。。。このご意見は,この人がPLSの専門家だからか,それとも98年当時は一般にそう考えられていたのか。それとも,もしや俺が知らないだけで,いまでもformativeな指標があるときはPLSを使うのが普通なのだろうか。
2007年7月 1日 (日)
Johnson, J.W. & LeBreton, J.M. (2004) History and use of relative importance indices in organizational research. Organizational Research Methods, 7, 3, 238-257.
マイナーな雑誌なので入手に困ったが,著者様が送ってくれた。ありがとうございました。
相対的重要度についての特集号に載ったレビュー(そんな特集号があるのね)。ここで相対的重要度というのは,ある結果側変数と複数の原因側変数を押さえている調査データを使い,それぞれの原因側変数に相対的な重要度を割り当てたい,でも原因側変数同士に相関があるので偏回帰係数は使い物にならない,さあどうしようか,という話。紹介されているのは,
(1)単回帰ベースの指標(r,b,β,t,R2増加量,βr)
(2)重回帰ベースの指標(部分相関の二乗のモデル間平均;偏相関の二乗のモデル間平均;BudescuのDominance指標;Anzen&Budescuのcriticality指標)
(3)いったん直交変数に変換する方法(Greenらのδ;著者らのε)
わかりやすくまとめてくれていて,大変助かった。この論文のおかげで霧が晴れた思いである。
もっとも,このテーマにはほかのアプローチもあると思う。主成分回帰やPLS回帰のように次元縮約するやり方もあるし,リッジ回帰という手もあるだろう。事前知識やグラフィカル・モデリングを使い,独立変数間の関係について正面からモデル化しちゃう路線もあるだろうし,データが大きければニューラルネットだっていけそうだ。その意味では狭い範囲に限定したレビューなのだが,ま,なにもかも人に頼ってはいけないよな。
Johnson, J.W. (2000) A heuristic method for estimating the relative weight of predictor variables in multiple regression. Multivariate Behavioral Research, 35,1,1-19.
上の論文でεという指標がお薦めされていたので(まあ自分が提案した指標だからな),国立の図書館に出張してコピーしてきた。数学苦手なのに,こんな雑誌の論文を読む羽目になろうとは。しかも自分でプログラムを書かねばならんのか,と途方にくれていたら,著者様がサンプルプログラムを送ってくれた。尋ねてみるものだ。ありがたやありがたや。
εというのはこういう指標である。変数X1,X2,...,Xkについて,まず,「ひとつひとつにぴったりフィットしつつも直交している」変数Z1,Z2,...,Zkをつくる(こういう手続きをなんていうのかね。直交化?) で,こいつらからYに対して重回帰する。いっぽう,ここが味噌なのだが,こいつらからX1,X2,...に対しても重回帰する。要するに三層のネットができて,真ん中の層(Z)から上の層(Y)と下の層(X)への矢印が延びるわけである。で,XiからYに行くすべての経路(k本)の係数の二乗和を,Xiの重要度とする。
ZからXにパスが延びる,というのは妙な感じだが,そこのところの理屈づけはない。とにかく結果をごらんあれ,Dominance Analysisと似た結果になるでしょう? でもDominance Analysisは2^k回の重回帰をかけなきゃいけないから,kが大きいとき計算できないでしょう? この方法ならkが大きくても大丈夫よ,というストーリー。
このあいだEdwards&Bagozziの論文を読んでいたら,うかつにformativeな測定モデルを組んではいけない,X1,X2,...にひとつづつ潜在変数Z1,Z2....を与え(これが真値),ZiからXiへのパスを引き,その上でZiから構成概念へのパスを引きなさい,そうすればXiの誤差がモデルに組み込めるでしょう,という話があった。この論文のモデルはその話に似ていると思う。この著者にとってZiはただの道具的な変数に過ぎないんだろうけど,もっと積極的に意味づけられないものだろうか。まあどうでもいいけどさ。
思うに相対的重要度などというものは,ピュアな統計学者なら見向きもしない不純な概念なのだろうと思う。今回いろいろ調べていて偶然みつけたのだが,Kruskal&Majorsの相対的重要度レビュー論文に対して,Ehrenbergという人がこんなコメントを寄せている。"I think, however, that they have missed an important factor, which is that only unsophisticated people try to make such assessments." そうかunsophisticated peopleか,と笑ってしまった。
確かに,この人が書いているとおり,"As soon as the relationships in question come to be better understood [...], the discussion turns, I think, to modelling the processes and their possible causal mechanisms as such, rather than their relative 'importance.'" なのである。因果的身分が異なる変数群を一緒にし,さあどれが重要か,と問うのはナンセンスなのだ。
しかしその一方で,(たとえば)顧客満足度を左右する特性がk個ある,特性間の関係についてはどうでもいい,注力すべきなのはどれなんだ!という切実なニーズに,全く応えないわけにもいかない。このギャップを埋めるためには,まず相対的重要度が必要とされる状況を概念的に整理し,分類しておいたほうがいいんじゃないかと思うのだが,うーん,難しくて手に負えない。
2007年6月15日 (金)
Jarvis, C.B., MacKenzie, S.B., & Podsakoff, P.M. (2003) A critical review of construct indicators and measurement model misspecification in marketing and consumer research. Journal of Consumer Research, 30, 199-218.
測定モデルにおいて,指標をformativeだとみなすかreflectiveだとみなすかを正しく定めることはとても大事だ。本論文では[測定モデルの2つのタイプ,その概念的区別] (略)
- 決定に際しての概念的基準を示します
- マーケティング分野で測定モデルを誤って指定している例をレビューします
- 誤って指定するとどんな目にあうのかシミュレーションしてみます
- formativeなモデリングの際のアドバイスを示します
[formative指標モデルとreflective指標モデルを区別する基準]どれかに答えられなかったり,答えが矛盾していたりするのは,構成概念がうまく定義できていないからだ。
- 概念的にいって,指標と構成概念の間の因果関係はどちら向きか
- 指標は入れ替え可能か(formative指標はほかの指標と入れ替えられない)
- 指標は共変するはずか(reflective指標は共変するはず)
- 各指標の因果的先件と帰結は指標間で同一か (reflective指標なら同一)
[多次元的な構成概念]
マーケティング分野での構成概念は抽象度が高く,そのため多次元的であることが多い。これを二次因子モデルで指定する場合,一次因子が{reflective/formative}×二次因子が{reflective/formative}の4通りがありうる。(それぞれについての実例を紹介。略)
[マーケティング文献のレビュー]
J. Consumer Res., J. Marketing, J. Marketing Res., Marketing Sci.の4誌の1977年以降の論文178本から,構成概念1192個を取り出し,どのようにモデル化されているか,本当はどのようにモデル化すべきだったか,の2点を調べた。68%が正しくreflective, 28%が誤ってreflective, 3%が正しくformative, 1%が誤ってformativeであった。(正しくformativeなモデルの実例を紹介。略)
[モデルの誤指定はどのくらい深刻な問題か?]
formativeな構成概念を含んだモデルから共分散行列をつくり,当該の構成概念をreflectiveだとみなしたモデルで分析する,というモンテカルロ・シミュレーションを行った。モデルが間違っていると,構成概念間のパラメータ推定にとても大きなバイアスが生じた。しかもモデルを誤指定しているということは適合度指標からはわからなかった。
[formativeなモデルをつくるときのお勧め][結論] (略)
- モデルを同定可能にするコツ: reflective指標を2つ付け加えるのがお勧め。例: 顧客満足なら全体的満足度や好意度を付け加えるとよかろう。
- 外生変数間相関のモデル化: SEMではふつう外生変数間の共分散を自由推定する。これをformative指標モデルにそのままあてはめると,formativeな指標は外生変数なので,仮説のない共分散が無数に生まれてしまう。それらを0に固定するのも筋が通らないし,すべて推定するとモデルの倹約性が失われる。対策:モデルに少しづつ追加して,適合度指標の変化を見ると良い。ないしRNFIやRPNFIのような指標をつかうと良い。
formative/reflective論文の第二弾。マーケティング分野向けの啓蒙論文という感じで,Edwards & Bagozziを読んだ直後だからあまり得るところがなかったが,formativeなモデルをどうやって同定可能にするか,という話は役に立った。悩んでるのは俺だけじゃないのね。
過去論文を集計するくだりでこんな話が出てきた。一般に,心理学的構成概念はreflectiveにするのが自然で,いっぽう経営上の構成概念(業務の成果とか)はformativeにするのが自然であることが多い由。なるほど,なんとなくわかるような気がするけど,たとえばお店の顧客満足のような心理的概念であっても,もし指標が「レジの前の列が短い」「店内が清潔だ」というような項目だったら,それはやっぱしformativeにモデル化すべきだろう。やっぱし結局は,概念と指標の性質によるとしかいいようがないと思う。
2007年6月 6日 (水)
Edwards, J. R. & Bagozzi, R.P. (2000) On the nature and direction of relationships between constructs and measures. Psychological Methods, 5, 2, 155-174.
ある指標(measure)がreflectiveかformativeかを決めるための一般的原則について論じる。
[構成概念とはなにか,指標とはなにか] (略)
[構成概念-指標間関係の因果方向]
科学哲学の分野で受け入れられている,因果性を確立する際の4つの基準に沿って考えると[構成概念-指標間関係のモデル]
- 弁別性: 構成概念と指標は弁別できなければならない。たとえば,操作的に定義された知能は構成概念になりえない。
- 連関性: 構成概念と指標は共変しなければならない。評価の方法には以下がある:(a)指標間の共変動によって推論する(必要条件を与えるが十分条件を与えてはくれない),(b)頭の中で実験する。どちらも決め手にはならない。
reflectiveな指標の場合,構成概念と指標の間の関係は,モデルがどうであれ変わらない。しかしformativeな指標の場合,構成概念は指標の関数であると同時に,モデルのなかのなにかの従属変数を予測する合成変数でもあるから,その従属変数がなにかによって,構成概念と指標の関係も変わってくる。というわけで,構成概念の意味はあいまいになる。- 時間的先行性: 構成概念における変化が先か,指標における変化が先か。評価の方法としては:(a)原因側を制御する実験を行う,(b)頭のなかで実験する。
後者の場合,結論は指標の定義そのものによって決まる。たとえば,態度→項目提示→反応と考えることもできるし,項目提示→態度→反応と考えることもできる。
Heise(1972)は,SESという構成概念が結果側で,教育・所得などの指標が原因側だ,と論じている。筋は通っているが,たとえば通学年数を教育そのものとみなしているわけで,これは社会経済的現象についてのある種の操作主義である。いっぽう,通学年数が教育のあとに生じ,測定誤差を伴っていると考えれば,これらの指標はそれぞれに対応する構成概念のreflectiveな指標であり,SESはこれらの構成概念の結果である,ということになる。- 対抗する因果的説明の除去: この基準を満たすのが一番難しい。一般的な処方箋はない。ここではライバルとなる説明を同定する方法について考える。(a)準実験のときに妥当性を損なうような脅威について考える。たとえば i)history。原因と結果のあいだに,統制されていない媒介変数があること。ii)instrumentation。原因と結果の間にあるとみなされている関係が,実はデータ収集手法によって引き起こされていること(nuisance factorとか)。(b)頭のなかで実験する。
6個の基本的モデルを考えることができる。(同定可能なモデルかどうかはこの際どうでもよろしい)以上を整理すると
- direct reflective model: (指標 x_i) = (因子負荷 λ_i)×(構成概念 ξ) + (誤差δ_i)。テスト理論,因子分析,などなどはこのモデル。
- direct formative model: (構成概念 η) = Σ(係数 γ_i × x_i) + (誤差ζ)。使い道としては:(a)観察変数の合計を表す潜在変数をつくるとき。ζを含めないことも多い(主成分分析,正準相関分析,PLSなど)。(b)いくつかの変数の効果を要約するブロック変数をつくるとき。(b)潜在変数の実験的制御の効果をあらわすとき。例, 睡眠剥奪(formative指標)で疲労(構成概念)を制御し,別の変数で操作チェックする(reflective指標)。
- indirect reflective model: reflectiveモデルなのだが,指標と構成概念のあいだをいくつかの潜在変数が媒介していて,それらの変数にもそれぞれ誤差が刺さっているモデル。
- indirect formative model: formativeモデルなのだが,指標と構成概念のあいだをいくつかの潜在変数が媒介していて,それらの変数にもそれぞれ誤差が刺さっているモデル。
- spurious model: まずいくつかの潜在変数があって(相関もあるかも),それらが構成概念の原因でもありまた指標の原因でもあるモデル。仮に指標の誤差が0ならば,direct formative モデルになる。
- unanalyzed model: そのほかいろいろ:(a)構成概念も指標も外生(ただ相関だけがある), (b)指標は外生で,それと相関のある潜在変数があって,それが構成概念の原因, (c)指標は外生で,ほかのなにかの指標と相関していて,そいつらが構成概念のreflectiveな指標, (d)構成概念が外生で,別の潜在変数と相関があり,指標はそいつのformativeな指標。
[適用事例]
- reflectiveな指標が構成概念の原因をあらわしている→spurious
- reflectiveな指標が構成概念の本質的な属性をあらわしている→direct reflective
- reflectiveな指標が構成概念の結果を表している→indirect reflective
- formativeな指標が構成概念の原因を表している→indirect formative
- formativeな指標が構成概念の本質的な属性をあらわしている→direct formative
- formativeな指標が構成概念の結果を表している→unanalyzed
[要約と含意]
- ライフ・ストレス。SRRS(社会再適応評価尺度)はライフストレスのreflectiveな指標であるともformativeな指標であるともいわれている。上記基準を適用すれば,弁別性はある,連関性はある,時間的先行性は怪しい(ライフストレスを引き起こすライフイベントよりは後だが,ライフイベントによって生じる生活パターンの変化より前かもしれないから),対抗説明がありうる(ライフイベントがSRRS得点とライフストレスの原因である)。個々のライフイベントを共通原因とするspurious modelが正しかろう。
- 組織コミットメント。広く用いられている指標OCQは一次元尺度であると捉えられており,内的整合性で信頼性を評価するのが通例である(つまりdirect reflective modelである)。しかし項目のなかにはコミットメントの原因のreflectiveな指標もあれば,コミットメントの結果のreflectiveな指標もある。spurious modelとindirect reflectiveモデルの混ざったのが正しかろう。
- 社会的相互作用。Doney&Cannon(1997)の指標はformativeな指標であるとされている。しかし各項目はイベントの有無について尋ねているので,構成概念のほうが時間的に先行している。さらにそれらのイベントには会話と会合がある。二つの下位構成概念についてのdirect reflectiveモデルが正しかろう。
本稿のガイドラインをつかい,かつ構成概念-指標間関係についての補助理論を充実させることをお勧めします。
本稿の原則を適用することによる主な副産物としては:
- direct formative modelの多くの例は,実はspurious modelにしたほうがよい。モデルが同定できなくなるのならdirect reflectiveな指標を付け加えるがよかろう。
- 一般的構成概念の諸側面を記述する項目を,一般的構成概念のdirect reflectiveな指標とみなしてはいけない。
- 信頼性係数が低いからといってdirect formative modelをつくるのはやめろ。formativeかreflectiveかというのはアプリオリな概念的基準で決めるべきだ。
sem-netで紹介されていた論文。ネットで拾った。
SEMは独りで読みかじっただけなので,基本的なところについていっぱい疑問があって困ってしまう。たとえばこのあいだ,かのトヨダ先生によるAmosのセミナーに行ったらば,弟子の院生が示したすごく初歩的なモデル例のなかで,"講義後の充実感"が潜在変数,講義への満足感・理解度・目的一致度がその指標となっていた。たったこれだけのことで,いやちょっと待って,矢印の向きが逆じゃないの?むしろ理解度が高いと充実感が高くなるんじゃないの?だからこれはformative indicatorであるべきなんじゃないかしら,とすっかり混乱してしまったのである。まあ矢印の向きについて考えるのは大事なんだろうけど(Loehlinの本にもboth possibilities should be kept in mindと書いてある),こういちいち悩んでいたのでは身が持たない。場数を踏んでいない悲しさである。
会社の仕事でもSEMのモデル構築について悩むことがあったので,暇をみつけて読んでみた。「こんなデータのときにはformativeなモデルをつくるといいよ」というプラクティカルなアドバイスを期待していたのだが,そういうポストホックな発想がいかんのだ,と叱られてしまった。失礼いたしました。
どうやら「指標が潜在変数の原因側だったらformativeだ」と単純に考えるわけにもいかないようだ(うかつにformativeなモデルをつくると測定誤差がないことになってしまう)。なるほど。やっぱし勉強しなきゃなあ。
2006年11月25日 (土)
Rockhill, B., Newman, B, & Weinberg, C. (1998) Use and misuse of population attributable fractions. American Journal of Public Health. 88(1): 15–19.
[背景] 人口における疾病リスクのうち,リスク要因の因果的効果に帰属されうる割合のことを人口寄与部分(Population Attributable Fractions)という(人口寄与リスク,人口寄与リスク割合,超過部分ともいう)。この指標は<もし問題の要因への曝露を除去することができたら,一定の時間幅のあいだの疾病リスクの平均が何割減っただろうか>というかたちで定義されることが多い。<曝露の除去によって防げていたはずの症例数の割合>としても解釈できる。(ここでいうリスクとは正確には「リスクの部分」のことであるからして,よく用いられる「人口寄与リスク」という言葉は不正確である。)
[計算方法] 疾病D, リスク要因への曝露をE, 交絡要因をCとすると,人口寄与部分は
{(疾病確率)-(交絡要因の水準を通して平均した,非曝露時の疾病確率)} / (疾病確率)
={P(D) - \sum_C P(D|notC, notE) P(C) } / P(D)
となる。その推定式にはいろいろあるけど,たとえば以下。
a) {(疾病率)-(非曝露群の疾病率)}/(疾病率)
※疾病率が低ければ,{(発症率)-(非曝露群の発症率)}/(発症率) で近似できる
b) {(曝露率)×((リスク比)-1)}/{(曝露率)×((リスク比)-1)+1}
[分散的特性] 人口寄与部分は曝露カテゴリ特定な寄与割合(もしその曝露カテゴリだけが非曝露群にシフトしたら,疾病リスクが何割減るか)の合計であるといえる。曝露の定義が包括的になるほど,人口寄与部分は増える。しかし同時に,曝露群の割合が5割を越えて増えるにつれて,人口寄与部分の標準誤差は増え,正確でなくなってしまう。
[計算の誤り] (略)
[概念的問題]
- <複数のリスク要因についてそれぞれの人口寄与割合を求め,それを合計する>のはよくある誤りである。1を越えても知らないぞ。
- Seidman et al. は,10個の乳ガンリスク要因の人口寄与割合を,30-54歳女性において0.21, 55-84歳女性において0.29と推定している。ここで彼らが「たいていの乳ガンはリスク要因がない女性において起きるのだ」といっているのは間違いである。人口寄与割合は患者におけるリスク要因への曝露率ではないからだ(現に,患者のなかでリスク要因を一つでも持っている人の割合は,0.76, 0.82である)。さらに,患者の約1/4についてその原因が特定できた,というのも間違いである。人口寄与割合は,当該のリスク要因を取り除いたら患者の1/4が取り除かれていただろう,ということにすぎず,そのリスク要因によって引き起こされた患者とそれ以外の患者を区別してくれるわけではない。
- 人口寄与割合が役に立つのは,関心のあるリスク要因とエンドポイントとの間に明確な因果的関連があり,かつ曝露にたいして介入が可能だというコンセンサスがあるときである。しかし多くの場合,修正不能な属性や疾病の前臨床マーカを,リスク要因の代理変数として用いた分析が行われてしまっている。乳ガンに対する結婚の人口寄与割合だとかなんとか。
- 公衆衛生における介入方略の優先順位をつける際には,曝露-非曝露のカットオフポイントは現実的観点から定義しなければならない。たいていの症例は,平均的なリスク要因の持ち主から生まれている。慢性病についての人口寄与割合は,"曝露"の定義をよほど緩くしないと高くならないし,そうすると,誰も彼もを非曝露群にシフトさせないといけないという話になってしまう。
- 人口寄与割合を,リスク要因によって"説明"された患者の割合だと述べると,混乱を招く。"説明"をそのような意味で用いるなら,「15歳以上であること」を乳ガンのリスク要因だとみなせば,すべての患者はこの要因で"説明"できることになってしまう。
いわゆるPAR%の誤用についての短いコメント。仕事の都合で読んだ。あれこれ探したところ,population attributable riskよりもpopulation attributable fractionのほうが検索にひっかかりやすい。へー。
リスク要因の代理変数についてPARを求めるのは誤用だ,というのは納得だが(抑うつと肥満に対するSESのPARだなんて,調べてどうすんじゃと思うわね,確かに),じゃあそういうときは何を使えば良いのだろうか。単にリスク比を使えということだろうか。知識がないのでわからないぜ。
2006年11月 6日 (月)
Tomarken, A.J. & Waller, N.G. (2005) Structural equation modeling: Strengths, Limitations, and Misconceptions. Annual Review of Clinical Psychology, 1, pp.31-65.
SEMの使い方レビュー。
この論文はfprでみかけて,今年の春先に読み始めたのだが,直後の転職のどたばたで中断してしていた。いったん途中でやめるとどうにも気が乗らなくなり,ずっと鞄に放り込みっぱなしだったのを,このたび無理やり読みおえた。論文の中身とはなんの関係もないが,やれやれ,ようやく一区切りついたという気分である。
2006年8月31日 (木)
Carroll, J.D., Green, P.E. (1995) Psychonomic methods in marketing analysis: Part I., Conjoint analysis. Journal of Marketing Research. 32(4), 385-391.
コンジョイント分析の概説。P. Greenの著作アーカイブで入手。仕事の都合で読んだ。
2006年1月30日 (月)
Vandenberg, R.J. & Lance, C. (2000) A Review and Synthesis of the Measurement Invariance Literature: Suggestions, Practices, and Recommendations for Organizational Research. Organizational Research Methods, 3(1), 4-70.
測定不変性についての文献(方法論と実用例)を集めて,どういう段取りを取っているかを整理したレビュー。普通のCFAの分野に絞られていて,知りたかったこと(カテゴリカルSEMの話やIRTとの関係)は載っていなかったのだが,知識の整理になったのでよしとしよう。
こういう長い論文は,去年までだったら二の足を踏んでいたところだが,最近はなぜか気軽に読める。きっと真剣な関心を持っていないからだろう。
Crawford, J.R., Garthwaite, P.H., Howell, D.C., & Gray, C.D. (2004) Inferential methods for comparing a single case with a control sample: modified t-tests versus Mycroft et al.'s (2002) modified ANOVA. Cognitive Neuropsychology, 21(7), 750-755.
先日Iくんにもらって読んだ論文を批判した論文。Google Scholar で見つけた。便利な世の中になったものである。
論点は,(1)Mycroftの帰無仮説はおかしい,(2)患者群の母集団なるものの分布の形状が統制群と同じで分散だけ大きいと仮定するのは変だ,(3)実用性がない(患者群の分散なるものは見当がつかないし検定力も落ちる),(4)それに引き替え我々の手法のなんと柔軟なことか。
「ひどい論文だけど,まあココロザシは誉めてやるよ」と云わんばかりのコテンパンぶりで,なんだかコワイ。
先日俺が真剣に考えたことがことごとく網羅されている。最初はちょっと嬉しかったけど(同志よ!なんて思ってしまった),よく考えたらこんなに虚しいことはない(向こうは俺のことを同志だと思ってくれるわけじゃない)。なにやってんだかなあ。
2006年1月20日 (金)
Mycroft, R.H., Mitchell, D.C., & Kay, J. (2002). An evaluation of statistical procedures for comparing an individual performance with that of a group of controls. Cognitive Neuropsychology, 19(4), 291-299.
ひょんなことからIくんが送ってくれた(感謝!)。
ケース・コントロール研究でケースがN=1のときは,まずコントロール群の分布から母平均と母分散を推定し,それらを使ってケースの値を標準化し,それがN(0,1)の両側5%に落ちるかどうか調べたり,あるいはコントロールの分散だけを使ってANOVAをやったりするのが普通である。しかし,ケース群の真の被験者間変動は,実はコントロール群の被験者間変動よりはるかに大きいことが多い。そんなときはType Iエラーが大きくなってしまうので困る。そこでこのたび,モンテカルロ法で適切なF臨界値を求めました。という論文。
ケース群のほうが標本分散が大きいから困ったねどうしようか,という話ではなくて,ケースの値がほんとに1個しかない(繰り返しがない)ときにコントロールとどうやって比較するかという話である。そこのところでちょっと戸惑ったけど,でも問題意識ははっきりしているし説明は丁寧だし,わかりやすい論文だと思う。提案している方法は,要するに検定力を削ってαを無理矢理保つという話だと思うけど,こっちの業界ではきっと検定力なんて気にならないんだろう。
それでもなお,この論文からはなんだか奇妙な印象を受ける。ケースはヤマダさんだけですというタイプのケース・コントロール研究は,「ヤマダさんは(コントロール群に代表される)健常者の母集団からのサンプルだ」というH0を棄却しようとするのが普通だ。だからこそ,コントロール群の分布から推定した母集団パラメータを使ってケースの値を標準化してみたり,コントロールの分散だけを使ってANOVAをやったってみたりするのである。著者はそういう分析について,ケース群の被験者間変動の大きさを無視していると批判するけれども,そういう研究はそもそもケース群というものを考えていないのだ。
N=1ということは,ケース群の分布についての実証的な証拠が手元に無いんだから,あくまでヤマダさんについてのH0を立てるのが,なんというか,自然であろう。もちろん研究の関心はヤマダさんその人にあるのではなく,ヤマダさんに代表されるナントカ患者の一般的性質にあるのだけれど,ケースから得た知見をナントカ障害へと一般化する推論は実質科学的なレベルの問題だ,というのが,常識的な考え方なんじゃないかと思う。
ところがこの論文では,ヤマダさんからナントカ障害への一般化を統計的推論の道具立てに繰り込んでしまい,「(ヤマダさんに代表される)患者の母平均は,(コントロール群に代表される)健常者の母平均と同じだ」というH0を設定する。それはそれで一つの考え方だと思うけれど,そういう考え方が必要になるのはいったいどういう問題状況なのか,うまくイメージできない。いいじゃん,ヤマダさんについて検定してれば。
さらにいえば,臨床研究では「患者の母集団平均」なるものを問題にすることそのものが無意味な場合も少なくないと思う。この点はちょっと自分の中で整理できていないんだけど,たとえば「高血圧患者の血圧の平均」ってなんだろう? 普通の人より高い,ちょっと高い人もいればすごく高い人もいる,としか云いようがないと思う。
まあいいや,俺にわからんだけで,「ケースの母集団分布」について検討するのが必要かつ有意義であるような問題状況が,きっとどこかにあるのだろう。次のハードルは,その母集団分布について正規性を仮定しなければならないという点だ。さらに,ケースのσがコントロールのσの何倍くらいなのかがわからないと,この論文の手法は使えない。ケースはN=1なのに,どうやって見当をつけるんだろう?
きっとどこかで役に立つんだろうけど,でもいったいどこで役に立つのか想像がつかない。そういう意味で面白い論文だった。
2006年1月15日 (日)
Seltzer, M.H., Frank, K.A., & Bryk, A.S. (1994). The metric matters: The sensitivity of conclusions about growth in student achevement to choice of metric. Educational Evaluation and Policy Analysis, 16(1), 41-49.
著者に送ってもらった(ありがたきかな)。データ解析の論文を読むのはもう止めようと思うのだが(今度こそ縁が切れるかもしれん),そんなわけでこれは大急ぎで読了。
みなさん学力変化を調べるときにGEをつかっていませんか。GEスコアの群平均の変化は宿命的に時間線形になるわけでよろしくないですよ。個人ベースのLGMであってもミスリーディングな結果を呼びますよ。ちゃんとIRTつかいなさい。という主旨。
恥ずかしながらよく知らなかったのだが,GE(grade equivalent)スコアというのは,5年生第7ヶ月目月末の集団の得点平均が60点だとしたら,60点のことを5.7と呼ぶ,というもの(学期だけみるので,1年は10ヶ月)。ってことは,5年生向けのテストでも他学年のサンプルをとっておかねばならんということかね。
主旨自体は当たり前なんだけど,GEを使ったせいで生じる誤解の具体例が面白い(Iowa Test of Basic Skillsで実例を示している)。たとえば,群平均の成長曲線のまわりで個人差がラッパ型になったりする。なんだかもっともらしく解釈しちゃいそうだけど(「学力格差が増大しています」とか),これはGEを使ったせいで起きたartifactなのである。なるほど。
身近な問題に当てはめると,学力変化を捉える際にテストの標準化得点(偏差値)の推移を見ててもだめだなあ,というのは日々考えることだし,現場の人も感じていることだと思う。とはいえ,IRTで等化するのはなかなかままならない(テスト項目を使い捨てる日本の教育評価にもそれなりの事情と美点があると思うので,そこを批判しても仕方がない)。なかなか難しい問題である。それでも,その難しい問題に取り組まなきゃいけないよなあ,と思うのである(その努力を放棄したところに残るのは精神主義だけだと思うから)。標準化得点でできる分析はどこまでか,その限界をはっきりさせたい。
思うに,この論文で指摘されているGEの問題点は,時間に対する変化量を時点間で比較できない(時間関数が構築できない)ということだ。だったら,LGM的なアプローチを捨て,時間経過を定量的に捉えるのをやめちゃって,たとえば反復測定SEMで時点ごとに変化量を推定するのであれば,GEなり標準化得点なりを分析してもかまわないのだろうか。あるいはLGMであっても,時間経過を推定しちゃえばいいのか。うーん,俺の能力を超える問題だなあ。
2005年12月26日 (月)
Curran, P.J., and Bollen, K.A. The best of both worlds: Combining autoregressive and latent curve models. in Collins, L.M. and Sayer, A. (eds.) New methods for the analysis of change (pp.107-135). APA.
「Collins&Sayerひとり読書会」第三弾。
LGMに一次の自己回帰を組み込むという話。二変量LGMで成長因子間に相関があることがわかっても、どっちの変量が原因側かはわからないが、クロスラグ(なんて訳すのだろうか)を調べればそれがわかる。云々。
成長因子間の相関とクロスラグの両方をモデルに入れても、識別可能なモデルは組めるらしい。ふうん、そういうものか。
NLSYデータで実演してくれているのがありがたい(綺麗な分析例とはお世辞にもいえないんだけど、そこがまた良い)。これは役に立ちそうだ。プログラム例があればもっと助かるんだけどな。
2005年12月24日 (土)
McArdle, J.J. and Hamagami, F. (2001) Latent difference score structural models for linear dynamic analyses with imcomplete longitudinal data. in Collins, L.M. and Sayer, A. (eds.) New methods for the analysis of change (pp.139-175). APA.
「Collins&Sayerひとり読書会」第一弾。通勤電車と昼休みと勤務時間だけで一冊読み終えようというのがポイントである。
latent difference score analysisの紹介。基本的なアイデアは: T時点の個人成長曲線 Y_0, Y_1, ..., Y_Tについて、それはその裏にある潜在曲線 y_0, y_1, ..., y_Tにホワイトノイズが乗ったものだ、と考える。で、このy_tについてのモデルを考えるんじゃなくて、さらに「隣り合う2時点間の差」を表す潜在変数Δy_1, Δy_2, ..., Δy_Tを考える。y_tにはy_{t-1}からのパスとΔy_tからのパスが刺さるわけだ。このΔy_tについてモデルを組む。要するに、普通のLGMより層がひとつ増えているような感じだ。ふうん。
NLSYデータを使った分析例が載っていたが(プログラム例はなし)、そこは飛ばして読了。そのせいか、この手法のメリットがまだよく理解できていないのだが、まあいいや、あとで考えよう。
Graham, J.W., Taylor, B.J., and Cumsille, P.E. (2001) Planned missing-data designs in analysis of change. in Collins, L.M. and Sayer, A. (eds.) New methods for the analysis of change (pp.335-353). APA.
「Collins&Sayerひとり読書会」第二弾。
不完全データの話ってどうにも関心が持てない(新手法のおかげで新発見できるわけじゃないからだろうな)。この章は優先順位が低かったのだが、missing by designつきの時系列データをどう扱うのか調べる必要があって、急遽繰り上げて読んだ。
想像とは異なり、どういうデザインならパワーが落ちないかをシミュレーションしましたという話であった。分析手法はAllison(1987)とMuthen et al.(1987,Psychometrika)に従った由。Psychometrikaの論文なんて読みたくないよ。。。
2005年12月 6日 (火)
Nagin, D.S. (2002) Overview of a semi-parametric, group-based approach for analyzing trajectories of development. Proceedings of Statistics Canada Symposium 2002: Modelling survey data for social and economic research.
Webで拾った。論文でさえないのだけれど,せっかく目を通したので。
Ferrer, E. and Nesselroade, J.R. (2003) Modeling Affective Processes in Dyadic Relations via Dynamic Factor Analysis. Emotion, 3(4), 344-360.
ネットで拾った。動的因子分析を使いましたという主旨の論文。ということは,感情研究方面でもそんなにポピュラーな手法じゃないってことだろうか。
対象は夫婦1組,データは二人が半年にわたって毎晩回答した気分評定。ポジ感情とネガ感情の因子がある(2人×2因子で4本の時系列曲線があるようなものだ)。ラグ付きの構造があると考えて,(1)ラグ2まで考えれば十分ということを示す。(2)モデルを比較したところ,前日までの旦那の気分が女房に影響するというモデルの適合度が良い。(3)交差妥当化の真似事のようなことをして確認。
SEMのモデル比較が決め手になっている研究を見ると,なんだかキツネにつままれたような気がしてしまう。どうせ俺が不勉強なだけなんだろうけどさ。
時系列変化が非定常な場合には別の手法を使えとのこと。ちょっとがっくりだけど,読むべき文献がわかったので良しとしよう。
block-toeplitz行列をつくる方法がわからなくて困る。豊田本(「応用編」)はSAS/IMLをつかっているので駄目。未確認だがWood&Brown(1994PB)もそうらしい(semnetのログに、Woodさんの「欲しけりゃやるよ」という投稿があった)。MATLABにもtoeplitzという関数があるようだが、やはり処理系がない。こないだ読んだHershbergerはFortranのプログラムを書いた由であった。このFerrerさんもavailable upon requestだと書いている。
2005年11月16日 (水)
Nagin, D.S. (1999) Analyzing Developmental Trajectories: A Semiparametric, Group-Based Approach. Psychological Methods, 4(2), 139-157.
ここしばらくの間、昼飯時にだらだらめくっていたのだが,きりがないので読み終えたことにしておく。いわゆる成長曲線モデルとは発想がちょっとちがうようだ。
2005年11月15日 (火)
Hershberger, S.L. (1998) "Dynamic Factor Analysis." in Marcoulides, A. (ed.), Modern Methods for Business Research. LEA.
動的因子分析の紹介。仕事で読んだ。ざっとめくっただけだけど,読んだことにしちゃおう。
この本は私費で衝動買いしてしまったのである。元をとらねばならん。
2005年6月24日 (金)
Fidler, F., Thomason, N., Cumming, G., Finch, S., Leeman, J. (2004). Editors can lead researchers to confidence intervals, but can't make them think. Psychological Science, 15(2), 119-126.
かつてKenneth Rothmanという疫学の有名な先生が,American J. Public Healthという雑誌の副エディターになったとき,担当した投稿論文すべてに対して「仮説検定についての記述を削るか,さもなくば他の雑誌に出せ」と命じた。そこで掲載論文を調べてみると,たしかにその4年間はp値の使用が激減しているが,Rothmanが辞めるとすぐに元に戻っている。いっぽう信頼区間の掲載はこの時期から定着しているものの,結果の考察には用いられていない節がある。心理学に対する教訓:「検定よりも信頼区間を使いましょう」という決まり文句に安住するのはもうやめて,どうすればみんなが信頼区間を使うようになるのかを考えるべきだ ---という内容。
うんうんそうだよねえ,と楽しく読んだ。解析手法方面に強い人(嫌な言い方をすれば,統計マニアの人)は,仮説検定論の問題点を好んで主張するけど,特に代替案があるわけではなかったりすることも多くて,単に批判が好きなだけと違うか?というような感じを受けることがままある。まあどうでもいいけど。
Loftus(旦那のほう)は,Memory&Cognitionのエディターになったとき,信頼区間を書いてくれと投稿者に頼んでも埒があかないので,自分でいちいち計算してやったそうだ。ははは。
こういうメタレベルな研究は読んでいてとても楽しい。きっと性にあうのだろう。
この論文の後で,信頼区間は検定のかわりにならないというコメントも載ったようだ。CIは群内の分布を記述するためには便利だが,群間の差について推論するなら効果量のほうが便利だ,という趣旨らしい。ふうん。
2005年5月23日 (月)
Muthen, B. (2004). Latent variable analysis: Growth mixture modeling and related techniques for longitudinal data. in Kaplan, D. (ed.) "The SAGE Handbook of Quantitative Methodology for the Social Sciences." pp. 345-368.
Mplusのページから。一般成長混合モデルについてのユーザ向け解説。非常にわかりやすく,目の覚める思いであった。PROC TRAJがなにをしておるのかということが,Jones,et.al. ではなくてこれを読んでようやくわかった次第だ。もうトヨダヒデキの本読むのが嫌になってしまった(失礼な...)。Muthenさんステキ,ついていきますです。
2005年5月18日 (水)
Moon, S.M., Illingworth, A.J. (2005) Exploring the dynamic nature of procrastination: A latent growth curve analysis of academic procrastination. Personality and Individual Differences, 38, 297-309.
いわゆるギリギリ・ボーイズ&ガールズについての研究。締め切りまでの課題遂行の推移は双曲線みたいになりました、曲線の形には個人差はありませんでした。つまり特性論的アプローチは怪しいです。云々。
どこか忘れたが,ネットで拾った論文。そもそも、こんな問題が研究されているということ自体が新鮮で面白かったんだけど(procrastinationってなんて訳すんだろう?)、課題状況が人工的に過ぎるような気がした。まあどうでもいいけどさ。
縦断データ分析の手法としては、(1)潜在成長モデルをいくつかつくってあてはまりを比較したら二次式の勝ち、(2)曲線の一次と二次の係数(SEMでいえばこれが潜在変数)のばらつきが小さいから曲線の形には個人差がない、という理屈。ほかにも外生変数をいれたりしてるけど、パス図がないのでわかりにくい。ちょっとしょぼい感じの論文であった。
どうも腑に落ちないんだけど,潜在曲線の係数の分散が小さかったら,曲線の形状の個人差が小さいことになるのか? SEMの枠組みでいえば,「因子分析をやったらある因子の得点の分散が小さかったです,だからその特性の個人差は小さいです」という主張をしているようなもんなんじゃないか,と妙な気分なのだが,潜在成長モデルでは潜在変数から伸びるパス係数が定数になってるから、普通のSEMとは事情が違うのかも知らん。うーんよくわからん。大学ならまわりの人に相談できるんだけどな。
2005年5月17日 (火)
Carrig, M.M., Wirth, R.J., & Curran, P.J. (2004) A SAS Macro for Estimating and Visualizing Individual Growth Curves. Structural Equation Modeling, 11(1), 132-149.
掲載誌のサンプル号から(著者のページにもあった)。ひとりひとりの成長曲線をグラフにするSASのマクロを作りましたという話。あーそーですか。
2005年5月16日 (月)
Muthen, B. & Muthen, L.K. (2000) Integrating Person-Centered and Variable-Centered Analyses: Growth Mixture Modeling With Latent Trajectory Classes. Alcoholism: Clinical and Experimental Research, 24(6), 882-891.
Mplusのページから。潜在クラス分析,潜在transition分析,潜在クラス成長分析,成長混合モデル,一般成長混合モデルについて紹介した啓蒙論文。タイトルがちょっと大上段なのは,どうやら雑誌の特集テーマとあわせたかららしく,内容はとてもわかりやすい。収穫であった。もっとも,これを読んでも自分で分析できるようになるわけではない。Mplusを買いやがれ,ということだろうな。
Jones, B.L., Nagin, D.S., & Roeder, K. (2001) A SAS Procedure Based on Mixture Models for Estimating Developmental Trajectories. Sociological Methods & Research, 29(3), 374-393.
著者のページから。PROC TRAJというのをつくったからつかってね,という論文。Muthenの論文でいえば LCGMにあたるのだろうか。数理の論文はからきし読めないんだけど,こんなふうに全く理屈抜きだと,それはそれで不安になる。
2005年4月30日 (土)
Borsboom, Mellenbergh, & van Heerden (2004). The Concept of Validity. Psychological Review, 111(4), 1061-1071.
忠実度と帯域幅のジレンマについて一言でうまく説明できないかと,ネットを検索していてみつけた論文。著者のページから。火曜日だったかの昼休みに,川縁の公園で読み始めて,なんだかおかしくてくつくつと笑いながらめくったのだが,内容が面白いせいなのか,久しぶりに英語の論文を読むのが変な気分だったからなのか,区別がつかない。わからんところは飛ばして読了。今後は論文など滅多に読まなくなるだろうし,本と一緒に記録することにしよう。
妥当性というのは実在とデータの因果関係の問題なんであって,相関でそれが示せると思ってる連中や法則ネットワークの中での意味だとか解釈だとかを持ち出す連中はみなアホだ,アホアホだ。という主旨。クリアーですねえ。
もともと妥当性という概念自体についてよく知らなかったし,構成概念妥当性というのがそんなに広い概念だということもよくわかっていなかった手合いなので,ふうんわかりやすいなあ,という感想しか持てない。研究者に対する示唆としては,測定対象と得点のあいだの因果的モデルを作るべし,ということなのだが,実験研究というのは元来そうしたものなので(ラフな反応時間研究が疑いのまなざしで見られる所以である),あまり違和感がない。きっとテスト方面の人にとっては論争的な論文なんだろうなあ。
測定についてめっさ強い実在論の立場をとっているところ,哲学的にはちょっとナイーブなんじゃないかしらと疑問なのだが,その辺の議論は面倒で読み飛ばしてしまったから,なんともいえない。
(そういえば,「心理テストはウソでした」を読んでいたとき,YGの結果を因子分析しても12因子にはならないからYGには妥当性がない,という論法があって,それはいかがなものかと思ったものだ。まず因子的妥当性がそんなに大事なものなのかどうかがわからないし,ここでは12因子を想定する根拠がポイントなのだから,その想定の下でつくった質問紙で因子的妥当性が示せるかどうかはもはやどうでもよいのではないか。その辺,この論文の過激な言い回しにも共感できる。)